Using Elastic machine learning rare analysis to hunt for the unusual
It is incredibly useful to be able to identify the most unusual data in your Elasticsearch indices. However, it can be incredibly difficult to manually find unusual content if you are collecting large volumes of data. Fortunately, Elastic machine learning can be used to easily build a model of your data and apply anomaly detection algorithms to detect what is rare/unusual in the data. And with machine learning, the larger the dataset, the better.
One of the main reasons we use anomaly detection is to find rare or unusual users, processes, or error messages (among other things) in time series data. Using anomaly detection to find rare entities over time, or entities acting unusually, can be a signal of something compelling in the data stream. For example, rare data can be indicative of unauthorized access or a potential problem brewing.
Using machine learning to identify rare data in a time series model can sometimes be confused with outlier detection. Rare detection looks for rare events based on frequencies, while outlier detection identifies “rare” entities based on distance and density metrics in an n-dimensional (time independent) space.
This blog is going to dive deeper into rare functions, but if you prefer learning by video, jump down to the bottom of this post.
When to use a rare function in anomaly detection
Elastic machine learning supports several different functions that provide a wide variety of flexible ways to analyze time series data for anomalies. We can model counts of events, like user activity or error codes. We also can use metric functions to look for anomalies in the value of something, such as mean transaction times. In these cases, we are aggregating these values in time by rolling data up into configurable time intervals, or bucket spans.
Rare functions are their own class of functions that detect values that occur infrequently in time or within a population. For example, you can use the rare function to look for unusual user activity or an unusual or new exception error occurring in an application.
Rare functions are often used for security threat hunting because rare events in a security context can be a valuable indicator that something unusual is happening. For example, we can use rare functions to look for suspicious users based on their login frequency or identify processes that are run on machines that don’t often encounter them.
Types of rare analysis
You can use the table below to translate potential business problems to machine learning jobs.
| Goal | Example | Machine learning function |
| Find infrequent values for a field. | Detect hosts that are occurring infrequently. | Rare by X Ex: Rare by host |
| Find infrequent values for a field compared to other values. | Detect hosts that are visited by a small number of users compared to other hosts, or detect users that visit one or more rare hosts. | Rare by X over Y Ex: Rare by host over user |
| Find infrequent values for a field segmented by another field. | For each location, detect infrequently seen hosts. | Rare by X partitioned by Y Ex: Rare by host partitioned by location |
| Find infrequent values for a field by another field compared to similar results. | For each location, detect hosts that are visited by a small number of users compared to others, or detect users that visit one or more rare hosts in a location. | Rare by X over Y partitioned by Z Ex: Rare by host, over user, partitioned by location |
How bucket frequency affects results
The rare detector counts frequencies based on a scale of bucket length, the amount of time in each interval. All the entities are aggregated into a time bucket and if an entity appears in that bucket then it is counted. The model only counts whether the entity appears in the bucket, not how many times it appears.
This makes the rare detector particularly sensitive to changes in bucket span. If you increase the bucket span, it is likely that more entities will appear per bucket span, so you should be looking to use a bucket span that captures the frequency of the rare actions you want to identify. If the job is identifying things that you don’t consider rare, you can try increasing bucket span.
How rare anomalies are scored
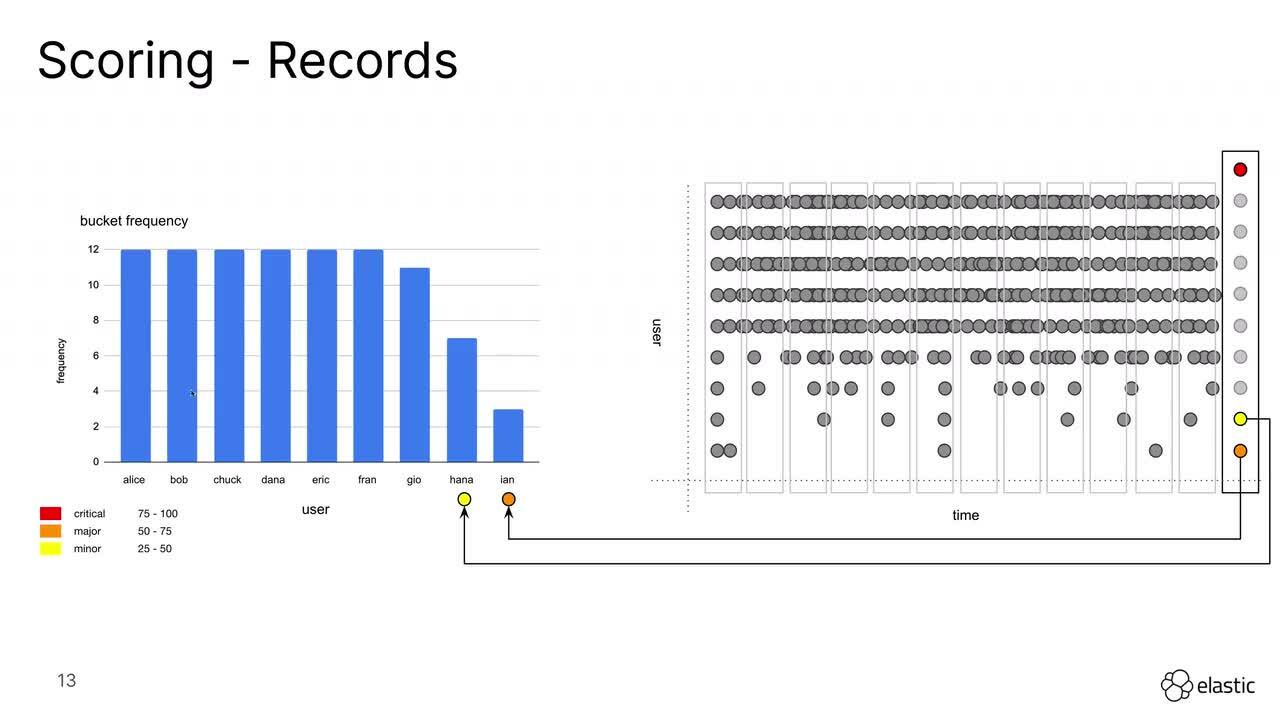
As with all of the other anomaly detection functions in Elastic, the rare function utilizes a severity scoring system to indicate how unusual a particular anomaly is compared to the rest of data that is being modeled. Because it is based on a time series model that is aggregated by interval bucket spans, the anomalies are based on time intervals and are not associated with individual documents. For example, within a time bucket there is no difference between a user logging in a thousand times and a different user logging in one time.
When partitioning anomaly detection jobs both the individual records, and the time buckets will receive severity scores. The individual record indicates how unique a value is compared to the partition over time. The overall score indicates how rare an individual time bucket is compared to others.
Using the rare function in anomaly detection for security
The rare function can be very useful for identifying signals from rare or unique instances within your data when understood and used correctly. It is the most common anomaly detection function that gets used within Elastic Security and a very important part of any security practitioner’s tool box.
In the case of rare detectors, it can be helpful to show you how it works, so we created this video:
Wrapping up
We hope you found this post useful for understanding rare detectors in Elastic machine learning. If you'd like to try them out for yourself in your security or observability use case, you can spin up a free trial of Elastic Cloud. And check back in soon, as we'll be putting out a few more posts diving deeper into specific use cases for rare detectors.