Elastic Search 8.14: Faster and more cost-effective vector search, improved relevance with retrievers and reranking, RAG and developer tooling


 Share on Twitter
Share on TwitterShare on Twitter

 Share on LinkedIn
Share on LinkedInShare on LinkedIn

 Share on Facebook
Share on FacebookShare on Facebook

 Share by Email
Share by EmailShare by Email

 Print this page
Print this pagePrint
We're committed to pushing the boundaries of search development and focusing on empowering search builders with powerful tools. With our latest updates, Elastic becomes even more potent for customers dealing with vast amounts of data represented as vectors. These enhancements promise faster speeds, reduced storage costs, and seamless integration between software and hardware.
Elastic Search 8.14 is available now on Elastic Cloud — the only hosted Elasticsearch offering to include all of the new features in this latest release. You can also download the Elastic Stack and our cloud orchestration products — Elastic Cloud Enterprise and Elastic Cloud for Kubernetes — for a self-managed experience.
What else is new in Elastic 8.14? Check out the 8.14 announcement post to learn more.
Bringing ludicrously fast vector search
In our mission to provide the most powerful development platform for search builders, customers operating at the billionth scale with vectors can now get even more mileage with Elastic. Our updates significantly boost vector indexing and search speeds, reduce storage costs, and provide synergy between software and hardware.
We made improvements to the codebase for calculating distances between vectors that deliver binary comparisons of up to 6x faster than Lucene’s implementation when dealing with vector data. This optimization can have a substantial impact on vector search speed.
The Elasticsearch Python client now supports orjson, which benchmarks as the fastest Python JSON library and allows indexing numpy vectors up to 10x faster.
Scalar quantization allows vectors to be encoded with slightly reduced fidelity but large space savings. It is no longer necessary to set the index type to int8_hnsw first when creating a new index with vectors. Instead, int8 vector values will be used by default to provide users with cost-effective, yet accurate, vector searches. Our systematic evaluation found that scalar quantization had nominal effects on retrieval performance.
Customers who use vector search on Elastic Cloud from all cloud service providers will be able to take advantage of vector-optimized hardware profiles for the best software performance. These hardware profiles are now available on Azure and GCP in addition to AWS.
Democratizing search relevance with retrievers and reranking
Retrievers and reranking play crucial roles in improving the relevance and accuracy of search results. Our updates are impactful to both vector search users and those leveraging more traditional models, such as BM25.
We add the retrievers abstraction to the _search API for returning top hits using standard, knn, or rrf methods. This allows users to more easily build sophisticated multi-stage retrieval without pipeline complexities.
For example, to use KNN and BM25 retrieval methods together, it is no longer necessary to define stages using a pipeline in order to perform a KNN search, retrieve the IDs of the results, and then perform a BM25 search on said IDs. Instead, the retriever tree can be built directly into the search query:
GET index/_search
{
"retriever": {
"rrf": {
"window_size": 100,
"retrievers": [
{
"knn": {
"field": "vector",
"k": 3,
"num_candidates": 10,
"query_vector": [1, 2, 3]
}
},
{
"standard": {
"query": {
"match": {
"message": {
"query": "{{query_string}}"
}
}
}
}
}
]
}
},
"size": 5,
"fields": ["message"]
}
Reranking retrieved documents can further improve relevance by returning the relevancy ranks of documents in relation to the search query. Reranking effectively delivers semantic search to all users: RAG systems will be able to rely on the most relevant top results for context, and traditional search, such as BM25, will be able to surface the most relevant results to the top.
Elastic is the only vector database to support the Cohere Rerank 3 model and makes reranking using this model seamless through our _inference API without requiring complex multiple queries or reindexing documents. To rerank retrieved results using the Cohere model, begin by configuring the inference endpoint:
PUT _inference/rerank/cohere_rerank
{
"service": "cohere",
"service_settings": {
"api_key": <API-KEY>,
"model_id": "rerank-english-v3.0"
},
"task_settings": {
"top_n": 10,
"return_documents": true
}
}
Once the inference endpoint is specified, use it to rerank results by passing in the original query used for retrieval along with the documents that were retrieved by a search.
POST _inference/rerank/cohere_rerank
{
"input": [{{query_results}}],
"query": "{{query_string}}"
}Elevating the RAG experience
Our latest tools and enhancements are designed to elevate the RAG experience. Both the Playground and Dev Console with Jupyter notebooks empower users to experiment, refine, and iterate quickly.
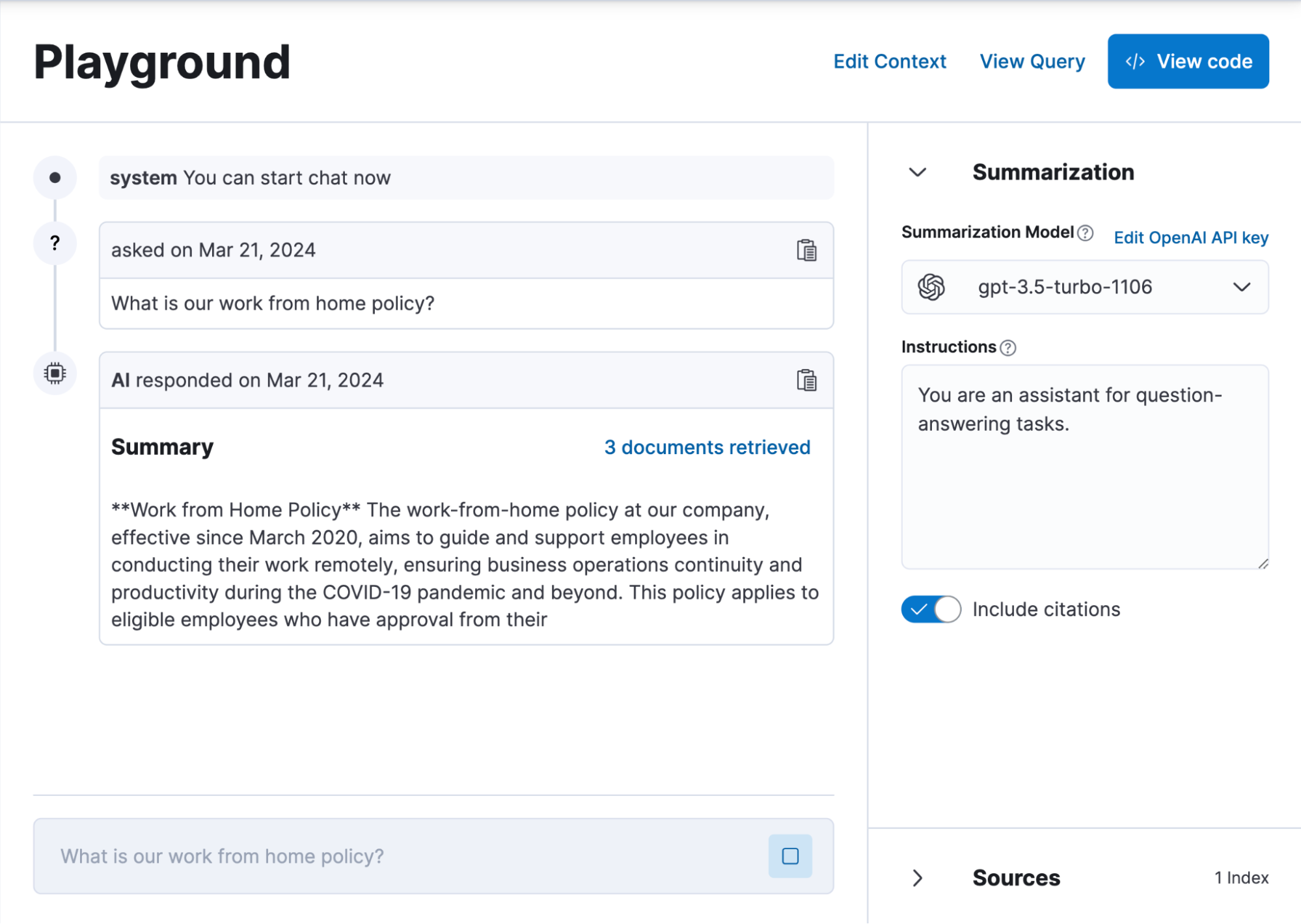
In Playground, developers can select multiple indices that are ingested from multiple third-party data sources to experiment with and refine semantic text queries, export generated code, and ultimately design a conversational search experience. This simplifies RAG implementation and allows for quick prototyping of chat experiences with Elasticsearch data to ground the LLM responses.
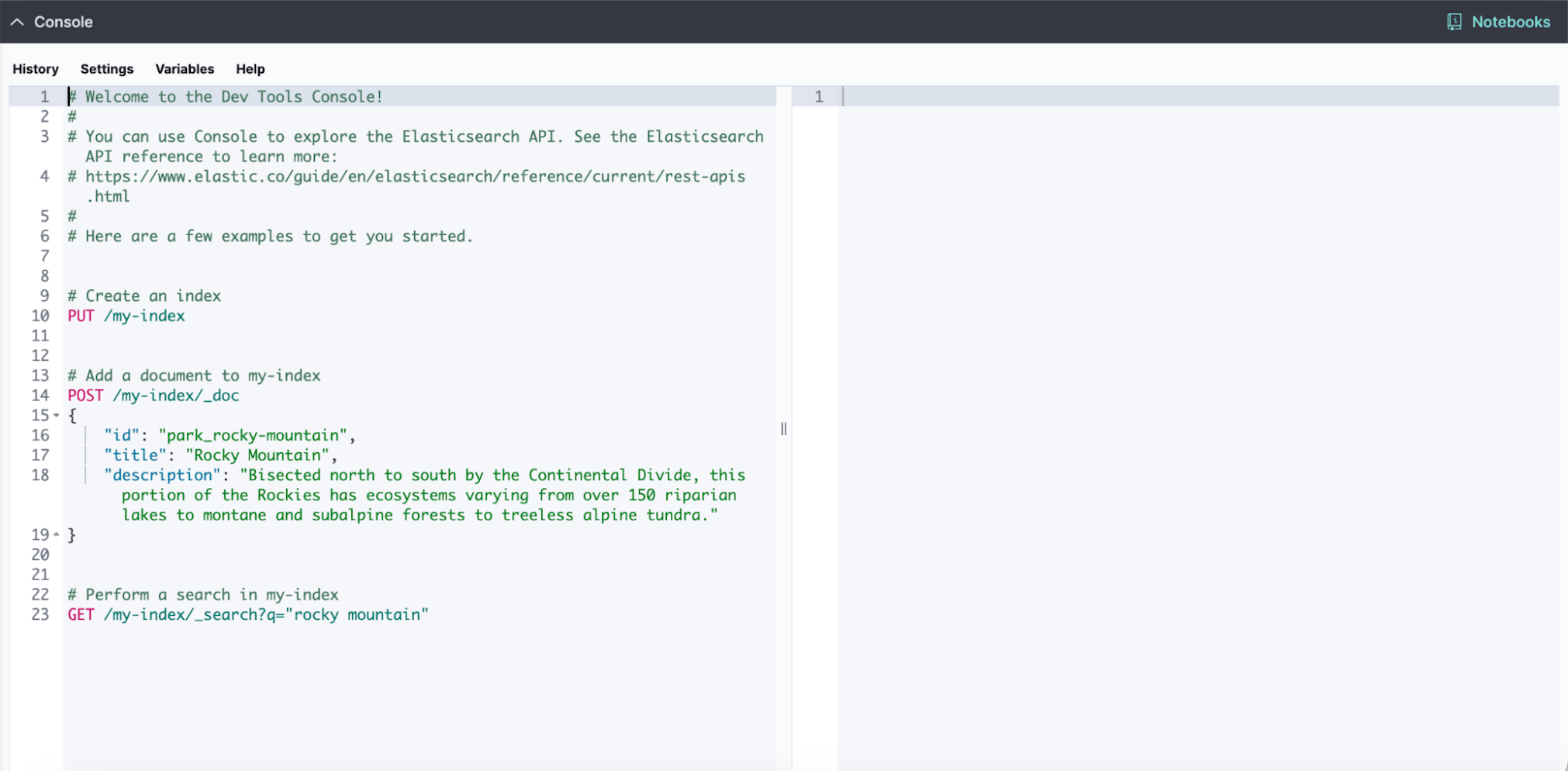
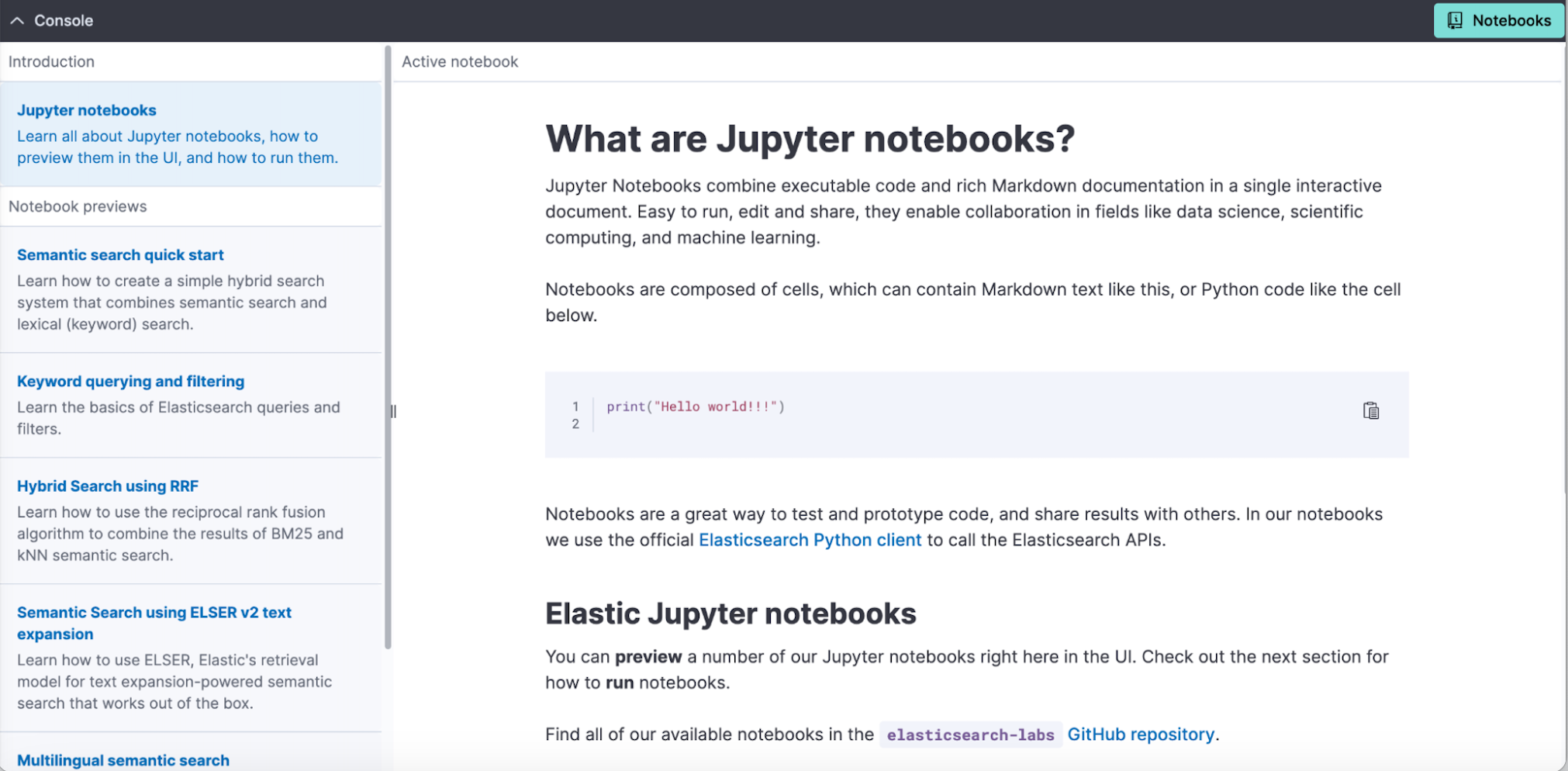
The Embeddable Dev Console is now available everywhere in Kibana to jumpstart query development with pre-populated, contextual code snippets as well as Jupyter notebooks.
We added support for getting embeddings from Azure OpenAI, unlocking advanced AI capabilities and enriching the functionality and insights of RAGs. OpenAI completion task is now available in the inference processor, streamlining the workflow for generating intelligent responses and enhancing the overall efficiency of RAG interactions.
Tooling enhancements for more effective data handling
The ability to load data into and handle data in Elastic efficiently is crucial for maintaining effective search applications. These enhancements allow users to tailor services to their specific needs and streamline development and operational processes:
Use ES|QL for easy query execution and automatic translation of results to Java objects and PHP objects.
Data Extraction Service is Open Code.
GraphQL connector is now in technical preview. GraphQL enables declarative data fetching where a client can specify exactly what data it needs from an API.
Connector API is now in beta.
- GitHub App authentication of GitHub Connector is supported.
Try it out
Read about these capabilities and more in the release notes.
Existing Elastic Cloud customers can access many of these features directly from the Elastic Cloud console. Not taking advantage of Elastic on cloud? Start a free trial.
The release and timing of any features or functionality described in this post remain at Elastic's sole discretion. Any features or functionality not currently available may not be delivered on time or at all.
In this blog post, we may have used or referred to third party generative AI tools, which are owned and operated by their respective owners. Elastic does not have any control over the third party tools and we have no responsibility or liability for their content, operation or use, nor for any loss or damage that may arise from your use of such tools. Please exercise caution when using AI tools with personal, sensitive or confidential information. Any data you submit may be used for AI training or other purposes. There is no guarantee that information you provide will be kept secure or confidential. You should familiarize yourself with the privacy practices and terms of use of any generative AI tools prior to use.
Elastic, Elasticsearch, ESRE, Elasticsearch Relevance Engine and associated marks are trademarks, logos or registered trademarks of Elasticsearch N.V. in the United States and other countries. All other company and product names are trademarks, logos or registered trademarks of their respective owners.
Share
- Share on Twitter
Share on Twitter
- Share on LinkedIn
Share on LinkedIn
- Share on Facebook
Share on Facebook
- Share by Email
Share by Email
- Print this page
Print