Elasticsearch and Kibana 8.16: Kibana gets contextual and BBQ speed and savings!


 Share on Twitter
Share on TwitterShare on Twitter

 Share on LinkedIn
Share on LinkedInShare on LinkedIn

 Share on Facebook
Share on FacebookShare on Facebook

 Share by Email
Share by EmailShare by Email

 Print this page
Print this pagePrint
The 8.16 release of the Elastic Search AI Platform (Elasticsearch, Kibana, and machine learning) is full of new features to increase performance, optimize workflows, and simplify data management.
Turn up the heat with Better Binary Quantization (BBQ) and generative AI (GenAI): Scorching speed, sizzling precision, and smoky cost savings in vector search
Elasticsearch’s new BBQ algorithm redefines vector quantization — boosting query speed, ranking precision, and cost efficiency. Achieve over 90% recall with lower latency than alternatives like product quantization (PQ) and cut RAM usage by 95%.
Kibana gets contextual: Discover the power of smarter data investigations
Kibana Discover dynamically adapts to the type of data you’re analyzing — thanks to its scalable contextual architecture. Save time and boost productivity, making data exploration smoother than ever.
Query evolution: Fast tracks, smart stacks, and geo hacks in Elasticsearch Query Language (ES|QL)
Unlock faster, easier, and more flexible querying in ES|QL with Elastic’s three new features — recommended queries, fast distance sorting, and per-aggregation filtering.
Dive in to explore these updates and more enhancements — all designed to enhance speed, productivity, and usability.
What else is new in Elastic 8.16? Check out the 8.16 announcement post to learn more >>
Enhancements in GenAI
In 8.16, Elastic has continued the pace of innovation in the generative AI space by bringing greater efficiency, scalability, and usability. With BBQ, achieve top-tier query speed and cost savings by reducing memory needs by up to 97%. The newly generally available (GA) inference API offers production-ready access to Elastic’s powerful AI models plus real-time interactions with just a few clicks. And with adaptive resources and flexible chunking strategies, you get peak performance during high demand and zero cost when idle.
BBQ
Elasticsearch introduces a novel algorithm for quantization of dense vectors, which produces incredible results in terms of query latency, ranking quality, and required computing resources (cost).
The overall concept is similar to PQ, in the sense that Elasticsearch produces a predictor vector much smaller than the original vector. The initial search is performed with the predictor vector. It then oversamples results for reranking and reranks them using the original vector to produce a subset of results in response to the query. The method in which the predictor vector is produced is completely different from PQ. It is based on generating a bit vector that is much more storage-efficient than the original vector and still has the ability to predict the correct ranking.
The bottom line is that BBQ produces excellent ranking, achieving >90% recall (compared to brute force on the original vector) with x2 to x5 oversampling. The latency is also superior to other alternatives, including PQ. Perhaps the most important thing is that the RAM needs are between 3% and 5% of those required by using HNSW on the original vectors, reducing costs dramatically. For a more complete description of the algorithm and some test results, check out this blog.
To use it, simply define the index_options to type bbq_hnsw or bbq_flat, and don’t forget to oversample and rerank with the full vector using script_score query. The functionality is still in technical preview, and we tentatively plan to make the experience of using it simpler in the coming releases.
The inference API is GA
We are thrilled to share that the inference API is now GA. Starting in 8.16, it is now recommended for production, offering production-level stability, robustness, and performance. Elastic’s inference API integrates the state-of-the-art in AI inference while offering unparalleled ease of use. It brings together Elastic’s AI semantic search model — Elastic Learned Sparse EncodeR (ELSER) — as well as your Elastic hosted models and an increasing array of prominent external models and tasks in a unified, lean syntax for use with your Elastic vector database. Used with semantic_text or the vector fields supported by the Elastic vector database, you can perform AI search, reranking, and completion with seamless simplicity.
In 8.16, we also added streamed completions for improved flows and real-time interactions and GenAI experiences. The inference API offers state-of-the-art AI inference at your fingertips with more services and tasks to follow.
ELSER, e5, trained models adaptive resources, and chunking strategies
Inference requires computing resources, so it is imperative that your model deployments adapt to the inference load automatically — scale up during high loads, such as during ingest peaks and busy search times, and scale down when the inference load drops. Until now, you had to actively manage this part, even with the Elastic Cloud ML autoscaling on. And how do you control all the parameters involved to achieve the optimal cost/performance tradeoff for your search and ingest needs at any point in time?
From 8.16, ELSER and the other AI search and natural language processing (NLP) models you use in Elastic automatically adapt resource consumption according to the inference load — providing the performance you need during peak times and reducing the cost during slow periods all the way down to zero cost during idle times. The e5 model is covered under the standard warranty with Elastic.
In addition, no convoluted configurations are required. Through a user-friendly UX, you can provision search-optimized and ingest-optimized model deployments with a one-click selection. An optimized configuration happens transparently behind the scenes. You can also easily plan for more dynamic resources toward search or ingest. We will continue improving this experience. Combined with the flexibility of ML autoscaling on Elastic Cloud and the incredible elasticity of Elastic Cloud Serverless, you are in full control of both performance and cost.

In 8.16, you can choose between a word or sequence-based chunking strategy to use with your trained models, and you can also customize the maximum size and overlap parameters. A suitable chunking strategy can result in gains depending on the model you use, the length and nature of the texts, and the length and complexity of the search queries.
Retrievers nesting in multiple layers and GA
Retrievers is an abstraction that returns top-ranking documents from a query. It was designed to allow nesting and makes it easier to define a query. Retrievers also allow further flexibility in defining the queries. The capability gained popularity since we released it in 8.14, and we’ve gotten requests to allow multiple levels of nesting. For example, users requested combining dense vector (kNN retriever), ELSER, and BM25 (standard retriever) through an RRF retriever and then reranking them with an external service using a text similarity reranker retriever, which is now supported. In 8.16, we also added support for other search functionality like collapse results and highlighting. And we made retrievers, including RRF, generally available.
The fast and the query-ous: ES|QL’s advanced new features
Elastic 8.16 introduces three powerful, new features designed to make querying faster, easier, and more flexible. Recommended ES|QL queries offer instant guidance with autocomplete options and prebuilt query suggestions that make it perfect for users at any skill level. Sorting by distance now boasts a performance boost of up to 100x for speedy geosearches and top-N queries. And with per-aggregation filtering, you can define unique filters for each aggregation, bringing pinpoint accuracy to your analytics.
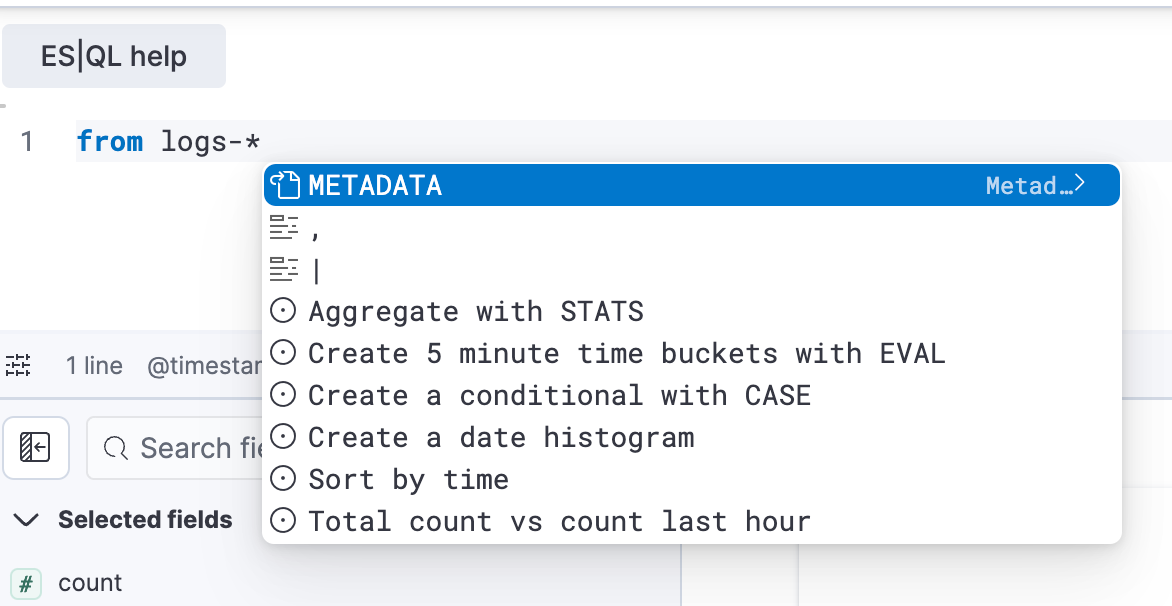
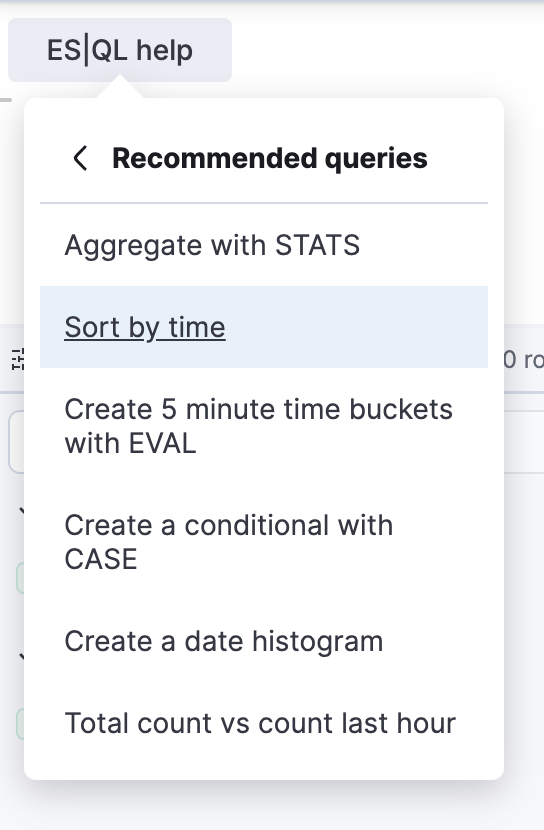
Recommended ES|QL queries
Creating queries in the ES|QL editor is now easier than ever. Recommended queries help streamline the process, especially for users unfamiliar with syntax or data structures. This feature reduces query creation time and simplifies the learning curve for both new and experienced users. You can now quickly select recommended queries from the ES|QL help menu or use autocomplete to get started faster.
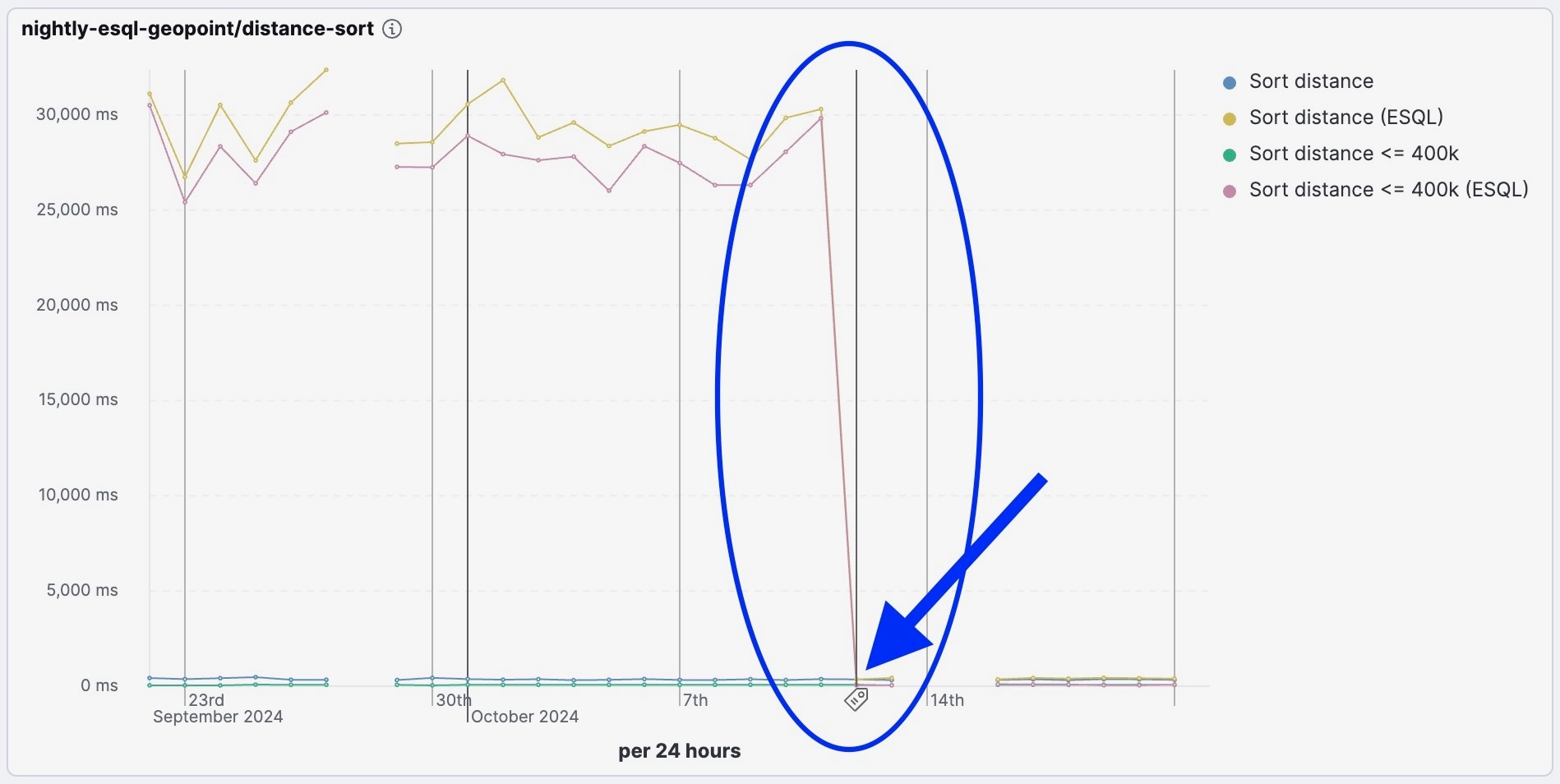
Faster sorting by distance in ES|QL
Having exposed the complete geosearch capabilities in ES|QL, we turned our attention to performance optimization — starting from the frequent case of filtering to sorting the results by distance. We got performance improvements of 10x to 100x faster for a range of queries that involve searching for documents within distances and/or sorting documents by distance. This also includes the ability to define the distance function in EVAL commands before using them in WHERE and SORT commands. Our best results — with around 100x faster queries — are the very useful top-N queries, sorting and limiting the results, as presented in our nightly benchmark dashboard:
Per-aggregation filtering in ES|QL
Aggregations in ES|QL gets even more flexible in 8.16. Now, you can define a filter per aggregation in your query, such as calculating count statistics based on different criteria for different groups like status codes for a web server:
FROM web-logs | STATS success = COUNT(*) WHERE 200 <= code AND code < 300,
redirect = COUNT(*) WHERE 300 <= code AND code < 400,
client_err = COUNT(*) WHERE 400 <= code AND code < 500,
server_err = COUNT(*) WHERE 500 <= code AND code < 600,
total_count = COUNT(*)
Dashboard dash and data flash: Kibana’s new tricks in 8.16
Kibana 8.16 elevates user experience with powerful new features for Discover, dashboards, and navigation designed to boost productivity and streamline data exploration. Discover now adapts data tables based on data type, making it easier for users to analyze logs. Dashboards gain quick access features with recent views, favorites, and usage insights. Additionally, a new solution-focused left-menu navigation tailors the interface for Search, Observability, and Security users — bringing a more intuitive and efficient experience across Kibana.
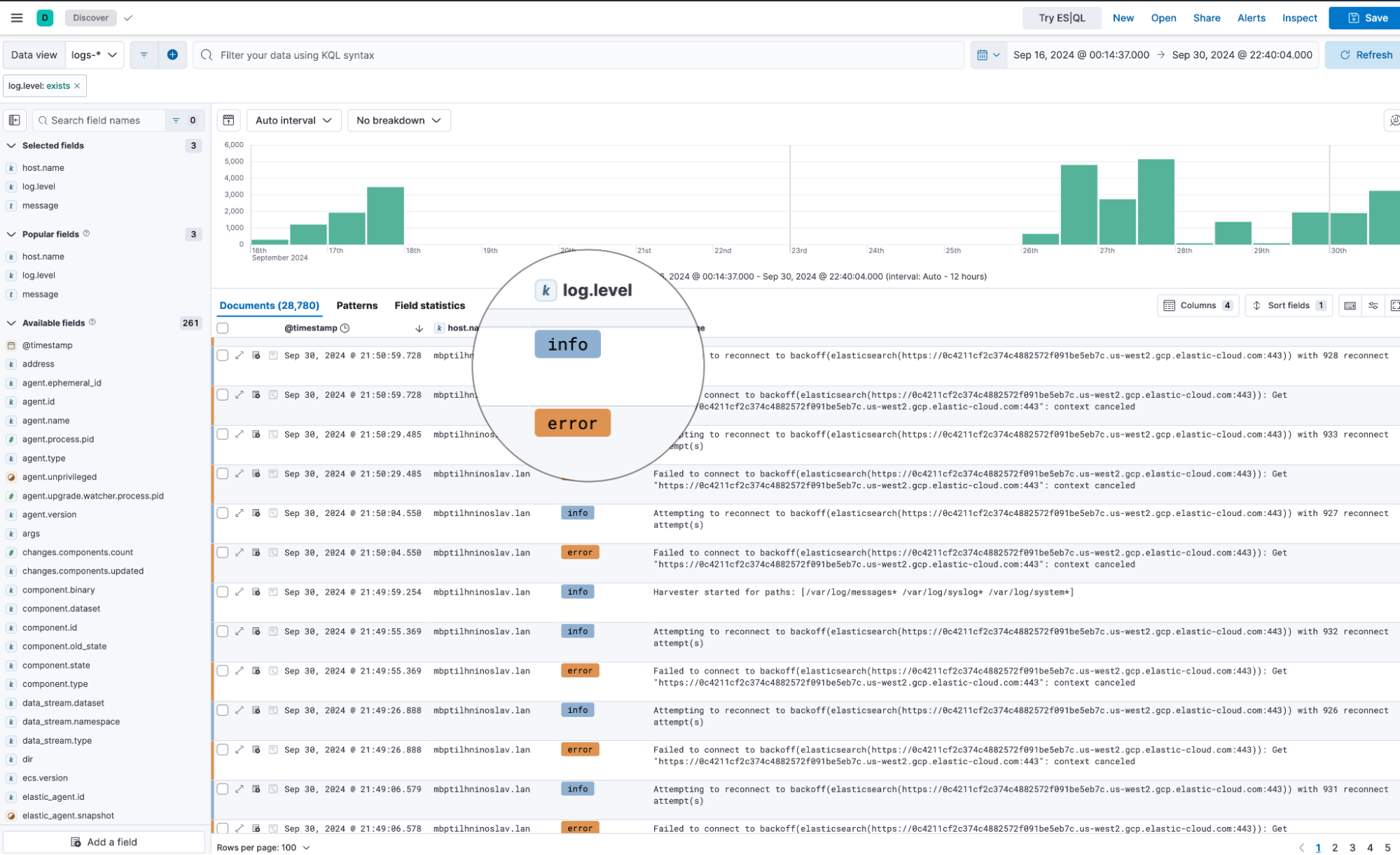
Discover contextual data presentation
Discover in Kibana 8.16 now automatically adjusts data table presentation based on the type of data being explored. For users working with logs, relevant fields like log levels are now automatically displayed in the table or in a custom logs overview in the Discover document viewer. This streamlined, context-aware approach boosts productivity by simplifying data exploration and highlighting key log insights without the need for additional configuration.
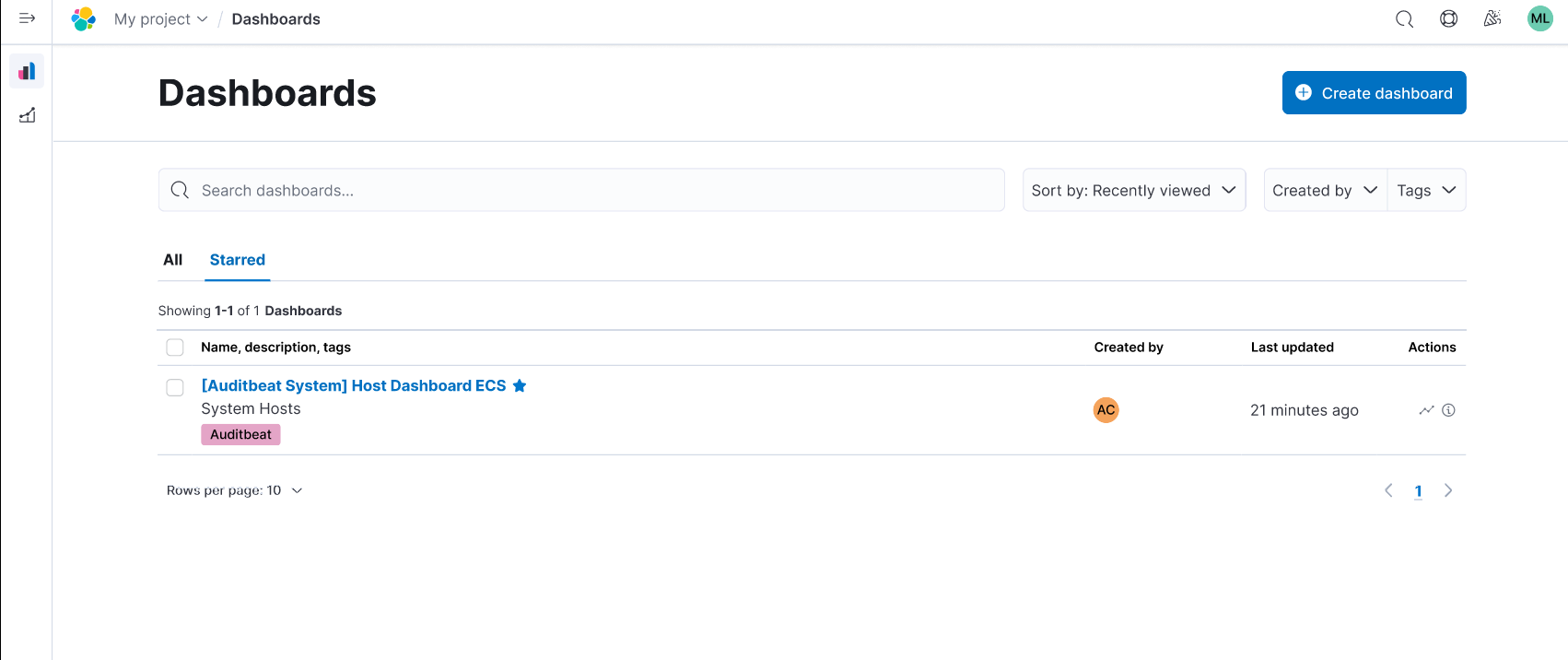
Managing dashboards easily and efficiently
As part of a series of improvements to Kibana dashboard management (see dashboard view creator and editor in 8.15), we’ve added new features designed to enhance efficiency and usability. You can now easily sort your dashboards in three ways — by keeping the "Recently Viewed" default setting, starring your favorite dashboards for quick and easy-to-find access, and viewing detailed usage statistics.
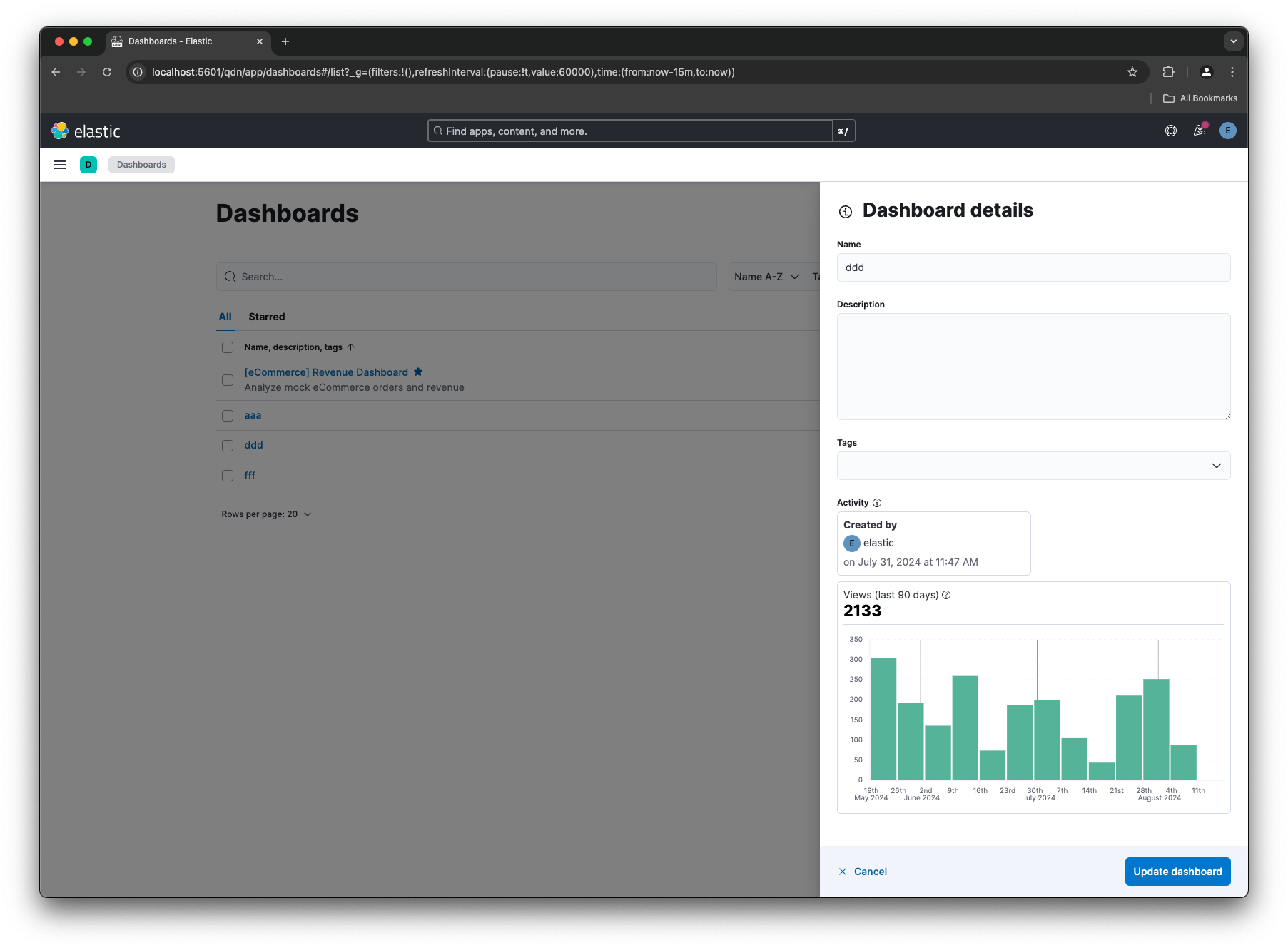
Additionally, a new usage insights feature allows you to click the “info” icon in the dashboard list view to access a histogram of dashboard views over the last 90 days. This provides insights into dashboard popularity, helping you identify and remove unused dashboards, ultimately optimizing your workspace. These updates make managing and organizing your dashboards faster and more intuitive.
Dev Console UX improvements
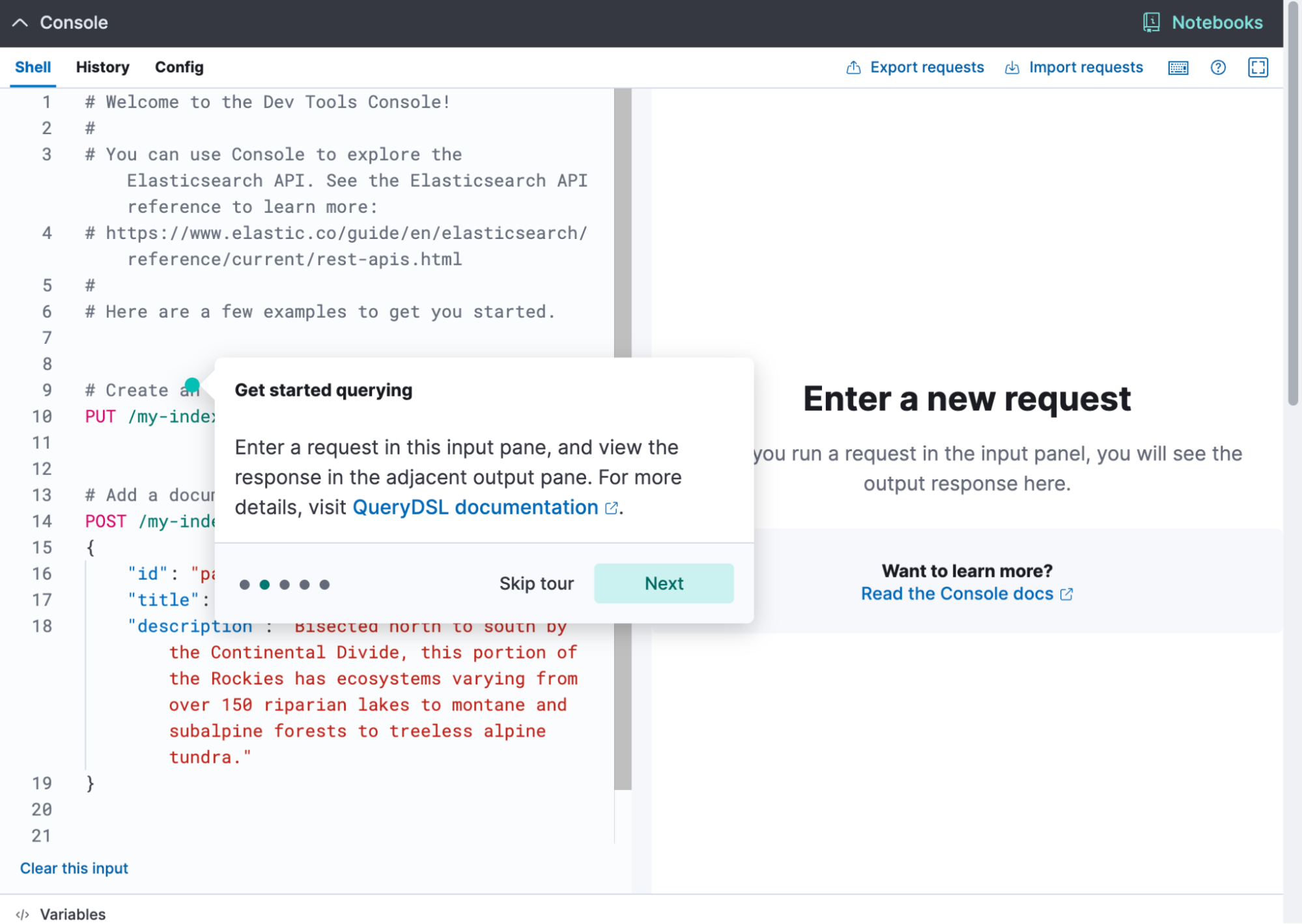
We’re excited to announce new enhancements to Dev Console — one of the most popular apps among our users! The latest improvements include an onboarding tour to help new users quickly get up to speed with the console. For seasoned users, new features like the ability to copy output to the clipboard and import or export files have been introduced. Additionally, overall responsiveness has been optimized, along with several quality-of-life improvements that streamline workflows and boost efficiency. These updates make the Dev Console even more user-friendly, enhancing both onboarding and daily operations for all users.
Beyond the highlights: Honorable mentions in Elastic 8.16
Beyond the headline features, Elastic 8.16 brings an array of impactful enhancements designed to optimize performance, streamline workflows, and simplify management.
More efficient searches using the event ingested time
Queries using the "event.ingested" field to search data based on its ingestion datetime now enjoy the same performance boost as those using "@timestamp" when using searchable snapshots. This is achieved thanks to an optimization that allows shards to be skipped based on the minimum and maximum values stored in the cluster state for "event.ingested".
Global settings for data stream maximum and default retention
Data streams are essential for efficiently ingesting logs and metrics over time, and managing data retention is crucial for maintaining system efficiency and cost-effectiveness. With this release, administrators gain access to two new global settings that allow them to define maximum and default retention periods for all data streams in their deployment, ensuring that outdated data is removed while keeping costs manageable.
Intervals query reaches feature parity with span queries
Intervals query was designed to replace span queries. It is simpler to define; it provides proximity scores; and in certain cases, it is more performant. Both queries are often used for legal and patent search. In 8.16, we enabled regexp and range in interval queries and increased the maximum clauses of a multiterm intervals query (prefix, wildcard, fuzzy, regexp, and range) from 128 to a configurable parameter (the same one used for span queries).
Log analysis dashboard panels
Group your logs into patterns with log pattern analysis to accelerate time to insights and resolution. Work through thousands of logs and identify the signal in the noise within seconds with Elastic’s artificial intelligence for IT operations (AIOps) capabilities. With the log pattern analysis available from within your dashboards, AIOps are increasingly embedded in your workflows in context. Filtering patterns will adjust the dashboard’s data accordingly, or choose the filtering to transition you in Discover for further exploration.

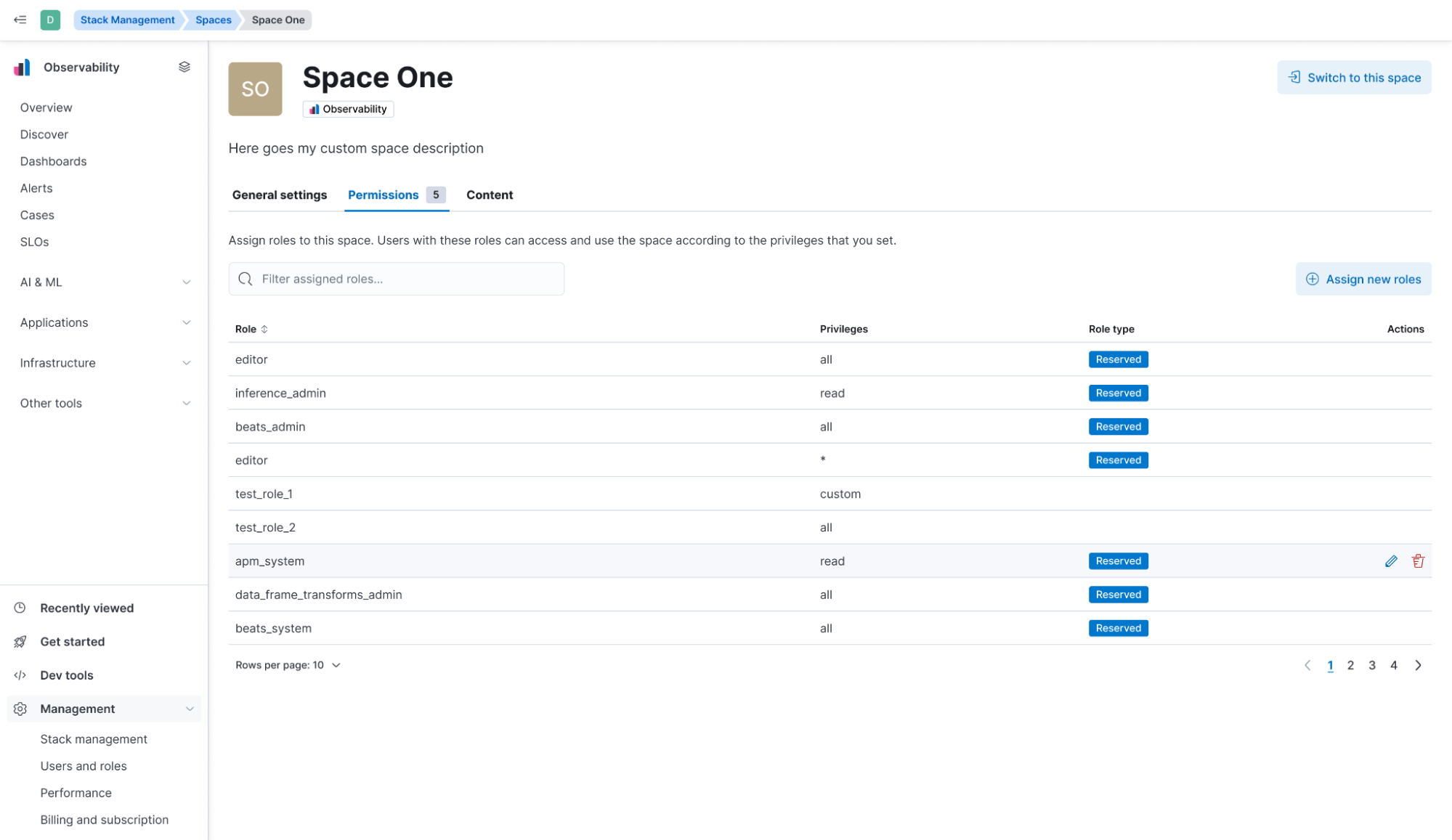
Intuitive Spaces settings
Kibana 8.16 streamlines role assignment by allowing admins to intuitively assign roles and permissions directly from Space settings. The new "Permissions" tab enables efficient role management for individual or multiple spaces, bringing a user-friendly approach to access control.
Support for daylight saving time (DST) changes in anomaly detection
In 8.16, we are introducing support for DST changes in anomaly detection. Set up a DST calendar by selecting the right time zone and apply it to your anomaly detection jobs individually or in groups for your convenience. Then, let your anomaly detection model work without the need for any DST-related intervention for many years to come. No more anomaly detection false positives due to DST changes. Let your detections do their work uninterrupted.

File uploader PDF support
The file uploader provides an easy way to upload data and start using Elastic in seconds. Now, you can upload data from PDF files and head to Search Playground with one click. Use it for fast time to data and Elastic’s technology.

Try it out!
Read about these capabilities and more in the release notes.
Existing Elastic Cloud Hosted and Elastic Cloud Serverless customers can access many of these features directly from the Elastic Cloud console. Not taking advantage of Elastic on cloud? Start a free trial.
The release and timing of any features or functionality described in this post remain at Elastic's sole discretion. Any features or functionality not currently available may not be delivered on time or at all.
In this blog post, we may have used or referred to third party generative AI tools, which are owned and operated by their respective owners. Elastic does not have any control over the third party tools and we have no responsibility or liability for their content, operation or use, nor for any loss or damage that may arise from your use of such tools. Please exercise caution when using AI tools with personal, sensitive or confidential information. Any data you submit may be used for AI training or other purposes. There is no guarantee that information you provide will be kept secure or confidential. You should familiarize yourself with the privacy practices and terms of use of any generative AI tools prior to use.
Elastic, Elasticsearch, ESRE, Elasticsearch Relevance Engine and associated marks are trademarks, logos or registered trademarks of Elasticsearch N.V. in the United States and other countries. All other company and product names are trademarks, logos or registered trademarks of their respective owners.
Share
- Share on Twitter
Share on Twitter
- Share on LinkedIn
Share on LinkedIn
- Share on Facebook
Share on Facebook
- Share by Email
Share by Email
- Print this page
Print