如何使用 Elastic APM Go 代理为 Go 应用装载测量工具
Elastic APM(应用程序性能监测)能够全面洞见应用程序性能和洞悉分布式工作负载,且正式支持多种语言,包括 Go、Java、Ruby、Python 和 JavaScript(Node.js 和用于浏览器的真实用户监测 (RUM))。
要获得这些对性能的洞见,您必须为应用程序装载测量工具。测量工具装载代码是改变应用程序代码以测量其行为的操作。对于某些受支持的语言,只需安装一个代理即可。例如,可以使用简单的 ‑javaagent 标志自动为 Java 应用程序装载测量工具,该标志使用字节码装载测量工具 — 这是操作编译后 Java 字节码的过程,通常会在程序启动后加载 Java 类时进行。除此之外,单个线程通常会从头到尾控制一个操作,因此,可以使用线程本地存储来关联各操作。
一般来说,Go 程序会被编译为本机代码,而本机代码不太适合自动装载测量工具。此外,Go 程序的线程模型与大多数其他语言不同。在 Go 程序中,执行代码的“goroutine”可以在操作系统线程之间移动,且逻辑操作通常跨越多个 goroutine。那如何为 Go 应用程序装载测量工具呢?
在本文中,我们将研究如何使用 Elastic APM 为 Go 应用程序装载测量工具,以便捕获详细的响应时间性能数据(跟踪)、捕获基础架构和应用程序指标,以及与日志集成 — 实现可观察性三要素。在本篇文章中,我们将构建一个应用程序及其测量工具装载代码,并按顺序贯穿以下主题:
跟踪 Web 请求
Elastic APM Go 代理针对“跟踪”操作(如到服务器的传入请求)提供了一个 API。跟踪操作包括记录描述操作的事件(例如,操作名称、类型/类别),以及一些属性(例如,源 IP、经身份验证的用户等)。此外,事件还将记录操作何时开始、花费多长时间,以及描述操作沿袭的标识符。
Elastic APM Go 代理提供了许多模块,用于对各种 Web 框架、RPC 框架和数据库驱动程序装载测量工具,以及用于与多个日志框架进行集成。查看受支持技术的完整列表。
接下来,让我们使用 gorilla/mux 路由器将 Elastic APM 测量工具装载代码添加到一个简单的 Web 服务中,并演示如何通过 Elastic APM 捕获其性能。
下面是未装载测量工具的原始代码:
package main
import (
"fmt"
"log"
"net/http"
"github.com/gorilla/mux"
)
func helloHandler(w http.ResponseWriter, req *http.Request) {
fmt.Fprintf(w, "Hello, %s!\n", mux.Vars(req)["name"])
}
func main() {
r := mux.NewRouter()
r.HandleFunc("/hello/{name}", helloHandler)
log.Fatal(http.ListenAndServe(":8000", r))
}
要对通过 gorilla/mux 路由器提供的请求装载测量工具,您需要一个支持中间件的最新版本的 gorilla/mux(v1.6.1 或更新版本)。然后,只需导入 go.elastic.co/apm/module/apmgorilla,并添加以下代码行即可:
r.Use(apmgorilla.Middleware())
apmgorilla 中间件会将每个请求作为一个事务报告给 APM 服务器。让我们暂时放下测量工具装载代码,先看看 APM UI 中的情况。
可视化性能
我们已经对 Web 服务装载了测量工具,但它没有地方发送数据。默认情况下,APM 代理会尝试将数据发送到位于 http://localhost:8200 的 APM 服务器。我们使用最新发布的 Elastic Stack 7.0.0 来设置一个刷新堆栈。您可以免费下载堆栈的默认部署,也可以开始免费试用 14 天 Elastic Cloud 上的 Elasticsearch 服务。如果您想自己运行,您可以在 https://github.com/elastic/stack-docker 找到 Docker Compose 配置的示例。
设置堆栈后,便可配置您的应用程序,以将数据发送到 APM 服务器。您需要知道 APM 服务器的 URL 和加密令牌。当使用 Elastic Cloud 时,这些内容可以在部署期间的“Activity”(活动)页和部署完成后的“APM”页上找到。在部署过程中,请记下 Elasticsearch 和 Kibana 的密码,因为之后就无法再看到它了(尽管您可以根据情况重置它)。
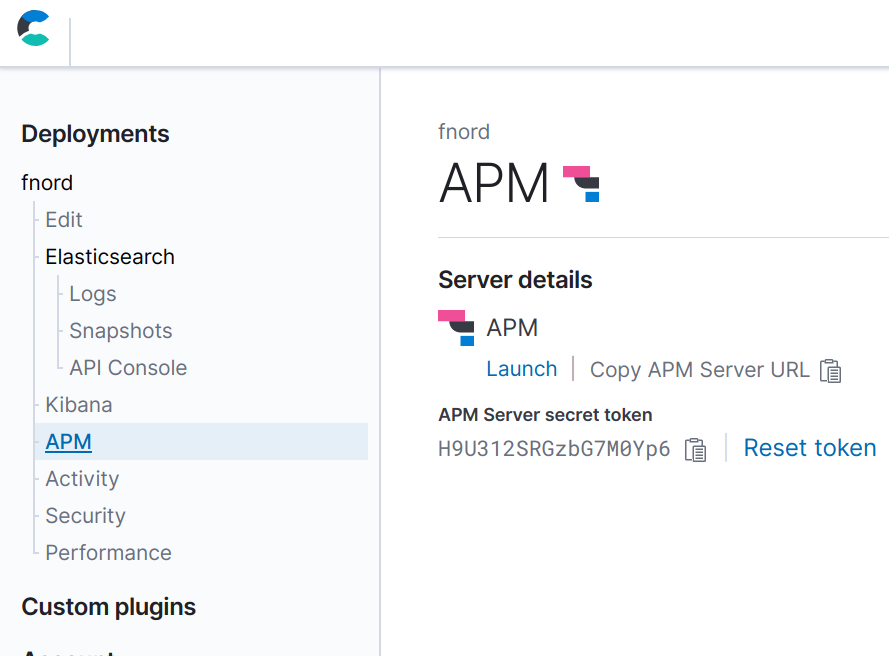
APM Go 代理是通过环境变量配置的。若要配置 APM 服务器 URL 和加密令牌,请导出以下环境变量,以便应用程序可以获取它们:
export ELASTIC_APM_SERVER_URL=https://bdf8658ddda74d47af1875242c3ef203.apm.europe-west1.gcp.cloud.es.io:443 export ELASTIC_APM_SECRET_TOKEN=H9U312SRGzbG7M0Yp6
现在,如果我们运行已装载测量工具的程序,应很快会在 APM UI 中看到一些数据。代理将定期发送以下指标:CPU 和内存使用情况,以及 Go 运行时统计数据。每当处理请求时,代理还会记录一个事务;默认情况下,每 10 秒会对这些事务进行缓冲并分批发送。下面让我们来运行服务,发送一些请求,看看会发生什么。
为了确保事件成功发送到 APM 服务器,我们可以设置两个附加环境变量:
export ELASTIC_APM_LOG_FILE=stderr export ELASTIC_APM_LOG_LEVEL=debug
现在,启动应用程序(hello.go 包含以前已装载测量工具的程序):
go run hello.go
接下来,我们会使用 github.com/rakyll/hey 将一些请求发送到服务器:
go get -u github.com/rakyll/hey hey http://localhost:8000/hello/world
在应用程序的输出中,您应看到类似如下内容:
{"level":"debug","time":"2019-03-28T20:33:56+08:00","message":"sent request with 200 transactions, 0 spans, 0 errors, 0 metricsets"}
在 hey 的输出中,您应看到各种统计数据,包括响应时间延迟的柱状图。如果现在打开 Kibana 并导航到 APM UI,则应看到一个称为“hello”的服务,以及一个称为“/hello/{name}”的事务组。我们来看看:
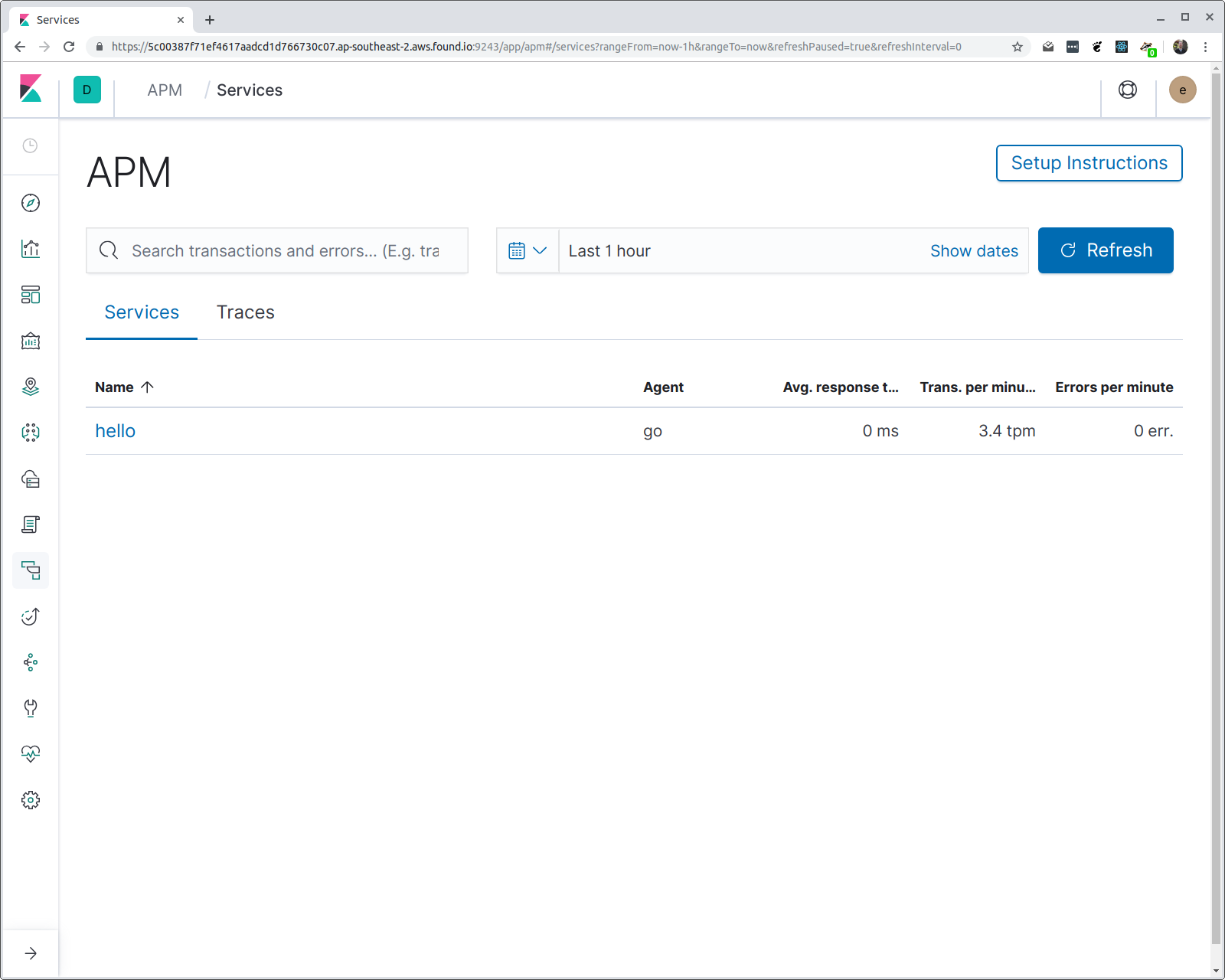
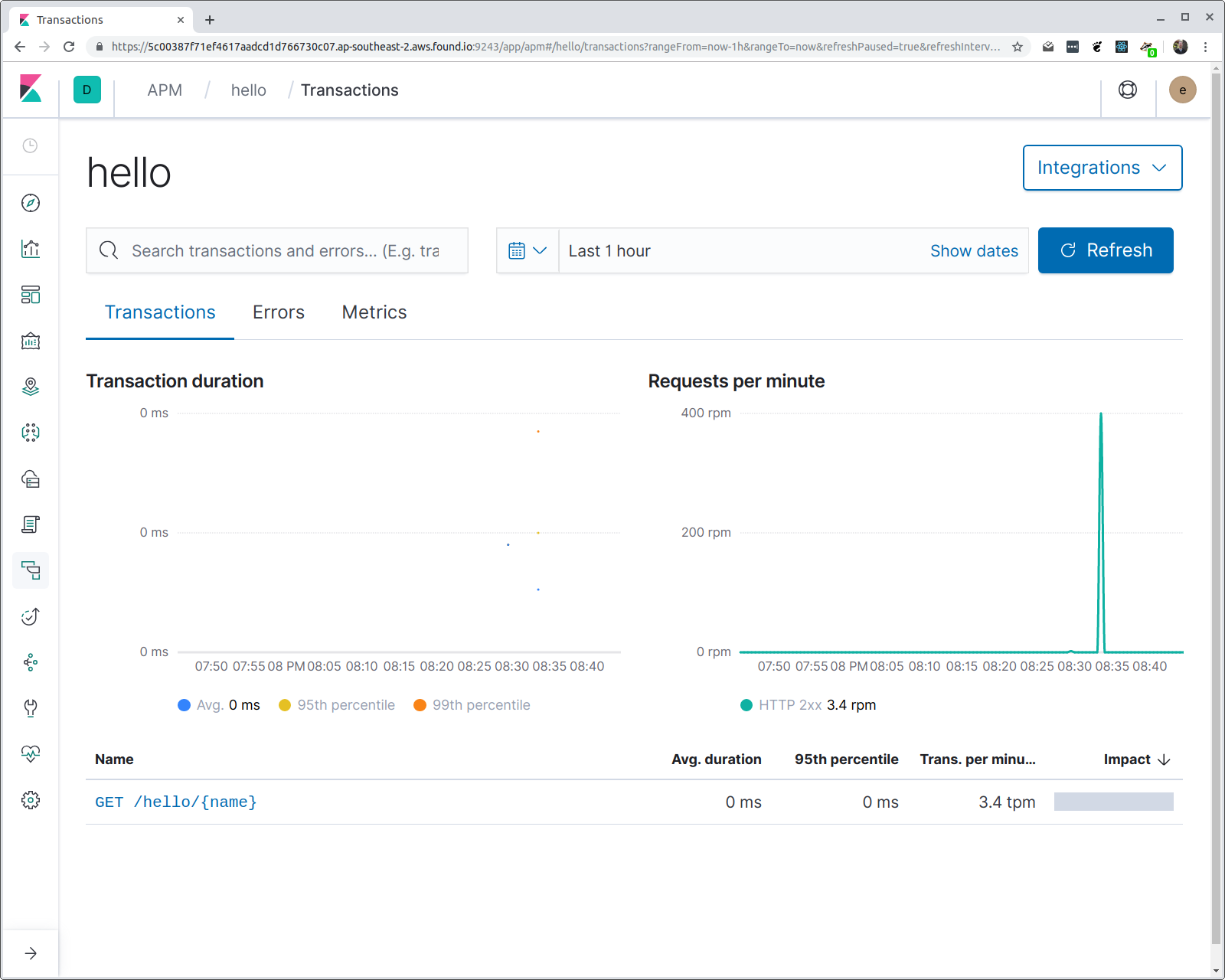
您可能想知道两件事:代理如何知道要为服务赋予的名称,以及为什么使用路由模式而不是请求 URI?第一件事很简单:如果您不指定服务名称(通过环境变量),则会使用程序二进制文件名称。在本例中,程序被编译成了一个名为“hello”的二进制文件。
使用路由模式的原因是为了启用聚合。如果我们现在单击事务,则可以看到一个响应时间延迟的柱状图。
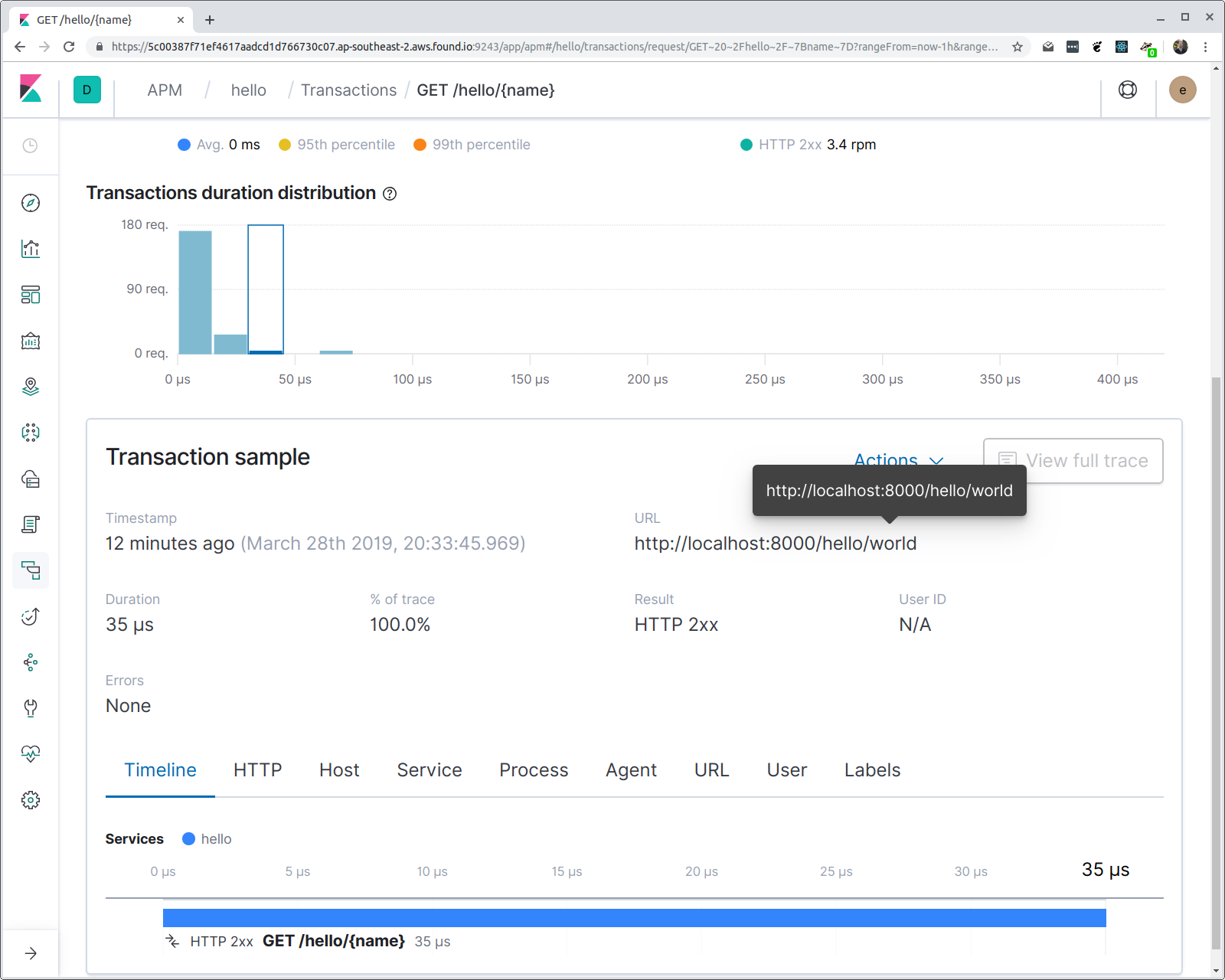
请注意,即使我们在路由模式上进行聚合,事务属性中也提供了完整的请求 URL。
跟踪 SQL 查询
在典型的应用程序中,逻辑会更为复杂,涉及诸如数据库等的外部服务、缓存等等。当您试图诊断应用程序中的性能问题时,能够看到与这些服务的交互至关重要。
让我们来看看如何观察通过 Go 应用程序执行的 SQL 查询。
出于演示目的,我们将使用一个嵌入式 SQLite 数据库,但只要您使用的是 database/sql 就好,使用哪个驱动程序并不重要。
为了跟踪 database/sql 操作,我们提供了装载测量工具模块 go.elastic.co/apm/module/apmsql。apmsql 模块会为 database/sql 驱动程序装载测量工具,以便作为事务中的跨度报告数据库操作。要使用这个模块,您需要更改注册和打开数据库驱动程序的方式。
通常在应用程序中,您将导入一个 database/sql 驱动程序包来注册驱动程序,例如
import _ “github.com/mattn/go-sqlite3” // registers the “sqlite3” driver
我们提供了几个方便的程序包来执行相同的操作,但它们注册了相同驱动程序的已装载测量工具的版本。例如,对于 SQLite3,您可以改按如下方式导入:
import _ "go.elastic.co/apm/module/apmsql/sqlite3"
后台代码,它使用 apmsql.Register 方法,该方法等同于调用 sql.Register,但会为已注册的驱动程序装载测量工具。无论何时使用 apmsql.Register,都必须使用 apmsql.Open(而不是使用 sql.Open)来打开连接:
import (
“go.elastic.co/apm/module/apmsql”
_ "go.elastic.co/apm/module/apmsql/sqlite3"
)
var db *sql.DB
func main() {
var err error
db, err = apmsql.Open("sqlite3", ":memory:")
if err != nil {
log.Fatal(err)
}
if _, err := db.Exec("CREATE TABLE stats (name TEXT PRIMARY KEY, count INTEGER);"); err != nil {
log.Fatal(err)
}
...
}
前面我们提到过,与许多其他语言不同,Go 中没有用于将相关操作绑在一起的线程本地存储设施。相反,您必须显式地传播上下文。当我们开始为 Web 请求记录事务时,我们会在请求上下文中存储一个对进行中事务的引用,可通过 net/http.Request.Context 方法获得。接下来,让我们通过记录每个名称被看到的次数,并将数据库查询报告给 Elastic APM 来了解该上下文的外观。
var db *sql.DB
func helloHandler(w http.ResponseWriter, req *http.Request) {
vars := mux.Vars(req)
name := vars[“name”]
requestCount, err := updateRequestCount(req.Context(), name)
if err != nil {
panic(err)
}
fmt.Fprintf(w, "Hello, %s! (#%d)\n", name, requestCount)
}
// updateRequestCount increments a count for name in db, returning the new count.
func updateRequestCount(ctx context.Context, name string) (int, error) {
tx, err := db.BeginTx(ctx, nil)
if err != nil {
return -1, err
}
row := tx.QueryRowContext(ctx, "SELECT count FROM stats WHERE name=?", name)
var count int
switch err := row.Scan(&count); err {
case nil:
count++
if _, err := tx.ExecContext(ctx, "UPDATE stats SET count=?WHERE name=?", count, name); err != nil {
return -1, err
}
case sql.ErrNoRows:
count = 1
if _, err := tx.ExecContext(ctx, "INSERT INTO stats (name, count) VALUES (?, ?)", name, count); err != nil {
return -1, err
}
default:
return -1, err
}
return count, tx.Commit()
}
关于此代码,需要指出两个关键点:
- 我们使用的是 database/sql *Context 方法(ExecContext、QueryRowContext)
- 我们将上下文从封闭请求传递到这些方法调用中。
已装载 apmsql 的数据库驱动程序希望在已提供上下文中找到对进行中事务的引用;这就是所报告的数据库操作与调用它的请求处理程序的关联方式。让我们将一些请求发送到这个修改后的服务,并查看它的外观:
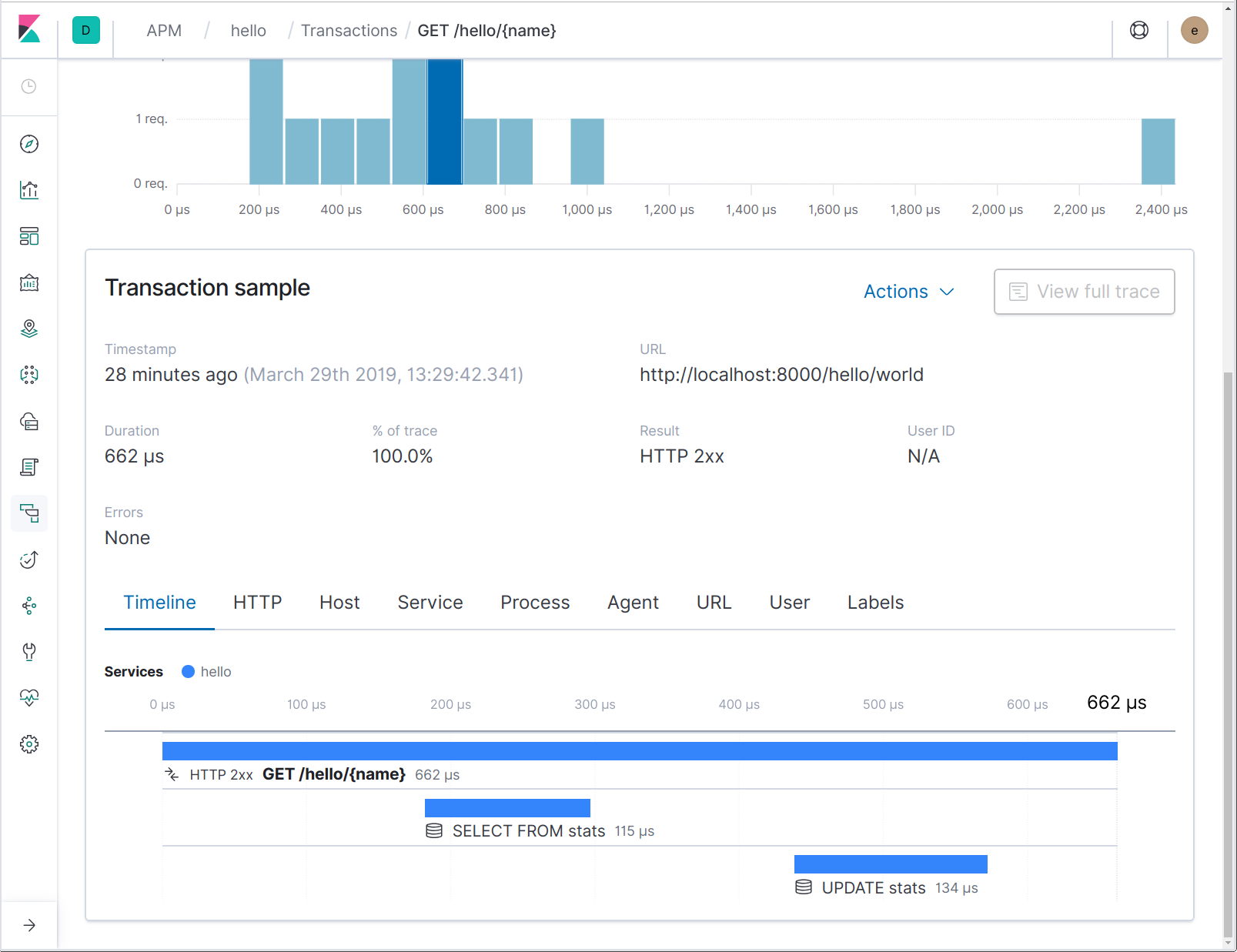
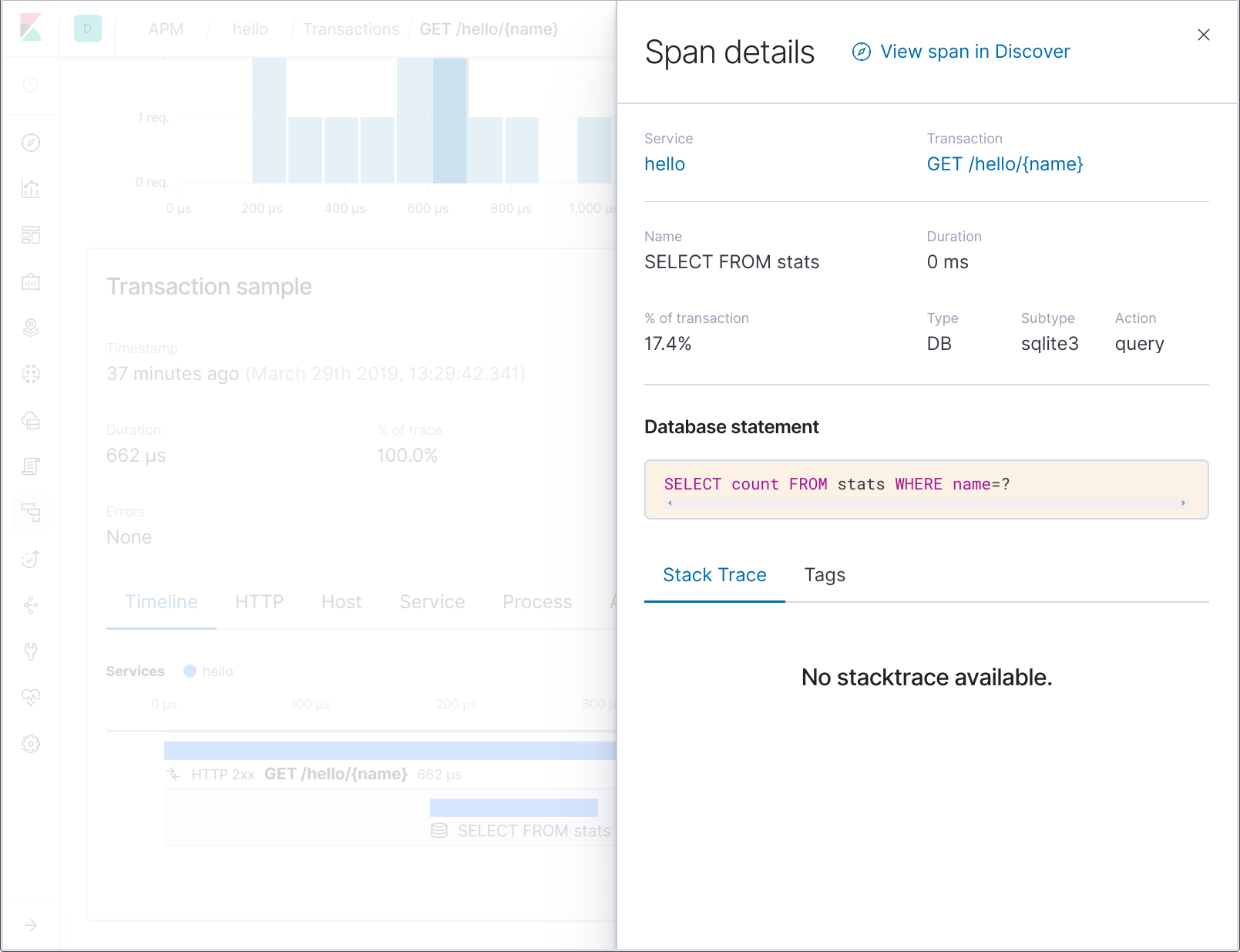
注意,数据库跨度名称不包含完整的 SQL 语句,而只是包含其中的一部分。譬如,这样能够让用户更容易地聚合表示某个表名上操作的跨度。通过单击跨度,就可在跨度详细信息中看到完整的 SQL 语句:
跟踪定制跨度
在前面部分,我们在跟踪中引入了数据库查询跨度。如果您很了解该服务,可能会马上知道这两个查询属于同一操作(查询然后更新计数器);其他人可能不知道。此外,如果在这些查询之间或围绕这些查询正在进行任何重要的处理,那么将其归因于“updateRequestCount”方法可能会很有用。我们可以通过报告该函数的定制跨度来完成此操作。
您可以用各种方式报告定制跨度,其中最简单的是使用 apm.StartSpan。您必须向这个函数传递一个上下文,其中要包含事务、跨度名称和类型。我们下面来创建一个称为“updateRequestCount”的跨度:
func updateRequestCount(ctx context.Context, name string) (int, error) {
span, ctx := apm.StartSpan(ctx, “updateRequestCount”, “custom”)
defer span.End()
...
}
从上面的代码可以看出,apm.StartSpan 返回了跨度和新的上下文。应使用这个新的上下文来代替传入的上下文,它包含新的跨度。下面是它当前在 UI 中的外观:
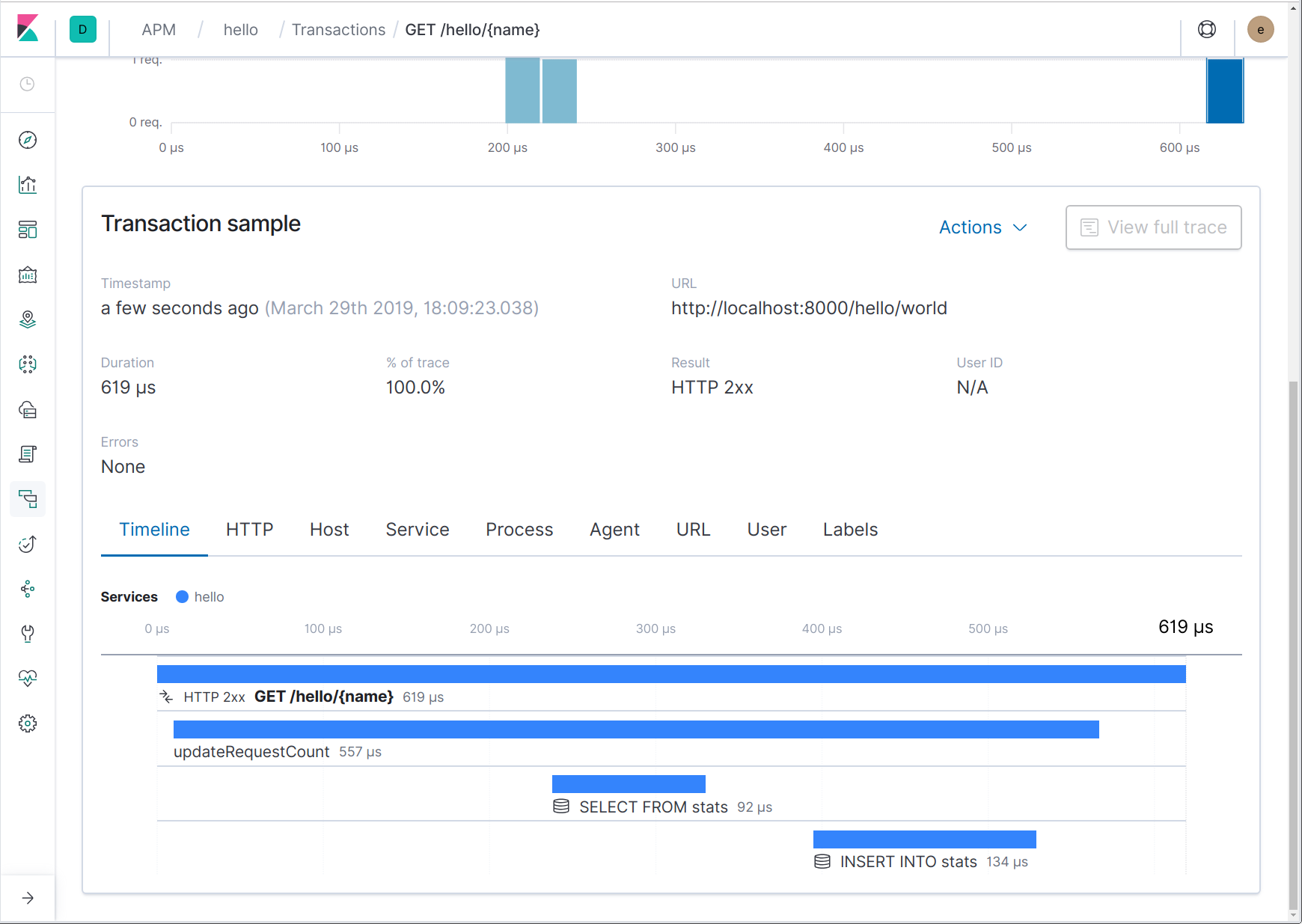
跟踪传出的 HTTP 请求
到目前为止,我们所描述的实际上都是单进程跟踪。即使涉及到多个服务,我们也只是在一个进程中进行跟踪:从客户端角度看为传入的请求和数据库查询。
近年来,微服务越来越普遍。在微服务出现之前,面向服务的架构 (SOA) 是另一种将大型整体应用程序分解为模块化组件的常用方法。无论是哪种情况,其结果都会增加复杂性,使可观察性更为复杂。现在,我们不仅要关联进程内的操作,而且还必须关联进程之间的操作,甚至可能关联不同机器、不同数据中心或第三方服务上的操作。
在 Elastic APM Go 代理中,我们处理进程内和进程之间跟踪的方式非常相似。例如,要跟踪传出的 HTTP 请求,您必须对 HTTP 客户端装载测量工具,并确保将封闭的请求上下文传播到传出请求。已装载测量工具的客户端将使用它创建一个跨度,并将标头插入到传出的 HTTP 请求中。让我们看看实际情况如何:
// apmhttp.WrapClient instruments the given http.Client client := apmhttp.WrapClient(http.DefaultClient) // If “ctx” contains a reference to an in-progress transaction, then the call below will start a new span. resp, err := client.Do(req.WithContext(ctx)) … resp.Body.Close() // the span is ended when the response body is consumed or closed
如果此传出请求由另一个已使用 Elastic APM 装载测量工具的应用程序处理,那么您将得到一个“分布式跟踪”— 跨服务的跟踪(相关事务和跨度的集合)。装载测量工具的客户端将插入一个标头,标识传出的 HTTP 请求的跨度,接收服务将提取该标头并使用它将客户端跨度与它记录的事务关联起来。这些都由 go.elastic.co/apm/module 下提供的各种 Web 框架装载测量工具模块处理。
为了演示这一点,让我们来扩展一下服务,在响应中添加一点内容:2018 年澳大利亚南部出生的同名婴儿的数量。“hello”服务将通过基于 HTTP 的 API 从第二个服务获取此信息。为了简洁起见,省略了第二个服务的代码,但您可以想象,它的实现和测量工具装载代码方式与“hello”服务几乎相同。
func helloHandler(w http.ResponseWriter, req *http.Request) {
...
stats, err := getNameStats(req.Context(), name)
if err != nil {
panic(err)
}
fmt.Fprintf(w, "Hello, %s! (#%d)\n", name, requestCount)
fmt.Fprintf(w, "In %s, %d: ", stats.Region, stats.Year)
switch n := stats.Male.N + stats.Female.N; n {
case 1:
fmt.Fprintf(w, "there was 1 baby born with the name %s!\n", name)
default:
fmt.Fprintf(w, "there were %d babies born with the name %s!\n", n, name)
}
}
type nameStatsResults struct {
Region string
Year int
Male nameStats
Female nameStats
}
type nameStats struct {
N int
Rank int
}
func getNameStats(ctx context.Context, name string) (nameStatsResults, error) {
span, ctx := apm.StartSpan(ctx, "getNameStats", "custom")
defer span.End()
req, _ := http.NewRequest("GET", "http://localhost:8001/stats/"+url.PathEscape(name),
nil)
// Instrument the HTTP client, and add the surrounding context to the request.
// This will cause a span to be generated for the outgoing HTTP request, including
// a distributed tracing header to continue the trace in the target service.
client := apmhttp.WrapClient(http.DefaultClient)
resp, err := client.Do(req.WithContext(ctx))
if err != nil {
return nameStatsResults{}, err
}
defer resp.Body.Close()
var res nameStatsResults
if err := json.NewDecoder(resp.Body).Decode(&res); err != nil {
return nameStatsResults{}, err
}
return res, nil
}
在为这两个服务装载测量工具之后,我们现在可以看到对“hello”服务的每个请求的分布式跟踪:
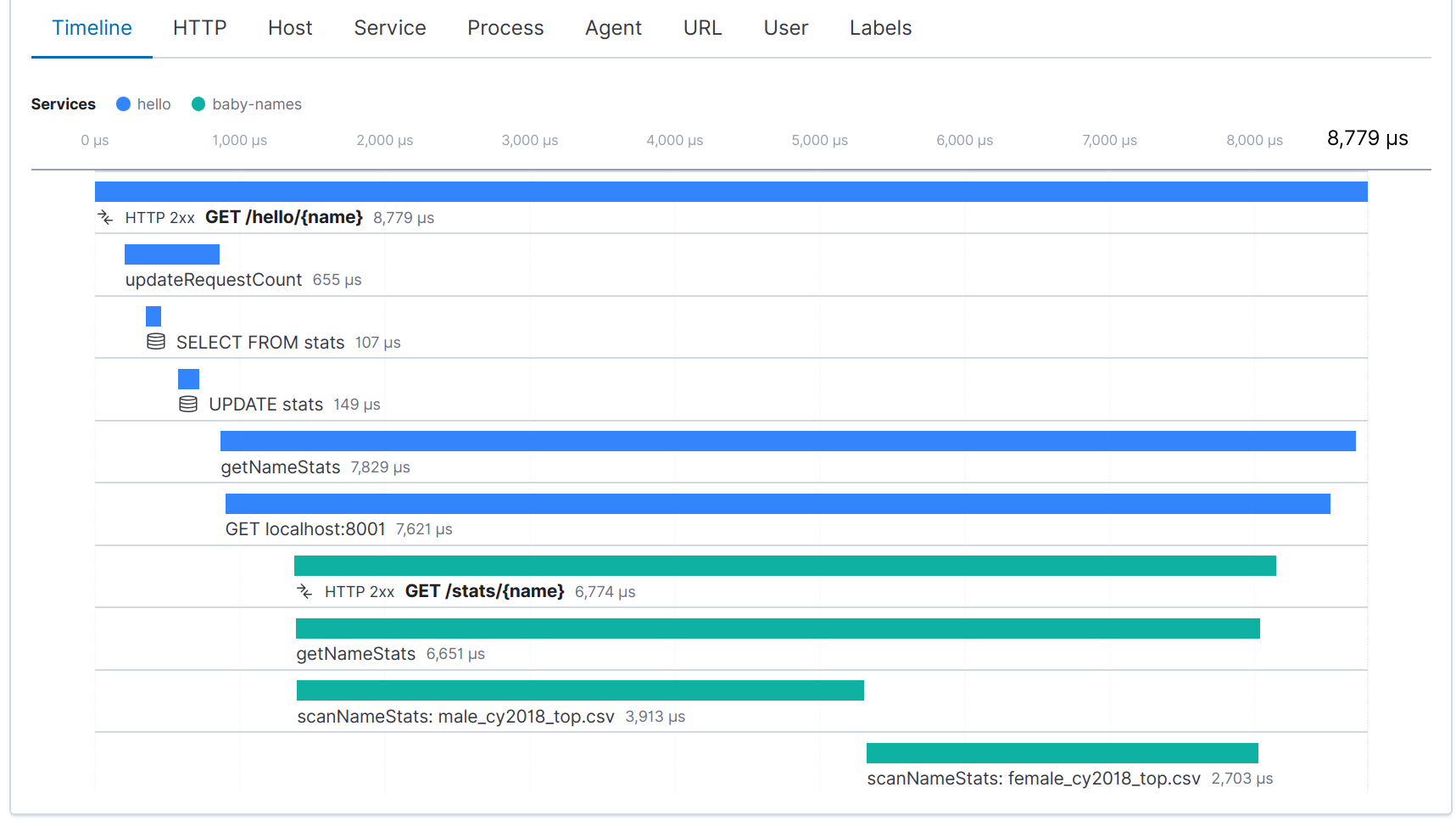
您可以在 Adam Quan 的 Distributed Tracing, OpenTracing and Elastic APM(分布式跟踪、OpenTracing 和 Elastic APM)这篇博文中阅读有关分布式跟踪主题的更多内容。
异常错误跟踪
正如我们所看到的,Web 框架装载测量工具模块提供了用于记录事务的中间件。除此之外,它们还将捕获错误并报告给 Elastic APM,以协助调查失败的请求。接下来,我们来修改一下 updateRequestCount,让它在遇到非 ASCII 字符时出错来尝试这个操作:
func updateRequestCount(ctx context.Context, name string) (int, error) {
span, ctx := apm.StartSpan(ctx, “updateRequestCount”, “custom”)
defer span.End()
if strings.IndexFunc(name, func(r rune) bool {return r >= unicode.MaxASCII}) >= 0 {
panic(“non-ASCII name!”)
}
...
}
现在发送一个包含一些非 ASCII 字符的请求:
curl -f http://localhost:8000/hello/世界 curl:(22) The requested URL returned error:500 Internal Server Error
嗯!有什么问题吗?让我们看看 APM UI 中“hello”服务的“Errors”(错误)页面:
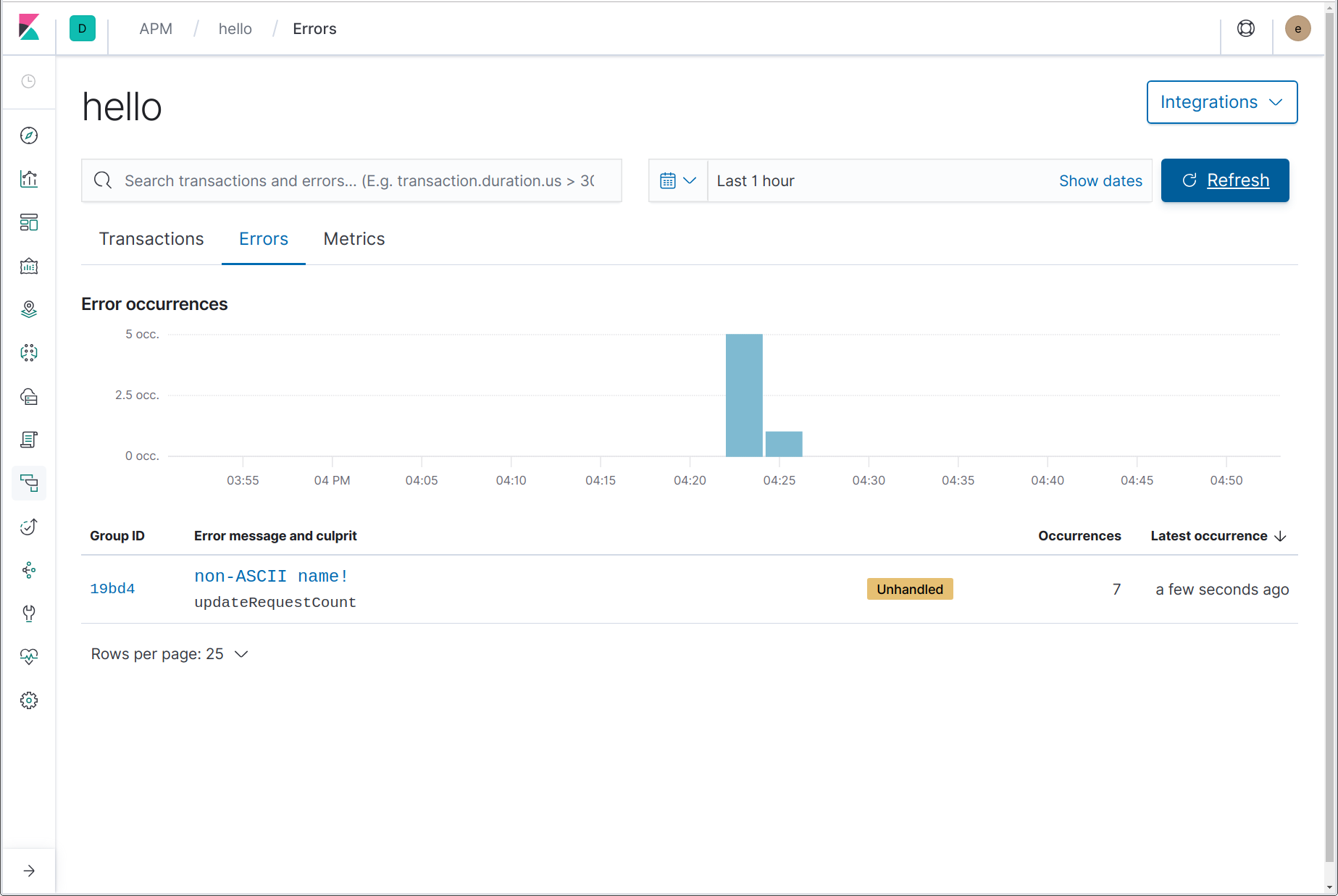
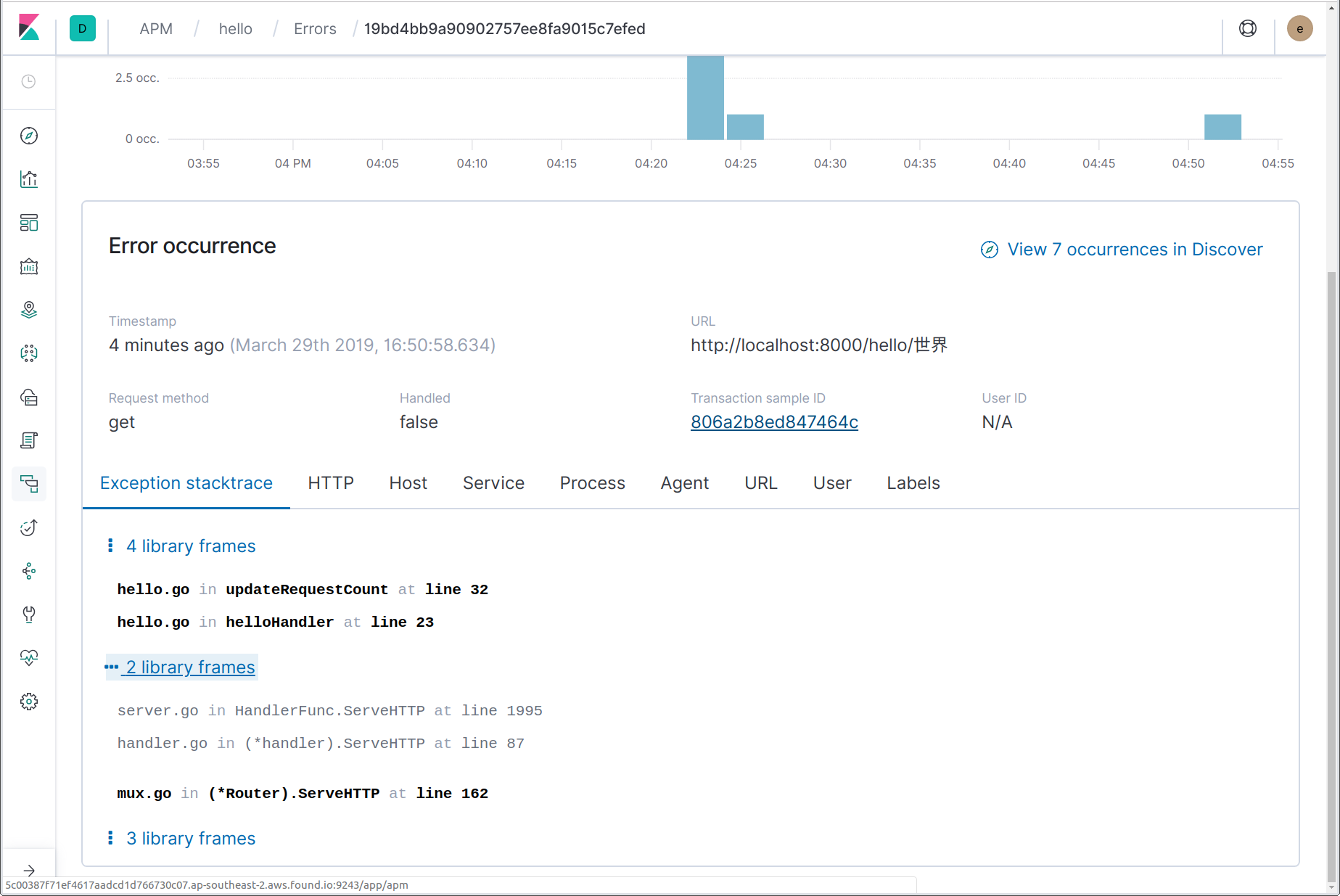
我们在这里可以看到发生了一个错误,包括错误消息“non-ASCII name!”(非 ASCII 名称!),以及引发错误的函数的名称 updateRequestCount。通过单击错误名称,我们可以链接到该错误的最近实例的详细信息。在错误详细信息页中,我们可以看到完整的堆栈跟踪、错误发生时出错事务的详细信息快照,以及指向已完成事务的链接。
除了捕获这些错误,您还可以使用 apm.CaptureError 函数将错误显式报告给 Elastic APM。您必须向此函数传递一个包含有事务和错误值的上下文。CaptureError 将返回一个“apm.Error”对象,您可以随意定制该对象,然后使用其 Send 方法完成:
if err != nil {
apm.CaptureError(req.Context(), err).Send()
return err
}
最后,可以与日志框架集成,以向 Elastic APM 发送错误日志。我们将在下一节详细讨论这个问题。
日志集成
近年来,关于“可观察性三大支柱”(跟踪、日志和指标)的讨论不绝于耳。到目前为止,我们一直在介绍跟踪,但 Elastic Stack 涵盖所有这三大支柱以及更多内容。我们后面会对指标稍作讨论;让我们先看看 Elastic APM 如何与应用程序日志集成。
如果您做过任何类型的集中日志,那么您或许已经非常熟悉 Elastic Stack 了,其以前称为 ELK(Elasticsearch、Logstash、Kibana)Stack。当您在 Elasticsearch 中同时拥有日志和跟踪时,交叉引用它们就变得非常简单。
Go 代理针对以下几种流行的日志框架提供了集成模块:Logrus (apmlogrus)、Zap (apmzap) 和 Zerolog (apmzerolog)。我们使用 Logrus 向 Web 服务添加一些日志,看看如何将其与跟踪数据集成。
import "github.com/sirupsen/logrus"
var log = &logrus.Logger{
Out: os.Stderr,
Hooks: make(logrus.LevelHooks),
Level: logrus.DebugLevel,
Formatter: &logrus.JSONFormatter{
FieldMap: logrus.FieldMap{
logrus.FieldKeyTime: "@timestamp",
logrus.FieldKeyLevel: "log.level",
logrus.FieldKeyMsg: "message",
logrus.FieldKeyFunc: "function.name", // non-ECS
},
},
}
func init() {
apm.DefaultTracer.SetLogger(log)
}
我们构造了 logrus.Logger,它向 stderr 写入数据,将日志格式化为 JSON。为了更好地适应 Elastic Stack,我们将一些标准日志字段映射到 Elastic Common Schema (ECS) 中的等效项。我们也可以将它们作为默认值,然后使用 Filebeat 处理器进行转换,但这要简单一些。此外,我们还告知 APM 代理使用这个 Logrus 记录器来记录代理级别的故障排查消息。
接下来,让我们看看如何将应用程序日志与 APM 跟踪数据集成。我们将一些日志添加到 helloHandler 路由处理程序,查看如何将跟踪 ID 添加到日志消息中。然后,我们将了解如何将错误日志记录发送到 Elastic APM,以显示在“Errors”(错误)页中。
func helloHandler(w http.ResponseWriter, req *http.Request) {
vars := mux.Vars(req)
log := log.WithFields(apmlogrus.TraceContext(req.Context()))
log.WithField("vars", vars).Info("handling hello request")
name := vars["name"]
requestCount, err := updateRequestCount(req.Context(), name, log)
if err != nil {
log.WithError(err).Error(“failed to update request count”)
http.Error(w, "failed to update request count", 500)
return
}
stats, err := getNameStats(req.Context(), name)
if err != nil {
log.WithError(err).Error(“failed to update request count”)
http.Error(w, "failed to get name stats", 500)
return
}
fmt.Fprintf(w, "Hello, %s! (#%d)\n", name, requestCount)
fmt.Fprintf(w, "In %s, %d: ", stats.Region, stats.Year)
switch n := stats.Male.N + stats.Female.N; n {
case 1:
fmt.Fprintf(w, "there was 1 baby born with the name %s!\n", name)
default:
fmt.Fprintf(w, "there were %d babies born with the name %s!\n", n, name)
}
}
func updateRequestCount(ctx context.Context, name string, log *logrus.Entry) (int, error) {
span, ctx := apm.StartSpan(ctx, "updateRequestCount", "custom")
defer span.End()
if strings.IndexFunc(name, func(r rune) bool { return r >= unicode.MaxASCII }) >= 0 {
panic("non-ASCII name!")
}
tx, err := db.BeginTx(ctx, nil)
if err != nil {
return -1, err
}
row := tx.QueryRowContext(ctx, "SELECT count FROM stats WHERE name=?", name)
var count int
switch err := row.Scan(&count); err {
case nil:
if count == 4 {
return -1, errors.Errorf("no more")
}
count++
if _, err := tx.ExecContext(ctx, "UPDATE stats SET count=?WHERE name=?", count, name); err != nil {
return -1, err
}
log.WithField("name", name).Infof("updated count to %d", count)
case sql.ErrNoRows:
count = 1
if _, err := tx.ExecContext(ctx, "INSERT INTO stats (name, count) VALUES (?, 1)", name); err != nil {
return -1, err
}
log.WithField("name", name).Info("initialised count to 1")
default:
return -1, err
}
return count, tx.Commit()
}
如果我们现在运行程序,将输出重定向到一个文件(/tmp/hello.log,假设您在 Linux 或 macOS 上运行),我们则可以安装并运行 Filebeat,以将日志发送给接收 APM 数据的相同 Elastic Stack。安装 Filebeat 后,我们将在 filebeat.yml 中修改其配置,如下所示:
- 在“filebeat.inputs”下为日志输入设置“enabled: true”,并将路径更改为“/tmp/hello.log”。
- 如果使用的是 Elastic Cloud,则设置“cloud.id”和“cloud.auth”,否则设置“output.elasticsearch.hosts”。
- 添加“decode_json_fields”处理器,“processors”应类似如下所示:
processors:
- add_host_metadata: ~
- decode_json_fields:
fields: ["message"]
target: ""
overwrite_keys: true
现在运行 Filebeat,日志将开始显示内容。现在,如果我们向服务发送一些请求,就可以使用“Show host logs”(显示托管日志)操作在同一时间点从跟踪跳到日志。
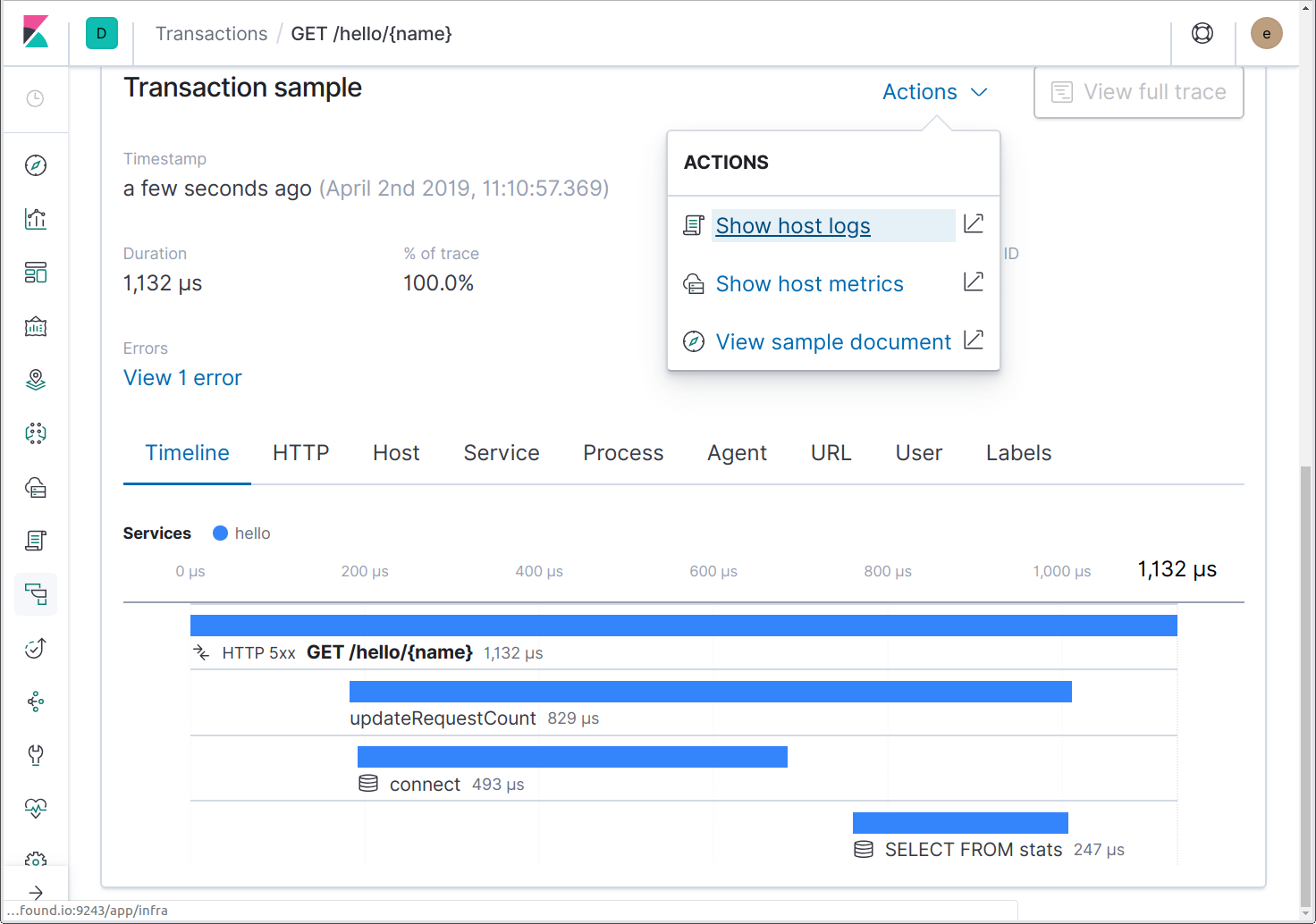
这个操作将显示已筛选的与托管有关的日志 UI。如果应用程序在 Docker 容器或 Kubernetes 中运行,则可以使用操作链接 Docker 容器或 Kubernetes Pod 的日志。
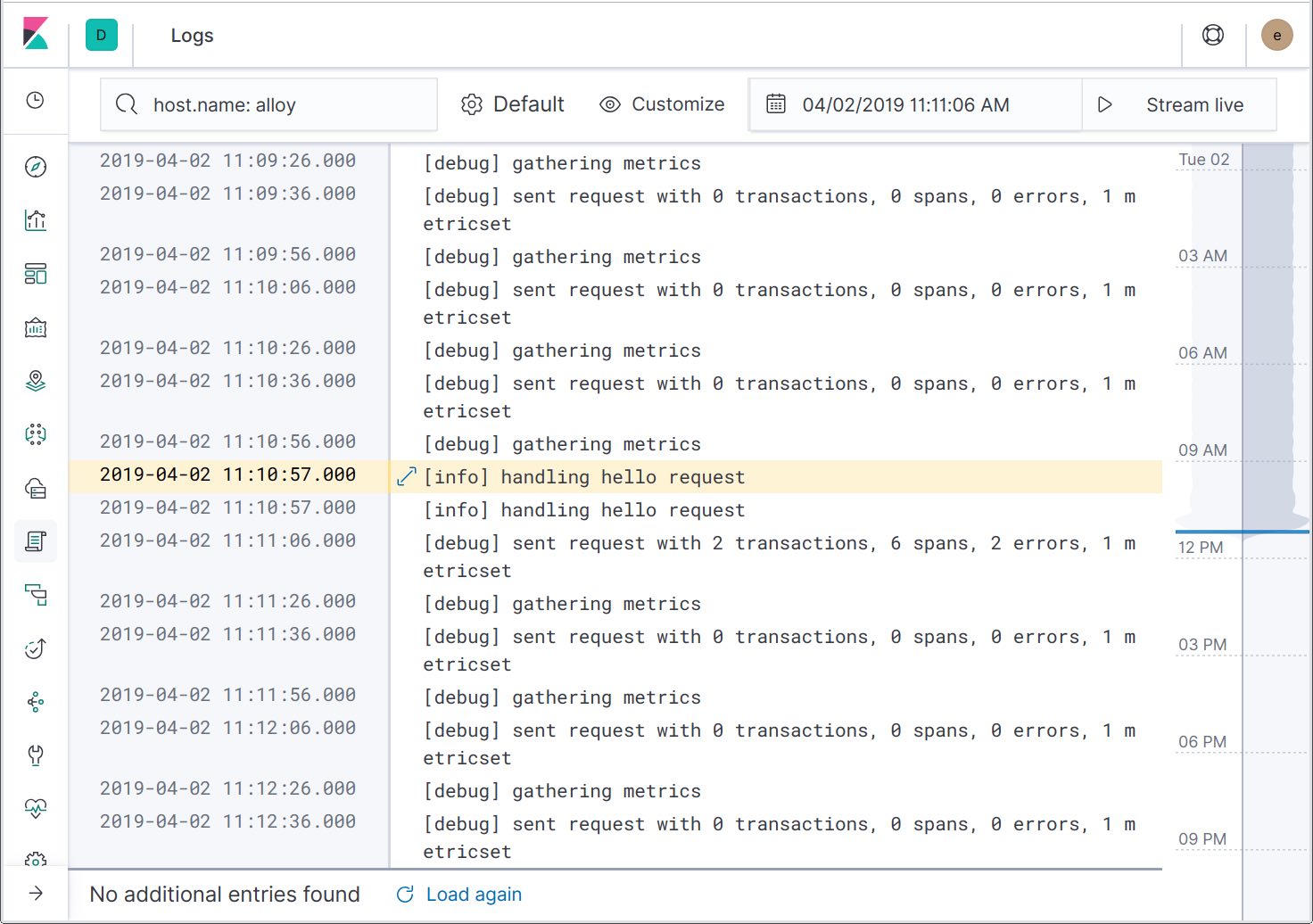
展开日志记录详细信息,我们可以看到跟踪 ID 已包含在日志消息中。在将来,会添加另一个操作,用以筛序与特定跟踪有关的日志,让您能够只查看相关的日志消息。
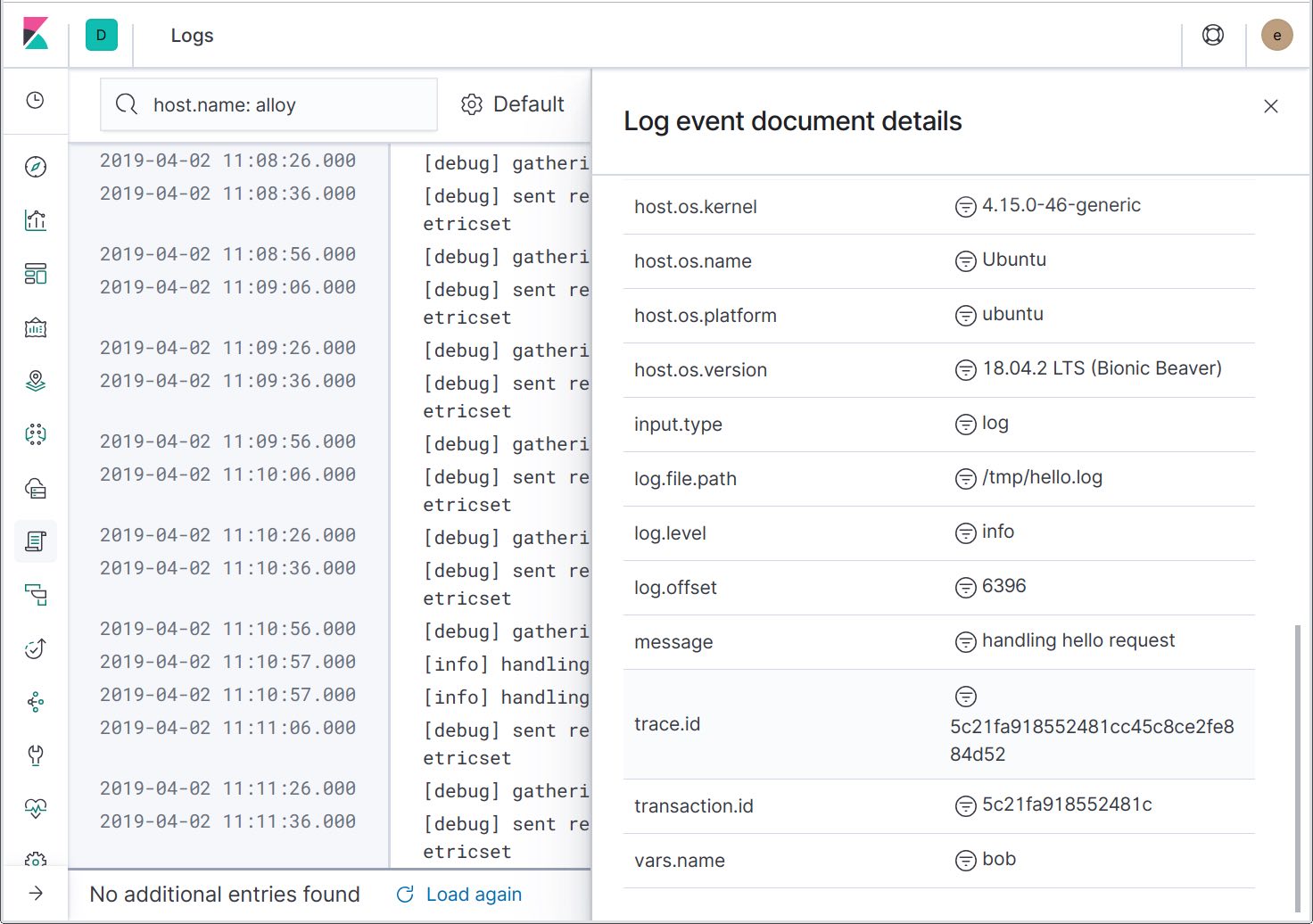
至此,我们已经能够从跟踪跳到日志,下面让我们看看另一个集成点:将错误日志发送到 Elastic APM,以显示在“Errors”(错误)页面中。为此,我们需要向记录器添加一个 apmlogrus.Hook:
func init() {
// apmlogrus.Hook will send "error", "panic", and "fatal" log messages to Elastic APM.
log.AddHook(&apmlogrus.Hook{})
}
先前,我们将 updateRequestCount 更改为了在第 4 个调用后返回错误,且更改了 helloHandler 以将其记录为一个错误。下面我们针对相同的名称发送 5 个请求,看看“Errors”(错误)页中会显示什么。
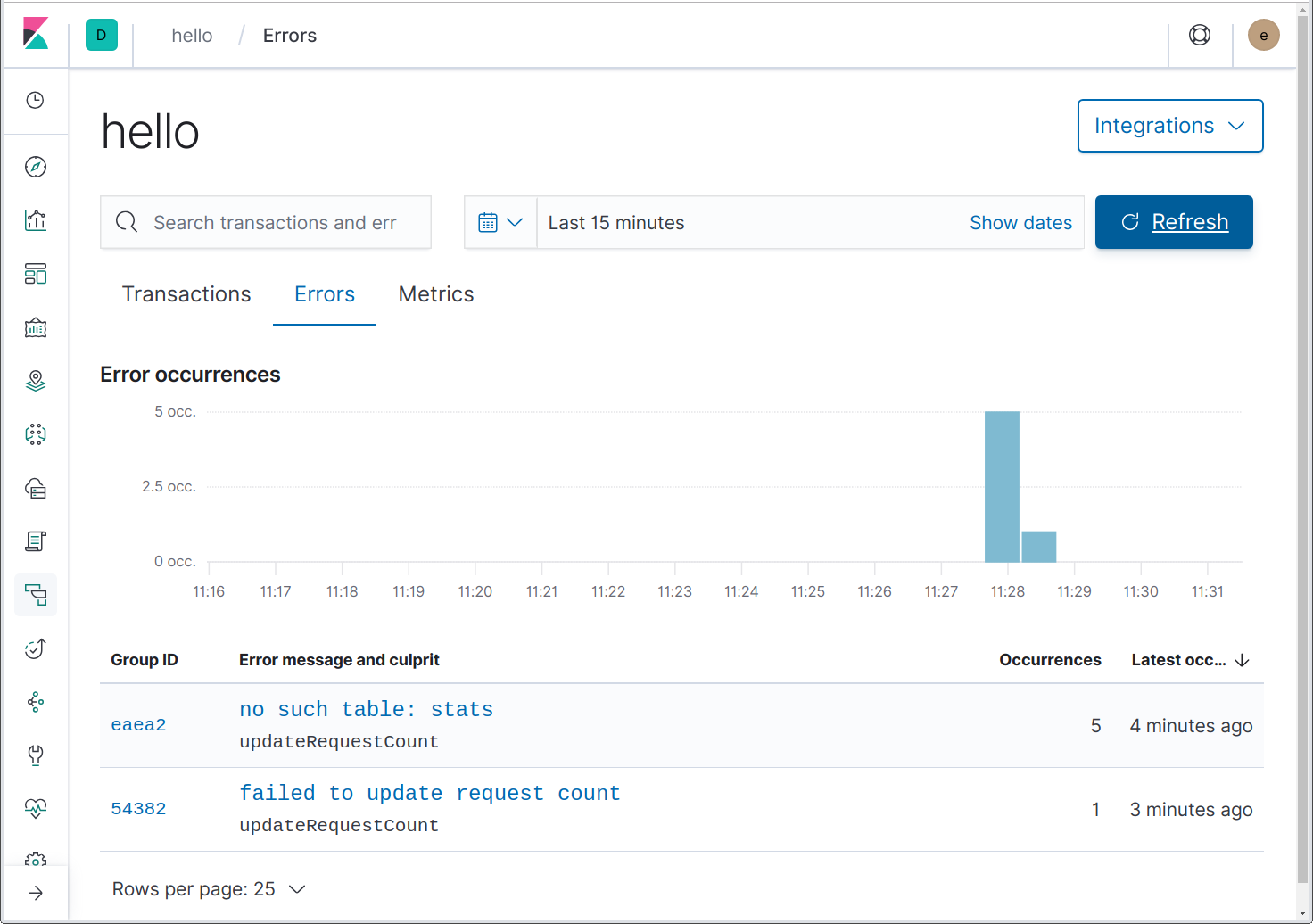
在这里,我们可以看到两个错误。其中一个错误是由于使用内存中数据库而导致的意外错误,https://github.com/mattn/go-sqlite3/issues/204 已对其做了清晰解释。非常好!“failed to update request count”(无法更新请求计数)错误是我们看到的错误。
注意,这两个错误的罪魁祸首都是 updateRequestCount。Elastic APM 如何知道这一点?因为我们使用的是 github.com/pkg/errors,它将堆栈跟踪添加到它创建或包装的每个错误,Go 代理知道如何使用这些堆栈跟踪。
基础架构和应用程序指标
最后,我们来谈谈指标。与使用 Filebeat 跳到托管和容器日志类似,您可以使用 Metricbeat 跳到托管和容器基础架构指标。此外,Elastic APM 代理还会定期报告系统和进程的 CPU 及内存使用情况。
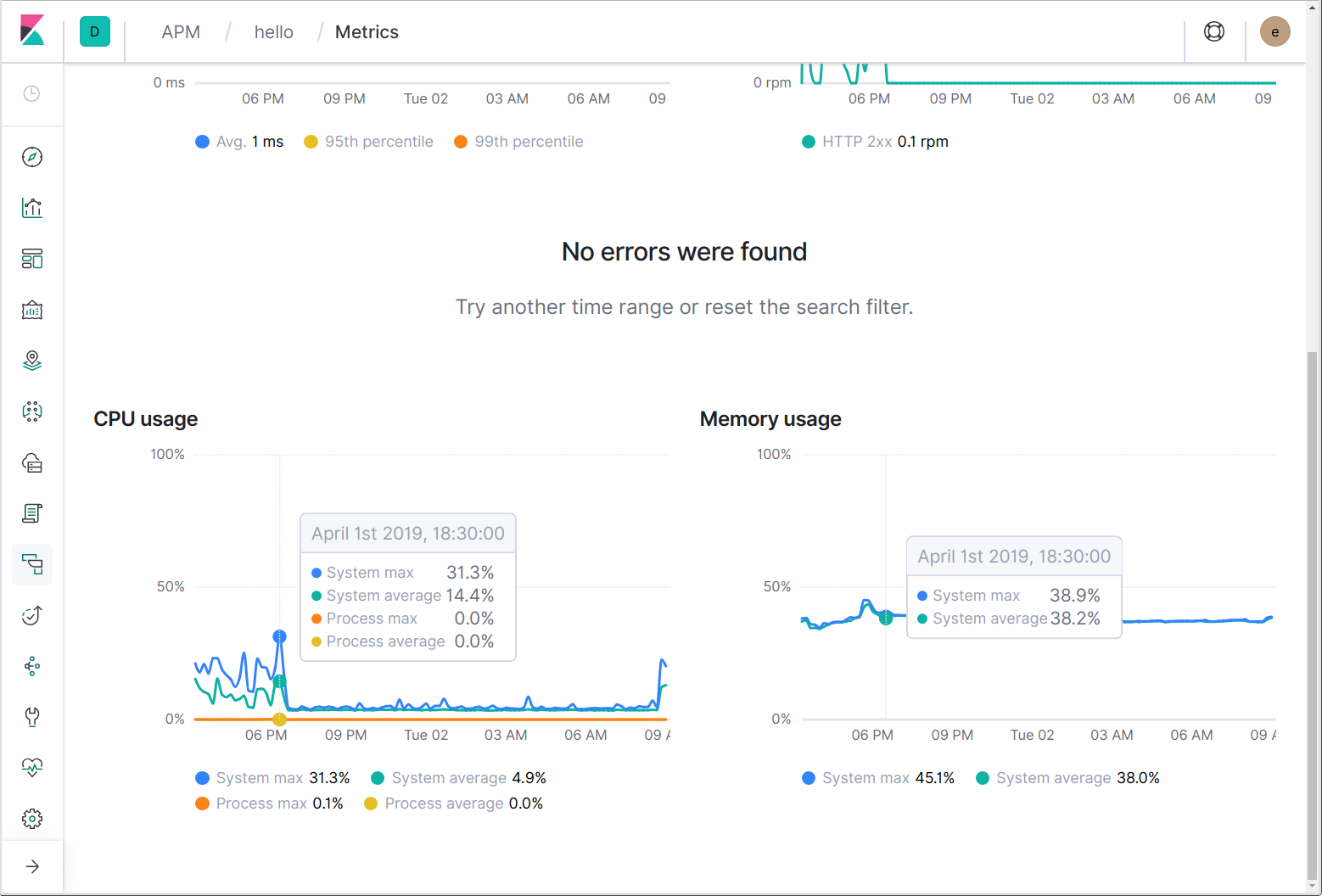
代理还可以发送特定于语言和应用程序的指标。例如,Java 代理可发送特定于 JVM 的指标,而 Go 代理可发送 Go 运行时的指标,例如,goroutine 的当前数量、堆分配的累积数量,以及垃圾收集的耗时百分比。
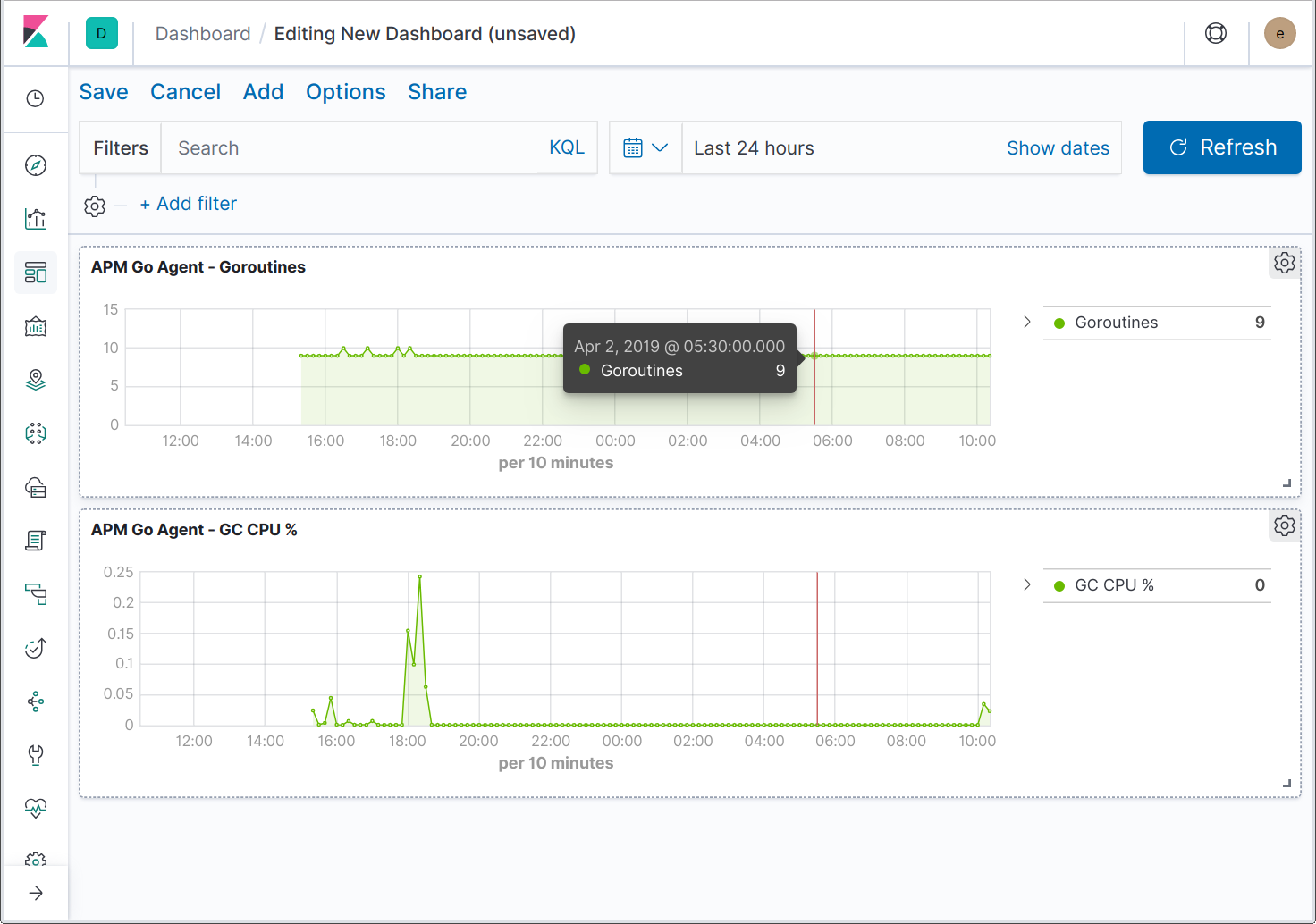
扩展 UI 以支持其他应用程序指标的工作正在进行中。同时,您可以创建仪表板来可视化特定于 Go 的指标。
但是等等,还有更多内容呢!
我们还没介绍如何与真实用户监测 (RUM) 代理集成,这将能够使您看到从浏览器开始的分布式跟踪,并一直跟踪您的后端服务。我们将在以后的博文中讨论这个主题。在这期间,您可以看看 Elastic RUM 浅谈来唤起您的兴趣。
我们在本篇文章中讨论了很多方面。如果您还有其他问题,请加入讨论论坛,我们将尽力回答。