使用 Google Dataflow 直接将数据从 Google BigQuery 采集到 Elastic 中


 Share on Twitter
Share on Twitter在 Twitter 上分享

 Share on LinkedIn
Share on LinkedIn在 LinkedIn 上分享

 Share on Facebook
Share on Facebook在 Facebook 上分享

 Share by Email
Share by Email通过邮件分享

 Print this page
Print this page打印
今天我们很高兴地宣布我们已支持直接将 BigQuery 数据采集到 Elastic Stack 中。现在,数据分析人员和开发人员只需在 Google Cloud 控制台中点击几下,就可以将数据从 Google BigQuery 采集到 Elastic Stack。通过利用 Dataflow 模板,本地集成允许客户简化他们的数据管道体系结构,并消除与代理安装和管理相关的运行开销。
许多数据分析人员和开发人员将 Google BigQuery 用作数据仓库解决方案,并将 Elastic Stack 用作搜索和仪表板可视化解决方案。为了增强两种解决方案的体验,Google 和 Elastic 合作提供了一种将数据从 BigQuery 表格和视图采集到 Elastic Stack 的简化方法。所有这些都是可行的,只需要在 Google Cloud 控制台中点击几下,而不需要安装任何数据采集器或 ETL(提取、转换、加载)工具。
在这篇博文中,我们将介绍如何进行从 Google BigQuery 到 Elastic Stack 的无代理数据采集。
简化 BigQuery + Elastic 的用例
BigQuery 是一种常用的无服务器数据仓库解决方案,这使得用户可以集中不同来源的数据,比如定制应用程序、数据库、Marketo、NetSuite、Salesforce、网络点击流,乃至 Elasticsearch。用户可以集合不同来源的数据集,然后运行 SQL 查询来分析数据。利用 BigQuery SQL 作业的输出在 BigQuery 中创建更多的视图和表格,或者创建仪表板以便与组织中的其他利益相关者和团队共享都是很常见的操作,而这些均可以通过 Elastic 的原生数据可视化工具 Kibana 实现!
BigQuery 和 Elastic Stack 的另一个关键用例是全文搜索。BigQuery 用户可将数据采集到 Elasticsearch 中,然后用 Elasticsearch API 或 Kibana 查询和分析搜索结果。
简化数据采集
Google Dataflow 是一种基于 Apache Beam 的无服务器异步消息传递服务。 Dataflow 可以代替 Logstash 直接从 Google Cloud 控制台采集数据。Google 和 Elastic 团队合作开发了一个开箱即用型 Dataflow 模板,可将数据从 BigQuery 推送到 Elastic Stack。这个模板取代了数据处理,比如以前由 Logstash 以无服务器的方式完成的数据格式转换,以前使用 Elasticsearch 采集管道的用户无需做其他更改。
如果您现在正在使用 BigQuery 和 Elastic Stack,您需要在 Google Compute Engine 虚拟机 (VM) 上安装一个单独的数据处理器(如 Logstash)或一个定制解决方案,然后使用其中一个数据处理器将数据从 BigQuery 发送到 Elastic Stack。配置 VM 和安装数据处理器会产生流程和管理开销。现在您可以省略这一步,直接用 Dataflow 的下拉菜单从 BigQuery 采集数据到 Elastic。化繁为简对许多用户来说是很有价值的,特别是当这一操作在 Google Cloud 控制台中点击几下就可以完成时,更加显得意义非凡。
下面是数据采集流的摘要。这种集成适用于所有用户,无论您使用的是 Elastic Cloud 上的 Elastic Stack、Google Cloud Marketplace 中的 Elastic Cloud,还是一个自管型环境。
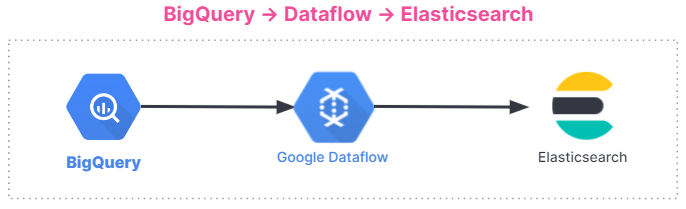
开始使用
为了展示将 BigQuery 的数据集成到 Elasticsearch 是多么容易,我们将使用常用的问答论坛 Stack Overflow 上的一个公共数据集。只需点击几下鼠标,您就可以通过 Dataflow 批处理作业采集数据,并开始在 Kibana 中搜索和分析。
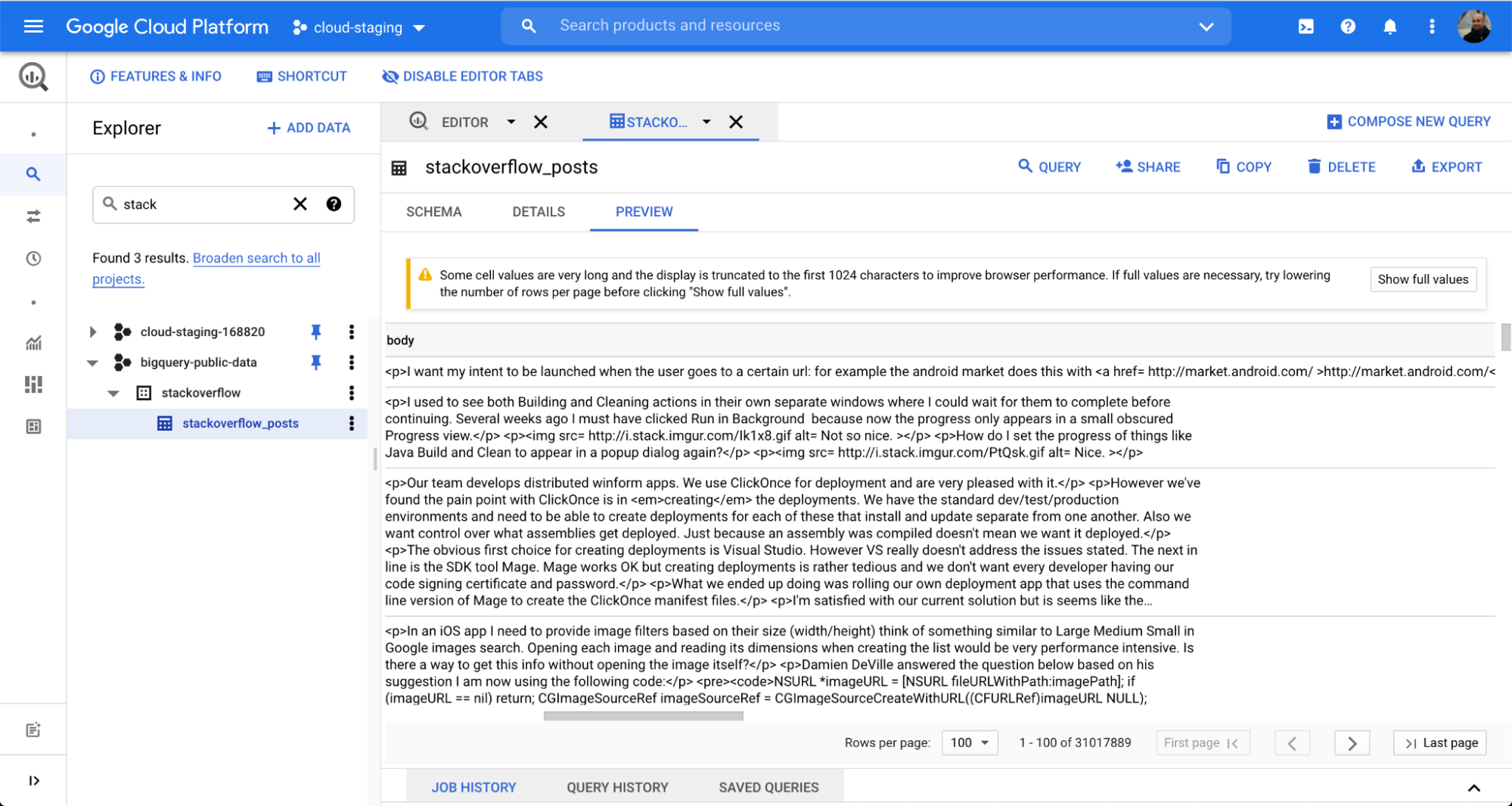
我们使用了一个 BigQuery 数据集堆栈溢出下名称为 stackoverflow_posts 的表格。它有几个结构化的字段作为列,如 post body、title、comment_count 等,我们将把它们引入 Elasticsearch 来执行自由文本搜索和聚合。
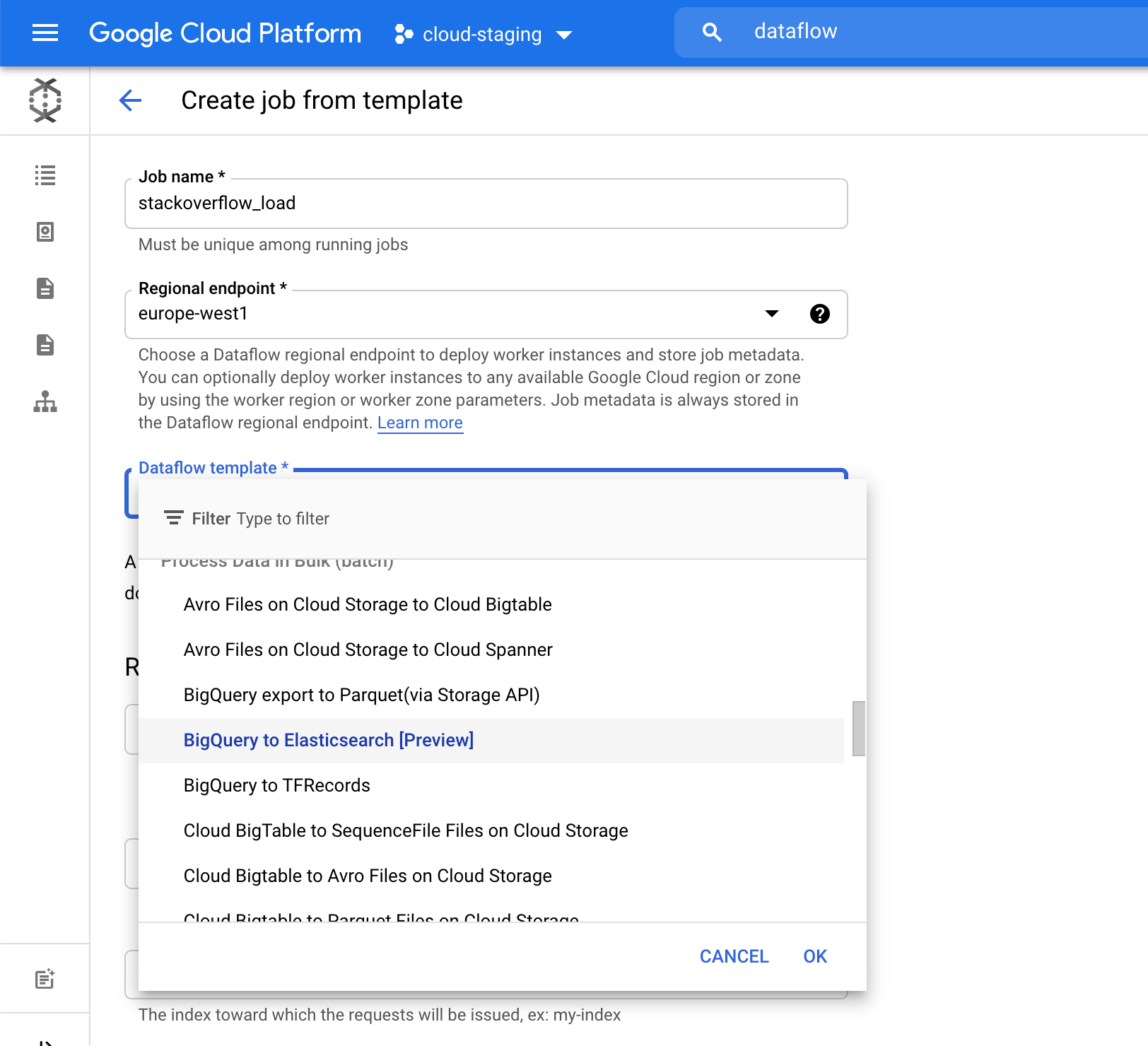
对于 Elasticsearch index 字段,请选择将加载数据的索引名称。例如,我们使用了索引 stack-posts。 要从 BigQuery 中读取的表,格式为:my-project:my-dataset.my-table。在我们的示例中,它是 bigquery-public-data:stackoverflow.stackoverflow_posts。
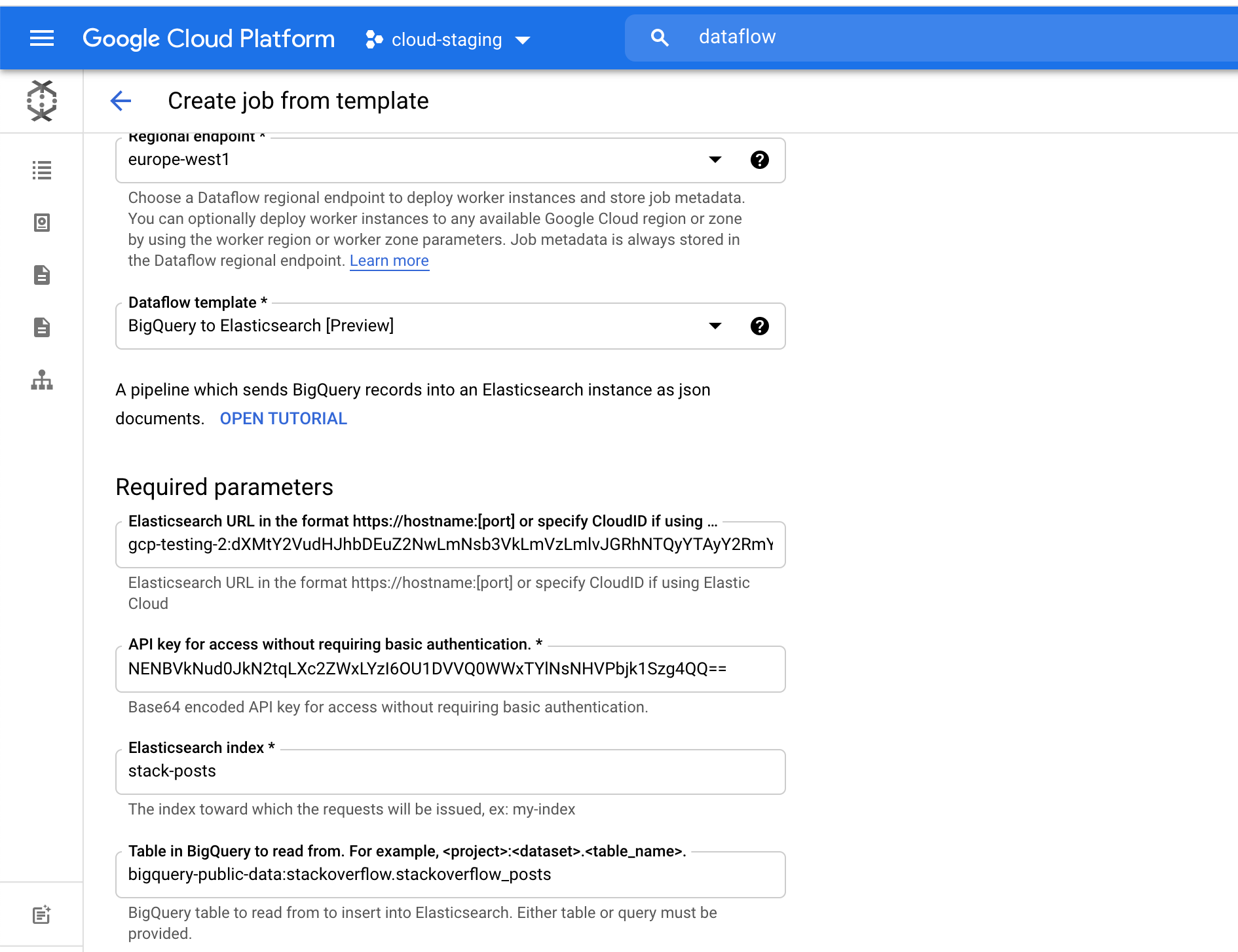
单击 Run Job(运行作业)可以开始批处理。
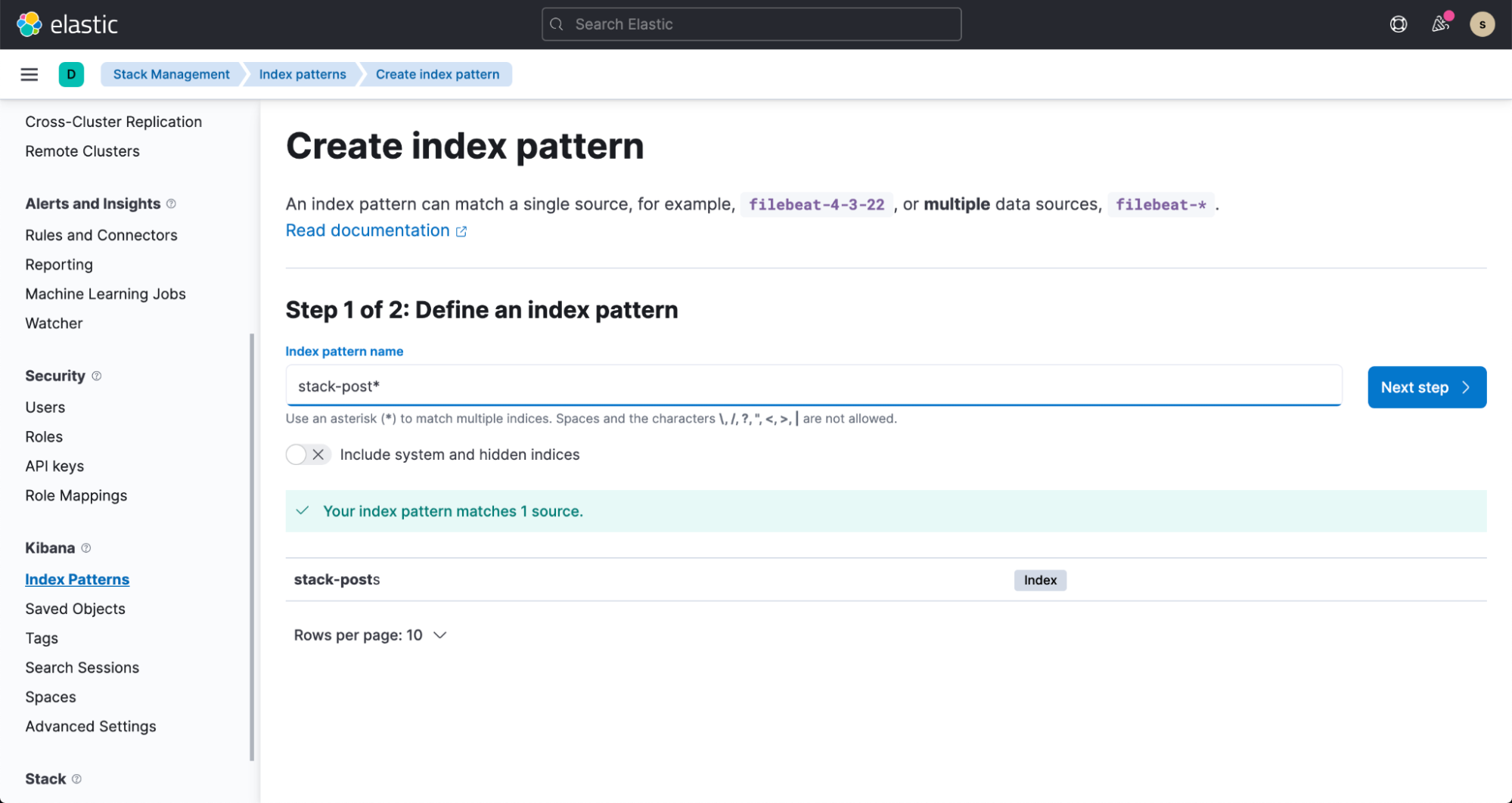
几分钟内,您就可以看到 Elasticsearch 索引中的数据流。要使这一数据可视化,请按照文档创建索引模式。
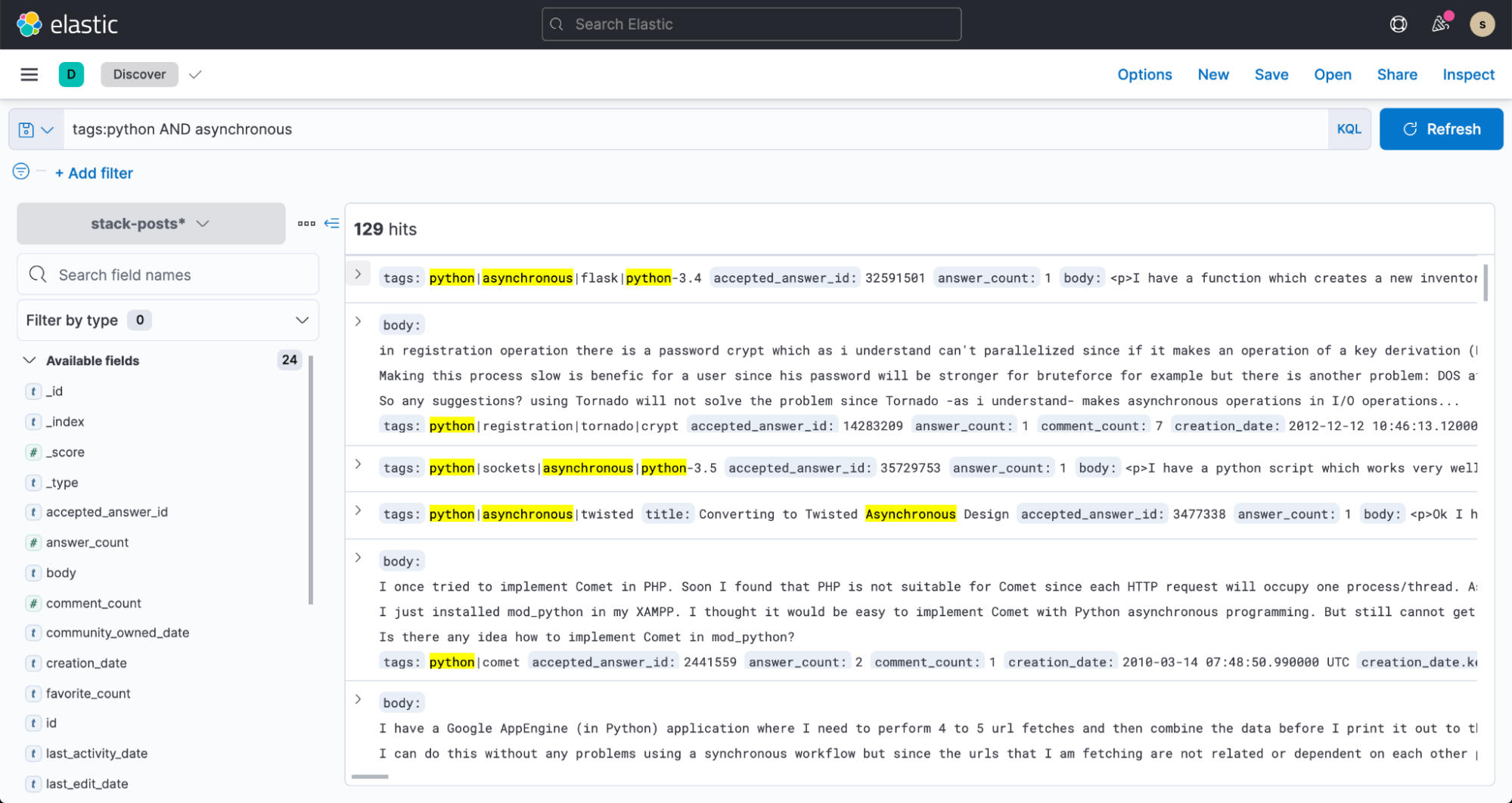
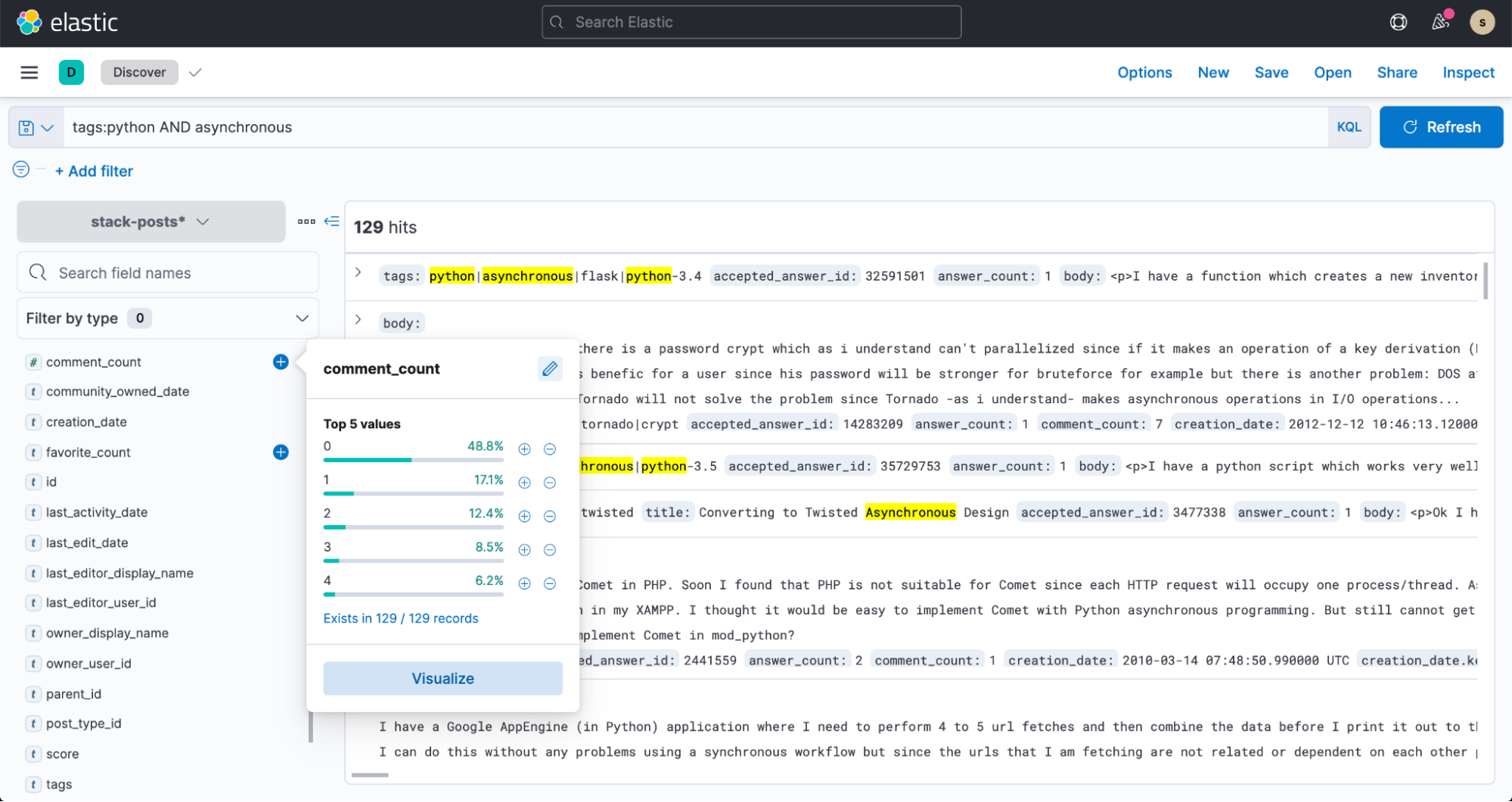
现在,请前往 Kibana 中的 Discover,开始搜索您的数据!
总结
Elastic 不断努力,使客户更容易、更顺畅地根据需要选择部署位置并使用所需功能,与 Google Cloud 的这种简化集成就是该理念的最新实例。Elastic Cloud 延伸了 Elastic Stack 的价值, 让客户的可用操作更多、更快,使它成为体验我们平台的最佳方式。要即刻体验 Google Cloud 上的 Elastic,请访问 Google Cloud Marketplace 或 elastic.co。分享
- Share on Twitter
在 Twitter 上分享
- Share on LinkedIn
在 LinkedIn 上分享
- Share on Facebook
在 Facebook 上分享
- Share by Email
通过邮件分享
- Print this page
打印

