Verteiltes Alerting mit dem Elastic Stack


 Share on Twitter
Share on TwitterAuf Twitter teilen

 Share on LinkedIn
Share on LinkedInAuf LinkedIn teilen

 Share on Facebook
Share on FacebookAuf Facebook teilen

 Share by Email
Share by EmailPer E-Mail teilen

 Print this page
Print this pageDrucken
Moderne Computing-Umgebungen und verteilte Belegschaften haben die herkömmlichen Ansätze für IT-Sicherheit vor neue Herausforderungen gestellt. Viele traditionelle Bedrohungserkennungs- und -Abwehrstrategien verlassen sich auf homogene Umgebungen, System-Baselines und einheitliche Kontrollimplementierungen. Diese Strategien setzen veraltete Annahmen in Bezug auf die Umgebung voraus, die in Ihrer Umgebung mit Cloud Computing, Remotearbeit und moderner Arbeitskultur womöglich nicht mehr zutreffen.
Elastic ist von Grund auf verteilt, von unserer Technologie bis hin zu unserer Belegschaft. Die Elastic-Mitarbeiter können jederzeit, überall und frei nach ihren Bedürfnissen arbeiten. Diese Freiheit umfasst auch verwendete Technologien, benötigte Konfigurationen und bevorzugte Software. Eine solche moderne Produktivitätskultur führt zu neuen Herausforderungen für die IT-Sicherheit.
Wie können wir eine Umgebung sichern, in der riskante Aktivitäten wie das Erstellen neuer Nutzer, das Konfigurieren von Netzwerkproxys und das Installieren neuer Software ohne Eingreifen der IT-Abteilung erlaubt sind? Wie können wir Bedrohungen in einer Umgebung ohne Baselines für Aktivitäten erkennen? Wie können wir unsere Erkennungs- und Abwehrfunktionen in einem modernen Unternehmen skalieren, das an vielen verschiedenen Standorten oder sogar in unterschiedlichen Ländern tätig ist? Wie können wir dieses Ziel ohne traditionelles Security Operation Center (SOC) erreichen?
Ganz einfach. Wir senden Alerts mit unserem verteilten Alerting-Framework an diejenigen, die am besten dazu geeignet sind, sie zu bestätigen oder zu verwerfen.
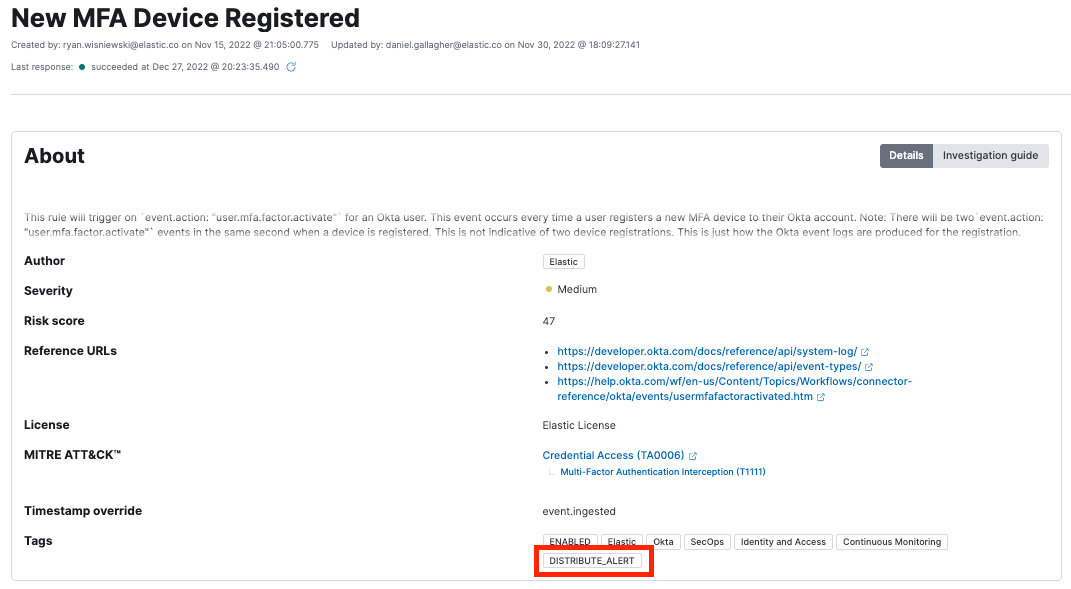
Mit dem verteilten Alerting kann unser Bedrohungserkennungs- und -Abwehrteam riskante Aktivitäten automatisch identifizieren, eine Nachricht in natürlicher Sprache an unsere Mitarbeiter senden und eine Bestätigung der Aktivität anfordern. Wenn die betroffene Person die Aktivität nicht erkennt, kann ein Alert sofort zur Behebung an unser Incident-Response-Team eskaliert werden. Das folgende Beispiel zeigt einen verteilten Alert an einen Mitarbeiter für ein neues MFA-Gerät, das für dessen Konto registriert wurde:
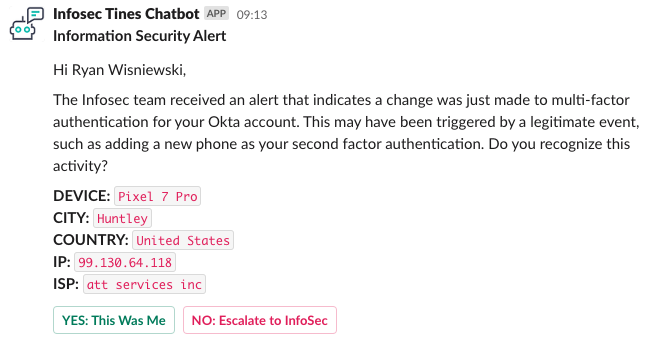
Wenn der Mitarbeiter die Aktivität erkennt, klickt er auf die Schaltfläche YES: This Was Me (JA: Das war ich). Anschließend können zusätzliche Informationen eingegeben werden, um die Aktivität zu erklären oder Optimierungsvorschläge zu machen.
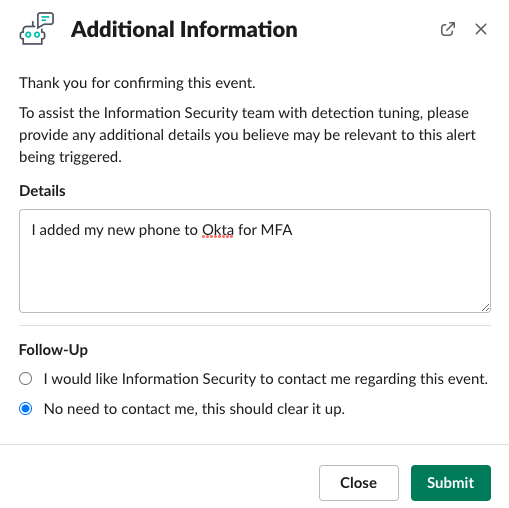
Im Backend wird ein neuer Sicherheitsfall erstellt, Alerts werden zum Fall zugeordnet, die Details werden erfasst und der Fall wird als „Keine Auswirkungen“ mit einer Zusammenfassung für den täglichen Bericht geschlossen.
Wenn der Mitarbeiter die Aktivität nicht erkennt, klickt er auf die Schaltfläche NO: Escalate to InfoSec (NEIN: an InfoSec eskalieren). Daraufhin werden ein neuer Sicherheitsfall und ein neuer Slack-Kanal erstellt, das Incident-Response-Team und die meldende Person werden in den Kanal eingeladen und das Team erhält zusätzliche Informationen.
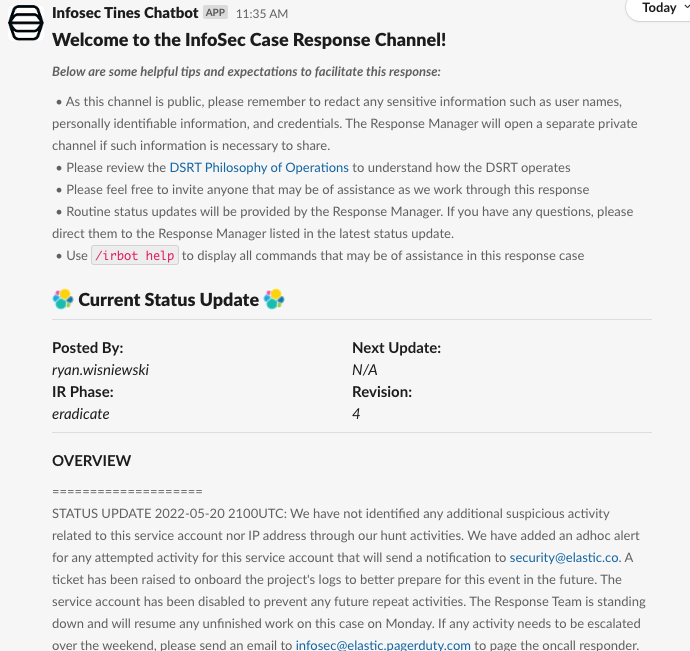
Wir senden diese Aktivitäten direkt an diejenigen, die sie am besten bestätigen können. Auf diese Weise optimieren wir nicht nur das Verhältnis zwischen echten Erkennungen und Falschmeldungen und beschleunigen die Behebung all dieser komplexen Erkennungen für Aktivitäten, die in unserer Umgebung regelmäßig auftreten, aber im schlimmsten Fall ein sehr hohes Risiko darstellen.
Wodurch zeichnen sich gute Kandidaten für verteiltes Alerting aus?
Gute Kandidaten für verteiltes Alerting sind Aktivitäten, die ein hohes Risiko für Ihre Sicherheitshaltung darstellen, aber keinerlei Kontext oder Anzeichen für bösartige Aktivitäten zeigen. Ein einzelner Alert für „Neues MFA-Gerät registriert“ für einen Nutzer enthält beispielsweise keinerlei Kontext oder Absicht für die Aktivität. Es kommt häufig vor, dass die Nutzer neue MFA-Geräte zu ihren Konten hinzufügen. Wenn es sich jedoch um das Gerät eines Angreifers handelt, gilt das Konto als kompromittiert, da alle nachfolgenden Anmeldungen mit einem gültigen Multi-Faktor-Gerät erfolgreich authentifiziert werden. Dieses Szenario stellt Bedrohungserkennungs- und -Abwehrteams vor eine schwierige Situation. Wie können wir diese Aktivitäten ohne jeglichen Kontext validieren, ohne jedes einzelne Detail der Ereignisse zu untersuchen? Indem wir die Alerts verteilen.
Hier ist unsere Bedrohungserkennungsstrategie, um Ihnen etwas Hintergrund zu liefern. Wir verfolgen verschiedene Ansätze, um alle Systemaktivitäten vollständig abzudecken.
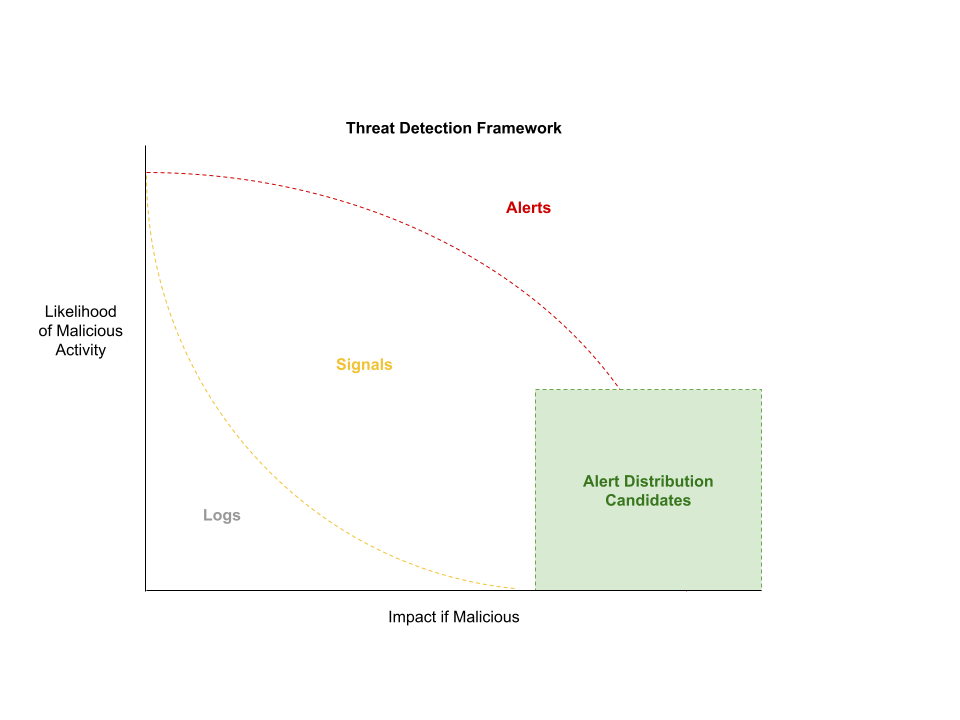
Dazu unterteilen wir unsere Ereignisse in drei Kategorien:
- Logs: Alle Ereignisse, die in einem System auftreten. Logs werden oft in Untersuchungen einbezogen, um herauszufinden, was vorgefallen ist. Ein Log-Ereignis an sich ist kein Anzeichen für eine verdächtige Aktivität. Log-Ereignisse zeichnen lediglich aufgetretene Vorgänge auf.
- Signale: Wir nutzen die Elastic Security-Anwendung, um Signale zu generieren. Speziell geschriebene Erkennungsregeln identifizieren Aktivitäten, die zwar möglicherweise verdächtig sind, aber auch gutartig sein können. Es ist schwierig, den Kontext solcher Ereignisse anhand eines einzelnen Vorkommnisses zu bewerten, daher wird nicht sofort ein Alert generiert. Sogenannte Threat Hunts verwenden Signale, um verwandte Aktivitäten zu identifizieren, mit denen gut- oder bösartige Inhalte erkannt werden und die Erkennungsregel von einem Signal zu einem Alert heraufgestuft wird.
- Alerts: Wir stufen Signale zu Alerts herauf, wenn wir zuversichtlich sind, dass das Signal auf eine bösartige Aktivität hindeutet (Wahrscheinlichkeit für eine bösartige Aktivität) oder wenn eine Aktivität so umfassende Auswirkungen hat, dass alle Ereignisse validiert werden müssen, um die Auswirkungen zu reduzieren (Auswirkung falls bösartig).
Alerts mit umfassenden Auswirkungen und niedriger Wahrscheinlichkeit für bösartige Absichten eignen sich hervorragend für die Verteilung. Auf diese Weise können wir Verwaltungstätigkeiten, neue Aktivitäten, ungewöhnliche Benutzeraktivitäten und alle sonstigen Aktivitäten im gesamten Unternehmen validieren, ohne dafür ein herkömmliches SOC zu benötigen.
Wie verteilen wir die Alerts?
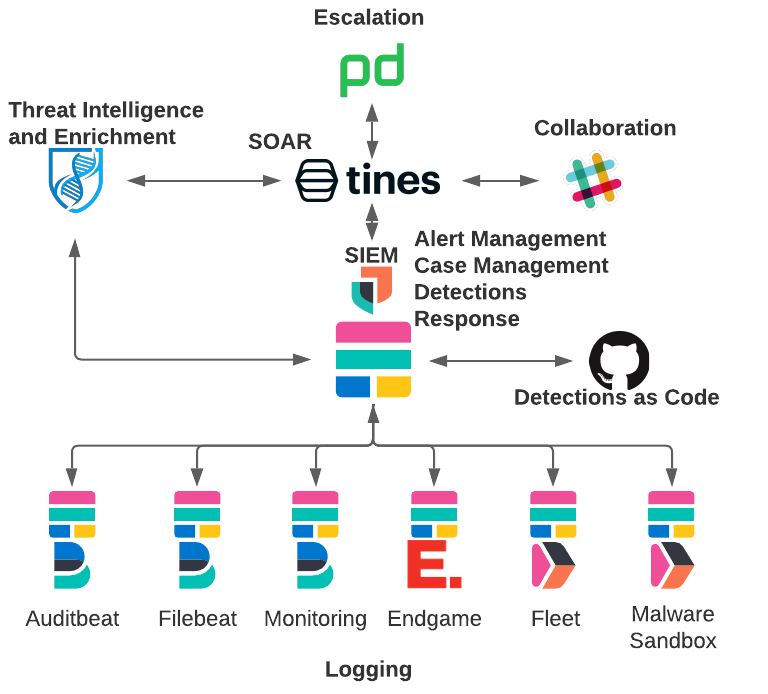
Als „Customer Zero“ für Elastic-Produkte steht unser Elastic Stack im Zentrum unserer SIEM- und SOAR-Architektur. Weitere Informationen dazu, wie wir all unsere Daten in den Elastic Stack ingestieren, finden Sie in unserem Blogeintrag Elastic on Elastic: Data Collected to the InfoSec SIEM (in englischer Sprache).
Wir haben einige Änderungen an unserer Architektur vorgenommen, um diese neue Funktion für verteiltes Alerting nutzen zu können.
Wir haben eine Automatisierungsplattform integriert, um unserer Workflows in der No-Code-Automatisierungsplattform von Tines zu zentralisieren. Mit den in Tines erstellten Workflows werden die Alerts aus dem Elastic Stack vorselektiert und anhand der vordefinierten Logik in den Tines-Storys verteilt.
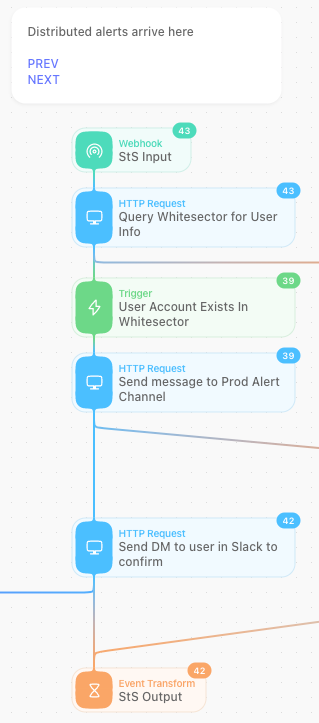
Wenn eine Erkennungsregel für die Verteilung markiert ist (DISTRIBUTE_ALERT), leitet Tines den Alert aus der Vorauswahl-Warteschlange an den Workflow für das verteilte Alerting weiter.
Alle Alerts mit der Markierung DISTRIBUTE_ALERT durchlaufen unseren Workflow für das verteilte Alerting. Der Tines-Workflow identifiziert die entsprechenden Nutzer in der Asset-Datenbank und sendet ihnen die Alerts anschließend per Slack zur Bestätigung.
Wenn ein Nutzer auf die Schaltfläche im Alert klickt, wird der nächste Workflow ausgelöst, der entweder zusätzliche Informationen anfordert oder den Alert zum Incident-Response-Team eskaliert.
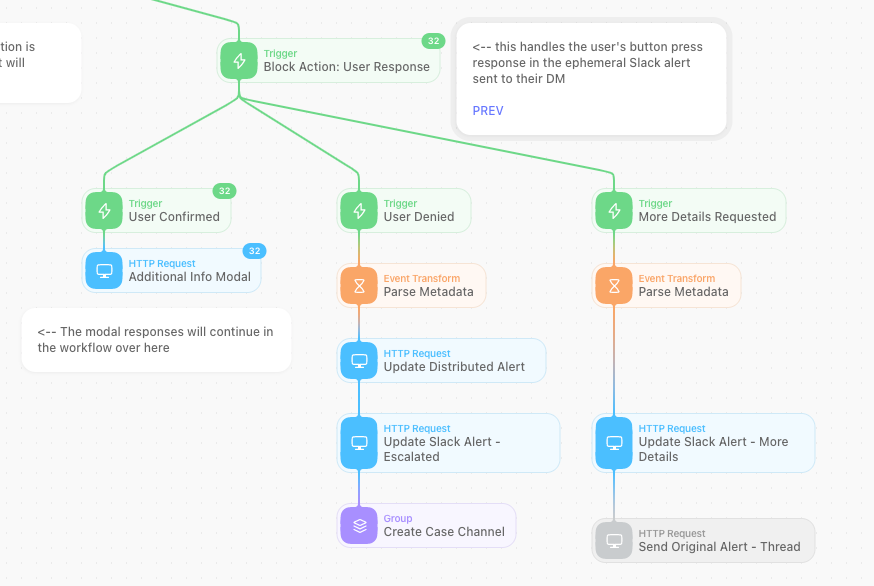
Diese Alerts eröffnen automatisch einen neuen Fall in Elastic Cases mit sämtlichen relevanten Informationen. Zusätzliche Automatisierungen liefern weitere Anreicherungen für Analysten, wie etwa GreyNoise und verwandte Elastic Security-Alerts. Außerdem werden die Aktivitäten der letzten 30 Tage für die IP-Adresse in einer Elastic Timeline bereitgestellt und können von Analysten überprüft werden.
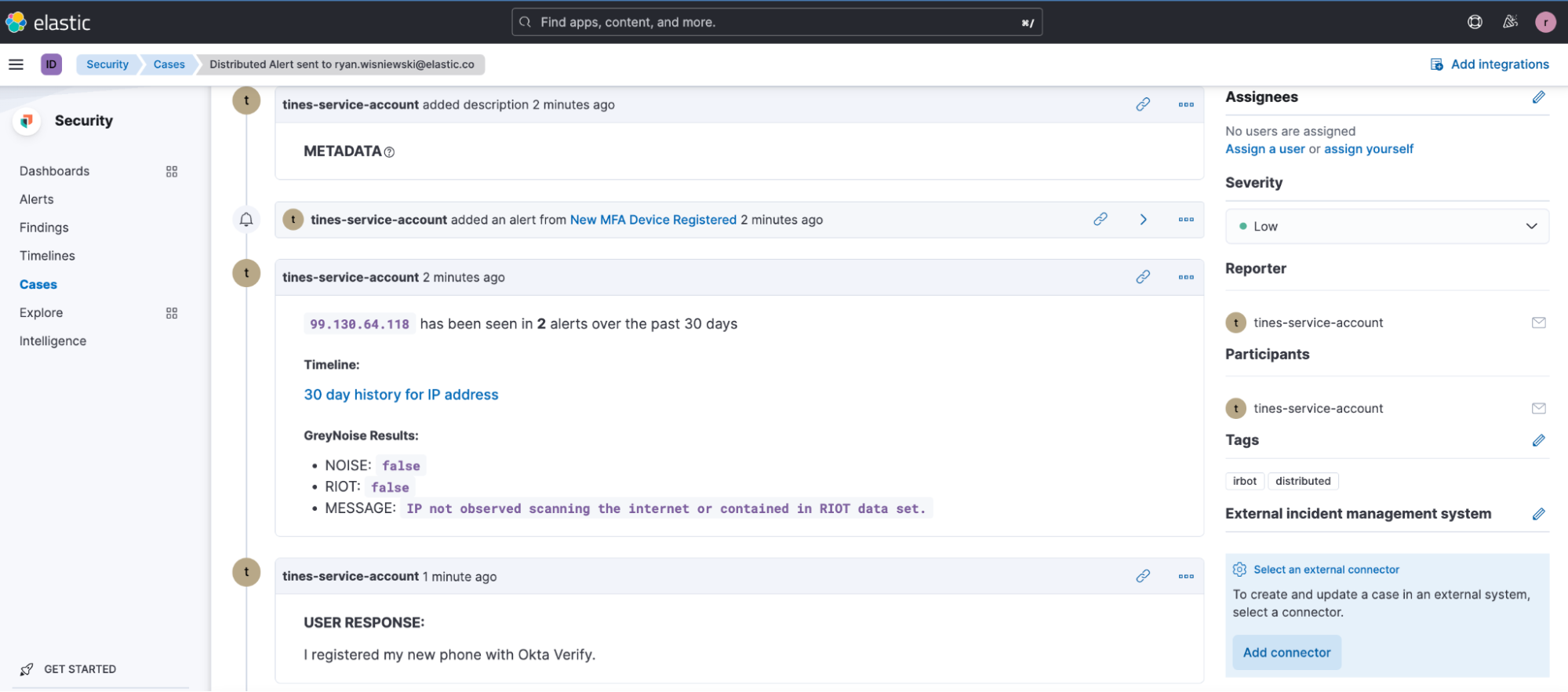
Wenn ein Nutzer sein Feedback abgibt und die Aktivität bestätigt, wird das Feedback im Fall erfasst und der Fall wird geschlossen.
Wie kann ich anfangen?
Sie können mit einerkostenlosen 14-tägigen Testversion von Elastic Cloud beginnen und die Tines-Beispielstory Triage Elastic Security alerts and block malicious IPs verwenden, um Elastic Security-Alerts in Ihre Automatisierungs-Workflows zu ingestieren. Anschließend können Sie die Lösung mit Ihrem bevorzugten Messaging-Client integrieren. Die Tines-Bibliothek enthält Beispiel-Storys für Slack und Microsoft Teams.
Teilen
- Share on Twitter
Auf Twitter teilen
- Share on LinkedIn
Auf LinkedIn teilen
- Share on Facebook
Auf Facebook teilen
- Share by Email
Per E-Mail teilen
- Print this page
Drucken