On-Demand-Forecasting mit Machine Learning in Elasticsearch
Anmerkung des Autors (3. August 2021): Dieser Beitrag verwendet veraltete Features. In der Dokumentation zum Thema Map custom regions with reverse geocoding (benutzerdefinierte Regionen mit umgekehrter Geocodierung zuordnen) finden Sie eine aktuelle Anleitung.
Die neueste X-Pack-Machine-Learning-Funktion in 6.1 ist On-Demand-Forecasting. Bisher war das Machine Learning in Elastic darauf ausgelegt, anhand historischer Daten den normalen Wertebereich für die „Jetztzeit“ vorherzusagen und diesen mit den tatsächlichen Daten zu vergleichen, um so eine Anomalieerkennung in Echtzeit zu ermöglichen. In 6.1 kann Machine Learning jetzt die Daten modellieren und über mehrere Zeitintervalle hinweg die Zukunft vorhersehen.
Wir nennen das „On-Demand-Forecasting“, weil Nutzer einen bestehenden Machine-Learning-Job nehmen und mithilfe des in Machine Learning integrierten Vorhersagemodells vorhersagen lassen können, wo dieses Modell im Laufe des Vorhersagezeitraums wachsen wird. Die Vorhersageergebnisse werden in einen Elasticsearch-Index geschrieben, der es Nutzern erlaubt, die tatsächlichen Ergebnisse mit den Vorhersagemodellen zu vergleichen.
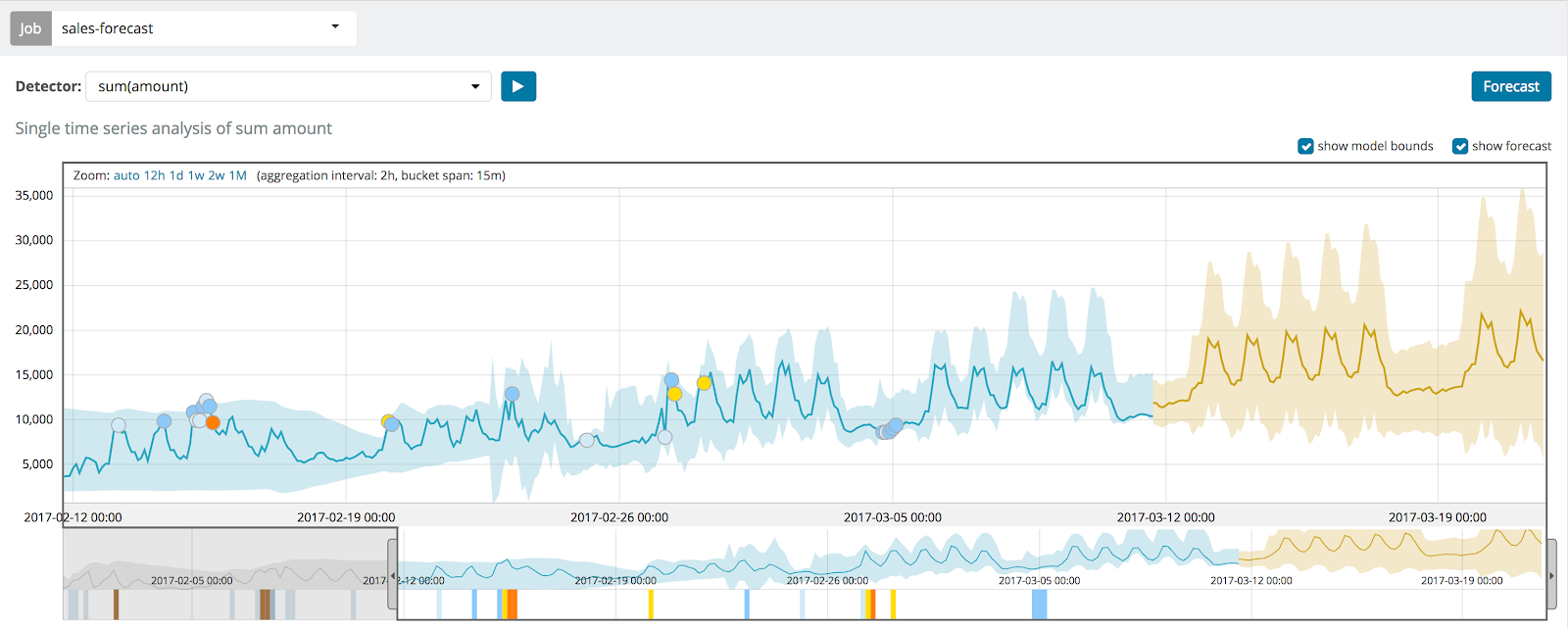
Kapazitätsplanung mit Machine Learning und Forecasting
Dass die Performance in der Vergangenheit nichts über künftige Ergebnisse aussagt, ist mittlerweile ein alter Hut. Und dennoch lassen sich Ergebnisse für die Kapazitätsplanung am besten anhand von Indikatoren vorhersagen, die auf der Performance in der Vergangenheit beruhen.
Wie lässt sich ermitteln, wann eine bestimmte Ressource ihre Kapazitätsgrenzen erreicht? Wenn Sie beispielsweise den Speicherplatz Ihres Servers überwachen, müssen Sie möglicherweise abschätzen können, wann dieser voll sein wird. Die auf Machine Learning basierenden Vorhersagemodelle von Elastic erlauben einen Blick in die Zukunft und ermöglichen es, Aussagen darüber zu treffen, wann Sie das System um weitere Speicherkapazitäten erweitern müssen.
Mit Kapazitätsplanung können Sie auch eine Mengenkennzahl zu einem bestimmten Zeitpunkt in der Zukunft vorhersagen. So lässt sich beispielsweise vorhersagen, wie viele Kundenanrufe Ihr Unternehmen an einem Montagmorgen zu erwarten hat. Durch die Analyse der historischen Daten und die Anwendung der komplexen Machine-Learning-Modelle können Sie Informationen erlangen, die Sie für Entscheidungen rund um Personalbesetzung und Ressourcen benötigen.
Erste Schritte mit der Forecasting-Funktion
Vorhersagen können über die Ansicht „Single Metric Viewer“ bestehender Machine-Learning-Jobs gestartet werden. Auf Systemen mit Version 6.1 und höher gibt es rechts oben die neue Optionsschaltfläche „Forecast“ (Vorhersagen), über die Sie Vorhersagen starten können.
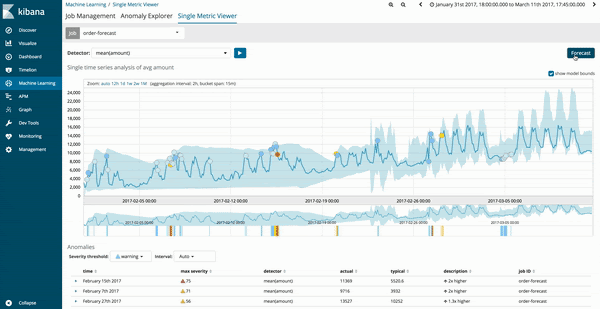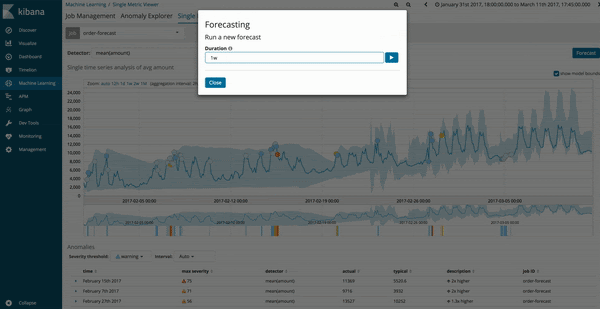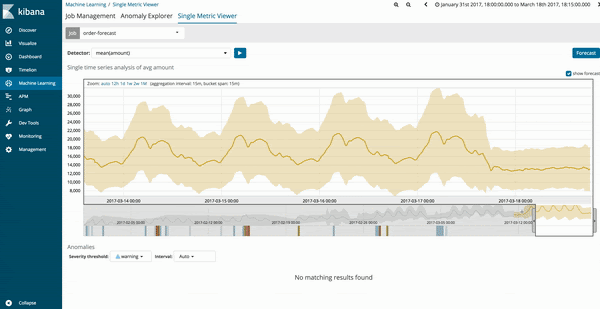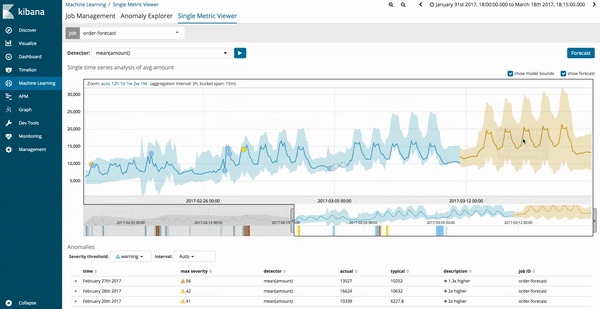
Die Ergebnisse der Vorhersagen für den Machine-Learning-Job werden als Schätzwerte in Form einer dunkelgelben Trendlinie dargestellt, die sich innerhalb eines hellgelben Bandes befindet, das den Zuverlässigkeitsbereich angibt. Je dünner der hellgelbe Zuverlässigkeitsbereich ist, desto größer ist die Zuverlässigkeit der Vorhersage. Dort, wo die Zuverlässigkeit des Vorhersagemodells abnimmt, wird der hellgelbe Bereich breiter.
Überlegungen zur Vorhersageerstellung
Bei der Erstellung von Vorhersagemodellen gilt es, bestimmte Aspekte zu berücksichtigen. Die Vorhersageergebnisse könnten anders als erwartet aussehen und nicht jede Gruppe von Daten eignet sich für eine Vorhersage.
Es wird empfohlen, ausreichende historische Daten zu sammeln, bevor Sie sich daran machen, einen Machine-Learning-Job für Vorhersagezwecke zu starten. Idealerweise sollten in der Regel Daten für ungefähr drei Wochen oder bei periodischen Daten für drei volle Intervalle vorliegen. Wenn Sie Ihre Vorhersage zu einem zu frühen Zeitpunkt in der Lernphase starten, also bevor das Modell wirklich auf eigenen Füßen steht, werden dabei wahrscheinlich unbrauchbare Ergebnisse herauskommen.
Sollten die Zuverlässigkeitswerte für die Vorhersage angemessene Grenzwerte überschreiten, bricht das Vorhersagemodell den Vorgang vorzeitig ab. In diesem Fall erhalten Sie eine Meldung (wie die unten dargestellte), aus der hervorgeht, dass die Zuverlässigkeitswerte außerhalb der akzeptablen Grenzen liegen.

Vorhersageergebnisse sind wesentlich einfacher zu verstehen, wenn die Option „model_plot“ aktiviert ist. Bei Jobs für eine einzelne Metrik ist dies standardmäßig der Fall, und bei Jobs mit mehreren Metriken kann die Option durch Konfigurieren der Option „model_plot_config“ innerhalb der Konfigurationsdatei für den Machine-Learning-Job aktiviert werden.
Um die Verfolgung von Vorhersagen außerhalb der Ansicht „Single Metric Viewer“ zu erleichtern, erhält jede Vorhersage eine eindeutige ID (forecast_ID), sodass die Vorhersagen separat abgefragt werden können. Es können mehrere Vorhersagen für ein und dieselbe Metrik ausgeführt werden, aber pro einzelne Metrik werden in der Benutzeroberfläche nur die letzten fünf Vorhersagen angezeigt. Dennoch sind alle Vorhersagen weiter verfügbar und belegen entsprechenden Indexplatz. Wird die Vorhersage von der Benutzeroberfläche aus ausgeführt, werden die Vorhersageergebnisse automatisch nach 14 Tagen gelöscht. In der API kann jedoch ganz frei festgelegt werden, wann die Daten ablaufen. Nähere Einzelheiten können der Dokumentation für die API für Vorhersage-Jobs entnommen werden.
Machine Learning ist Bestandteil eines Elastic Platinum-Abonnements, aber Sie können eine kostenlose Probeversion von X-Pack herunterladen und es selbst ausprobieren.