Semantische Suchen in Elasticsearch unter Verwendung eines NLP-Modells für Japanisch


 Share on Twitter
Share on TwitterAuf Twitter teilen

 Share on LinkedIn
Share on LinkedInAuf LinkedIn teilen

 Share on Facebook
Share on FacebookAuf Facebook teilen

 Share by Email
Share by EmailPer E-Mail teilen

 Print this page
Print this pageDrucken
In der Menge der täglich anfallenden internen Dokumente und Produktinformationen schnell genau die Dokumente zu finden, die man gerade braucht, ist sowohl im Arbeits- als auch im Alltagsleben äußerst wichtig. Wenn aber sehr viele Dokumente durchsucht werden müssen, kann es selbst für Computer zeitaufwendig sein, alle Dokumente in Echtzeit neu zu lesen und die richtige Datei zu finden. Das war das Motiv für das Entstehen von Elasticsearch® und anderer Suchmaschinen-Software. Suchmaschinen erstellen zu allererst Suchindexdaten, die dabei helfen, die Schlüsselsuchbegriffe in Dokumenten schnell zu finden.
Doch selbst dann, wenn die Nutzer:innen eine allgemeine Vorstellung davon haben, welche Art von Informationen sie suchen, können sie sich möglicherweise nicht an ein passendes Schlüsselwort erinnern oder aber sie suchen einen anderen Ausdruck, der dieselbe Bedeutung hat. Für solche Informationen können in Elasticsearch Synonyme und ähnliche Begriffe definiert werden, aber in manchen Fällen kann es schwierig sein, einfach eine Korrespondenztabelle zu verwenden, um eine Suchanfrage so umzuwandeln, dass sie besser passt.
Um hierfür eine Lösung bereitzustellen, wurde in Elasticsearch 8.0 die Vektorsuche eingeführt, die nach dem semantischen Inhalt einer Wendung sucht. Darüber hinaus gibt es bei uns eine Blog-Serie, in der es darum geht, wie Sie mit Elasticsearch Vektorsuchen und andere NLP-Aufgaben erledigen können. Bis zu Version 8.8 war Elasticsearch jedoch nicht in der Lage, Text in einer anderen Sprache als Englisch korrekt zu analysieren.
Seit Version 8.9 stehen Funktionen für die korrekte Analyse von Japanisch in der Textanalyse zur Verfügung. Dadurch ist Elasticsearch in der Lage, semantische Suchen wie die Vektorsuche in japanischen Texten sowie NLP-Aufgaben wie die Sentimentanalyse auf Japanisch durchzuführen. In diesem Artikel zeigen wir Schritt für Schritt, wie Sie diese Features nutzen können.
Voraussetzungen
Bevor Sie die semantische Suche implementieren und nutzen können, müssen einige Voraussetzungen erfüllt sein. In Elasticsearch-Clustern werden den einzelnen Rollen Knotenrollen zugewiesen. Die Machine-Learning-Knoten von Elasticsearch haben sich mittlerweile zu den Hauptantriebskräften des Machine-Learning-Modells entwickelt. Um dieses Feature nutzen zu können, muss im Elasticsearch-Cluster ein Machine-Learning-Knoten aktiv sein. Kontrollieren Sie, ob das bei Ihnen der Fall ist. Außerdem benötigen Sie mindestens eine Platinum-Lizenz, um Machine-Learning-Knoten nutzen zu können. Wenn Sie die Features erst einmal nur ausprobieren möchten, um zu sehen, wie sie funktionieren, reicht auch eine Testlizenz. Um die Funktionsfähigkeit in einer Entwicklungsumgebung oder einer ähnlichen Instanz zu überprüfen, aktivieren Sie die Testversion auf dem Kibana®-Bildschirm oder über die API.
Prozess der Ausführung einer semantischen Suche
Zum Ausführen einer semantische Suche in Elasticsearch sind die folgenden Schritte erforderlich:
(Vorbereitung) Eland und zugehörige Bibliotheken auf der Workstation installieren
Das Machine-Learning-Modell importieren, um NLP-Aufgaben zu ermöglichen
Textanalyseergebnisse im importieren Machine-Learning-Modell indexieren
Mithilfe des Machine-Learning-Modells eine kNN-Suche durchsuchen
Die semantische Suche ist nicht das Einzige, was die Verarbeitung natürlicher Sprache (NLP) möglich macht. In der zweiten Hälfte dieses Blogposts zeigen wir anhand von Beispielen, wie Sie das Machine-Learning-Modell, das eine Textklassifizierung ermöglicht, für eine Sentimentanalyse von Texten (positive oder negative Grundstimmung) verwenden können.
Sehen wir uns also die einzelnen Schritte einmal genauer an.
Installation von Eland
Elasticsearch ist jetzt in der Lage, sich wie eine NLP-Plattform zu verhalten. Allerdings fehlt es Elasticsearch an echten eigenen NLP-Funktionen. Jede notwendige Verarbeitung natürlicher Sprache muss nutzerseitig als Machine-Learning-Modell in Elasticsearch importiert werden. Dieser Import erfolgt mithilfe von Eland. Da Eland keine Grenzen hinsichtlich des zu importierenden externen Modells setzt, kann die Nutzerin oder der Nutzer jederzeit genau die Machine-Learning-Funktionalität hinzufügen, die er oder sie benötigt.
Eland ist eine von Elastic bereitgestellte Python-Bibliothek, mit deren Hilfe Nutzer:innen Elasticsearch-Daten mit umfangreichen Python-Machine-Learning-Bibliotheken wie PyTorch und scikit‑learn verknüpfen können. Mit dem Eland-eigenen Befehlszeilentool eland_import_hub_model können NLP-Modelle in Elasticsearch importiert werden, die auf Hugging Face veröffentlicht wurden. Alle in diesem Artikel beschriebenen Befehlszeilenaufgaben setzen die Verwendung eines Python-Notebooks wie Google Colaboratory voraus. (Selbstverständlich können auch andere Arten von Terminals verwendet werden, z. B. ein Mac- oder ein Linux-Computer. In diesem Fall ignorieren Sie bitte das Ausrufezeichen ! am Beginn der Befehle.)
Installieren Sie als Erstes unabhängige Bibliotheken.
!pip install torch==1.13
!pip install transformers
!pip install sentence_transformers
!pip install fugashi
!pip install ipadic
!pip install unidic_liteFür ein Japanisch-Modell sind Fugashi, ipadic und unidic_lite erforderlich.
Wenn diese Bibliotheken installiert sind, kann auch Eland installiert werden. Für ein Japanisch-Modell ist mindestens Eland 8.9.0 erforderlich. Achten Sie daher auf die Versionsnummer.
!pip install elandNach Abschluss der Installation vergewissern Sie sich mit dem folgenden Befehl, dass Eland einsatzbereit ist:
!eland_import_hub_model -h
Importieren des NLP-Modells
Die Hauptmethode zum Aktivieren der Vektorsuche ist dieselbe wie die, die in diesem Artikel für Englisch verwendet wird. Wir werden hier noch einmal kurz darauf eingehen.
Wie oben erläutert, muss das entsprechende Machine-Learning-Modell in Elasticsearch importiert werden, um die NLP-Verarbeitung in Elasticsearch zu ermöglichen. Es ist möglich, mit PyTorch selbst ein Machine-Learning-Modell zu implementieren, aber auch dies erfordert hinreichende Kenntnisse über Machine Learning und die Verarbeitung natürlicher Sprache sowie eine entsprechende Rechenleistung für Machine Learning. Es gibt jedoch inzwischen mit Hugging Face ein Online-Repository, das von ML- und NLP-Expert:innen intensiv genutzt wird, und in diesem Repository werden viele Modelle veröffentlicht. In diesem Beispiel verwenden wir zum Implementieren der semantischen Suche ein Modell von Hugging Face.
Für den Anfang wählen wir ein Modell aus Hugging Face, das japanische Sätze in numerische Vektoren einbettet (vektorisiert). In diesem Artikel werden wir das unten verlinkte Modell verwenden:
Welche Aspekte sollten bei der Auswahl eines Modells für Japanisch in 8.9 beachtet werden?
Der erste wichtige Aspekt ist, dass nur der Modellalgorithmus BERT unterstützt wird. Prüfen Sie daher die Tags in Hugging Face und andere Angaben, um sich zu vergewissern, dass das gewünschte NLP-Modell ein BERT-trainiertes Modell ist.
Außerdem wird der eingegebene Text für BERT und andere NLP-Aufgaben „vortokenisiert“, d. h., der Text wird auf Wortebene in Einheiten unterteilt. In diesem Fall wird zum „Vortokenisieren“ unseres japanischen Texts ein morphologisches Analyseprogramm für Japanisch verwendet. Elasticsearch 8.9 unterstützt die morphologische Analyse mit MeCab. Öffnen Sie auf der Hugging Face-Seite mit den Modellen den Tab „Files and versions“ und sehen Sie sich den Inhalt der Datei tokenizer_config.json an. Kontrollieren Sie, dass für word_tokenizer_type der Wert mecab angegeben ist.
{
"do_lower_case": false,
"word_tokenizer_type": "mecab",
"subword_tokenizer_type": "wordpiece",
"mecab_kwargs": {
"mecab_dic": "unidic_lite"
}
}
Sollte das Modell, das Sie verwenden wollen, einen anderen word_tokenizer_type-Wert als mecab haben, unterstützt Elasticsearch dieses Modell gegenwärtig leider nicht. Wenn Sie Unterstützung für bestimmte Wort-Tokenizer-Typen (word_tokenizer_type) benötigen, können Sie uns das gern mitteilen.
Nachdem Sie sich für ein Modell entschieden haben, kann dieses mit denselben Schritten wie das Modell für Englisch importiert werden. Verwenden Sie zunächst eland_import_hub_model, um das Modell in Elasticsearch zu importieren. Informationen zur Verwendung von eland_import_hub_model finden Sie hier.
!eland_import_hub_model \
--url "https://your.elasticserach" \
--es-api-key "your_api_key" \
--hub-model-id cl-tohoku/bert-base-japanese-v2 \
--task-type text_embedding \
--start
Nach Abschluss des Imports wird das Modell in Kibana unter „Machine Learning“ > „Model Management“ > „Trained Models“ angezeigt. Öffnen Sie den Tab „Config“ und vergewissern Sie sich, dass für die Tokenisierung „bert_ja“ verwendet wird und das Modell korrekt für Japanisch eingerichtet ist.
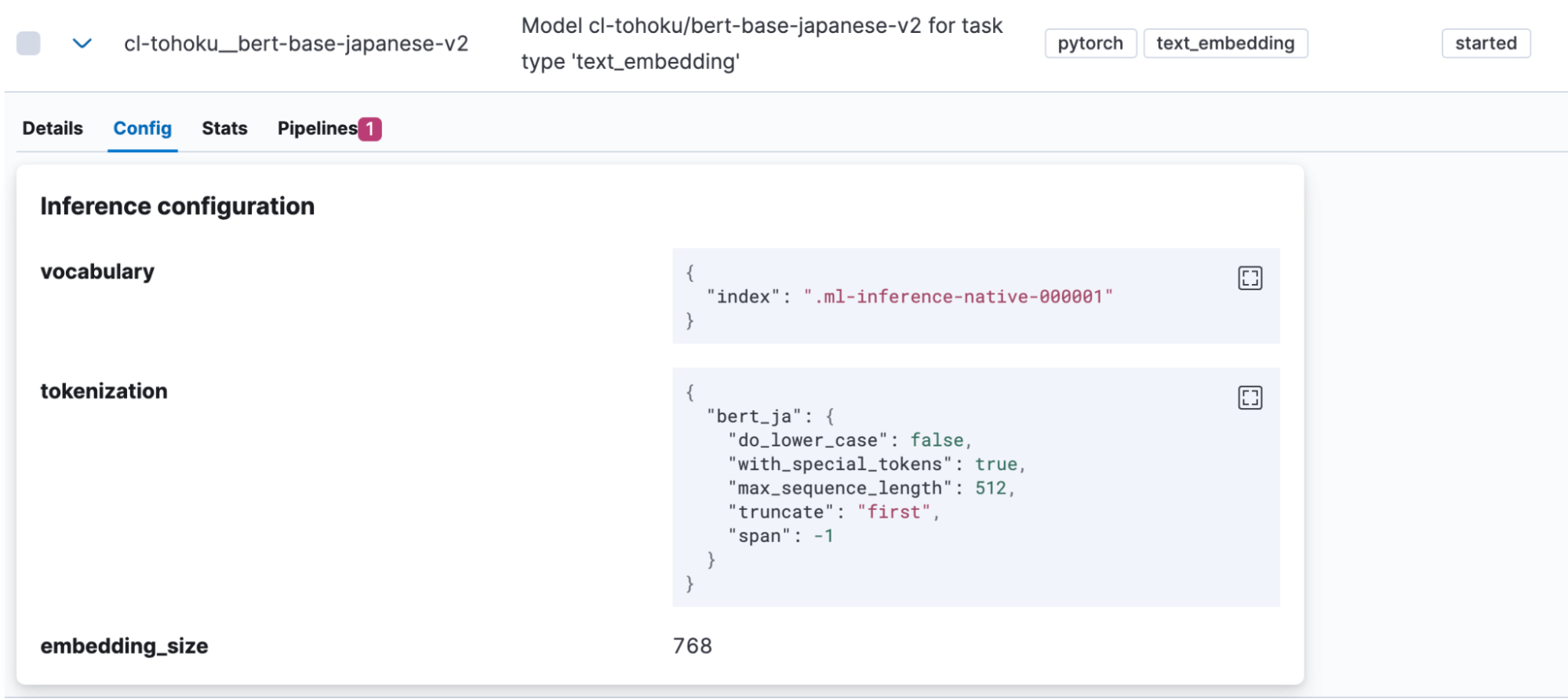
Wenn der Modell-Upload abgeschlossen ist, können wir das Modell ausprobieren. Klicken Sie in der Spalte „Actions“ auf eine Schaltfläche, um das Menü zu öffnen.
Wählen Sie „Test model“, geben Sie unter „Input text“ japanischen Text ein und klicken Sie auf die Schaltfläche „Test“.
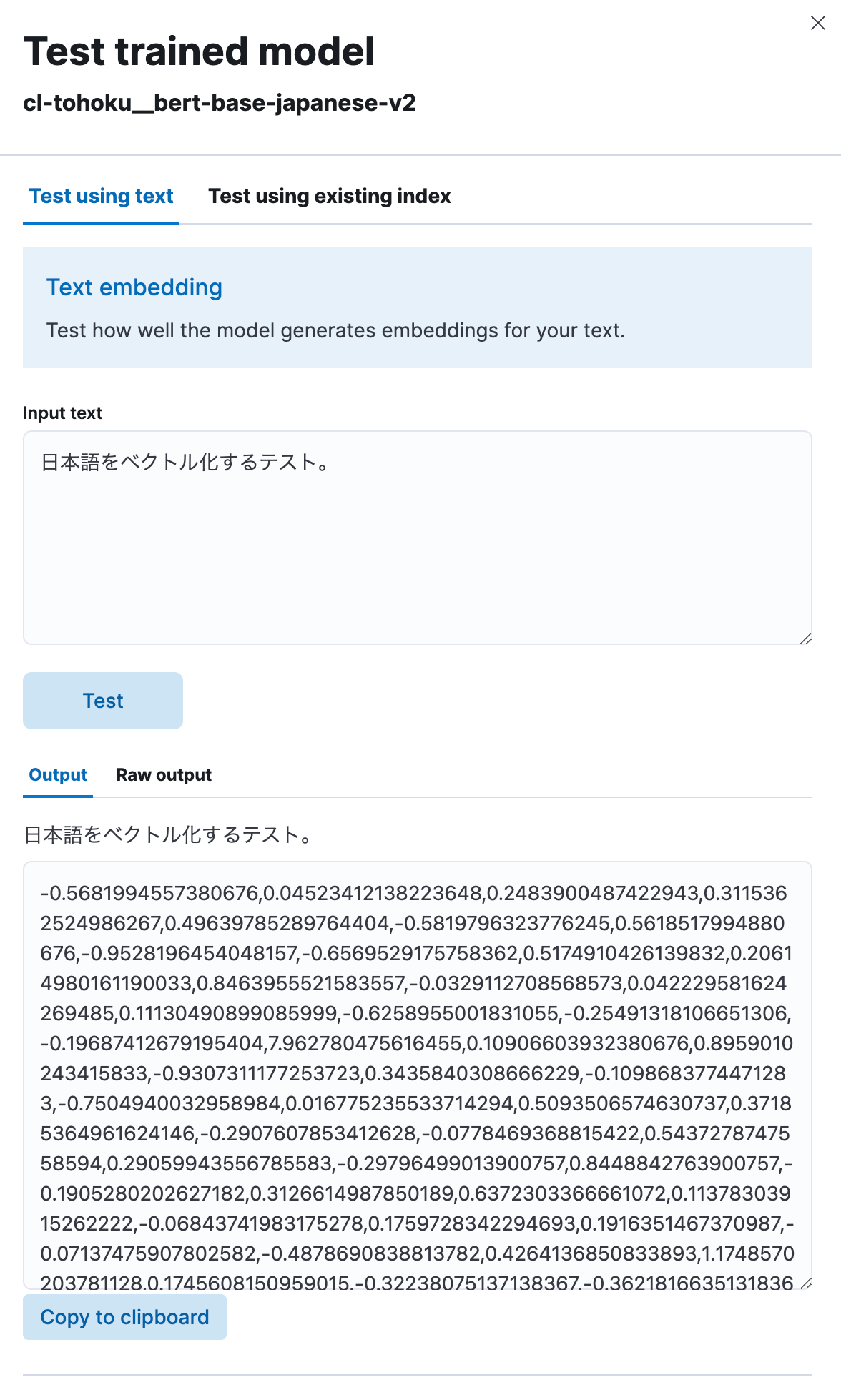
Wie zu sehen ist, hat das Modell den von Ihnen eingegebenen japanischen Text in eine numerische Zeichenfolge vektorisiert. Offenbar funktioniert also alles so, wie es soll.
Implementieren einer semantischen Suche mithilfe von Vektoreinbettungen
Nachdem wir nun das Modell hochgeladen haben, können wir jetzt die Funktion für die semantische Suche (Vektorsuche) in Elasticsearch implentieren.
Für die Durchführung einer Vektorsuche müssen zunächst die Vektorwerte indexiert werden, in die der ursprüngliche japanische Text eingebettet war. Dazu erstellen wir eine Pipeline, die einen Inferenzprozessor enthält, mit dem der japanische Text vektorisiert wird, bevor er mit dem vorhin hochgeladenen Modell in den Index überführt wird.
PUT _ingest/pipeline/japanese-text-embeddings
{
"description": "Text embedding pipeline",
"processors": [
{
"inference": {
"model_id": "cl-tohoku__bert-base-japanese-v2",
"target_field": "text_embedding",
"field_map": {
"title": "text_field"
}
}
}
],
"on_failure": [
{
"set": {
"description": "Index document to 'failed-<index>'",
"field": "_index",
"value": "failed-{{{_index}}}"
}
},
{
"set": {
"description": "Set error message",
"field": "ingest.failure",
"value": "{{_ingest.on_failure_message}}"
}
}
]
}
Bei Verwendung des Inferenzprozessors wird das in model_id angegebene Modell auf den Text in target_field angewendet (in diesem Fall title) und die entsprechende Ausgabe wird in target_field gespeichert. Außerdem erwartet jedes Modell für den Eingabewert für den Prozess ein anderes Feld (in diesem Fall text_field). Aus diesem Grund geben wir mit field_map die Entsprechung zwischen dem eigentlichen Eingabefeld für das Ziel des Prozesses und den vom ML-Modell erwarteten Feldnamen an.
Wenn die Pipeline fertig erstellt ist, kann sie für das Erstellen von Indizes verwendet werden. Da für das Speichern von Vektoren in diesen Indizes Felder benötigt werden, definieren wir die entsprechende Zuordnung. Im Beispiel unten ist das Feld text_embedding.predicted_value für die Aufnahme von 768-dimensionalen dense_vector-Daten eingerichtet. Da die Anzahl der Dimensionen modellabhängig ist, sehen Sie bitte auf der Hugging Face-Seite für das Modell (Wert von hidden_size in der Datei config.json des Modells) oder an anderer Stelle nach und legen Sie eine entsprechende Zahl fest.
PUT japanese-text-with-embeddings
{
"mappings": {
"properties": {
"text_embedding.predicted_value": {
"type": "dense_vector",
"dims": 768,
"index": true,
"similarity": "cosine"
}
}
}
}
Sollte es bereits einen Index geben, der die zu durchsuchenden japanischen Textdaten enthält, kann die Neuindexierungs-API verwendet werden. In diesem Beispiel befinden sich die ursprünglichen Textdaten im Index japanese‑text. Ein Dokument, das die Vektorisierung dieses Textes enthält, wird im Index japanese-text-embeddings registriert.
POST _reindex?wait_for_completion=false
{
"source": {
"index": "japanese-text"
},
"dest": {
"index": "japanese-text-with-embeddings",
"pipeline": "japanese-text-embeddings"
}
}
Alternativ kann ein Dokument zu Testzwecken auch direkt registriert werden, indem man eine Pipeline angibt, die wie unten dargestellt erstellt und im Index gespeichert wird.
POST japanese-text-with-embeddings/_doc?pipeline=japanese-text-embeddings
{
"title": "日本語のドキュメントをベクトル化してインデックスに登録する。"
}
Nachdem das vektorisierte Dokument registriert wurde, ist es nun möglich, eine Suche durchzuführen. Eine der verfügbaren Methoden, die auf Vektoren zurückgreift, ist die kNN-Suche (k-Nearest-Neighbor). Wir werden jetzt eine kNN-Vektorsuche mit der Option query_vector_builder in der Standard-API für die Suche (_search) durchführen. Bei Verwendung von query_vector_builder kann das in model_id angegebene Modell verwendet werden, um den Text in model_text in eine Suchanfrage zu konvertieren, die einen Vektor enthält, in den dieser Text eingebettet ist.
GET japanese-text-with-embeddings/_search
{
"knn": {
"field": "text_embedding.predicted_value",
"k": 10,
"num_candidates": 100,
"query_vector_builder": {
"text_embedding": {
"model_id": "cl-tohoku__bert-base-japanese-v2",
"model_text": "日本語でElasticsearchを検索したい"
}
}
}
}
Diese Suchanfrage erbringt ein Ergebnis der folgenden Art:
"hits": [
{
"_index": "japanese-text-with-embeddings",
"_id": "vOD6MIoBdRdLZd7EKaBy",
"_score": 0.82438844,
"_source": {
"title": "日本語のドキュメントをベクトル化してインデックスに登録する。",
"text_embedding": {
"predicted_value": [
-0.13586345314979553,
-0.6291824579238892,
0.32779985666275024,
0.36690405011177063,
(略、768次元のベクトルが表示される)
],
"model_id": "cl-tohoku__bert-base-japanese-v2"
}
}
}
]
Die Suche war also erfolgreich! Die Suche enthält auch Felder, in die japanischer Text eingebettet worden ist. In den meisten echten Anwendungsfällen ist es jedoch nicht notwendig, diesen Text in die Antwort aufzunehmen. In solchen Fällen sollten Sie den Parameter _source oder eine andere Methode verwenden, um diese Informationen aus der Antwort auszuschließen (oder eine entsprechende andere Maßnahme ergreifen).
Für die Feinjustierung der Suchrankings wurde die Funktion Reciprocal rank fusion (RRF) entwickelt, die die Ergebnisse von Vektorsuchen und Standard-Keyword-Suchen geschickt miteinander verbindet. Es empfiehlt sich, einen Blick auf diese Funktion zu werfen.
Damit schließen wir das Thema ab, wie sich mithilfe der Vektorsuche eine semantische Suche realisieren lässt. Die Einrichtung dieser Funktionalität mag zwar etwas aufwendiger sein als die Einrichtung einer Standard-Suche, und Sie müssen sich dabei möglicherweise mit speziellen Machine-Learning-Begriffe auseinandersetzen, aber wenn dies erst einmal geschafft ist, unterscheidet sich das eigentliche Suchen nicht wesentlich vom normalen Weg – Ausprobieren lohnt sich also.
Textklassifizierung (Sentimentanalyse)
Wir wissen jetzt, dass wir eine Vektorsuche mit kNN in Japanisch durchführen können. Sehen wir uns nun an, welche anderen NLP-Aufgaben sich auf die gleiche Weise erledigen lassen.
Die Textklassifizierung ist eine Aufgabe, bei der Texteingaben in verschiedene Kategorien eingeordnet werden. Für dieses Beispiel verwenden wir ein Sentimentanalysemodell, das auf Hugging Face bereitsteht und beurteilt, ob japanischer Text von einer positiven oder einer negativen Grundstimmung (Sentiment) geprägt ist (koheiduck/bert-japanese-finetuned-sentiment). Ein Blick auf dessen tokenizer_config.json-Datei zeigt, dass dieses Modell als word_tokenizer_type ebenfalls mecab verwendet. Das bedeutet, dass wir es mit „bert_ja“ von Elasticsearch verwenden können.
Wie oben importieren wir zuerst das Modell mit Eland in Elasticsearch.
!eland_import_hub_model \
--url "https://your.elasticserach" \
--es-api-key "your_api_key" \
--hub-model-id koheiduck/bert-japanese-finetuned-sentiment \
--task-type text_classification \
--start
Nach Abschluss des Imports wird das Modell in Kibana unter „Machine Learning“ > „Model Management“ > „Trained Models“ angezeigt.
In diesem Fall klicken wir im Kontextmenü in der Spalte „Actions“ auf „Test model“.
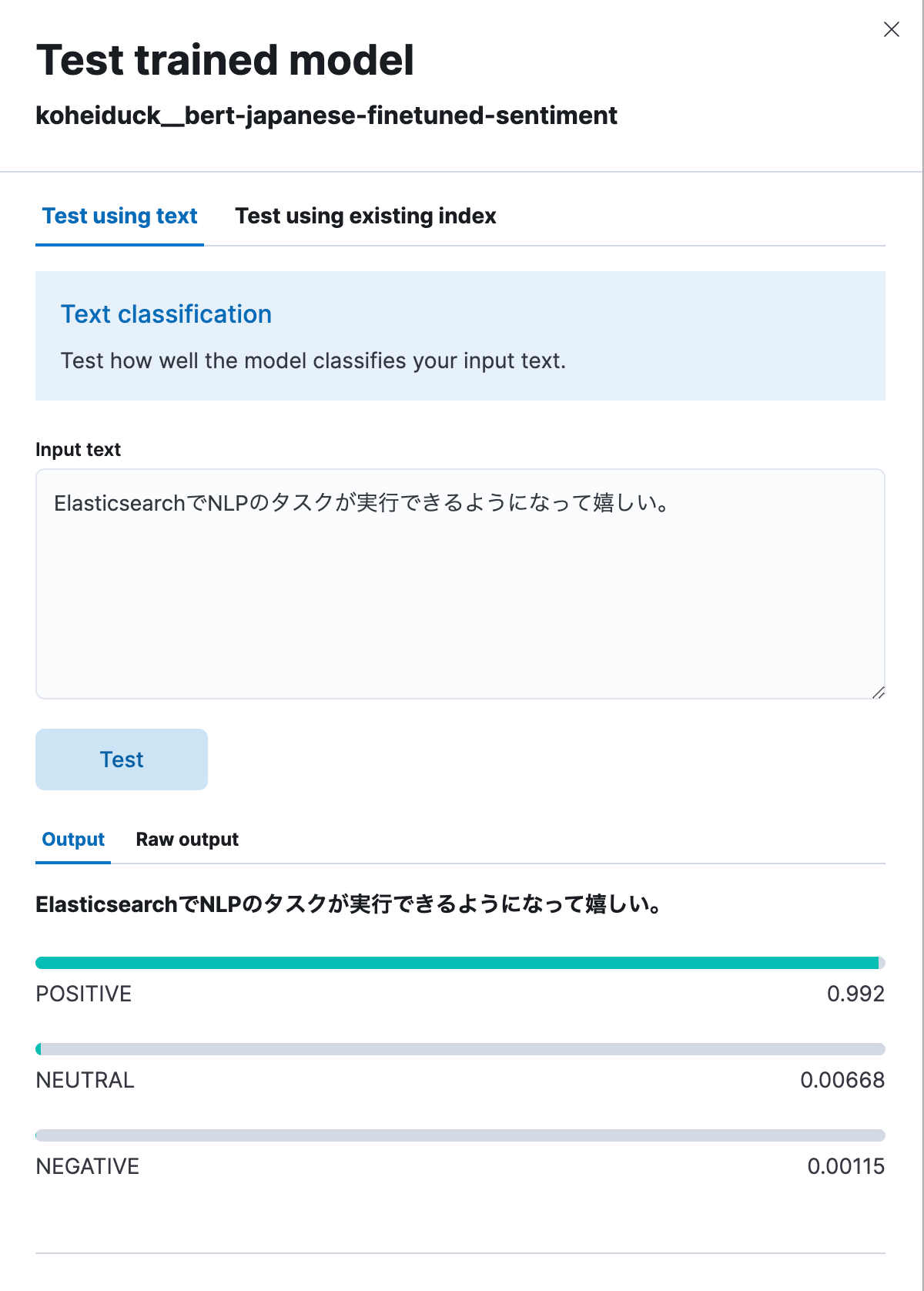
Wie vorhin erscheint daraufhin ein Dialog zum Ausprobieren. Geben Sie den zu klassifizierenden Text ein. Der Text wird jetzt einer der folgenden Klassifizierungen zugeordnet: POSITIVE, NEUTRAL und NEGATIVE. Lassen Sie uns das einmal mit dem folgenden Text ausprobieren, der übersetzt ungefähr Folgendes heißt: „Es ist schön, dass in Elasticsearch jetzt auch NLP-Aufgaben ausgeführt werden können.“ Wie unten zu sehen ist, wird dieser Text als 99,2 % positiv klassifiziert.
Im Folgenden machen wir dasselbe über die API.
POST _ml/trained_models/koheiduck__bert-japanese-finetuned-sentiment/_infer
{
"docs": [{"text_field": "ElasticsearchでNLPのタスクが実行できるようになって嬉しい。"}],
"inference_config": {
"text_classification": {
"num_top_classes": 3
}
}
}
Die Antwort sieht wie folgt aus:
{
"inference_results": [
{
"predicted_value": "POSITIVE",
"top_classes": [
{
"class_name": "POSITIVE",
"class_probability": 0.9921651090124636,
"class_score": 0.9921651090124636
},
{
"class_name": "NEUTRAL",
"class_probability": 0.006682728902566756,
"class_score": 0.006682728902566756
},
{
"class_name": "NEGATIVE",
"class_probability": 0.0011521620849697567,
"class_score": 0.0011521620849697567
}
],
"prediction_probability": 0.9921651090124636
}
]
}Da dieser Prozess auch mit dem Inferenzprozessor ausgeführt werden kann, ist es möglich, diese Analyseergebnisse anzuhängen, bevor der japanische Text indexiert wird. Wenn wir diesen Prozess auf den Text von Rezensionen zu bestimmten Produkten anwenden, kann uns das helfen, die Bewertungen der Nutzer:innen für diese Produkte in numerische Werte umzuwandeln.
Feedback
In Elasticsearch 8.9 befindet sich die Unterstützung von NLP-Modellen für Japanisch noch im Stadium einer technischen Vorschau. Wenn Sie Fehler finden oder Unterstützung für andere als BERT-Algorithmen oder andere als MeCab-Tokenizer usw. benötigen, melden Sie sich bitte bei Elastic®.
Der beste Weg, Feedback an Elastic zu senden, ist per GitHub Issues. Fügen Sie im elastic/elasticsearch-Repository unter „Issues“ das Tag :ml hinzu und formulieren Sie Ihr Anliegen. Das entsprechende Team wird sich dann darum kümmern.
Ich bin Consulting Architect für Elastic (und gehöre damit nicht zum Entwicklungsteam) und konnte dennoch als Außenstehender mit einem GitHub-Pull-Request erfolgreich anstoßen, dass auch Japanisch unterstützt wird. Wenn Sie Entwickler:in sind und ein Feature haben, das Sie gern für einen bestimmten Anwendungsfall hinzugefügt haben möchten, versuchen Sie es doch auch, wie ich es getan habe.
Fazit
Elastic investiert zur Zeit viele Ressourcen in die Implementierung von NLP-Funktionen mit Machine Learning in seine Suchfunktionen, und es gibt immer mehr solcher Funktionen, die in Elasticsearch ausgeführt werden können. Die meisten Features unterstützen bei Einführung jedoch zuerst Englisch und nur in begrenztem Umfang auch andere Sprachen.
Wir sind aber sehr froh, dass jetzt auch Japanisch unterstützt wird, und hoffen, dass diese neuen Elasticsearch-Features Ihnen helfen, Ihre Suchen und deren Ergebnisse sinnvoller zu machen.
Die Entscheidung über die Veröffentlichung von Funktionen oder Leistungsmerkmalen, die in diesem Blogpost beschrieben werden, oder über den Zeitpunkt ihrer Veröffentlichung liegt allein bei Elastic. Es ist möglich, dass nicht bereits verfügbare Funktionen oder Leistungsmerkmale nicht rechtzeitig oder überhaupt nicht veröffentlicht werden.
In diesem Blogpost haben wir möglicherweise generative KI-Tools von Drittanbietern verwendet oder darauf Bezug genommen, die von ihren jeweiligen Eigentümern betrieben werden. Elastic hat keine Kontrolle über die Drittanbieter-Tools und übernimmt keine Verantwortung oder Haftung für ihre Inhalte, ihren Betrieb oder ihre Anwendung sowie für etwaige Verluste oder Schäden, die sich aus Ihrer Anwendung solcher Tools ergeben. Gehen Sie vorsichtig vor, wenn Sie KI-Tools mit persönlichen, sensiblen oder vertraulichen Daten verwenden. Alle Daten, die Sie eingeben, können für das Training von KI oder andere Zwecke verwendet werden. Es gibt keine Garantie dafür, dass Informationen, die Sie bereitstellen, sicher oder vertraulich behandelt werden. Setzen Sie sich vor Gebrauch mit den Datenschutzpraktiken und den Nutzungsbedingungen generativer KI-Tools auseinander.
Elastic, Elasticsearch, ESRE, Elasticsearch Relevance Engine und zugehörige Marken, Waren- und Dienstleistungszeichen sind Marken oder eingetragene Marken von Elastic N.V. in den USA und anderen Ländern. Alle weiteren Marken- oder Warenzeichen sind eingetragene Marken oder eingetragene Warenzeichen der jeweiligen Eigentümer.
Teilen
- Share on Twitter
Auf Twitter teilen
- Share on LinkedIn
Auf LinkedIn teilen
- Share on Facebook
Auf Facebook teilen
- Share by Email
Per E-Mail teilen
- Print this page
Drucken