Bereitstellen von NLP: Erkennung benannter Entitäten (Named Entity Recognition, NER) – Beispiel


 Share on Twitter
Share on TwitterAuf Twitter teilen

 Share on LinkedIn
Share on LinkedInAuf LinkedIn teilen

 Share on Facebook
Share on FacebookAuf Facebook teilen

 Share by Email
Share by EmailPer E-Mail teilen

 Print this page
Print this pageDrucken
Im Rahmen unserer mehrteiligen Blogreihe zur Verarbeitung natürlicher Sprache (NLP) zeigen wir am Beispiel eines NLP-Modells mit Erkennung benannter Entitäten (NER), wie Sie vordefinierte Kategorien von Entitäten in unstrukturierten Textfeldern lokalisieren und extrahieren können. Wir demonstrieren an einem öffentlich verfügbaren Modell, wie Sie dieses Modell in Elasticsearch bereitstellen, benannte Entitäten im Text mit der neuen _infer-API finden und das NER-Modell in einer Ingestions-Pipeline verwenden können, um Entitäten beim Ingestieren von Dokumenten nach Elasticsearch zu extrahieren.
NER-Modelle sind hilfreich, um mit natürlicher Sprachverarbeitung Entitäten wie Personen, Orte und Organisationen aus Volltextfeldern zu extrahieren.
In diesem Beispiel verarbeiten wir Absätze des Buchs Les Misérables mit einem NER-Modell, um Personen und Orte aus dem Text zu extrahieren und die Beziehungen zwischen ihnen zu visualisieren.
NER-Modell in Elasticsearch bereitstellen
Zunächst müssen wir ein NER-Modell auswählen, mit dem wir die Namen der Personen und Orte aus Textfeldern extrahieren können. Glücklicherweise haben wir auf Hugging Face einige NER-Modelle zur Auswahl, und in der Elastic-Dokumentation finden wir ein NER-Modell von Elastic, das nicht zwischen Groß- und Kleinschreibung unterscheidet und das wir ausprobieren können.
Wir wählen also das gewünschte NER-Modell aus und installieren es mit Eland. In diesem Beispiel führen wir den Eland-Befehl in einem Docker-Image aus. Zunächst müssen wir jedoch das Docker-Image erstellen, indem wir das Eland-GitHub-Repository klonen und ein Docker-Image von Eland auf unserem System erstellen:
git clone git@github.com:elastic/eland.git
cd eland
docker build -t elastic/eland .
Sobald unser Eland-Docker-Client einsatzbereit ist, können wir den Befehl eland_import_hub_model in unserem neuen Docker-Image wie folgt ausführen:
docker run -it --rm elastic/eland \
eland_import_hub_model \
--url $ELASTICSEARCH_URL \
--hub-model-id elastic/distilbert-base-uncased-finetuned-conll03-english \
--task-type ner \
--startErsetzen Sie dabei ELASTICSEACH_URL durch die URL für Ihren Elasticsearch-Cluster. Für die Authentifizierung müssen Sie Benutzername und Passwort eines Administrators in der URL im Format https://Benutzername:Passwort@Host:Port angeben.
Da wir die Option --start am Ende des Eland-Importbefehls angegeben haben, stellt Elasticsearch das Modell auf allen verfügbaren Machine-Learning-Knoten bereit und lädt das Modell in den Arbeitsspeicher. Wenn wir mehrere Modelle hätten und eines davon auswählen wollten, könnten wir die Kibana-Benutzeroberfläche „Machine Learning > Modellverwaltung“ verwenden, um Modelle einzeln zu starten oder zu beenden.
NER-Modell testen
Wir können bereitgestellte Modelle mit der neuen _infer-API testen. Als Eingabe verwenden wir die Zeichenfolge, die wir analysieren möchten. In der folgenden Anfrage ist text_field der Name des Felds, in dem das Modell die Eingabe erwartet. Dies ist in der Modellkonfiguration definiert. Wenn das Modell mit Eland hochgeladen wurde, verwendet es standardmäßig text_field als Eingabefeld.
Testen Sie das folgende Beispiel in der Kibana Dev Tools-Konsole:
POST _ml/trained_models/elastic__distilbert-base-uncased-finetuned-conll03-english/deployment/_infer
{
"docs": [
{
"text_field": "Hi my name is Josh and I live in Berlin"
}
]
}
Das Modell hat zwei Entitäten gefunden: die Person „Josh“ und den Ort „Berlin“.
{
"predicted_value" : "Hi my name is [Josh](PER&Josh) and I live in [Berlin](LOC&Berlin)",
"entities" : {
"entity" : "Josh",
"class_name" : "PER",
"class_probability" : 0.9977303419824,
"start_pos" : 14,
"end_pos" : 18
},
{
"entity" : "Berlin",
"class_name" : "LOC",
"class_probability" : 0.9992474323902818,
"start_pos" : 33,
"end_pos" : 39
}
]
}
predicted_value ist die Eingabezeichenfolge im Format Annotated Text, class_name ist die vermutete Klasse und class_probability gibt die Zuverlässigkeit der Vermutung an. start_pos und end_pos sind die Positionen der Anfangs- und Endzeichen der identifizierten Entität.
NER-Modell zu einer Inferenz-Ingestions-Pipeline hinzufügen
Die _infer-API ist ein spannender und einfacher Einstiegspunkt, akzeptiert jedoch nur eine einzelne Eingabe, und die erkannten Entitäten werden nicht in Elasticsearch gespeichert. Als Alternative bietet sich die massenhafte Inferenz von Dokumenten beim Ingestieren mit einer Ingestions-Pipeline und dem Inferenz-Prozessor an.
Sie können die Ingestions-Pipeline in der Stack-Management-Benutzeroberfläche definieren oder in der Kibana-Konsole konfigurieren. Das folgende Beispiel verwendet mehrere Ingestions-Prozessoren:
PUT _ingest/pipeline/ner
{
"description": "NER pipeline",
"processors": [
{
"inference": {
"model_id": "elastic__distilbert-base-uncased-finetuned-conll03-english",
"target_field": "ml.ner",
"field_map": {
"paragraph": "text_field"
}
}
},
{
"script": {
"lang": "painless",
"if": "return ctx['ml']['ner'].containsKey('entities')",
"source": "Map tags = new HashMap(); for (item in ctx['ml']['ner']['entities']) { if (!tags.containsKey(item.class_name)) tags[item.class_name] = new HashSet(); tags[item.class_name].add(item.entity);} ctx['tags'] = tags;"
}
}
],
"on_failure": [
{
"set": {
"description": "Index document to 'failed-<index>'",
"field": "_index",
"value": "failed-{{{ _index }}}"
}
},
{
"set": {
"description": "Set error message",
"field": "ingest.failure",
"value": "{{_ingest.on_failure_message}}"
}
}
]
}
Wir beginnen mit dem inference-Prozessor. field_map hat das Ziel, paragraph (das zu analysierende Feld in den Quelldokumenten) zu text_field (das Feld, für dessen Verwendung das Modell konfiguriert wurde) zuzuordnen. target_field ist das Feld, in das die Inferenz-Ergebnisse geschrieben werden.
Der script-Prozessor extrahiert die Entitäten und gruppiert sie nach Typ. Das Ergebnis ist eine Liste der Personen, Orte und Organisationen, die im Eingangstext erkannt wurden. Mit diesem hilfreichen Skript können Sie Visualisierungen aus den generierten Feldern erstellen.
Die on_failure-Klausel dient zum Abfangen von Fehlern. Sie definiert zwei Aktionen. Zunächst legt sie einen neuen Wert für das _index-Metafeld fest, und das Dokument wird dort gespeichert. Außerdem wird die Fehlermeldung in das neue Feld ingest.failure geschrieben. Die Inferenz kann aus verschiedenen, leicht behebbaren Gründen fehlschlagen. Möglicherweise wurde das Modell nicht bereitgestellt, oder in einigen Quelldokumenten fehlt das Eingabefeld. Daher leiten wir fehlgeschlagene Dokumente an einen anderen Index weiter und definieren die Fehlermeldung, um die fehlgeschlagenen Inferenzen nicht zu verlieren und später überprüfen zu können. Sobald die Fehler behoben wurden, können wir den fehlerhaften Index neu indexieren, um die entsprechenden Anfragen wiederherzustellen.
Textfelder für Inferenz auswählen
NER kann auf viele verschiedene Datensätze angewendet werden. Für dieses Beispiel habe ich den Klassiker Les Misérables von Victor Hugo aus dem Jahr 1862 ausgewählt. Sie können die Absätze von Les Misérables aus unserer JSON-Beispieldatei mit dem Kibana-Dateiupload hochladen. Der Text ist in 14.021 JSON-Dokumente unterteilt, die jeweils einen einzelnen Absatz enthalten. Nehmen wir einen zufälligen Absatz als Beispiel:
{
"paragraph": "Father Gillenormand did not do it intentionally, but inattention to proper names was an aristocratic habit of his.",
"line": 12700
}
Nachdem der Absatz durch die NER-Pipeline ingestiert wurde, wird das resultierende Dokument in Elasticsearch gespeichert und mit einer identifizierten Person markiert.
{
"paragraph": "Father Gillenormand did not do it intentionally, but inattention to proper names was an aristocratic habit of his.",
"@timestamp": "2020-01-01T17:38:25",
"line": 12700,
"ml": {
"ner": {
"predicted_value": "Father [Gillenormand](PER&Gillenormand) did not do it intentionally, but inattention to proper names was an aristocratic habit of his.",
"entities": [{
"entity": "Gillenormand",
"class_name": "PER",
"class_probability": 0.9806354093873283,
"start_pos": 7,
"end_pos": 19
}],
"model_id": "elastic__distilbert-base-cased-finetuned-conll03-english"
}
},
"tags": {
"PER": [
"Gillenormand"
]
}
}
Eine Tag-Cloud ist eine Visualisierungsart, die Wörter nach deren Häufigkeit skaliert, und eignet sich perfekt zum Anzeigen der in Les Misérables gefundenen Entitäten. Öffnen Sie Kibana, erstellen Sie eine neue aggregationsbasierte Visualisierung und wählen Sie die Tag-Cloud aus. Wählen Sie den Index aus, der die NER-Ergebnisse enthält, und fügen Sie eine Begriffs-Aggregation für das Feld tags.PER.keyword hinzu.
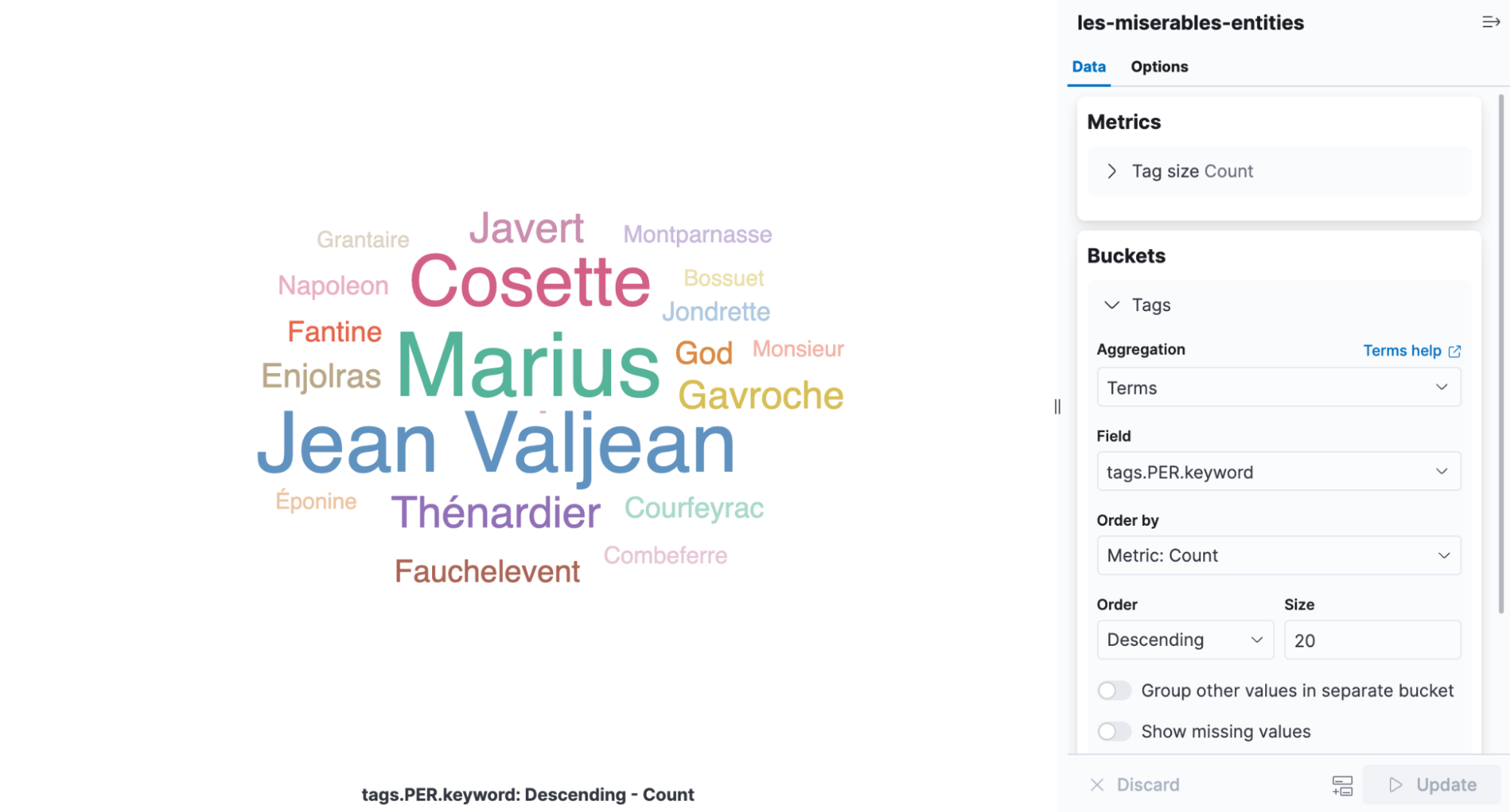
In der Visualisierung erkennen wir sofort, dass Cosette, Marius und Jean Valjean die am häufigsten erwähnten Personen im Buch sind.
Feinabstimmung des Deployments
Wenn Sie zur Modellverwaltung zurückkehren, finden Sie unter „Deployment stats“ den Wert Avg Inference Time. Dies ist die vom nativen Prozess gemessene Inferenzdauer für eine einzelne Anforderung. Beim Starten eines Deployments können wir mit zwei Parametern festlegen, wie die CPU-Ressourcen genutzt werden: inference_threads und model_threads.
inference_threads ist die Anzahl der Threads, mit denen das Modell pro Anforderung ausgeführt wird. Wenn wir inference_threads erhöhen, nimmt die Inferenzdauer ab. Mit model_threads können wir festlegen, wie viele Anforderungen parallel verarbeitet werden. Diese Einstellung reduziert zwar nicht die durchschnittliche Inferenzdauer, erhöht jedoch den Durchsatz.
Im Allgemeinen können wir inference_threads erhöhen, um die Latenz zu verbessern, und mit model_threads können wir den Durchsatz steigern. Beide Einstellungen verwenden standardmäßig einen Thread. Wir können die Performance also deutlich steigern, indem wir diese Werte erhöhen. Dieser Effekt lässt sich am NER-Modell gut beobachten.
Um eine der Thread-Einstellungen zu ändern, müssen wir das Deployment beenden und neu starten. Wir übergeben den Parameter ?force=true an die stop-API, weil das Deployment von einer Ingestions-Pipeline referenziert wird, die das Beenden normalerweise verhindern würde.
POST _ml/trained_models/elastic__distilbert-base-uncased-finetuned-conll03-english/deployment/_stop?force=true
Nach dem Neustart verwenden wir vier Inferenz-Threads. Die durchschnittliche Inferenzdauer wird zurückgesetzt, wenn wir das Deployment neu starten.
POST _ml/trained_models/elastic__distilbert-base-uncased-finetuned-conll03-english/deployment/_start?inference_threads=4Beim Verarbeiten der Absätze von Les Misérables ist die durchschnittliche Inferenzdauer jetzt auf 55,84 ms pro Anfrage gesunken, im Vergleich zu 173,86 ms mit einem einzigen Thread.
Mehr erfahren und selbst ausprobieren
NER ist nur eine der NLP-Aufgaben, die Sie jederzeit selbst ausprobieren können. Textklassifizierung, Zero-Shot-Klassifizierung und Texteinbettung sind ebenfalls verfügbar. Weitere Beispiele finden Sie in der NLP-Dokumentation zusammen mit einer keinesfalls vollständigen Liste der Modelle, die im Elastic Stack bereitgestellt werden können.
NLP ist ein wichtiges neues Feature im Elastic Stack 8.0 mit einer spannenden Roadmap. Entdecken Sie neue Features und bleiben Sie bei den neuesten Entwicklungen auf dem Laufenden – mit einem eigenen Cluster in Elastic Cloud. Wenn Sie selbst mit den Beispielen in diesem Blogpost experimentieren möchten, probieren Sie Elastic Cloud 14 Tage kostenlos aus.
Mehr zu NLP finden Sie in den folgenden Blogposts:
Teilen
- Share on Twitter
Auf Twitter teilen
- Share on LinkedIn
Auf LinkedIn teilen
- Share on Facebook
Auf Facebook teilen
- Share by Email
Per E-Mail teilen
- Print this page
Drucken