Monitoring von containerisiertem Kafka mit Elastic Observability
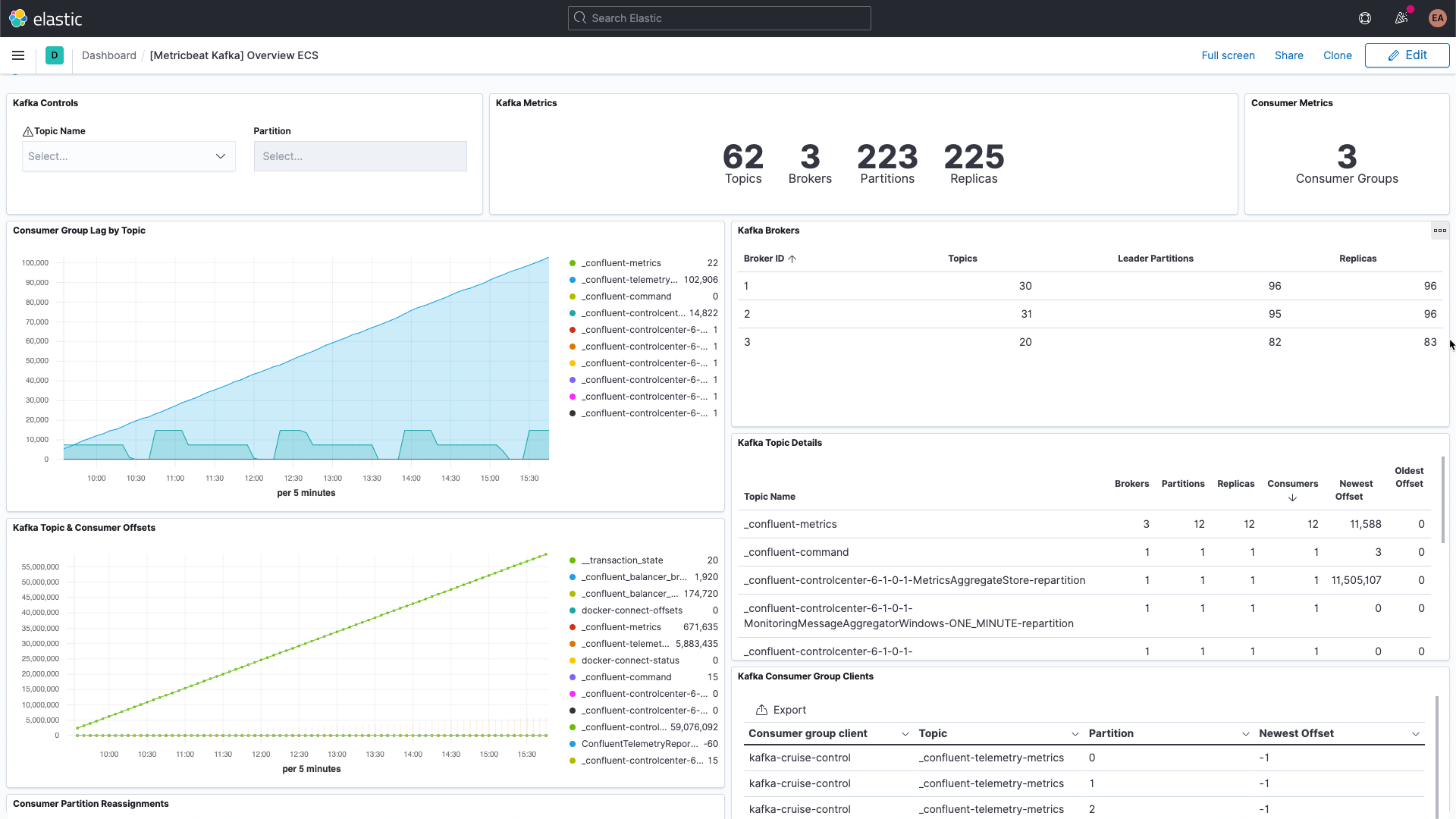
Kafka ist eine verteilte, hochverfügbare Ereignis-Streaming-Plattform, die sowohl auf einem Bare-Metal-Server als auch virtualisiert, containerisiert oder als verwalteter Dienst ausgeführt werden kann. Es handelt sich hierbei um ein Publish/Subscribe-System (Pub/Sub-System), das einen Broker bereitstellt, der die Verteilung der Ereignisse übernimmt. Die Rolle des „Publishers“ übernehmen dabei sogenannte Producer, die Ereignisse an sogenannte Topics senden, die von Consumern (die „Subscriber“) abonniert werden können. Sobald ein neues Ereignis an ein Topic gesendet wird, erhalten die Consumer, die dieses Topic abonniert haben, eine entsprechende Benachrichtigung. Auf diese Weise können mehrere Clients über Aktivitäten informiert werden, ohne dass der Producer wissen muss, wer oder was die von ihm gesendeten Ereignisse konsumiert. So kann zum Beispiel ein Webshop beim Eintreffen einer neuen Bestellung ein Ereignis mit den Details der Bestellung veröffentlichen. Dieses kann dann von Consumern im Lager genutzt werden, um die entsprechenden Artikel aus den Regalen zu holen, während Consumer im Versand anhand dieser Informationen ein Versandetikett ausdrucken können – denkbar wären auch beliebige andere Anwendungsgebiete. Je nachdem, wie Sie Consumer-Gruppen und Partitionen konfigurieren, können Sie steuern, welche Consumer neue Nachrichten erhalten.
Kafka wird in der Regel zusammen mit ZooKeeper bereitgestellt, das die Speicherung der Konfigurationsinformationen, wie Topics, Partitionen und Replikats-/Redundanzinformationen, übernimmt. Beim Monitoring von Kafka-Clustern müssen unbedingt auch die zugehörigen ZooKeeper-Instanzen überwacht werden – wenn es bei ZooKeeper Probleme gibt, übertragen sie sich unweigerlich auf den Kafka-Cluster.
Es gibt viele Möglichkeiten, wie Kafka zusätzlich zum Elastic Stack genutzt werden kann. Sie können Metricbeat oder Filebeat so konfigurieren, dass Daten an Kafka-Topics gesendet werden, Sie können Daten aus Kafka an Logstash oder aus Logstash an Kafka senden oder Sie können mithilfe von Elastic Observability Kafka und ZooKeeper überwachen, um Ihren Cluster stets im Blick zu behalten. Genau darum wird es in diesem Blogpost gehen. Erinnern Sie sich noch an die „Bestellungsdetails“-Ereignisse, die wir oben erwähnt haben? Mithilfe des Kafka-Input-Plugins kann auch Logstash diese Ereignisse abonnieren und Ihrem Elasticsearch-Cluster hinzufügen. Durch Hinzufügen von Geschäfts- oder beliebigen anderen Daten, die Sie für das Verständnis der Vorgänge in Ihrer Umgebung benötigen, erhöhen Sie die Observability Ihrer Systeme.
Worauf ist beim Kafka-Monitoring zu achten?
Bei Kafka gibt es mehrere sich bewegende Teile. Dazu gehören der Dienst selbst, der in der Regel aus mehreren Brokern und ZooKeeper-Instanzen besteht, und die Clients, die Kafka nutzen – die Producer und die Consumer. Kafka stellt verschiedene Arten von Metriken bereit, einige davon über die Broker selbst, andere über JMX. Vom Broker kommen die Metriken für die Partitionen und Consumer-Gruppen. Mit Partitionen können Sie Nachrichten auf mehrere Broker verteilen und so für eine parallele Verarbeitung sorgen. Consumer erhalten Nachrichten von einer einzelnen Topic-Partition; sie können gruppiert werden, um alle Nachrichten für ein Topic zu erhalten. Diese Consumer-Gruppen erlauben eine Verteilung der Arbeitslast.
Jede Kafka-Nachricht ist mit einem Offset versehen. Dabei handelt es sich um eine Kennung, die angibt, wo sich die jeweilige Nachricht in der Nachrichtenabfolge befindet. Jede Nachricht, die die Producer einem Topic hinzufügen, erhält einen neuen Offset-Wert. Der neueste Offset in einer Partition zeigt die letzte Kennung (ID). Consumer erhalten die Nachrichten von den Topics, und der Unterschied zwischen dem neuesten Offset und dem Offset, den der Consumer erhält, wird als Consumer-Lag bezeichnet. Die Consumer liegen immer etwas hinter den Producern zurück. Wenn aber das Consumer-Lag immer größer wird, ist dies ein Hinweis darauf, dass wahrscheinlich weitere Consumer benötigt werden, damit die Arbeitslast auch zukünftig bewältigt werden kann.
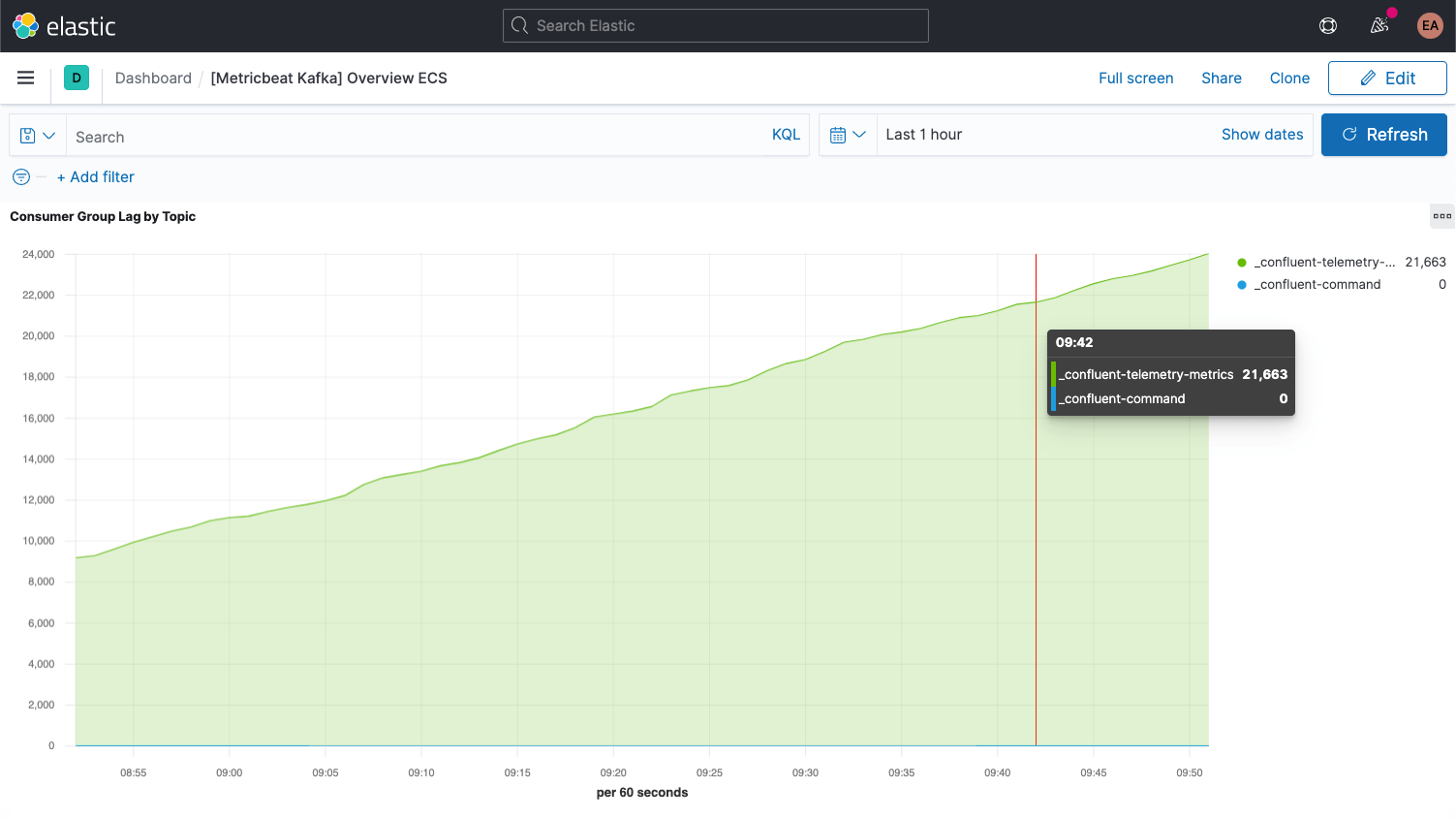
Beim Blick auf Metriken für die Topics selbst ist es wichtig, nach Topics Ausschau zu halten, die von keinem Consumer abonniert wurden. Dies kann darauf hindeuten, dass etwas, was eigentlich laufen sollte, nicht läuft.
Wenn wir dann alles fertig eingerichtet haben, werden wir uns mit einigen weiteren wichtigen Metriken für die Broker beschäftigen.
Einrichten von Kafka und ZooKeeper
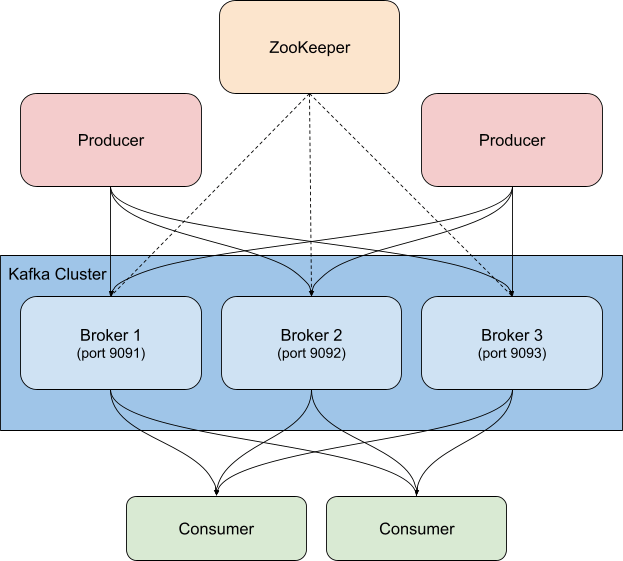
In unserem Beispiel haben wir es mit einem containerisierten Kafka-Cluster zu tun, der auf der Confluent-Plattform basiert. Es kommen drei Kafka-Broker (cp-server-Images) sowie eine einzelne ZooKeeper-Instanz zum Einsatz. In der Praxis benötigen Sie wahrscheinlich auch eine robustere, hochverfügbare Konfiguration für ZooKeeper.
Ich habe deren Konfiguration geklont und bin ins Verzeichnis cp-all-in-one gewechselt:
git clone https://github.com/confluentinc/cp-all-in-one.git cd cp-all-in-one
Alles, was in diesem Blogpost jetzt noch kommt, erfolgt von diesem Verzeichnis cp-all-in-one aus.
In meiner Konfiguration habe ich ein wenig an den Ports herumgeschraubt, damit klarer wird, welcher Port zu welchem Broker gehört (sie brauchen unterschiedliche Ports, weil jeder Port gegenüber dem Host exponiert ist). Das heißt konkret, dass zum Beispiel broker3 zum Port 9093 gehört. Aus Konsistenzgründen habe ich auch den Namen des ersten Brokers in broker1 geändert. Die vollständige Datei vor der Instrumentierung finden Sie in meinem GitHub-Fork des offiziellen Repository.
Die Konfiguration für broker1 nach der Portanpassung sieht wie folgt aus:
broker1:
image: confluentinc/cp-server:6.1.0
hostname: broker1
container_name: broker1
depends_on:
- zookeeper
ports:
- "9091:9091"
- "9101:9101"
environment:
KAFKA_BROKER_ID: 1
KAFKA_ZOOKEEPER_CONNECT: 'zookeeper:2181'
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: PLAINTEXT:PLAINTEXT,PLAINTEXT_HOST:PLAINTEXT
KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://broker1:29092,PLAINTEXT_HOST://broker1:9091
KAFKA_METRIC_REPORTERS: io.confluent.metrics.reporter.ConfluentMetricsReporter
KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 1
KAFKA_GROUP_INITIAL_REBALANCE_DELAY_MS: 0
KAFKA_CONFLUENT_LICENSE_TOPIC_REPLICATION_FACTOR: 1
KAFKA_CONFLUENT_BALANCER_TOPIC_REPLICATION_FACTOR: 1
KAFKA_TRANSACTION_STATE_LOG_MIN_ISR: 1
KAFKA_TRANSACTION_STATE_LOG_REPLICATION_FACTOR: 1
KAFKA_JMX_PORT: 9101
KAFKA_JMX_HOSTNAME: localhost
KAFKA_CONFLUENT_SCHEMA_REGISTRY_URL: http://schema-registry:8081
CONFLUENT_METRICS_REPORTER_BOOTSTRAP_SERVERS: broker1:29092
CONFLUENT_METRICS_REPORTER_TOPIC_REPLICAS: 1
CONFLUENT_METRICS_ENABLE: 'true'
CONFLUENT_SUPPORT_CUSTOMER_ID: 'anonymous'
Wie zu sehen ist, habe ich auch die Hostnamen von broker in broker1 geändert. Natürlich werden auch alle anderen Konfigurationsblöcke in der Datei docker-compose.yml, die auf broker verweisen, entsprechend geändert, damit alle drei Knoten unseres Clusters berücksichtigt werden. Das Confluent-Control-Center hängt damit von allen drei Brokern ab:
control-center:
image: confluentinc/cp-enterprise-control-center:6.1.0
hostname: control-center
container_name: control-center
depends_on:
- broker1
- broker2
- broker3
- schema-registry
- connect
- ksqldb-server
(...)
Erfassen von Logdaten und Metriken
Meine Kafka- und ZooKeeper-Dienste werden in Containern ausgeführt, anfänglich mit drei Brokern. Damit ich das Ganze später problemlos nach oben oder unten skalieren oder die ZooKeeper-Seite robuster gestalten kann, um die Sache dynamisch zu halten, möchte ich vermeiden, dass ich mein Monitoring komplett umkonfigurieren und von vorn starten muss. Zu diesem Zweck verlege ich auch das Monitoring in Docker-Container, wie zuvor schon den Kafka-Cluster, und nutze die Elastic-Beats-Funktion „hinweisbasiertes Autodiscover“.
Hinweisbasiertes Autodiscover
Für das Monitoring benötigen wir Logdaten und Metriken von unseren Kafka-Brokern und von der ZooKeeper-Instanz. Für die Metriken nutzen wir Metricbeat und für die Logdaten Filebeat; beide Beats werden in Containern ausgeführt. Um den Prozess in Gang zu bringen, müssen wir die jeweiligen Docker-Konfigurationsdateien, metricbeat.docker.yml und filebeat.docker.yml, herunterladen. Ich werde diese Monitoring-Daten an mein Elastic Observability-Deployment auf dem Elasticsearch Service auf Elastic Cloud senden (wenn Sie es mir gleichtun möchten, können Sie Elastic Cloud kostenlos ausprobieren). Wer seinen Cluster lieber selbst verwalten möchte, kann den Elastic Stack kostenlos herunterladen und ihn lokal ausführen. Ich zeige für beide Szenarios, wie es geht.
Ganz gleich, ob Sie ein Deployment auf Elastic Cloud verwenden oder einen selbstverwalteten Cluster haben – Sie müssen über die Kibana- und die Elasticsearch-URL angeben, wo sich der Cluster befindet, und Sie müssen die Anmeldeinformationen für den Cluster bereitstellen. Über den Kibana-Endpoint können wir Standard-Dashboards und Konfigurationsinformationen laden, und Elasticsearch ist das Ziel für die Daten, die die Beats senden. Bei Elastic Cloud fasst die Cloud-ID die Endpoint-Informationen zusammen:
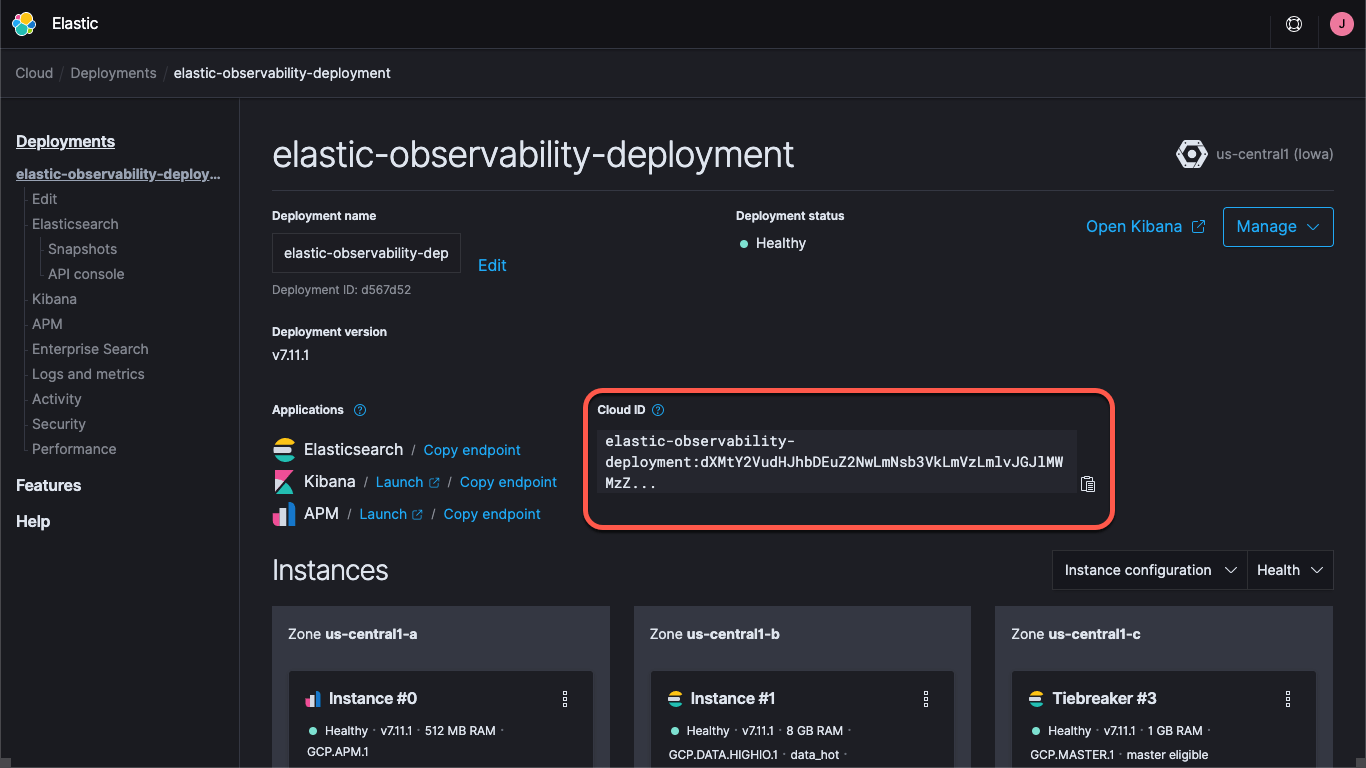
Wenn Sie ein Deployment auf Elastic Cloud erstellen, erhalten Sie ein Passwort für den Nutzer elastic. Um es einfach zu halten, verwende ich in diesem Blogpost diese Anmeldeinformationen. Sie sollten aber unbedingt API-Schlüssel oder Nutzer und Rollen mit nur so vielen Berechtigungen wie für die Aufgabe erforderlich erstellen.
Wir laden jetzt die Standard-Dashboards für Metricbeat und für Filebeat. Dies muss nur einmal gemacht werden und die Vorgehensweise ist bei beiden Beats im Prinzip dieselbe. Zunächst laden wir die Metricbeat-Dashboards:
docker run --rm \
--name=metricbeat-setup \
--volume="$(pwd)/metricbeat.docker.yml:/usr/share/metricbeat/metricbeat.yml:ro" \
docker.elastic.co/beats/metricbeat:7.11.1 \
-E cloud.id=elastic-observability-deployment:dXMtY2VudHJhbDEuZ2NwLmNsb3VkLmV... \
-E cloud.auth=elastic:some-long-random-password \
-e -strict.perms=false \
setup
Dieser Befehl erstellt einen Metricbeat-Container namens metricbeat-setup, lädt die von uns heruntergeladene Datei metricbeat.docker.yml, stellt eine Verbindung zur Kibana-Instanz her (die er aus dem Feld cloud.id bezieht) und führt den Befehl setup aus, mit dem die Dashboards geladen werden. Wenn Sie nicht Elastic Cloud nutzen, erfolgt die Bereitstellung der URLs für Kibana und Elasticsearch über die Felder setup.kibana.host und output.elasticsearch.hosts. Außerdem müssen die entsprechenden Felder für die Anmeldeinformationen befüllt werden. Das Ganze sieht so aus:
docker run --rm \
--name=metricbeat-setup \
--volume="$(pwd)/metricbeat.docker.yml:/usr/share/metricbeat/metricbeat.yml:ro" \
docker.elastic.co/beats/metricbeat:7.11.1 \
-E setup.kibana.host=localhost:5601 \
-E setup.kibana.username=elastic \
-E setup.kibana.password=your-password \
-E output.elasticsearch.hosts=localhost:9200 \
-E output.elasticsearch.username=elastic \
-E output.elasticsearch.password=your-password \
-e -strict.perms=false \
setup
-e -strict.perms=false hilft, ein unausweichliches Problem mit der Eigentümerschaft/Berechtigung bezüglich der Docker-Datei zu umschiffen.
Für das Einrichten der Filebeat-Dashboards für die Logdaten sieht der Befehl wie folgt aus:
docker run --rm \
--name=filebeat-setup \
--volume="$(pwd)/filebeat.docker.yml:/usr/share/filebeat/filebeat.yml:ro" \
docker.elastic.co/beats/filebeat:7.11.1 \
-E cloud.id=elastic-observability-deployment:dXMtY2VudHJhbDEuZ2NwLmNsb3VkLmV... \
-E cloud.auth=elastic:some-long-random-password \
-e -strict.perms=false \
setup
Standardmäßig sind diese Konfigurationsdateien für das Erfassen von Container-Logdateien und ‑Metriken zum Monitoring generischer Container eingerichtet. Das ist zwar durchaus nützlich, aber wir möchten sicherstellen, dass sie auch dienstspezifische Logdaten und Metriken erfassen. Dazu konfigurieren wir unsere Metricbeat- und Filebeat-Container so, dass sie die oben erwähnte Funktion zur automatischen Erkennung nutzen. Das kann auf verschiedene Art und Weise erfolgen. Wir könnten die Beats so einrichten, dass sie nach konkreten Images oder Namen Ausschau halten, aber das erfordert eine Menge Vorabwissen. Stattdessen nutzen wir das hinweisbasierte Autodiscover und überlassen es den Containern, die Beats anzuweisen, was sie überwachen sollen.
Mit der Funktion „Hinweisbasiertes Autodiscover“ fügen wir den Docker-Containern Labels hinzu. Sobald andere Container gestartet werden, erhalten die Container metricbeat und filebeat (die wir noch nicht gestartet haben) eine Benachrichtigung, die es ihnen erlaubt, mit dem Monitoring zu beginnen. Wir möchten die Broker-Container so einrichten, dass sie vom Metricbeat- und vom Filebeat-Modul von Kafka überwacht werden, und wir möchten auch, dass Metricbeat für Metriken das ZooKeeper-Modul nutzt. Filebeat erfasst die ZooKeeper-Logdaten, ohne sie weiter zu analysieren.
Wir beginnen mit dem Konfigurieren von ZooKeeper, weil das einfacher ist als das Einrichten von Kafka: Die Ausgangskonfiguration in der Datei docker-compose.yml für ZooKeeper sieht wie folgt aus:
zookeeper:
image: confluentinc/cp-zookeeper:6.1.0
hostname: zookeeper
container_name: zookeeper
ports:
- "2181:2181"
environment:
ZOOKEEPER_CLIENT_PORT: 2181
ZOOKEEPER_TICK_TIME: 2000
Wir fügen der YAML-Datei einen labels-Block hinzu, um das Modul, die Verbindungsinformationen und die Metricsets anzugeben. Das geht so:
labels:
- co.elastic.metrics/module=zookeeper
- co.elastic.metrics/hosts=zookeeper:2181
- co.elastic.metrics/metricsets=mntr,server
Damit teilen wir dem metricbeat-Container mit, dass er für das Monitoring dieses Containers das Modul zookeeper verwenden soll und dass er über die Host-Port-Kombination zookeeper:2181 auf das Modul zugreifen kann. Dies ist der Port, den ZooKeeper überwacht. Außerdem wird festgelegt, dass für das ZooKeeper-Modul die Metricsets mntr und server verwendet werden sollen. Am Rande sei bemerkt, dass neuere Versionen von ZooKeeper einige sogenannte four letter words standardmäßig sperren, weshalb wir der Liste der in unserem Deployment zugelassenen Befehle mithilfe von KAFKA_OPTS die Befehle srvr und mntr hinzufügen müssen. Nachdem dies getan ist, sieht die ZooKeeper-Konfiguration in der Compose-Datei wie folgt aus:
zookeeper:
image: confluentinc/cp-zookeeper:6.1.0
hostname: zookeeper
container_name: zookeeper
ports:
- "2181:2181"
environment:
ZOOKEEPER_CLIENT_PORT: 2181
ZOOKEEPER_TICK_TIME: 2000
KAFKA_OPTS: "-Dzookeeper.4lw.commands.whitelist=srvr,mntr"
labels:
- co.elastic.metrics/module=zookeeper
- co.elastic.metrics/hosts=zookeeper:2181
- co.elastic.metrics/metricsets=mntr,server
Das Erfassen der Logdaten von den Brokern ist recht einfach – wir fügen ihnen einfach ein Label für das Logging-Modul hinzu: co.elastic.logs/module=kafka. Was die Broker-Metriken anbelangt, ist es ein wenig komplizierter. Im Metricbeat-Kafka-Modul gibt es fünf verschiedene Metricsets:
- Consumer-Gruppen-Metriken
- Partitionsmetriken
- Broker-Metriken
- Consumer-Metriken
- Producer-Metriken
Die ersten beiden Metricsets kommen von den Brokern selbst, während die letzten drei über JMX beigesteuert werden. Die letzten beiden, consumer und producer, sind nur für Java-basierte Consumer bzw. Producer (die Clients des Kafka-Clusters) relevant, weswegen wir uns nicht weiter mit ihnen beschäftigen (aber für sie gelten dieselben Muster wie unten beschrieben). Sehen wir uns die ersten beiden an, weil sie auf die gleiche Art und Weise konfiguriert werden. Die Ausgangskonfiguration in unserer Compose-Datei für broker1 sieht wie folgt aus:
broker1:
image: confluentinc/cp-server:6.1.0
hostname: broker1
container_name: broker1
depends_on:
- zookeeper
ports:
- "9091:9091"
- "9101:9101"
environment:
KAFKA_BROKER_ID: 1
KAFKA_ZOOKEEPER_CONNECT: 'zookeeper:2181'
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: PLAINTEXT:PLAINTEXT,PLAINTEXT_HOST:PLAINTEXT
KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://broker1:29091,PLAINTEXT_HOST://broker1:9091
KAFKA_METRIC_REPORTERS: io.confluent.metrics.reporter.ConfluentMetricsReporter
KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 1
KAFKA_GROUP_INITIAL_REBALANCE_DELAY_MS: 0
KAFKA_CONFLUENT_LICENSE_TOPIC_REPLICATION_FACTOR: 1
KAFKA_CONFLUENT_BALANCER_TOPIC_REPLICATION_FACTOR: 1
KAFKA_TRANSACTION_STATE_LOG_MIN_ISR: 1
KAFKA_TRANSACTION_STATE_LOG_REPLICATION_FACTOR: 1
KAFKA_JMX_PORT: 9101
KAFKA_JMX_HOSTNAME: broker1
KAFKA_CONFLUENT_SCHEMA_REGISTRY_URL: http://schema-registry:8081
CONFLUENT_METRICS_REPORTER_BOOTSTRAP_SERVERS: broker1:29091
CONFLUENT_METRICS_REPORTER_TOPIC_REPLICAS: 1
CONFLUENT_METRICS_ENABLE: 'true'
CONFLUENT_SUPPORT_CUSTOMER_ID: 'anonymous'
Ähnlich wie bei der Konfiguration für ZooKeeper müssen wir Labels hinzufügen, um Metricbeat anzuweisen, die Kafka-Metriken zu erfassen:
labels:
- co.elastic.logs/module=kafka
- co.elastic.metrics/module=kafka
- co.elastic.metrics/metricsets=partition,consumergroup
- co.elastic.metrics/hosts='$${data.container.name}:9091'
Damit werden die kafka-Module für Metricbeat und Filebeat zum Erfassen von Kafka-Logdaten sowie von partition- und consumergroup-Metriken vom Container broker1 an Port 9091 eingerichtet. Ich habe statt des Hostnamens die Variable data.container.name (mit einem doppelten Dollarzeichen als Escape-Zeichen) verwendet; es steht Ihnen frei, ein anderes Muster zu verwenden. Wir müssen diesen Schritt für jeden Broker einzeln wiederholen und dabei jeweils die Portnummer (oben 9091) an den jeweiligen Broker anpassen. (Genau aus diesem Grund habe ich die Broker ganz am Anfang entsprechend umbenannt.) Für den Broker 2 verwenden wir 9092 und für den Broker 3 9093.
Wir können den Confluent-Cluster starten, indem wir docker-compose up --detach ausführen, und wir können jetzt auch Metricbeat und Filebeat starten, damit sie mit dem Erfassen von Kafka-Logdaten und ‑Metriken beginnen.
Nachdem wir den Kafka-Cluster cp-all-in-one zum Laufen gebracht haben, erstellt er ein eigenes virtuelles Netzwerk namens cp-all-in-one_default und führt es aus. Da wir in unseren Labeln Dienst-/Hostnamen verwenden, muss Metricbeat im selben Netzwerk ausgeführt werden, damit es die Namen auflösen und korrekte Verbindungen herstellen kann. Zum Starten von Metricbeat fügen wir daher in den Ausführungsbefehl den Netzwerknamen ein:
docker run -d \
--name=metricbeat \
--user=root \
--network cp-all-in-one_default \
--volume="$(pwd)/metricbeat.docker.yml:/usr/share/metricbeat/metricbeat.yml:ro" \
--volume="/var/run/docker.sock:/var/run/docker.sock:ro" \
docker.elastic.co/beats/metricbeat:7.11.1 \
-E cloud.id=elastic-observability-deployment:dXMtY2VudHJhbDEuZ2NwLmNsb3VkLmV... \
-E cloud.auth=elastic:some-long-random-password \
-e -strict.perms=false
Der Ausführungsbefehl von Filebeat ist ähnlich, benötigt aber keine Angabe des Netzwerks, da Filebeat keine Verbindung zu den anderen Containern herstellt, sondern direkt vom Docker-Host aus läuft:
docker run -d \
--name=filebeat \
--user=root \
--volume="$(pwd)/filebeat.docker.yml:/usr/share/filebeat/filebeat.yml:ro" \
--volume="/mnt/data/docker/containers:/var/lib/docker/containers:ro" \
--volume="/var/run/docker.sock:/var/run/docker.sock:ro" \
docker.elastic.co/beats/filebeat:7.11.1 \
-E cloud.id=elastic-observability-deployment:dXMtY2VudHJhbDEuZ2NwLmNsb3VkLmV... \
-E cloud.auth=elastic:some-long-random-password \
-e -strict.perms=false
In beiden Fällen laden wir die YAML-Konfigurationsdatei, ordnen dem Container die Datei docker.sock vom Host zu und fügen die Konnektivitätsinformationen ein (bei Ausführung eines selbstverwalteten Clusters werden die Anmeldedateien verwendet, die für das Laden der Dashboards verwendet wurden). Beachten Sie, dass Sie bei Ausführung auf Docker Desktop auf einem Mac keinen Zugriff auf die Logdaten haben, da sie in der Virtual Machine gespeichert sind.
Visualisieren der Performance- und historischen Daten für Kafka und ZooKeeper
Wir erfassen jetzt dienstspezifische Logdaten von unseren Kafka-Brokern sowie Logdaten und Metriken aus Kafka und ZooKeeper. Wenn Sie zu den Dashboards in Kibana gehen und die Daten filtern, finden Sie Dashboards für Kafka,
darunter auch das Kafka-Logdaten-Dashboard:
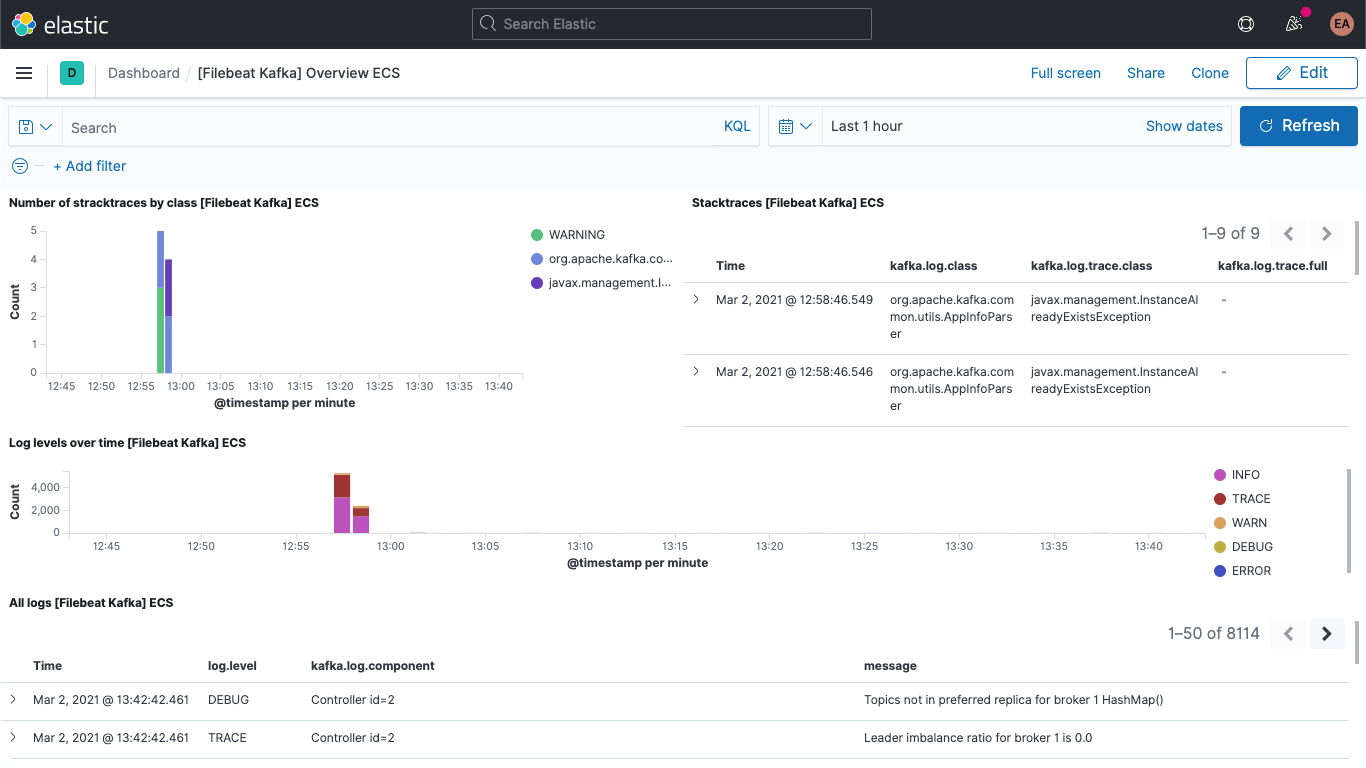
und das Kafka-Metriken-Dashboard:
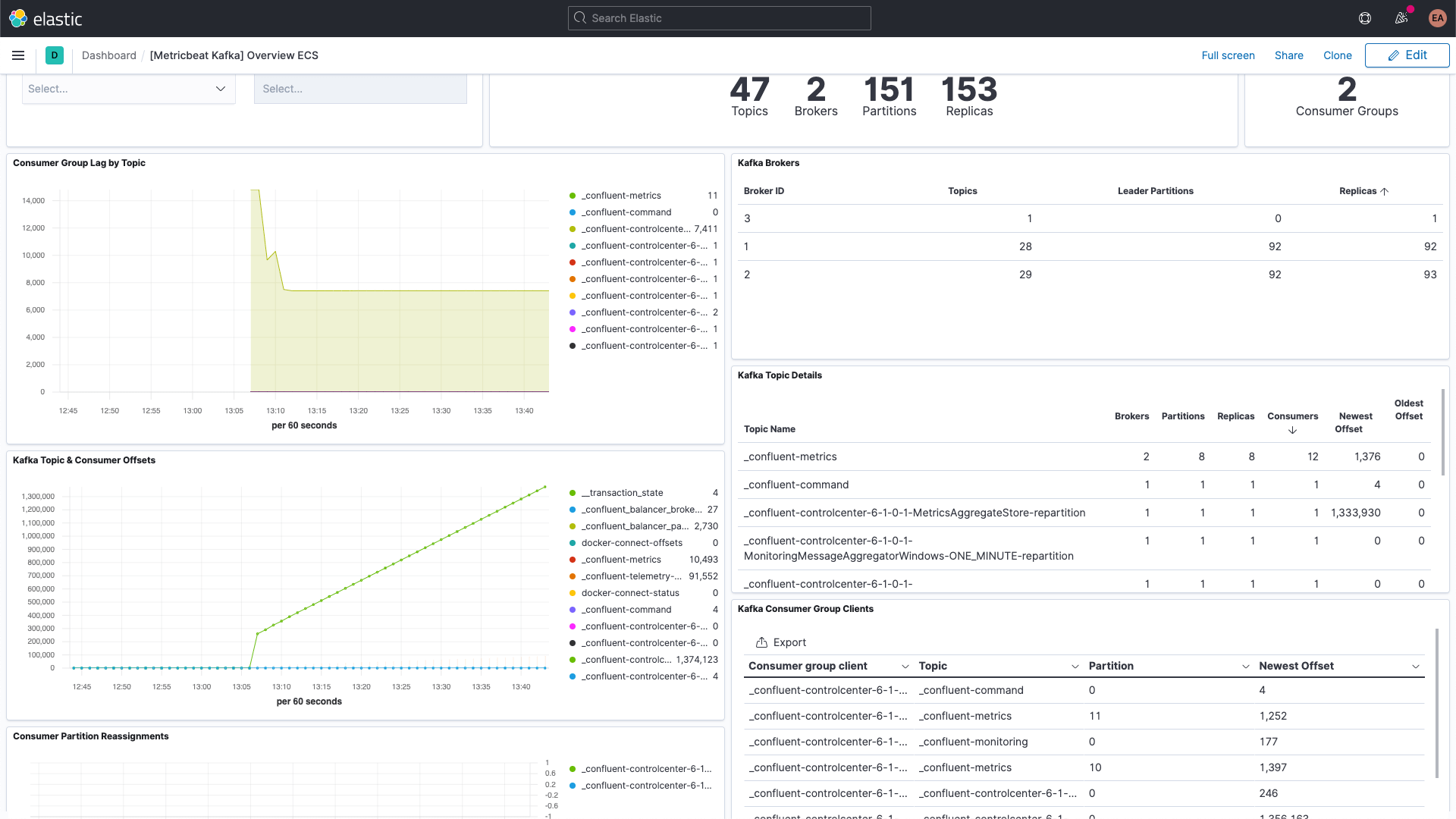
Es gibt auch ein Dashboard für ZooKeeper-Metriken:
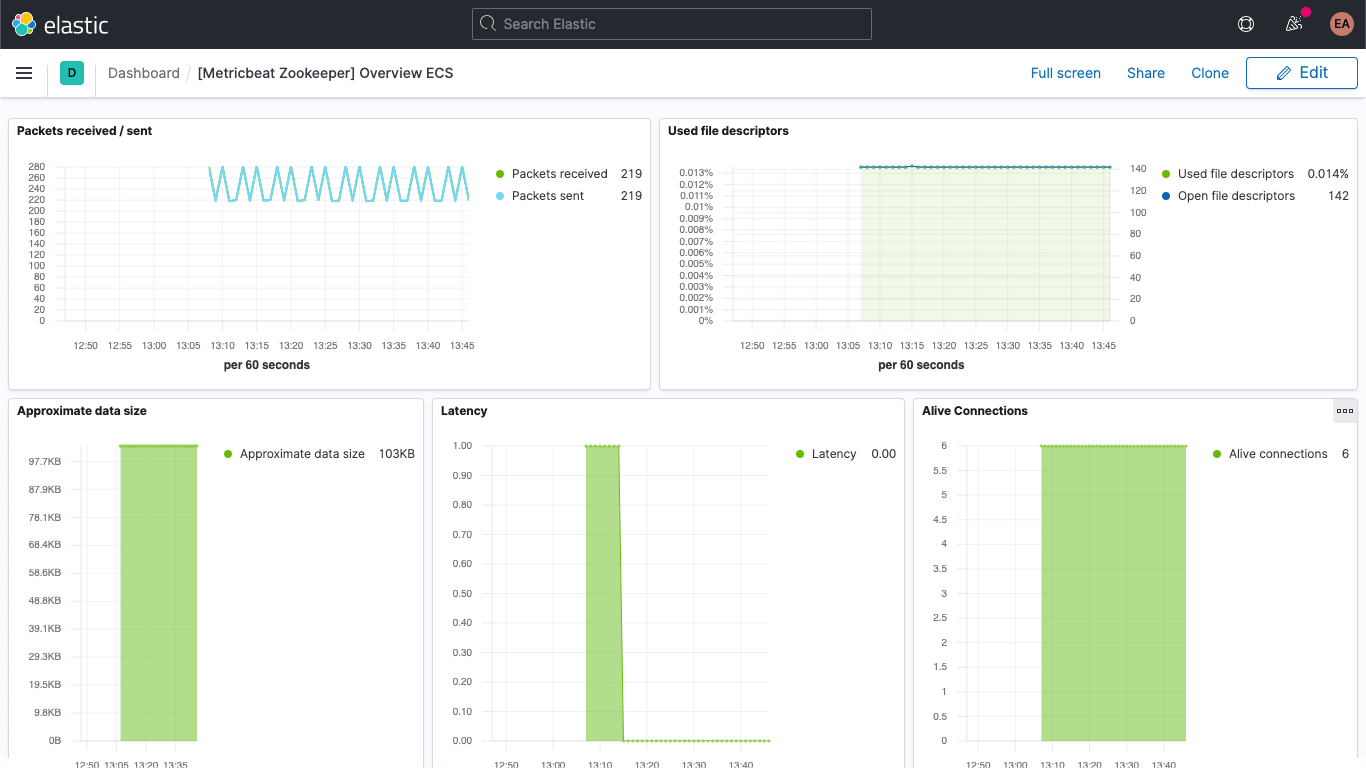
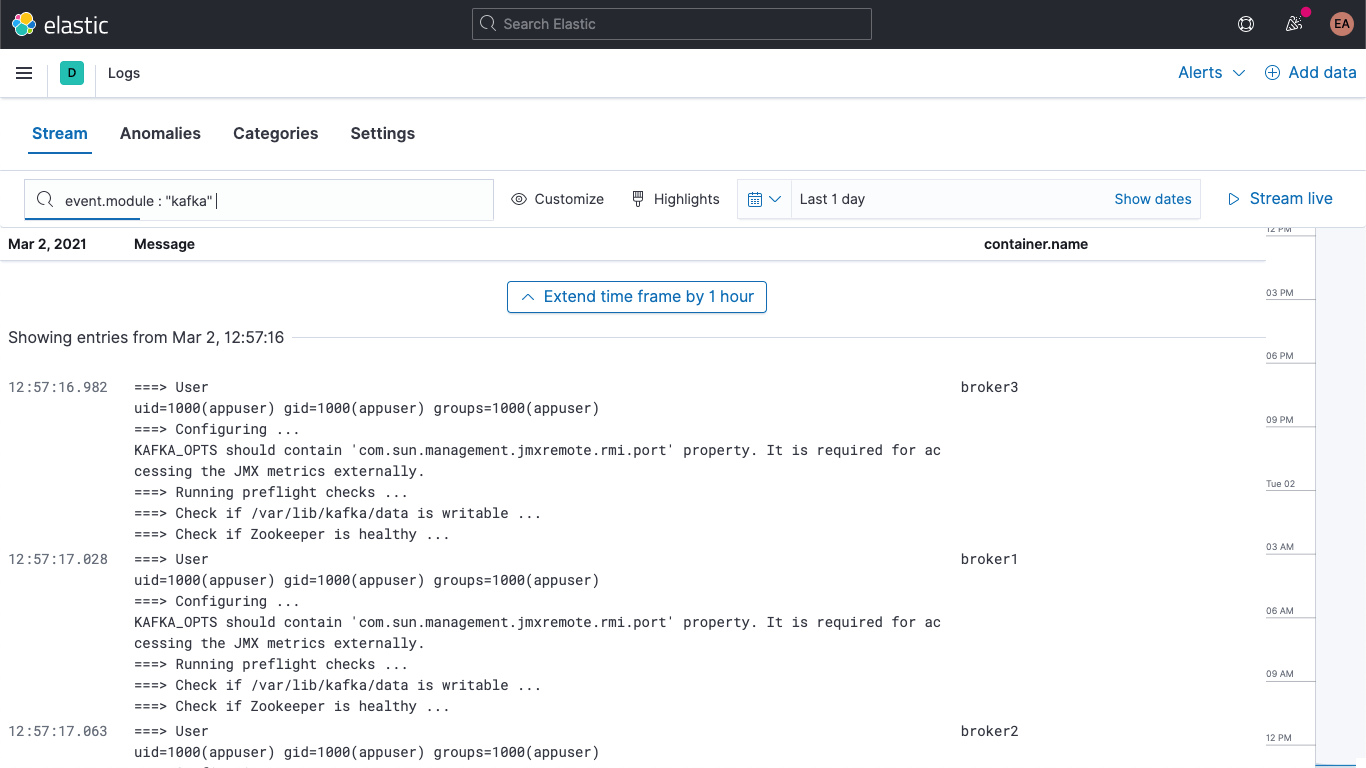
Ihre Kafka- und ZooKeeper-Logdaten sind außerdem in der Logs-App in Kibana verfügbar, wo Sie sie filtern, durchsuchen und aufschlüsseln können:
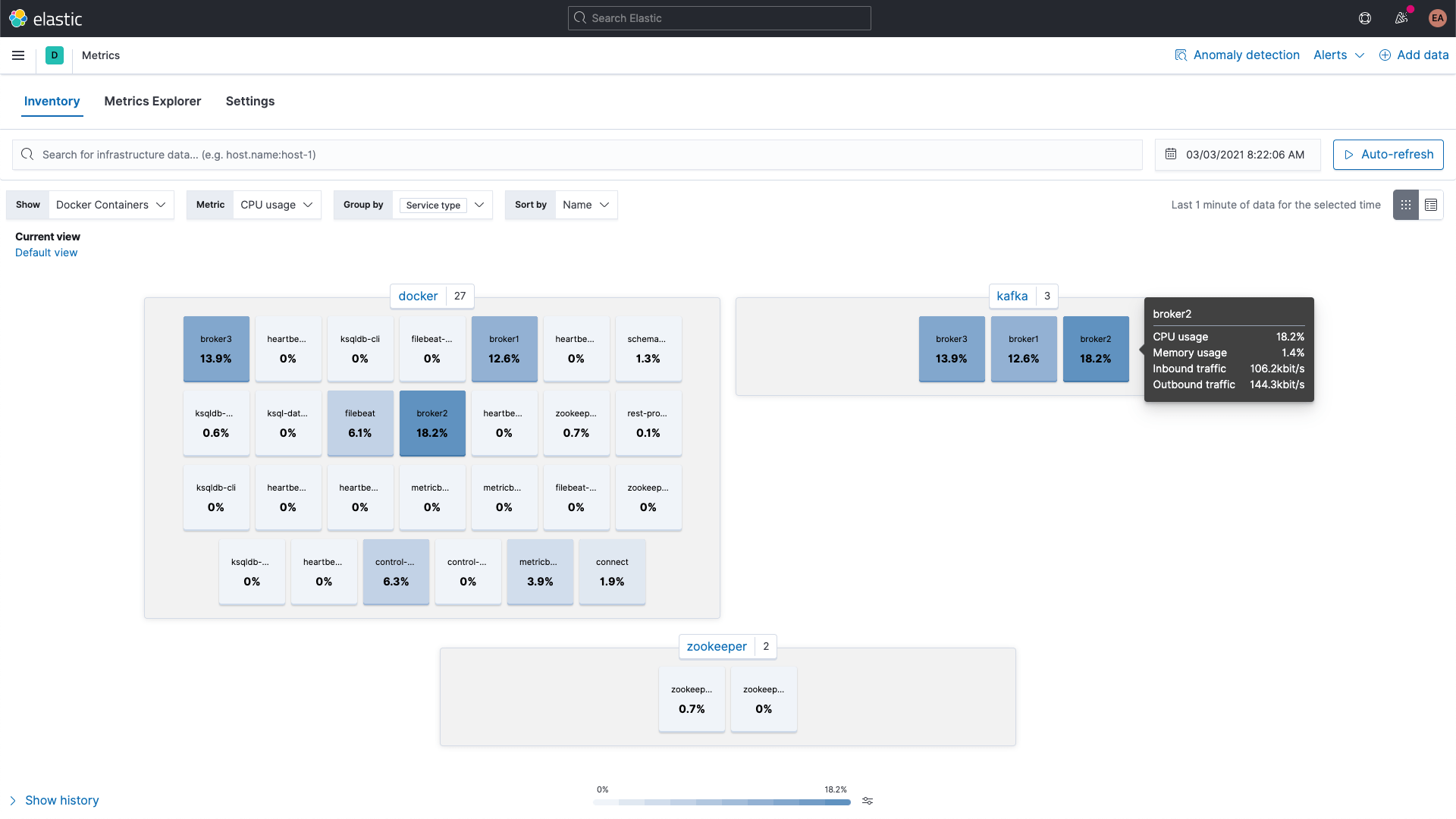
Die Metriken der Kafka- und ZooKeeper-Container können dagegen in Kibana mit der Metrics-Apps in Kibana durchsucht werden, wie im Folgenden zu sehen (hier gruppiert nach Diensttyp):
Broker-Metriken
Gehen wir etwas zurück und richten auch das Erfassen von Metriken vom broker-Metricset im kafka-Modul ein. Ich habe ja schon erwähnt, dass diese Metriken von JMX bezogen werden. Die Broker-, Producer- und Consumer-Metricsets nutzen im Hintergrund Jolokia, eine Brücke zwischen JMX und HTTP. Der Broker-Metricset ist ebenfalls Teil des kafka-Moduls, aber er nutzt JMX und muss daher einen anderen Port verwenden als die consumergroup- und partition-Metricsets, weshalb wir in labels einen neuen Block für unsere Broker benötigen, ähnlich wie die Annotationskonfiguration für mehrere Hinweis-Sets.
Außerdem müssen wir den Broker-Containern die jar-Datei für Jolokia hinzufügen. Dazu verwenden wir ein Volume und richten es ebenfalls ein. Laut der Downloadseite lautet die aktuelle Version des Jolokia-JVM-Agents 1.6.2, wir holen uns also diese Version. Mit -OL geben wir an, dass cURL die Datei als Remote-Name speichern und Weiterleitungen folgen soll:
curl -OL https://search.maven.org/remotecontent?filepath=org/jolokia/jolokia-jvm/1.6.2/jolokia-jvm-1.6.2-agent.jar
Wir fügen der Konfiguration pro Broker einen Abschnitt hinzu, um die JAR-Datei an die Container anzuhängen:
volumes:
- ./jolokia-jvm-1.6.2-agent.jar:/home/appuser/jolokia.jar
Und wir geben KAFKA_JVM_OPTS an, um die jar-Datei als Java-Agent anzufügen (die Portnummern sind jeweils brokerspezifisch, d. h., Broker 1 hat Port 8771, Broker 2 Port 8772 und Broker 3 Port 8773):
KAFKA_JMX_OPTS: '-javaagent:/home/appuser/jolokia.jar=port=8771,host=broker1 -Dcom.sun.management.jmxremote=true -Dcom.sun.management.jmxremote.authenticate=false -Dcom.sun.management.jmxremote.ssl=false'
Ich verwende an dieser Stelle keine Authentifizierung, weshalb ich dem Launch ein paar Flags hinzufügen muss. Wie Sie sehen, stimmt der Pfad der Datei jolokia.jar in KAFKA_JMX_OPTS mit dem Pfad auf dem Volume überein.
Wir müssen noch ein paar kleinere Anpassungen vornehmen. Da wir Jolokia verwenden, ist es nicht mehr nötig, im Abschnitt ports einen KAFKA_JMX_PORT-Wert anzugeben. Stattdessen geben wir den Port an, der von Jolokia überwacht wird: 8771. Außerdem entfernen wir die KAFKA_JMX_*-Werte aus der Konfiguration.
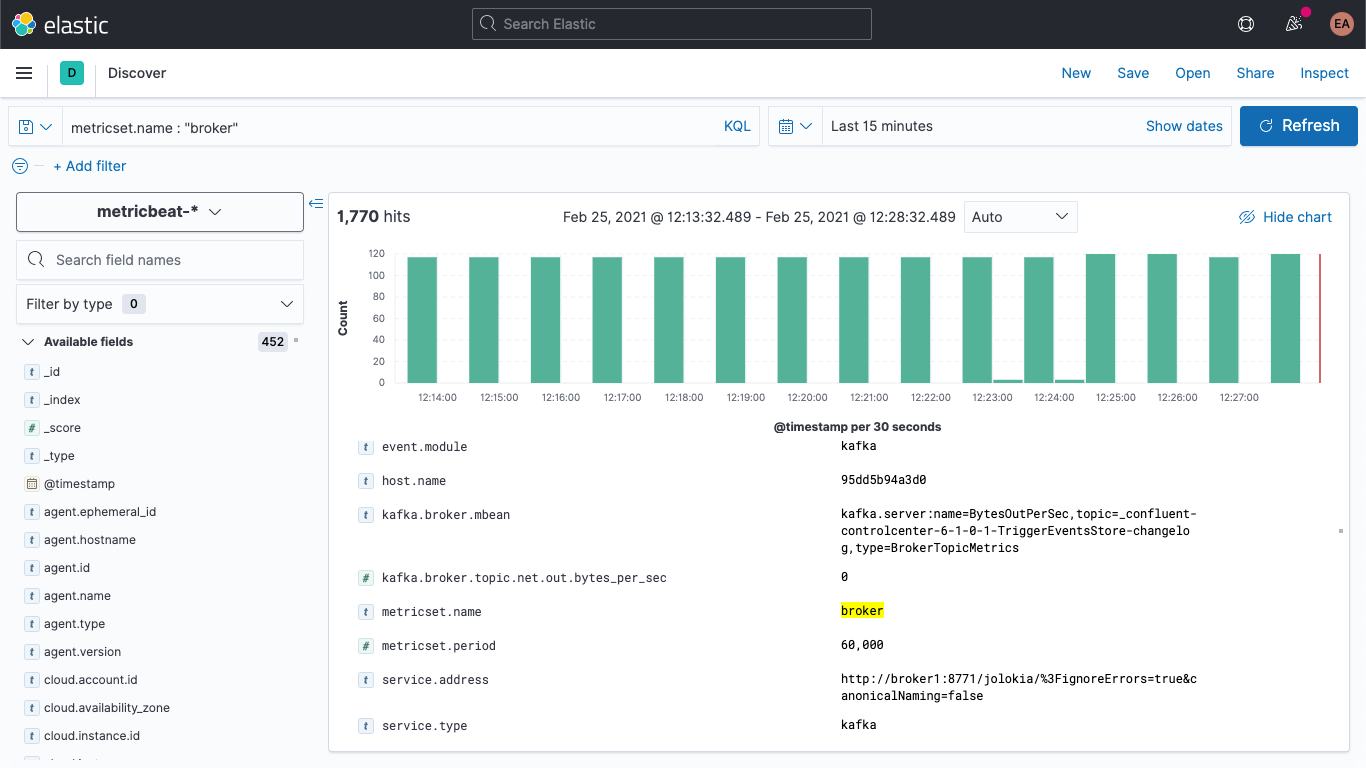
Nachdem wir unseren Kafka-Cluster neugestartet haben (docker-compose up --detach), treffen in unserem Elasticsearch-Deployment die ersten Broker-Metriken ein. Wenn ich zum „Discover“-Tab wechsle, dort das Indexmuster metricbeat-* auswähle und nach metricset.name : "broker" suche, kann ich sehen, dass tatsächlich Daten angekommen sind:
Die Struktur der Broker-Metriken sieht ungefähr so aus:
kafka
└─ broker
├── address
├── id
├── log
│ └── flush_rate
├── mbean
├── messages_in
├── net
│ ├── in
│ │ └── bytes_per_sec
│ ├── out
│ │ └── bytes_per_sec
│ └── rejected
│ └── bytes_per_sec
├── replication
│ ├── leader_elections
│ └── unclean_leader_elections
└── request
├── channel
│ ├── fetch
│ │ ├── failed
│ │ └── failed_per_second
│ ├── produce
│ │ ├── failed
│ │ └── failed_per_second
│ └── queue
│ └── size
├── session
│ └── zookeeper
│ ├── disconnect
│ ├── expire
│ ├── readonly
│ └── sync
└── topic
├── messages_in
└── net
├── in
│ └── bytes_per_sec
├── out
│ └── bytes_per_sec
└── rejected
└── bytes_per_sec
Die Ergebnisse liegen damit sozusagen als Namen/Wert-Paare vor, wie anhand des Feldes kafka.broker.mbean zu sehen ist. Sehen wir uns das Feld kafka.broker.mbean aus einer Beispielmetrik an:
kafka.server:name=BytesOutPerSec,topic=_confluent-controlcenter-6-1-0-1-TriggerEventsStore-changelog,type=BrokerTopicMetrics
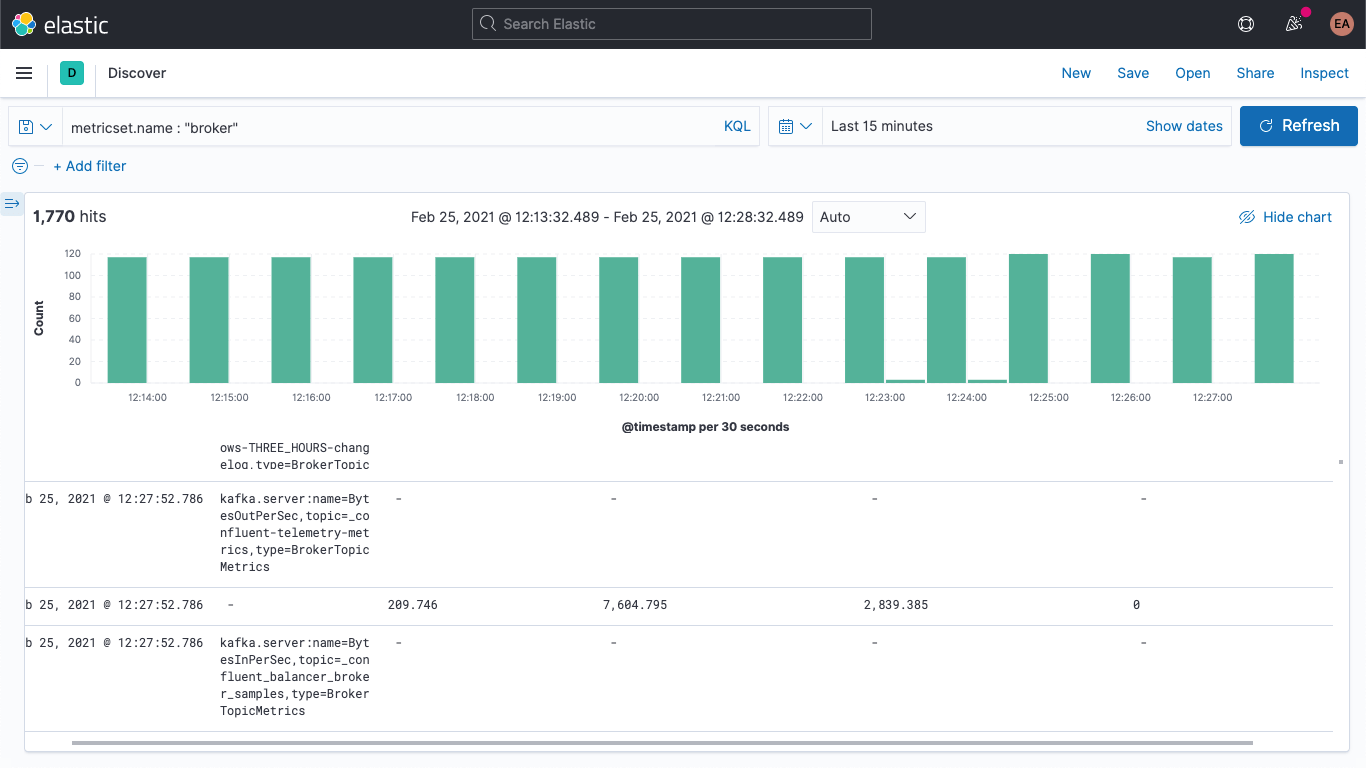
Es enthält den Namen der Metrik („BytesOutPerSec“), das Kafka-Topic, auf das sie sich bezieht („_confluent-controlcenter-6-1-0-1-TriggerEventsStore-changelog“), und den Metriktyp („BrokerTopicMetrics“). Je nach Metriktyp und Name werden unterschiedliche Felder festgelegt. In diesem Beispiel wird nur das Feld kafka.broker.topic.net.out.bytes_per_sec mit Werten versehen (hier: 0). Wenn wir uns das etwas mehr in Spaltenform ansehen, sehen wir, dass die Daten recht spärlich verteilt sind:
Durch Hinzufügen einer Ingest-Pipeline können wir das ein wenig zusammenfassen, um das Feld mbean in Einzelfelder aufzuschlüsseln, sodass wir die Daten einfacher visualisieren können. Wir verwenden jetzt zum Aufschlüsseln drei Felder:
- KAFKA_BROKER_METRIC (im Beispiel oben „beBytesOutPerSec“)
- KAFKA_BROKER_TOPIC (im Beispiel oben „be_confluent-controlcenter-6-1-0-1-TriggerEventsStore-changelog“)
- KAFKA_BROKER_TYPE (im Beispiel oben „beBytesTropicMetrics“)
In Kibana gehen wir zu DevTools:
Von dort fügen wir Folgendes ein, um eine Ingest-Pipeline namens kafka-broker-fields zu definieren:
PUT _ingest/pipeline/kafka-broker-fields
{
"processors": [
{
"grok": {
"if": "ctx.kafka?.broker?.mbean != null",
"field": "kafka.broker.mbean",
"patterns": ["kafka.server:name=%{GREEDYDATA:kafka_broker_metric},topic=%{GREEDYDATA:kafka_broker_topic},type=%{GREEDYDATA:kafka_broker_type}"
]
}
}
]
}
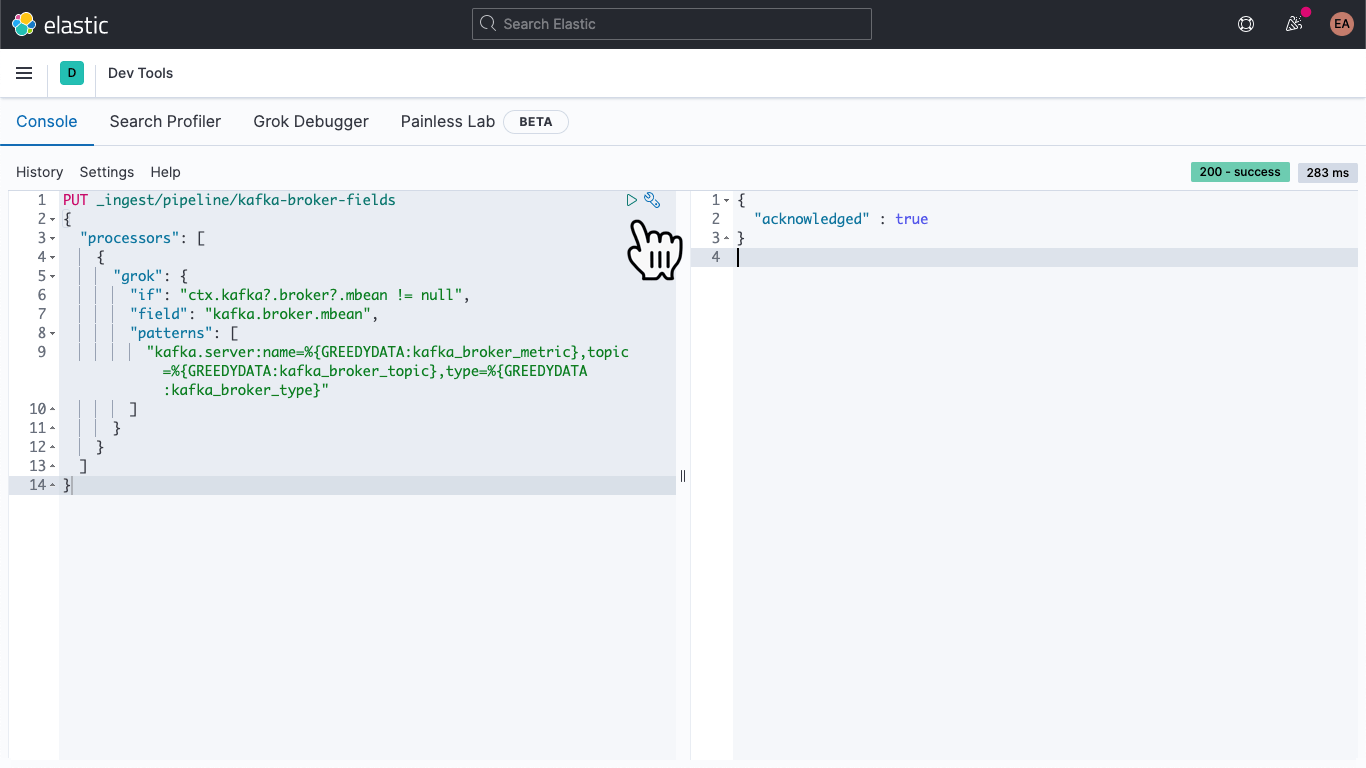
Nachdem wir auf das „Play“-Symbol geklickt haben, müsste eine Quittierungsmeldung erscheinen (siehe oben).
Unsere Ingest-Pipeline steht, aber wir haben noch nichts mit ihr getan. Unsere alte Daten sind immer noch spärlich verteilt und lassen sich nicht so einfach abrufen, während weiterhin neue Daten auf dieselbe Art und Weise hereinkommen. Wenden wir uns als Erstes dem letzteren Problem zu.
Ich öffne die Datei metricbeat.docker.yml in einem Texteditor meiner Wahl und füge dem Block output.elasticsearch eine Zeile hinzu. (Wenn Sie die Host-, Nutzernamen- und Passwort-Konfiguration eh nicht verwenden, können Sie sie entfernen.) Anschließend gebe ich meine Pipeline an:
output.elasticsearch: pipeline: kafka-broker-fields
Damit weiß Elasticsearch, dass jedes eintreffende Dokument zur Prüfung auf das Feld mbean diese Pipeline durchlaufen soll. Wir starten Metricbeat neu:
docker rm --force metricbeat
docker run -d \
--name=metricbeat \
--user=root \
--network cp-all-in-one_default \
--volume="$(pwd)/metricbeat.docker.yml:/usr/share/metricbeat/metricbeat.yml:ro" \
--volume="/var/run/docker.sock:/var/run/docker.sock:ro" \
docker.elastic.co/beats/metricbeat:7.11.1 \
-E cloud.id=elastic-observability-deployment:dXMtY2VudHJhbDEuZ2NwLmNsb3VkLmV... \
-E cloud.auth=elastic:some-long-random-password \
-e -strict.perms=false
Jetzt können wir uns in Discover vergewissern, dass neue Dokumente mit den neuen Feldern versehen werden:
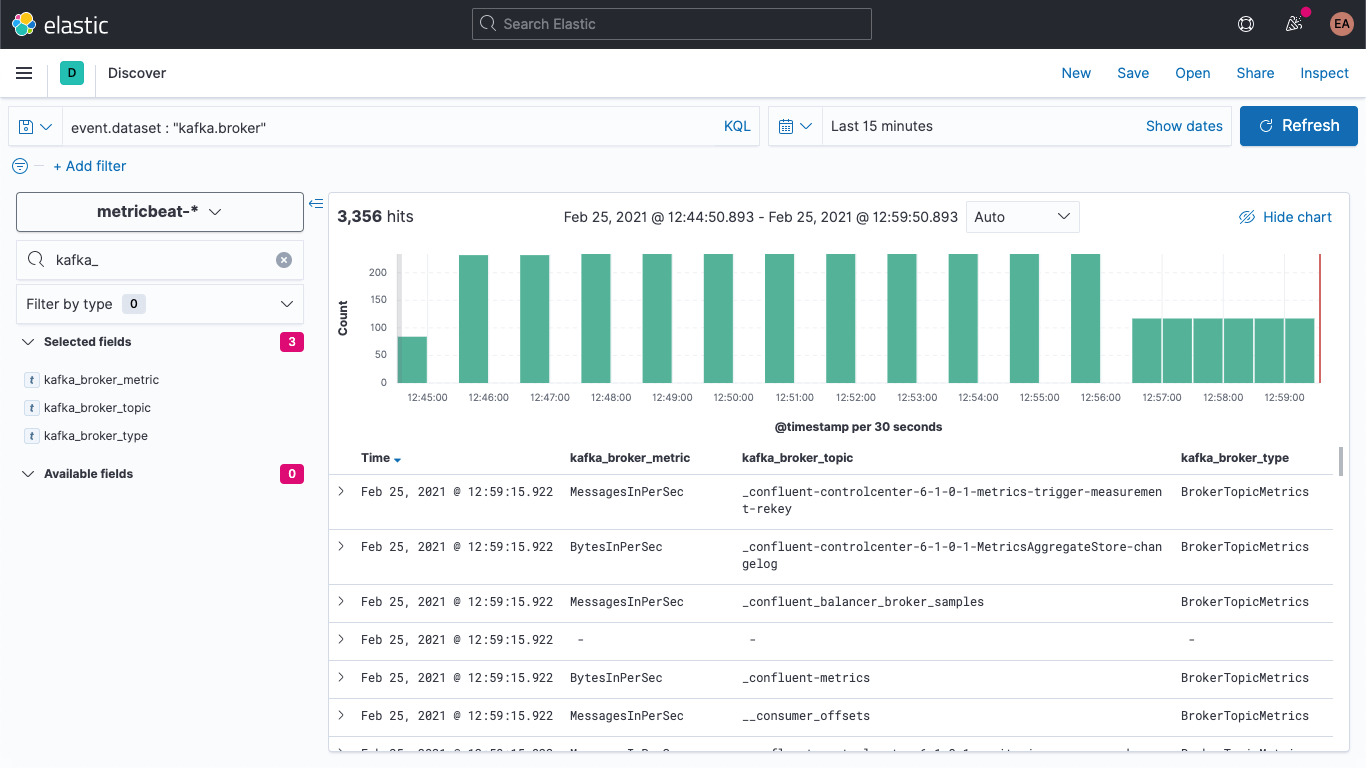
Außerdem können wir die älteren Dokumente so aktualisieren, dass diese Felder auch bei ihnen Werte erhalten. Wieder in DevTools führen wir den folgenden Befehl aus:
POST metricbeat-*/_update_by_query?pipeline=kafka-broker-fields
Wahrscheinlich erhalten Sie eine Timeout-Warnung, aber keine Sorge, er läuft asynchron im Hintergrund weiter, bis er fertig ist.
Visualisieren der Broker-Metriken
Nun gehen wir zur Metrics-App und wählen den Tab „Metrics Explorer“, um unsere neuen Felder auszuprobieren. Wir fügen kafka.broker.topic.net.in.bytes_per_sec und kafka.broker.topic.net.out.bytes_per_sec ein und sehen uns an, wie beide gegeneinander dargestellt werden:
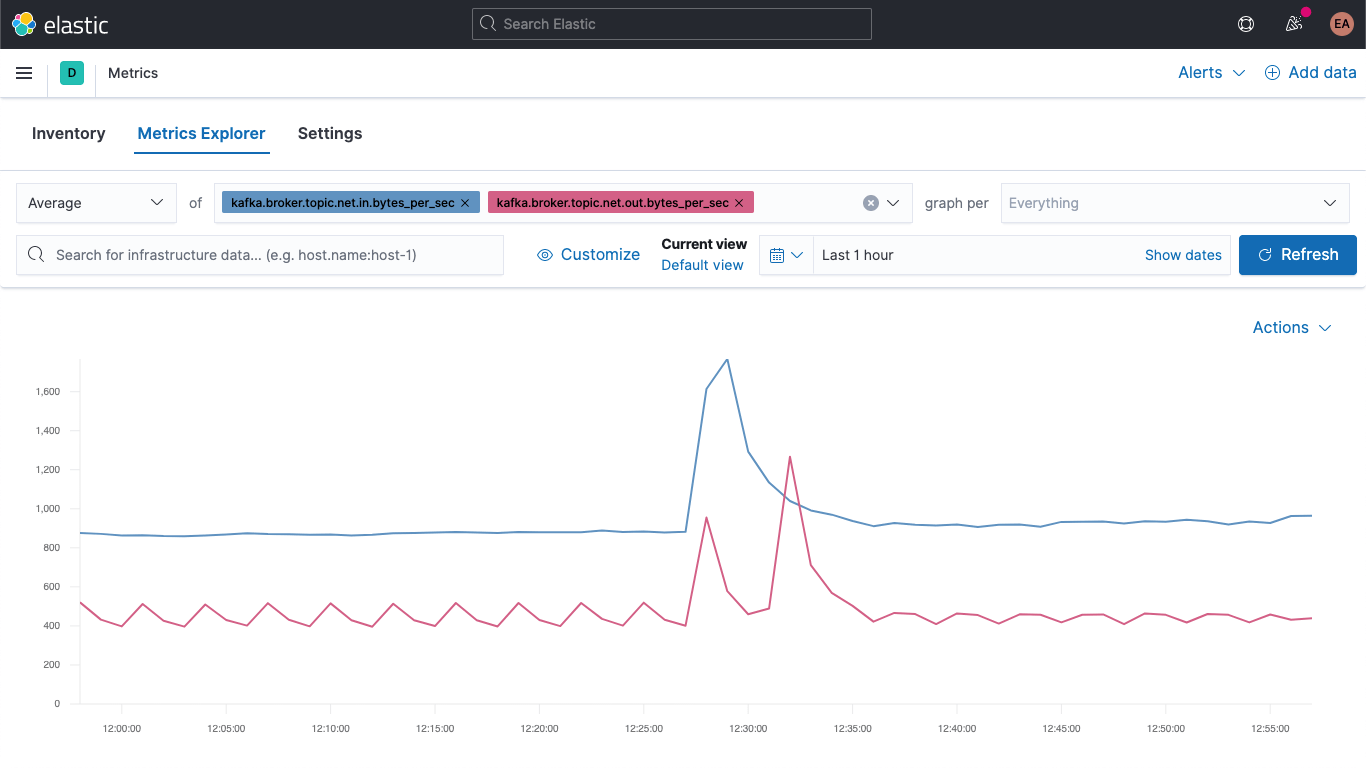
Jetzt nutzen wir eines unserer neuen Felder, öffnen das Drop-down-Menü „graph per“ und wählen kafka_broker_topic aus:
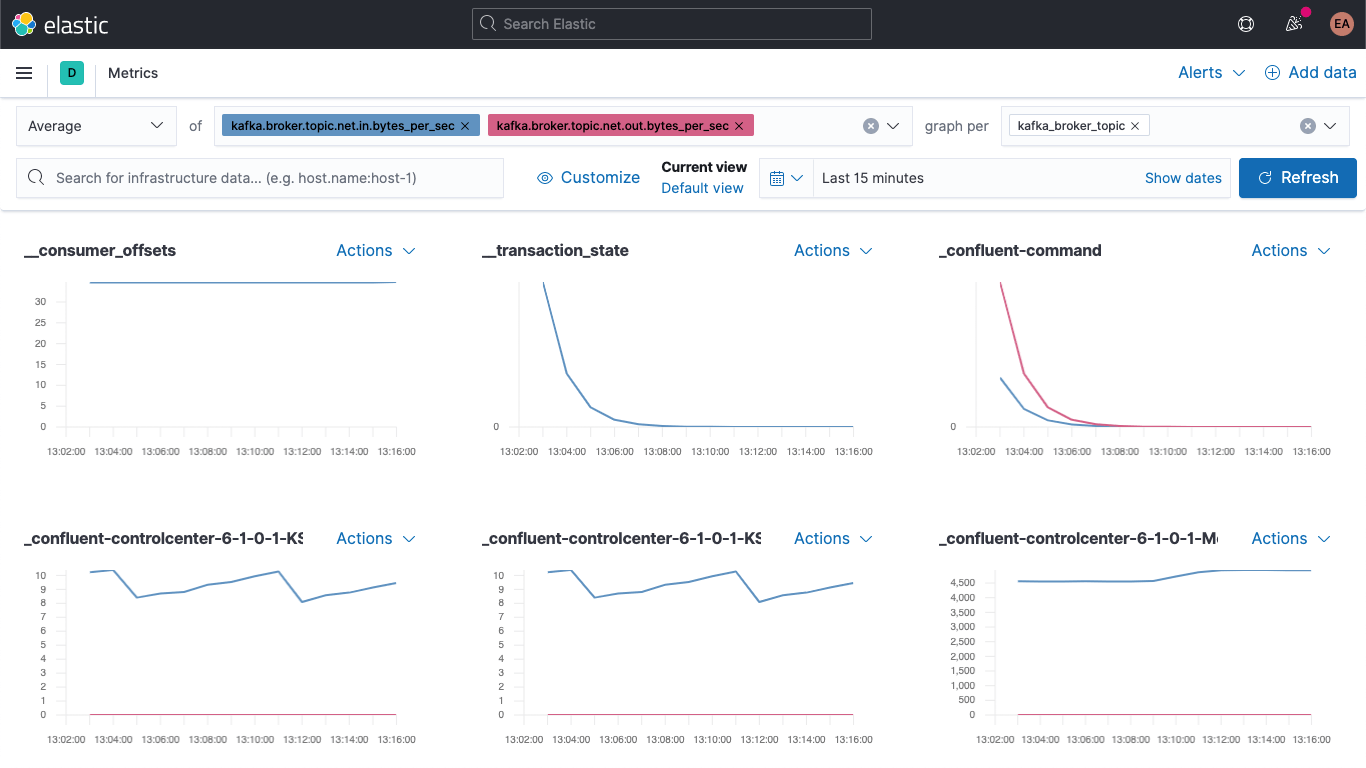
Es wird auch weiterhin Etliches mit dem Wert 0 geben (derzeit ist nicht sehr viel los im Cluster), aber es ist jetzt sehr viel einfacher, die Broker-Metriken darzustellen und nach Topic aufzuschlüsseln. Wir können jeden dieser Graphen als Visualisierung exportieren und in unser Kafka-Metriken-Dashboard laden, oder wir können mithilfe der verschiedensten Diagramm- und Tabellenformate in Kibana eigene Visualisierungen erstellen. Wenn Sie Visualisierungen lieber mit Drag-and-Drop erstellen möchten, probieren Sie Lens aus.
Ein guter Ausgangspunkt für das Visualisieren von Broker-Metriken sind die „failed“-Meldungen in „produce“- und „fetch“-Blöcken:
kafka
└─ broker
└── request
└── channel
├── fetch
│ ├── failed
│ └── failed_per_second
├── produce
│ ├── failed
│ └── failed_per_second
└── queue
└── size
Der Schweregrad der hier angezeigten Fehler hängt vom jeweiligen Anwendungsfall ab. Wenn der Fehler in einem Ökosystem auftritt, in dem wir Werte erhalten, die in kurzen Intervallen sowieso aktualisiert werden, z. B. Aktienkurse oder Temperaturmessungen, sind ein paar Fehler in der Regel nicht allzu schlimm. Handelt es sich aber z. B. um ein Bestellsystem, kann es katastrophale Folgen haben, wenn ein paar Nachrichten unberücksichtigt bleiben, denn das kann bedeuten, dass jemand seine Warensendung nicht erhält.
Fazit
Wir können jetzt Kafka-Broker und ZooKeeper mit Elastic Observability überwachen. Wir haben auch gelernt, wie wir mithilfe von Hinweisen dafür sorgen können, dass neue Instanzen von containerisierten Diensten automatisch überwacht werden. Und wir haben erfahren, wie eine Ingest-Pipeline dazu beitragen kann, Daten einfacher zu visualisieren. Wenn Sie das Ganze selbst ausprobieren möchten, melden sich an, um den Elasticsearch Service auf Elastic Cloud kostenlos auszuprobieren, oder laden Sie den Elastic Stack herunter und hosten Sie ihn lokal.
Wenn Sie keinen containerisierten Kafka-Cluster zu laufen haben, sondern Kafka als verwalteten Dienst oder auf einem Bare-Metal-Server ausführen, bleiben Sie dran. In diesem Blog wird es demnächst verschiedene Blogposts geben, die sich ähnlichen Themen widmen werden:
- Monitoring eines eigenständigen Kafka-Clusters mit Metricbeat und Filebeat
- Monitoring eines eigenständigen Kafka-Clusters mit Elastic Agent