Einführung von mehrsprachigen Engines in die Elastic App-Suche
Sie können Ihre Elastic App-Suchmaschine für eine spezielle Sprache sofort „Out-of-the-box“ optimieren. Wir bieten Ihnen insgesamt 13 Sprachen zur Auswahl, darunter: Englisch, Spanisch, Deutsch, Dänisch, Russisch, Chinesisch, Koreanisch und Japanisch.
Aber wie verändert sich dadurch die zugrunde liegende Suchmethodologie? Wie lässt sich dadurch das Sucherlebnis eines Besuchers verbessern? Sind für diese Vorteile weitere Konfigurationen erforderlich? Antworten finden Sie weiter unten. Alternativ können Sie sich auch die Dokumentation durchlesen und direkt loslegen.
Die Übung? Analysieren und Tokenizieren
Bei der Suche geht es um die Analyse. Die erste Analyse findet bei der Erstellung Ihres Index innerhalb Ihrer Suchmaschine statt. Während des Indexierungsprozesses wird der Text in Ihren Dokumenten in Token umgewandelt. Dann werden die Token am Index als Begriff organisiert.
Nachdem der Index strukturiert wurde, erfolgt jede Suchabfrage in Relation zu diesem Index. Der eingehende Text wird analysiert, in Token verwandelt und dann mit den indizierten Begriffen verglichen. Je dichter die eingehenden Abfragebegriffe dem indexierten Begriff kommen können, desto relevanter wird die Suche sein.
Wenn Sie Elasticsearch eingesetzt haben, um die Suche selbst anzulegen, müssen Sie unter Umständen einen oder mehrere benutzerdefinierte Analyzer konfigurieren, um die Tiefen der von Ihnen gewählten Sprache besser auszuloten. Wie die Token erstellt werden und wie die Begriffe aufgebaut sind steht in direkter Relation zu der Art, in der Sie Ihren Analyzer bzw. Ihren Analyzersatz konfiguriert haben. In typischen Fällen kann ein effektiver Sprachanalyzer im Rahmen der grundlegenden Indexerstellung integriert werden. Bei tieferreichenden Konfigurationen müssen jedoch Zeichenfilter, ein Tokenizer sowie Tokenfilter feinjustiert werden.
Bei der App-Suche wird diese Komplexität abstrahiert und somit eliminiert. Das Resultat ist eine optimierte API-basierte Lösung, die Sie in Ihre Anwendung integrieren können. Um zu demonstrieren, wie dies funktioniert, können wir uns ansehen, wie App-Suchmaschinen jetzt in der Lage sind, chinesische Zeichen zu interpretieren.
Gut bezahlte Arbeit
Die Grundeinstellung in einer App-Suchmaschine ist Universell. Sie ist gut konfiguriert und eignet sich optimal für die meisten Suchfälle. Wenn jedoch eine Sprache festgelegt ist, nutzt die App-Suchmaschine einen benutzerdefinierten Analyzer, der für diese Sprache optimiert ist.
Bei universellen Einstellungen ist die Suche intelligent genug, um Wörter im Kontext des jeweiligen Dokuments abzufragen, anstatt nach jedem Begriff separat zu suchen. Bei einer Suche nach „Hockey“ „Schläger“ würde nicht separat nach „Hockey“ und dann nach „Schläger“ gesucht werden. Stattdessen würde nach „Hockeyschläger“ gesucht werden.
Dies ist im Englischen – oder beim universellen Begriffsabgleich – hilfreich, kann jedoch in anderen Sprachen zu irreführenden Abfragen führen.
Dieses chinesische Zeichenpaar steht für Gehalt:
工资 : Gehalt
Es besteht aus zwei verschiedenen Zeichen, für Arbeit und für Geld
工 : Arbeit
资 : Geld
Bei der Sprachagnostik-Analyse trennt der Tokenizer die beiden Zeichen in zwei Token und sucht dann für jedes Token auf einer wörtlichen – und nicht syntaxbewussten – Basis.
Ausgehend davon, dass ein chinesischer Suchender eine Suchanfrage für „Gehalt“ durchgeführt hat, würden wir erwarten, dass er Ergebnisse für „Arbeit-Geld“ und nicht für „Gehalt“ erhalten hat. Sie sehen selbst, wie verwirrend dies sein kann!
Im Englischen erhalten Sie Ergebnisse, bei denen die Beziehung zwischen „Arbeit-Geld“ berücksichtigt wird – wie bei „Hockeyschläger“. Im Chinesischen repräsentieren diese beiden Zeichen hingegen ein vollkommen anderes Konzept.
Durch Verwendung des richtigen chinesischen Analyzers weiß das System, dass es sich bei „工资“ um ein Bigramm – ein Begriffspaar – handelt und erstellt ein Token für das kombinierte Begriffspaar. Dadurch wird im Index der richtige Begriff für „Gehalt“ angelegt. Das Bigramm „工资“ wird nun statt mit ‚Arbeit-Geld‘ mit „Gehalt“ assoziiert. Kombiniert bedeutet das Token mehr als seine disparaten Bestandteile.
App-Suche
Das Konfigurieren einer bestimmten Sprache in der App-Suche ist nun ein einfacher Teil der Engine-Erstellung.
Wenn Sie eine App-Suchmaschine mithilfe der App-Such-API erstellen, sieht das Beispiel „POST“ folgendermaßen aus. Nachfolgend wird eine neue chinesische - „zh“ -Engine namens Panda erstellt:
curl -X POST 'https://host-xxxxxx.api.swiftype.com/api/as/v1/engines' \
-H 'Content-Type: application/json' \
-H 'Authorization: Bearer private-xxxxxxxxxxxxxxxxxxxx' \
-d '{
"name": "panda",
"language": "zh"
}'
Den Sprachen ist ein Sprachencode zugewiesen. Die Codes folgen IETF RFC 5646, welcher ISO 639-1 und ISO 3166-1 entspricht.
Wenn Sie zum Anlegen Ihrer Engine eine Benutzeroberfläche verwenden möchten, ist die Sprachauswahl bei der Engine-Erstellung beim Onboarding sowie innerhalb des Dashboards verfügbar:
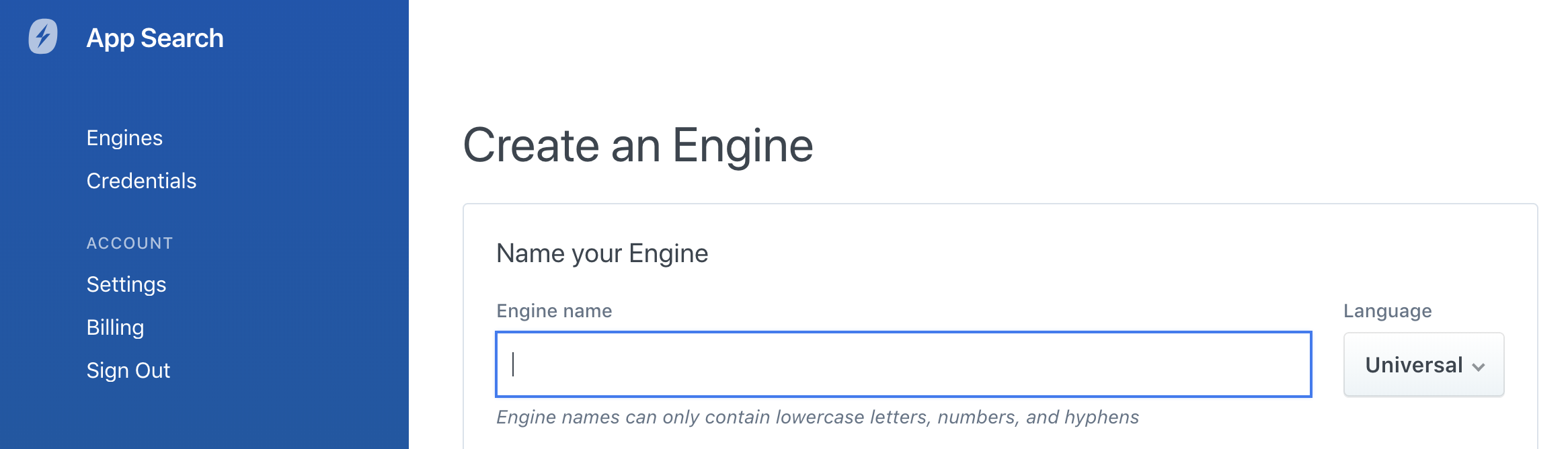
Oben links unter dem Namen Ihrer Engine können Sie sehen, für welche Sprache eine Engine konfiguriert ist. Wenn Sie keine Sprache sehen, ist der Typ Universell:
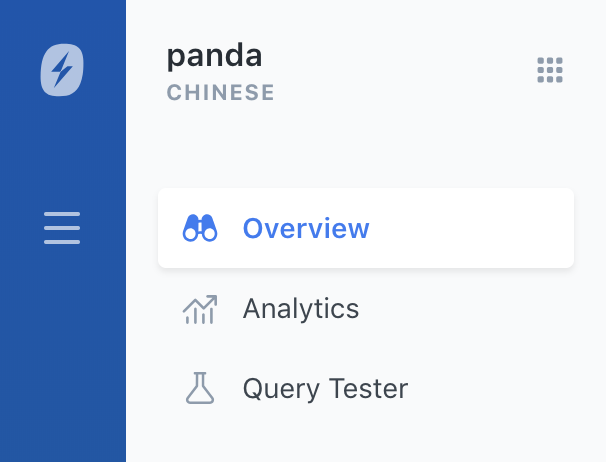
Sind, nachdem Sie nun über eine Engine verfügen, die auf eine bestimmte Sprache spezialisiert ist, noch weitere Schritte erforderlich? Nein! Die fortschrittliche, sprachspezifische Analyse wird bei jeder Datenindexierung in die Engine durchgeführt. Danach wenden die Suchabfragen in diesen Sprachen denselben relevanten und sprachoptimierten Analyzer an, der auch beim Indexieren zum Einsatz kommt.
Zusammenfassung
Selbst wenn Sie sich auf nur einen Wert, einen Datentyp und eine Sprache konzentrieren könnten, wäre eine Suche eine anspruchsvolle technische Herausforderung. In Wirklichkeit ist eine Suche deutlich komplexer: Wir müssen viele Werte, viele Datentypen sowie eine große Vielzahl von Sprachen unterstützen. Die Zielsetzung ist eine hochpräzise Sprach- und Datentyp-Agnostiksuche mit einem durch Machine Learning prognostizierten Kontext.
Bis dahin ist Elastic App-Suche eine effektive Möglichkeit, ein umfassendes Suchfachwissen in Ihre Anwendungen zu integrieren. Sie verfügen über 14 hervorragend optimierte Sprachen und können so wieder zum Schaffen hochwertiger Sucherlebnisse mithilfe eines intuitiven Dashboards und einfachen, dynamischen, gut verwalteten APIs zurückkehren. Sie können sich für eine 14-tägige Testphase anmelden, um mit den APIs zu experimentieren und um festzustellen, ob die Elastic App-Suche für Sie die optimale Lösung ist.
Update*: In Elastic Site Search werden jetzt mehrere Sprachen unterstützt. Geben Sie Ihre Domäne ein, wählen Sie Ihre Sprache aus und gestatten Sie dem Site-Suchcrawler das Indexieren Ihrer Seiten für Sie. Deinstallieren Sie danach das Snippet und genießen Sie ein hochwertiges Sucherlebnis.*