Mehr Elasticsearch-Performance durch zusätzliche Knoten im Cluster


 Share on Twitter
Share on TwitterAuf Twitter teilen

 Share on LinkedIn
Share on LinkedInAuf LinkedIn teilen

 Share on Facebook
Share on FacebookAuf Facebook teilen

 Share by Email
Share by EmailPer E-Mail teilen

 Print this page
Print this pageDrucken
Mit zusätzlichen Knoten in Ihrem Elasticsearch-Cluster kann dieser problemlos mit enormen Workloads umgehen. Damit dies nicht zu Lasten der Performance geht, ist es wichtig, beim Erweitern des Elasticsearch-Clusters bestimmte Dinge zu beachten.
Elasticsearch ist eine schnelle und leistungsfähige Technologie für die Suche. Wenn ihre Datenbestände irgendwann zu groß geworden sind, ist es Zeit, die beeindruckenden Skalierbarkeitsfunktionen von Elasticsearch zu nutzen. Durch Hinzufügen neuer Knoten zu Ihrem Cluster erweitern Sie die Datenspeicherkapazität des Clusters, verbessern dessen Fähigkeit, mehrere Anfragen gleichzeitig zu bearbeiten, und beschleunigen die Suche – in der Regel.
Herausfinden zu müssen, warum das Hinzufügen neuer Knoten für Instabilität, Ausfälle, Downtime, zunehmende Frustration und entgangene Einnahmen gesorgt hat, kann schon mal ein ganzes Wochenende ruinieren. Sehen wir uns also einige häufig vorkommende Konfigurationen an, bei denen die Skalierung eines Clusters zu erheblichen Engpässen bei der Performance führen kann.
Es gibt bei uns ein hervorragendes Webinar mit dem Titel „Elasticsearch sizing and capacity planning“. Darin werden, was die Hardware angeht, die folgenden vier Hauptressourcen in einem Cluster definiert:
- Rechenleistung: bezieht sich auf den Prozessor (CPU) und bestimmt, wie schnell der Cluster seine Arbeit verrichten kann
- Speicherplatz: bezieht sich auf die Massenspeicher (Festplatten, SSDs) und bestimmt, wie viele Daten der Cluster langfristig speichern kann
- Arbeitsspeicher: bezieht sich auf die Kapazität des RAM und bestimmt, wie viele Abfragen der Cluster auf einmal verarbeiten kann
- Netzwerk: bezieht sich auf die Bandbreite und bestimmt, wie schnell Knoten Daten untereinander austauschen können
Die beiden häufigsten Engpasskandidaten sind die Rechenleistung und der Speicherplatz. Wenn diese Ressourcen knapp werden, kann sich dies deutlich negativ auf die Datenknoten des Clusters auswirken. Andere Aufgaben der Knoten, wie das Agieren als Master, das Ingestieren und das Transformieren, sind jeweils ein Thema für sich.
Hinweis: Aus Gründen der Einfachheit konzentrieren wir uns in diesem Artikel auf das Skalieren eines einzelnen Elasticsearch-Clusters. Bei mehreren Clustern auf gemeinsam genutzter Hardware wird das Ganze noch komplexer.
Die Art und Weise, wie Hardware-Ressourcen zugeordnet werden, ist jeweils plattformspezifisch. So stellt sich beispielsweise die Frage, ob Knoten Hardware, virtuelle Maschinen oder containerbasierte Systeme sind.
Wenn durch das Hinzufügen von Elasticsearch-Knoten mehr Kapazität hinzugefügt wird
Hinzufügen dedizierter Hardware-Knoten
Am vorhersehbarsten lässt sich die Performance eines Clusters erhöhen, indem man neue Hardware hinzufügt. Neue dedizierte Hardware bedeutet eine Steigerung bei allen vier Hauptressourcen. Abgesehen von einer wichtigen Ausnahme (zu der wir später noch kommen) führt das Hinzufügen neuer Hardware-Knoten zu einer besseren Performance des Clusters.
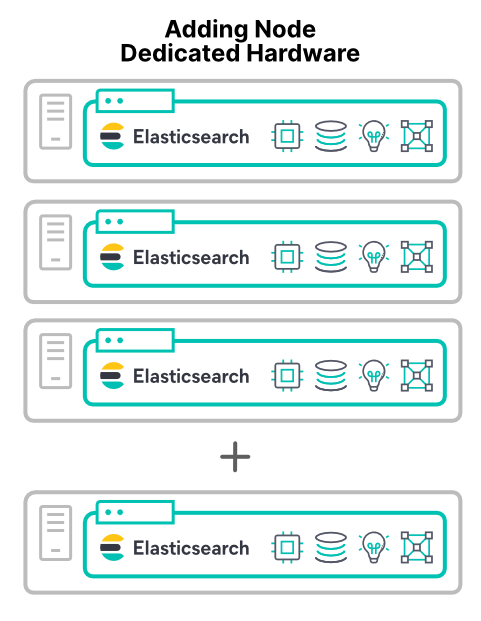
Hinzufügen von Knoten in virtuellen Maschinen oder Containern auf neuen Hosts
Das Hinzufügen von Knoten als virtuelle Maschinen (VMs) oder Container wirft neue Fragen auf. Wenn Sie dem Cluster neue Knoten auf neuen Hosts zuweisen, stehen mehr Hardwareressourcen zur Verfügung: es gibt mehr CPU-Kerne, mehr RAM, mehr Speicherplatz und insgesamt mehr Bandbreite.
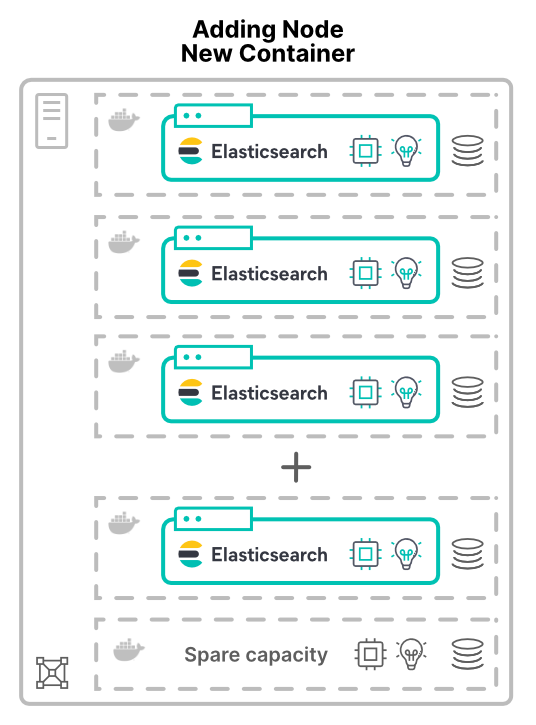
Anwendungen werden unter anderem deshalb virtualisiert (oder containerisiert), weil man sich davon eine verbesserte Hardware-Auslastung erhofft. Werden in einem solchen Szenario Knoten hinzugefügt, führt dies lediglich dazu, dass dem Cluster mehr Hardware zur Verfügung steht. Inwiefern die Performance dadurch steigt, hängt von den Limits der gemeinsam genutzten Ressourcen ab.
Wenn mehr Knoten eine Aufteilung der Kapazität bedeuten
Ob die Hardware mittels VMs oder Containern aufgeteilt wird – in jedem Fall müssen sich die Elasticsearch-Knoten Hardware teilen. Dies gilt für alle Bereitstellungsmodelle, auch für Elastic Cloud Enterprise (ECE) und Elastic Cloud on Kubernetes (ECK).
Engpass bei der Rechenleistung
Beim Zuweisen von CPUs über virtuelle Maschinen gibt es in aller Regel kein Problem mit fehlender Vorhersehbarkeit: Sie weisen jeder VM so viele Kerne zu, wie sie verwenden soll. Bei Containern gestaltet sich die gemeinsame Nutzung von CPUs komplizierter.
Containersysteme wie Kubernetes können CPU-Ressourcen in Tausendstel einer CPU, den sogenannten Millicores, messen. Zwischen den Anfragen und den Limits besteht ein erheblicher Unterschied. Wenn nur die angefragte CPU definiert wird, kann der Container bis zu 100 % der CPU des Hosts nutzen. Bei einer zu starken Limitierung der CPU bleiben jedoch teure Ressourcen ungenutzt.
> Tipp: Die Threadpools verwenden CPU-Cores als Ausgangspunkt. Bei Containern ist es daher wichtig zu prüfen, dass Ihre Threadpool-Konfiguration den Erwartungen entsprechend funktioniert.
In Kubernetes können die CPU-Limits der Container insgesamt über der insgesamt verfügbaren Hardware liegen. Dabei wird davon ausgegangen, dass nicht alle Container zur gleichen Zeit voll ausgelastet sind.
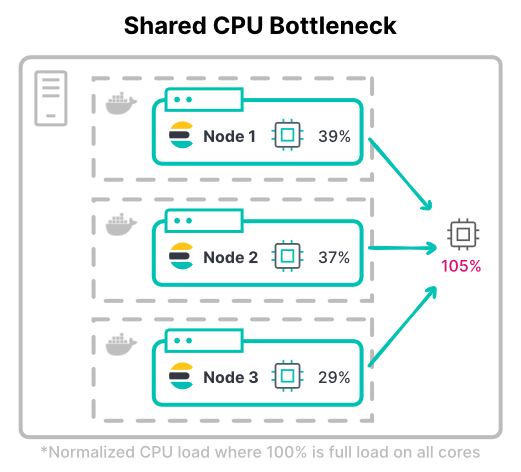
Betrachten wir den maximalen Durchsatz eines Clusters. Bei rechenintensiven Workloads benötigen Knoten für das Indexieren oft die vollen zugewiesenen CPU-Limits. Die häufigste indexlastige Workload ist ein Logging-Cluster mit großen Datenmengen.
> Tipp: Denken Sie bei der Ermittlung der CPU-Limits sowohl an die Peak- als auch an die typische CPU-Auslastung. Überlegen Sie dabei auch, wie viel CPU-Drosselung akzeptabel ist.
Engpass beim Speicherplatz
Die Vermeidung von Speicherplatz-Engpässen ist mitunter sehr schwierig, da der Speicherplatz nach Platz und nicht nach Durchsatz zugewiesen wird. Wenn einem Elasticsearch-Knoten der Speicherplatz ausgeht, sinkt der verfügbare Speicherplatz unter den Grenzwert für wenig Speicherplatz, worauf die Shard-Zuweisung gestoppt wird.
Gleich, ob VM oder Container, den meisten Plattformen mangelt es an einfachen Möglichkeiten, die Speicherplatznutzung zu begrenzen. In den meisten Umgebungen gibt es keine konfigurierbaren Limits für IOPS (Input/Output Operations Per Second) oder den Lese-/Schreibdurchsatz. Selbst das empfohlene XFS-Dateisystem erlaubt nur Disk-Kontingente auf der Basis der Speicherkapazität des Datenträgers.
Ohne Limits kann jeder Container mit einer speicherplatzintensiven Workload die Speicherhardware überlasten. Darunter leiden dann andere Knoten, die diese Hardware ebenfalls nutzen. Bei großen Implementierungen kann es zu Problemen mit den /de/data-Verzeichnissen kommen. Wenn mehrere Knoten ihr /de/data-Verzeichnis auf derselben SAN-Hardware (Storage Area Network) mounten, kann der Gesamtdurchsatz von allen diesen Knoten das Gerät überfordern.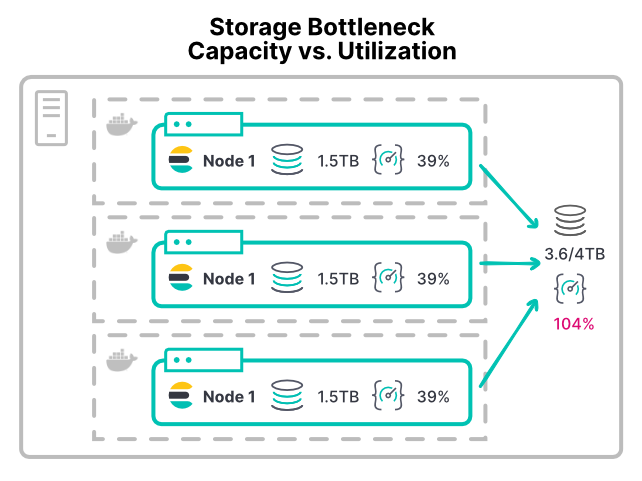
Bei einem Container-Setup wie diesem wird dem Cluster durch zusätzliche Knoten mehr CPU und mehr Arbeitsspeicher zugewiesen. Der bestehende Speicherdurchsatz wird dadurch aber weiter aufgeteilt. Dies führt dazu, dass Festplattenoperationen langsamer werden und sich die Performance durch das Hinzufügen von Knoten verschlechtert.
> Tipp: Ein frühes Warnsignal, dass Knoten zu wenig Speicherdurchsatz haben, ist eine CPU-E/A-Wartezeit von über 10 %. Diese Metrik steht für VMs und Container-Hosts, nicht aber für individuelle Container zur Verfügung.
Wenn das Hinzufügen von Knoten die Geschwindigkeit nicht beschleunigt
Bei der effektiven Skalierung gibt es noch eine letzte Schwierigkeit. Zu diesem Konfigurationsengpass kommt es selbst dann, wenn physische Hardware hinzugefügt wird.
Limitierung des Indexdurchsatzes bei nicht genügend Shards
Wenn Knoten hinzugefügt werden, ändert sich an der Zahl der Shards in einem Index nichts – das gilt unabhängig von der Methode, mit der die Knoten hinzugefügt werden. Wenn ein Index zwei primäre Shards und ein Replikat-Set hat, sind insgesamt vier Shards vorhanden. In einem aus vier Knoten bestehenden Cluster reicht eine Shard pro Knoten aus, um den Indexierungsdurchsatz auf hervorragende Weise zu maximieren.
Wenn die Menge der eingehenden Daten steigt, fügen wir dem Cluster zwei weitere Knoten hinzu. Damit erhöhen wir die Cluster-Ressourcen insgesamt um 50 %, die Geschwindigkeit beim Ingestieren verbessert sich aber genau um 0 %. Warum ist das so?
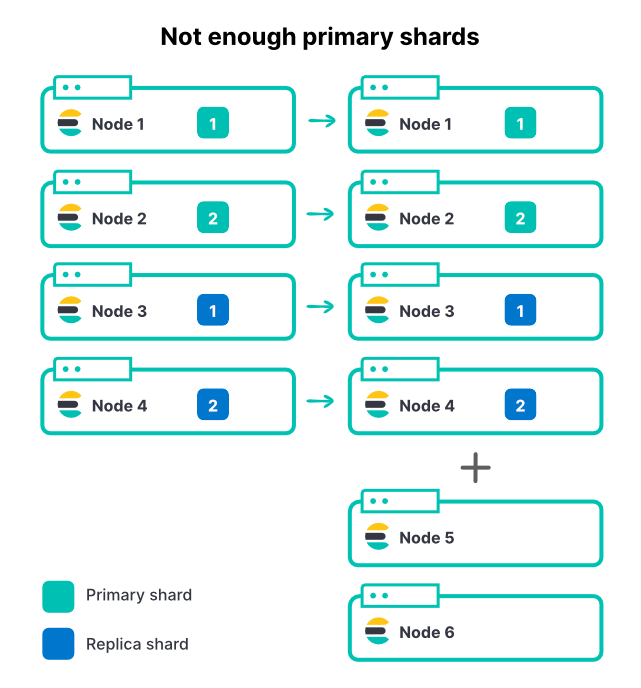
Die neuen Knoten können in diesem Fall nichts zur Indexierung beitragen, weil alle Shards bereits zugewiesen sind. Damit ein Index von zusätzlichen Knoten profitiert, muss auch die Zahl der primären Shards erhöht werden. Wenn es in einem Cluster viele aktive Indizes gibt (was häufig vorkommt), erhöhen zusätzliche Knoten zwar den Gesamtdurchsatz des Clusters, durch die begrenzte Zahl an primären Shards kann es aber sein, dass die meisten aktiven Indizes davon nicht profitieren. Die Auswahl einer angemessenen Anzahl Shards für Elasticsearch ist daher ein wichtiger Teil der Kapazitätsplanung.
Im Beispiel oben würde sich eine Erhöhung von zwei auf drei primäre Shards plus das eine Replikat pro Shard eine Gesamtzahl von sechs Shards ergeben, die auf die sechs Knoten aufgeteilt werden könnten.
> Tipp: Eine Möglichkeit, hier ein Sicherheitsnetz einzuziehen, besteht darin, die Zahl der Shards pro Knoten mit „index.routing.allocation.total_shards_per_node [docs]“ zu begrenzen. Wird dieses Limit zu niedrig gesetzt, kann es allerdings passieren, dass Shards nicht zugewiesen werden.
Fazit
Verbessert sich die Performance eines Elasticsearch-Clusters, wenn ihm Knoten hinzugefügt werden? Es kommt darauf an … Wenn Knoten Hardware gemeinsam nutzen, müssen Sie darauf achten, keine Engpässe bei den gemeinsam genutzten Ressourcen zu schaffen. Zwei häufig auftretende Engpasskandidaten sind die Überlastung von Rechenleistung und Speicherplatz. Mit einer sorgfältigen Planung und einer guten Shard-Strategie stellen Sie sicher, dass das Hinzufügen von Knoten die Leistung auch wirklich erhöht.
Einer der vielen Vorteile der Ausführung in der Elastic Cloud besteht darin, dass unser Team Performance-Probleme genau dieser Art bei gemeinsam genutzten Ressourcen erkennt und löst. Warum also warten? Probieren Sie Elastic Cloud einfach einmal kostenlos aus: https://www.elastic.co/de/cloud/
Und wenn Sie tiefer in das Thema „Performance von Elasticsearch“ eintauchen möchten, sehen Sie sich unser Webinar Elasticsearch sizing and capacity planning an.
Teilen
- Share on Twitter
Auf Twitter teilen
- Share on LinkedIn
Auf LinkedIn teilen
- Share on Facebook
Auf Facebook teilen
- Share by Email
Per E-Mail teilen
- Print this page
Drucken