Kubernetes-Monitoring im Elastic-Stil mit Filebeat und Metricbeat
In einem früheren Blogpost habe ich gezeigt, wie Sie Prometheus und Fluentd mit dem Elastic Stack nutzen können, um Kubernetes zu überwachen. Das ist eine gute Option, wenn Sie diese Open-Source-Monitoring-Tools bereits in Ihrem Unternehmen einsetzen. Aber für alle, die noch kein Kubernetes-Monitoring betreiben oder die Möglichkeiten von Elastic Observability voll ausschöpfen möchten, gibt es eine einfachere und umfassendere Methode. In diesem Blogpost sehen wir uns an, wie Sie Kubernetes im Elastic-Stil überwachen können – mit Filebeat und Metricbeat.
Monitoring mit Filebeat und Metricbeat
Beats ist, wie Sie wissen, eine kostenlose und offene Plattform für das Versenden („Shipping“) von Daten. Mit Beats können Sie Daten von Hunderten oder Tausenden von Maschinen an Logstash oder Elasticsearch senden.
Filebeat, ein leichtgewichtiger Logdaten-Shipper, unterstützt auch containerisierte Architekturen. Das Tool kann in Docker-, Kubernetes- und Cloud-Umgebungen bereitgestellt werden und erfasst alle Logdaten-Streams sowie Metadaten, z. B. Informationen zu Containern, Pods, Nodes, virtuellen Umgebungen und Hosts, und korreliert diese automatisch mit entsprechenden Log-Ereignissen. Metricbeat ist ein leichtgewichtiger Metriken-Shipper, der ebenfalls containerisierte Umgebungen unterstützt. In einer Kubernetes-Umgebung werden Container dynamisch als Pods auf verfügbaren Worker-Nodes bereitgestellt. Die Betonung liegt dabei auf „dynamisch“, und sowohl Filebeat als auch Metricbeat sind dafür mit einem praktischen Feature namens „Autodiscover“ ausgestattet. Anwendungen, die in Containern ausgeführt werden, werden zu sich bewegenden Zielen für Monitoring-Systeme. Kubernetes-Autodiscover-Provider für Filebeat und Metricbeat überwachen das Starten, Aktualisieren und Stoppen von Kubernetes-Nodes, ‑Pods und ‑Diensten. Wenn Filebeat oder Metricbeat diese Ereignisse erkennt, stellen die Shipper die entsprechenden Metadaten für das jeweilige Ereignis bereit, soweit diese verfügbar sind. Außerdem wenden sie, je nach den Annotationen der gestarteten Kubernetes-Pods, die entsprechenden Einstellungen auf die Ziel-Logdaten und ‑Metriken an. Das hinweisbasierte Autodiscover wird ausführlich in unserem Blogpost zum hinweisbasierten Autodiscover mit Beats in Docker und Kubernetes besprochen.
Monitoring-Architektur
Wie schon im besagten Blogpost werden auch wir eine einfache Multi-Container-Anwendung namens „Cloud-Voting-App“ auf einem Kubernetes-Cluster bereitstellen und die Kubernetes-Umgebung überwachen, in der sich diese Anwendung befindet. In diesem Blogpost gehe ich näher darauf ein, wie beim Erfassen von Logdaten mit Filebeat, beim Erfassen von Metriken mit Metricbeat, beim Ingestieren der erfassten Daten direkt in Elasticsearch und beim Überwachen der Daten mit Kibana vorzugehen ist. Außerdem werde ich zeigen, wie Sie mithilfe von Elastic APM individuell definierte Prometheus-Metriken abrufen können. Die Übersichtsarchitektur wird in der folgenden Abbildung dargestellt. Der Code für dieses Tutorial ist in meinem GitHub-Repo zu finden.
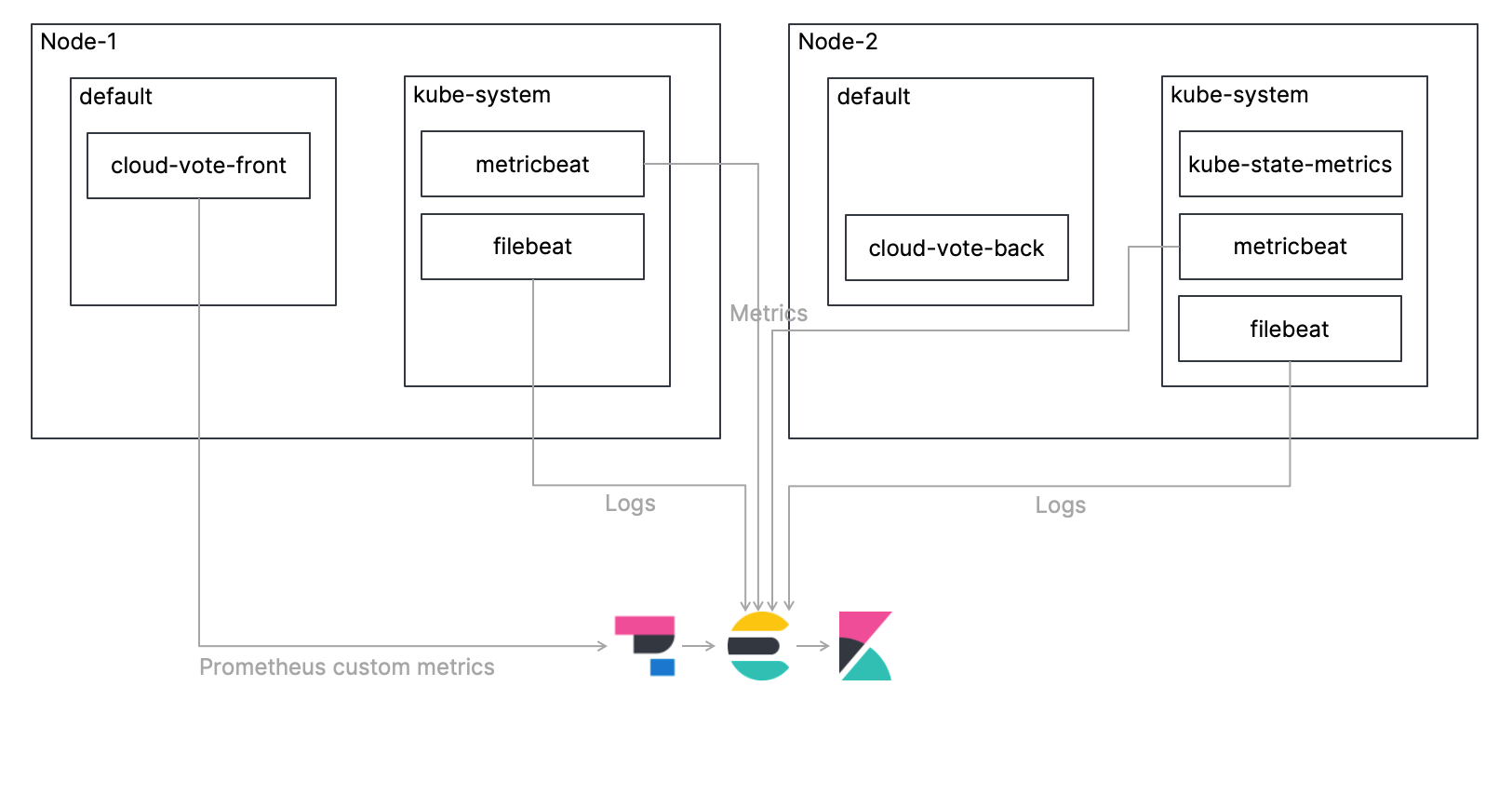
Schauen wir uns die Schritte genauer an!
Bereitstellen von Filebeat als DaemonSet
Pro Kubernetes-Node sollte jeweils nur eine Filebeat-Instanz bereitgestellt werden. Das Manifest für das DaemonSet ist bereits in der Datei elastic/filebeat-kubernetes.yaml definiert. Lassen Sie uns einen Blick auf die relevanten Einstellungen werfen.
Als Erstes verwenden wir den Kubernetes-Autodiscover-Provider, um die Einstellungen für die Anwendungs-Pod-Annotationen für den Umgang mit Logdaten zu konfigurieren. Wie Sie sehen können, sind die Autodiscover-Einstellungen im Abschnitt filebeat.autodiscover definiert. Ich habe die Hinweise aktiviert und den Standardpfad für die Container-Logdaten angegeben. Wenn Sie mehr darüber erfahren möchten, wie Sie Autodiscover für Filebeat konfigurieren können, sehen Sie sich die Filebeat-Dokumentation an.
...
# Zum Aktivieren des hinweisbasierten Autodiscover die `filebeat.inputs`-Konfiguration entfernen und die Kommentierung des Folgenden aufheben:
filebeat.autodiscover:
providers:
- type: kubernetes
node: ${NODE_NAME}
hints.enabled: true
hints.default_config:
type: container
paths:
- /de/var/log/containers/*${data.kubernetes.container.id}.log
...
Im Gegensatz zu oben müssen wir hier lediglich die URL und die Anmeldeinformationen für unseren Elasticsearch-Cluster hinzufügen.
...
containers:
- name: filebeat
image: docker.elastic.co/beats/filebeat:7.13.0
args: {
"-c", "/de/etc/filebeat.yml",
"-e",
]
env:
- name: ELASTICSEARCH_HOST
value: elasticsearch
- name: ELASTICSEARCH_PORT
value: "9200"
- name: ELASTICSEARCH_USERNAME
value: elastic
- name: ELASTICSEARCH_PASSWORD
value: changeme
- name: ELASTIC_CLOUD_ID
value:
- name: ELASTIC_CLOUD_AUTH
value:
...
Bereitstellen von „kube-state-metrics“
Bei „kube-state-metrics“ handelt es sich um ein Kubernetes-Add-on, das die in Kubernetes gespeicherten Objekte überwacht, um den Zustand der in einem Kubernetes-Cluster bereitgestellten Kubernetes-Objekte zu erkennen. So kann es z. B. Informationen dazu liefern, wie viele Pods zum aktuellen Zeitpunkt im Cluster bereitgestellt sind, welchen CPU-Cores im Cluster Last zugewiesen werden kann, wie viele Aufträge erfolglos geblieben sind usw. usf. „kube-state-metrics“ muss eigens von Ihnen bereitgestellt werden, da es nicht zur standardmäßigen Ausstattung von Kubernetes-Clustern gehört. Unter examples/standard ist ein Muster-Manifest von „kube-state-metrics“ zu finden. Wenn Sie mehr über „kube-state-metrics“ erfahren möchten, sehen Sie sich dieses GitHub-Repo an.
Bereitstellen von Metricbeat als DaemonSet
Wie für Filebeat gilt auch für Metricbeat: Pro Kubernetes-Node sollte jeweils nur eine Instanz bereitgestellt werden. Das Manifest für das DaemonSet ist bereits in der Datei elastic/metricbeat-kubernetes.yaml definiert. Es ist allerdings ein wenig komplizierter als bei Filebeat. Sehen wir uns die wichtigsten Einstellungen einmal näher an:
Die Einstellungen für Autodiscover sind im Abschnitt metricbeat.autodiscover definiert. Die erste Einstellung - type: kubernetes gilt für den gesamten Kubernetes-Cluster. Wir nutzen hier das Kubernetes-Modul von Metricbeat, um Metriken für den gesamten Kubernetes-Cluster zu konfigurieren. Die erste - module: kubernetes-Konfiguration richtet die Metriken ein, die wir vom oben erwähnten „kube-state-metrics“ erhalten. Die zweite - module: kubernetes-Konfiguration wird für das Monitoring des Kubernetes-API-Servers („kube-apiserver“) eingerichtet, der das Kernstück der Kubernetes-Steuerungsebene bildet, die die Kubernetes-API präsentiert. Wenn Sie mehr über das Kubernetes-Modul von Metricbeat erfahren möchten, sehen Sie sich die Metricbeat-Dokumentation an.
metricbeat.autodiscover:
providers:
- type: kubernetes
scope: cluster
node: ${NODE_NAME}
unique: true
templates:
- config:
- module: kubernetes
hosts: ["kube-state-metrics:8080"]
period: 10s
add_metadata: true
metricsets:
- state_node
- state_deployment
- state_daemonset
- state_replicaset
- state_pod
- state_container
- state_cronjob
- state_resourcequota
- state_statefulset
- state_service
- module: kubernetes
metricsets:
- apiserver
hosts: ["https://${KUBERNETES_SERVICE_HOST}:${KUBERNETES_SERVICE_PORT}"]
bearer_token_file: /de/var/run/secrets/kubernetes.io/serviceaccount/token
ssl.certificate_authorities:
- /de/var/run/secrets/kubernetes.io/serviceaccount/ca.crt
period: 30s
Zusätzlich sind Hinweise definiert, die den Kubernetes-Autodiscover-Provider nutzen, sodass die Verarbeitung der Metriken mittels Annotations-Einstellungen für den Anwendungs-Pod möglich ist. Wenn Sie mehr darüber erfahren möchten, wie Sie Autodiscover für Metricbeat konfigurieren können, sehen Sie sich die Metricbeat-Dokumentation an.
# Zum Aktivieren des hinweisbasierten Autodiscover die Kommentierung des Folgenden aufheben:
- type: kubernetes
node: ${NODE_NAME}
hints.enabled: true
Die folgenden ConfigMap-Einstellungen gelten für „node/system/pod/container/volume“ und damit für Standard-Metricsets des Metricbeat-eigenen Kubernetes-Moduls. Diese Metriken werden vom „kubelet“-Endpoint der einzelnen Nodes bezogen.
kubernetes.yml: |-
- module: kubernetes
metricsets:
- node
- system
- pod
- container
- volume
period: 10s
host: ${NODE_NAME}
hosts: ["https://${NODE_NAME}:10250"]
bearer_token_file: /de/var/run/secrets/kubernetes.io/serviceaccount/token
ssl.verification_mode: "none"
Wie bei Filebeat müssen wir hier lediglich die URL und die Anmeldeinformationen für unseren Elasticsearch-Cluster hinzufügen.
Bereitstellen der Anwendung
Wie schon im vorherigen Blogpost werden wir die Cloud-Voting-App bereitstellen. Die Benutzeroberfläche der Anwendung wurde mit Python/Flask erstellt. Die Datenkomponente nutzt Redis. Wie Sie sich vielleicht erinnern, wurde die Anwendung mit dem Prometheus-Python-Client instrumentiert, um individuell definierte Prometheus-Metriken zur Verfügung zu stellen. Wie kommen wir nun aber an die individuell definierten Prometheus-Metriken, wenn wir hier gar kein Prometheus haben? Ab Version 7.12 können wir den Elastic APM Agent nutzen, um individuell definierte Prometheus-Metriken zu erhalten!
Zunächst importiert die Anwendung ElasticAPM und konfiguriert die Elastic APM Agent-Einstellungen unter Verwendung der Umgebungsvariablen. SERVICE_NAME ist eine frei festlegbare Zeichenfolge, die als Kennung der Anwendung verwendet wird, ENVIRONMENT ist eine frei festlegbare Zeichenfolge zur Benennung der Anwendungsumgebung und SECRET_TOKEN sowie SERVER_URL werden für die Kommunikation mit dem APM-Server benötigt. Schließlich gibt es noch den Parameter PROMETHEUS_METRICS, der angibt, ob die Metrik vom Prometheus-Client bezogen werden soll.
from elasticapm.contrib.flask import ElasticAPM
...
app = Flask(__name__)
...
# Elastic APM-Konfigurationen
app.config['ELASTIC_APM'] = {
# Erforderlichen Dienstnamen festlegen; folgende Zeichen sind erlaubt:
# a–z, A–Z, 0–9, -, _ und Leerzeichen
'SERVICE_NAME': os.environ['SERVICE_NAME'],
#
# Zu verwenden, wenn APM-Server ein Token benötigt
'SECRET_TOKEN': os.environ['SECRET_TOKEN'],
#
# Benutzerdefinierte URL für den APM-Server festlegen (Standard: http://localhost:8200)
'SERVER_URL': os.environ['SERVER_URL'],
#
# Umgebung festlegen
'ENVIRONMENT': os.environ['ENVIRONMENT'],
#
# prometheus_metrics festlegen
'PROMETHEUS_METRICS': os.environ['PROMETHEUS_METRICS'],
}
apm = ElasticAPM(app)
Das Folgende ist das Manifest für die Bereitstellung der Cloud-Voting-App auf einem Kubernetes-Cluster. Die entsprechende Datei befindet sich unter elastic/cloud-vote-all-in-one-redis-aks.yaml. Zunächst einmal werden für die Benutzeroberfläche cloud-vote-front die Variablen, die für den oben erwähnten APM Agent benötigt werden, in der „Container“-Spezifikation als Umgebungsvariablen eingerichtet. In diesem Fall werden keine Pod-spezifischen Annotationen spezifiziert, sodass sowohl die Logdaten als auch die Metriken mit den Standardeinstellungen beschafft werden.
apiVersion: apps/v1
kind: Deployment
metadata:
name: cloud-vote-front
spec:
replicas: 1
selector:
matchLabels:
app: cloud-vote-front
strategy:
rollingUpdate:
maxSurge: 1
maxUnavailable: 1
minReadySeconds: 5
template:
metadata:
labels:
app: cloud-vote-front
spec:
nodeSelector:
"beta.kubernetes.io/os": linux
containers:
- name: cloud-vote-front
image: your image name
ports:
- containerPort: 80
resources:
requests:
cpu: 250m
limits:
cpu: 500m
env:
- name: REDIS
value: "cloud-vote-back"
- name: SERVICE_NAME
value: "cloud-voting"
- name: SECRET_TOKEN
value: "APM Server secret token"
- name: SERVER_URL
value: "APM Server URL"
- name: ENVIRONMENT
value: "Production"
- name: PROMETHEUS_METRICS
value: "True"
Auf der anderen Seite, dem Backend, verwendet cloud-vote-redis Pod-Annotationen, um das „redis“-Modul von Filebeat für Logdaten und das „redis“-Modul von Metricbeat für Metriken zu aktivieren. Dazu werden die jeweils erforderlichen Einstellungen angewendet. Während „cloud-vote-front“ zum Erfassen von Logdaten und Metriken mit Beats die Standardeinstellungen verwendet, greift „cloud-vote-back“ zum Erfassen von Logdaten und Metriken auf das Beats-eigene „redis“-Modul zurück. Da die Art und Weise, wie Logdaten und Metriken erfasst werden sollen, nicht im Beats-Manifest, sondern im Manifest der Anwendung festgelegt ist, lassen sich die Zuständigkeiten zwischen Entwicklungs- und Observability-Plattformteam streng voneinander abtrennen.
apiVersion: apps/v1
kind: Deployment
metadata:
name: cloud-vote-back
spec:
replicas: 1
selector:
matchLabels:
app: cloud-vote-back
template:
metadata:
labels:
app: cloud-vote-back
annotations:
co.elastic.logs/enabled: "true"
co.elastic.logs/module: redis
co.elastic.logs/fileset.stdout: log
co.elastic.metrics/enabled: "true"
co.elastic.metrics/module: mysql
co.elastic.metrics/hosts: "${data.host}:6379"
spec:
nodeSelector:
"beta.kubernetes.io/os": linux
containers:
- name: cloud-vote-back
image: redis
ports:
- containerPort: 6379
name: redis
Zugreifen auf Kibana
Jetzt haben wir alle erforderlichen Komponenten bereitgestellt. Wir werden jetzt ein paar Mal mit der Cloud-Voting-App voten und dann auf Kibana zugreifen.
Observability im Überblick
Zunächst: Wenn wir Elastic Observability in Kibana öffnen, werden die Logging-Frequenz der Log-Inputs aus Filebeat und die Zusammenfassung der Metriken-Inputs aus Metricbeat angezeigt, ohne dass etwas passiert. Dies kommt daher, dass Filebeat und Metricbeat Daten standardmäßig im ECS-Format ingestieren.
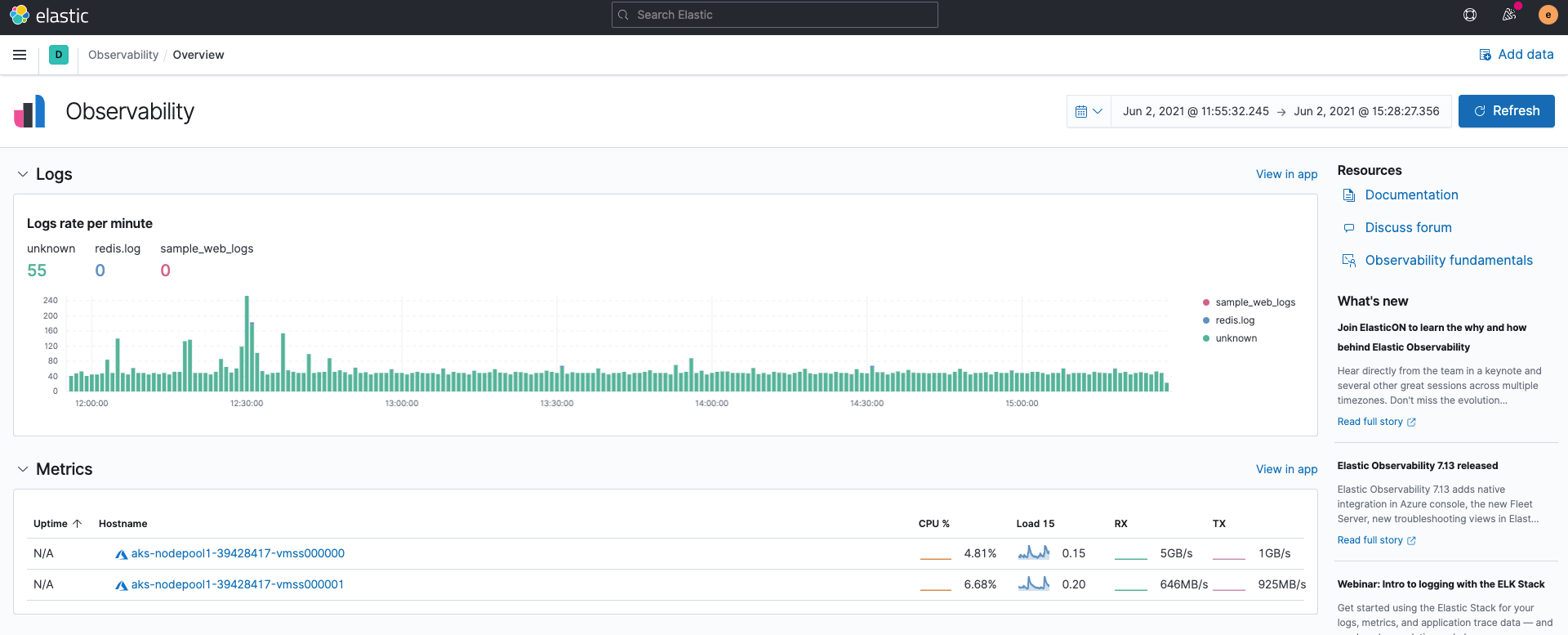
Logdaten
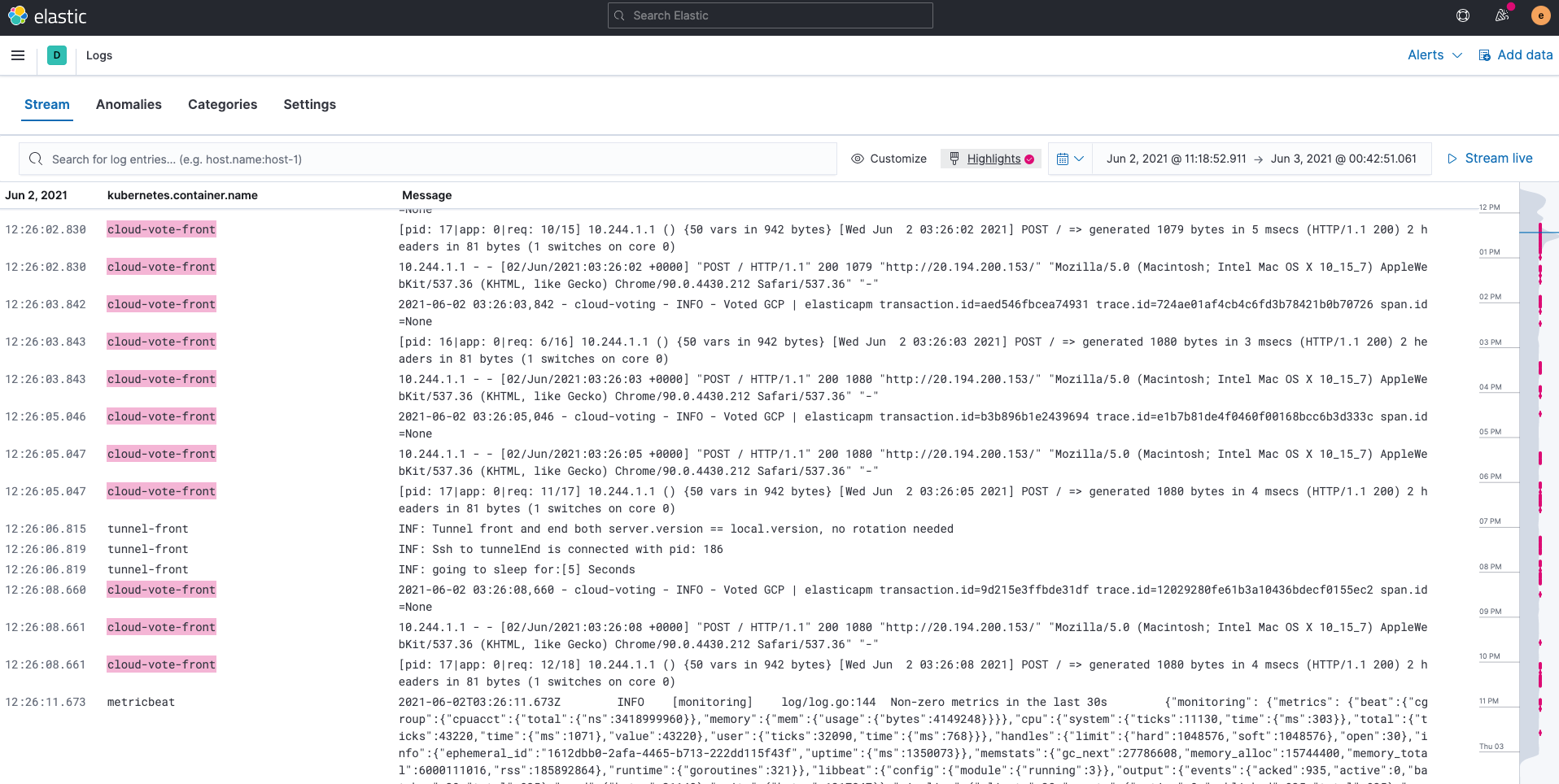
Von Filebeat ingestierte Logdaten werden in den „filebeat-*“-Indizes gespeichert. Wenn wir die in Elasticsearch gespeicherten Logdaten durchsuchen, filtern und „tailen“ wollen, steht dafür die Logs-Anwendung in Kibana zur Verfügung. Wir können auch Zeichenfolgen hervorheben, wie wir das im folgenden Beispiel mit der Zeichenfolge cloud-vote-front getan haben.
Metriken
Von Metricbeat ingestierte Metriken werden in den „metricbeat-*“-Indizes gespeichert. Die in Elasticsearch verfügbaren Metriken lassen sich am einfachsten über die Metrics-Anwendung in Kibana betrachten. Die Verwendung der Ansicht Kubernetes Pods, wie unten gezeigt, ordnet Kubernetes-Nodes und ‑Pods zu und zeigt, wie die einzelnen Ressourcen genutzt werden.
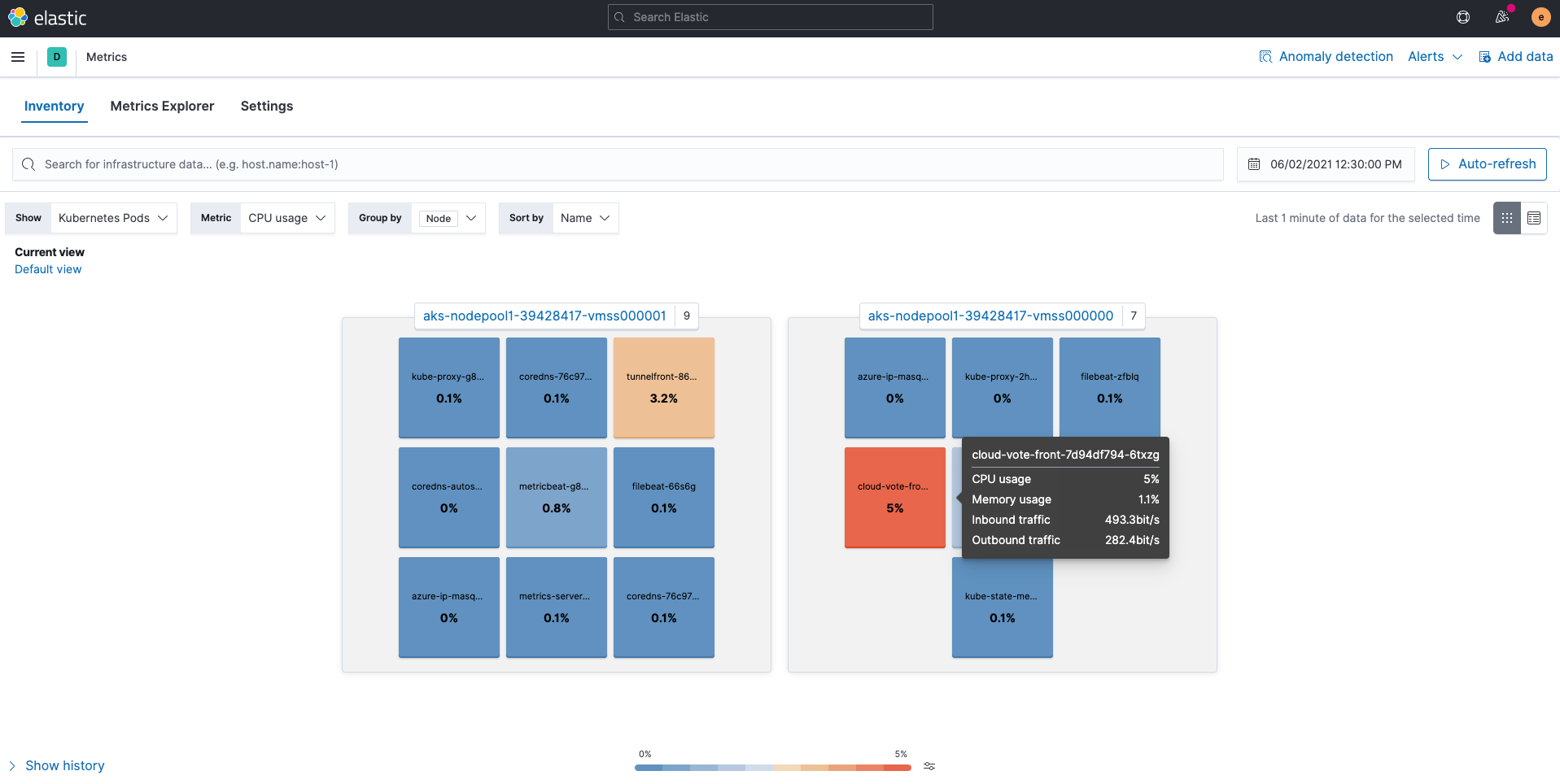
Wir können auch auf einen Pod klicken, um zu anderen Anwendungen zu gelangen, wie Pod-Logdaten oder APM-Traces, und dabei den Kontext beizubehalten. Wie Sie sehen, wird auf dem Bildschirm View details for kubernetes.pod.uid a47d81b1-02d7-481a-91d4-1db9fe82d7a7 angezeigt.
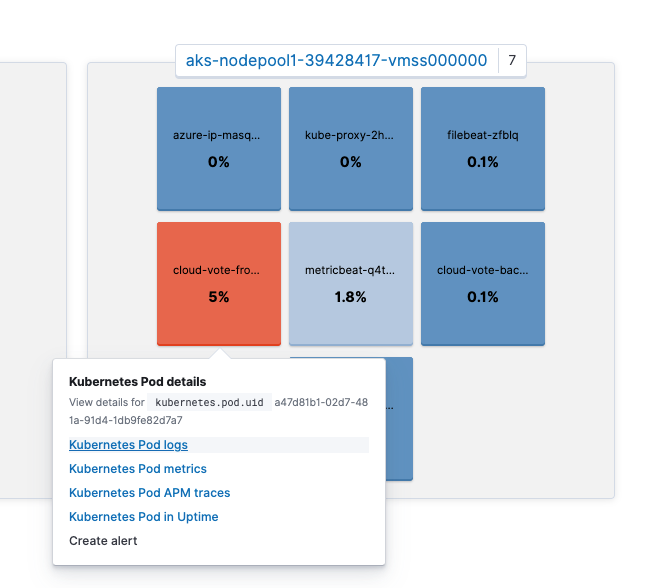
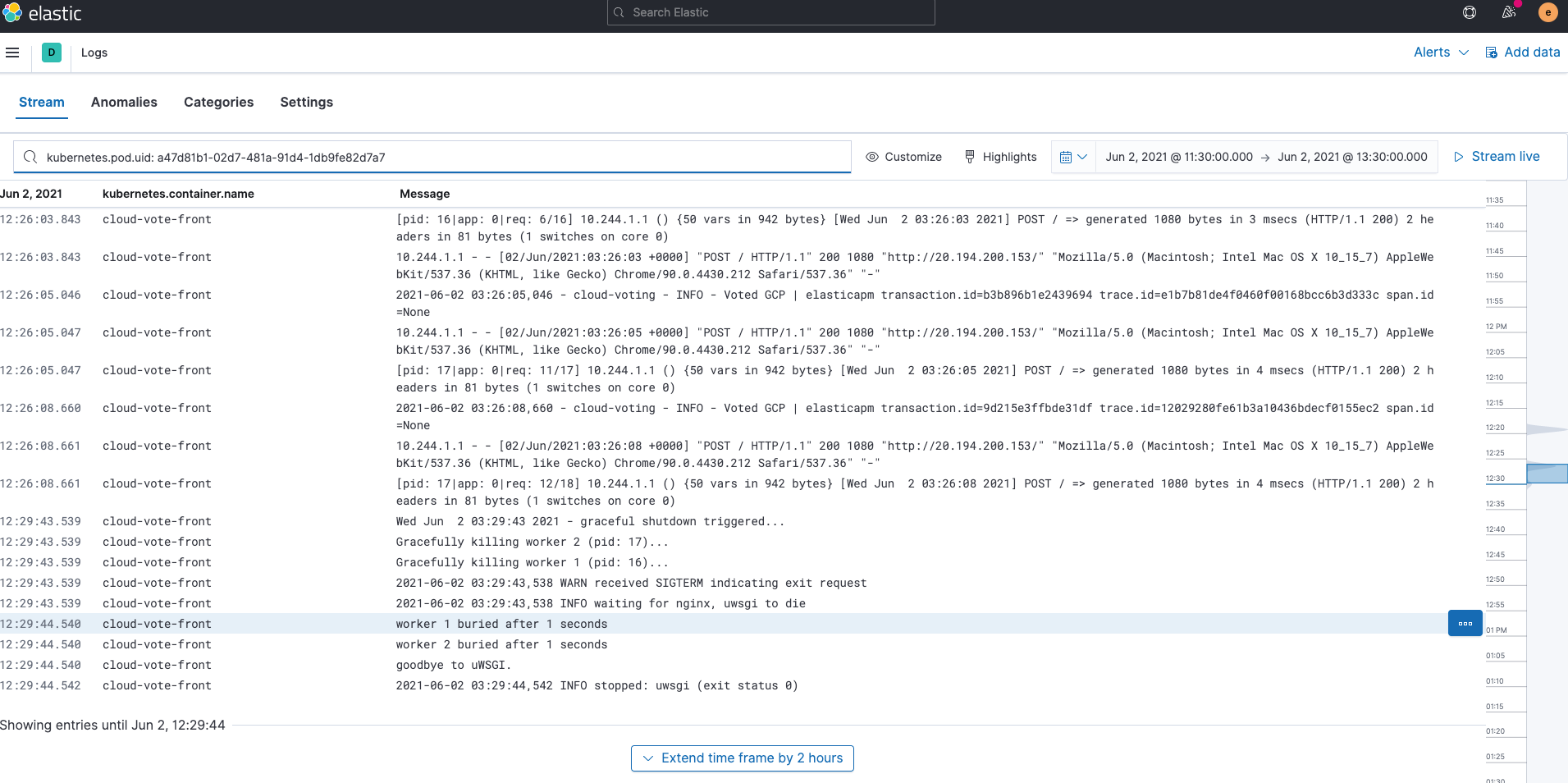
Wenn wir auf Kubernetes Pod logs klicken, gelangen wir zu den Logdaten für diesen Pod. Ist Ihnen aufgefallen, dass die Suchleiste in der Logs-Anwendung bereits kubernetes.pod.uid: a47d81b1-02d7-481a-91d4-1db9fe82d7a7 enthält? Dadurch, dass der Kontext auf diese Weise erhalten bleibt, kann Kibana nahtlos von Anwendung zu Anwendung wechseln und sofort relevante Ergebnisse zurückgeben.
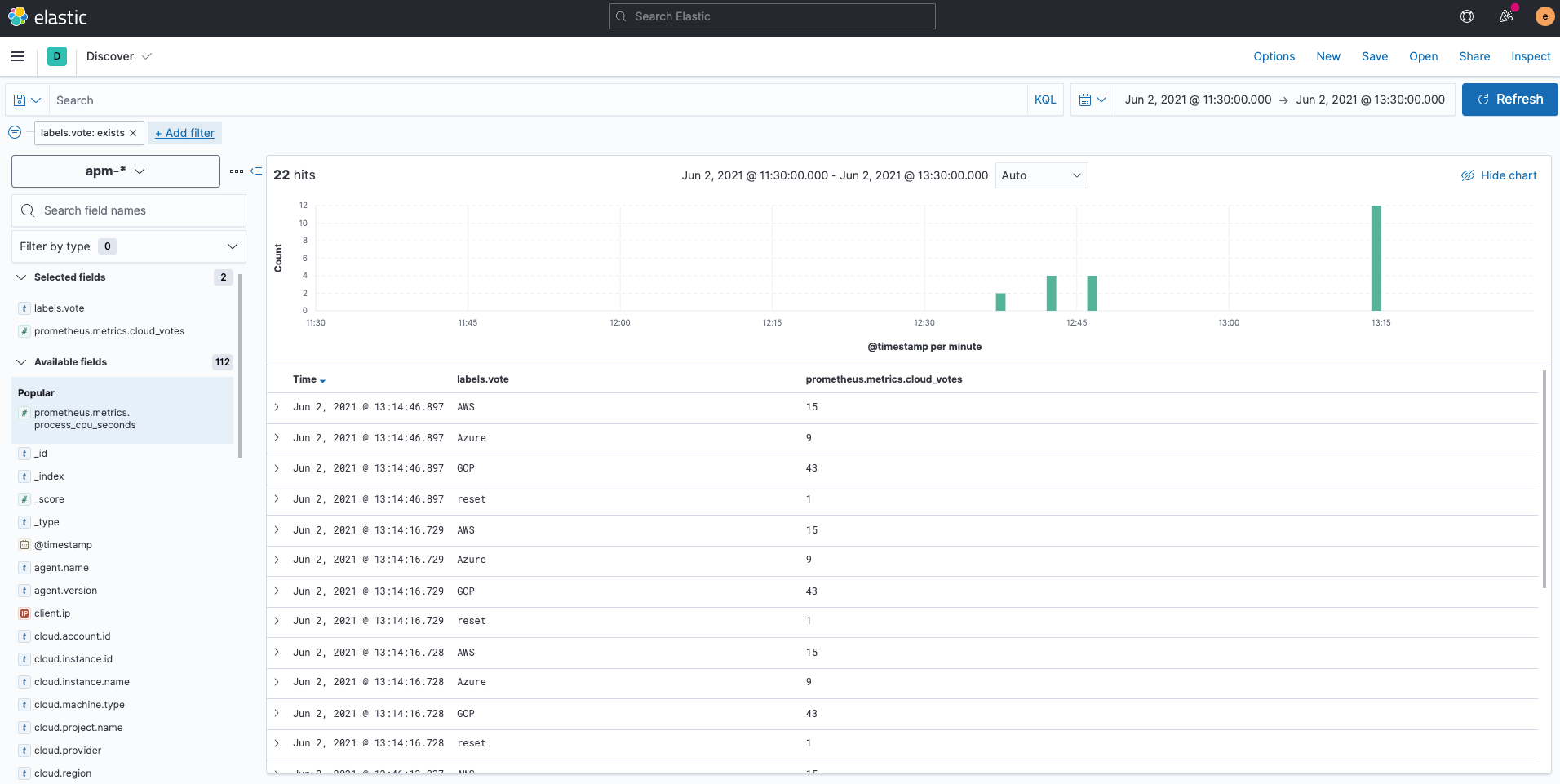
Was ist denn nun mit den individuell definierten Prometheus-Metriken? Individuell definierte Metriken, die vom Prometheus-Python-Client gespeichert werden, werden über den Elastic APM Agent in „apm-*“-Indizes geschrieben. In Kibana Discover ist zu sehen, dass sie im Feld prometheus.metrics.cloud_votes erfasst werden. Die Variable im POST-Request wird als labels.vote gespeichert. Wenn Sie mehr über das Erfassen individuell definierter Prometheus-Metriken mit dem Elastic APM-Python-Agent erfahren möchten, sehen Sie sich die APM-Dokumentation an.
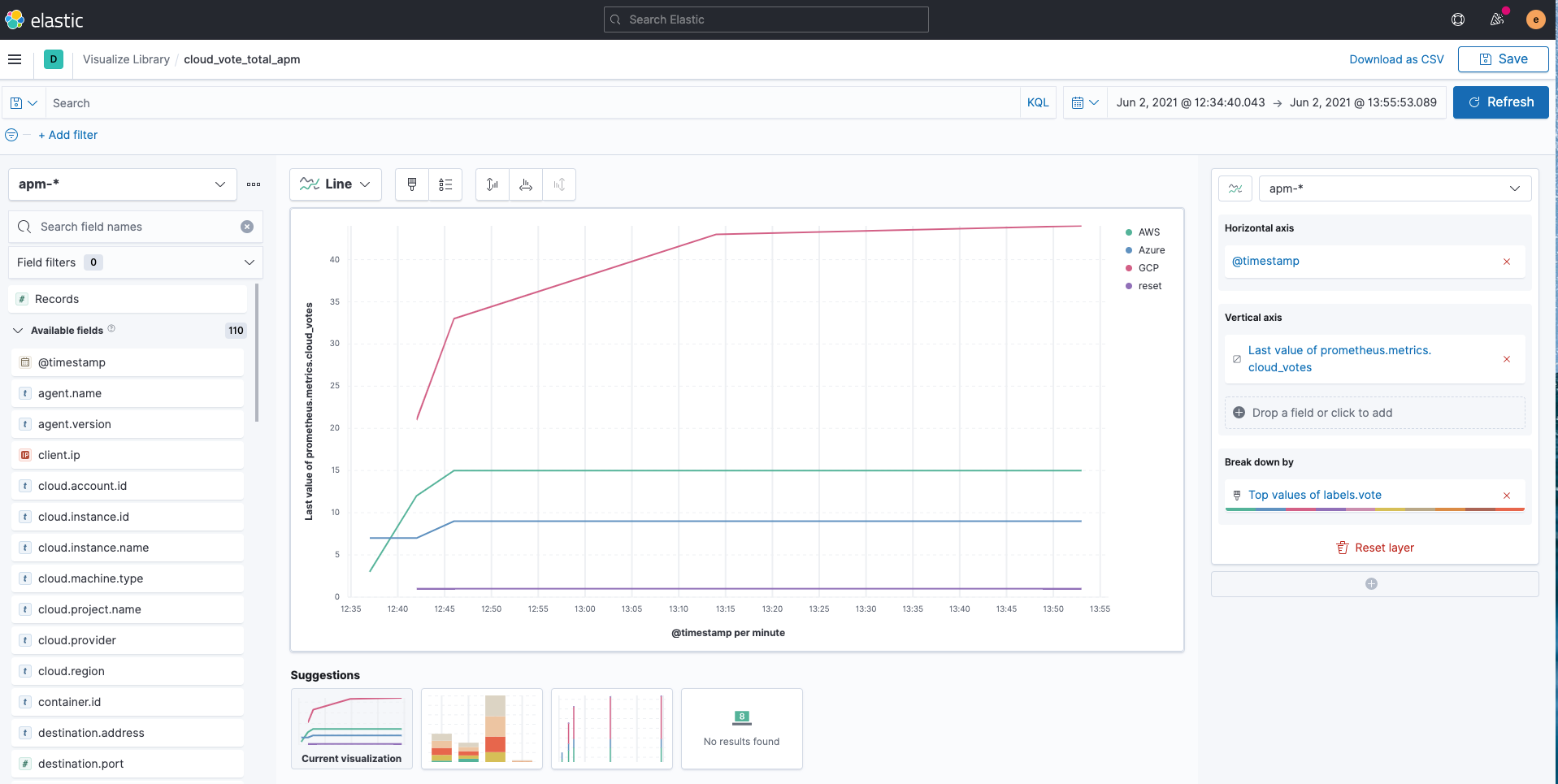
Wenn nötig, können wir die „apm-*“-Indizes ganz einfach wie folgt mit Kibana Lens visualisieren:
Vordefinierte Dashboards
Für den cloud-vote-back-Pod, der Redis verwendet, haben wir sowohl für Filebeat als auch für Metricbeat das „redis“-Modul aktiviert. Das sorgt auch für die Voraberstellung zugehöriger Standard-Dashboards. Auf diese Weise ist es möglich, Redis-Logdaten und ‑Metriken sofort und ohne zusätzliche Konfiguration zu erstellen.
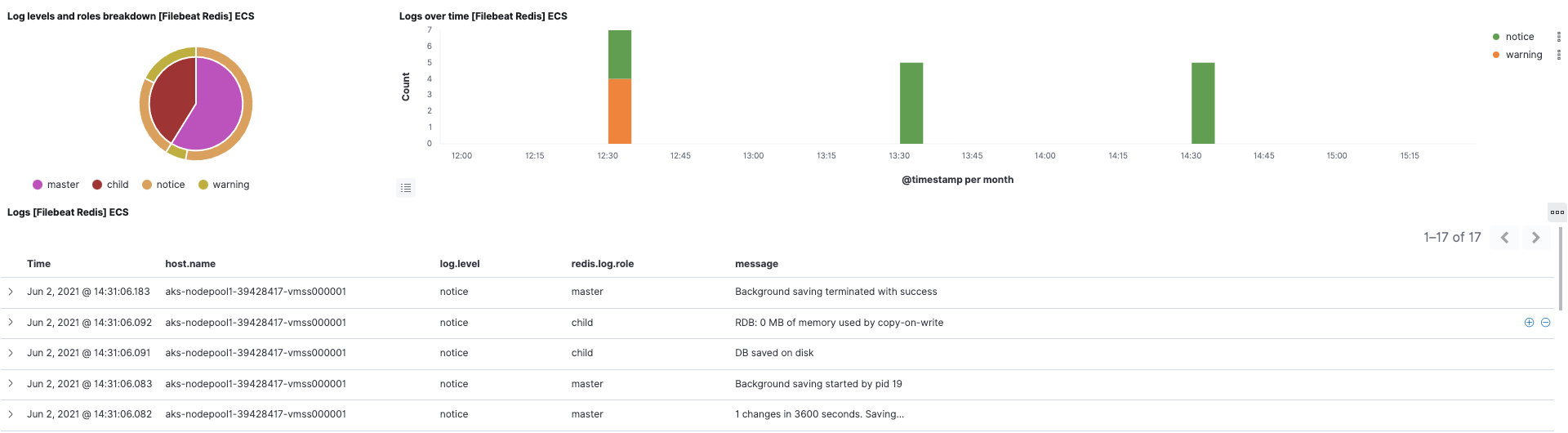
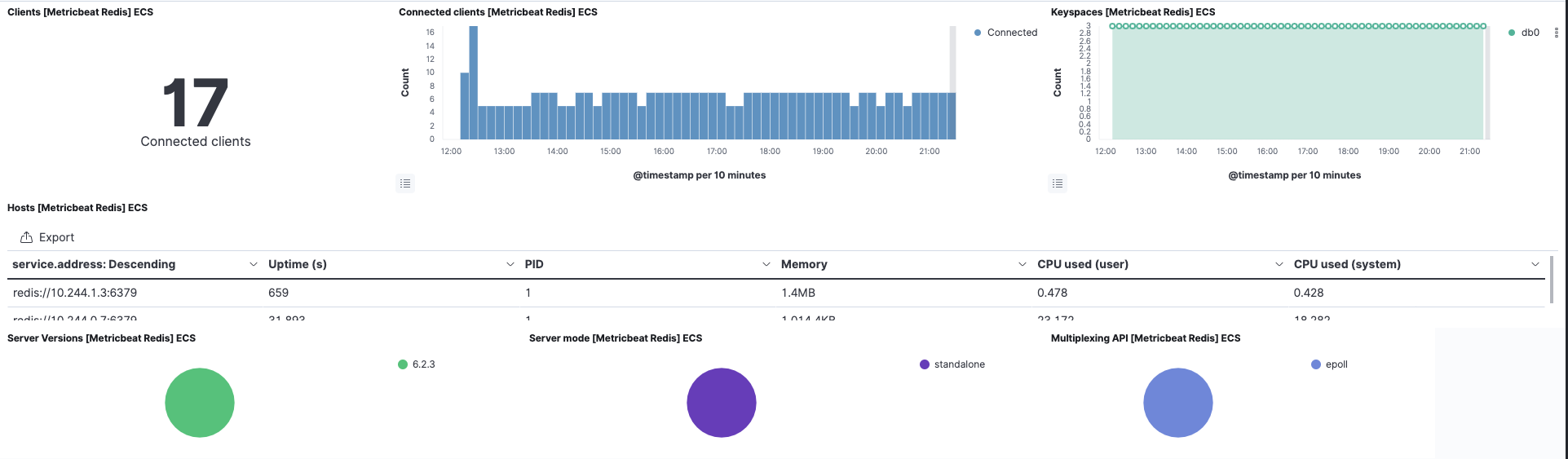
Außerdem steht dank des Metricbeat-eigenen Kubernetes-Moduls auch das Kubernetes-Dashboard zur Nutzung bereit.
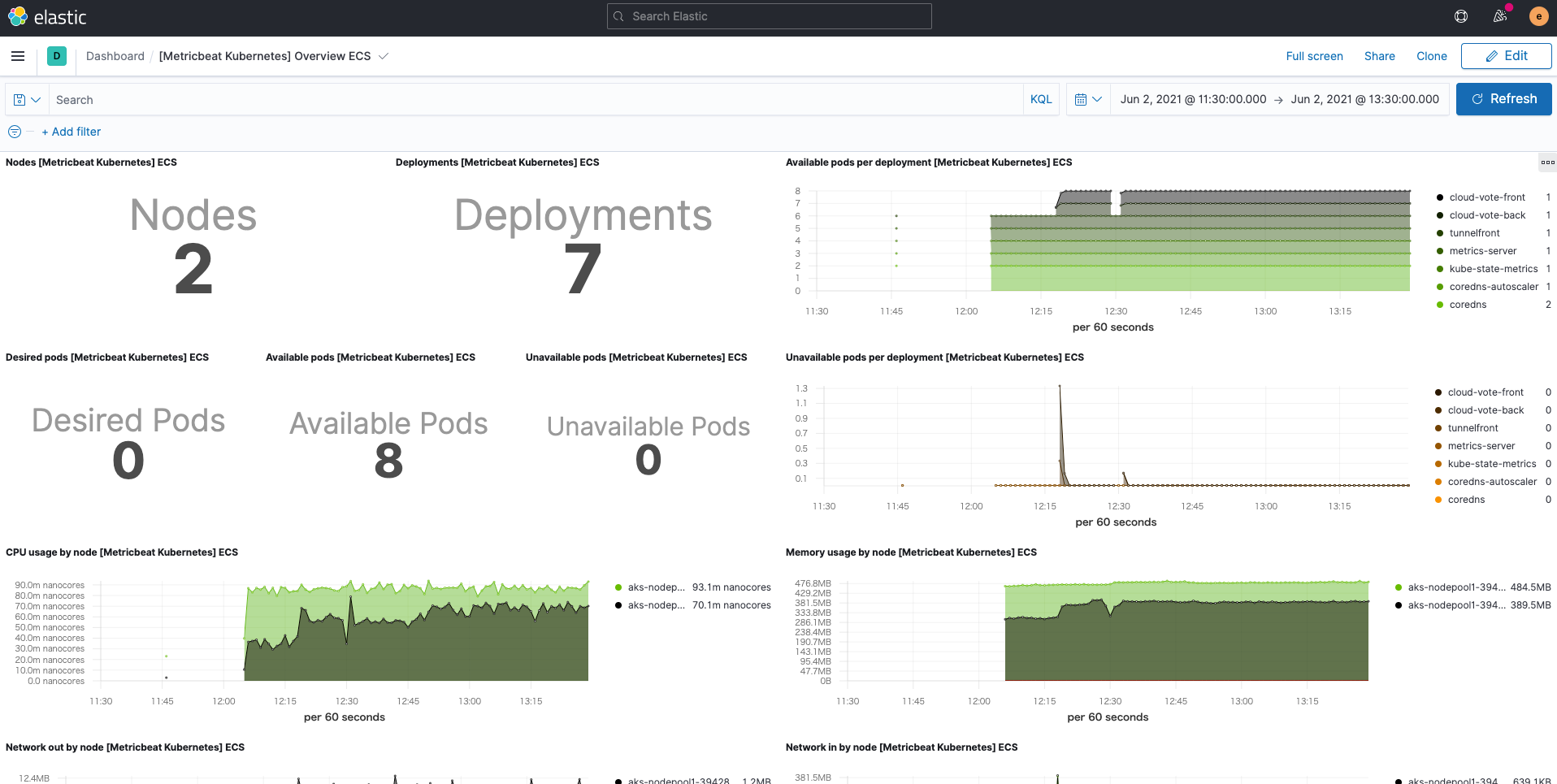
Zusammenfassung
In diesem Blogpost haben wir eine eher dem Elastic-Stil entsprechende Möglichkeit präsentiert, den Elastic Stack mithilfe von Filebeat und Metricbeat mit Logdaten und Metriken für das Kubernetes-Monitoring zu versehen. Außerdem wurde gezeigt, wie der Elastic APM Agent eingesetzt werden kann, um individuell definierte Prometheus-Metriken zu beschaffen. Wenn auch Sie beginnen möchten, Ihre Kubernetes-Umgebungen zu überwachen, können Sie sich registrieren, um Elastic Cloud kostenlos auszuprobieren oder den Elastic Stack herunterladen und ihn selbst hosten. Elastic Observability ermöglicht eine effizienteres und effektiveres Monitoring. Für hochgradig automatisierte, verwertbare und umfassende Observability-Einblicke und ‑Funktionen lässt es sich auch mit Elastic-Machine-Learning- und Kibana-Alerting-Funktionen verknüpfen. Wenn Sie auf Probleme stoßen oder Fragen haben, wird Ihnen in unseren Discuss-Foren sicher schnell weitergeholfen.
Ein weiterer Blogpost mit Informationen zu zusätzlichen Möglichkeiten für das Monitoring von Kubernetes ist bereits in Arbeit.