Schnellere Ergebnisse durch Optimieren von Abfragen mit sortierten Suchergebnissen in Elasticsearch


 Share on Twitter
Share on TwitterAuf Twitter teilen

 Share on LinkedIn
Share on LinkedInAuf LinkedIn teilen

 Share on Facebook
Share on FacebookAuf Facebook teilen

 Share by Email
Share by EmailPer E-Mail teilen

 Print this page
Print this pageDrucken
Es ist sehr üblich, Elasticsearch aufzufordern, die Suchergebnisse nach einem bestimmten Feld zu sortieren. Daher haben wir viel Zeit und Mühe investiert, das Sortieren von Suchergebnissen bei Abfragen zu optimieren, damit die Nutzer:innen schneller Ergebnisse erhalten. In diesem Blogpost sollen einige dieser Optimierungen für Suchen in numerischen und Datumsfeldern beschrieben werden.
So funktionieren Abfragen mit sortierten Suchergebnissen
Wenn Sie Dokumente finden möchten, die einem Filter entsprechen, und angeben, dass die Ergebnisse nach einem bestimmten Feld sortiert werden sollen, untersucht Elasticsearch die doc_value-Werte dieses Feldes für alle Dokumente, die dem Filter entsprechen, und wählt dann die k Dokumente mit den am besten passenden Werten aus. Im schlimmsten Fall – bei einem sehr breiten Filter (z. B. bei einer match_all-Abfrage) – müssen die doc_value-Werte für alle Dokumente im Index untersucht und verglichen werden. Bei großen Indizes kann dies richtig lange dauern.
Eine Möglichkeit, Abfragen mit Sortierung anhand eines bestimmten Feldes zu optimieren, besteht darin, mit Indexsortierung zu arbeiten und den ganzen Index in diesem Feld zu sortieren. Wenn der Index nach einem Feld sortiert wird, werden dessen doc_value-Werte ebenfalls sortiert. Um eine nach einem Feld sortierte Liste der Top‑k-Dokumente zu erhalten, müssen wir uns lediglich die ersten k Dokumente zur Brust nehmen und können den Rest getrost ignorieren. Dadurch werden Abfragen mit sortierten Suchergebnissen superschnell.
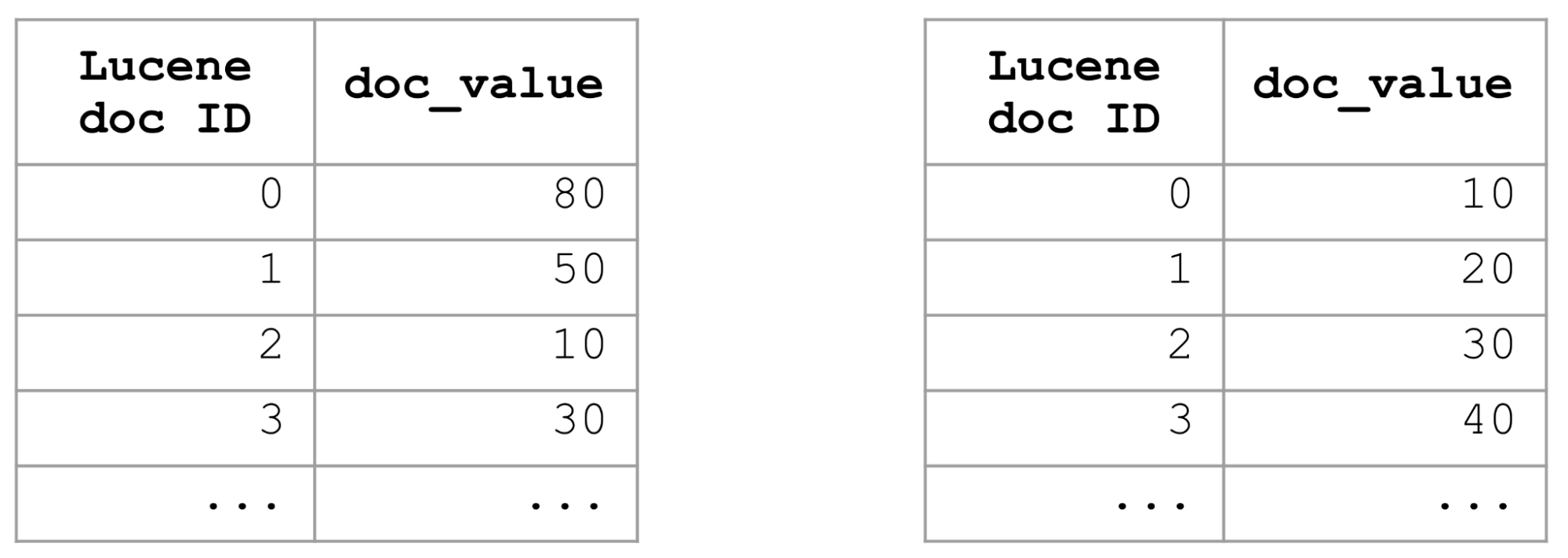
Die Indexsortierung ist zwar eine tolle Lösung, sie lässt sich aber nur auf eine einzige Weise durchführen. Sie eignet sich daher nicht für Abfragen mit sortierten Suchergebnissen, bei denen andere Sortierkriterien, wie z. B. absteigend und aufsteigend, andere Felder oder andere Kombinationen als die verwendet werden, die in der jeweiligen Indexsortierdefinition festgelegt sind. Es brauchte also andere, flexiblere Ansätze zur Beschleunigung von Abfragen mit sortierten Suchergebnissen.
Optimieren von distance_feature-Abfragen mit sortierten Suchergebnissen
In der Vergangenheit haben wir erhebliche Geschwindigkeitssteigerungen bei begriffsbasierten, nach _score sortierten Abfragen erzielt, indem wir für jeden Block von Dokumenten dessen maximale Auswirkung gespeichert haben – eine Kombination aus Begriffshäufigkeit und Dokumentenlänge. Während der Abfragezeit können wir schnell beurteilen, ob ein Block von Dokumenten Chancen hat, unter den Top k zu landen, indem wir seine maximale Auswirkung betrachten. Ist ein Block nicht konkurrenzfähig, können wir ihn vollständig überspringen, wodurch Abfragen deutlich schneller werden.
Wir dachten uns, dass wir einen ähnlichen Ansatz verfolgen könnten, um Abfragen mit sortierten Suchergebnissen für numerische und Datumsfelder zu beschleunigen. Es stellte sich heraus, dass dies möglich war, indem man die Sortierung durch eine distance_feature-Abfrage ersetzte. distance_feature-Abfragen sind interessant, weil sie die k Dokumente zurückgeben, die einem bestimmten Ursprung am nächsten liegen. Wenn wir den Mindestwert für das Feld als Ursprung verwenden, erhalten wir die Top‑k-Dokumente, aufsteigend sortiert. Wenn wir den Höchstwert als Ursprung verwenden, erhalten wir die Top‑k-Dokumente in absteigender Reihenfolge.
Die interessanteste Eigenschaft der distance_feature-Abfrage war für uns, das sie nicht konkurrenzfähige Blöcke von Dokumenten effizient außer Acht lassen kann. Das schafft sie, indem sie sich auf die Eigenschaften von BKD-Bäumen verlässt, die in Elasticsearch für das Indexieren von numerischen und Datumsfeldern verwendet werden. Ähnlich wie ein Postings-Index für ein Textfeld in Blöcke von Dokumenten unterteilt ist, ist ein BKD-Index in Zellen unterteilt, wobei jede Zelle ihren Mindest- und ihren Höchstwert kennt. So kann eine distance_feature-Abfrage allein durch die Untersuchung der Mindest- und der Höchstwerte der Zellen effizient nicht konkurrenzfähige Zellen von Dokumenten überspringen. Damit diese Sortieroptimierung funktioniert, muss das numerische oder Datumsfeld sowohl indexiert sein als auch doc_value-Werte haben.
Durch Ersetzen der Sortierung nach doc_value-Werten durch eine distance_feature-Abfrage konnten wir große Geschwindigkeitssteigerungen erzielen (bei einigen Datensätzen sind die Abfragen bis zu 35‑mal so schnell). Wir haben diese Form der Sortieroptimierung bei date- und long-Feldern in Elasticsearch 7.6 eingeführt.
Optimieren von Abfragen mit sortierten Suchergebnissen mit search_after
So erfreulich diese Geschwindigkeitssteigerungen für uns waren, so sehr fehlte uns eine gute Lösung für das Sortieren mit einem search_after-Parameter. Das Sortieren mit search_after wird viel genutzt, da Nutzer:innen oft nicht nur an der ersten Seite der Ergebnisse, sondern auch an den folgenden Seiten interessiert sind. Wir haben uns daher entschieden, nicht mehr auf das Umschreiben von Abfragen mit sortierten Suchergebnissen in Elasticsearch zu setzen, sondern diese Sortieroptimierung Komparatoren und Kollektoren in Lucene zu überlassen und nicht konkurrenzfähige Dokumente zu ignorieren. Da Komparatoren und Kollektoren in Lucene bereits mit search_after arbeiten, haben wir damit auch eine Lösung für dieses Problem gefunden. Den numerischen Komparatoren von Lucene wurde derselbe Elasticsearch-Code hinzugefügt, den distance_feature-Abfragen zum Überspringen von nicht konkurrenzfähigen Blöcken von Dokumenten verwenden.
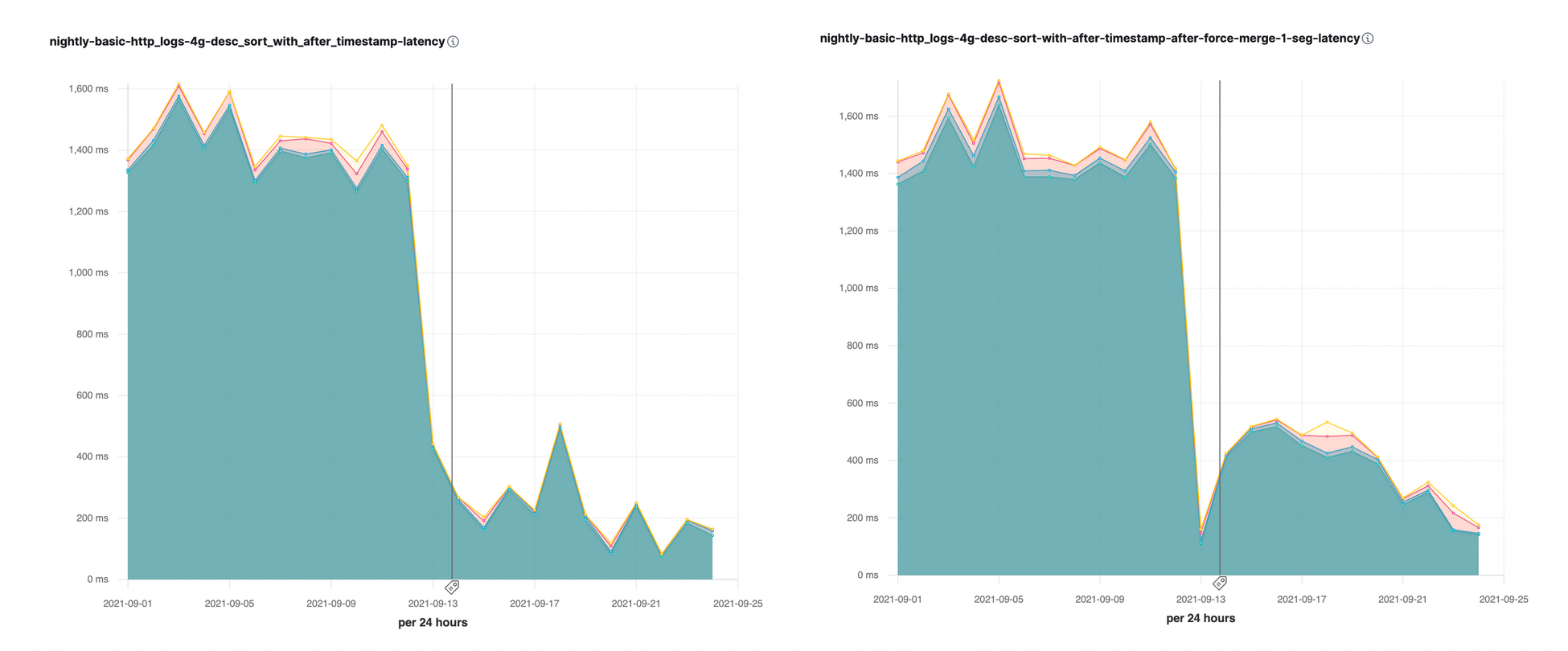
Diese Sortieroptimierung mit dem search_after-Parameter war erstmals in Elasticsearch 7.16 verfügbar. Bei einigen unserer nächtlichen Performance-Benchmarks waren daraufhin sofort deutliche Geschwindigkeitsbeschleunigungen (bis zum 10-Fachen) zu beobachten:
Optimieren der Sortierung über mehrere Segmente
Eine Shard besteht aus mehreren Segmenten. Da Elasticsearch die Segmente zum Suchzeitpunkt sequenziell untersucht, wäre es sehr vorteilhaft, die Verarbeitung mit dem Segment zu beginnen, das am wahrscheinlichsten Dokumente mit Top‑k-Werten enthält. Sobald wir Dokumente mit Top‑k-Werten gesammelt haben, können wir sehr schnell andere Segmente ignorieren, die nur schlechtere Werte enthalten.
Mit welchen Segmenten die Verarbeitung beginnen sollte, hängt stark vom Anwendungsfall ab. Bei Zeitreihenindizes besteht die häufigste Anforderung darin, die Ergebnisse absteigend nach dem timestamp-Feld zu sortieren, da hier vor allem die neuesten Ereignisse interessieren. Um diese Art der Sortierung für Zeitreihenindizes zu optimieren, haben wir damit begonnen, die Segmente absteigend nach dem @timestamp-Feld zu sortieren. So können wir die Verarbeitung mit einem Segment beginnen, das die neuesten Daten enthält, im Idealfall im ersten Segment die Dokumente sammeln, die laut Zeitstempel die neuesten sind, und alle anderen Segmente überspringen. Bei Abfragen, deren Suchergebnisse absteigend nach dem timestamp-Feld sortiert werden sollen, ergaben sich daraus durchaus beachtliche Geschwindigkeitssteigerungen.
Da kleinere Segmente zu größeren Segmenten zusammengeführt werden, sollten wir vermeiden, dass die neuesten Dokumente in den neu entstandenen Segmenten am Ende stehen. Um ausgewogenere zusammengeführte Segmente zu erhalten, haben wir eine neue Zusammenführungsrichtlinie eingeführt, die alte und neue Segmente miteinander verschachtelt, d. h., Dokumente aus alten und neuen Segmenten werden im neuen kombinierten Segment in gemischter Reihenfolge angeordnet. So können wir auch die neuesten Dokumente effizient finden.
Optimieren der Sortierung über mehrere Shards
Die Stärke von Elasticsearch liegt in seiner verteilten Suche, und alle Optimierungen wären unvollständig, wenn sie nicht auch den Aspekt „verteilt“ berücksichtigen würden. Da sich einige Suchvorgänge über Hunderte von Shards erstrecken können (z. B. Suchvorgänge in Zeitreihenindizes), wäre es sehr vorteilhaft, mit den „richtigen“ Shards zu beginnen und Shards, die keine konkurrenzfähigen Treffer enthalten dürften, außen vor zu lassen. Und genau das haben wir gemacht. Ab Elasticsearch 7.6 nehmen wir eine Vorsortierung von Shards nach dem Mindest-/Höchstwert des primären Sortierfelds vor, was es uns ermöglicht, eine verteilte Suche mit denjenigen Shards zu beginnen, die die besten Kandidaten für Top-Werte sind. Ab Elasticsearch 7.7 kürzen wir die Abfragephase ab, indem wir die Ergebnisse anderer Shards verwenden, d. h., sobald wir die Top-Werte aus den ersten Shards gesammelt haben, können wir den Rest der Shards komplett außer Acht lassen, da alle ihre möglichen Werte schlechter sind als die in den vorherigen Shards berechneten niedrigsten Werte für die Sortierung. In vielen maschinell generierten Zeitreihenindizes gilt für die Dokumente eine Indexlebenszyklusrichtlinie, bei der performanceorientierten Hardware beginnend und bei der kostenoptimierten Hardware endend, bevor sie gelöscht werden. Dieser Mechanismus des Überspringens von Shards bedeutet oft, dass Nutzer:innen allgemein gehaltene Anfragen senden können und dabei von einer Abfrage-Performance profitieren, die von der Leistungsfähigkeit ihrer performanceoptimierten Hardware abhängt, weil die Shards auf der langsameren und sparsameren Hardware übersprungen werden (was die Verwendung von durchsuchbaren Snapshots besonders effizient macht).
Auswirkungen auf die Nutzer:innen
Wie können Sie als Elasticsearch-Nutzer:in von diesen Sortieroptimierungen profitieren? Diese Sortieroptimierungen funktionieren nur, wenn Ihnen die genaue Zahl der Gesamttreffer für eine Anfrage egal ist und die Anfrage keine Aggregationen enthält. Wenn Sie die genaue Gesamttrefferzahl wissen müssen, dürfen wir nichts überspringen – in diesem Fall müssen alle Dokumente gezählt werden, die einem Filter entsprechen. Der Standardwert von track_total_hits beträgt 10.000. Das bedeutet, dass die Sortieroptimierung erst dann einsetzt, wenn wir 10.000 Dokumente gesammelt haben. Wenn Sie einen niedrigeren Wert festlegen oder den Wert auf „false“ einstellen, startet Elasticsearch die Suchoptimierung viel früher und Sie erhalten deutlich schneller Suchergebnisse.
Seit neuestem sendet Kibana auch Anfragen, bei denen track_total_hits deaktiviert ist, sodass Abfragen mit sortierten Suchergebnissen in Kibana ebenfalls schneller gehen sollten.
Jetzt ausprobieren
Wenn Sie Elastic Cloud bereits nutzen, können Sie direkt von der Elastic Cloud-Konsole aus auf viele dieser Features zugreifen. Neuen Nutzer:innen von Elastic Cloud legen wir unsere Quick Start-Anleitungen (kurze Schulungsvideos für einen schnellen Einstieg) und unsere kostenlosen Grundlagenschulungen ans Herz. Sie können aber auch jederzeit Elastic Enterprise Search 14 Tage lang kostenlos ausprobieren. Und wer das Ganze lieber selbst verwalten möchte, kann den Elastic Stack kostenlos herunterladen.
Teilen
- Share on Twitter
Auf Twitter teilen
- Share on LinkedIn
Auf LinkedIn teilen
- Share on Facebook
Auf Facebook teilen
- Share by Email
Per E-Mail teilen
- Print this page
Drucken

