„Schema-on-Write“ oder „Schema-on-Read“?
Der Elastic Stack (häufig auch „ELK-Stack“ genannt) wird gern zum Speichern von Logs verwendet.
Viele Nutzer fangen zunächst damit an, aus den gespeicherten Logs lediglich den Zeitstempel herauszuparsen und vielleicht noch ein paar einfache Tags hinzuzufügen, um das Filtern zu erleichtern. Mehr Struktur erhalten die gespeicherten Daten nicht. Filebeat übernimmt diese Aufgabe standardmäßig. Es überwacht Logs und sendet sie schnellstmöglich an Elasticsearch, ohne zusätzliche Struktur zu extrahieren. Auch die Kibana Logs-Benutzeroberfläche interessiert sich nicht für die Struktur der Logdaten – ein einfaches Schema, bestehend aus Zeitstempel und Meldung, genügt. Diese Herangehensweise an das Logging bezeichnen wir als das Minimalschema. Bei dieser Methode wird zwar weniger Speicherplatz benötigt, sie bringt aber nicht viel, wenn es um mehr als eine einfache Keyword-Suche und Tag-basiertes Filtern geht.
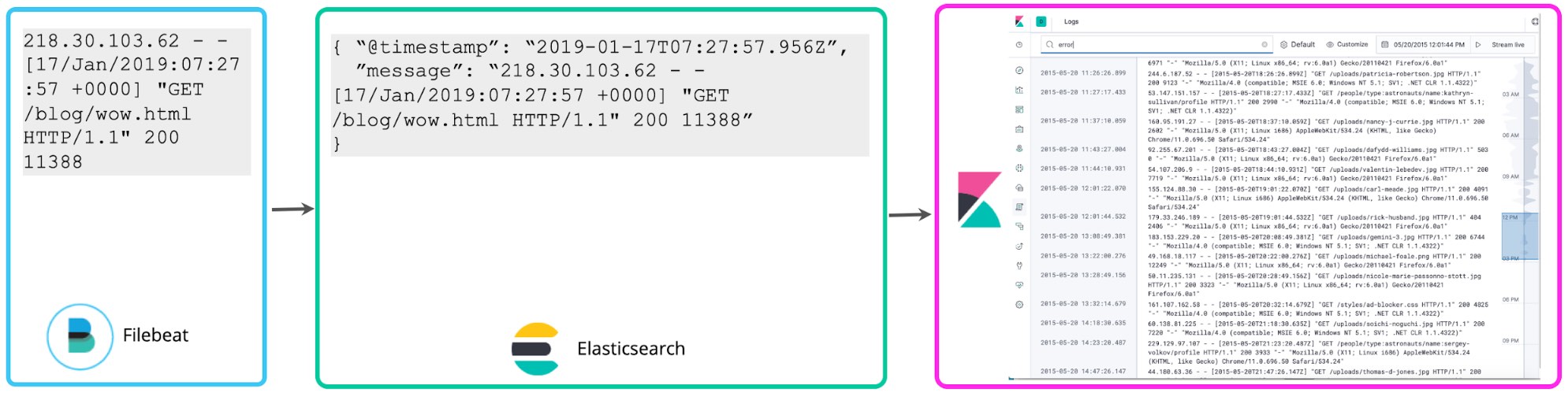
Wenn man sich erst einmal mit den Logs vertraut gemacht hat, möchte man sie in der Regel mehr nutzen. Wer in Logeinträgen Zahlen findet, die mit Statuscodes korrelieren, könnte zum Beispiel interessiert sein zu erfahren, wie viele 5xx-Statuscodes in der letzten Stunde dazugekommen sind. Mit geskripteten Feldern in Kibana lässt sich zum Zeitpunkt der Suche ein Schema über die Logs legen, anhand dessen diese Statuscodes extrahiert und Aggregationen, Visualisierungen und andere Aktionen ausgeführt werden. Diese Herangehensweise an das Logging wird häufig als „Schema-on-Read“ bezeichnet.
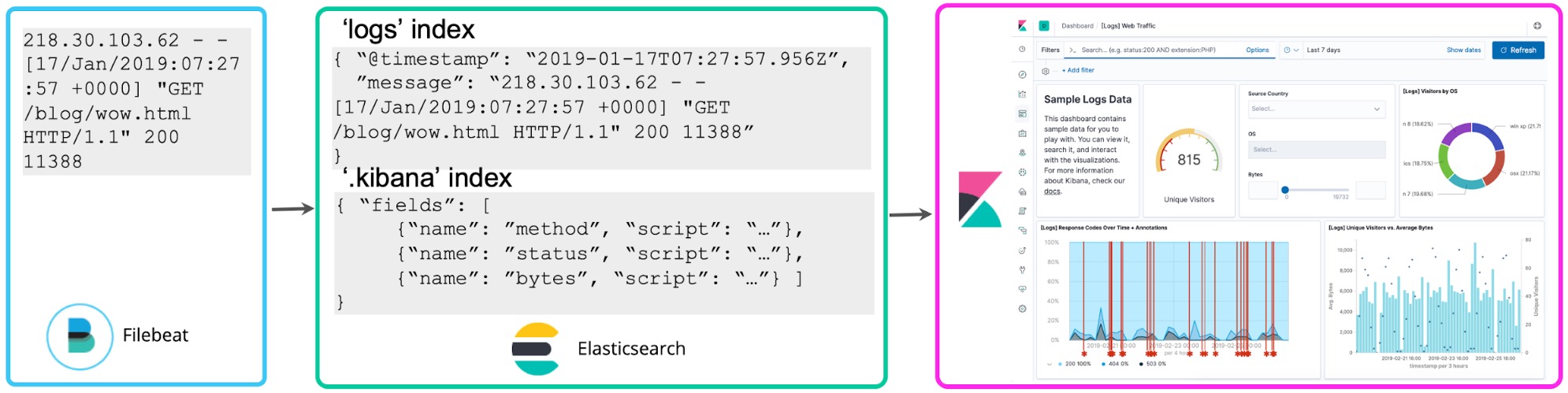
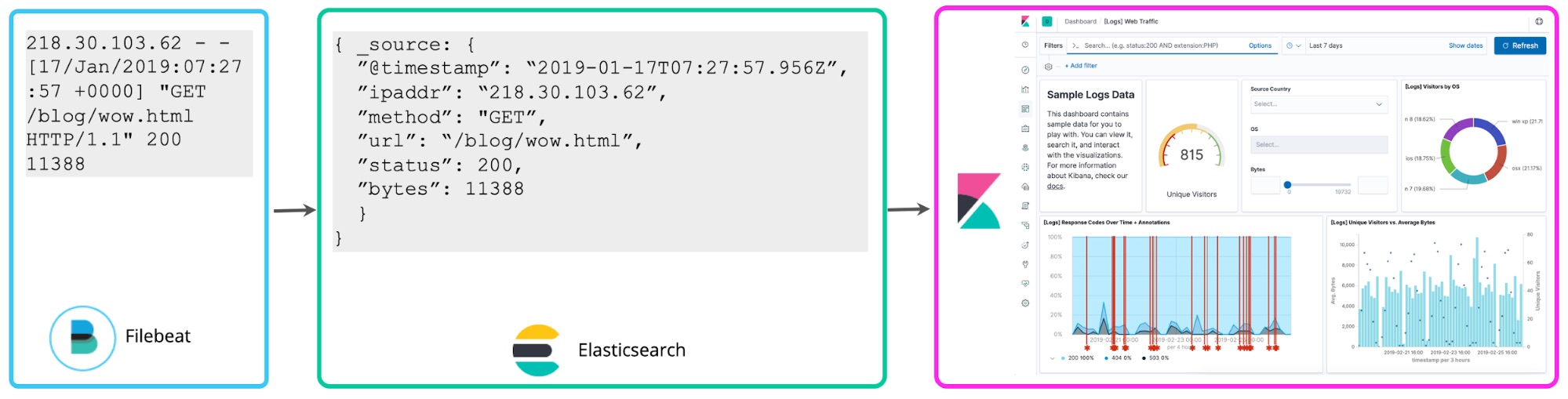
„Schema-on-Read“ eignet sich zwar gut für die Ad-hoc-Exploration, hat aber beim Einsatz für häufig wiederkehrende Berichte und für Dashboards den Nachteil, dass die Felder bei jeder Suche oder jedem Neuaufbau der Visualisierung von Neuem extrahiert werden müssen. Stattdessen können Sie nach der Festlegung der gewünschten strukturierten Felder im Hintergrund einen Reindexierungsprozess starten, mit dessen Hilfe diese geskripteten Felder in strukturierte Felder in einem permanenten Elasticsearch-Index übertragen und dauerhaft gespeichert werden. Und für das Streamen von Daten nach Elasticsearch lässt sich eine Logstash- oder eine Ingest-Knoten-Pipeline einrichten, mit der diese Felder über dissect- oder grok-Prozessoren proaktiv extrahiert werden.
Das bringt uns zu einer dritten Herangehensweise: Es ist auch möglich, Logeinträge zum Zeitpunkt des Schreibens zu parsen und so die oben erwähnten Felder bereits im Vorfeld zu extrahieren. Diese strukturierten Logs bieten Analysten jede Menge Zusatzinformationen und sie müssen nicht mehr darüber nachdenken, wie sie Felder im Nachhinein extrahieren können. So werden Abfragen beschleunigt und die Logdaten können sehr viel sinnvoller genutzt werden. Diese „Schema-on-Write“ genannte Herangehensweise an die zentralisierte Analyse von Logs ist für viele ELK-Nutzer die Methode der Wahl.
In diesem Blogpost werde ich die Vor- und Nachteile dieser Herangehensweisen erläutern und sie aus der Planungsperspektive betrachten. Ich werde darauf eingehen, warum das Strukturieren von Logdaten im Vorfeld sinnvoll ist und warum dies die natürliche Entwicklungsrichtung für alle ist, deren zentralisiertes Logging-Deployment eine gewisse Reife erlangt hat – auch dann, wenn die Daten anfänglich nur wenig strukturiert werden.
„Schema-on-Write“ – Vorteile und Vorurteile
Beginnen wir damit, warum es überhaupt sinnvoll ist, Logdaten zu strukturieren, wenn sie in einen zentralisierten Logging-Cluster geschrieben werden.
Besseres Abfrageerlebnis. Wer in Logs nach wertvollen Informationen sucht, wird häufig damit beginnen, einfach nach einem Keyword wie „Fehler“ zu suchen. Um mit einer solchen Abfrage Ergebnisse zu erzielen, kann man jede Logzeile als ein Dokument in einem invertierten Index behandeln und eine Volltextsuche durchführen. Was jedoch, wenn die Fragen komplexer werden, z. B. so: „Bei welchen Logzeilen hat ‚mein_Feld‘ den Wert ‚N‘?“ Wenn das Feld „mein_Feld“ nicht definiert wurde, kann diese Frage nicht direkt gestellt werden (keine automatische Vervollständigung). Und selbst dann, wenn Ihr Log diese Information doch enthält, müssen Sie als Teil Ihrer Abfrage eine Parsing-Regel einfügen, die dafür sorgt, dass das Feld extrahiert wird. Nur so können Sie es mit dem erwarteten Wert vergleichen. Beim proaktiven Strukturieren von Logdaten im Elastic Stack unterbreitet die Kibana-Funktion zur automatischen Vervollständigung Vorschläge für Felder und Werte. Diese Vorschläge helfen Ihnen dabei, Ihre Abfragen zu erstellen. Das bedeutet eine immense Steigerung der Produktivität von Analysten! Jetzt können Sie und Ihre Kollegen Fragen direkt stellen, ohne dass jeder für sich herausfinden muss, was die Felder bedeuten, und ohne komplexe Parsing-Regeln für das Extrahieren der Felder zum Zeitpunkt der Suche erstellen zu müssen.
Schnellere Abfragen von historischen Daten und Aggregationen. Abfragen für strukturierte Felder im Elastic Stack, selbst bei Vorhandensein riesiger Mengen an historischen Daten, sind eine Sache von Millisekunden. Dagegen dauern solche Abfragen bei typischen „Schema-on-Read“-Systemen gern Minuten oder sogar Stunden. Der Grund dafür ist, dass das Filtern und das Ausführen statistischer Aggregationen bei strukturierten Feldern, die vorab extrahiert und indexiert wurden, wesentlich schneller geht, als das Ausführen regulärer Ausdrücke für jede einzelne Logzeile mit dem Ziel, das Feld zu extrahieren und mathematische Operationen am Wert auszuführen. Dies ist speziell für Ad-hoc-Abfragen wichtig, deren Ausführung nicht proaktiv beschleunigt werden kann, da nicht bekannt ist, welche Abfragen während der Untersuchung nötig werden.
Logs zu Metriken. Im Zusammenhang mit dem oben Gesagten sei darauf hingewiesen, dass das Ergebnis der Extrahierung numerischer Werte aus strukturierten Logs überraschend wie numerische Zeitreihen oder Metriken aussieht. Die schnelle Durchführung von Aggregationen zusätzlich zu diesen wertvollen Datenpunkten hat aus operationaler Sicht große Vorteile. Mit strukturierten Feldern können Sie numerische Datenpunkte aus Logs großangelegt als Metriken verwenden.
Fakten zum richtigen Zeitpunkt. Die Auflösung von Feldern, wie z. B. die Auflösung der IP-Adresse in einen Hostnamen, muss zum Zeitpunkt des Indexierens geschehen, denn es kann passieren, dass später ausgeführte Auflösungen für frühere Transaktionen nicht mehr gültig sind – eine Woche später kann dieselbe IP-Adresse mit einem ganz anderen Hostnamen verknüpft sein. Dies gilt für Suchen in allen externen Quellen, in denen nur der neueste Snapshot des Mappings bereitsteht, also für Suchen nach Benutzernamen in Identitätsverwaltungssystemen, für Suchen nach Asset-Tags in CMDB und so weiter.
Erkennen und Melden von Anomalien in Echtzeit. Ähnlich wie Aggregationen ist das Erkennen und Melden von Anomalien in Echtzeit im großen Rahmen am effizientesten, wenn die Felder strukturiert sind. Anderenfalls hätte Ihr Cluster unter den ständigen Verarbeitungsanforderungen stark zu leiden. Wir hören häufig von Kunden, dass sie sich nicht an Jobs zum Erkennen und Melden von Anomalien heranwagen, weil das Extrahieren von Feldern zum Zeitpunkt der Suche für ihre Alerting-Anforderungen nicht bewältigbar scheint. Das bedeutet, dass die von diesen Kunden erfassten Logdaten im Großen und Ganzen lediglich für reaktive Anwendungsfälle eingesetzt werden können, was den ROI solcher Projekte schmälert.
Logs in Beobachtbarkeitsinitiativen. Wer eine Beobachtbarkeitsinitiative zu laufen hat, weiß, dass es nicht damit getan ist, einfach nur Logdaten zu erfassen und in ihnen zu suchen. Logdaten sollten im Idealfall mit Metriken (z. B. Ressourcennutzung) und Anwendungs-Traces korreliert werden. Nur so können sie, unabhängig von der Herkunft der Datenpunkte, ein ganzheitliches Bild davon vermitteln, was mit dem Dienst passiert. Diese Korrelationen funktionieren am besten, wenn die Felder strukturiert sind. Ist dies nicht der Fall, verlangsamen sich die Suchvorgänge so stark, dass das Ganze für den großangelegten Einsatz in der Praxis unbrauchbar wird.
Datenqualität. Wenn Ihre Ereignisse vorab verarbeitet werden, haben Sie die Gelegenheit, ungültige, doppelte oder fehlende Daten ausfindig zu machen und die Ursachen zu korrigieren. Bei der „Schema-on-Read“-Herangehensweise wissen Sie nicht, ob Ihre Ergebnisse akkurat zurückkommen, da es keine Vorabprüfung der Gültigkeit und Vollständigkeit der Daten gibt. Das kann zu ungenauen Ergebnissen und falschen Schlussfolgerungen führen.
Granulare Zugriffssteuerung. Bei unstrukturierten Logdaten ist es schwierig, granulare Sicherheitsregeln, z. B. von Einschränkungen auf Feldebene, anzuwenden. Filter, die den Zugriff auf Daten während der Suche begrenzen, können zwar hilfreich sein, ihre Fähigkeiten sind aber recht eingeschränkt. So ist es mit ihnen nicht möglich, Teilergebnisse für eine Auswahl von Feldern zu erhalten. Im Elastic Stack lässt sich die Sicherheit bis auf die Feldebene hinunter steuern und so festlegen, dass Nutzer mit geringeren Zugriffsrechten bestimmte Felder sehen können, während andere Felder ausdrücklich nicht angezeigt werden. So können personenbezogene Daten in Logs wesentlich einfacher und flexibler geschützt werden, während gleichzeitig eine größere Gruppe von Nutzern Zugriff auf andere Informationen erhält.
Hardware-Voraussetzungen
Zu den Vorurteilen, die im Zusammenhang mit „Schema-on-Write“ immer wieder auftauchen, gehört, dass der Cluster bei dieser Herangehensweise automatisch mehr Ressourcen benötigt, damit die Logdaten geparst und sowohl im ungeparsten als auch im geparsten (oder „indexierten“) Format gespeichert werden können. Sehen wir uns ein paar Kompromisse an, die Sie für Ihren speziellen Anwendungsfall betrachten sollten, denn die Antwort ist, wie so oft, nicht so eindeutig wie es scheint.
Einmaliges Parsen vs. kontinuierliches Extrahieren von Feldern. Das Parsen und Speichern von Logdaten in einem strukturierten Format erfordert Verarbeitungskapazität beim Ingestieren. Allerdings werden bei wiederholten Abfragen von unstrukturierten Logdaten, die zum Extrahieren von Feldern komplexe reguläre Ausdrücke verwenden, deutlich mehr RAM- und CPU-Ressourcen verbraucht – und das ständig. Wenn Sie absehen können, dass der normale Anwendungsfall für Ihre Logdaten lediglich gelegentliche Suchen vorsieht, ist es vielleicht übertrieben, die Daten vorab zu strukturieren. Aber überall dort, wo Logs aktiv abgefragt und Aggregationen für Logdaten durchgeführt werden sollen, sind die einmaligen Kosten für das Ingestieren möglicherweise weniger problematisch als die laufenden Kosten für das wiederkehrende Ausführen der immer gleichen Operationen zum Zeitpunkt der Abfrageverarbeitung.
Anforderungen an das Ingestieren. Aufgrund des zusätzlichen Vorab-Verarbeitungsaufwands kann das Tempo beim Ingestieren etwas geringer ausfallen als ohne diesen Aufwand. Zur Bewältigung dieser Last können Sie zusätzliche Ingest-Infrastruktur einführen, indem Sie Ihre Elasticsearch-Ingest-Knoten oder Logstash-Instanzen einzeln skalieren. Diese Herangehensweise ist gut in verschiedenen Ressourcen und Blogs dokumentiert, und wenn Sie Elasticsearch Service auf Elastic Cloud nutzen, brauchen Sie zum Skalieren der Ingest-Knoten lediglich weitere „Ingest-fähige“ Knoten hinzuzufügen.
Speicher-Voraussetzungen. Auch wenn es erst einmal schräg klingen mag: Wer sich vorab etwas mit der Struktur seiner Logdaten beschäftigt und sie verstehen lernt, benötigt am Ende unter Umständen sogar weniger Speicherplatz. Logdaten können sehr ausführlich sein und viel Unwesentliches enthalten. Eine Vorabprüfung (selbst, wenn nicht jedes einzelne Feld vollständig geparst wird) ermöglicht es Ihnen zu entscheiden, welche Logzeilen und extrahierten Felder für die Suche in Ihrem zentralisierten Log-Cluster online zugänglich gehalten werden sollen und welche auf der Stelle archiviert werden können. Diese Herangehensweise kann dazu beitragen, dass weniger Platz für das Speichern von Logdaten benötigt wird. Filebeat verfügt zu genau diesem Zweck über leichtgewichtige dissect- und drop-Prozessoren.
Selbst dann, wenn die Regulierungsbehörden vorschreiben, dass jede Logzeile aufzubewahren ist, gibt es Möglichkeiten, mit „Schema-on-Write“ die Speicherkosten zu optimieren. Die erste: Die Kontrolle liegt ganz bei Ihnen: Sie müssen Ihre Logdaten nicht komplett strukturieren. Wenn Ihr Anwendungsfall danach verlangt, genügt es, ein paar wichtige strukturierte Metadaten hinzuzufügen und den Rest der Logzeile ungeparst zu lassen. Allerdings gilt auch: Wenn Sie Ihre Logdaten komplett durchstrukturieren, sodass jedes Bisschen wichtiger Daten im strukturierten Speicher abgelegt wird, gibt es keine Notwendigkeit, das Ausgangsfeld im selben Cluster zu speichern, in dem sich auch die indexierten Logs befinden. Es kann somit archiviert und billiger aufbewahrt werden.
Zudem existieren verschiedene Wege, Elasticsearch-Standardwerte zu optimieren, wenn Speicherplatz weiterhin ein Problem darstellt. So lassen sich beispielsweise mit ein paar Mausklicks die Komprimierungsverhältnisse anpassen. Bei weniger häufig benötigten Daten, die über längere Zeiträume aufbewahrt werden müssen, können Sie auch mit Heiß-Warm-Architekturen und eingefrorenen Indizes arbeiten. Dabei sollte jedoch nicht außer Acht gelassen werden, dass selbst das Speichern „heißer“ Daten relativ günstig ist, vergleicht man es mit den Kosten, die das minutenlange Warten auf eine dringendst benötigte Antwort mit sich bringen kann.
Vorabdefinition der Struktur
Ein weiteres gern wiederholtes Vorurteil ist, dass das Strukturieren von Logdaten vor dem Speichern schwierig ist. Lassen Sie mich diese Behauptung widerlegen.
Strukturierte Logdaten. Viele Logdaten werden bereits in einem strukturierten Format erstellt. Die meisten üblichen Anwendungen unterstützen JSON als direktes Ziel für Logdaten. Das bedeutet, dass Sie Ihre Logdaten direkt in Elasticsearch ingestieren und in strukturierten Formaten speichern lassen können, ohne sie parsen zu müssen.
Vordefinierte Regeln für das Parsen. Es gibt Dutzende vordefinierter Regeln für das Parsen, die offiziell von Elastic unterstützt werden. So strukturieren z. B. Filebeat-Module Logdaten von bekannten Anbietern automatisch, und Logstash enthält eine ausführliche Grok-Muster-Bibliothek. Darüber hinaus stellt die Community zahllose vordefinierte Regeln für das Parsen bereit.
Automatisch generierte Parsing-Regeln. Beim Definieren von Regeln für das Extrahieren von Feldern helfen Tools wie der Kibana Data Visualizer, der automatisch Vorschläge für das Parsen macht. Wenn Sie eine Stichprobe aus Ihrem Log in das Tool kopieren, erhalten Sie ein Grok-Muster, das Sie im Ingest-Knoten oder in Logstash verwenden können.
Was passiert, wenn sich das Logformat ändert
Zum Schluss soll es um das immer wieder gehörte Vorurteil gehen, dass „Schema-on-Write“ Probleme bereitet, wenn es Änderungen beim Logformat gibt. Das stimmt ganz einfach nicht – wenn es um mehr als eine reine Volltextsuche geht, muss immer irgendjemand sich irgendwann mit der Umstellung des Formats beschäftigen, ganz gleich, ob die Informationen vorab oder erst im Anschluss extrahiert werden. Sowohl bei der Grok-Verarbeitung des Logs durch eine Ingest-Knoten-Pipeline während des Indexierens als auch bei der gleichen Tätigkeit durch ein mit Kibana geskriptetes Feld zum Zeitpunkt der Suche gilt, dass jede Änderung des Logformats eine Modifizierung der Logik zum Extrahieren der Felder nach sich ziehen muss. Bei den von uns gepflegten Filebeat-Modulen sorgen wir dafür, dass von Upstream-Log-Anbietern veröffentlichte neue Versionen geprüft und entsprechend installiert werden.
Es gibt verschiedene Ansätze für den Umgang mit sich ändernden Logstrukturen zum Zeitpunkt des Schreibens.
Vorabmodifizierung der Parsing-Logik. Wenn Sie wissen, dass sich das Logformat ändern wird, können Sie eine parallele Verarbeitungspipeline erstellen und für eine Übergangszeit beide Versionen des Logs unterstützen. Dies gilt üblicherweise für die Formate der Logs, die Sie in-house verwalten.
Bei fehlgeschlagenem Parsing Minimalschema schreiben. Nicht alle Änderungen sind vorab bekannt und manchmal kann es passieren, dass sich das Format von Logs, die nicht unter Ihrer Kontrolle stehen, ohne Vorankündigung ändert. Sie können dem in der Logpipeline von Anfang an vorbauen, indem Sie beim Fehlschlagen des Grok-Parsings ein aus Zeitstempel und ungeparster Meldung bestehendes Minimalschema schreiben und eine Benachrichtigung an den Betreiber senden lassen. Zu diesem Zeitpunkt kann ein geskriptetes Feld für das neue Logformat erstellt werden. Um Unterbrechungen im Analysten-Workflow zu vermeiden, modifizieren Sie die Pipeline für die Zukunft und überlegen Sie, ob es sinnvoll ist, die Felder für die kurze Unterbrechungszeit in der Parsing-Logik neu zu indexieren.
Bei fehlgeschlagenem Parsing Schreiben des Ereignisses verzögern. Wenn das Schreiben eines Minimalschemas nichts nutzt, können Sie stattdessen festlegen, dass bei einem Parsing-Problem die Logzeile nicht geschrieben und das Ereignis in eine Warteschlange für unzustellbare Nachrichten (auch „Dead Letter Queue“ genannt) verschoben wird (bei Logstash ist diese Funktionalität standardmäßig enthalten), woraufhin der Betreiber eine entsprechende Benachrichtigung erhält. Dieser kann dann die Logik reparieren und die Ereignisse aus der Warteschlange für unzustellbare Nachrichten durch die neue Parsing-Pipeline schicken. Dadurch wird zwar die Analyse unterbrochen, Sie müssen sich aber nicht mit geskripteten Feldern und einer erneuten Indexierung beschäftigen.
Eine passende Analogie
Dieser Post wird ziemlich lang und jedem, der es bis hierhin durchgehalten hat, gebührt mein Dank! Wenn es darum geht, sich gründlich mit einem Konzept vertraut zu machen, hilft mir persönlich immer eine gute Analogie. Neil Desai, Security Specialist bei Elastic, hat dazu kürzlich ein Video veröffentlicht, das eine der besten Analogien für den Unterschied zwischen „Schema-on-Read“ und „Schema-on-Write“ enthält. Ich hoffe, Sie finden diese Analogie so hilfreich wie ich.

Fazit – Sie haben die Wahl
Wie anfangs erwähnt, gibt es auf die Frage, ob nun „Schema-on-Read“ oder „Schema-on-Write“ besser ist, keine allgemeingültige Antwort für jedes zentralisierte Logging-Deployment. Die meisten Deployments befinden sich irgendwo dazwischen – einige Logdaten werden in großem Maße strukturiert, während es bei anderen beim einfachsten Schema (Zeitstempel und Meldung) bleibt. Der beste Weg hängt davon ab, was man mit den Logdaten machen möchte und ob man den mit strukturierten Abfragen verbundenen Vorabaufwand – und die damit verbundenen Tempo- und Effizienzvorteile – im Vergleich zum aufwandlosen schnellen Schreiben der Daten auf das Speichermedium als gerechtfertigt erachtet. Der Elastic Stack unterstützt beide Herangehensweisen.
Wenn auch Sie Logs im Elastic Stack nutzen möchten, richten Sie in Elasticsearch Service einen Cluster ein oder laden Sie den Elastic Stack herunter, um ihn lokal zu nutzen. Und sehen Sie sich die neue Logs-App in Kibana an, die Ihren Workflow für die Arbeit mit Logs jeder Form – ob strukturiert oder nicht – optimiert.