Machine Learning und Elasticsearch für Security-Analytics: Ein detaillierter Einblick
Anmerkung des Autors (3. August 2021): Dieser Beitrag verwendet veraltete Features. In der Dokumentation zum Thema Map custom regions with reverse geocoding (benutzerdefinierte Regionen mit umgekehrter Geocodierung zuordnen) finden Sie eine aktuelle Anleitung.
Einleitung
Im letzten Beitrag unserer mehrteiligen Serie über die Integration von Elasticsearch mit ArcSight SIEM, als wir die Alerting-Funktionen von X-Pack zur Erkennung erfolgreicher Brute-Force-Login-Angriffe eingesetzt haben, haben wir bereits auf die bevorstehende Veröffentlichung unserer Machine Learning Funktionen in X-Pack hingewiesen.
Und nun ist es so weit: X-Pack Machine Learning ist da. Wir möchten an dieser Stelle Schritt für Schritt erklären, was es bedeutet, Machine Learning zur Erkennung von Anomalien in Log-Daten von Elasticsearch einzusetzen, die mit typischen Cyberbedrohungen einhergehen.
Simple Mathematik, kein Magie
Bevor wir loslegen, beschäftigen wir uns erst einmal mit dem Hintergrund. Wenn die Sprache auf das Thema Sicherheit kommt, kursiert häufig die falsche Annahme, dass es sich bei Machine Learning einfach um eine magische Kiste voll mit Algorithmen handelt, die man auf seine Daten loslässt, damit sie nützliche Informationen ausgeben. Aber so funktioniert es nicht.
Man sollte Machine Learning auf dem Gebiet der Cybersicherheit eher als „Algorithmus-Assistenten“ betrachten, die dem Sicherheitsteam helfen, die Analyse sicherheitsrelevanter Log-Daten zu automatisieren, indem potenziell gefährliche Anomalien und Muster untersucht werden – und zwar immer unter der Leitung menschlicher Sicherheitsexperten.
Überwachung von Bedrohungen? Oder doch eher Jagd auf Bedrohungen? Die Rolle von Machine Learning.
X-Pack Machine Learning kann für die interaktive Untersuchung von Anomalien in Zusammenhang mit Bedrohungen eingesetzt werden. Häufig werden Swimlane-Visualisierungen von Anomalien in Kibana als Ausgangspunkt für die Untersuchung von Bedrohungen eingesetzt. Aber detaillierte Informationen über die aufgedeckten Anomalien zeigen dem Sicherheitsanalysten erst konkret, „warum“ das erkannte Verhalten auffällig war und als Anomalie eingestuft wurde, wie ungewöhnlich die Anomalie war, warum die Bedrohung zu einem elementaren Angriffsverhaltensmuster passt und welche Datenentitäten das Angriffsverhalten beeinflusst haben.
Da X-Pack Machine Learning fest in den Elastic Stack integriert ist, lassen sich die Benachrichtigungsmethoden, die wir in unseren Beiträgen zur Integration von Elasticsearch mit ArcSight SIEM Teil 2 und Teil 4 bereits thematisiert haben, nun auch auf eine neue Quelle für interessante Einblicke anwenden: den Index der Machine Learning Ergebnisse, der „ml-anomalies-*“ heißt. So können Ergebnisse, die durch diese Algorithmus-Assistenten ausgegeben wurden, dazu eingesetzt werden, Benachrichtigungen für die weitere Bedrohungsüberwachung auszulösen.
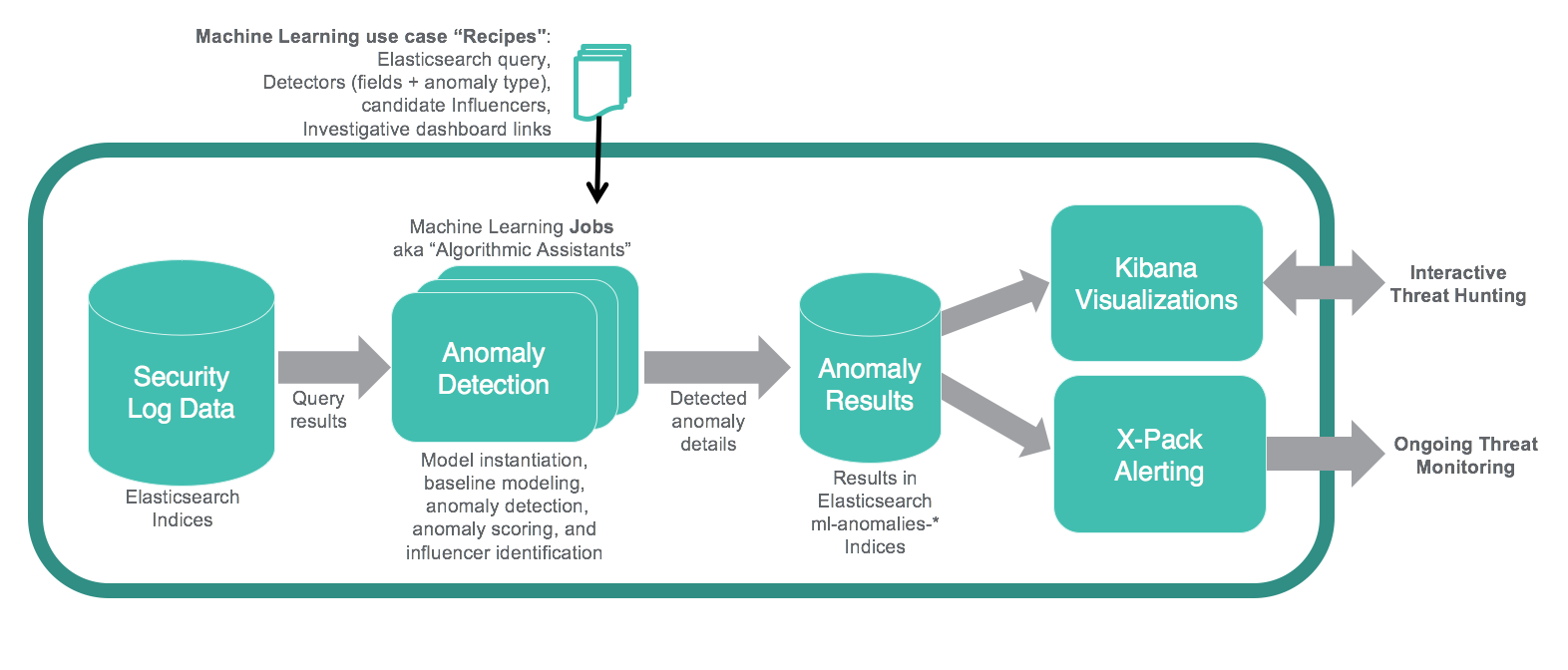
Anleitungen für die Erkennung von Bedrohungen mittels Machine Learning
Die auf Schwellenwerten basierende Benachrichtigung über Ereignisse erfüllt zweifellos ihren Zweck (z. B. bei der Auslösung einer Benachrichtigung, wenn es vor einem erfolgreichen Login mehrere nicht erfolgreiche Login-Versuche gab). Doch die automatisierte Erkennung auffälliger Verhaltensweisen, ohne dass spezifische Datenbedingungen bestimmt werden müssen, erleichtert die Arbeit von Sicherheitsanalysten um ein Vielfaches.
Da wir es, wie oben schon erwähnt, mit Mathematik und nicht mit Zauberei zu tun haben, musst du zuerst die Machine Learning Engine starten, indem du die entsprechenden Einstellungen in der Job-Konfiguration vornimmst. Da die Engine jede Art von Daten über längere Zeiträume modellieren kann – ganz egal, ob numerisch oder kategorisch – ist die Anzahl der konfigurierbaren Arten von Machine-Learning-Jobs unbegrenzt. Das ist zwar gut für alle, die gerne flexibel sind, kann aber für einen Sicherheitsanalysten, der einfach nur Bedrohungen finden möchte, ein bisschen zu viel werden.
Aus diesem Grund stellen wir dir hier beispielhaft eine Anleitung für die Konfiguration eines Machine Learning Jobs für Anwendungsfälle im Sicherheitsbereich vor. Diese Anleitungen erklären, wie du Machine Learning Jobs konfigurieren musst, um mithilfe automatisierter Anomalie-Erkennung elementare Angriffsverhaltensmuster zu erkennen, die sich anderweitig nur schwer entdecken lassen. Zu solchen elementaren Angriffsverhaltensmustern gehören Aktivitäten wie DNS-Tunneling, Web-Daten-Exfiltration, die Ausführung verdächtiger Prozesse am Endpunkt und mehr.

Abb. 2: Beispielhafte Anleitung für eine Machine Learning Konfiguration für einen Anwendungsfall im Sicherheitsbereich
Jede Anleitung befindet sich in einem kurzen Dokument, das aus verschiedenen Abschnitten besteht: theoretische Durchführung, eine Beschreibung und konkrete Schritte zur Modellierung und Beobachtung von Ergebnissen. Die konkreten Schritte umfassen eine Auswahl von Eigenschaften, einen Modellierungsansatz, das Ziel (was soll erkannt werden), einen Vergleichsdatensatz, Influencer-Elemente, den Analysezeitraum und die Interpretation der Ergebnisse.
Wir haben mit der Einführung von Version 5.4 vier Machine Learning Konfigurationen für Anwendungsfälle aus dem Sicherheitsbereich zusammengestellt. Diese sind ab sofort in diesem GitHub-Repository verfügbar und jedes Beispiel enthält eine Anleitung für einen Sicherheitsanwendungsfall und diverse Konfigurationen, Daten und Skripte, die dir helfen, alles auszuprobieren.
Eine Machine Learning Anleitung zur Erkennung von DNS-Tunneling
Als Beispiel für solch eine Anleitung schauen wir uns an, wie Machine Learning zur Erkennung von DNS-Tunneling-Aktivitäten eingesetzt werden kann.
Eine kurze Erklärung zu den Hintergründen: DNS-Tunneling bezieht sich auf eine Aktivität, bei der versucht wird, das Domain Name Service (DNS) Protokoll zu benutzen, um Nicht-DNS-Informationen in das bzw. aus dem Netzwerk einer Organisation zu transferieren. Da das DNS-Netzwerk von allen mit dem Internet verbundenen IT-Infrastrukturen genutzt wird, wird dieser Traffic in der Regel nicht durch Firewalls geblockt und ist deshalb ein attraktives Ziel, um unautorisierte und/oder schädliche Informationen zu versenden, die den „Tunnel“ der vorhandenen Sicherheitssysteme eines Unternehmens nutzen. Die FrameworkPOS-Malware nutzt diese Technik beispielsweise, um gestohlene Kartendaten aus Verkaufsterminals zu exfiltrieren.
Schauen wir uns nun die detaillierte Anleitung für eine Machine Learning Konfiguration für einen Anwendungsfall im Sicherheitsbereich an, die in Elastic-Sicherheitskreisen unter dem Namen DNS-EAB02 bekannt ist. „DNS“ weist darauf hin, dass die in dieser Anleitung analysierten Logs vom „DNS“-Protokoll stammen. „EAB“ weist darauf hin, dass diese Anleitung elementare Angriffsverhaltensmuster erkennt. „02“ ist eine eindeutige Kennung, um diese Anleitung von anderen DNS-Anleitungen zu unterscheiden. Die Anleitung besteht aus mehreren Abschnitten:
Theorie: Eine ungewöhnliche Entropie (hier als „Informationsmenge“ bezeichnet) im Subdomain-Feld der DNS-Query-Anfragen kann ein Hinweis auf die Exfiltration von Daten über das DNS-Protokoll sein.
Bitte beachte, dass es viele Möglichkeiten gibt, um die Exfiltration von DNS-Daten zu erkennen. In diesem Job wird ein spezielles Verfahren verwendet, das sich in realen Enterprise-Umgebungen als effektiv erwiesen hat. Falls dein Sicherheitsteam eine andere oder eine zusätzliche Methode bevorzugt, kannst du diesen Job ganz einfach klonen, ihn entsprechend anpassen und durchführen! Oder du führst beide Jobs durch, um Ergebnisse zu vergleichen oder sogar zu kombinieren.
Beschreibung: Diese Anleitung für einen Anwendungsfall erkennt Domains, an die DNS-Query-Anfragen gesendet werden, die ungewöhnlich hohe Mengen an „Informationsinhalten“ enthalten, und IP-Adressen, die diese auffälligen Anfragen generieren.
Es ist nicht unbedingt auf den ersten Blick offensichtlich, dass die Erkennung von Domains, an die Anfragen mit einer ungewöhnlich hohen Informationsmenge im Subdomain-Bereich des Felds gesendet werden, überhaupt hilfreich ist. Aber betrachtet man das Ganze aus der Perspektive der Datenmodellierung, müssen wir die Funktion finden, die im Laufe der Analyse am ehesten ungewöhnliche Merkmale aufweist. Für diese Analyse ist das Domain-Feld im DNS-Query-Log die Eigenschaft, die wir modellieren möchten. Das Merkmal ist die Menge an Informationsinhalten im Subdomain-Feld dieser DNS-Anfragen.
Effektivität: Diese Anleitung für einen Anwendungsfall dient als grundlegendes Beispiel, wie die automatische Erkennung von Anomalien eingesetzt werden kann, um die Exfiltration von DNS-Daten zu erkennen. Andere Anleitungen, die alternative oder komplexere Ansätze nutzen, können bei der Erkennung zu effektiveren Ergebnissen führen.
Bitte denk daran, dass diese Anleitung lediglich ein Beispiel ist. Sprich mit deinem Team, damit ihr gemeinsam Wege findet, um noch effektivere Ergebnisse zu erzielen.
Art des Anwendungsfalls: Elementares Angriffsverhalten (EAB für „Elementary Attack Behavior“). Dieser Anwendungsfall erkennt Anomalien in Zusammenhang mit elementaren Angriffsverhaltensmustern. Jeder erkannten Anomalie wird ein standardisierter Anomalie-Score zugewiesen, der außerdem Werte anderer Felder in den Daten enthält, die sich statistisch auf die Anomalie auswirken können. Elementare Angriffsverhaltensmuster mit gemeinsamen statistischen Influencern hängen häufig mit einem gemeinsamen Angriffsprozess zusammen.
Ein wenig Hintergrund dazu: Mit dieser Anleitung führst du keine Metaanalyse von Risikofaktoren durch, sondern sie dient eher dazu, elementare Angriffsverhaltensmuster zu erkennen, die mit anderen Angriffen korrelieren können. Für diese Erkennung von Cyberangriffen wird X-Pack Alerting verwendet.
Datenquelle für diesen Anwendungsfall: DNS-Query-Logs (vom Client zum DNS-Server)
Welche Daten brauchen wir für diese Anleitung?
Anleitung für einen konkreten Anwendungsfall
Für: DNS-Query-Anfragen (gefiltert nach den Typen: A, AAAA, TXT)
Modell: Informationsinhalte innerhalb des Subdomain-Strings
Erkennt: Ungewöhnlich hohe Informationsmengen
Vergleich: Gruppe aller (auf höchster Ebene registrierten) Domains in Query-Ergebnissen
Partitionierung: Keine
Ausschluss: Domains, die häufig in der Analyse auftreten
Dauer: Analyse von DNS-Anfragen für einen Zeitraum von mindestens 2 Wochen oder länger
Zugehörige Anleitungen: Durchführung dieses EAB-Anwendungsfalls für sich allein oder gemeinsam mit DNS-EAB01 DNS DGA-Aktivität
Ergebnisse: Influencer-Hosts sind wahrscheinlich die Ursache für DNS-Tunneling-Aktivitäten
Wir möchten gerne erklären, weshalb wir diese Anleitung in Form von Klartext erstellt haben. Dieser Abschnitt bestimmt, aus welchen Log-Mitteilungen wir Daten herausziehen, welche Datenmerkmale wir modellieren, welche ungewöhnlichen Verhaltensmuster wir versuchen zu entdecken, was wir dazu in den Vergleich setzen möchten, ob wir die Analyse partitionieren möchten oder nicht, ob wir häufige Werte, die die Ergebnisse dominieren können, ausschließen möchten oder nicht, wie viele Daten benötigt werden, um aussagekräftige Ergebnisse zu erzielen, welche anderen Jobs zu diesem Job passen und zu guter Letzt, wie man die Ergebnisse der Analyse findet und interpretiert.
Zusätzliche Konfigurationsparameter:
Diese Abschnitte (Beispiel für Elasticsearch Index-Patterns, Beispiel für Elasticsearch Query und Machine Learning Analyse/Detektorkonfiguration) liefern dir die notwendigen Konfigurationsdetails, damit sichergestellt ist, dass der Machine Learning Job so funktioniert wie von uns beabsichtigt. Diese Details entsprechen genau den Einstellungen in der Ansicht für die Job-Konfiguration.
Sobald ein Machine Learning Job mit dieser Anleitung konfiguriert und gestartet wurde, beginnen Machine Learning mit der Indizierung und der Analyse von DNS-Anfrage-Logs, die über Client-Workstations eingehen. Dabei werden Basiswerte normalen Verhaltens für DNS-Anfragen von jedem Client erstellt, sodass erkennbar ist, wann auffällige Aktivitäten auftreten.
Wie oben bereits erwähnt, werden Anomalien in einem Elasticsearch-Index mit dem Standardnamen „ml-anomalies-*“ gespeichert, wo sie durchsucht und in Kibana-Dashboards angezeigt werden können. Sie lassen sich im Detail mithilfe des X-Pack Machine Learning Plugins untersuchen, oder verwenden, um mit X-Pack Alerting eine Benachrichtigung zu generieren.
Wir haben ein paar kurze Videos vorbereitet, die dir Machine Learning in Aktion zeigen. Hier siehst du erst einmal ein Beispiel der Ansicht des X-Pack Machine Learning Anomaly Explorers in Version 5.4 (Beta) für Ergebnisse aus einem DNS-Tunneling-Job.
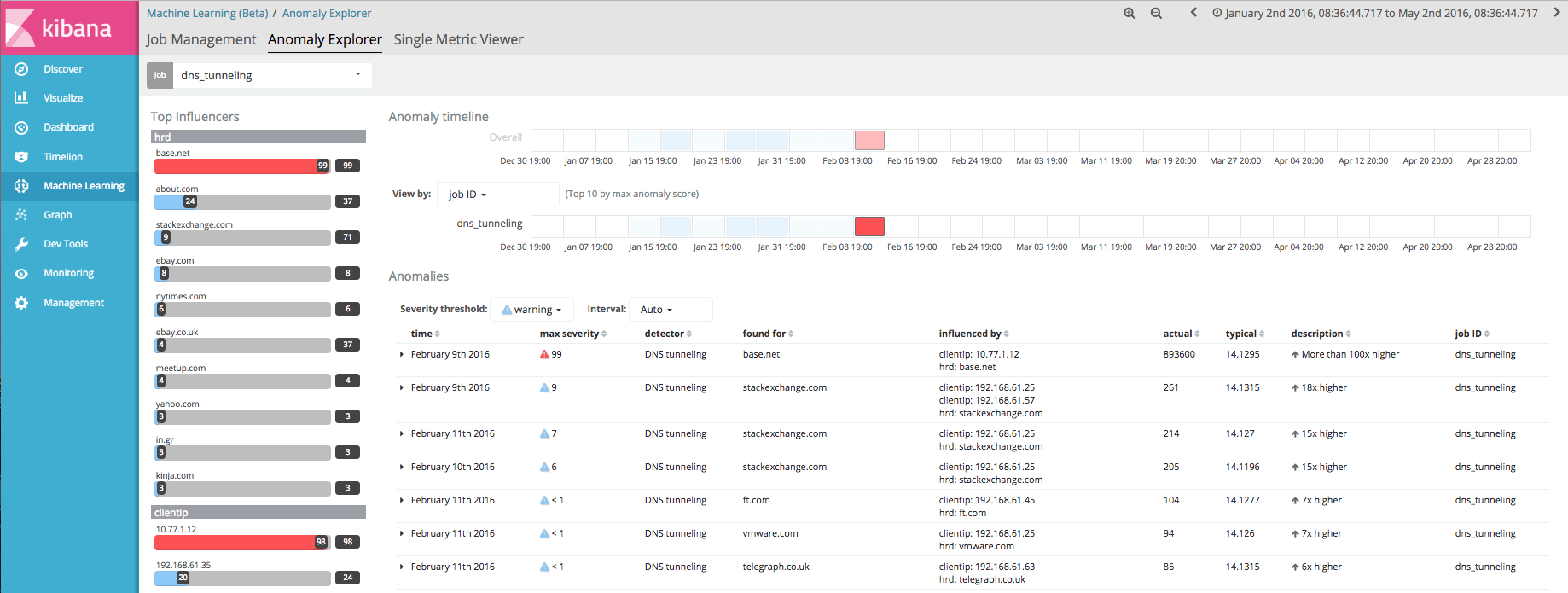
Fazit
X-Pack Machine Learning macht maschinelles Lernen für Sicherheitsanalysten und Entwickler zugänglich, die mit sicherheitsrelevanten Log-Daten in Eleasticsearch arbeiten. Der Job zur Erkennung von Anomalien bildet das Grundelement für X-Pack Machine Learning. Die Anleitungen für Anwendungsfälle aus dem Bereich Sicherheits-Analyse beschreiben, wie man Jobs konfiguriert, um Angriffsverhaltensmuster zu erkennen. Ohne irgendetwas programmieren zu müssen, kannst du so Algorithmus-Assistenten nutzen, um Bedrohungen zu erkennen und die Sicherheit insgesamt zu optimieren.
Hier erfährst du mehr
- Schau dir unsere Videos aus dem Machine Learning Lab an: Video 1, Video 2, und Video 3.
- Weitere Beispiele für Machine Learning Anleitungen, um Angriffsverhaltensmuster zu erkennen.
- Lade dir eine kostenlose Testversion von X-Pack herunter und probiere es aus.
- Nimm am Webinar teil, um dir die ganze Produkttour anzusehen.