Was gibts Neues in Elastic Observability 7.11? APM-Dienstübersichtsseite plus ECS-Logging-Bibliothek jetzt allgemein verfügbar
Wir freuen uns, die Veröffentlichung von Version 7.11 von Elastic Observability bekanntgeben zu können. Sie enthält mehrere Features, die Analytics-Workflows beschleunigen und bei Observability-Anwendungsfällen für bessere Mean-Time-to-Insight(MTTI)- und Mean-Time-to-Resolution(MTTR)-Werte sorgen. Die neue Dienstübersichtsseite in Elastic APM zeigt wichtige Aspekte des Zustands des Dienstes in einer zentralen Ansicht an, sodass Entwickler und für die Zuverlässigkeit zuständige Engineers Probleme schnell aufspüren und ohne aufwendiges Umschalten zwischen verschiedenen Kontextquellen Ursachenforschung betreiben können. Auch die Metrics-App bietet eine erweiterte Ansicht mit Angaben zum Zustand des Hosts in einer zentralen Ansicht und hilft so, die Infrastruktur-Monitoring- und Troubleshooting-Workflows zu beschleunigen. Und last but not least: Die ECS-Logging-Bibliotheken, die Anwendungslogdaten automatisch um Trace-Kontext erweitern, um eine Korrelation zwischen Log und Trace zu ermöglichen, sind jetzt allgemein verfügbar.
Die neueste Version von Elastic Observability finden Sie in unserem Elasticsearch Service auf Elastic Cloud (eine kostenlose 14-tägige Testversion ist verfügbar) oder Sie installieren die neueste Version des Elastic Stack und verwalten Ihr Deployment selbst.
Genug der einleitenden Worte – lassen Sie uns mit der Vorstellung einiger der Highlights der neuen Version beginnen:
Die neue Dienstintegritätsansicht in Elastic APM beschleunigt die Ursachenanalyse und Fehlerbehebung.
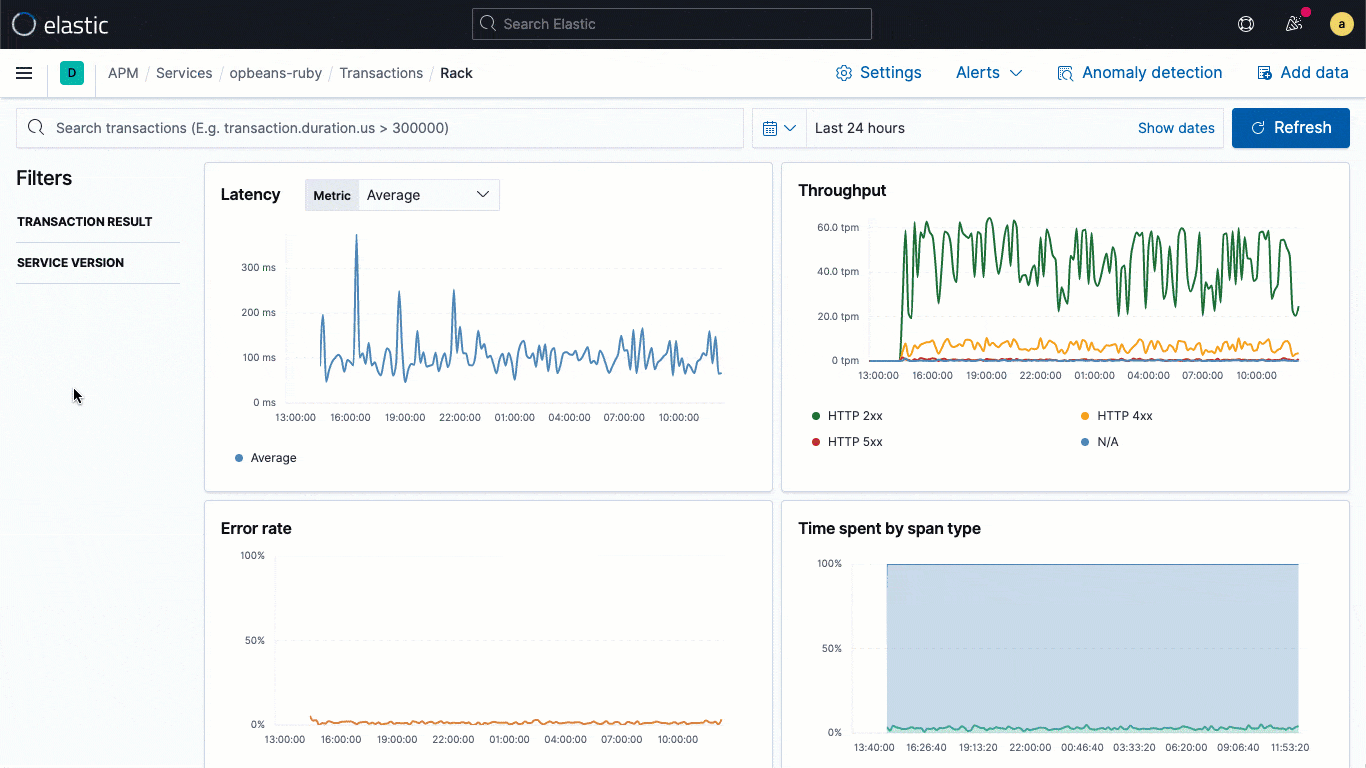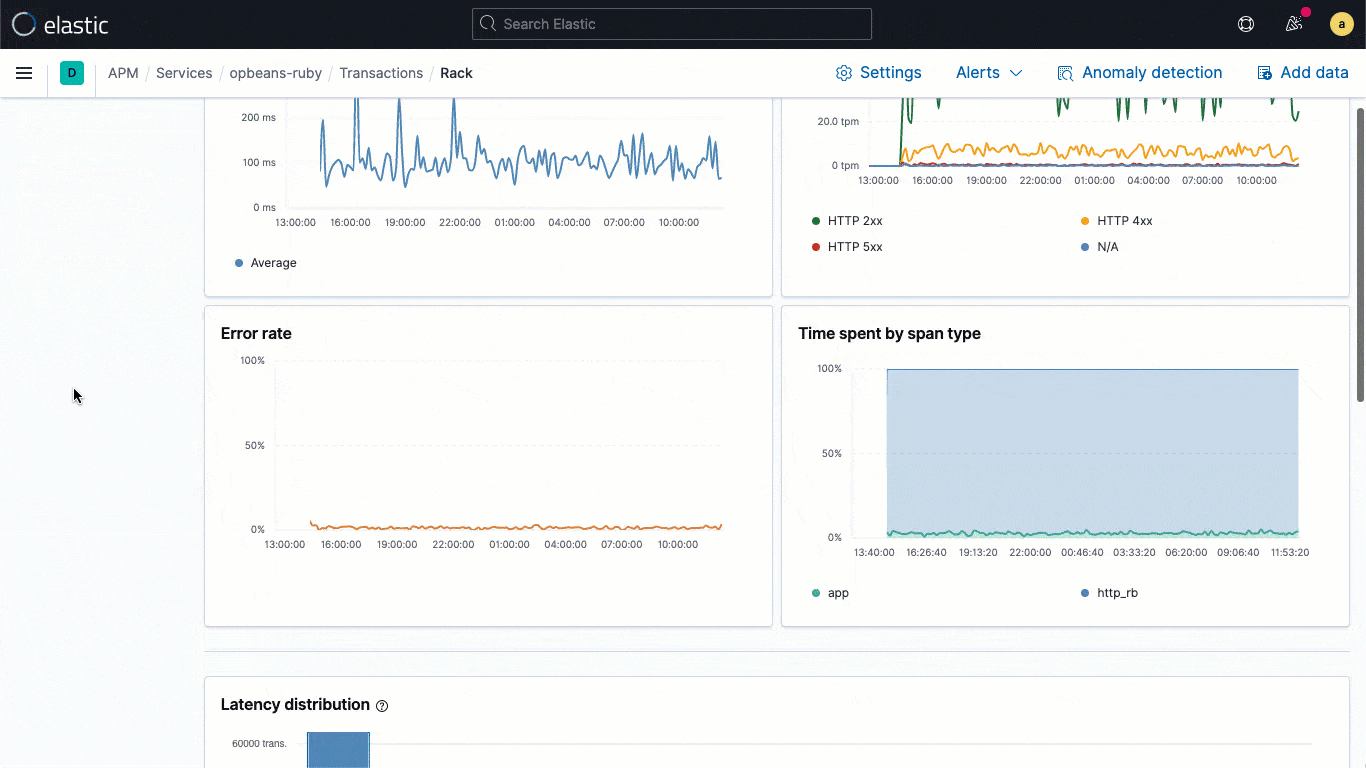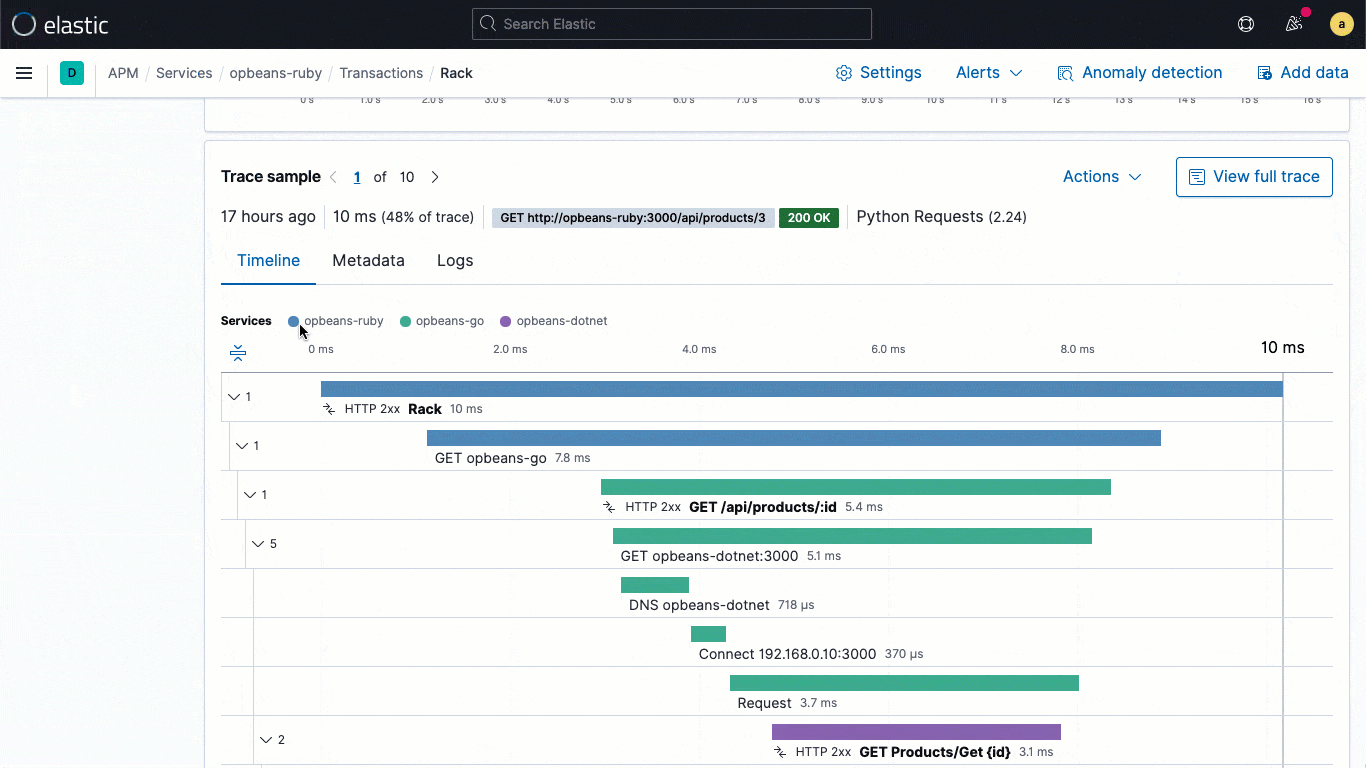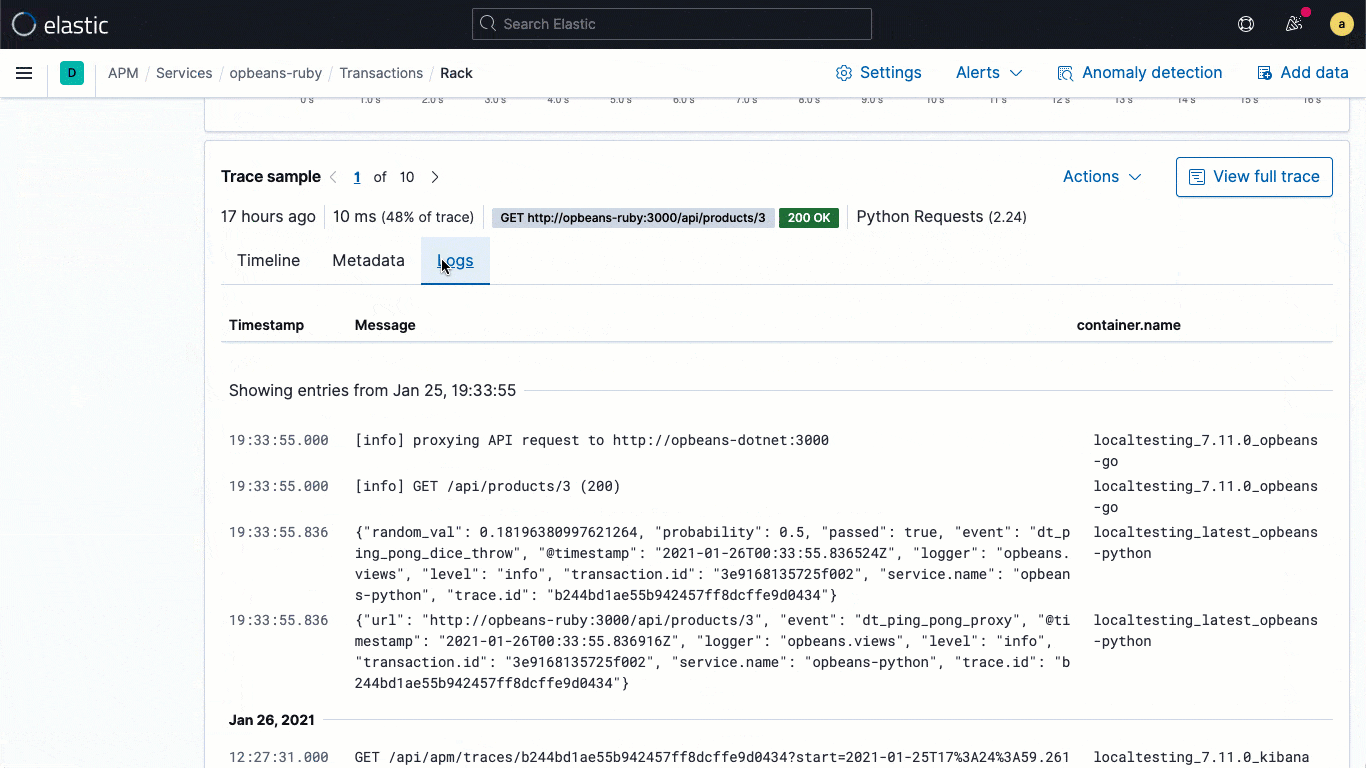
Moderne cloud-native Anwendungen bestehen oft aus Dutzenden oder Hunderten von Mikrodiensten. Für einen effizienten und effektiven Analytics-Workflow ist es wichtig, jederzeit in der Lage zu sein, den Zustand einzelner Dienste schnell zu ermitteln. Das kann auch helfen, den MTTI- und den MTTR-Wert zu verbessern. So kann beispielsweise eine kartografische Aufbereitung von Diensten dabei helfen, ein Anwendungsproblem auf einen konkreten Dienst einzugrenzen. Anschließend müssen Sie aber auch herausfinden, warum dieser Dienst nicht funktioniert. In 7.11 führen wir eine ganz neue Dienstübersichtsseite ein, die alle Informationen zum Zustand eines Dienstes an einem zentralen Ort zusammenfasst, sodass Entwickler und SREs nur noch eine Seite aufrufen müssen, um Fragen wie die folgenden zu klären:
- Wie hat sich ein neues Deployment auf die Performance ausgewirkt?
- Welche Transaktionen sind am meisten betroffen?
- Kommt es durch Downstream-Dienste oder Backends zu Regression?
- Wie korreliert die Performance mit der zugrunde liegenden Infrastruktur? Auf welchen Instanzen (Container, VMs) kommt es zu den Performance-Problemen?
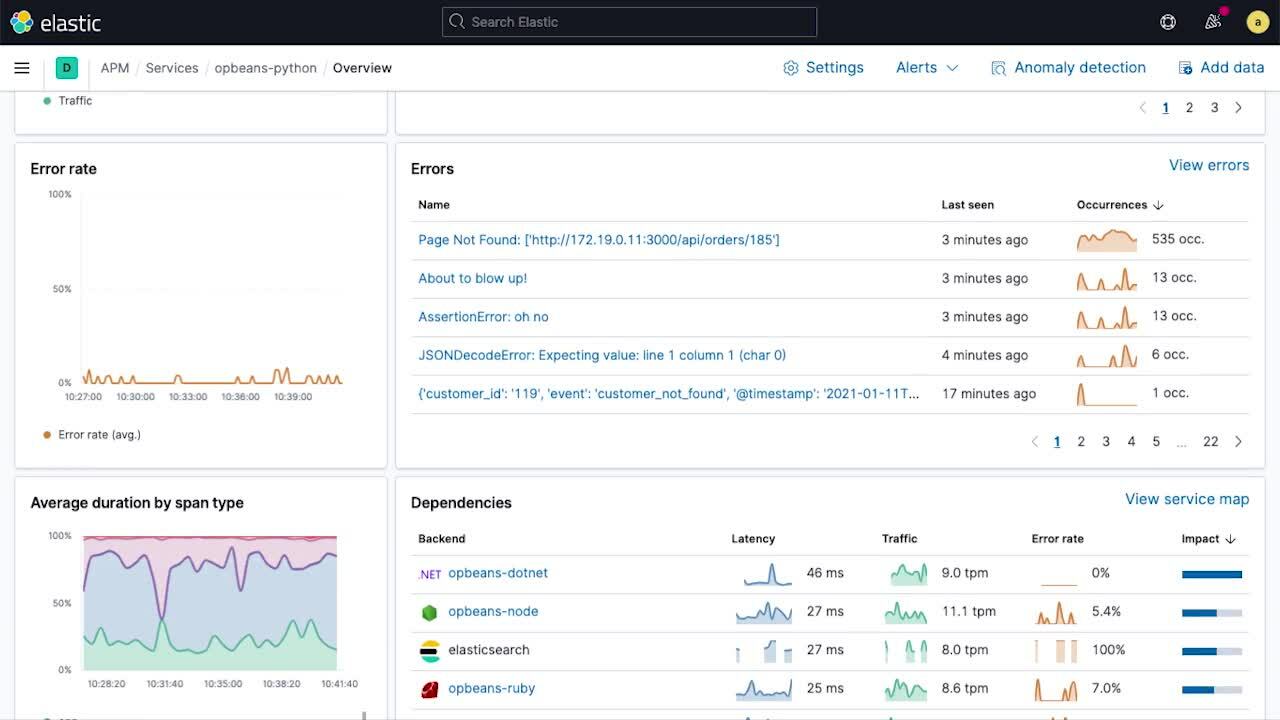
Zeitreihendiagramme zur Darstellung von Dienstlatenz, Datenverkehr und Fehlerraten bieten einen grundlegenden Überblick über die Entwicklung von Dienst-KPIs. Zusätzliche Annotationen im Zeitreihendiagramm, wie Deployment-Markers, Anomalie-Alerts usw., liefern umfassende Kontextinformationen für wichtige Ereignisse, die zu Verhaltensänderungen beigetragen haben könnten. Diese Annotationen helfen bei der Eingrenzung des Umfangs der Analyse und tragen so zur Suche nach Abhilfemaßnahmen (z. B. Durchführung eines Rollbacks) bei.
Die Sparklines auf der Dienstübersichtsseite bieten einen kompakten Überblick über temporäre Trends der Teilkomponenten, sodass bei der Analyse ungewöhnliche Änderungen im Verhalten (beispielsweise wenn die Fehlerrate bei einer bestimmten Transaktion in die Höhe schießt) einfach erkannt und sinnvolle „nächste Schritte“ ermittelt werden können. Auf der Dienstübersichtsseite wird außerdem die Dienstintegrität nach den zugrunde liegenden Infrastrukturinstanzen (z. B. Container) aufgeschlüsselt, auf denen der Dienst bereitgestellt wurde, um eine direkte Zuordnung von Problemen zur entsprechenden Infrastruktur vornehmen zu können.
In Version 7.11 wird die erste Phase dieser neuen Ansicht zum Dienstzustand eingeführt. In zukünftigen Versionen werden dann weitere Kontexte und Ansichten verfügbar sein, um die Workflows zur Fehlersuche und ‑beseitigung sowie zur Ursachenanalyse weiter zu rationalisieren und zu beschleunigen.
Neue erweiterte Host-Detailansicht für das schnellere Beheben von Infrastrukturproblemen
Die Ressourcen-Heatmap in der Metrics-App bietet einen Überblick über den Status Ihrer Infrastruktur, sodass Sie problematische Ressourcen (z. B. Hosts mit Spitzen bei der CPU-Nutzung) einfach schnell aufspüren und die nächsten Schritte der Analyse auf die Hosts einschränken können, die einer genaueren Prüfung bedürfen. Wir führen in der Metrics-App eine neue Ansicht ein, mit der Sie mühelos von der Überblicksebene aus historische Trends bei den Schlüsselmetriken für einzelne Hosts aufrufen können.
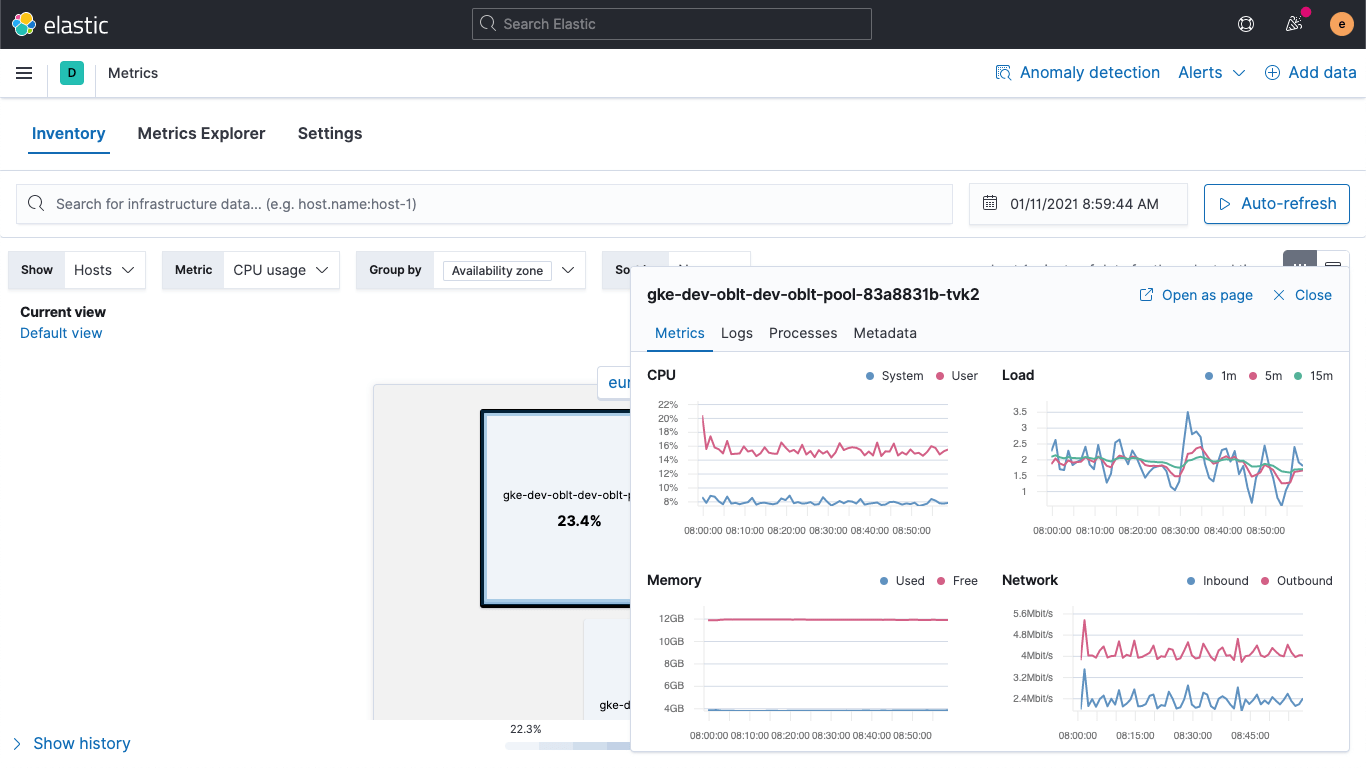
So ähnlich, wie die neue Dienstübersichtsseite in APM einen Überblick über Trends gibt, hilft auch die verbesserte Hostdetailansicht, die Ursachenanalyse zu beschleunigen, indem sie alle Informationen (Logdaten, Metriken, Prozesse usw.), die Sie über einen Host benötigen, in einer zentralen Ansicht zusammenführt, sodass Infrastrukturteams einfacher Probleme mit der Infrastruktur überwachen und beseitigen können.
Wenn Sie auf eine Kachel in der Heatmap klicken, erscheint ein Popup mit wichtigen Informationen zum Host:
- Zeitdiagramme wichtiger Host-Metriken (CPU, Arbeitsspeicher, Netzwerk usw.)
- Logdaten, die vom Host oder den auf diesem Host ausgeführten Diensten erzeugt werden
- Prozesse, die auf dem Host (durch die CPU oder den Arbeitsspeicher) ausgeführt werden
- Host-Metadaten (Details zum Betriebssystem, Cloud-Anbieter)
- Links, über die sich noch ausführlichere Informationen zu Trace- oder Uptime-Daten aufrufen lassen
In Version 7.11 steht diese neue erweiterte Ansicht in der Metrics-App für Hosts oder VMs zur Verfügung, in späteren Versionen dann auch für andere Ressourcentypen (Pods, Container usw.).
Mehr zur Dienstübersichtsseite und zu anderen neuen APM-Features finden Sie unter „Was gibts Neues in 7.11?“.
ECS-Logging-Bibliotheken verknüpfen Anwendungs-Logdaten automatisch mit Traces und vertiefen so die Observability von Anwendungen
Für Troubleshooting-Workflows bei Anwendungen ist es wichtig, Anwendungs-Logdaten und -Traces korrelieren und zwischen ihnen hin- und herwechseln zu können, ohne den Kontext zu verlieren. Welche Logdaten gehören zu welcher Trace oder welcher Trace hat die Logdaten erzeugt? Welche Anwendungsanfrage hat die Aufzeichnung dieser Logdaten ausgelöst? Die Logging-Bibliotheken im Elastic Common Schema (ECS), die in Version 7.11 allgemein verfügbar gemacht wurden, erleichtern es Anwendungsentwicklern, den vom APM-Agent erfassten Trace-Kontext automatisch in ihre Anwendungs-Logs zu injizieren, um die für eine reibungslose Analyse erforderliche Korrelation zwischen Logdaten und Traces herstellen zu können.
ECS-Logging-Bibliotheken sind Plugins für Logging-Frameworks (z. B. log4j) und ermöglichen es Entwicklern, Anwendungs-Logdaten in einem ECS-konformen JSON-Format zu schreiben, ohne dass die nativen Workflows geändert werden müssen. Die ECS-Logger schreiben den vom APM-Agent erfassten Trace-Kontext automatisch in das Log, sodass Entwickler ohne zusätzlichen Aufwand Observability für ihre Anwendungen implementieren können. Ein typischer Trace-Kontext enthält Werte für trace.id transaction.id und span.id.
Aufbauend auf dieser grundsätzlichen Verknüpfung auf Datenebene bringt 7.11 einen eingebetteten Logdaten-Stream direkt in die Trace-Ansicht. Nutzer können so bei der Analyse direkt die mit einer bestimmten Trace verknüpften Logdaten sehen, ohne den visuellen Kontext ändern zu müssen.
Neben dieser „Log ↔ Trace“-Korrelation hat das Erfassen von Logdaten im ECS-Format noch weitere Vorteile, wie automatisches Parsing, Logdaten in Klartext und ein über den gesamten Anwendungs-Stack hinweg normalisiertes Datenmodell.
Weitere Informationen dazu und zu anderen Verbesserungen beim Infrastruktur-Monitoring finden Sie unter „Was gibts Neues in 7.11?“.
Andere wichtige Highlights
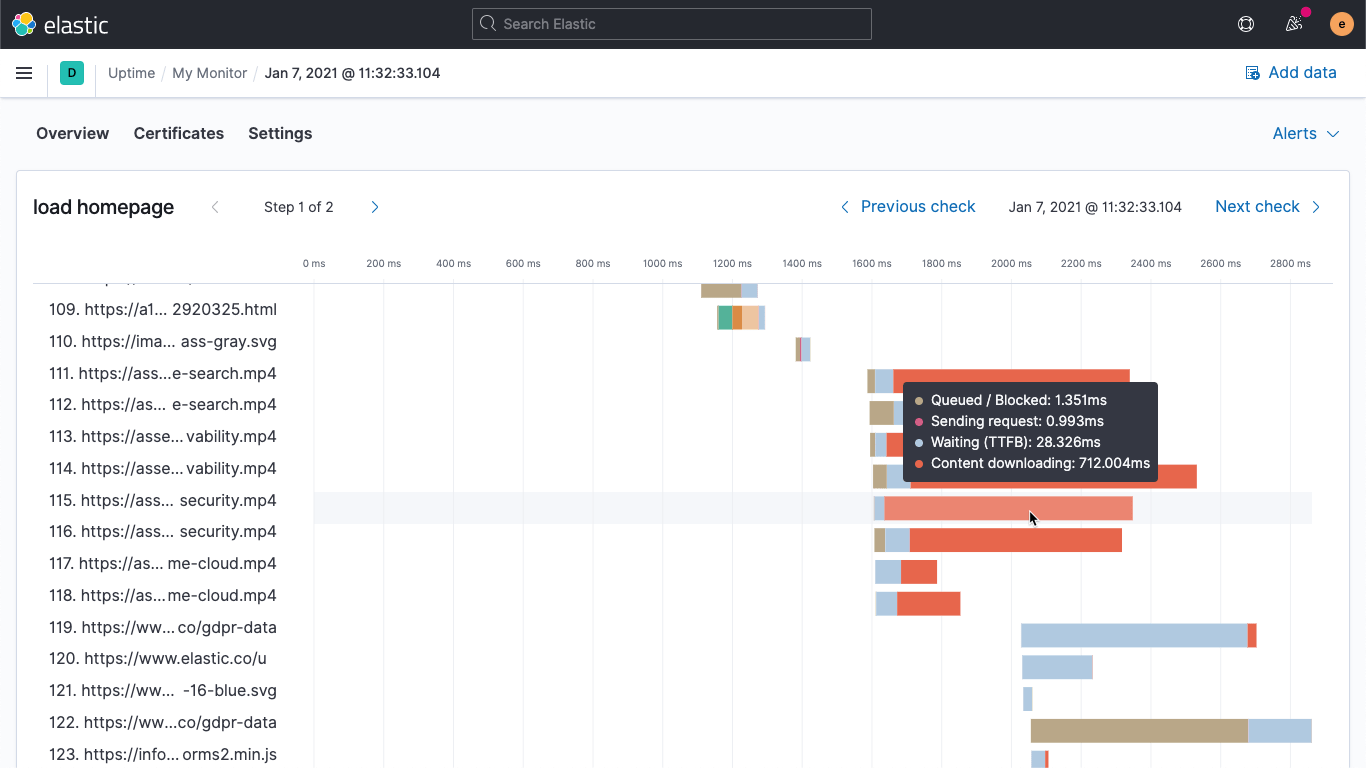
Wasserfalldiagramm zum Laden der Seite
In 7.10 haben wir das synthetische Monitoring für Mehrschritt-User-Journeys eingeführt. In 7.11 gibt es nun die erste Iteration unseres Wasserfalldiagramms zum Laden der Seite, das für jedes Objekt auf der Seite statistische Verbindungsinformationen zeigt. Das Wasserfalldiagramm gibt bei synthetischen Tests schnellen Aufschluss über Performance-Engpässe beim Endnutzer.
Laufzeitfelder bilden die Basis für Schema-on-Read
Mit der von der Elastic Observability-Community heiß ersehnten Funktion „Laufzeitfelder“ lassen sich zur Laufzeit ad hoc neue Felder erstellen, indem Felder aus den indexierten Daten transformiert, angereichert oder extrahiert werden. Damit ist diese Funktion etwas grundlegend Neues, das neue Observability-Workflows ermöglicht, darunter auch eines der meist gewünschten Features aller Zeiten: Schema-on-Read.
Mit dem Start dieser Funktion kommen die Nutzer in den Genuss des Besten aus beiden Welten: Sie können mit Schema-on-Write blitzschnell suchen und analysieren, indem Sie Daten schon beim Indexieren parsen und strukturieren, oder sie nutzen Schema-on-Read und definieren Felder ad hoc während der Laufzeit, um so mehr Flexibilität bei ihren Analytics-Workflows zu erhalten.
Laufzeitfelder werden in Elasticsearch in 7.11 unterstützt. Die Benutzeroberflächenunterstützung in Kibana ist eingeschränkt. Wenn Sie mehr über unsere Laufzeitfelder-Vision erfahren möchten, lesen Sie unseren Blogpost zum Thema.
Durchsuchbare Snapshots und Tier für „eingefrorene“ Daten jetzt allgemein verfügbar
Durchsuchbare Snapshots, die als Beta-Funktion in 7.10 eingeführt wurden, sind jetzt allgemein verfügbar. Mit durchsuchbaren Snapshots können Nutzer Daten in Objektspeichern wie S3 direkt durchsuchen und analysieren. Das erleichtert die Implementierung einer Daten-Tier-Strategie, mit der ein gutes Verhältnis von Performance und Kosten gefunden werden kann. Die durch durchsuchbare Snapshots ermöglichte neue Tier für „kalte“ Daten kann bei nur minimalen Performance-Einbußen die Speicherkosten um bis zu 50 % reduzieren.
Durchsuchbare Snapshots und Daten-Tiers sind Features, die die Observability grundlegend transformieren. Mit ihnen können Nutzer mit weniger mehr tun, ohne dass dies mit einer größeren operationalen Komplexität, einer Änderung bei den Analyse-Workflows oder einer Einschränkung beim Zugriff auf Daten einhergeht.
Probieren Sie die neue Version gleich aus!
Wenn Sie mehr über all diese neuen Funktionen erfahren möchten, sehen Sie sich den Überblick über die Neuigkeiten in der neuen Version an.
Oder besser noch: Upgraden Sie Ihr Deployment auf 7.11, um diese interessanten neuen Funktionen nutzen zu können. Wie? Entweder Sie probieren den Elasticsearch Service 14 Tage lang kostenlos aus oder Sie installieren die neueste Version des Elastic Stack.