Elastic Platform 8.14: ES|QL GA, encryption at rest, and vector search optimizations


 Share on Twitter
Share on TwitterAuf Twitter teilen

 Share on LinkedIn
Share on LinkedInAuf LinkedIn teilen

 Share on Facebook
Share on FacebookAuf Facebook teilen

 Share by Email
Share by EmailPer E-Mail teilen

 Print this page
Print this pageDrucken
Elastic Platform 8.14 delivers the general availability (GA) of Elasticsearch Query Language (ES|QL) — the future of data exploration and manipulation in Elastic. It also includes the GA release of several other new features: Logstash on ECK, API key-based security model for remote clusters, AIOps log pattern analysis, built-in data stream lifecycle settings for retention and downsampling, dashboard links panels, and more. Also with 8.14, the Elastic Cloud platform makes encryption of data and snapshots at rest using customer-managed keys from AWS Key Management Service (AWS KMS) generally available.
On the relevance ranking front, Elasticsearch 8.14 introduces optimizations to vector search for improved performance, makes scalar quantization of vectors the default option, and introduces the concept of retrievers to simplify queries and allow more flexibility in query construction.
These new features allow customers to:
Compose powerful queries to expose data insights in new ways
Achieve regulatory compliance and enhanced security with encryption at rest using their AWS KMS keys
Easily manage retention and downsampling for time series data using data streams
Automatically manage Logstash pods in Kubernetes
Find patterns in unstructured log messages to quicken RCA and reduce MTTR
Elastic 8.14 is available now on Elastic Cloud — the only hosted Elasticsearch offering to include all of the new features in this latest release. You can also download the Elastic Stack and our cloud orchestration products — Elastic Cloud Enterprise and Elastic Cloud for Kubernetes — for a self-managed experience.
Elastic’s piped query language, ES|QL, is now generally available
ES|QL offers a streamlined way to filter, transform, and analyze data in Elasticsearch. Its intuitive design, utilizing "pipes" (|) for step-by-step data exploration, enables you to easily compose powerful queries for detailed analysis.
Whether you're a developer, SRE, or security analyst, ES|QL empowers you to uncover specific events, perform robust statistical analyses, and create compelling visualizations. As we move from technical preview to general availability, discover the enhanced capabilities of ES|QL and elevate your data operations.
ES|QL enables complex multi-step analysis to be performed all in one query. This could be things that would have taken huge search queries before, or might not have even been possible in a search.
For example, this query identifies hosts that have the highest number of outbound connections:
FROM logs-*
| WHERE NOT CIDR_MATCH(destination.ip, "10.0.0.0/8", "172.16.0.0/12", "192.168.0.0/16")
| STATS destcount = COUNT(destination.ip) BY user.name, host.name
| ENRICH ldap_lookup_new ON user.name
| WHERE group.name IS NOT NULL
| EVAL follow_up = CASE(destcount >= 100, "true","false")
| SORT destcount DESC
| KEEP destcount, host.name, user.name, group.name, follow_upNote how this query includes not only filters and aggregations, but a CASE statement and enriching based on a lookup into an enrich policy - previously only possible within ingest pipelines.
Want more ES|QL?
- If you don’t have your own environment you can also try ES|QL with some sample data instantly in our ES|QL Demo environment.
- Head over to Search Labs for a comprehensive overview of E|QL features and future plans.
Encrypt data and snapshots at rest with customer-managed keys
Elastic Cloud now supports integration with AWS KMS, enabling the use of customer-managed keys for encrypting deployment data and snapshots at rest. With this feature, customers can:
Leverage filesystem-level encryption for deployment data at rest using their own AWS KMS keys.
Employ the AWS-native mechanism for snapshot encryption in S3.
Rotate their keys used in Elastic Cloud, providing an additional security measure to prevent key compromise. This can be done manually directly from AWS KMS or automatically from Elastic Cloud.
Revoke their keys used in Elastic Cloud, serving as a break-glass operation in case of emergency with the ability to revert the action. This can be done directly from AWS KMS.
This addition expands the existing encryption at rest capability with Elastic-managed keys. The primary benefits of using customer-managed keys include regulatory compliance and reduction of risks associated with data storage.
Retrievers (standard, kNN, and RRF)
Retrievers are a new type of abstraction in the _search API that describes how to retrieve a set of top documents. Retrievers are designed to be nested in a tree structure so that any retriever can have child retrievers. Retrievers are a standard, more general and simpler API that replaces other various _search elements like kNN and query. In 8.14 we introduce support for three types of retrievers:
Standard — providing standard query functionality
kNN — enabling HNSW-based dense vector search
RRF — merging various dense and sparse vector-ranking result set into a single blended and ranked result set using the reciprocal rank fusion algorithm
There are two main benefits to the retrievers approach:
Retrievers are all structured in the same way, so they are easier to learn, write, and maintain.
Being designed to be combined together in a tree structure provides more flexibility to design queries that could not be defined before — for example, not having kNN or RRF as a top-level element.
The introduction of retrievers is yet another step in our move to simplify the use of search in general and of vector search in particular. This theme includes enhancements like automatic vector normalization for a more performant cosine similarity and the introduction of RRF so that there is no need for tuning to achieve a high-quality blended set. We continue to invest heavily in that and plan to introduce relevance ranking through our new ES|QL language in the future.

See this blog for additional examples for the use of RRF with retrievers.
Vector distance function optimized with SIMD (Neon) for int8 vectors
Elasticsearch now uses native code for vector comparison using SIMD (Neon) for improved performance on ARM AArch64 architecture processors. The details of this enhancement are discussed in Vector Similarity Computations - ludicrous speed. The bottom line is that segment merging of int8 vectors has become several times faster than it was on these processors (typically 3–6 times faster). This improvement frees up resources for other tasks and speeds up the segment size optimization process.
This is yet another step in a series of vector similarity performance improvements. In the future, we intend to use this kind of optimization in other contexts, such as improving query latency.
Int8 quantization by default for dense vector fields
Many models produce vectors with float32 elements. However, when examining real-life scenarios, it quickly becomes apparent that int8 elements provide a better compromise with a significantly smaller index (lower cost), improved ingest performance, and improved query latency. All of that is achieved with hardly any impact on ranking quality. The little impact that can sometimes be spotted in ranking quality metrics, such as NDCG or recall, can be easily mitigated by increasing the number of candidates that are being considered. But even without that, the change is typically not noticeable for end users, nor from a business perspective.
With that in mind, we introduced scalar quantization to int8 in 8.12. After examining the production use of this functionality, we decided to make it the default behavior for new indices. Providing sensible defaults like that makes it easier for users that make their first steps toward vector search.
General availability of Logstash on ECK
Logstash on ECK is now the easiest way to install and manage Logstash deployments and offers seamless operation with the management of other Elastic Stack components. With just a few lines of code, users can deploy and configure Logstash pods on Kubernetes. Existing Logstash pipeline definitions just work when Logstash is deployed on ECK, making it easy for users to take advantage of the flexibility and scalability of Kubernetes. Logstash on ECK is available under Elastic’s Basic and Enterprise licenses.
API key-based security model for remote clusters is now GA
Remote cluster connections are the foundation of all CCS and CCR operations: they must ensure high-grade security while staying flexible and easy to use for users.
Using the API key-based security model, administrators can grant fine-grained access to their data and cover modern scenarios that don’t reflect the assumptions of the previous model.
In a modern world, remote clusters are often not fully trusted and administrators need to have full control over their data and who can access them.
The new security model introduces two key assumptions:
The trust relationship is unidirectional: If ClusterA configured ClusterB as its remote, ClusterB cannot automatically “call back” ClusterA.
Remote administrators are not trusted by design: The remote cluster holding data can restrict access to just a given subset of its indices, and no one — including superusers on the other cluster — can access anything else.
The core of the authentication and authorization flow are cross-cluster API keys — a new dedicated type that is scoped for this specific task only. API keys can be created via Elasticsearch API or using Kibana, and they define CCS and CCR indices in the same way we’re used to. They can also be easily updated in case requirements change over time.
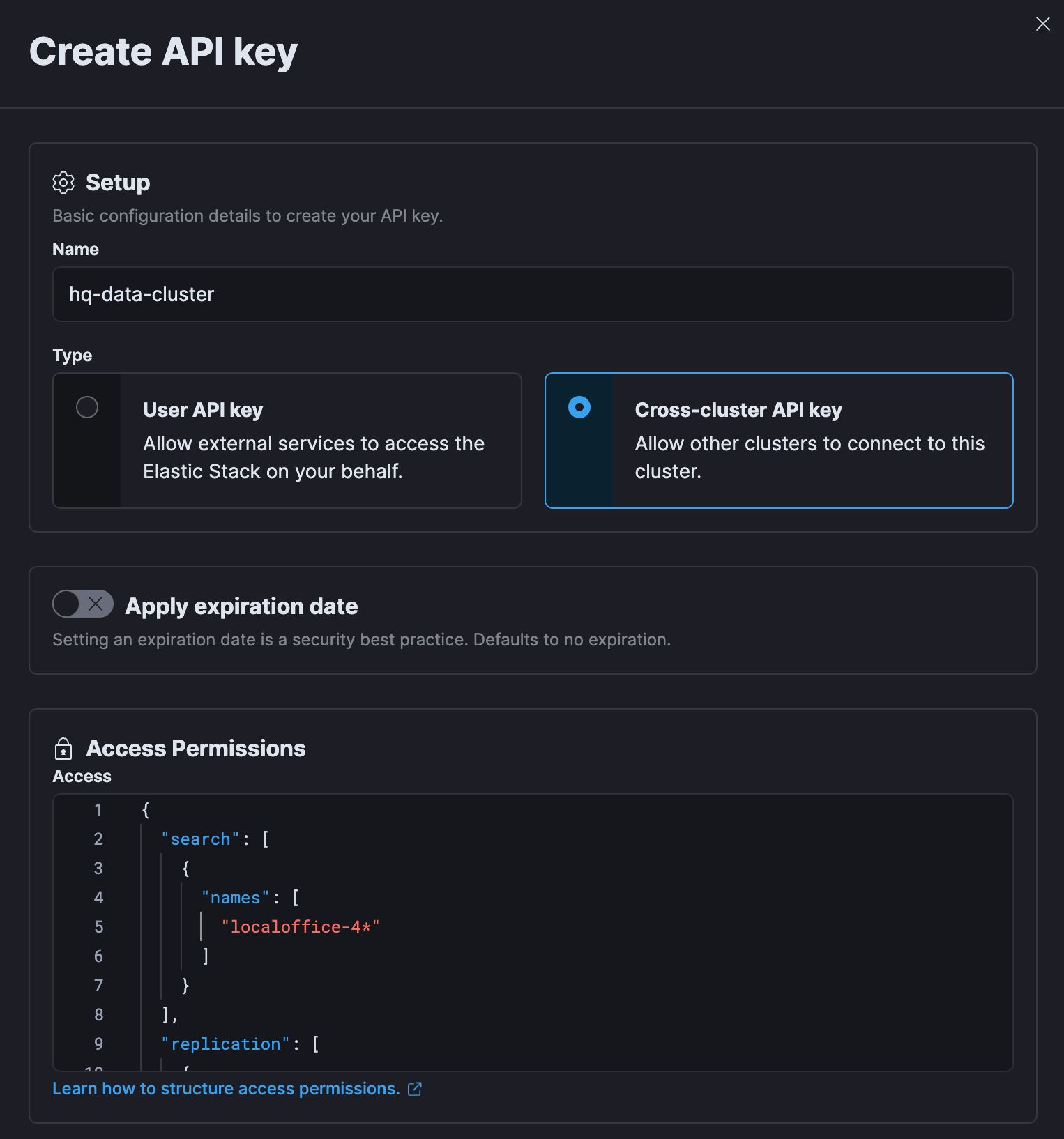
The API key-based security model is now GA in Elasticsearch 8.14, and it can be used on Elastic Cloud, Elastic Cloud Enterprise, and standalone deployments. This is now our recommended option for all remote clusters that support it.
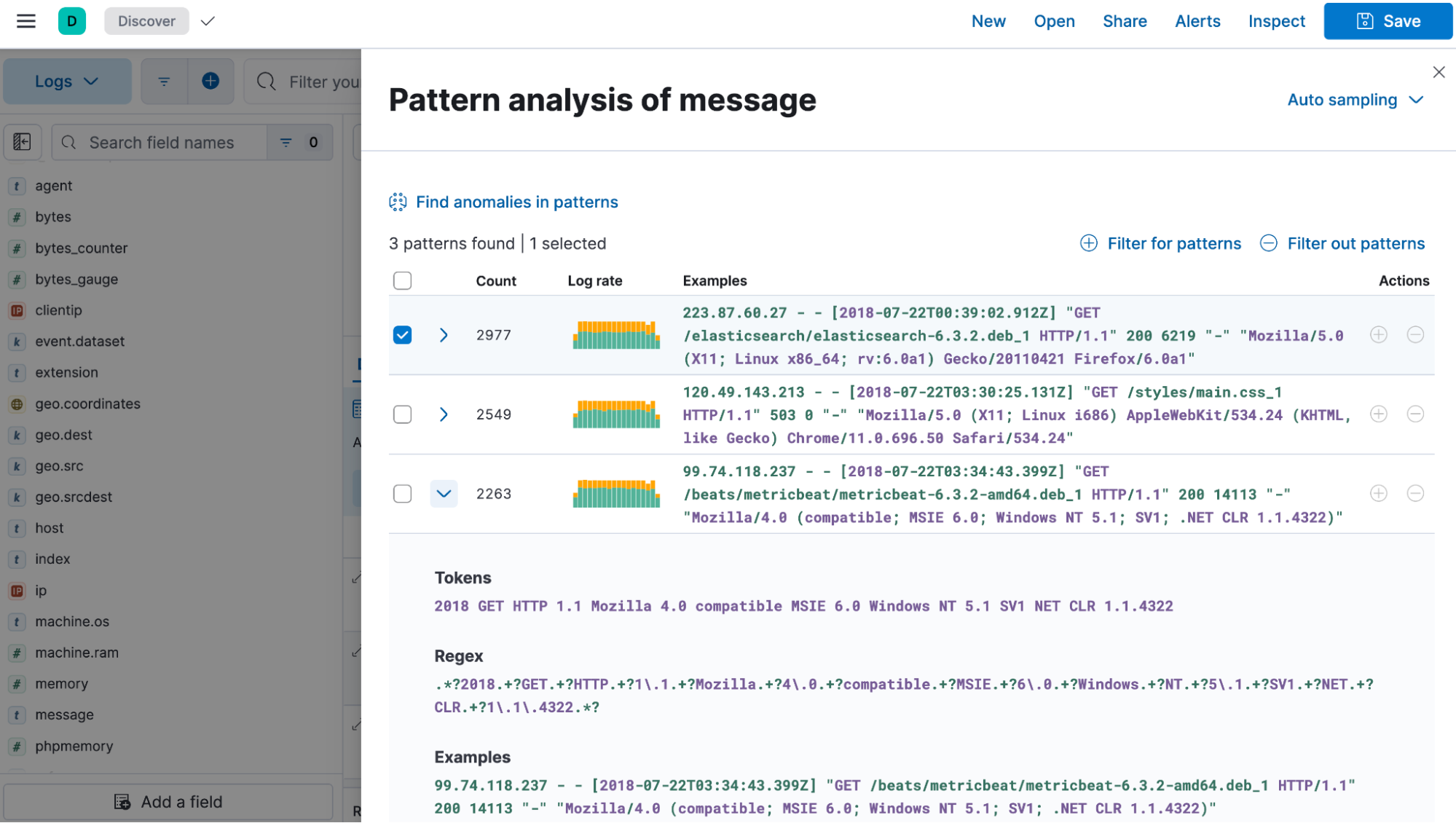
AIOps log pattern analysis is generally available
In 8.14, log pattern analysis becomes GA. Log pattern analysis enables faster and smarter investigation across thousands of log messages in order to analyze, troubleshoot, and identify the root cause of an incident. Combine it with anomaly detection and our other AIOps features to drastically reduce the MTTR.
Data stream lifecycle settings now GA
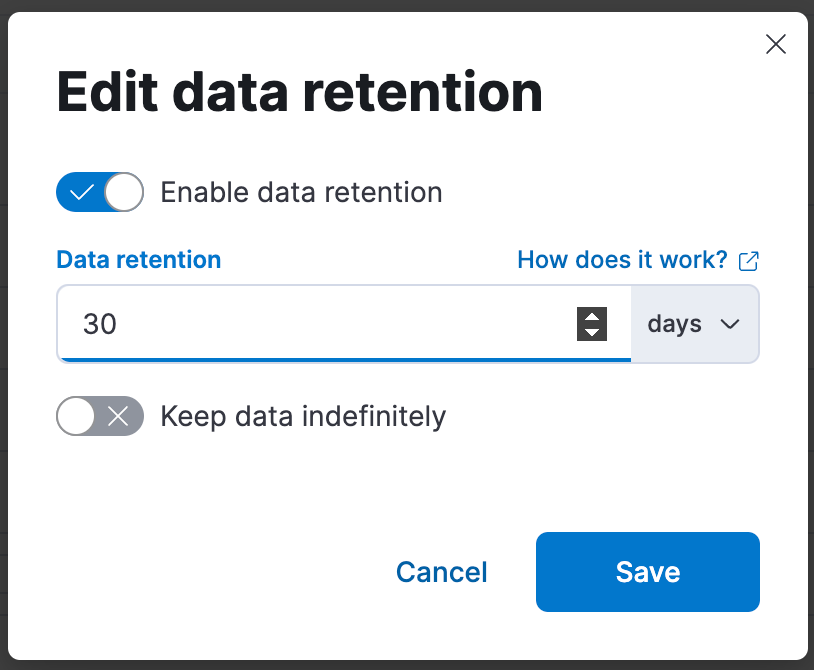
In 8.11, we introduced new lifecycle settings built-in to data streams as an easy, new way to configure retention or downsampling without needing to use index lifecycle management (ILM). This new lifecycle capability in data streams also takes care of housekeeping for you, managing rollover and force merging automatically. And now it’s GA in 8.14.
It’s really easy to use. You can set the retention for a data stream in Kibana’s Index Management page under Data Streams:
Or via the _data_stream API:
PUT _data_stream/my-data-stream/_lifecycle
{
"data_retention": "90d"
}You can update an existing data stream to use these settings, create a new data stream using this, or migrate a data stream from ILM. This is also being used automatically by some of the system indices like ilm-history and slm-history.
The lifecycle setting for data streams only works on data streams, not regular indices. It also doesn’t have any support for moving data to different tiers — if you need that, stick with ILM for now.
What if you start using the lifecycle setting on a data stream for its ease, and then realize you need ILM instead for some advanced functionality like data tiers? We have you covered: data streams can be switched to and from ILM as needed. Just configure ILM, which takes precedence over any data stream lifecycle configuration.
Document comparison mode in Discover and ES|QL
We are enabling users to select and compare documents or fields. This functionality will be a game-changer for tasks like debugging, allowing you to perform detailed comparisons, such as diffing SIP messages of a certain ID across multiple documents in Elasticsearch. This will streamline your analysis and troubleshooting processes.

Links panel is GA
You can now easily navigate from one dashboard to another using the links panel. Organize your dashboards better and make them more performant by chunking them in multiple dashboards with fewer visualizations and linking them together. You can carry over your filters, query, and time range when navigating to other related dashboards. Display your links horizontally or vertically as it better suits your dashboard layout. You can also use the links panel to include external links in your dashboards like to your wiki page or other applications. And decide whether you want to open the links in the same browser tab or in a new one.

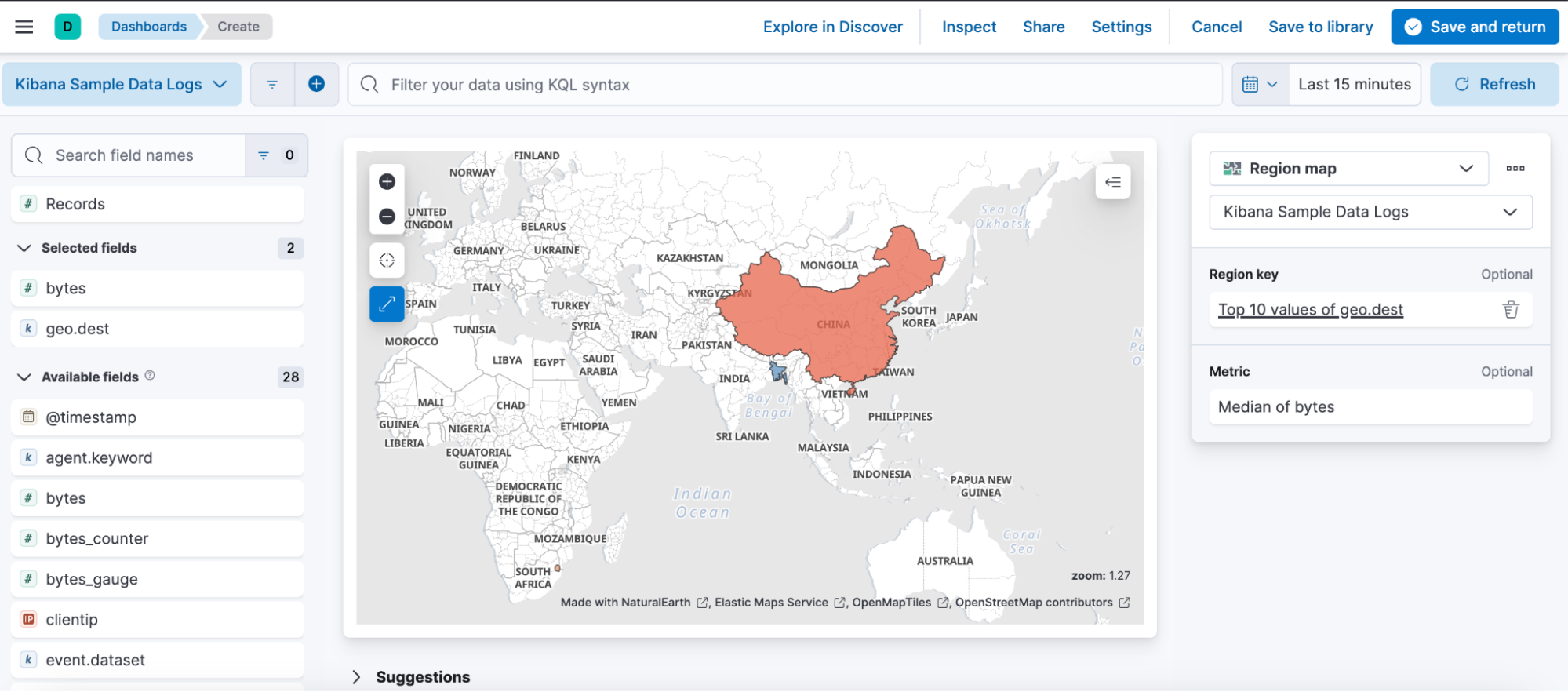
Region map goes GA
Users don’t need to navigate the complexity of the Elastic Maps app (meant to be used by more advanced geo users) to build a simple map. They can now do it easily from the Lens editor.
New Spanish plural stemmer
In 8.14, we are adding support for a Spanish stemmer in addition to the Spanish stemmer we already offer and will continue to support. This new stemmer transforms plural to singular but does not alter gender, so it is suitable for particular use cases.
Use MaxMind Enterprise and Anonymous IP files with ingest GeoIP processors
Our customers rely on GeoIP enrichment to help them locate customer problems, screen transactions for fraud, identify security threats and suspicious activity, and more. You can use the GeoIP enrich ingest processor to add information about the location of an IP address to an incoming document, such as a log entry or security event. We automatically download the latest free MaxMind GeoLite2 databases to ensure they are up to date (as required by MaxMind’s EULA) and distribute them throughout the cluster to be used by ingest processing.
This is convenient and satisfies many customers and use cases. However, some enterprises need the additional accuracy and fields that are offered by the paid GeoIP files, such as the GeoIP2 Enterprise Database and the GeoIP2 Anonymous IP Database. This enables them to have more confidence in the decisions they make based on the geolocation data, such as blocking potentially fraudulent transactions or denying access to services.
Elasticsearch 8.14 adds support for using those two paid geo databases with the GeoIP ingest processor in technical preview. In 8.14, you will have to manage the download and deployment of the files. We’re working to add automatic downloading of these files to a future release to make it more seamless to keep them updated.
Enrich policies can target data streams
Speaking of enrichment, it’s now easier to use a data stream as the source of reference data for enrich policies. Previously, if a data stream was targeted by an enrich policy like the following . . .
PUT /_enrich/policy/my-policy
{
"match": {
"indices": ["data_stream"],
"match_field": "fieldA",
"enrich_fields": ["fieldB", "fieldC"]
}
}. . . then an index_not_found_exception error was returned. Elasticsearch 8.14 now supports specifying a data stream as the indices source, so you can benefit from the time series management features of data streams and use them for enrichment at the same time.
Write to an index after ILM shrink
You might be using the ILM shrink action to reduce the number of primary shards in an index once it no longer needs extra-high write parallelism for indexing throughput. A source index must be read only during the shrink processing, so ILM sets them to read-only. Historically, ILM would also leave the new (shrunken) index read-only, blocking writes.
We heard from users who need to be able to write to the shrunken index as updates arrive for older documents, so we added an option (allow_write_after_shrink) to remove the write block after shrinking. For backward compatibility, this configuration parameter defaults to false, thus keeping the target index read-only.
User information in the slow log
The slow log is one of the main troubleshooting resources to identify and fix problematic queries that don’t perform well and that may affect the entire system. One of the main hurdles was to identify the user that performed the query since it’s not always clear to figure it out looking at the query itself.
In Elasticsearch 8.14, it’s now possible to track the calling user information directly in the slow log so that administrators can solve problems more efficiently.
You can enable it for both index and search log entries by calling the Update index settings API:
PUT /my-index-000001/_settings
{
"index.indexing.slowlog.include.user": true,
"index.search.slowlog.include.user": true
}After that, the output will report user information:
…
"auth.type": "REALM",
"auth.name": "elastic",
"auth.realm": "reserved"
…Try it out
Read about these capabilities and more in the release notes.
Existing Elastic Cloud customers can access many of these features directly from the Elastic Cloud console. Not taking advantage of Elastic on cloud? Start a free trial.
The release and timing of any features or functionality described in this post remain at Elastic's sole discretion. Any features or functionality not currently available may not be delivered on time or at all.
In this blog post, we may have used or referred to third party generative AI tools, which are owned and operated by their respective owners. Elastic does not have any control over the third party tools and we have no responsibility or liability for their content, operation or use, nor for any loss or damage that may arise from your use of such tools. Please exercise caution when using AI tools with personal, sensitive or confidential information. Any data you submit may be used for AI training or other purposes. There is no guarantee that information you provide will be kept secure or confidential. You should familiarize yourself with the privacy practices and terms of use of any generative AI tools prior to use.
Elastic, Elasticsearch, ESRE, Elasticsearch Relevance Engine and associated marks are trademarks, logos or registered trademarks of Elasticsearch N.V. in the United States and other countries. All other company and product names are trademarks, logos or registered trademarks of their respective owners.
Teilen
- Share on Twitter
Auf Twitter teilen
- Share on LinkedIn
Auf LinkedIn teilen
- Share on Facebook
Auf Facebook teilen
- Share by Email
Per E-Mail teilen
- Print this page
Drucken

