Primeros pasos con ES|QL (Elasticsearch Query Language)
Crea agregaciones, visualizaciones y alertas directamente desde Discover con ES|QL para reducir el tiempo de creación de información

 Share on Twitter
Share on TwitterComparte en Twitter

 Share on LinkedIn
Share on LinkedInComparte en LinkedIn

 Share on Facebook
Share on FacebookComparte en Facebook

 Share by Email
Share by EmailComparte por correo electrónico

 Print this page
Print this pageImprime
¿Qué es ES|QL (Elasticsearch Query Language)?
ES|QL (Elasticsearch Query Language) es el nuevo lenguaje de búsqueda con barras verticales innovador de Elastic®, diseñado para acelerar los análisis de datos y procesos de investigación ofreciendo capacidades de agregación y procesamiento poderosas.
Navega por las complejidades de identificar ataques cibernéticos en desarrollo o problemas de producción con facilidad y eficiencia mejoradas.
ES|QL no solo simplifica la búsqueda, agregación y visualización de sets de datos masivos, sino que también empodera a los usuarios con características avanzadas, como búsquedas tipo lookup y procesamiento en tiempo real, todo desde una única pantalla en Discover.
ES|QL agrega 3 capacidades poderosas al Elastic Stack
-
Un nuevo y rápido motor de búsqueda dedicado y distribuido que impulsa _query. El nuevo motor de búsqueda de ES|QL brinda capacidades de búsqueda avanzadas con procesamiento concurrente y mejora así la velocidad y la eficiencia independientemente de la estructura y la fuente de datos. El rendimiento del nuevo motor se mide y es público. Sigue la evaluación comparativa de rendimiento en este dashboard público.
-
Un nuevo y poderoso lenguaje con barras verticales. ES|QL es el nuevo lenguaje con barras verticales de Elastic que transforma, enriquece y simplifica las investigaciones de datos. Obtén más información sobre las capacidades del lenguaje ES|QL en la documentación.
-
Una experiencia de investigación y exploración de datos nueva y unificada que acelera la resolución creando agregaciones y visualizaciones desde una pantalla que brinda un flujo de trabajo ininterrumpido.
¿Por qué invertimos tiempo y esfuerzo en ES|QL?
Nuestros usuarios necesitan herramientas ágiles que no solo presentan datos, sino que ofrecen también métodos eficientes para darles sentido, además de la capacidad de actuar sobre la información en tiempo real y luego del procesamiento de datos de ingesta.
El compromiso de Elastic con mejorar la experiencia de exploración de datos de los usuarios nos llevó a invertir en ES|QL. Está diseñado para ser accesible para los principiantes y poderoso para los expertos. Con la interfaz intuitiva de ES|QL, los usuarios pueden comenzar rápido y adentrarse en sus datos sin curvas de aprendizaje pronunciadas. La documentación en la app y autocompletar garantizan que elaborar búsquedas avanzadas se vuelva un flujo de trabajo sencillo.
Además, ES|QL no solo muestra números, les da vida. Las visualizaciones contextuales impulsadas por el motor de sugerencias Lens se adaptan automáticamente a la naturaleza de tus búsquedas, lo cual brinda una vista clara de tu información.
Además, una integración directa en las funcionalidades Dashboards y Alerting refleja nuestra visión de una experiencia integral y cohesiva.
Básicamente, nuestra inversión en ES|QL fue una respuesta directa a las necesidades en evolución de nuestra comunidad; un paso hacia un flujo de trabajo más interconectado, revelador y eficiente.
Profundizar en los casos de uso de observabilidad y seguridad
Nuestro compromiso con ES|QL también surge de una comprensión profunda de los desafíos que enfrentan nuestros usuarios (p. ej., los ingenieros de confiabilidad del sitio [SRE], DevOps y buscadores de amenazas).
Para los SRE, la observabilidad es esencial. Cada segundo de tiempo de inactividad o fallo puede tener un efecto cascada en la experiencia del usuario y, en consecuencia, en los resultados. Un ejemplo de esto es la característica Alerting de ES|QL: con su énfasis en resaltar tendencias significativas por sobre incidentes aislados, los SRE pueden identificar y abordar de manera proactiva fallos o ineficiencias en el sistema. Esto reduce el ruido y garantiza que reaccionen a amenazas genuinas a la estabilidad del sistema, lo que hace que su respuesta sea más oportuna y efectiva.
Los equipos de DevOps se encuentran de manera constante en una carrera contra el tiempo; despliegan varias actualizaciones, parches y características nuevas. Con la exploración y la visualización de datos poderosas y nuevas de ES|QL, pueden evaluar rápidamente el impacto de cada despliegue, monitorear el estado del sistema y recibir comentarios en tiempo real. Esto no solo mejora la calidad de los despliegues, sino que asegura una rápida corrección del curso, de ser necesario.
En el caso de los buscadores de amenazas, el panorama de seguridad evoluciona y cambia constantemente. Un ejemplo de cómo ES|QL los empodera en este panorama cambiante es la característica ENRICH. Esta característica les permite buscar datos en distintos sets de datos, de este modo revela anomalías o patrones ocultos que pueden indicar una amenaza de seguridad. Además, las visualizaciones contextuales significan que no solo ven datos, sino que obtienen información procesable, presentada de manera visual. Esto reduce drásticamente el tiempo necesario para distinguir amenazas potenciales, lo que garantiza reacciones más rápidas frente a vulnerabilidades.
Seas un SRE intentando descifrar un aumento repentino en la carga del servidor, un profesional de DevOps evaluando el impacto del lanzamiento más reciente o un buscador de amenazas investigando una potencial filtración, ES|QL complementa al usuario, más que complicar el recorrido.
Las secciones siguientes del blog te ayudarán a dar los primeros pasos con ES|QL y mostrar algunos ejemplos tangibles de lo poderoso que es para explorar los datos.
Cómo dar los primeros pasos con ES|QL en Kibana
Para comenzar a usar ES|QL, navega a Discover y simplemente selecciona Try ES|QL (Probar ES|QL) en el selector de vista de datos. Es sencillo y fácil de usar para el usuario.
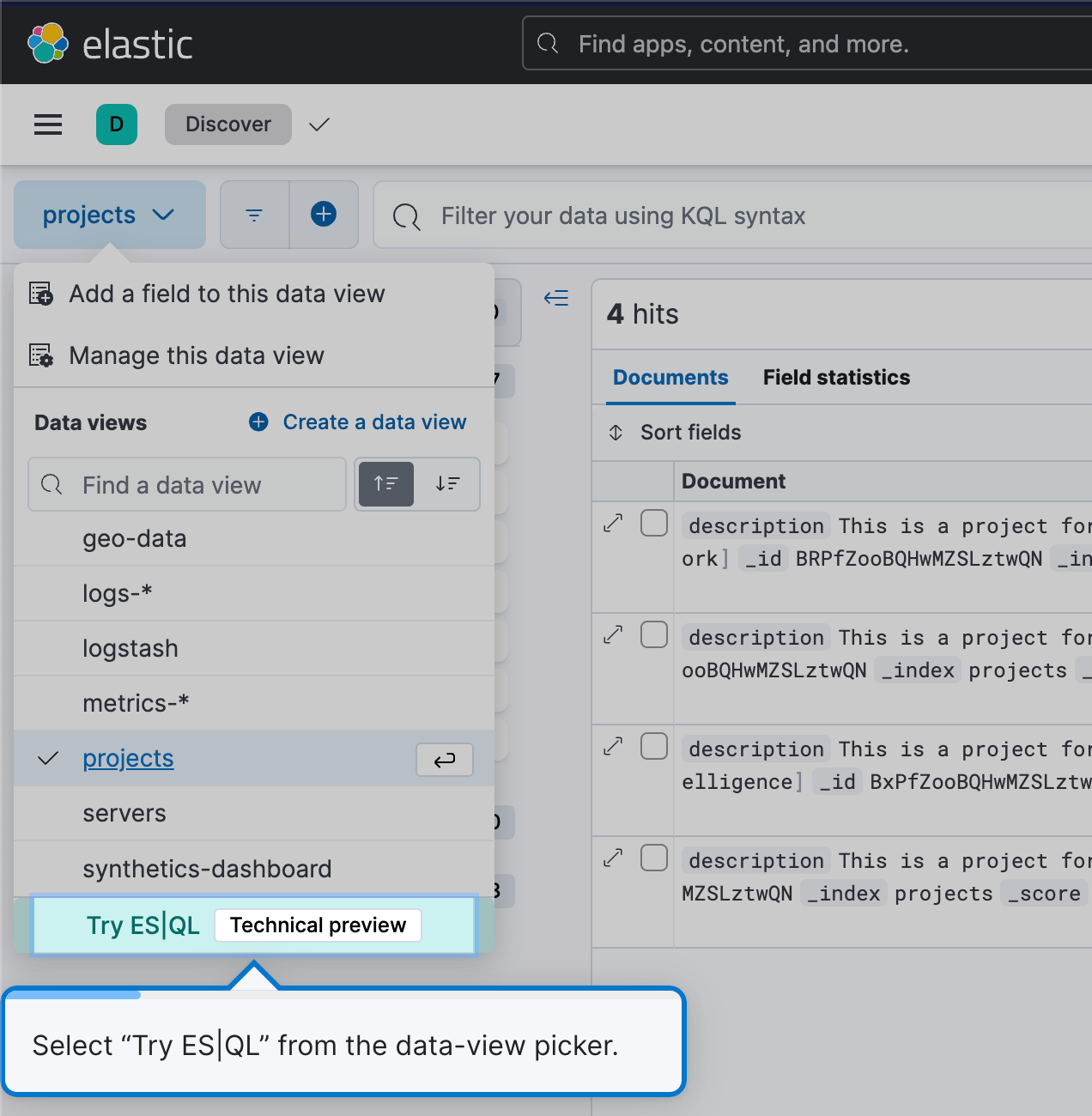
Esto te pondrá en modo ES|QL en Discover.
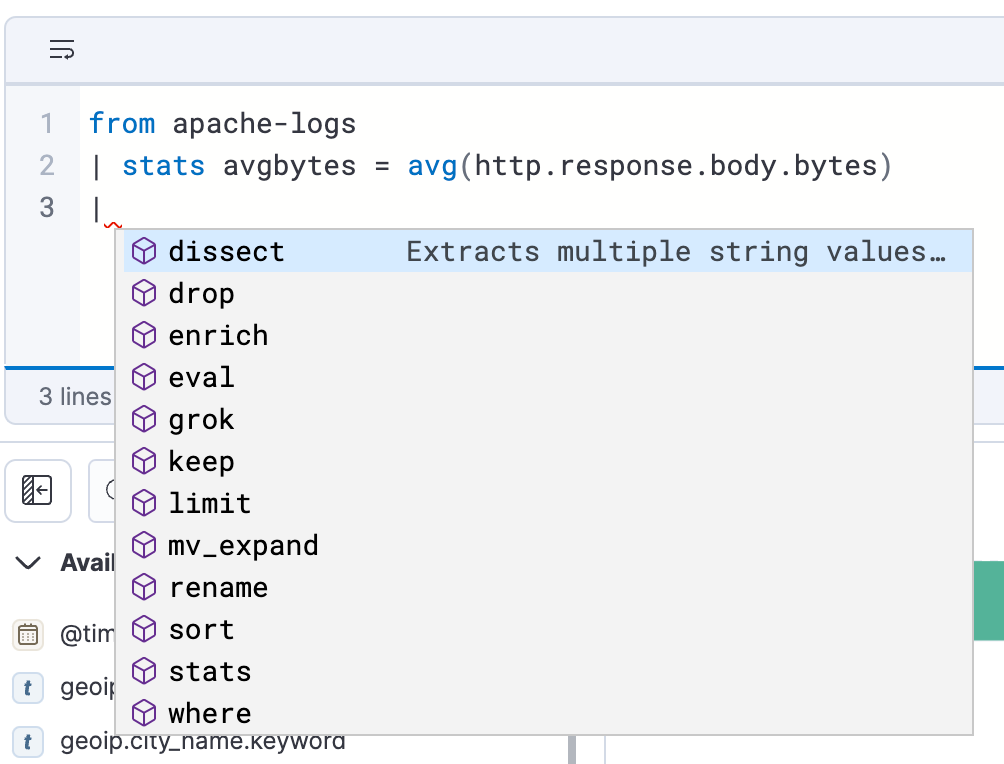
Crear búsqueda de forma fácil y eficiente
ES|QL en Discover ofrece documentación en la app y autocompletar, lo que facilita la elaboración de búsquedas poderosas directamente desde la barra de búsqueda.
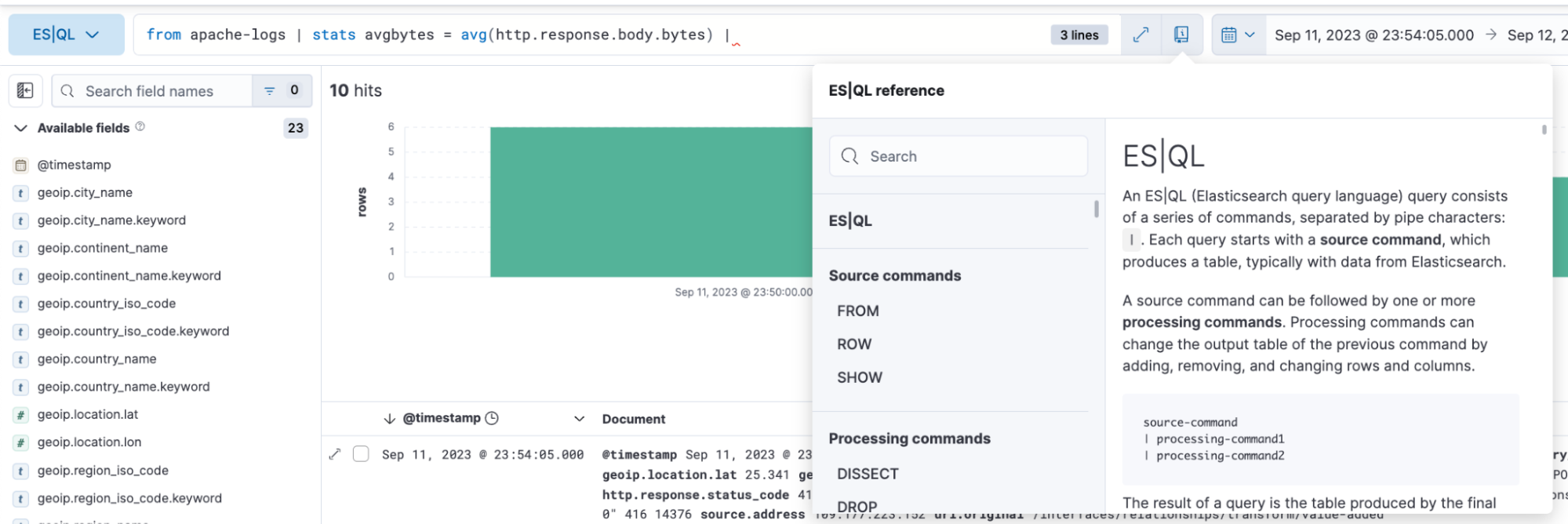
Cómo analizar y visualizar datos con ES|QL
Con ES|QL, puedes hacer una exploración de datos poderosa e integral. Te permite realizar una exploración de datos ad-hoc en Discover, crear agregaciones, transformar datos, enriquecer sets de datos y más directamente desde el generador de búsquedas. Los resultados se presentan en formato tabular o como visualizaciones; depende de la búsqueda que estés ejecutando.
A continuación, encontrarás ejemplos de búsquedas de ES|QL para observabilidad y cómo se representan los resultados tanto en formato tabular y como una representación visual.
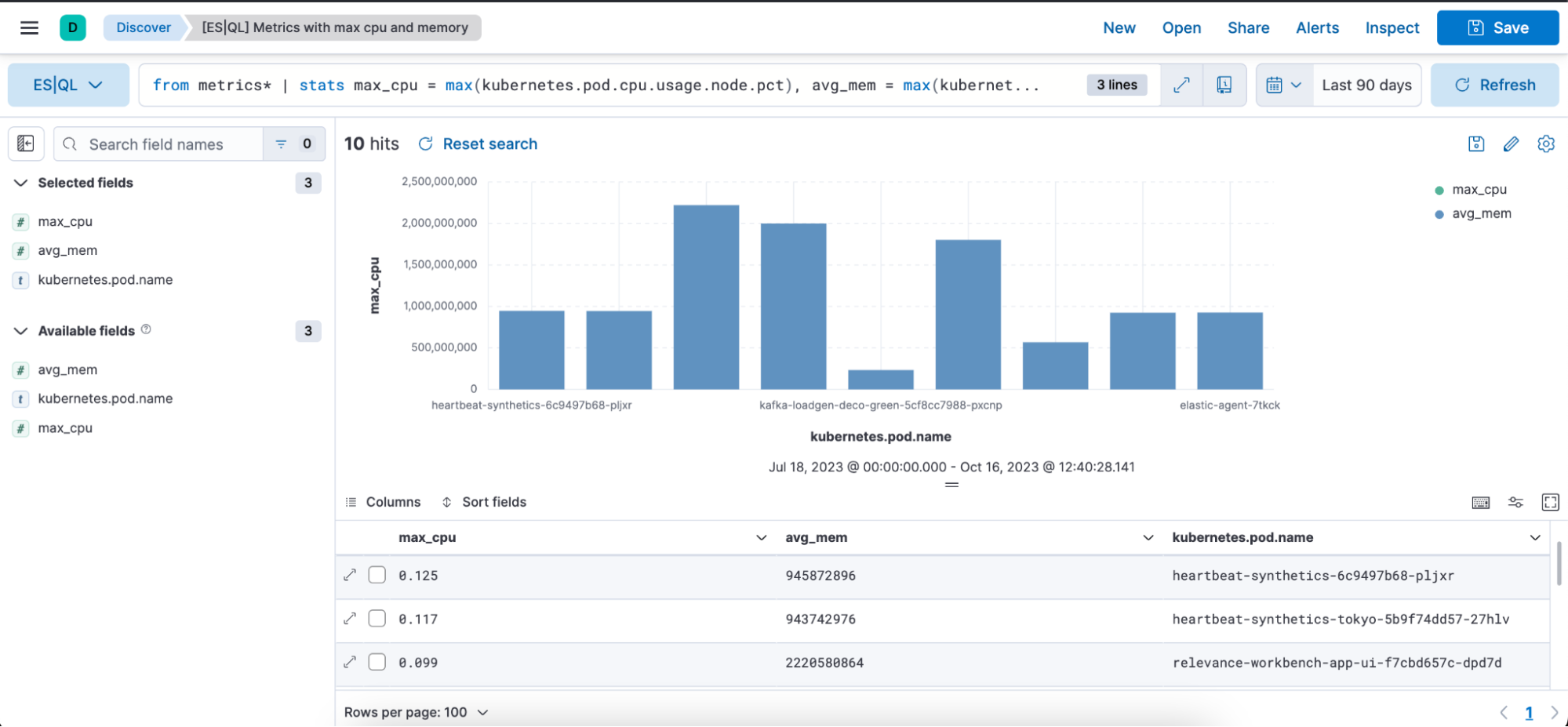
Búsqueda de ES|QL con el caso de uso de métricas:
from metrics*
| stats max_cpu = max(kubernetes.pod.cpu.usage.node.pct), max_mem = max(kubernetes.pod.memory.usage.bytes) by kubernetes.pod.name
| sort max_cpu desc
| limit 10La búsqueda anterior muestra cómo puedes usar el comando de origen siguiente, funciones de agregación y comandos de procesamiento:
Comando de origen from (documentación)
from metrics*: inicia una búsqueda a partir de patrones de índice que coinciden con el patrón "metrics*". El asterisco(*) cumple la función de comodín, lo que significa que seleccionará datos de todos los patrones de índice cuyos nombres comiencen con "metrics".
Agregaciones stats…by (documentación), max (documentación) y by (documentación)
Este segmento agrega datos sobre la base de estadísticas específicas. Se desglosa de la siguiente manera:
max_cpu=max(kubernetes.pd.cpu.usage.node.pct): para cada "kubernetes.pod.name" diferente, encuentra el porcentaje de uso de CPU máximo y almacena ese valor en una columna nueva denominada "max_cpu".
max_mem = max(kubernettes.pod.memory.usage.bytes): para cada "kubernetes.pod.name" diferente, encuentra el uso de memoria máximo en bytes y almacena ese valor en una columna nueva denominada "avg_mem".
Comandos de procesamiento (documentación)
- sort (documentación)
- limit (documentación)
sort max_cpu desc: esto ordena las filas de datos resultantes según la columna "max_cpu" en orden descendente. Esto significa que la fila con el valor "max_cpu" más alto estará en la parte superior.
limit 10: esto limita la salida a las primeras 10 filas luego de la clasificación.
En resumen, la búsqueda:
- Agrupa datos de todos los índices de métricas usando un patrón de índice.
- Agrega los datos para encontrar el porcentaje de uso de CPU máximo y el uso de memoria máximo para cada pod de Kubernetes diferente.
- Ordena los datos agregados según el uso de CPU máximo en orden descendente.
- Genera la salida de solo las primeras 10 filas con el uso de CPU más alto.
Visualizaciones contextuales: Al escribir búsquedas de ES|QL en Discover, recibirás representaciones visuales impulsadas por el motor de sugerencias Lens. La naturaleza de tu búsqueda determina el tipo de visualización que obtienes, ya sea una métrica un mapa de calor de histograma, etc.
A continuación, encontrarás una representación visual en forma de gráfico de barras y una representación de tabla de la búsqueda anterior con las columnas max_cpu, avg_mem y kubernetes.pod.name:
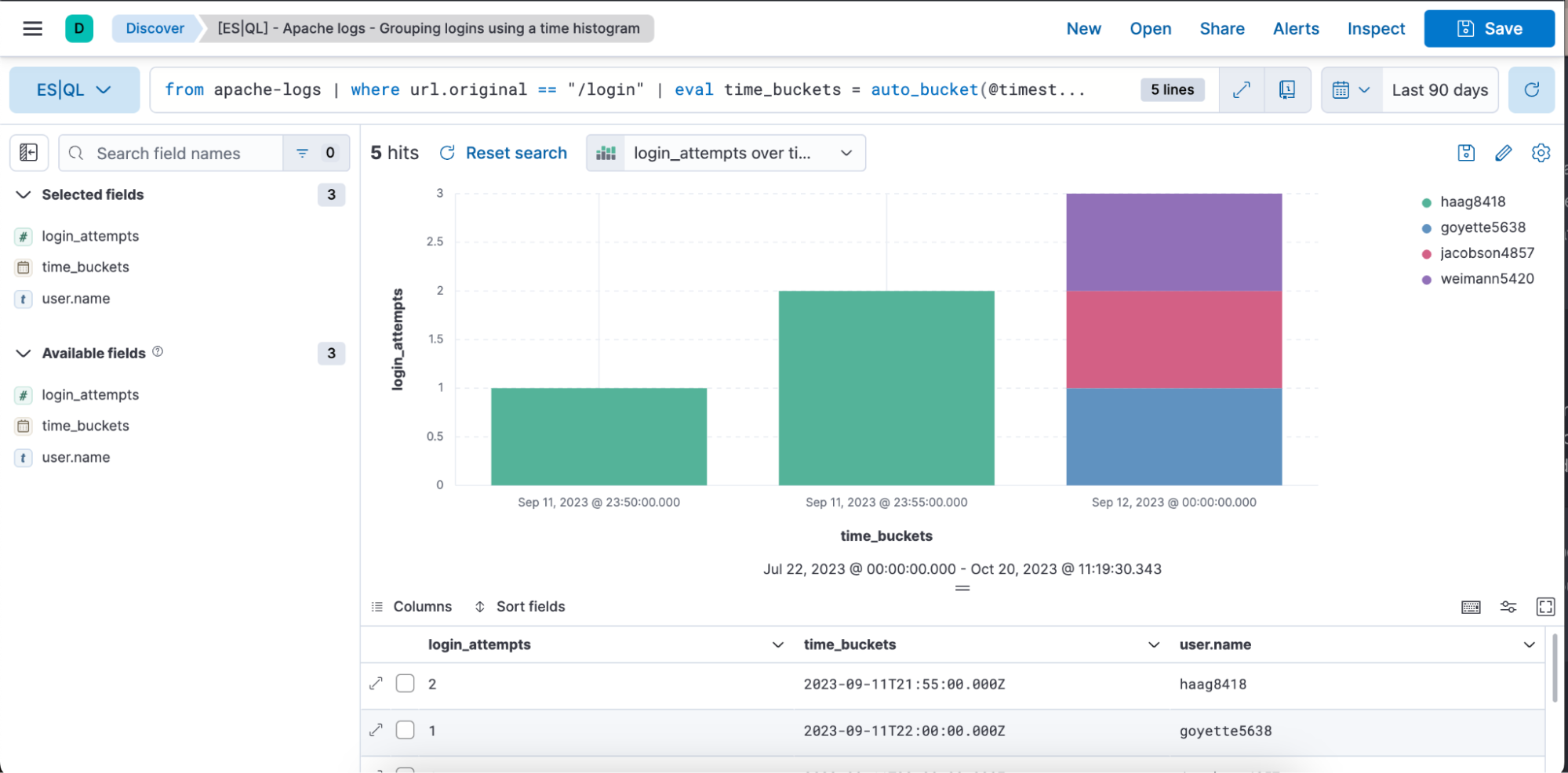
Ejemplo de una búsqueda de ES|QL con el caso de uso de datos de series temporales y Observability:
from apache-logs |
where url.original == "/login" |
eval time_buckets = auto_bucket(@timestamp, 50, "2023-09-11T21:54:05.000Z", "2023-09-12T00:40:35.000Z") |
stats login_attempts = count(user.name) by time_buckets, user.name |
sort login_attempts descLa búsqueda anterior muestra cómo puedes usar el comando de origen siguiente, funciones de agregación, comandos de procesamiento y funciones.
Comando de origen from (documentación)
from apache-logs: inicia una búsqueda desde un índice denominado "apache-logs". Este índice contiene entradas de log relacionadas con el tráfico del servidor web Apache.
where (documentación)
where url.original==”/login”: filtra los registros a solo aquellos en los que el campo "url.original" es igual a "/es/login". Esto significa que solo nos interesan las entradas de logs relacionadas con los intentos de inicio de sesión o accesos a la página de inicio de sesión.
eval (documentación) y auto_bucket (documentación)
eval time_buckets =... : crea una columna nueva denominada "time_buckets".
La función "auto_bucket" crea cubetas fáciles de usar para las personas y devuelve un valor datetime para cada fila que corresponde a la cubeta resultante a la que corresponde la fila.
"@timestamp" es el campo que contiene la marca de tiempo de cada entrada de log.
"50" es la cantidad de cubetas.
"2023-09-11T21:54:05.000Z": hora de inicio de la creación de cubetas
"2023-09-12T00:40:35.000Z": hora de finalización de la creación de cubetas
Esto significa que las entradas de log entre "2023-09-11T21:54:05.000Z" y "2023-09-12T00:40:35.000Z" se dividirán en 50 intervalos regulares y que cada entrada estará asociada a un intervalo específico según su marca de tiempo.
El objetivo no es proporcionar exactamente la cantidad de cubetas objetivo, es elegir un rango con el que te sientas cómodo que proporcione, como máximo, la cantidad de cubetas objetivo. Si solicitas más cubetas, entoncesauto_bucket puede elegir un rango más pequeño.
Agregaciones stats…by (documentación), count (documentación) y by (documentación)
stats login_attempts = count(user.name) by time_buckets, user.name: agrega los datos para calcular la cantidad de intentos de inicio de sesión. Lo hace contando las instancias de "user.name" (representa usuarios únicos que intentan iniciar sesión).
El conteo está agrupado por "time_buckets" (los intervalos de tiempo que creamos) y "user.name". Esto significa que por cada cubeta de tiempo, veremos cuántas veces intentó cada usuario iniciar sesión.
sort (documentación)
Sort login_attempts desc: Por último, los resultados agregados se ordenan según la columna "login_attempts" en orden descendente. Esto significa que el resultado mostrará la mayor cantidad de intentos de inicio de sesión en la parte superior.
En resumen, la búsqueda:
- Selecciona datos del índice "apache-logs".
- Filtra entradas de logs relacionadas con la página de inicio de sesión.
- Agrupa en cubetas estas entradas en intervalos de tiempo específicos.
- Hace un conteo de la cantidad de intentos de inicio de sesión de cada usuario en cada uno de estos intervalos de tiempo.
- Genera la salida de resultados ordenados por la mayor cantidad de intentos de inicio de sesión en primer lugar.
A continuación, encontrarás una representación visual en forma de gráfico de barras y una representación de tabla de la búsqueda anterior con las columnas login_attempts, time_buckets y user.name.
Edición de visualización en línea en Discover y Dashboard
Edita las visualizaciones de ES|QL directamente en Discover y Dashboards. No hace falta navegar a Lens para hacer ediciones rápidas; puedes hacer cambios sin inconvenientes.
A continuación, puedes ver un video de un flujo de trabajo integral o leer la guía paso a paso:
Escribir una búsqueda de ES|QL
Obtener visualización contextual basada en la naturaleza de la búsqueda
Editar en línea la visualización
Guardarla en un Dashboard
Poder editar la visualización desde un Dashboard
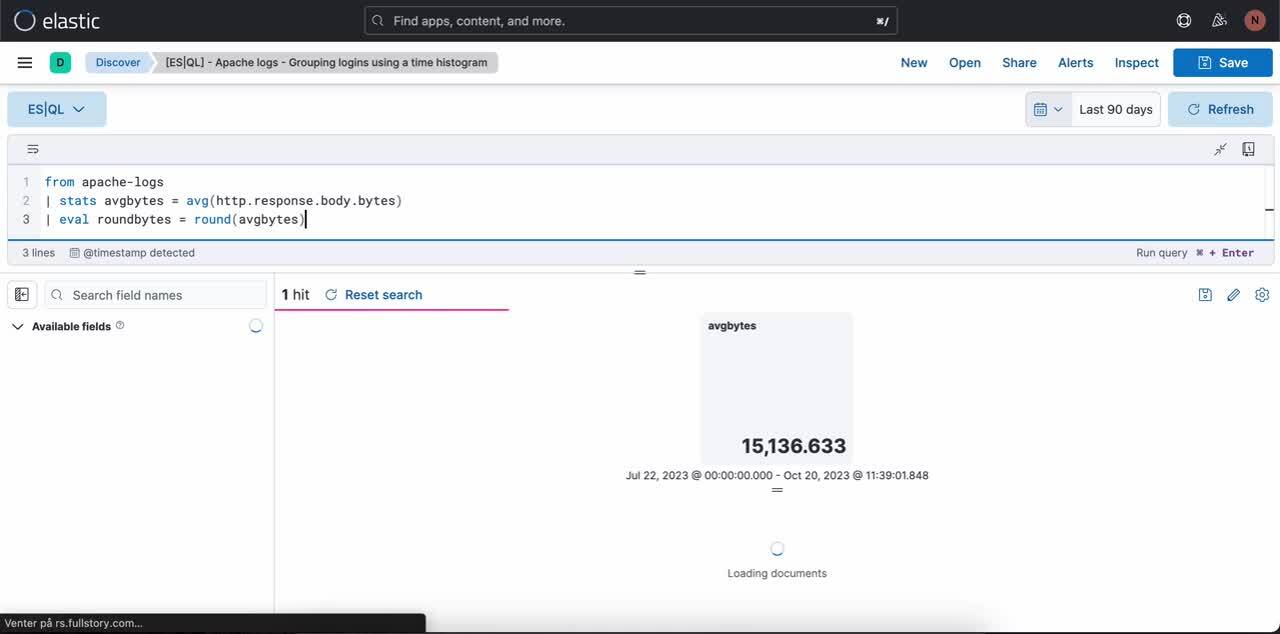
Paso 1. Escribir una búsqueda ES|QL. Ejemplo de búsqueda que genera una visualización de métricas:
from apache-logs
| stats avgbytes = avg(http.response.body.bytes)
| eval roundbytes = round(avgbytes)
| drop avgbytesPaso 2. Obtener visualización contextual (en este caso, una visualización de métricas) basada en la naturaleza de la búsqueda. Luego puedes seleccionar el ícono de lápiz para entrar en modo de edición en línea.
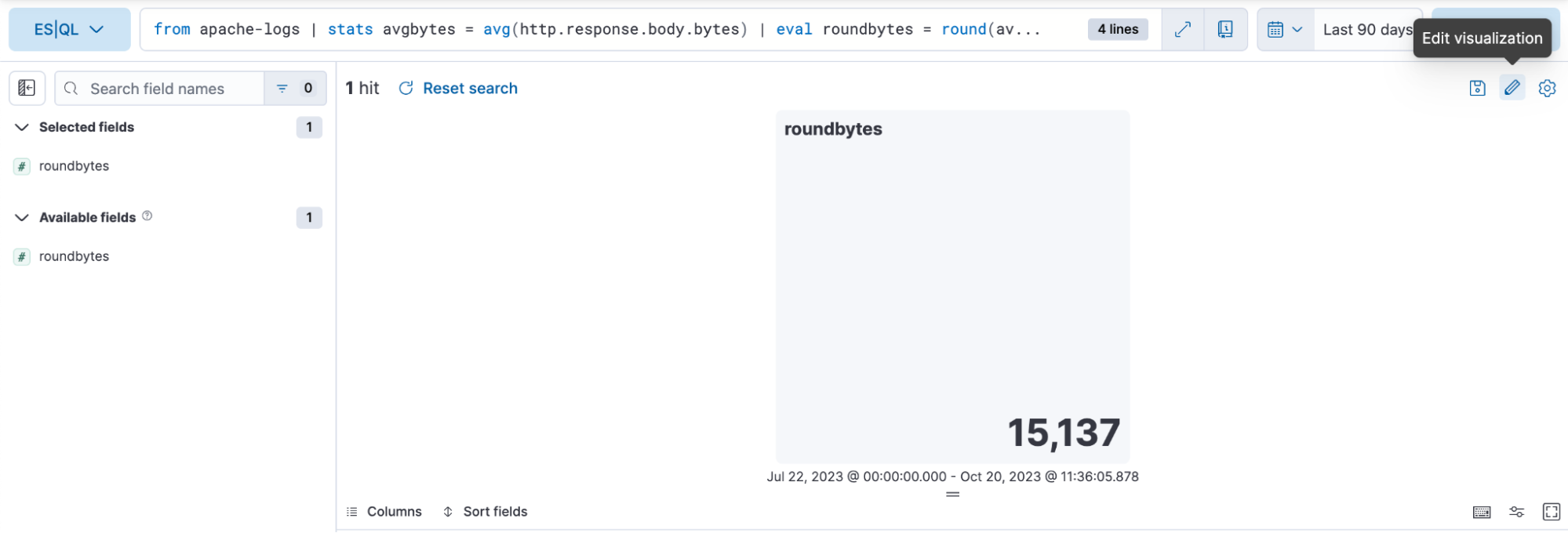
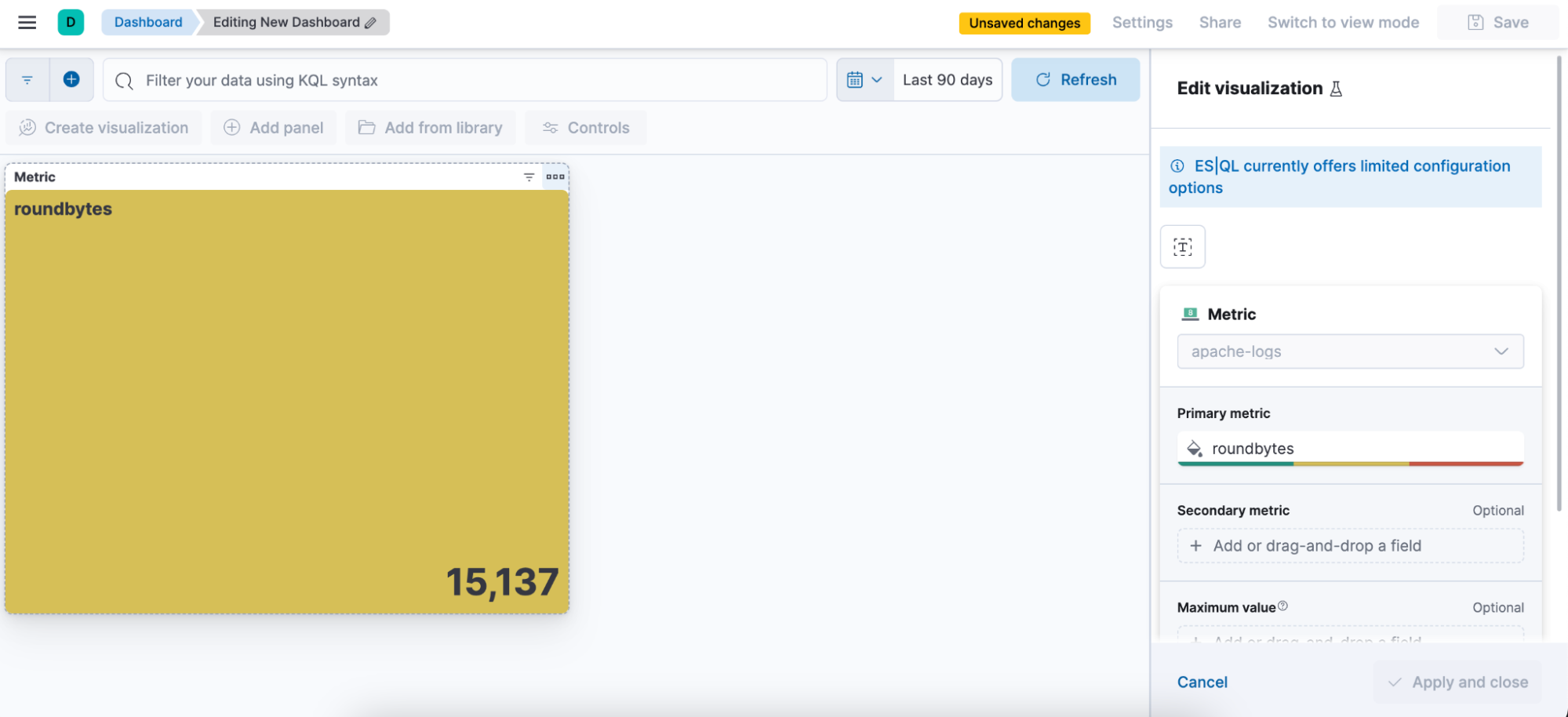
Paso 3. Editar la visualización usando el modo de edición en línea
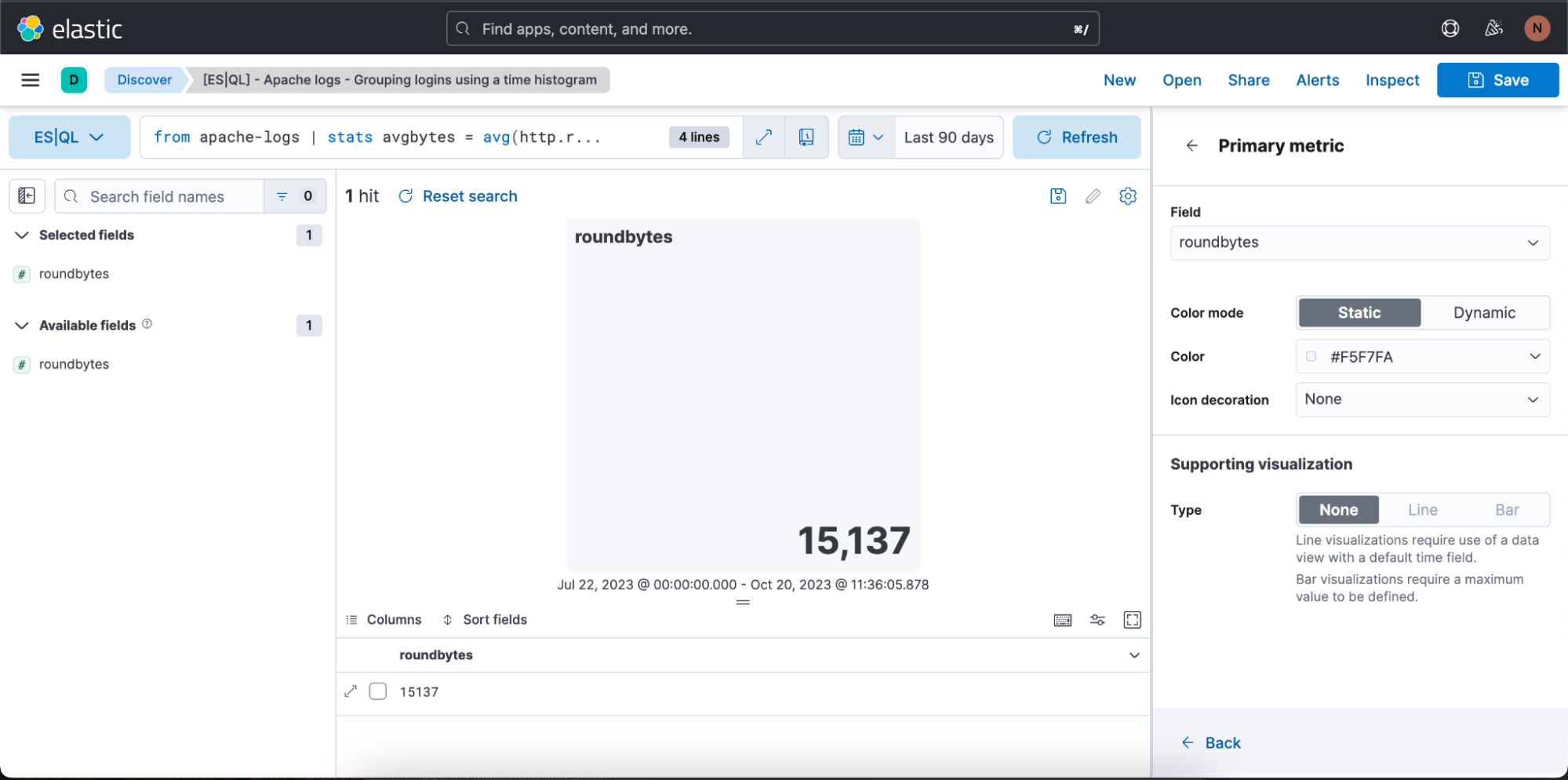
En el caso anterior, queremos que la visualización esté en modo de color dinámico, por lo que cambiamos a "Dynamic" (Dinámico).
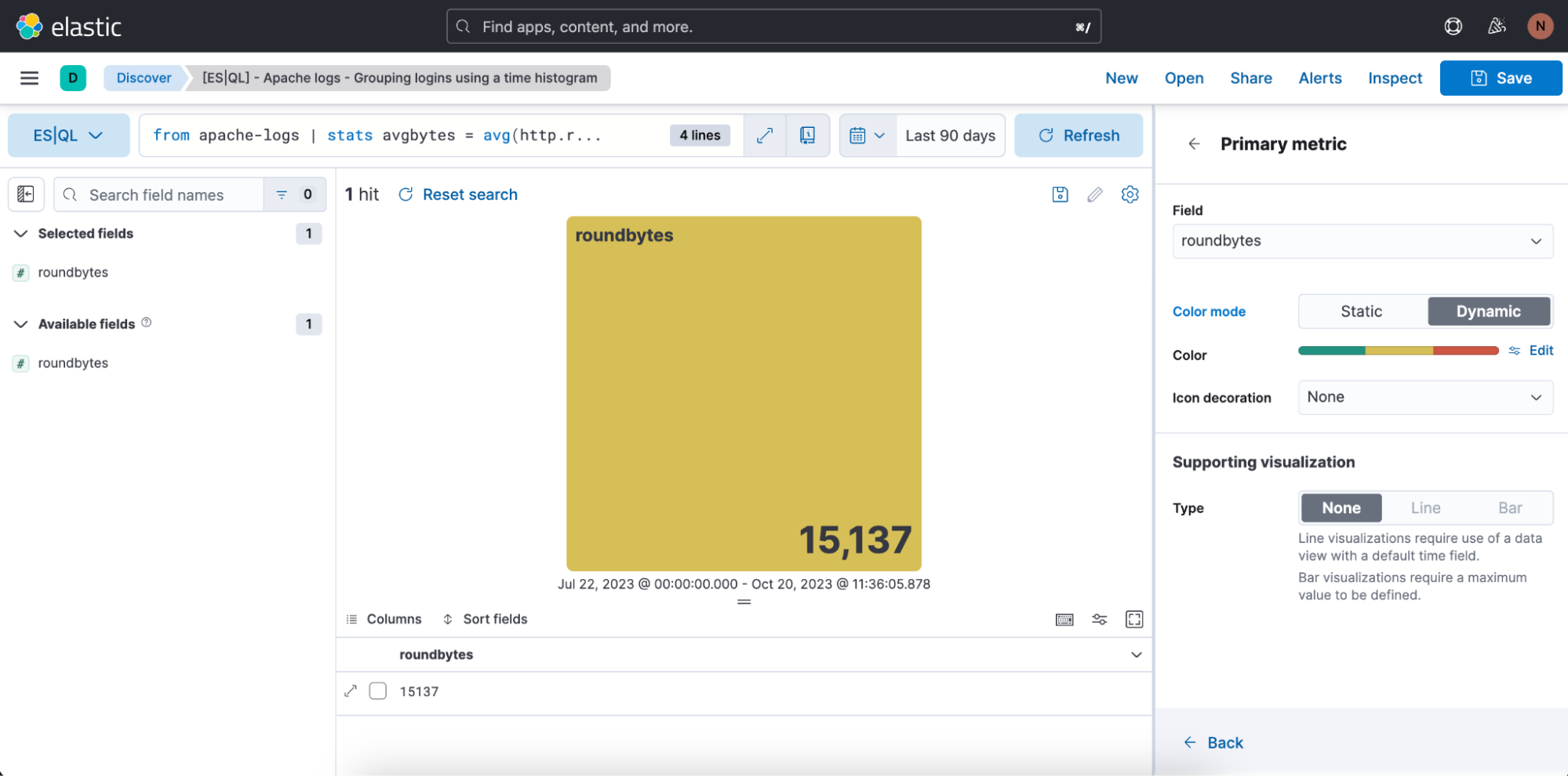
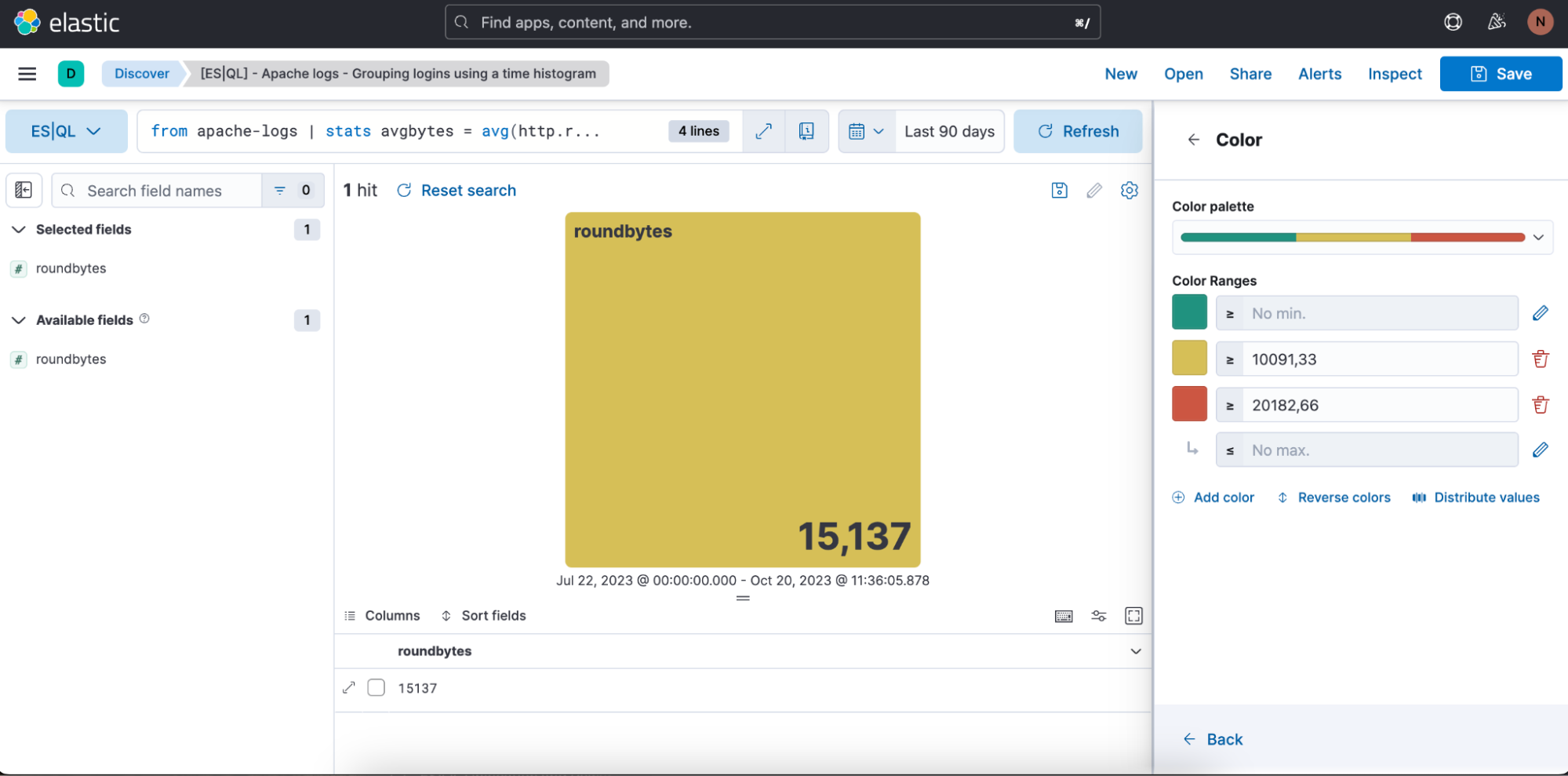
También tenemos la oportunidad de definir los rangos de color que deseamos usar:
Paso 4. Guardar en un Dashboard
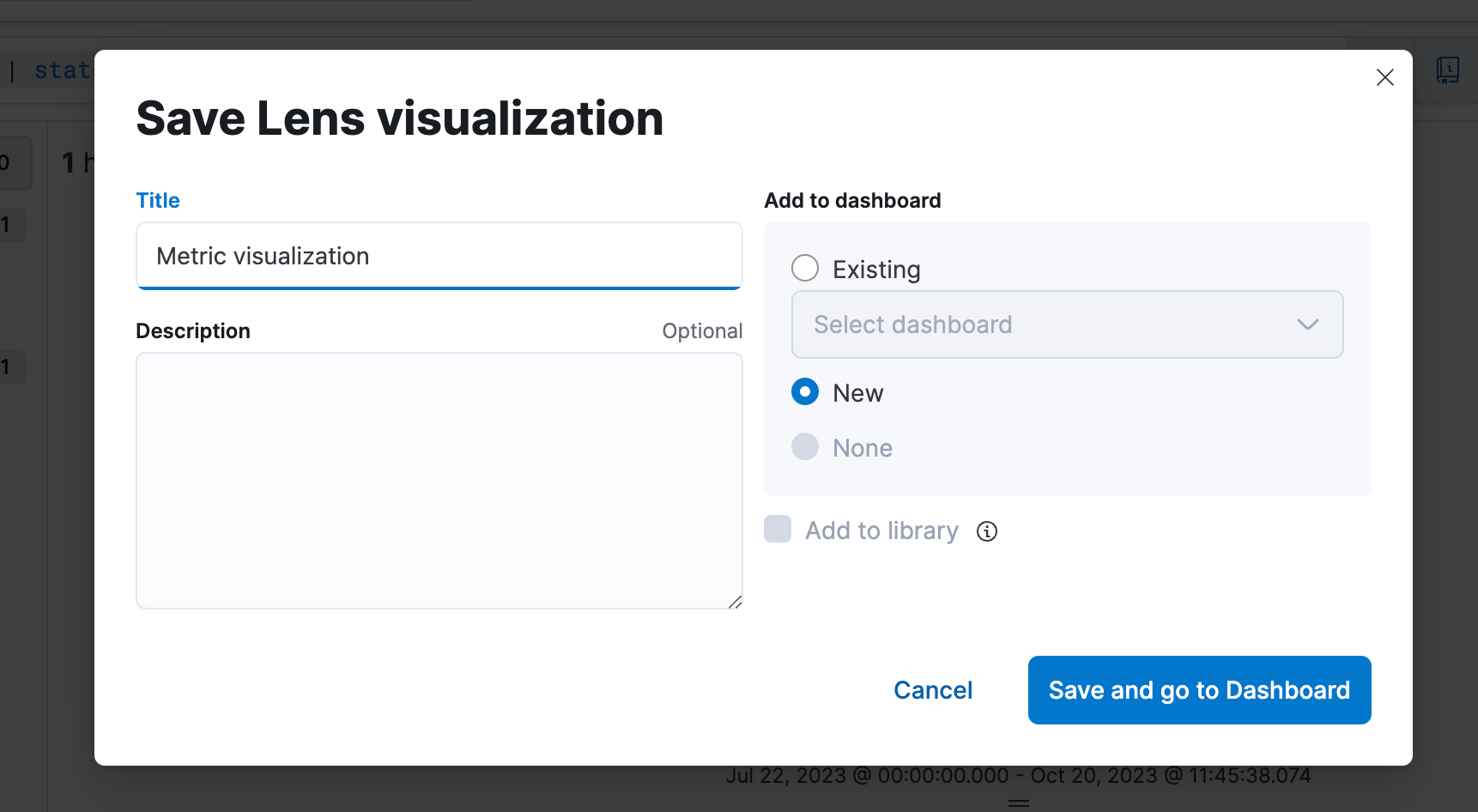
Paso 5. Poder editar la visualización desde un Dashboard
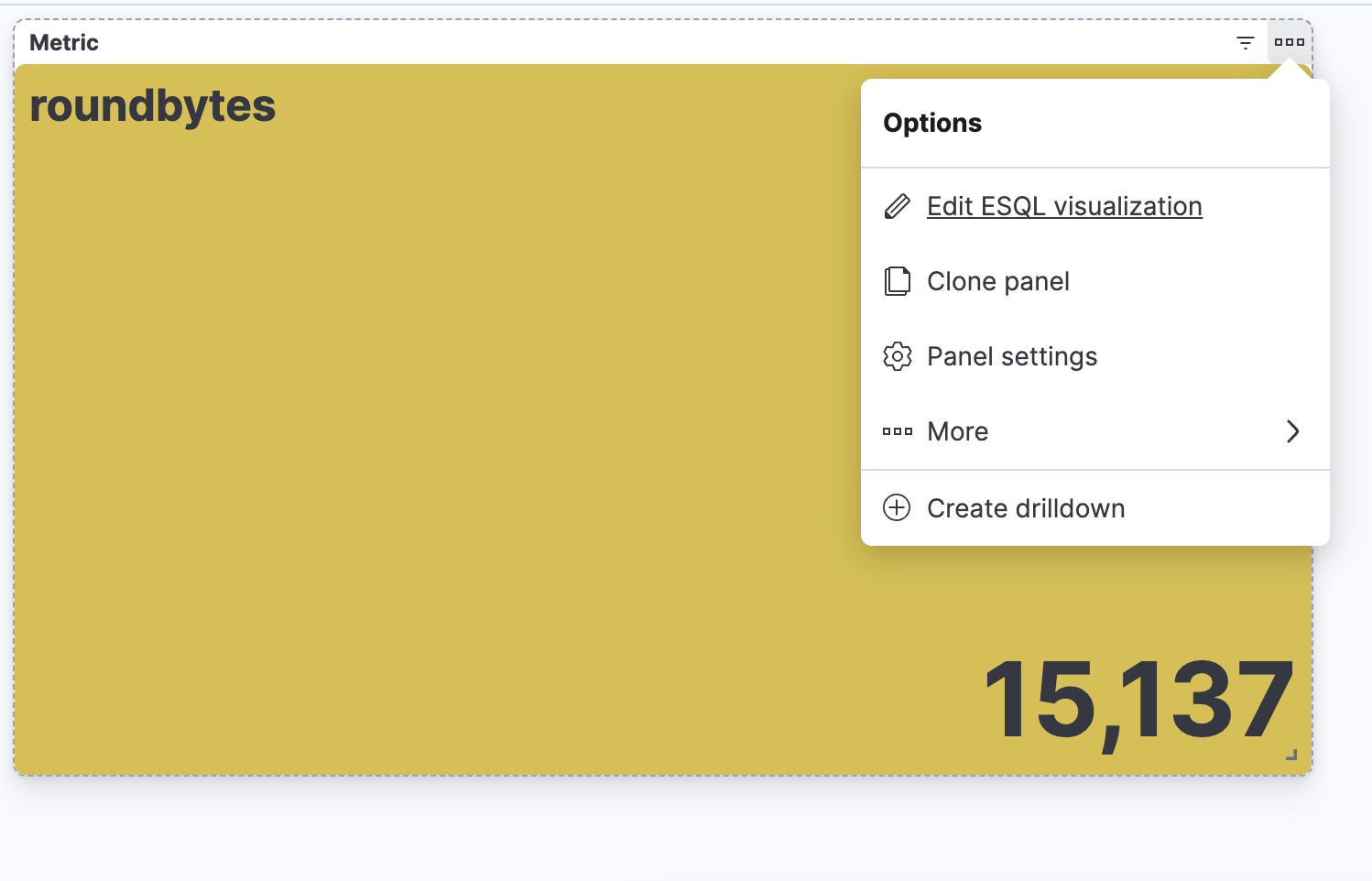
Crear una alerta de ES|QL directamente desde Discover
Puedes usar ES|QL para alertas de seguridad y observabilidad, configurando valores agregados como umbrales. Mejora la precisión de detección y recibe notificaciones procesables enfatizando tendencias significativas por sobre incidentes aislados a fin de reducir los falsos positivos.
A continuación, nos enfocaremos en cómo crear un tipo de regla de alerta de ES|QL desde Discover.
El nuevo tipo de regla de alerta está disponible dentro del tipo de regla de Elasticsearch existente. Este tipo de regla trae todas las funcionalidades nuevas disponibles en ES|QL y desbloquea nuevos casos de uso de alertas.
Con el nuevo tipo, los usuarios podrán generar una sola alerta basada en una búsqueda de ES|QL definida y previsualizar el resultado de la búsqueda antes de guardar la regla. Cuando la búsqueda devuelva un resultado vacío, no se generarán alertas.
Ejemplo de búsqueda para una alerta:
from metrics-pods |
stats max_cpu = max(kubernetes.pod.cpu.usage.node.pct) by kubernetes.pod.name|
sort max_cpu desc | limit 10
Cómo crear una alerta desde Discover
Paso 1. Haz clic en "Alerts" (Alertas) y luego en "Create search threshold rule" (Crear regla de umbral de búsqueda). Puedes comenzar a crear tu tipo de regla de alerta de ES|QL ya sea después de haber definido tu búsqueda de ES|QL en la barra de búsquedas o antes de haber definido tu búsqueda de ES|QL. El beneficio de hacerlo después de haberla definido es que la búsqueda se pega automáticamente en el elemento flotante "Create Alert" (Crear alerta).
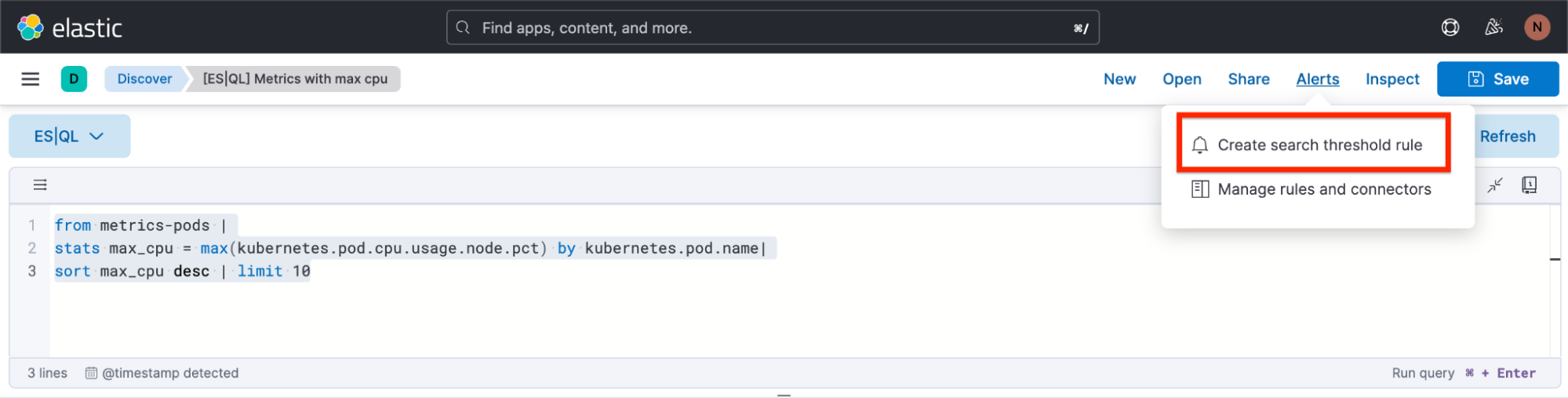
Paso 2. Comienza a definir tu tipo de regla de alerta de ES|QL.
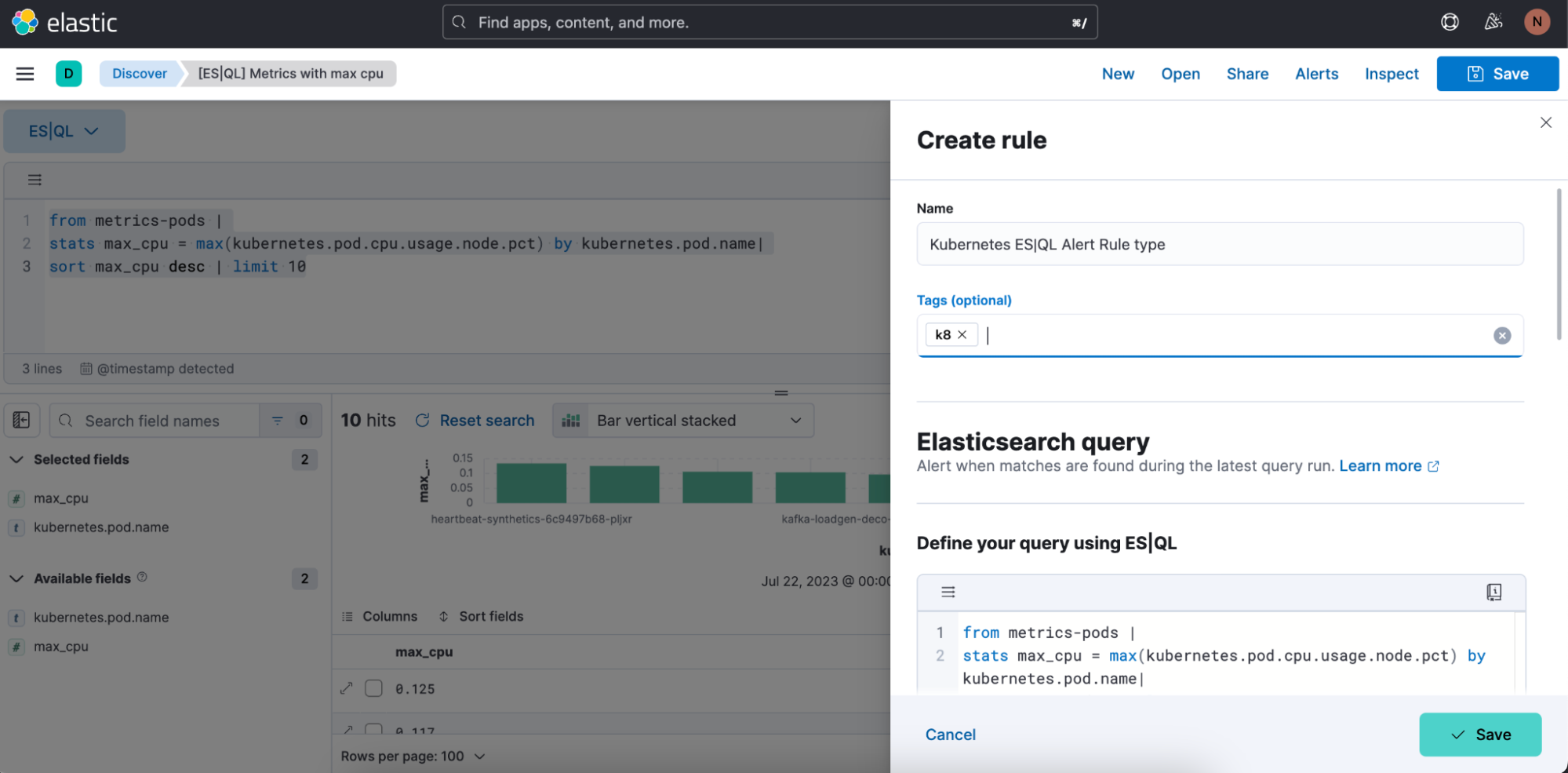
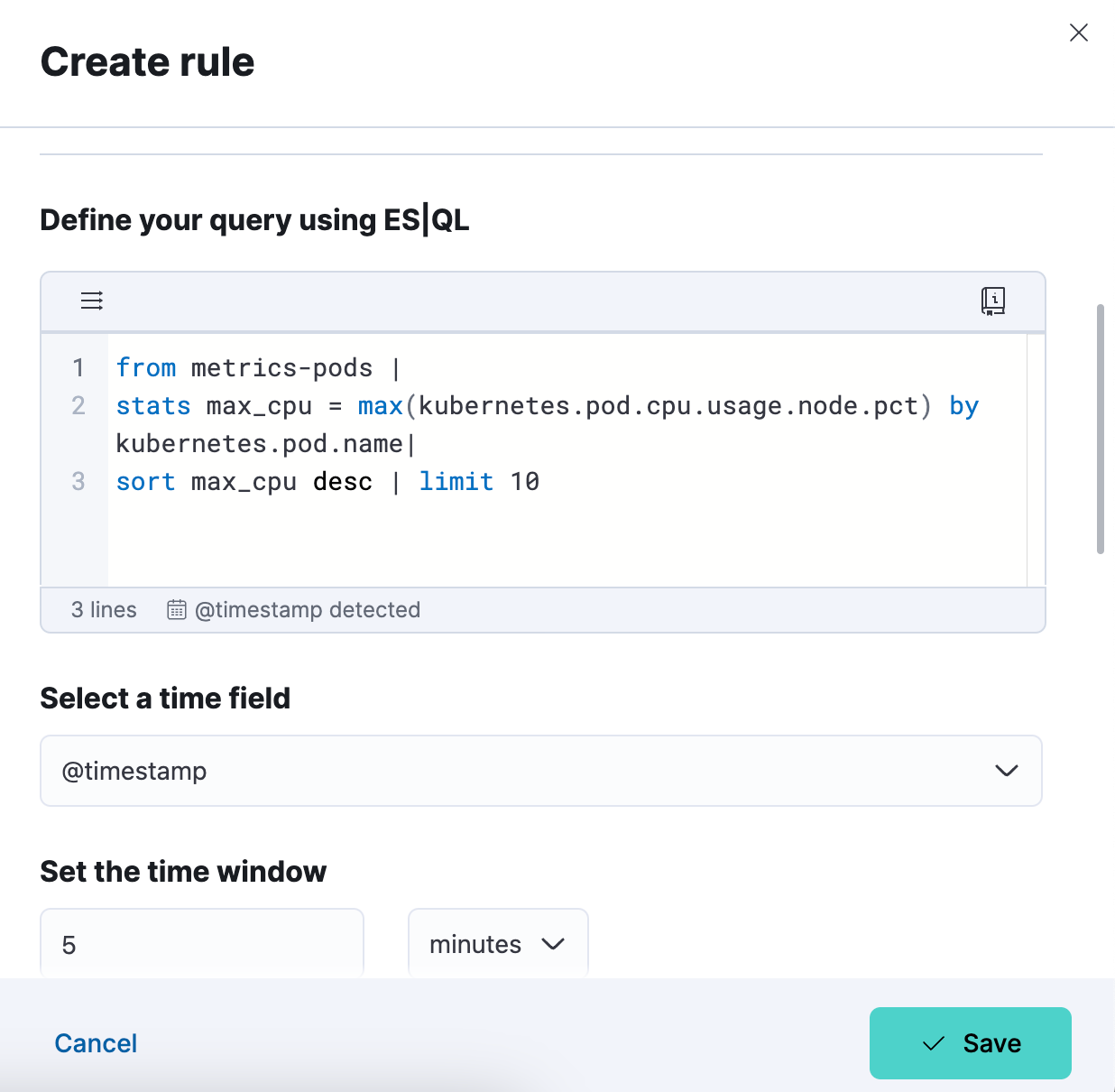
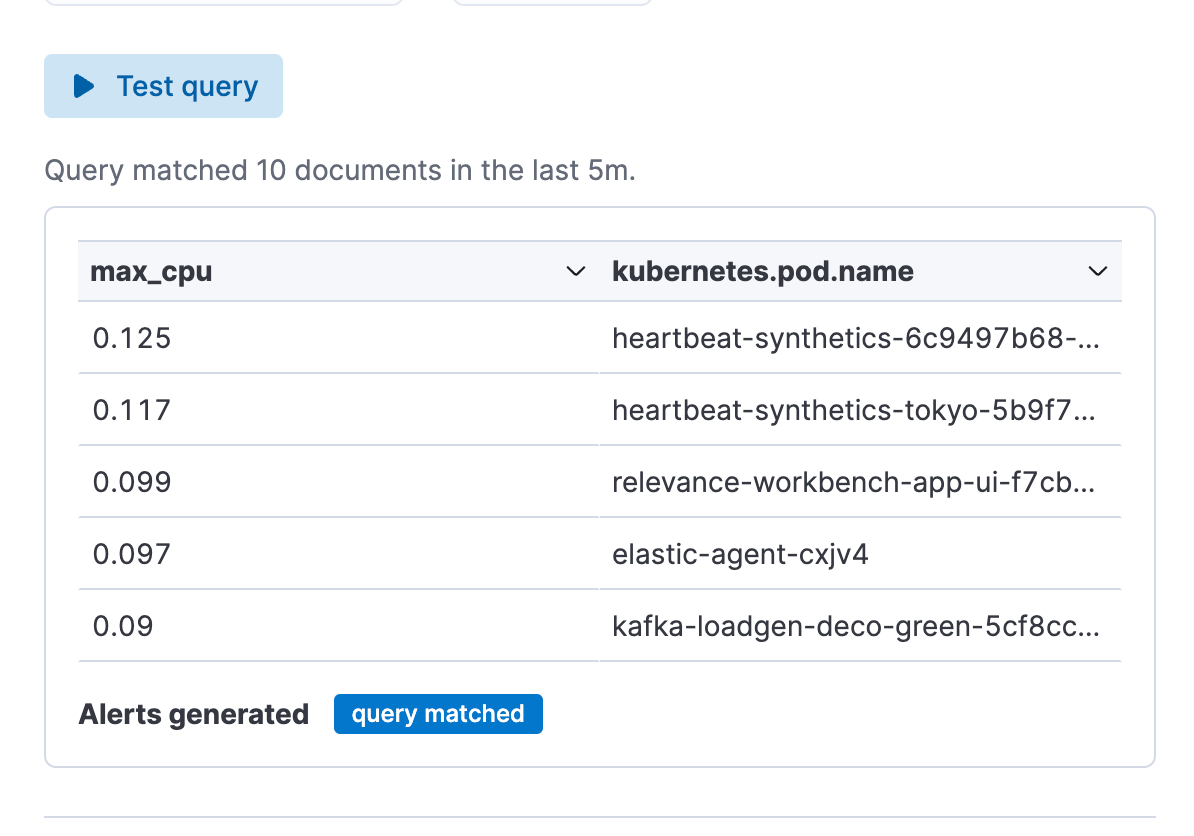
Paso 3. Prueba tu búsqueda de tipo de regla de alerta. Puedes iterar en la búsqueda de ES|QL pegada y probarla haciendo clic en "Test query" (Probar búsqueda). Esto te dará una vista previa de los resultados en una tabla.
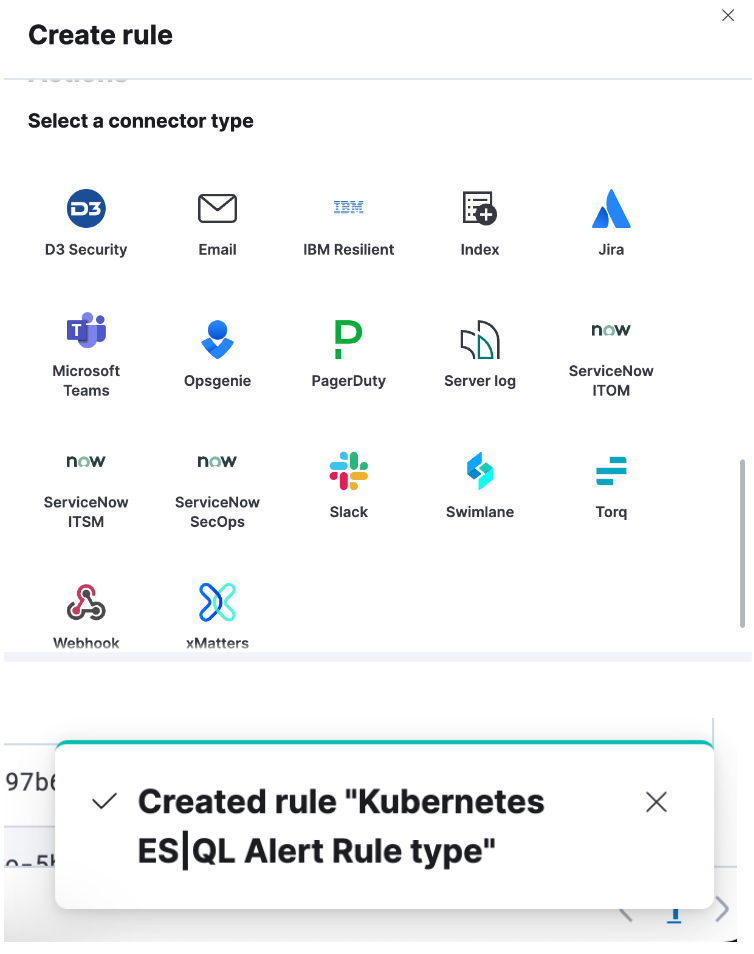
Paso 4. Configura tu conecto y haz clic en "Save" (Guardar). Creaste correctamente un tipo de regla de alerta de ES|QL.
Enriquecer el set de datos de búsqueda con campos de otro set de datos
Puedes usar el comando de enriquecimiento (documentación) para mejorar tu set de datos de búsqueda con campos de otro set de datos, completo con sugerencias en contexto para la política seleccionada (es decir, que hacen referencia al campo coincidente y columnas enriquecidas).
Ejemplo de búsqueda que usa ENRICH, en la que se usa una política de enriquecimiento "servers-to-project" a través de la búsqueda para enriquecer el set de datos con nombre, server_hostname, y costo:
from projects* | limit 10 |
enrich servers-to-project on project_id with name, server_hostname, cost |
stats num_of_servers = count(server_hostname), total_cost = sum(cost) by project_id |
sort total_cost desc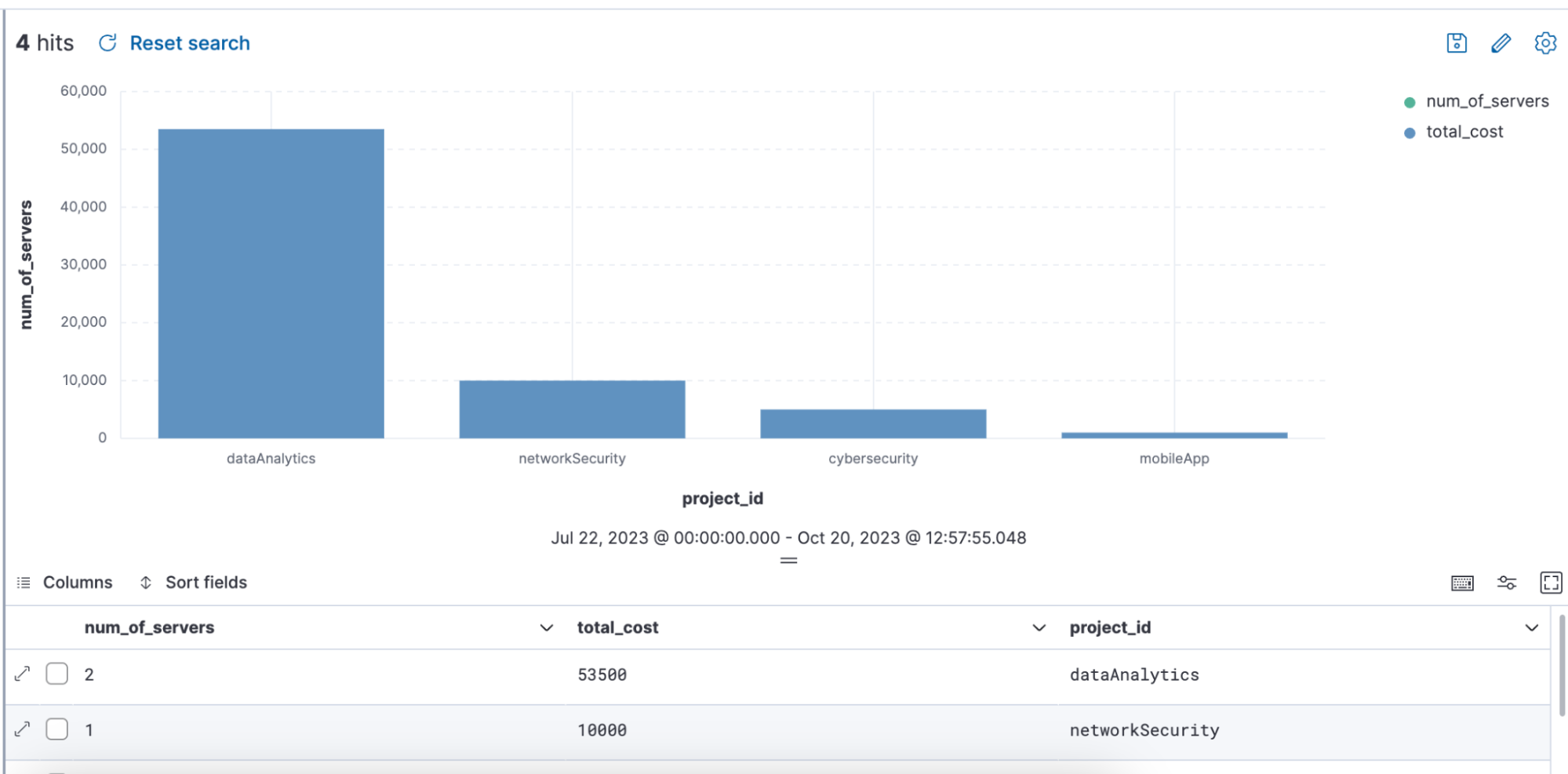
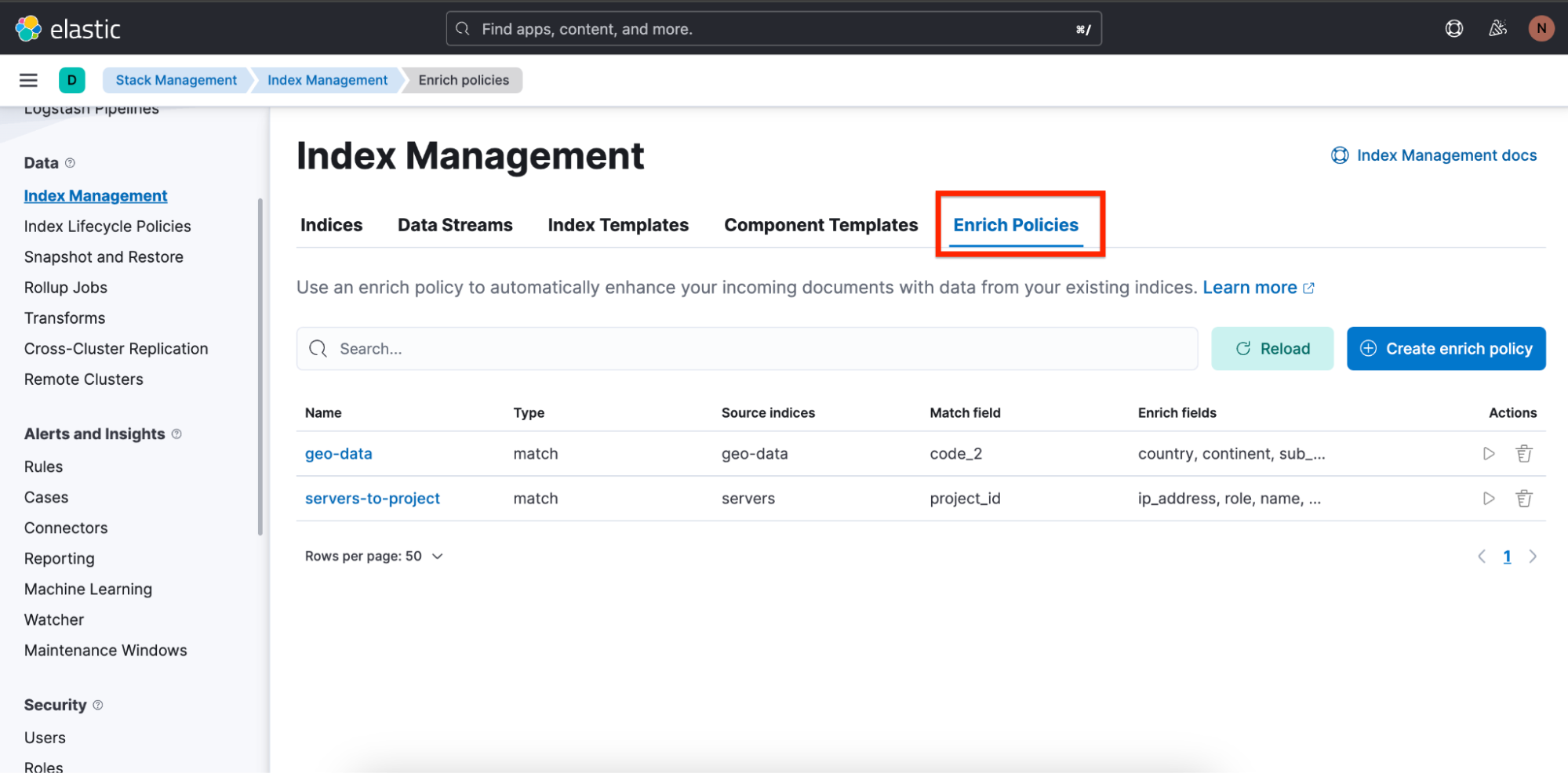
También facilitamos a los usuarios la creación de políticas de enriquecimiento agregando una visión general y un asistente para crear políticas de enriquecimiento.
Para encontrar una visión general de políticas de enriquecimiento, navega a Stack Management (Gestión del stack) ⇒ Index Management (Gestión de índices) y allí verás una pestaña llamada Enrich Policies (Políticas de enriquecimiento):
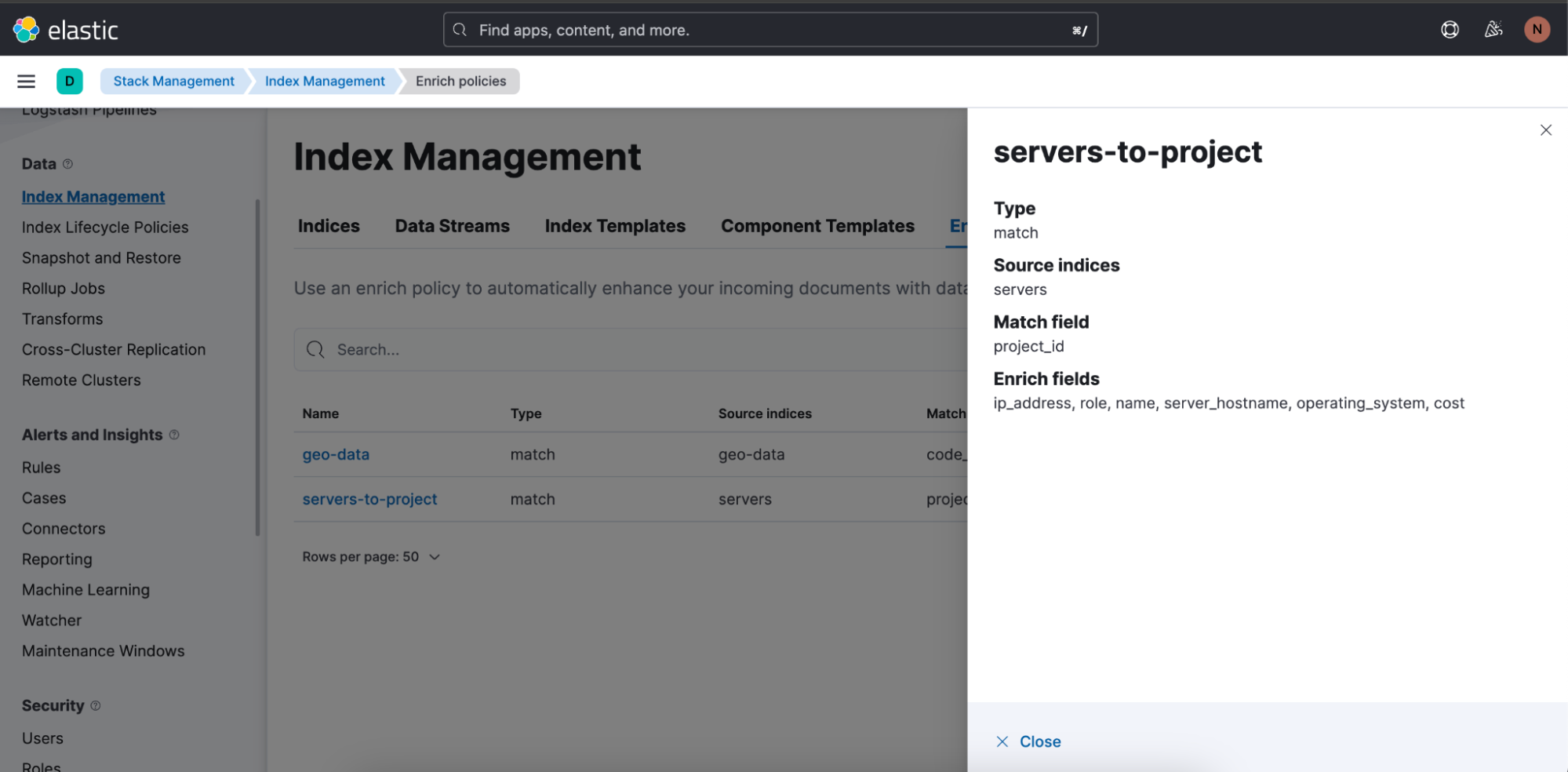
Esta es la política de enriquecimiento usada en la búsqueda anterior: "servers-to-project":
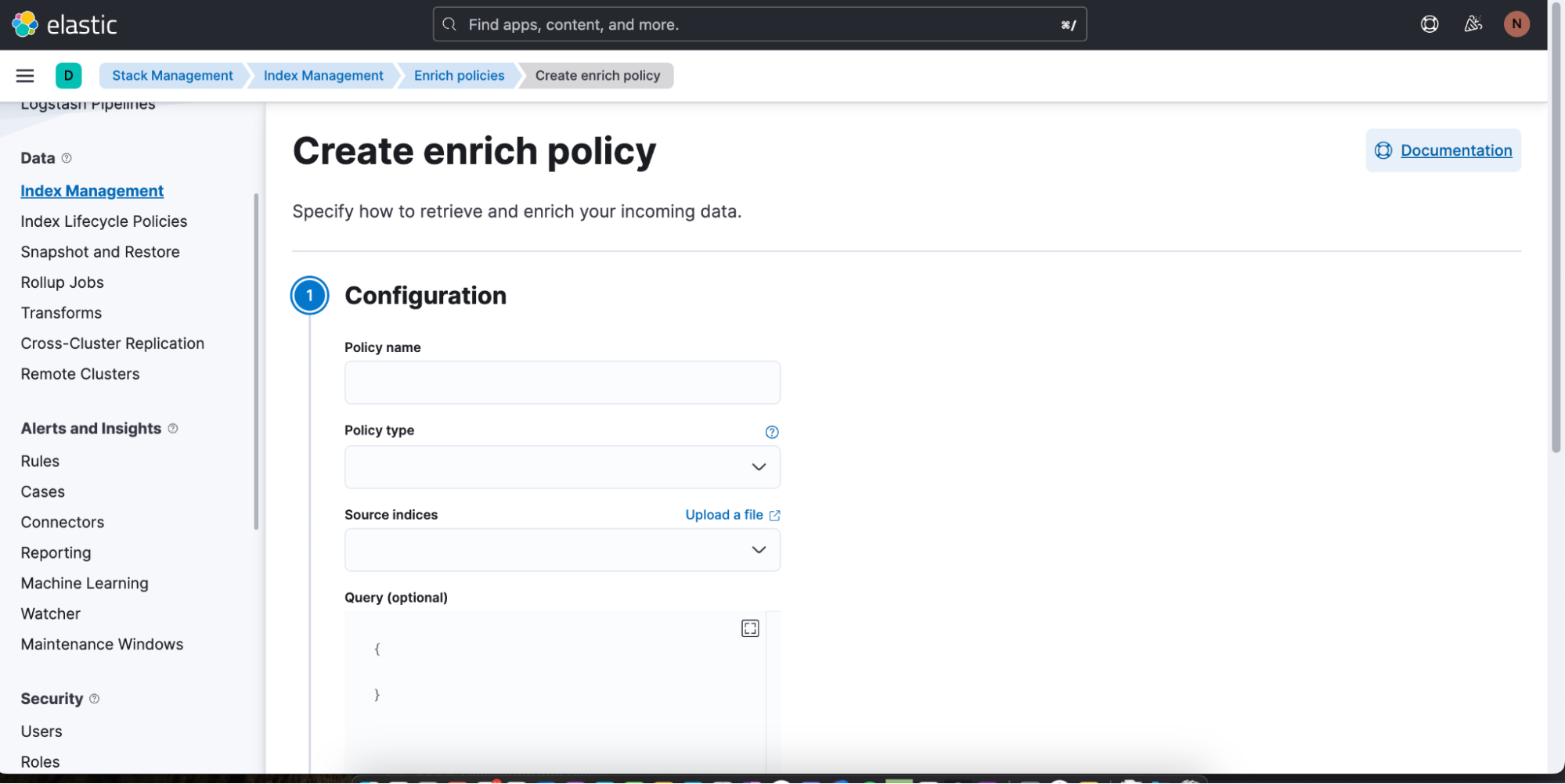
Puedes comenzar a crear con facilidad una nueva política de enriquecimiento haciendo clic en Create enrich policy (Crear política de enriquecimiento). Tan pronto hayas creado y ejecutado una, luego se puede usar en una búsqueda de ES|QL en Discover.
Obtén más información sobre las políticas de enriquecimiento aquí y sobre el comando ENRICH en ES|QL aquí.
Elevar la exploración de datos: El poder y la promesa de ES|QL
ES|QL es la innovación más reciente de Elastic para potenciar el análisis y la exploración de datos. No se trata solo de mostrar los datos; se trata de hacer que sean comprensibles, procesables y visualmente atractivos. Impulsados por un motor de búsqueda rápido, distribuido y dedicado, diseñado como un nuevo lenguaje con barras verticales e incluido en una experiencia de exploración de datos unificada, ES|QL afronta los desafíos de los usuarios, como ingenieros de confiabilidad del sitio, DevOps, buscadores de amenazas y otros tipos de analistas.
ES|QL empodera a los SRE para acabar con las ineficiencias del sistema de forma efectiva, ayuda a DevOps a asegurar despliegues de calidad y brinda a los buscadores de amenazas las herramientas para distinguir con rapidez potenciales amenazas de seguridad. Su integración directa en Dashboards, edición de visualización en línea, funcionales de alerta y habilidades, como comandos de enriquecimiento, brindan un flujo de trabajo eficiente y sin inconvenientes. La interfaz de ES|QL combina tanto la potencia como la facilidad de uso para los usuarios, lo que les permite profundizar en sus datos y hacer que el análisis sea más simple y revelador. El lanzamiento de ES|QL es solo una continuación del recorrido de Elastic para mejorar las experiencias de exploración de los datos y abordar las necesidades en evolución de nuestra comunidad de usuarios.
Puedes probar todas las capacidades de ES|QL hoy mismo. Para hacerlo, regístrate para una cuenta de prueba de Elastic o pruébalo en nuestro entorno de demostración público.
El lanzamiento y el plazo de cualquier característica o funcionalidad descrita en este blog quedan a la entera discreción de Elastic. Cualquier característica o funcionalidad que no esté disponible actualmente puede no entregarse a tiempo o no entregarse en absoluto.
Comparte
- Share on Twitter
Comparte en Twitter
- Share on LinkedIn
Comparte en LinkedIn
- Share on Facebook
Comparte en Facebook
- Share by Email
Comparte por correo electrónico
- Print this page
Imprime