Logging de Operaciones en Lyft: Migrando de Splunk Cloud a Amazon ES a Elasticsearch on-prem
¿Buscas una alternativa a Splunk? Conoce más sobre cómo migrar a Elastic desde Splunk puede ayudarte a unificar los datos de observabilidad y seguridad en una única plataforma mientras disminuyes los costos generales y la sobrecarga administrativa.
Esta publicación es una recapitulación de una conversación para usuarios presentada en Elastic{ON} 2018. ¿Te interesa ver más conversaciones como esta? Revisa el archivo de conferencia o descubre cuándo llegará la gira de Elastic{ON} a una ciudad cercana a la tuya.
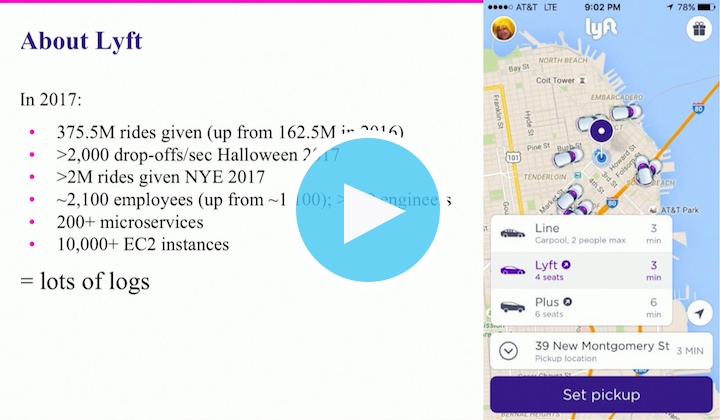
Lyft necesita una infraestructura tecnológica potente para manejar cientos de millones de viajes en todo el mundo cada año (más de 375 millones solo en el 2017) y para asegurarse de que todos sus clientes lleguen a donde necesitan ir. Esto quiere decir que, en 2017, hubo más de 200 microservicios a lo largo de más de 10 000 instancias de EC2; una cantidad que aumentaría en los momentos de incrementos estacionales, como víspera de Año Nuevo, (más de 2 millones de viajes en un día) y Halloween (más de 2000 viajes por minuto en el punto máximo). Para que todos esos sistemas y viajes sigan funcionando, es importante que los ingenieros de Lyft tengan acceso a todos los logs de operaciones. Para Michael Goldsby y su equipo de Observabilidad, esto quiere decir que deben mantener el flujo del servicio de pipeline de los logs.
En las primeras épocas de análisis de logging de Lyft, usaban Splunk Cloud como su proveedor de servicios. Pero los límites de retención de su contrato, los backup de ingesta de hasta 30 minutos durante los períodos de mucha actividad y los costos asociados con el escalado hicieron que Lyft decidiera cambiar a Elasticsearch.
A finales de 2016, un equipo de dos ingenieros pudo hacer la transición de Splunk a Amazon Elasticsearch Service en AWS en alrededor de un mes. Empezar a usar Elasticsearch fue genial, pero había algunas partes de la oferta de AWS que no eran perfectas. Para empezar, el equipo de Goldsby quería acceder a la versión de Elasticsearch 5.x, pero AWS solo ofrecía la versión 2.3 en ese momento. Además, las instancias nuevas estaban limitadas a Amazon EBS para almacenamiento, que tenía un rendimiento y una confiabilidad por debajo de lo óptimo en la escala de Lyft. Y no todas las API de Elasticsearch estaban expuestas en AWS. Pero estas limitaciones no eran suficientes como para sobrepasar los beneficios de la transición desde Splunk Cloud.
Sin los límites de ingesta (o, al menos, con un aumento radical), el equipo de Observabilidad decidió abrir las compuertas y adoptar una nueva filosofía: “envíanos todos tus logs”. Esto subió las tasas de ingesta rápidamente de 100 mil eventos por minuto a 1.5 millones por minuto. Con este nuevo enfoque, las cosas se desarrollaron muy bien durante unos cuatro meses. Cuando el equipo de Goldsby experimentó tiempos de espera de ingesta altos, merma de la retención o dashboards de Kibana lentos, lo único que tuvieron que hacer fue escalar verticalmente. Y cuando alcanzaron el límite de 20 nodos de AWS, se les dio una excepción especial que les permitió aumentar a 40 nodos.
Pero incluso con 40 nodos, había problemas. Problemas de clusters en rojo.
Los clusters en rojo eran un problema que el equipo de Goldsby sabía cómo solucionar (reiniciar, reemplazar los nodos, etc.). El verdadero problema era que no tenían acceso directo a sus clusters. En su lugar, tenían que presentar un ticket a Amazon, y a veces esperar por horas durante los momentos máximos del negocio para recibir soporte. Luego, el ticket necesitaría escalarse, ya que la primera línea de soporte no podía acceder a los clusters. Con el tiempo, Lyft descubrió que para acelerar el proceso de escalamiento podía dirigirse directamente a su administrador técnico de cuenta (TAM), quien se encargaría de volver a cambiar los clusters a verde.
Entre las inevitables intervenciones de soporte, el límite de la versión 2.3, el requisito de EBS y otras limitaciones impuestas por AWS (balanceo de cargas round-robin, tiempos de espera de 60 segundos, ofuscación de API, etc.), el equipo de Observabilidad decidió volver a cambiar; esta vez a un despliegue de Elasticsearch autoadministrado on-prem. “[En AWS] no obtienes todas las características. No puedes tocar todos los botones”, dijo Goldsby. “Sentíamos que teníamos suficiente experiencia operativa interna con Elasticsearch... [como] para hacerlo”.
Con un equipo apenas mayor que el que usaron para la migración de Splunk, Lyft pudo migrar de Amazon Elasticsearch Service a Elasticsearch autoadministrado en solo dos semanas. Ahora tienen su propio despliegue, así como todas las características que habían establecido anteriormente en AWS. Esto también significa que están a cargo de todos los aspectos operativos de Elastic Stack, incluido mantener los clusters en verde y a sus usuarios (compañeros de trabajo) felices.
Descubre cómo Lyft implementó su despliegue de Elasticsearch autoadministrado viendo la conversación La aventura de Lyft: desde Amazon ES a Elasticsearch autoadministrado para alcanzar un análisis de log operativo en Elastic{ON} 2018. Aprenderás todo sobre las opciones de hardware, las decisiones de administración del ciclo de vida de indexación y más, incluida la diferencia entre “llevar logs de todo y llevar logs de cualquier cosa” en lo que respecta a la calidad de servicio.