BM25 práctico - Parte 2: El algoritmo BM25 y sus variables
Este es el segundo blog de la serie de tres partes de BM25 práctico sobre la clasificación por similitud (relevancia). Si recién te estás sumando, echa un vistazo a la Part 1: How Shards Affect Relevance Scoring in Elasticsearch (Parte 1: Cómo afectan los shards a la relevancia en Elasticsearch).
El algoritmo BM25
Intentaré profundizar en los conceptos matemáticos solo en la medida de lo necesario para explicar lo que sucede, pero esta es la parte en la que observamos la estructura de la fórmula BM25 para obtener información sobre lo que sucede. Primero observaremos la fórmula, luego desglosaré cada componente en piezas comprensibles:
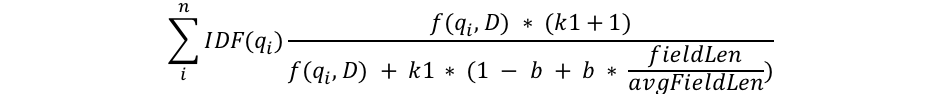
Podemos ver algunos componentes comunes, como qi, IDF(qi), f(qi,D), k1, b y algo sobre las longitudes de los campos. Esto es lo que son:
- qi es el término de búsqueda ith.
Por ejemplo, si buscamos "shane", hay solo 1 término de búsqueda, entonces q0 es "shane". Si buscamos "shane connelly" en inglés, Elasticsearch verá el espacio en blanco y tokenizará esto como 2 términos: q0 será "shane" y q1 será "connelly". Estos términos de búsqueda están conectados con las otras partes de la ecuación y todo está resumido. - IDF(gi) es la frecuencia inversa de documento del término de búsqueda ith.
Para quienes ya trabajaron con TF/IDF antes, el concepto de IDF puede resultar conocido. Si no es así, ¡no te preocupes! (En ese caso, ten en cuenta que hay una diferencia entre la fórmula de IDF en TF/IDF e IDF en BM25). El componente IDF de nuestra fórmula mide la frecuencia con la que ocurre un término en todos los documentos y "penaliza" los términos comunes. La fórmula real que usa Lucene/BM25 para esta parte es la siguiente: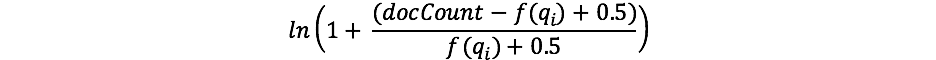
Donde docCount es la cantidad total de documentos que tienen un valor para el campo en el shard (en todos los shards, si usassearch_type=dfs_query_then_fetch) y f(qi) es la cantidad de documentos que contienen el término de búsqueda ith. Podemos ver en nuestro ejemplo que "shane" aparece en los 4 documentos, por lo que, para el término "shane", tenemos un IDF("shane") de: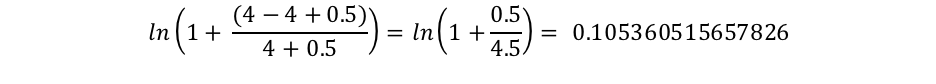
Sin embargo, podemos ver que "connelly" solo aparece en 2 documentos, por lo que tenemos un IDF("connelly") de: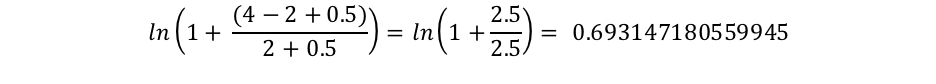
Aquí podemos ver que las búsquedas que contienen estos términos poco frecuentes ("connelly" menos frecuente que "shane" en nuestro corpus de 4 documentos) tienen un multiplicador más alto, por lo que contribuyen más a la puntuación final. Esto puede intuirse: el término "the" probablemente aparezca en casi todo documento en inglés, por lo que, cuando un usuario busca algo como "the elephant", "elephant" es probablemente más importante (y queremos que tenga una mayor contribución en la puntuación) que el término "the" (que aparecerá en casi todos los documentos).
- Vemos que la longitud del campo se divide por la longitud de campo promedio en el denominador, como fieldLen/avgFieldLen.
Podemos pensar en esto como la longitud de un documento en relación con la longitud del documento promedio. Si un documento es más largo que el promedio, el denominador es más grande (lo que disminuye la puntuación), y si es más corto que el promedio, el denominador es menor (lo que aumenta la puntuación). Ten en cuenta que la implementación del largo de campo en Elasticsearch se basa en la cantidad de términos (y no en otros factores, como el largo de caracteres). Esto es tal como se describe en el documento de BM25 original, aunque sí tenemos una marca especial (discount_overlaps) que se ocupa específicamente de los sinónimos, si así lo deseas. La forma de pensar en esto es: mientras más términos haya en el documento (al menos los que no coincidan con la búsqueda), menor será la puntuación del documento. Nuevamente, esto puede intuirse: si un documento tiene 300 páginas y menciona mi nombre solo una vez, es menos probable que esté tan relacionado conmigo que un tweet breve que me menciona una vez. - Vemos la variable b que aparece en el denominador y que se multiplica por el cociente de la longitud del campo de la que acabamos de hablar. Si b es más grande, los efectos de la longitud del documento en comparación con la longitud promedio se amplifican más. Para visualizar esto, puedes imaginar que si configuras b como 0, el efecto del cociente se anularía por completo y la longitud del documento no tendría relevancia en la puntuación. De forma predeterminada, b tiene un valor de 0.75 en Elasticsearch.
- Por último, vemos dos componentes de la puntuación que aparecen tanto en el numerador como en el denominador: k1 y f(qi,D). Su presencia en ambos lados hace que sea difícil ver cuál es su función con solo mirar la fórmula, pero analicémoslos brevemente.
- f(qi,D) es "¿cuántas veces aparece el término de búsqueda ith en el documento D?". En todos estos documentos, f("shane",D) es 1, pero f("connelly",D) varía: es 1 en los documentos 3 y 4, pero 0 en los documentos 1 y 2. Si hubiera un 5 to documento que tuviera el texto "shane shane", tendría un f("shane",D)" de 2. Podemos ver que f(qi,D) se encuentra tanto en el numerador como en el denominador, y está ese factor "k1" especial, que veremos a continuación. La forma de pensar en f(qi,D) es que cuantas más veces ocurran los términos de búsqueda en un documento, mayor será su puntuación. Esto puede intuirse: un documento que tiene nuestro nombre muchas veces más probablemente esté relacionado con nosotros que un documento que solo lo tiene una vez.
- k1 es una variable que ayuda a determinar las características de saturación de frecuencia de términos. Es decir, limita cuánto un único término de búsqueda puede afectar la puntuación de un documento dado. Lo hace mediante la aproximación a una asíntota. Puedes ver la comparación de BM25 con TF/IDF aquí:
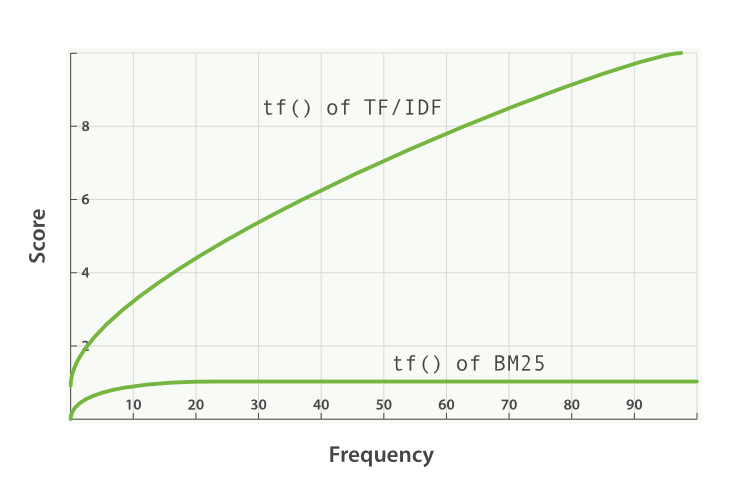
Un valor k1 más alto//más bajo significa que la pendiente de la curva de "tf() of BM25" cambia. Esto tiene el efecto de cambiar cómo "los términos que aparecen más veces agregan más puntuación". Una interpretación de k1 es que, para documentos de largo promedio, es el valor de la frecuencia del término que asigna una puntuación de la mitad de la puntuación máxima del término considerado. La curva del impacto de tf en la puntuación crece rápidamente cuando tf() ≤ k1 y es cada vez más lenta cuando tf() > k1.
Para continuar con nuestro ejemplo, con k1 controlamos la respuesta a la pregunta "¿cuánto más debería contribuir a la puntuación agregar una segunda instancia de ‘shane’ al documento en comparación con el primero, o una tercera instancia en comparación con la segunda?". Un k1 más alto significa que la puntuación de cada término puede continuar aumentando relativamente más por más instancias de ese término. Un valor de 0 para k1 significaría que todo excepto IDF(qi) se cancelaría. De forma predeterminada, k1 tiene un valor de 1.2 en Elasticsearch.
Revisión de la búsqueda con nuestro nuevo conocimiento
Eliminaremos el índice people y lo recrearemos con solo 1 shard para no tener que usar search_type=dfs_query_then_fetch. Comprobaremos nuestro conocimiento configurando tres índices: uno con un valor k1 de 0 y b de 0.5, un segundo índice (people2) con un valor b de 0 y k1 de 10, y un tercer índice (people3) con un valor b de 1 y k1 de 5.
DELETE people
PUT people
{
"settings": {
"number_of_shards": 1,
"index" : {
"similarity" : {
"default" : {
"type" : "BM25",
"b": 0.5,
"k1": 0
}
}
}
}
}
PUT people2
{
"settings": {
"number_of_shards": 1,
"index" : {
"similarity" : {
"default" : {
"type" : "BM25",
"b": 0,
"k1": 10
}
}
}
}
}
PUT people3
{
"settings": {
"number_of_shards": 1,
"index" : {
"similarity" : {
"default" : {
"type" : "BM25",
"b": 1,
"k1": 5
}
}
}
}
}
Ahora agregaremos algunos documentos a los tres índices:
POST people/_doc/_bulk
{ "index": { "_id": "1" } }
{ "title": "Shane" }
{ "index": { "_id": "2" } }
{ "title": "Shane C" }
{ "index": { "_id": "3" } }
{ "title": "Shane P Connelly" }
{ "index": { "_id": "4" } }
{ "title": "Shane Connelly" }
{ "index": { "_id": "5" } }
{ "title": "Shane Shane Connelly Connelly" }
{ "index": { "_id": "6" } }
{ "title": "Shane Shane Shane Connelly Connelly Connelly" }
POST people2/_doc/_bulk
{ "index": { "_id": "1" } }
{ "title": "Shane" }
{ "index": { "_id": "2" } }
{ "title": "Shane C" }
{ "index": { "_id": "3" } }
{ "title": "Shane P Connelly" }
{ "index": { "_id": "4" } }
{ "title": "Shane Connelly" }
{ "index": { "_id": "5" } }
{ "title": "Shane Shane Connelly Connelly" }
{ "index": { "_id": "6" } }
{ "title": "Shane Shane Shane Connelly Connelly Connelly" }
POST people3/_doc/_bulk
{ "index": { "_id": "1" } }
{ "title": "Shane" }
{ "index": { "_id": "2" } }
{ "title": "Shane C" }
{ "index": { "_id": "3" } }
{ "title": "Shane P Connelly" }
{ "index": { "_id": "4" } }
{ "title": "Shane Connelly" }
{ "index": { "_id": "5" } }
{ "title": "Shane Shane Connelly Connelly" }
{ "index": { "_id": "6" } }
{ "title": "Shane Shane Shane Connelly Connelly Connelly" }
Ahora, cuando hagamos:
GET /es/people/_search
{
"query": {
"match": {
"title": "shane"
}
}
}
Vemos en people que todos los documentos tienen una puntuación de 0.074107975. Esto concuerda con nuestro entendimiento de tener k1 configurado en 0: solo el IDF del término de búsqueda importa para la puntuación.
Ahora veamos people2, que tiene b = 0 y k1 = 10:
GET /es/people2/_search
{
"query": {
"match": {
"title": "shane"
}
}
}
Tenemos dos aprendizajes de los resultados de esta búsqueda.
Primero, podemos ver que las puntuaciones se ordenan meramente por la cantidad de veces que aparece "shane". Los documentos 1, 2, 3 y 4 contienen "shane" una vez y, por lo tanto, comparten la misma puntuación de 0.074107975. El documento 5 tiene "shane" dos veces, por lo que tiene una puntuación mayor (0.13586462) gracias a f("shane",D5) = 2, y el documento 6 tiene una puntuación aún más alta (0.18812023) gracias a f("shane",D6) = 3. Esto se ajusta a nuestra intuición de configurar b como 0 en people2: la longitud (o la cantidad total de términos en el documento) no afecta la puntuación; solo el conteo y la relevancia de los términos que coinciden.
Lo segundo que se debe tener en cuenta es que las diferencias entre estas puntuaciones son no lineales, si bien parecen ser bastante lineales con estos 6 documentos.
- La diferencia de puntuación entre ninguna instancia de nuestro término de búsqueda y la primera es 0.074107975.
- La diferencia de puntuación entre agregar una segunda instancia de nuestro término de búsqueda y la primera es 0.13586462 - 0.074107975 = 0.061756645.
- La diferencia de puntuación entre agregar una tercera instancia de nuestro término de búsqueda y la segunda es 0.18812023 - 0.13586462 = 0.05225561.
0.074107975 se acerca bastante a 0.061756645, que se acerca bastante a 0.05225561, pero claramente disminuyen. El motivo por el que parece casi lineal es porque k1 es grande. Podemos ver, al menos, que la puntuación no aumenta de forma lineal con instancias adicionales; si así fuera, esperaríamos ver la misma diferencia con cada término adicional. Retomaremos esta idea luego de ver people3.
Ahora veamos people3, que tiene k1 = 5 y b = 1:
GET /es/people3/_search
{
"query": {
"match": {
"title": "shane"
}
}
}
Recibimos lo siguiente:
"hits": [
{
"_index": "people3",
"_type": "_doc",
"_id": "1",
"_score": 0.16674294,
"_source": {
"title": "Shane"
}
},
{
"_index": "people3",
"_type": "_doc",
"_id": "6",
"_score": 0.10261105,
"_source": {
"title": "Shane Shane Shane Connelly Connelly Connelly"
}
},
{
"_index": "people3",
"_type": "_doc",
"_id": "2",
"_score": 0.102611035,
"_source": {
"title": "Shane C"
}
},
{
"_index": "people3",
"_type": "_doc",
"_id": "4",
"_score": 0.102611035,
"_source": {
"title": "Shane Connelly"
}
},
{
"_index": "people3",
"_type": "_doc",
"_id": "5",
"_score": 0.102611035,
"_source": {
"title": "Shane Shane Connelly Connelly"
}
},
{
"_index": "people3",
"_type": "_doc",
"_id": "3",
"_score": 0.074107975,
"_source": {
"title": "Shane P Connelly"
}
}
]
Podemos ver en people3 que ahora el cociente entre términos coincidentes ("shane") y términos no coincidentes es lo único que afecta la puntuación relativa. Por lo tanto, los documentos, como el documento 3, que solo tiene 1 término coincidente de 3, tiene una puntuación inferior que 2, 4, 5 y 6, que tienen coincidencia exacta con la mitad de los términos, y todos ellos tienen una puntuación inferior que el documento 1, que coincide de forma exacta.
Nuevamente, podemos ver que hay una "gran" diferencia entre los documentos con mejor puntuación y aquellos con menor puntuación en people2 y people3. Esto se debe, nuevamente, a un valor alto de k1. Como ejercicio adicional, intenta eliminar people2/people3 y volver a configurarlos con algo como k1 = 0.01, así verás que las puntuaciones entre los documentos con un valor inferior son menores. Con b = 0 y k1 = 0.01:
- La diferencia de puntuación entre ninguna instancia de nuestro término de búsqueda y la primera es 0.074107975.
- La diferencia de puntuación entre agregar una segunda instancia de nuestro término de búsqueda y la primera es 0.074476674 - 0.074107975 = 0.000368699.
- La diferencia de puntuación entre agregar una tercera instancia de nuestro término de búsqueda y la segunda es 0.07460038 - 0.074476674 = 0.000123706.
Entonces, con k1 = 0.01, podemos ver que la influencia en la puntuación de cada instancia adicional disminuye mucho más rápido que con k1 = 5 o k1 = 10. La 4ta instancia agregaría mucho menos a la puntuación que la 3ra y así sucesivamente. En otras palabras, las puntuaciones de términos se saturan mucho más rápidos con estos valores k1 más pequeños. ¡Tal como esperábamos!
Ojalá esto ayude a mostrar lo que hacen estos parámetros en varios conjuntos de documentos. Con este conocimiento, luego veremos cómo elegir un b y k1 apropiados, y cómo Elasticsearch proporciona las herramientas para comprender las puntuaciones e iterar en tu enfoque.
Continúa esta serie con: Part 3: Considerations for Picking b and k1 in Elasticsearch (Parte 3: Consideraciones para elegir b y k1 en Elasticsearch)