- Fleet and Elastic Agent Guide: other versions:
- Fleet and Elastic Agent overview
- Beats and Elastic Agent capabilities
- Quick starts
- Migrate from Beats to Elastic Agent
- Set up Fleet Server
- Install Elastic Agents
- Install Fleet-managed Elastic Agents
- Install standalone Elastic Agents (advanced users)
- Install Elastic Agents in a containerized environment
- Installation layout
- Air-gapped environments
- Use a proxy server with Elastic Agent and Fleet
- Uninstall Elastic Agents from edge hosts
- Start and stop Elastic Agents on edge hosts
- Elastic Agent configuration encryption
- Secure connections
- Manage Elastic Agents in Fleet
- Manage integrations
- Configure standalone Elastic Agents
- Define processors
- Processor syntax
- add_cloud_metadata
- add_cloudfoundry_metadata
- add_docker_metadata
- add_fields
- add_host_metadata
- add_id
- add_kubernetes_metadata
- add_labels
- add_locale
- add_network_direction
- add_nomad_metadata
- add_observer_metadata
- add_process_metadata
- add_tags
- community_id
- convert
- copy_fields
- decode_base64_field
- decode_cef
- decode_csv_fields
- decode_duration
- decode_json_fields
- decode_xml
- decode_xml_wineventlog
- decompress_gzip_field
- detect_mime_type
- dissect
- dns
- drop_event
- drop_fields
- extract_array
- fingerprint
- include_fields
- move_fields
- parse_aws_vpc_flow_log
- rate_limit
- registered_domain
- rename
- replace
- script
- syslog
- timestamp
- translate_sid
- truncate_fields
- urldecode
- Command reference
- Troubleshoot
- Release notes
Fleet Server scalability
editFleet Server scalability
editThis page summarizes the resource and Fleet Server configuration requirements needed to scale your deployment of Elastic Agents. To scale Fleet Server, you need to modify settings in your deployment and the Fleet Server agent policy.
First modify your Fleet deployment settings in Elastic Cloud:
- Log in to Elastic Cloud and go to your deployment.
- Under Deployments > deployment name, click Edit.
-
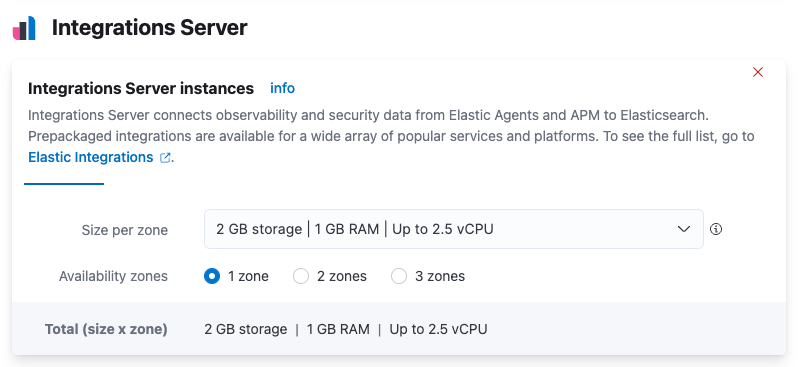
Under Integrations Server:
- Modify the compute resources available to the server to accommodate a higher scale of Elastic Agents
- Modify the availability zones to satisfy fault tolerance requirements
For recommended settings, refer to Scaling recommendations (Elastic Cloud).
Next modify the Fleet Server configuration by editing the agent policy:
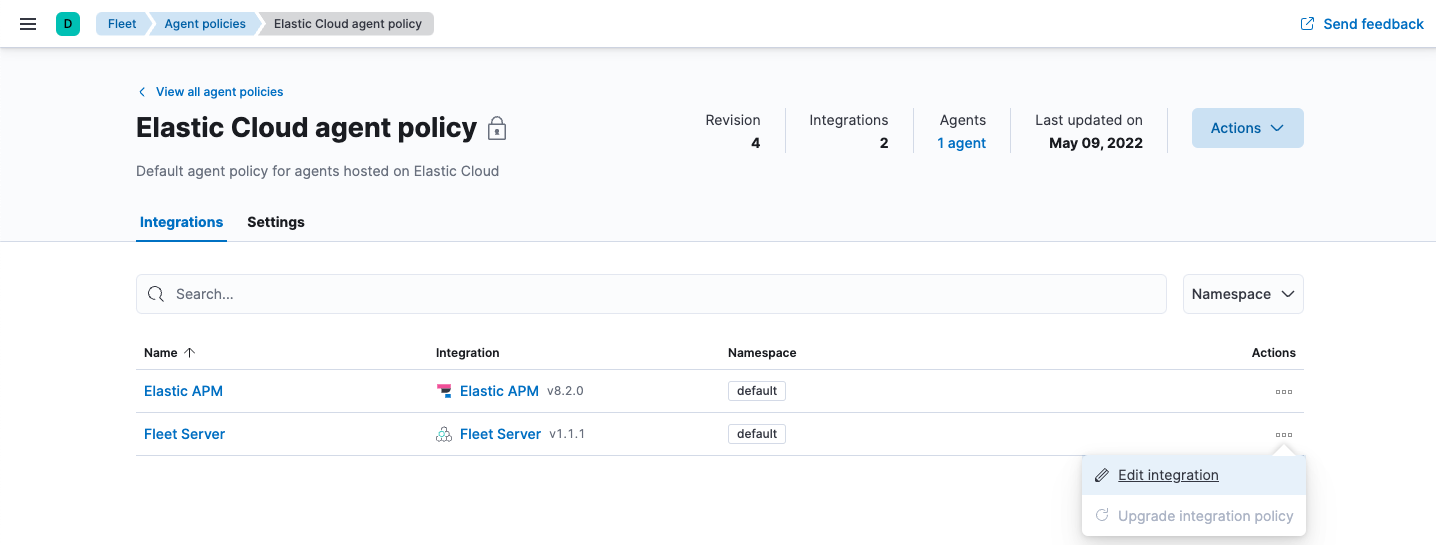
- In Kibana, go to Management > Fleet > Agent Policies. Click the name of the Elastic Cloud agent policy to edit the policy.
-
Open the Actions menu next to the Fleet Server integration and click Edit integration.
-
Under Fleet Server, modify Max Connections and other advanced settings as described in Scaling recommendations (Elastic Cloud).
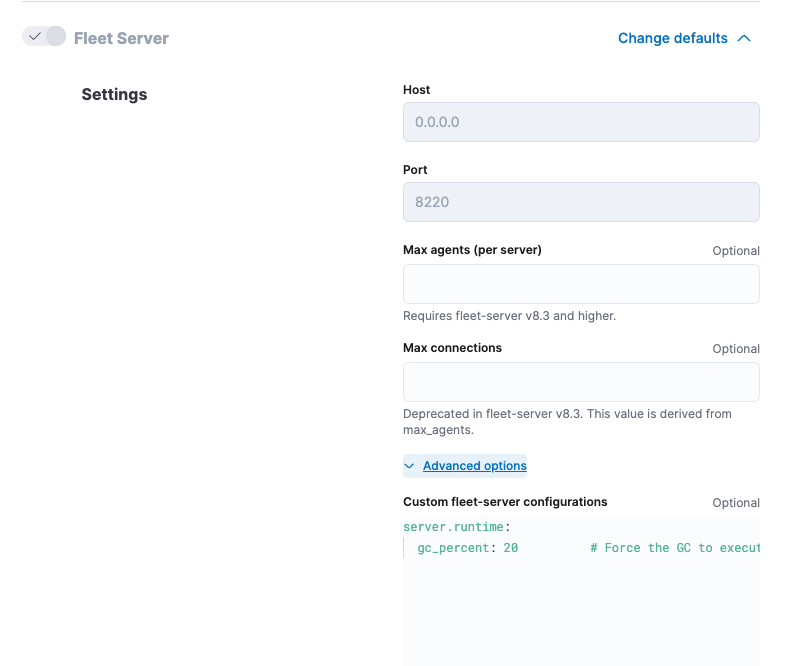
Advanced Fleet Server options
editThe following advanced settings are available to fine tune your Fleet Server deployment.
-
cache -
-
num_counters - Size of the hash table. Best practice is to have this set to 10 times the max connections.
-
max_cost - Total size of the cache.
-
-
server.timeouts -
-
checkin_timestamp -
How often Fleet Server updates the "last activity" field for each agent.
Defaults to
30s. In a large-scale deployment, increasing this setting may improve performance. If this setting is higher than2m, most agents will be shown as "offline" in the Fleet UI. For a typical setup, it’s recommended that you set this value to less than2m. -
checkin_long_poll -
How long Fleet Server allows a long poll request from an agent before
timing out. Defaults to
5m. In a large-scale deployment, increasing this setting may improve performance.
-
-
server.limits -
-
policy_throttle - How often a new policy is rolled out to the agents.
-
checkin_limit.interval - How fast the agents can check in to the Fleet Server.
-
checkin_limit.burst -
Burst of check-ins allowed before falling back to the rate defined by
interval. -
checkin_limit.max - Maximum number of agents.
-
artifact_limit.max - Maximum number of agents that can call the artifact API concurrently. It allows the user to avoid overloading the Fleet Server from artifact API calls.
-
artifact_limit.interval -
How often artifacts are rolled out. Default of
100msallows 10 artifacts to be rolled out per second. -
artifact_limit.burst - Number of transactions allowed for a burst, controlling oversubscription on outbound buffer.
-
ack_limit.max - Maximum number of agents that can call the Ack API concurrently. It allows the user to avoid overloading the Fleet Server from Ack API calls.
-
ack_limit.interval -
How often an acknowledgment (ACK) is sent. Default value of
10msenables 100 ACKs per second to be sent. -
ack_limit.burst -
Burst of ACKs to accommodate (default of 20) before falling back to the rate
defined in
interval. -
enroll_limit.max - Maximum number of agents that can call the Enroll API concurrently. This setting allows the user to avoid overloading the Fleet Server from Enrollment API calls.
-
enroll_limit.interval -
Interval between processing enrollment request. Enrollment is both CPU and RAM
intensive, so the number of enrollment requests needs to be limited for overall
system health. Default value of
100msallows 10 enrollments per second. -
enroll_limit.burst -
Burst of enrollments to accept before falling back to the rate defined by
interval.
-
Scaling recommendations (Elastic Cloud)
editThe following tables provide resource requirements and scaling guidelines based on the number of agents required by your deployment:
Resource requirements by number of agents
editNumber of Agents |
Memory |
vCPU |
Elasticsearch Cluster size |
50 |
1 GB |
Up to 8.5 vCPU |
480 GB disk | 16 GB RAM | up to 5 vCPU |
5,000 |
2 GB |
Up to 8.5 vCPU |
960 GB disk | 32 GB RAM | 5 vCPU |
7,500 |
4 GB |
Up to 8.5 vCPU |
1.88 TB disk | 64 GB RAM | 9.8 vCPU |
10,000 |
8 GB |
Up to 8.5 vCPU |
3.75 TB disk | 128 GB RAM | 19.8 vCPU |
15,000 |
16 GB |
8.5 vCPU |
7.5 TB disk | 256 GB RAM | 39.4 vCPU |
25,000 |
16 GB |
8.5 vCPU |
7.5 TB disk | 256 GB RAM | 39.4 vCPU |
50,000 |
32 GB |
16.9 vCPU |
11.25 TB disk | 384 GB RAM |59.2 vCPU |
Recommended settings by number of deployed Elastic Agents
editYou might need to scroll to the right to see all the table columns.
50 |
5,000 |
7,500 |
10,000 |
12,500 |
30,000 |
50,000 |
|
Max Connections |
100 |
7,000 |
10,000 |
20,000 |
32,000 |
32,000 |
32,000 |
Cache settings |
|||||||
|
2000 |
20000 |
40000 |
80000 |
160000 |
160000 |
320000 |
|
2097152 |
20971520 |
50971520 |
104857600 |
209715200 |
209715200 |
209715200 |
Server limits |
|||||||
|
200 ms |
50 ms |
10 ms |
5 ms |
5 ms |
2 ms |
5 ms |
|
|||||||
|
50 ms |
5 ms |
2 ms |
1 ms |
500 us |
500 us |
500 us |
|
25 |
500 |
1000 |
2000 |
4000 |
4000 |
4000 |
|
100 |
5001 |
7501 |
10001 |
12501 |
15001 |
25001 |
|
|||||||
|
100 ms |
5 ms |
2 ms |
1 ms |
500 us |
500 us |
500 us |
|
10 |
500 |
1000 |
2000 |
4000 |
4000 |
4000 |
|
10 |
1000 |
2000 |
4000 |
8000 |
8000 |
8000 |
|
|||||||
|
10 ms |
4 ms |
2 ms |
1 ms |
500 us |
500 us |
500 us |
|
20 |
500 |
1000 |
2000 |
4000 |
4000 |
4000 |
|
20 |
1000 |
2000 |
4000 |
8000 |
8000 |
8000 |
|
|||||||
|
100 ms |
20 ms |
10 ms |
10 ms |
10 ms |
10 ms |
10 ms |
|
5 |
50 |
100 |
100 |
100 |
100 |
100 |
|
10 |
100 |
200 |
200 |
200 |
200 |
200 |
Server runtime settings |
|||||||
|
20 |
20 |
20 |
20 |
20 |
20 |
20 |
On this page