- Machine Learning: other versions:
- What is Elastic Machine Learning?
- Setup and security
- Anomaly detection
- Finding anomalies
- Advanced concepts
- API quick reference
- Examples
- Tutorial: Getting started with anomaly detection
- Generating alerts for anomaly detection jobs
- Aggregating data for faster performance
- Customizing detectors with custom rules
- Detecting anomalous categories of data
- Reverting to a model snapshot
- Detecting anomalous locations in geographic data
- Performing population analysis
- Altering data in your datafeed with runtime fields
- Adding custom URLs to machine learning results
- Handling delayed data
- Mapping anomalies by location
- Exporting and importing machine learning jobs
- Resources
- Data frame analytics
- Natural language processing
Add NLP inference to ingest pipelines
editAdd NLP inference to ingest pipelines
editAfter you deploy a trained model in your cluster, you can use it to perform natural language processing tasks in ingest pipelines.
- Verify that all of the ingest pipeline prerequisites are met.
- Add an inference processor to an ingest pipeline.
- Ingest documents.
- View the results.
Add an inference processor to an ingest pipeline
editIn Kibana, you can create and edit pipelines in Stack Management > Ingest Pipelines.
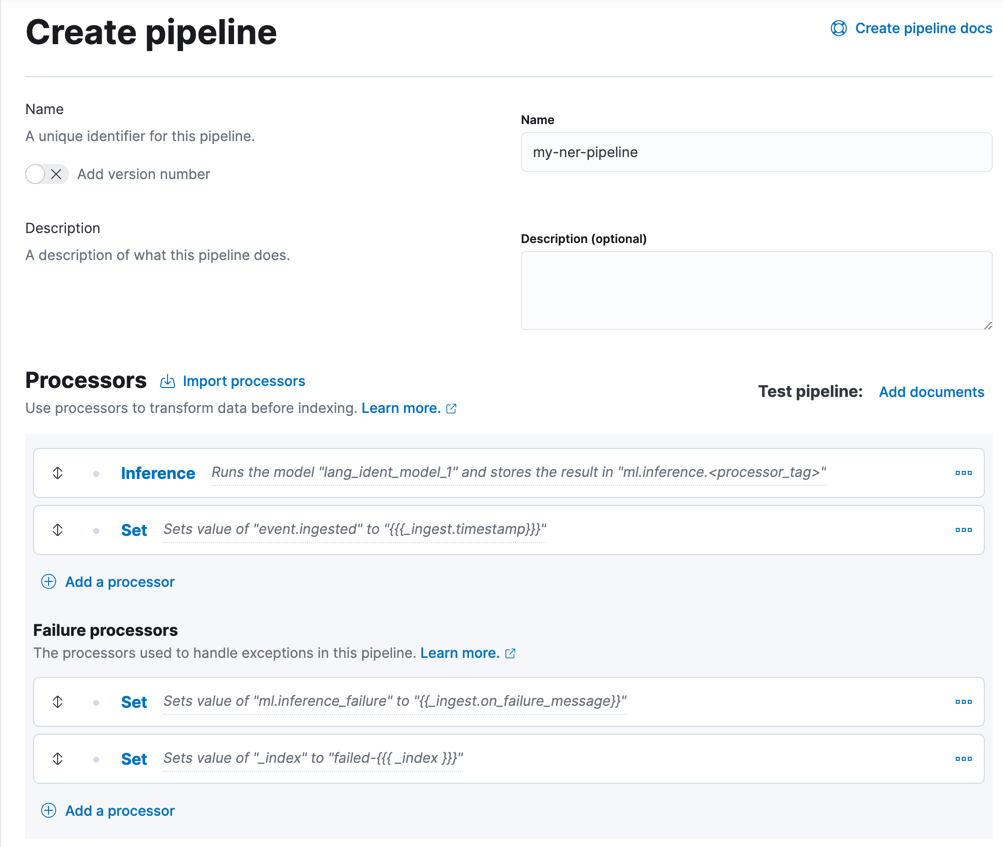
- Click Create pipeline or edit an existing pipeline.
-
Add an inference processor to your pipeline:
- Click Add a processor and select the Inference processor type.
-
Set Model ID to the name of your trained model, for example
elastic__distilbert-base-cased-finetuned-conll03-englishorlang_ident_model_1. -
If you use the language identification model (
lang_ident_model_1) that is provided in your cluster:-
The input field name is assumed to be
text. If you want to identify languages in a field with a different name, you must map your field name totextin the Field map section. For example:{ "message": "text" }
-
You can also optionally add classification configuration options in the Inference configuration section. For example, to include the top five language predictions:
{ "classification":{ "num_top_classes":5 } }
-
- Click Add to save the processor.
-
Optional: Add a set processor to index the ingest timestamp.
- Click Add a processor and select the Set processor type.
-
Choose a name for the field (such as
event.ingested) and set its value to{{{_ingest.timestamp}}}. For more details, refer to Access ingest metadata in a processor. - Click Add to save the processor.
-
Optional: Add failure processors to handle exceptions. For example, in the Failure processors section:
-
Add a set processor to capture the
pipeline error message. Choose a name for the field (such as
ml.inference_failure) and set its value to the{{_ingest.on_failure_message}}document metadata field. -
Add a set processor to reroute
problematic documents to a different index for troubleshooting purposes. Use
the
_indexmetadata field and set its value to a new name (such asfailed-{{{ _index }}}). For more details, refer to Handling pipeline failures.
-
Add a set processor to capture the
pipeline error message. Choose a name for the field (such as
-
To test the pipeline, click Add documents.
-
In the Documents tab, provide a sample document for testing.
For example, to test a trained model that performs named entity recognition (NER):
[ { "_source": { "text_field":"Hello, my name is Josh and I live in Berlin." } } ]
To test a trained model that performs language identification:
[ { "_source":{ "message":"Sziasztok! Ez egy rövid magyar szöveg. Nézzük, vajon sikerül-e azonosítania a language identification funkciónak? Annak ellenére is sikerülni fog, hogy a szöveg két angol szót is tartalmaz." } } ]
-
Click Run the pipeline and verify the pipeline worked as expected.
In the language identification example, the predicted value is the ISO identifier of the language with the highest probability. In this case, it should be
hufor Hungarian. - If everything looks correct, close the panel, and click Create pipeline. The pipeline is now ready for use.
-
Ingest documents
editYou can now use your ingest pipeline to perform NLP tasks on your data.
Before you add data, consider which mappings you want to use. For example, you can create explicit mappings with the create index API in the Dev Tools > Console:
PUT ner-test { "mappings": { "properties": { "ml.inference.predicted_value": {"type": "annotated_text"}, "ml.inference.model_id": {"type": "keyword"}, "text_field": {"type": "text"}, "event.ingested": {"type": "date"} } } }
To use the annotated_text data type in this example, you must install the
mapper annotated text plugin. For more
installation details, refer to
Add plugins provided with Elasticsearch Service.
You can then use the new pipeline to index some documents. For example, use a
bulk indexing request with the pipeline query parameter for your NER pipeline:
POST /_bulk?pipeline=my-ner-pipeline {"create":{"_index":"ner-test","_id":"1"}} {"text_field":"Hello, my name is Josh and I live in Berlin."} {"create":{"_index":"ner-test","_id":"2"}} {"text_field":"I work for Elastic which was founded in Amsterdam."} {"create":{"_index":"ner-test","_id":"3"}} {"text_field":"Elastic has headquarters in Mountain View, California."} {"create":{"_index":"ner-test","_id":"4"}} {"text_field":"Elastic's founder, Shay Banon, created Elasticsearch to solve a simple need: finding recipes!"} {"create":{"_index":"ner-test","_id":"5"}} {"text_field":"Elasticsearch is built using Lucene, an open source search library."}
Or use an individual indexing request with the pipeline query parameter for
your language identification pipeline:
POST lang-test/_doc?pipeline=my-lang-pipeline { "message": "Mon pays ce n'est pas un pays, c'est l'hiver" }
You can also use NLP pipelines when you are reindexing documents to a new
destination. For example, since the
sample web logs data set
contain a message text field, you can reindex it with your language identification
pipeline:
POST _reindex { "source": { "index": "kibana_sample_data_logs", "size": 500 }, "dest": { "index": "lang-test", "pipeline": "my-lang-pipeline" } }
However, those web log messages are unlikely to contain enough words for the model to accurately identify the language.
Set the reindex size option to a value
smaller than the queue_capacity for the trained model deployment. Otherwise, requests might be rejected
with a "too many requests" 429 error code.
View the results
editBefore you can verify the results of the pipelines, you must create data views. Then you can explore your data in Discover:
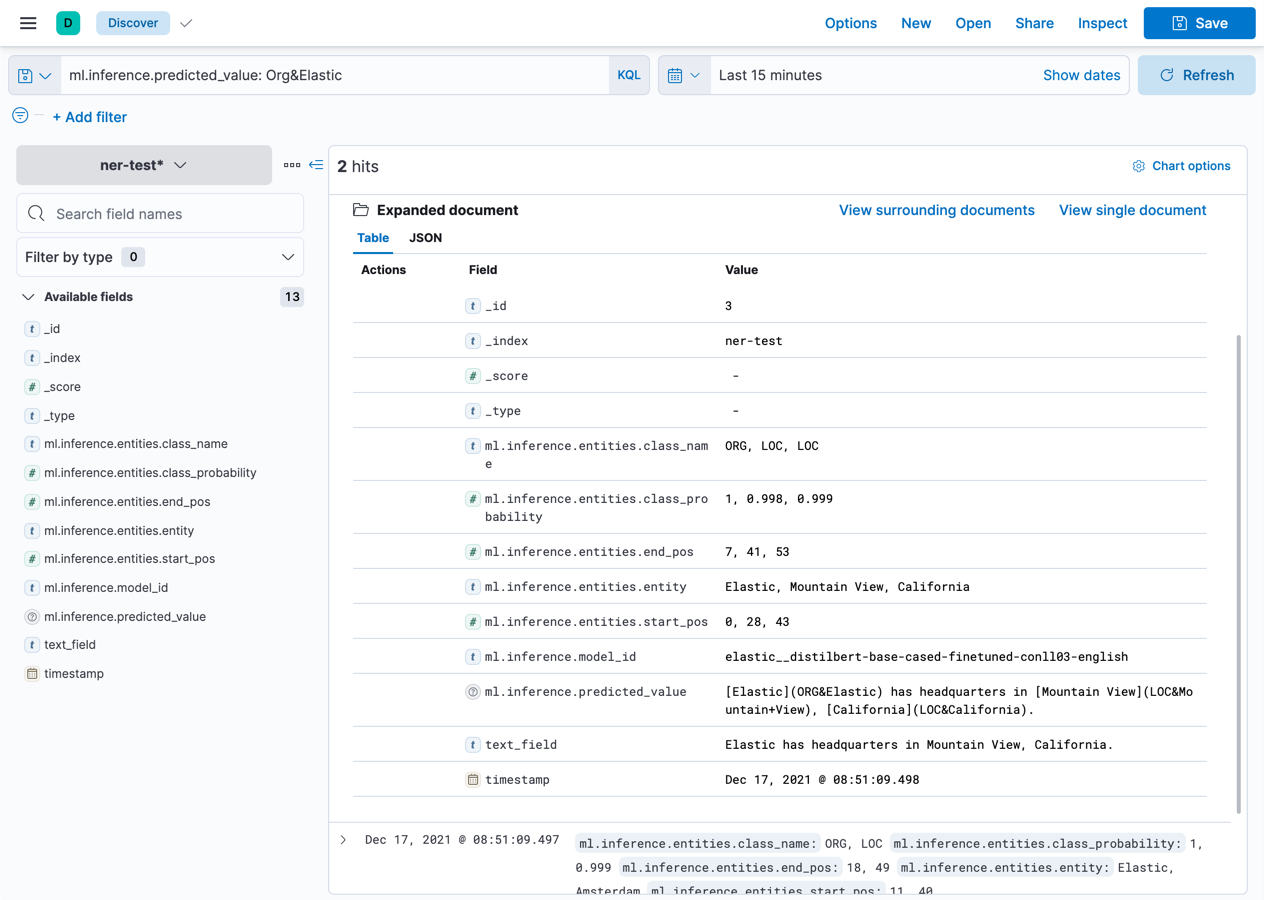
The ml.inference.predicted_value field contains the output from the inference
processor. In this NER example, there are two documents that contain the
Elastic organization entity.
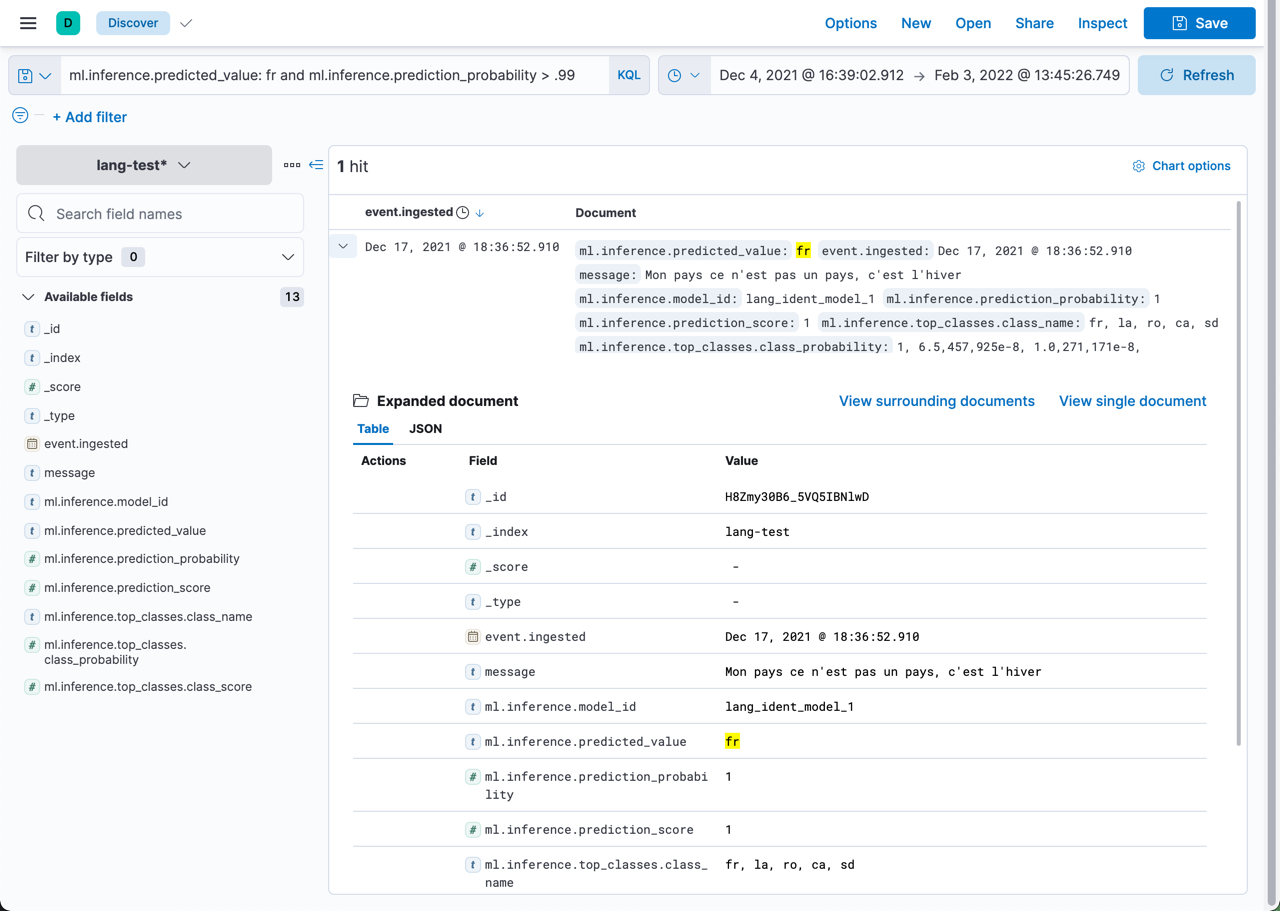
In this language identification example, the ml.inference.predicted_value contains the
ISO identifier of the language with the highest probability and the
ml.inference.top_classes fields contain the top five most probable languages
and their scores:
To learn more about ingest pipelines and all of the other processors that you can add, refer to Ingest pipelines.
Common problems
editIf you encounter problems while using your trained model in an ingest pipeline, check the following possible causes:
-
The trained model is not deployed in your cluster. You can view its status in
Machine Learning > Model Management or use the
get trained models statistics API. Unless
you are using the built-in
lang_ident_model_1model, you must ensure your model is successfully deployed. Refer to Deploy the model in your cluster. - The default input field name expected by your trained model is not present in your source document. Use the Field Map option in your inference processor to set the appropriate field name.
-
There are too many requests. If you are using bulk ingest, reduce the number
of documents in the bulk request. If you are reindexing, use the
sizeparameter to decrease the number of documents processed in each batch.
These common failure scenarios and others can be captured by adding failure processors to your pipeline. For more examples, refer to Handling pipeline failures.
Further reading
editOn this page