Universal Profiling
Impulsione a otimização e a sustentabilidade com a criação de perfis contínua
Mantenha a integridade com visibilidade de todo o sistema em ambientes complexos e nativos da nuvem. A criação de perfis contínua e sem atrito, baseada no OpenTelemetry, possibilita que você otimize o desempenho em todos os níveis da aplicação, dos serviços e da infraestrutura sem necessidade de instrumentação.
A engenharia de desempenho alia-se à sustentabilidade com a disponibilidade geral do Elastic Universal Profiling
Saiba maisConheça a mais recente contribuição da Elastic — agente de Universal Profiling para o OpenTelemetry.
Leia o postSaiba por que a Elastic foi nomeada Visionária no Magic Quadrant da Gartner para Monitoramento de Performance de Aplicação de 2023.
Saiba maisCriação de perfis contínua que simplesmente funciona
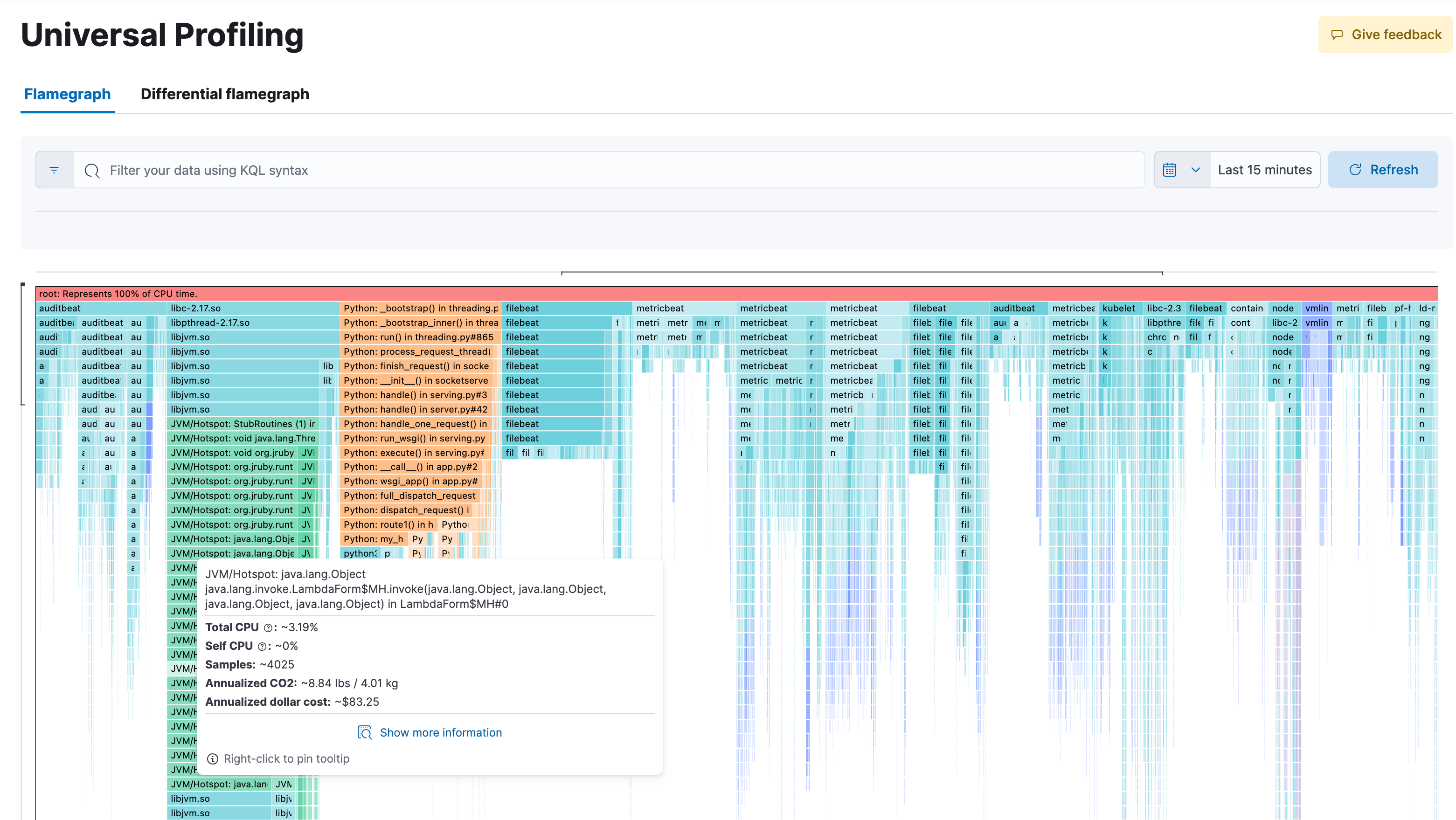
Obtenha visibilidade sem precedentes em todos os níveis com a criação de perfis de todo o sistema 24 horas por dia, 7 dias por semana. Aproveitando a tecnologia eBPF e o OpenTelemetry, o Universal Profiling traça o perfil de cada linha de código em execução na máquina, incluindo não apenas o código da sua aplicação, mas também o kernel e bibliotecas de terceiros. Ao capturar apenas os dados necessários de maneira discreta, ele consegue ser executado continuamente em sistemas de produção sem nenhum impacto perceptível (menos de 1% de sobrecarga da CPU)! Não são necessárias alterações intrusivas no código ou na instrumentação.
Otimização do desempenho ao seu alcance
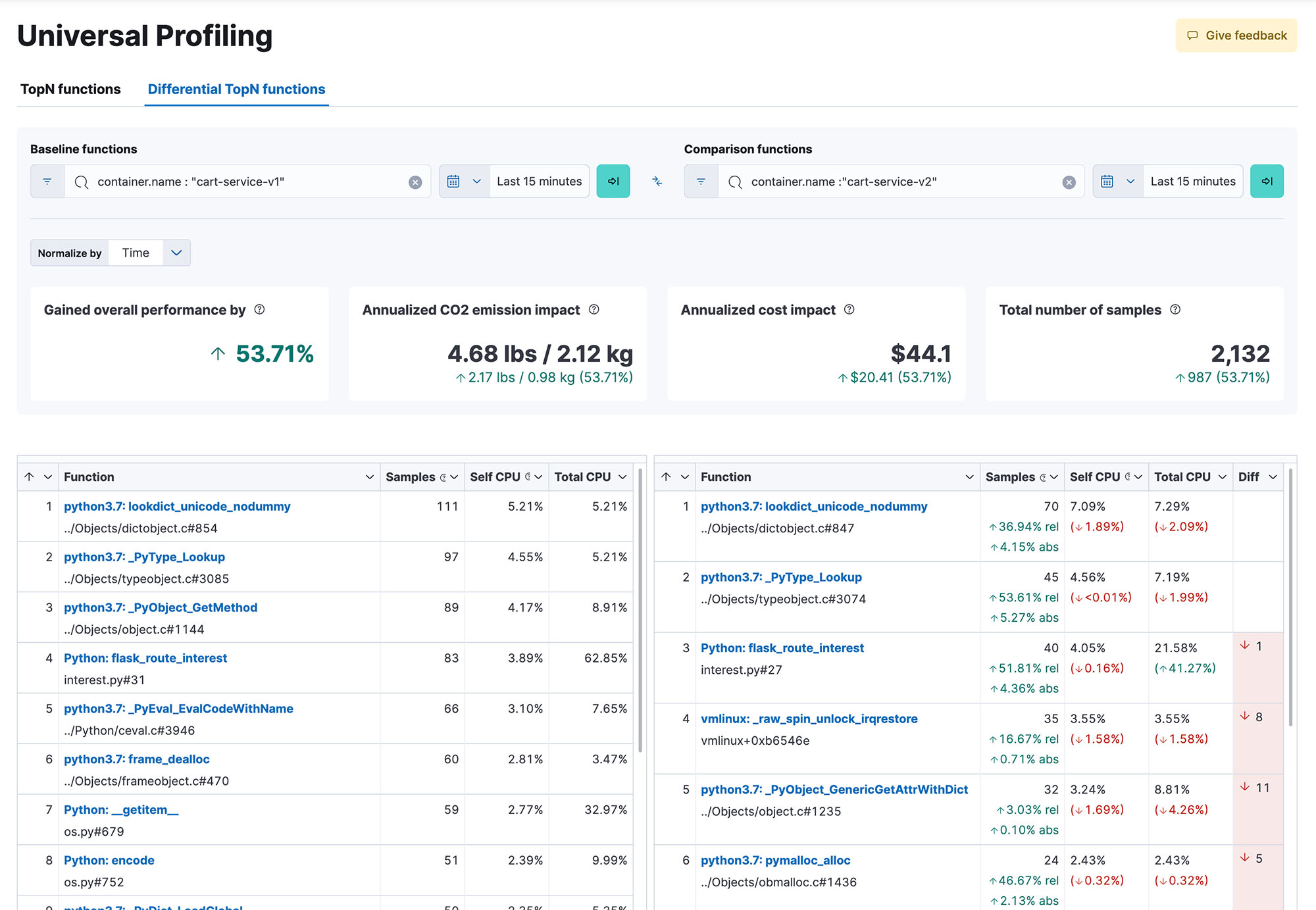
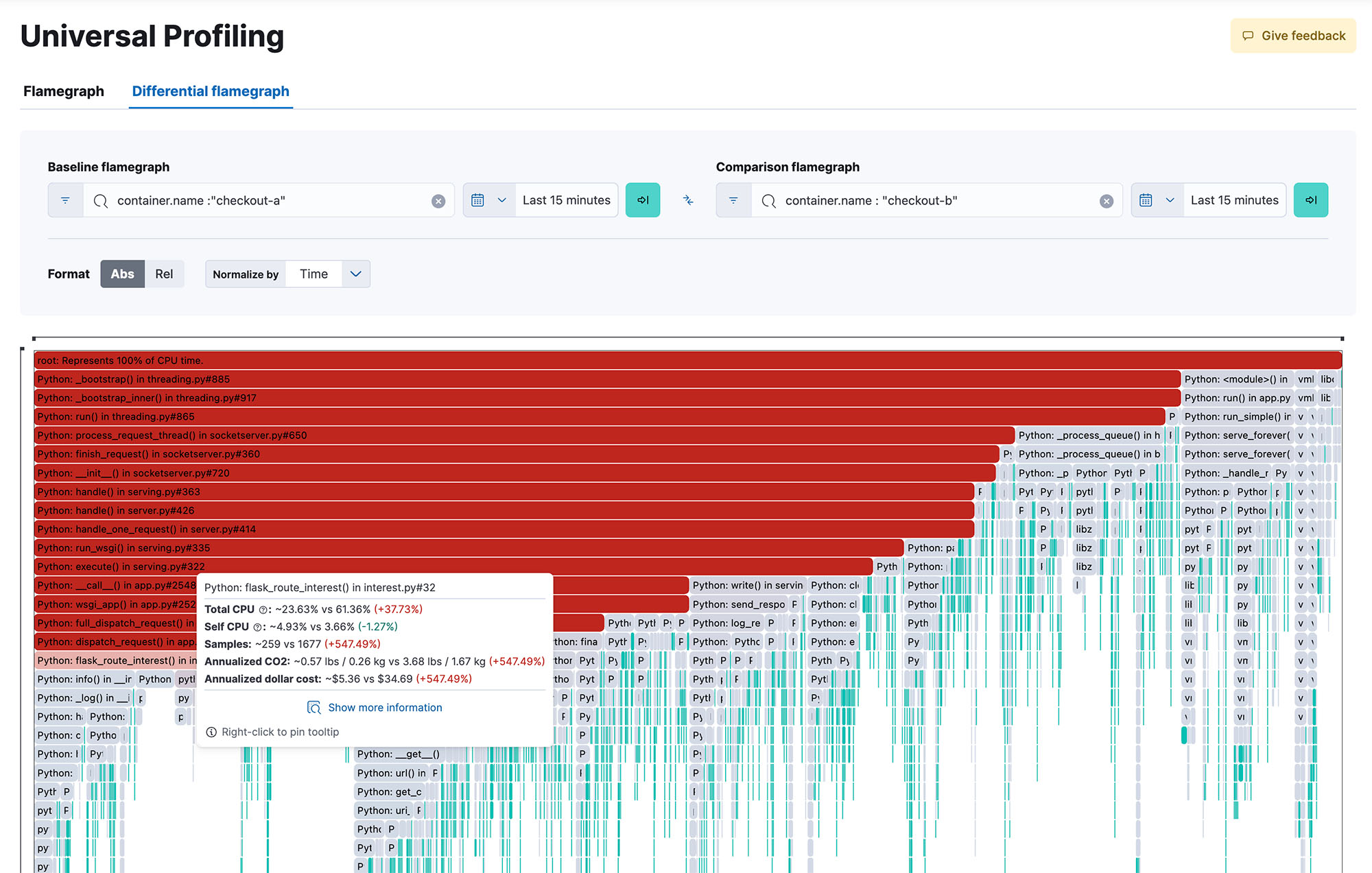
Obtenha visibilidade de todo o sistema em 100% do seu código durante a execução, em todos os métodos, classes, threads e containers, bem como a capacidade de comparar entre compilações para identificar regressões de desempenho. Grafos de chama responsivos e fáceis de usar ajudam você a explorar o desempenho de todo o seu sistema em uma única visualização. Identifique o código que consome mais recursos para identificar e resolver gargalos de desempenho, otimizar os gastos com a nuvem e reduzir a pegada de carbono da sua infraestrutura.
Implantação flexível e sem atrito
O Elastic Universal Profiling não requer nenhuma alteração no código-fonte da aplicação, instrumentação ou outras operações intrusivas. Basta implantar o agente e receber os dados de criação de perfis alguns minutos depois. O agente pode ser implantado usando o Elastic Agent, executado manualmente como um binário nativo ou como um container do Docker privilegiado, ou implantado automaticamente usando o framework de orquestração do seu cluster.
Amplo suporte para o ecossistema
O suporte para a criação de perfis inclui traces de linguagem mistos em quase todos os tempos de execução de linguagem populares, incluindo PHP, Python, Java (ou qualquer linguagem JVM), Go, Rust, C/C++, Node.js/V8, Ruby, Perl e Zig. Além de suporte de primeira classe para todos os principais frameworks de containerização e orquestração, seja executado no local ou em uma plataforma do Kubernetes gerenciada, como GKE, AKS ou EKS.

A criação de perfis contínua em todo o sistema é apenas uma das maneiras de observar suas cargas de trabalho
Monitore sua infraestrutura, seus logs e seus usuários em uma única solução.