From vector search to powerful REST APIs, Elasticsearch offers developers the most extensive search toolkit. Dive into our sample notebooks in the Elasticsearch Labs repo to try something new. You can also start your free trial or run Elasticsearch locally today.
All code may be found in the Searchlabs repo, in the advanced-rag-techniques branch.
Welcome to Part 2 of our article on Advanced RAG Techniques! In part 1 of this series, we set up, discussed, and implemented the data processing components of the advanced RAG pipeline:
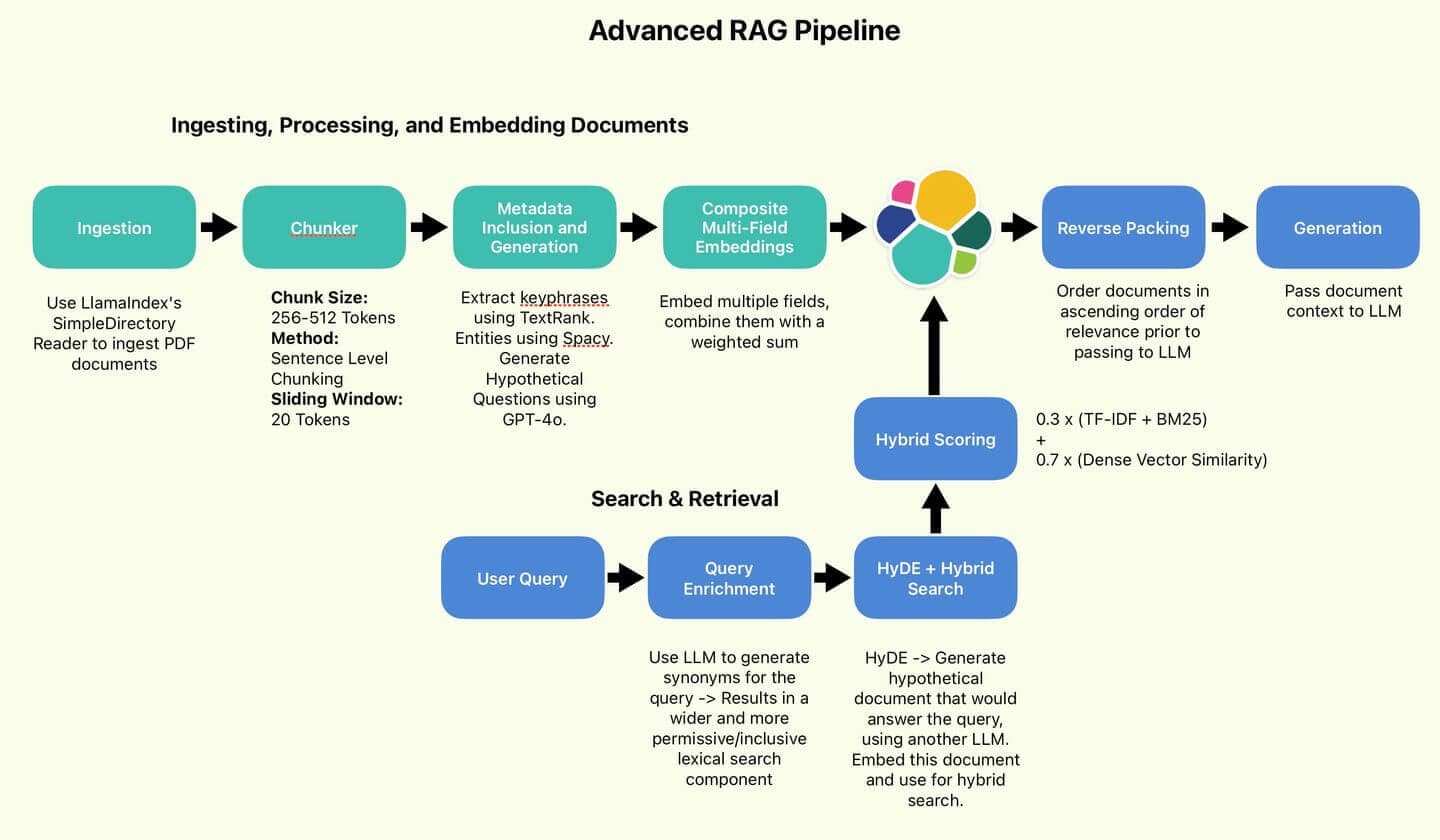
The RAG pipeline used by the author.
In this part, we're going to proceed with querying and testing out our implementation. Let's get right to it!
Table of contents
- Searching and retrieving, generating answers
- Experiments
- Conclusion
- Appendix
Searching and retrieving, generating answers
Let's ask our first query, ideally some piece of information found primarily in the annual report. How about:
Now, let's apply a few of our techniques to enhance the query.
Enriching queries with synonyms
Firstly, let's enhance the diversity of the query wording, and turn it into a form that can be easily processed into an Elasticsearch query. We'll enlist the aid of GPT-4o to convert the query into a list of OR clauses. Let's write this prompt:
When applied to our query, GPT-4o generates synonyms of the base query and related vocabulary.
In the ESQueryMaker class, I've defined a function to split the query:
Its role is to take this string of OR clauses and split them into a list of terms, allowing us do a multi-match on our key document fields:
Finally ending up with this query:
This covers many more bases than the original query, hopefully reducing the risk of missing a search result because we forgot a synonym. But we can do more.
HyDE (Hypothetical Document Embedding)
Let's enlist GPT-4o again, this time to implement HyDE.
The basic premise of HyDE is to generate a hypothetical document - The kind of document that would likely contain the answer to the original query. The factuality or accuracy of the document is not a concern. With that in mind, let's write the following prompt:
Since vector search typically operates on cosine vector similarity, the premise of HyDE is that we can achieve better results by matching documents to documents instead of queries to documents.
What we care about is structure, flow, and terminology. Not so much factuality. GPT-4o outputs a HyDE document like this:
It looks pretty believable, like the ideal candidate for the kinds of documents we'd like to index. We're going to embed this and use it for hybrid search.
Hybrid search
This is the core of our search logic. Our lexical search component will be the generated OR clause strings. Our dense vector component will be embedded HyDE Document (aka the search vector). We use KNN to efficiently identify several candidate documents closest to our search vector. We call our lexical search component Scoring with TF-IDF and BM25 by default. Finally, the lexical and dense vector scores will be combined using the 30/70 ratio recommended by Wang et al.
Finally, we can piece together a RAG function. Our RAG, from query to answer, will follow this flow:
- Convert Query to OR Clauses.
- Generate HyDE document and embed it.
- Pass both as inputs to Hybrid Search.
- Retrieve top-n results, reverse them so that the most relevant score is the "most recent" in the LLM's contextual memory (Reverse Packing) Reverse Packing Example: Query: "Elasticsearch query optimization techniques" Retrieved documents (ordered by relevance): Reversed order for LLM context: By reversing the order, the most relevant information (1) appears last in the context, potentially receiving more attention from the LLM during answer generation.
- "Use bool queries to combine multiple search criteria efficiently."
- "Implement caching strategies to improve query response times."
- "Optimize index mappings for faster search performance."
- "Optimize index mappings for faster search performance."
- "Implement caching strategies to improve query response times."
- "Use bool queries to combine multiple search criteria efficiently."
- Pass the context to the LLM for generation.
Let's run our query and get back our answer:
Nice. That's correct.
Experiments
There's an important question to answer now. What did we get out of investing so much effort and additional complexity into these implementations?
Let's do a little comparison. The RAG pipeline we've implemented versus baseline hybrid search, without any of the enhancements we've made. We'll run a small series of tests and see if we notice any substantial differences. We'll refer to the RAG we have just implemented as AdvancedRAG, and the basic pipeline as SimpleRAG.

Simple RAG Pipeline without bells and whistles
Summary of results
This table summarizes the results of five tests of both RAG pipelines. I judged the relative superiority of each method based on answer detail and quality, but this is a totally subjective judgement. The actual answers are reproduced below this table for your consideration. With that said, let's take a look at how they did!
SimpleRAG was unable to answer questions 1 & 5. AdvancedRAG also went into far greater detail on questions 2, 3, and 4. Based on the increased detail, I judged the quality of AdvancedRAG's answers better.
| Test | Question | AdvancedRAG Performance | SimpleRAG Performance | AdvancedRAG Latency | SimpleRAG Latency | Winner |
|---|---|---|---|---|---|---|
| 1 | Who audits Elastic? | Correctly identified PwC as the auditor. | Failed to identify the auditor. | 11.6s | 4.4s | AdvancedRAG |
| 2 | What was the total revenue in 2023? | Provided the correct revenue figure. Included additional context with revenue from previous years. | Provided the correct revenue figure. | 13.3s | 2.8s | AdvancedRAG |
| 3 | What product does growth primarily depend on? How much? | Correctly identified Elastic Cloud as the key driver. Included overall revenue context & greater detail. | Correctly identified Elastic Cloud as the key driver. | 14.1s | 12.8s | AdvancedRAG |
| 4 | Describe employee benefit plan | Gave a comprehensive description of retirement plans, health programs, and other benefits. Included specific contribution amounts for different years. | Provided a good overview of benefits, including compensation, retirement plans, work environment, and the Elastic Cares program. | 26.6s | 11.6s | AdvancedRAG |
| 5 | Which companies did Elastic acquire? | Correctly listed recent acquisitions mentioned in the report (CmdWatch, Build Security, Optimyze). Provided some acquisition dates and purchase prices. | Failed to retrieve relevant information from the provided context. | 11.9s | 2.7s | AdvancedRAG |
Test 1: Who audits Elastic?
AdvancedRAG
SimpleRAG
Summary: SimpleRAG did not identify PWC as the auditor
Okay that's actually quite surprising. That looks like a search failure on SimpleRAG's part. No documents related to auditing were retrieved. Let's dial down the difficulty a little with the next test.
Test 2: total revenue 2023
AdvancedRAG
SimpleRAG
Summary: Both RAGs got the right answer: $1,068,989,000 total revenue in 2023
Both of them were right here. It does seem like AdvancedRAG may have acquired a broader range of documents? Certainly the answer is more detailed and incorporates information from previous years. That is to be expected given the enhancements we made, but it's far too early to call.
Let's raise the difficulty.
Test 3: What product does growth primarily depend on? How much?
AdvancedRAG
SimpleRAG
Summary: Both RAGs correctly identified Elastic Cloud as the key growth driver. However, AdvancedRAG includes more detail, factoring in subscription revenues and customer growth, and explicitly mentions other Elastic offerings.
Test 4: Describe employee benefit plan
AdvancedRAG
SimpleRAG
Summary: AdvancedRAG goes into much greater depth and detail, mentioning the 401K plan for US-based employees, as well as defining contribution plans outside of the US. It also mentions Health and Well-Being plans but misses the Elastic Cares program, which SimpleRAG mentions.
Test 5: Which companies did Elastic acquire?
AdvancedRAG
SimpleRAG
Summary: SimpleRAG does not retrieve any relevant info about acquisitions, leading to a failed answer. AdvancedRAG correctly lists CmdWatch, Build Security, and Optimyze, which were the key acquisitions listed in the report.
Conclusion
Based on our tests, our advanced techniques appear to increase the range and depth of the information presented, potentially enhancing quality of RAG answers.
Additionally, there may be improvements in reliability, as ambiguously worded questions such as Which companies did Elastic acquire? and Who audits Elastic were correctly answered by AdvancedRAG but not by SimpleRAG.
However, it is worth keeping in perspective that in 3 out of 5 cases, the basic RAG pipeline, incorporating Hybrid Search but no other techniques, managed to produce answers that captured most of the key information.
We should note that due to the incorporation of LLMs at the data preparation and query phases, the latency of AdvancedRAG is generally between 2-5x larger that of SimpleRAG. This is a significant cost which may make AdvancedRAG suitable only for situations where answer quality is prioritized over latency.
The significant latency costs can be alleviated using a smaller and cheaper LLM like Claude Haiku or GPT-4o-mini at the data preparation stage. Save the advanced models for answer generation.
This aligns with the findings of Wang et al. As their results show, any improvements made are relatively incremental. In short, simple baseline RAG gets you most of the way to a decent end-product, while being cheaper and faster to boot. For me, it's an interesting conclusion. For use cases where speed and efficiency are key, SimpleRAG is the sensible choice. For use cases where every last drop of performance needs squeezing out, the techniques incorporated into AdvancedRAG may offer a way forward.
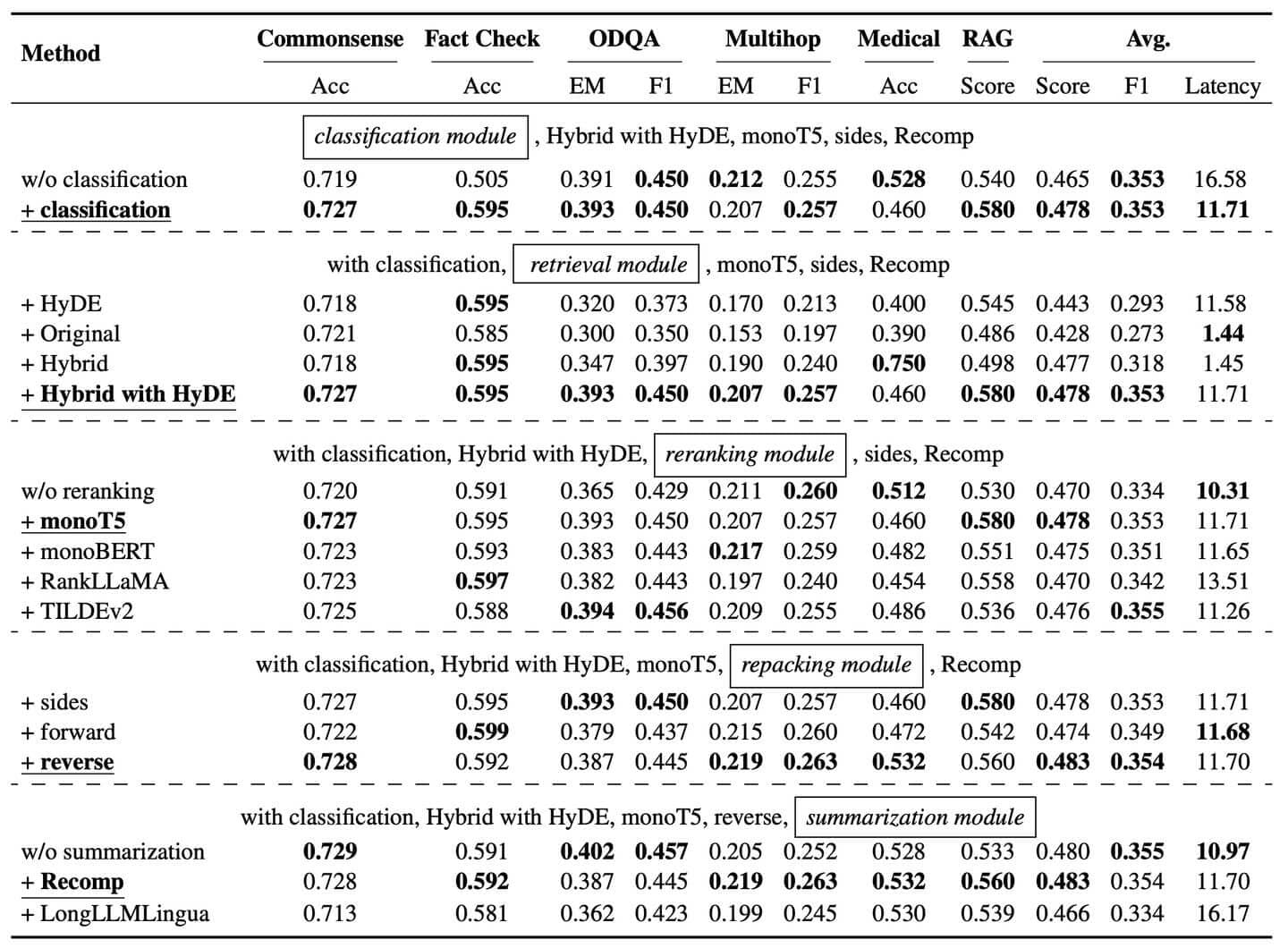
Results of the study by Wang et al reveal that the use of advanced techniques creates consistents but incremental improvements.
Appendix
Prompts
RAG question answering prompt
Prompt for getting the LLM to generate answers based on query and context.
Elastic query generator prompt
Prompt for enriching queries with synonyms and converting them into the OR format.
Potential questions generator prompt
Prompt for generating potential questions, enriching document metadata.
HyDE generator prompt
Prompt for generating hypothetical documents using HyDE
Sample hybrid search query
Related Content

February 18, 2026
Better text analysis for complex languages with Elasticsearch and neural models
Using neural models and the Elasticsearch inference API to improve search in Hebrew, German, Arabic, and other morphologically complex languages.

February 16, 2026
Elasticsearch 9.3 adds bfloat16 vector support
Exploring the new Elasticsearch element_type: bfloat16, which can halve your vector data storage.

February 10, 2026
How to defend your RAG system from context poisoning
How context engineering techniques prevent context poisoning in LLM responses.

February 12, 2026
Entity resolution with Elasticsearch & LLMs, Part 1: Preparing for intelligent entity matching
Learn what entity resolution is and how to prepare both sides of the entity resolution equation: your watch list and the articles you want to search.
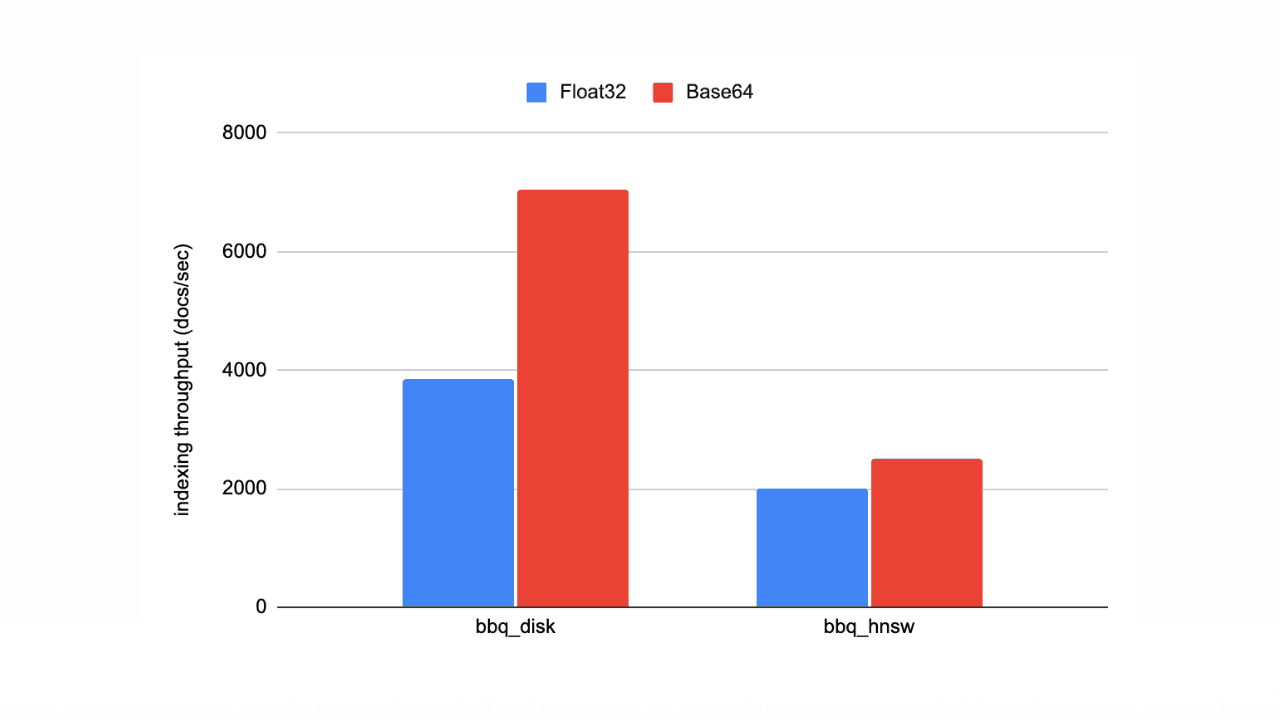
February 4, 2026
Speed up vector ingestion using Base64-encoded strings
Introducing Base64-encoded strings to speed up vector ingestion in Elasticsearch.