From vector search to powerful REST APIs, Elasticsearch offers developers the most extensive search toolkit. Dive into our sample notebooks in the Elasticsearch Labs repo to try something new. You can also start your free trial or run Elasticsearch locally today.
We have been progressively making vector search with Elasticsearch and Lucene faster and more affordable. Our main focuses have been not only improving the search speeds through SIMD, but also by reducting the cost through scalar quantization. First by 4x and then by 8x. However, this is still not enough. Through techniques like Product Quantization (referred to as PQ), 32x reductions can be achieved without significant costs in recall. We need to achieve higher levels of quantization to provide adequate tradeoffs for speed and cost.
One way to achieve this is by focusing on PQ. Another is simply improving on binary quantization. Spoilers:
- BBQ is 10-50x faster at quantizing vectors than PQ
- BBQ is 2-4x faster at querying than PQ
- BBQ achieves the same or better recall than PQ
So, what exactly did we test and how did it turn out?
What exactly are we going to test?
Both PQ and Better Binary Quantization have various pros vs. cons on paper. But we needed a static set of criteria from which to test both. Having an independent "pros & cons" list is too qualitative a measurement. Of course things have different benefits, but we want a quantitative set of criteria to aid our decision making. This is following a pattern similar to the decision making matrix explained by Rich Hickey.
Our criteria were:
- Search speed
- Indexing speed flat
- Indexing speed with HNSW
- Merge speed
- Memory reduction possible
- Is the algorithm well known and battle tested in production environments?
- Is coarse grained clustering absolutely necessary? Or, how does this algorithm fair with just one centroid
- Brute-force oversampling required to achieve 95% recall
- HNSW indexing still works and can acheive +90% recall with similar reranking to brute-force
Obviously, almost all the criteria were measurable, we did have a single qualitative criteria that we thought important to include. For future supportability, being a well known algorithm is important and if all other measures were tied, this could be the tipping point in the decision.
How did we test it?
Lucene and Elasticsearch are both written in Java, consequently we wrote two proof of concepts in Java directly. This way we get an apples-to-apples comparison on performance. Additionally, when doing Product Quantization, we only tested up to 32x reduction in space. While PQ does support further reduction in space by reducing the number of code books, we found that for many models recall quickly became unacceptable. Thus requiring much higher levels of oversampling. Additionally, we did not use Optimized PQ due to the compute constraints required for such a technique.
We tested over different datasets and similarity metrics. In particular:
- e5Small, which only has 384 dimensions and whose vector space is fairly narrow compared to other models. You can see how poorly e5small with naive binary quantization performs in our bit vectors blog. Consequently, we wanted to ensure an evolution of binary quantization could handle such a model.
- Cohere's v3 model, which has 1024 dimensions and loves being quantized. If a quantization method doesn't work with this one, it probably won't work with any model.
- Cohere's v2 model, which has 768 dimensions and its impressive performance relies on the non-euclidean vector space of max-inner product. We wanted to ensure that it could handle non-euclidean spaces just as well as Product Quantization.
We did testing locally on ARM based macbooks & remotely on larger x86 machines to make sure any performance differences we discovered were repeatable no matter the CPU architecture.
Well, what were the results?
e5small quora
This was a smaller dataset, 522k vectors built using e5small. Its few dimensions and narrow embedding space make it prohibitive to use with naive binary quantization. Since BBQ is an evolution of binary quantization, verifying that it worked with such an adverse model in comparison with PQ was important.
Testing on an M1 Max ARM laptop:
| Algorithm | quantization build time (ms) | brute-force latency (ms) | brute-force recall @ 10:50 | hnsw build time (ms) | hnsw recall @ 10:100 | hnsw latency (ms) |
|---|---|---|---|---|---|---|
| BBQ | 1041 | 11 | 99% | 104817 | 96% | 0.25 |
| Product Quantization | 59397 | 20 | 99% | 239660 | 96% | 0.45 |
CohereV3
This model excels at quantization. We wanted to do a larger number of vectors (30M) in a single coarse grained centroid to ensure our smaller scale results actually translate to higher number of vectors.
This testing was on a larger x86 machine in google cloud:
| Algorithm | quantization build time (ms) | brute-force latency (ms) | brute-force recall @ 10:50 | hnsw build time (ms) | hnsw recall @ 10:100 | hnsw latency (ms) |
|---|---|---|---|---|---|---|
| BBQ | 998363 | 1776 | 98% | 40043229 | 90% | 0.6 |
| Product Quantization | 13116553 | 5790 | 98% | N/A | N/A | N/A |
When it comes to index and search speed at similar recall, BBQ is a clear winner.
Inner-product search and BBQ
We have noticed in other experiments that non-euclidean search can be tricky to get correct when quantizing. Additionally, naive binary quantization doesn't care about vector magnitude, vital for inner-product.
Well, footnote in hand, we spent a couple of days on the algebra as we needed to adjust the corrective measures applied at the end of the query estimation. Success!
| Algorithm | recall 10:10 | recall 10:20 | recall 10:30 | recall 10:40 | recall 10:50 | recall 10:100 |
|---|---|---|---|---|---|---|
| BBQ | 71% | 87% | 93% | 95% | 96% | 99% |
| Product Quantization | 65% | 84% | 90% | 93% | 95% | 98% |
That wraps it up
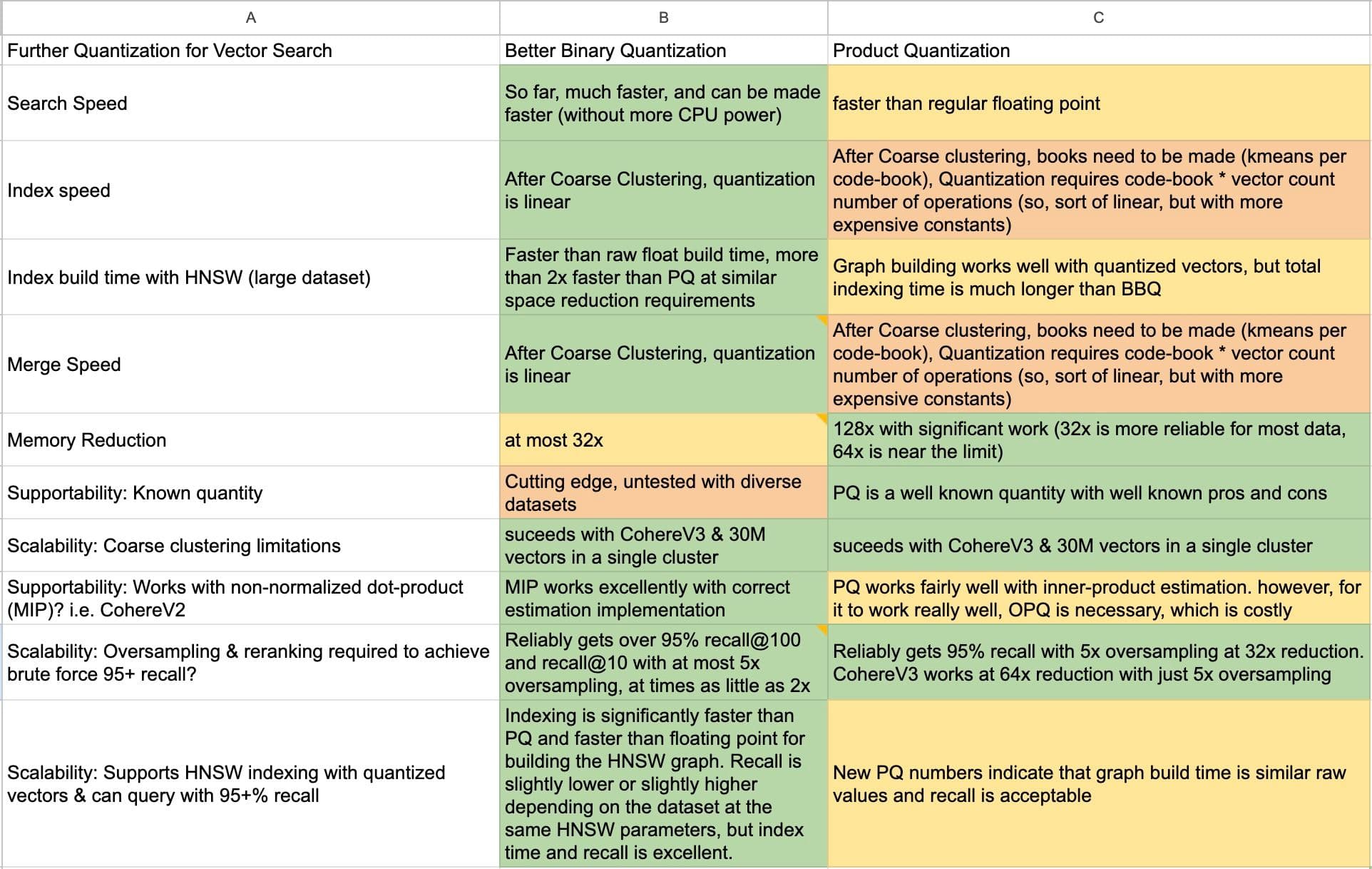
The complete decision matrix for BBQ vs Product Quantization.
We are pretty excited about Better Binary Quantization (BBQ). We have been hard at work kicking the tires and are continually surprised at the quality of results we get with just a single bit of information retained per vector dimension.
Look for it coming in an Elasticsearch release near you!
Related Content
March 2, 2026
Adaptive early termination for HNSW in Elasticsearch
Introducing a new adaptive early termination strategy for HNSW in Elasticsearch.
February 25, 2026
Elasticsearch vector search is up to 8x faster than OpenSearch
Exploring filtered vector search benchmarks of OpenSearch vs. Elasticsearch and why vector search performance is critical for context-engineered systems.

February 16, 2026
Elasticsearch 9.3 adds bfloat16 vector support
Exploring the new Elasticsearch element_type: bfloat16, which can halve your vector data storage.

February 10, 2026
How to defend your RAG system from context poisoning
How context engineering techniques prevent context poisoning in LLM responses.
February 4, 2026
Speed up vector ingestion using Base64-encoded strings
Introducing Base64-encoded strings to speed up vector ingestion in Elasticsearch.