Elasticsearch is packed with new features to help you build the best search solutions for your use case. Learn how to put them into action in our hands-on webinar on building a modern Search AI experience. You can also start a free cloud trial or try Elastic on your local machine now.
In this blog post we'll take another deep dive with retrievers. We've already talked about them in previous blogs from their very introduction to semantic reranking using retrievers. Now, we're happy to announce that retrievers are becoming generally available with Elasticsearch 8.16.0, and in this blog post we'll take a technical tour on how we implemented them, as well as we'll get the chance to discuss the newly available capabilities!
Elasticsearch retriever
The main concept of a retriever remains the same as with their initial release; retrievers is a framework that provides the basic building blocks that can be stacked hierarchically to build multi-stage complex retrieval and ranking pipelines. E.g. of a simple standard retriever, which just bring backs all documents:
Pretty straightforward, right? In addition to the standard retriever, which is essentially just a wrapper around the standard query search API element, we also support the following types:
knn- return the top documents from a kNN (k Nearest Neighbor) searchrrf- combine results from different retrievers based on the RRF (Reciprocal Rank Fusion) ranking formulatext_similarity_reranker- rerank the top results of a nested retriever using areranktype inference endpoint
More detailed information along with the specific parameters for each retriever can also be found in the Elasticsearch documentation.
Let's briefly go through some of the technical details first, which will help us understand the architecture and what has changed and why all these previous limitations have now been lifted!
Technical drill down of retrievers
One of the most important (and requested) things that we wanted to address was the ability to use any retriever, at any nesting level. Whether this means having 2 or more text_similarity_reranker stacked together, or an rrf retriever operating on top of another rrf along with a text_similarity_reranker, or any combination and nesting you can think of, we wanted to make sure that this would be something one could express with retrievers!
To account for this, we have introduced some significant changes to the retriever execution plan. Up until now, retrievers were evaluated as part of the standard search execution flow, where (in a simplified scenario for illustration purposes) we reach out to the shards twice:
- once for querying the shards and bringing back
from + sizedocuments from each shard, and - once for fetching all field data and perform any additional operations (e.g. highlighting) for the true top
[from, from+size]results.
This is a nice linear execution flow that is (relatively) easy to follow, but introduces some significant limitations if we want to execute multiple queries, operate on different results sets, etc. In order to work around this, we have moved to an eager evaluation of all sub-retrievers of a retriever pipeline at the very early stages of query execution. This means that, if needed, we are recursively rewriting any retriever query to a simpler form, the specifics of which depend on the retriever type.
- For non-compound retrievers we rewrite similar to how we do in a standard query, as they could still follow the linear execution plan.
- For compound retrievers, i.e. for retrievers that operate on top of other retriever(s), we flatten them to a single
rank_window_sizeresult set, which is essentially a<doc, shard>tuple list that represents the top ranked documents for this retriever.
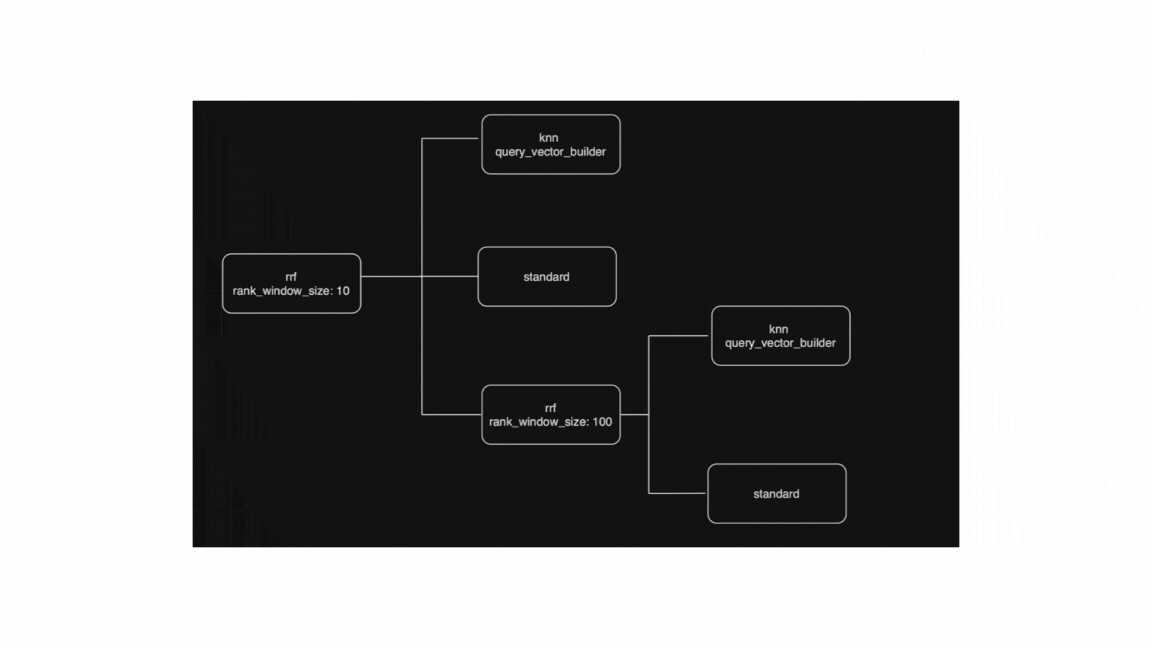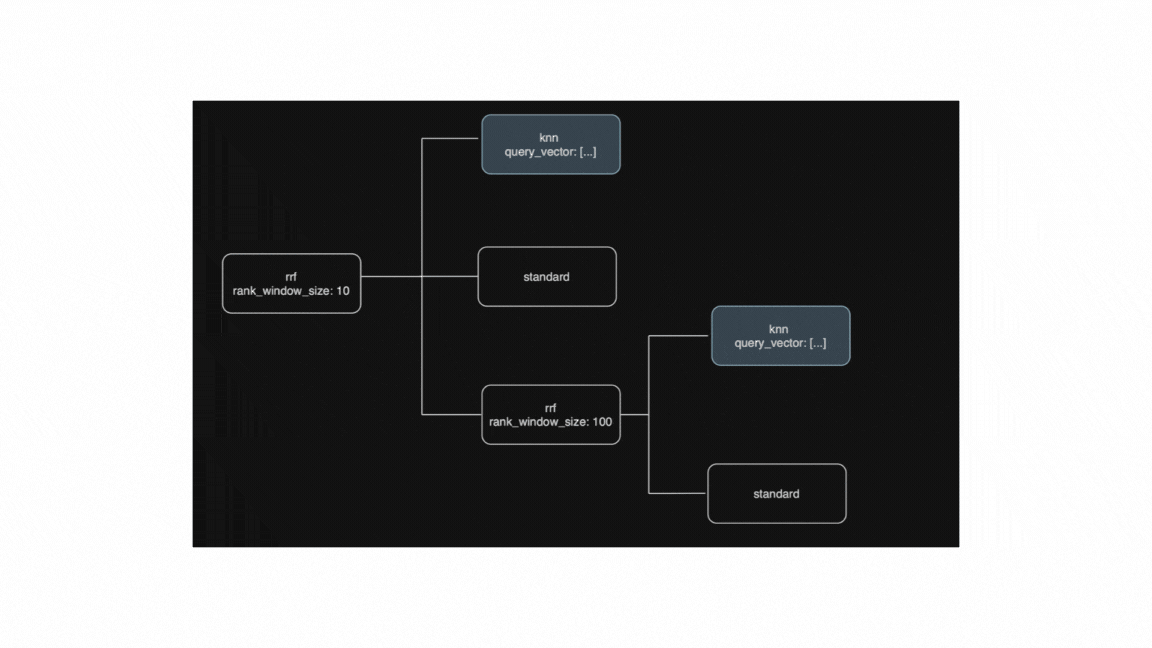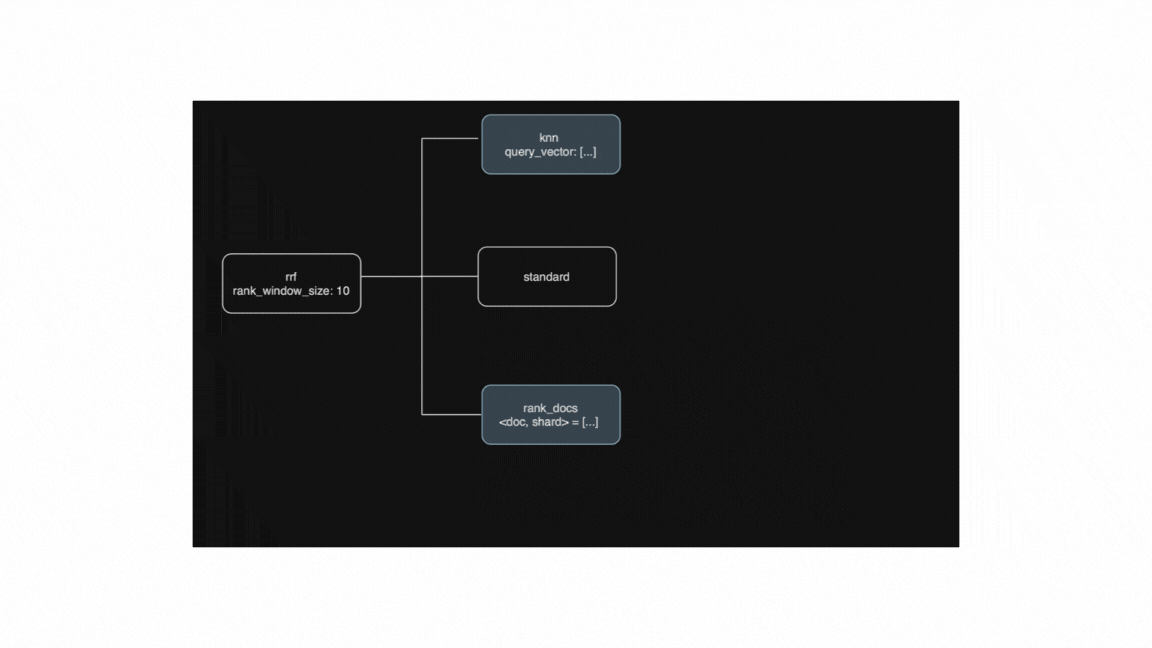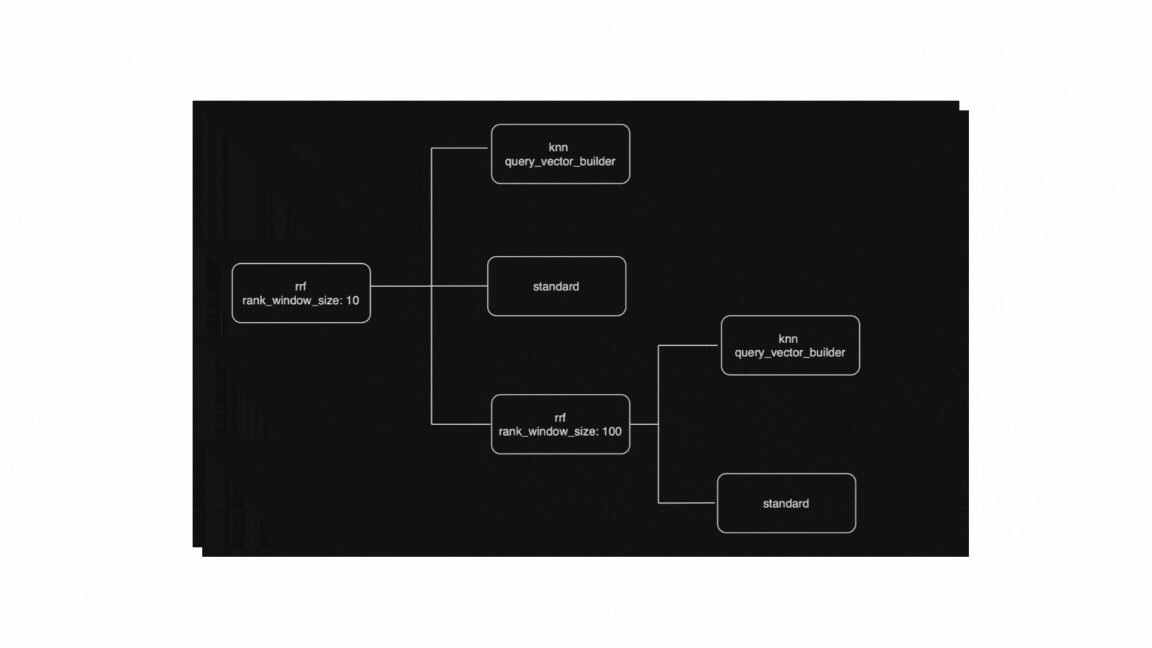
Let's see what this actually looks like, by working through the following (rather complex) retriever request:
The rrf retriever above is a compound one, as it operates on the results of some other retrievers, so we'll try to rewrite it to a simpler, flattened, list of <doc, shard> tuples, where each tuple specifies a document and the shard that it was found on. This rewrite will also enforce a strict ranking, so no different sort options are currently supported.
Let's proceed now to identify all components and describe the process of how this will be evaluated:
[1] top level rrf retriever; this is the parent of all sub-retrievers which will be rewritten and evaluated last, as we'd first need to know the top 10 (based on rank_window_size) results from each of its sub-retrievers.
[2] This knn retriever is the first child of the top level rrf retriever and uses an embedding service (my-text-embedding-model) to compute the actual query vector that will be used. This will be rewritten as the usual knn query by making an async request to the embedding service to compute the vector for the given model_text.
[3] A standard retriever that is also part of the top-level's rrf retriever's children, which returns all documents matching topic: science query.
[4] Last child of the top-level rrf retriever which is also an rrf retrievers that needs to be flattened.
[5] [6] similar to [2] and [3], these are retrievers that are direct children of an rrf retriever, for which we will fetch the top 100 results (based on the rrf retriever's rank_window_size [4]) for each one, combine them using the rrf formula, and then rewrite to a flattened <doc, shard> list of the true top 100 results.
The updated execution flow for retrievers is now as follows:
- We'll start by rewriting all leaves that we can. This means that we'll rewrite the
knnretrievers [2] and [6] to compute the query vector, and once we have that we can move up one level in the tree. - At the next rewrite step, we are now ready to evaluate the nested
rrfretriever [4], which we will eventually rewrite to a flattenedRankDocsQueryquery (i.e. a list of<doc, shard>tuples). - Finally, all inner rewritten steps for the top-level
rrfretriever [1] will have taken place, so we should be ready to combine and rank the true top 10 results as requested. Even this top-levelrrfretriever will rewrite itself to a flattenedRankDocsQuerywhich will be later used to proceed with the standard linear search execution flow.
Visualizing all the above, we have:
Looking at the example above, we can see how a hierarchical retriever tree is asynchronously rewritten to just a simple RankDocsQuery. This simplification gives us the nice (and desired!) side effect of eventually executing a normal request with explicit ranking, and in addition to that we can also perform any complementary operations we choose.
Playing with the (golden) retrievers!
As we briefly mentioned above, with the rework in place, we can now support a plethora of additional search features! In this section we'll go through some examples and use-cases, but more can also be found in the documentation.
We'll start with the most coveted one which is composability, i.e. the option to have any retriever at any level of the retriever tree.
Composability
In the following example, we want to perform a semantic query (using an embedding service like ELSER), and then merge those results along with a knn query, using rrf. Finally, we'd want to rerank those using the text_similarity_reranker retriever using a reranker. The retriever to express the above would look like this:
Aggregations
Recall that with the rework we discussed, we rewrite a compound retriever to just a RankDocsQuery (i.e. a flattened explicitly ranked result list). This however does not block us from computing aggregations, as we also keep track of the source queries that were part of a compound retriever. This means that we can fallback to the nested standard retrievers below, to properly compute aggregations for the topic field, based on the union of the results of the two nested retrievers.
So in the example above, we'll compute a term aggregation for the topic field, where either the year field is greater than 2023, or the document has the topic elastic associated with it.
Collapsing
In addition to the aggregation option we discussed above, we can now also collapse results, as we'd do with a standard query request. In the following example, we compute the top 10 results of the rrf retriever, and then collapse them under the year field. The main difference with standard searches is that here we're collapsing just the top rank_window_size results, and not the ones within the nested retrievers.
Pagination
As is also specified in the docs compound retrievers also support pagination. There is a significant difference with standard queries where, similarly to collapse above, the rank_window_size parameter is the whole result set upon which we can perform navigation. This means that if from + size > rank_window_size then we would bring no results back (but we'd still return aggregations).
In the example above, we would compute the top 10 results (as defined in rrf's rank_window_size) from the combination of the two nested retrievers (standard and knn) and then we'd perform pagination by consulting the from and size parameters. So, in this case, we'd skip the first 2 results (from) and pick the next 2 (size).
Consider now a different scenario, where, in the same query above, we would instead have from: 10 and size: 2. Given that rank_window_size is 10, and that these would be all the results that we can paginate upon, requesting to get 2 results after skipping the first 10 would fall outside of the navigatable result set, so we'd get back empty results. Additional examples and a more detailed break-down can also be found in the documentation for the rrf retriever.
Explain
We know that with great power comes great responsibility. Given that we can now combine retrievers in arbitrary ways, it could be rather difficult to understand why a result was eventually returned first, and how to optimize our retrieval strategy. For this very specific reason, we have worked to ensure that the explain output of a retriever request (i.e. by specifying explain: true) will convey all necessary information from all sub-retrievers, so that we can have a proper understanding of all the factors that contributed to the final ranking of a result. Taking the rather complex query in the Collapsing section, the explain for the first result looks like this:
Still a bit verbose, but it conveys all necessary information on why a document is at a specific position. For the top-level rrf retriever, we have 2 details specified, one for each of its nested retrievers. The first one is a text_similarity_reranker retriever, where we can see on explain the weight for the rerank operation, and the second one is a knn query informing us of the doc's computed similarity with the query vector. It might take a bit to familiarize with, but each retriever ensures to output all the information you might need to evaluate and optimize your search scenario!
Conclusion
That's all for now! We hope you stayed with us until now and you enjoyed this topic! We're really excited with the release of the retriever framework and all the new use-cases that we can now support! Retrievers were built in order to support from very simple searches, to advanced RAG and hybrid search scenarios! As mentioned above, watch this space and more will be available soon!
Frequently Asked Questions
What are retrievers in Elasticsearch?
Retrievers are a new abstraction layer added to the Search API in Elasticsearch that is now generally available. They offer the convenience of configuring multi-stage retrieval pipelines within a single `_search` API call.
What queries can I generate with retrievers?
All base queries are accessible through the use of the `standard` retriever. In addition to that, one can use more fine-grained retrievers like `knn`, `rrf`, and `text_similarity_reranker` to either produce a set of results, or combine/rerank the results of another retriever.
Related Content

March 5, 2026
Does MCP make search obsolete? Not even close
Explore why search engines and indexed search remain the foundation for scalable, accurate, enterprise-grade AI, even in the age of MCP, federated search, and large context windows.

February 20, 2026
Ensuring semantic precision with minimum score
Improve semantic precision by employing minimum score thresholds. The article includes concrete examples for semantic and hybrid search.

February 17, 2026
An open‑source Hebrew analyzer for Elasticsearch lemmatization
An open-source Elasticsearch 9.x analyzer plugin that improves Hebrew search by lemmatizing tokens in the analysis chain for better recall across Hebrew morphology.
January 30, 2026
Query rewriting strategies for LLMs and search engines to improve results
Exploring query rewriting strategies and explaining how to use the LLM's output to boost the original query's results and maximize search relevance and recall.

All about those chunks, ’bout those chunks, and snippets!
Exploring chunking and snippet extraction for LLMs, highlighting enhancements for identifying the most relevant chunks and snippets to send to models such as rerankers and LLMs.