From vector search to powerful REST APIs, Elasticsearch offers developers the most extensive search toolkit. Dive into our sample notebooks in the Elasticsearch Labs repo to try something new. You can also start your free trial or run Elasticsearch locally today.
Sparse vector queries take advantage of Elasticsearch’s powerful inference API, allowing easy built-in setup for Elastic-hosted models such as ELSER and E5, as well as the flexibility to host other models.
Background
Vector search is evolving, and as our needs for vector search evolve so does the need for a consistent and forward thinking vector search API.
When Elastic first launched semantic search, we leveraged existing rank_features fields using the text_expansion query. We then reintroduced the sparse_vector field type for semantic search use cases.
As we think about what sparse vector search is going forward, we’ve introduced a new sparse vector query. As of Elasticsearch 8.15.0, both the text_expansion query and weighted_tokens query have been deprecated in favor of the new sparse vector query.
The sparse vector query supports two modes of querying: using an inference ID and using precomputed query vectors. Both modes of querying require data to be indexed in a sparse_vector mapped field.
These token-weight pairs are then used in a query against a sparse vector. At query time, query vectors are calculated using the same inference model that was used to create the tokens.
Let’s look at an example: let’s say we’ve indexed a document detailing when Orion is most visible in the night sky:
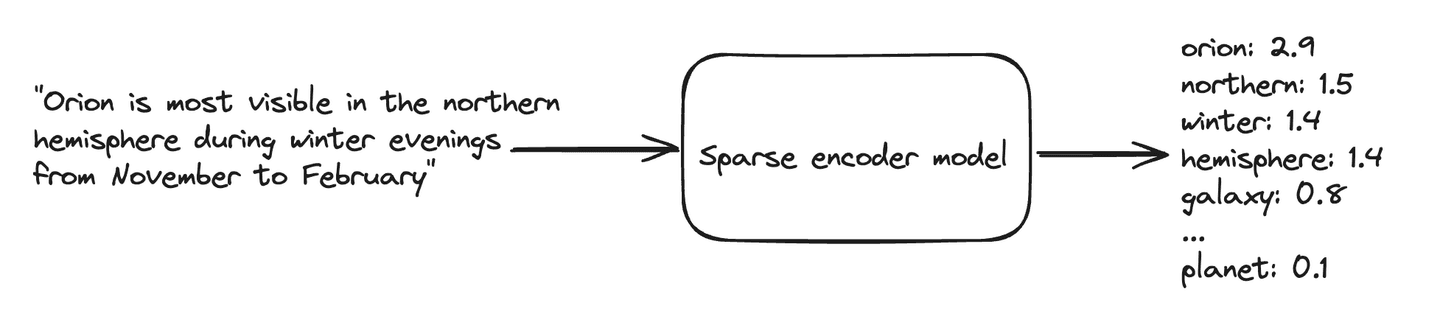
Now, assume we’re looking for constellations that are visible in the northern hemisphere, and we run this query through the same learned sparse encoder model. The output might look similar to this:
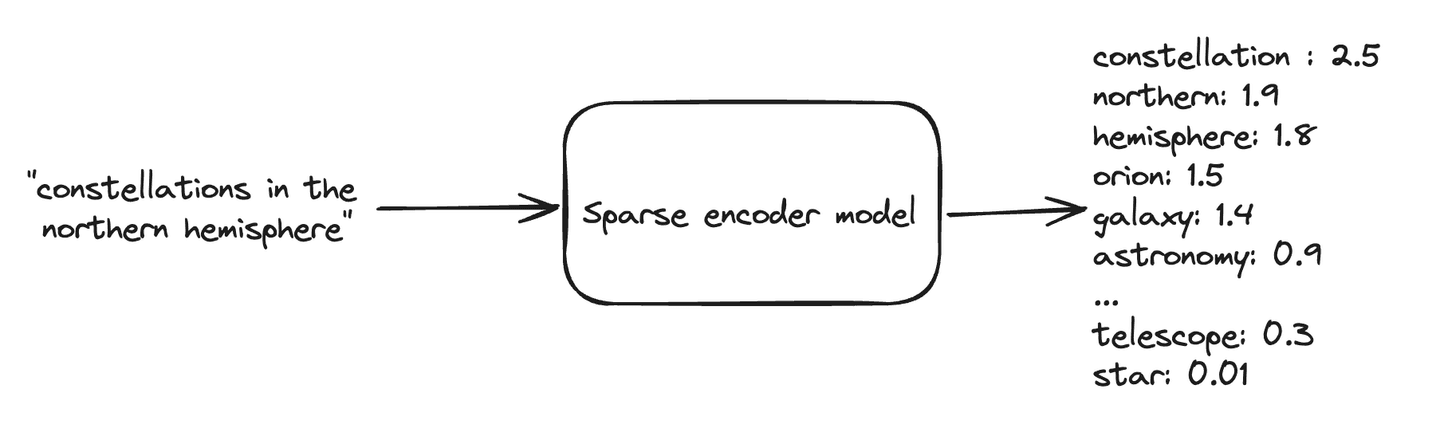
At query time, these vectors are ORed together, and scoring is effectively a dot product calculation between the stored dimensions and the query dimensions, which would score this example at 10.84:
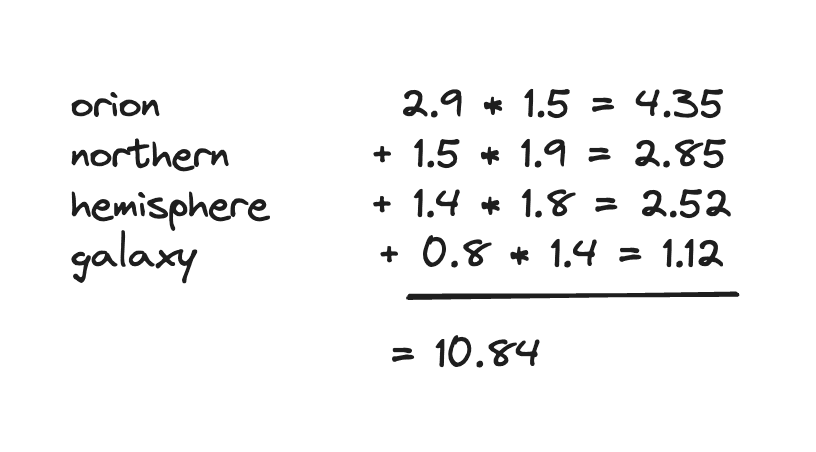
Sparse vector queries with inference
Sparse vector queries using inference work in a very similar way to the previous text expansion query, instead of sending in a trained model, we create an inference endpoint associated with the model we want to use.
Here’s an example of how to create an inference endpoint for ELSER:
You should use an inference endpoint to index your sparse vector data, and use the same endpoint as input to your sparse_vector query. For example:
Sparse vector queries with precomputed query vectors
You may have precomputed vectors that don’t require inference at query time. These can be sent into the sparse_vector query instead of using inference. Here is an example:
Query optimization with token pruning
Like text expansion search, the sparse vector query is subject to performance penalties from huge boolean queries. Therefore the same token pruning strategies available for text expansion strategies are available in the sparse vector query. You can see the impact of token pruning in our nightly MS Marco Passage Ranking benchmarks.
In order to enable pruning with the default pruning configuration (which has been tuned for ELSER V2), simply add prune: true to your request:
Alternately, you can adjust the pruning configuration by sending it directly in with the request:
Because token pruning will incur a recall penalty, we recommend adding the pruned tokens back in a rescore:
What's next?
While the text_expansion query is GA’d and will be supported throughout Elasticsearch 8.x, we recommend updating to the sparse_vector query as soon as possible in order to ensure you’re using the most up to date features as we continually improve the vector search experience in Elasticsearch.
If you are using the weighted_tokens query, this was never GA’d and will be replaced by the sparse_vector query very soon.
The sparse_vector query will be available starting with 8.15.0 and is already available in Serverless - try it out today!
Frequently Asked Questions
What are sparse vector queries in Elasticsearch?
Sparse vector queries take advantage of Elasticsearch’s powerful inference API, allowing easy built-in setup for Elastic-hosted models such as ELSER and E5, as well as the flexibility to host other models.
Related Content

February 16, 2026
Elasticsearch 9.3 adds bfloat16 vector support
Exploring the new Elasticsearch element_type: bfloat16, which can halve your vector data storage.

February 10, 2026
How to defend your RAG system from context poisoning
How context engineering techniques prevent context poisoning in LLM responses.
February 4, 2026
Speed up vector ingestion using Base64-encoded strings
Introducing Base64-encoded strings to speed up vector ingestion in Elasticsearch.

February 5, 2026
ES|QL dense vector search support
Using ES|QL for vector search on your dense_vector data.

January 28, 2026
Apache Lucene 2025 wrap-up
2025 was a stellar year for Apache Lucene; here are our highlights.