From vector search to powerful REST APIs, Elasticsearch offers developers the most extensive search toolkit. Dive into our sample notebooks in the Elasticsearch Labs repo to try something new. You can also start your free trial or run Elasticsearch locally today.
Implementing semantic search for the e-commerce use case can be tricky since product formatting is far from standardized. In this blog, we tackle this challenge by using query profiles in Elastic - a method that takes multiple metadata fields and transforms them into a piece of text that resembles a user's preferences and requests. Through a practical example, we demonstrate how query profiles can improve e-commerce search.
Introduction to e-commerce & Elasticsearch
Elasticsearch is naturally suited for e-commerce data, by which I mean large quantities of product definitions, like this Amazon product dataset. Let's download the sample file, with 10,000 products, and upload the CSV to an Elastic index (I'm using my Elastic Cloud Deployment) called amazon_product_10k.
When we look at the data, we see product descriptions like this one, about a superhero themed bobblehead for a character called Black Lightning:
A search use-case here involves the user looking for a product, making with a request like:
For enthusiasts of semantic search, there is an immediate problem. The main source of searchable text is the product description, which looks like this:
Which tells us nothing about the product. A naive approach might be to choose an embedding model, embed the description and then do semantic search over it. This particular product would never appear for a query like "Superhero bobbleheads", regardless of the choice of embedding. Let's try this and see what happens.
Naive semantic search
Go ahead and deploy elser_v2 with this command (Make sure ML node autoscaling is enabled):
And let's define a new index called amazon_product_10k_plain_embed, define the product description as a semantic_text type using our elser_v2 inference endpoint, and run a reindex:
And run a semantic search:
Behold. The product_names we get back are pretty bad.
Corgi is not a superhero despite being a bobblehead. The Sons of Anarchy are not superheroes, they are motorcycle enthusiasts, and a Funko Pop is certainly not a bobblehead. So why are the results so awful?
The required information is actually in the category and technical_details fields:
Second problem, only the category tells us that this product is a bobblehead, and only the technical_details field tells us that this is superhero related. So the next naive thing to do is embed all three fields, then do a vector search over all three, and hope that the average score will place this product near the top of the results.
Other than the obvious tripling of compute and storage cost, we're also taking a leap of faith that the resulting trio of embeddings will not be noisy, because the product description is very irrelevant, and the category and technical_details each only contain one word relevant to the search query.
Naive semantic search even harder
Let's just try it anyway and see what happens. Let's embed the three fields:
And run another search using retrievers with Elastic's built-in reciprocal rank fusion.
Behold, the results are actually worse than before:
I have a colleague who would probably really enjoy Bob from Bob's Burgers coming out as top result for superhero merchandise @Jeff Vestal.
So what now?
HyDE
Here's a thought. Let's use an LLM to improve the quality of our data, and make vector search a little bit more effective. There is a technique called HyDE. The proposal is pretty intuitive. The query contains key content, namely the keywords "Superhero" and "Bobblehead". However, it does not capture the form and structure of the documents we are actually searching over. In other words, search queries do not resemble indexed documents in form, though they may have shared content. So with both keyword and semantic search, we match content to content, but we do not match form to form.
HyDE uses an LLM to transform queries into hypothetical documents, which capture relevance patterns but do not contain actual real content that would answer the query. The hypothetical document is then embedded and used for vector search. In short, we match form with form, as well as content with content.
Let's modify the idea a little bit for e-Commerce.
Query profiles
What I call query profiles is really about taking multiple metadata fields, and transforming them into a piece of text that resembles a user's preferences and likely requests. This Query Profile is then embedded, and subsequent vector searches are done on it. The LLM is instructed to create a document that mimics what a user might ask for when searching for a product. The flow looks like this:
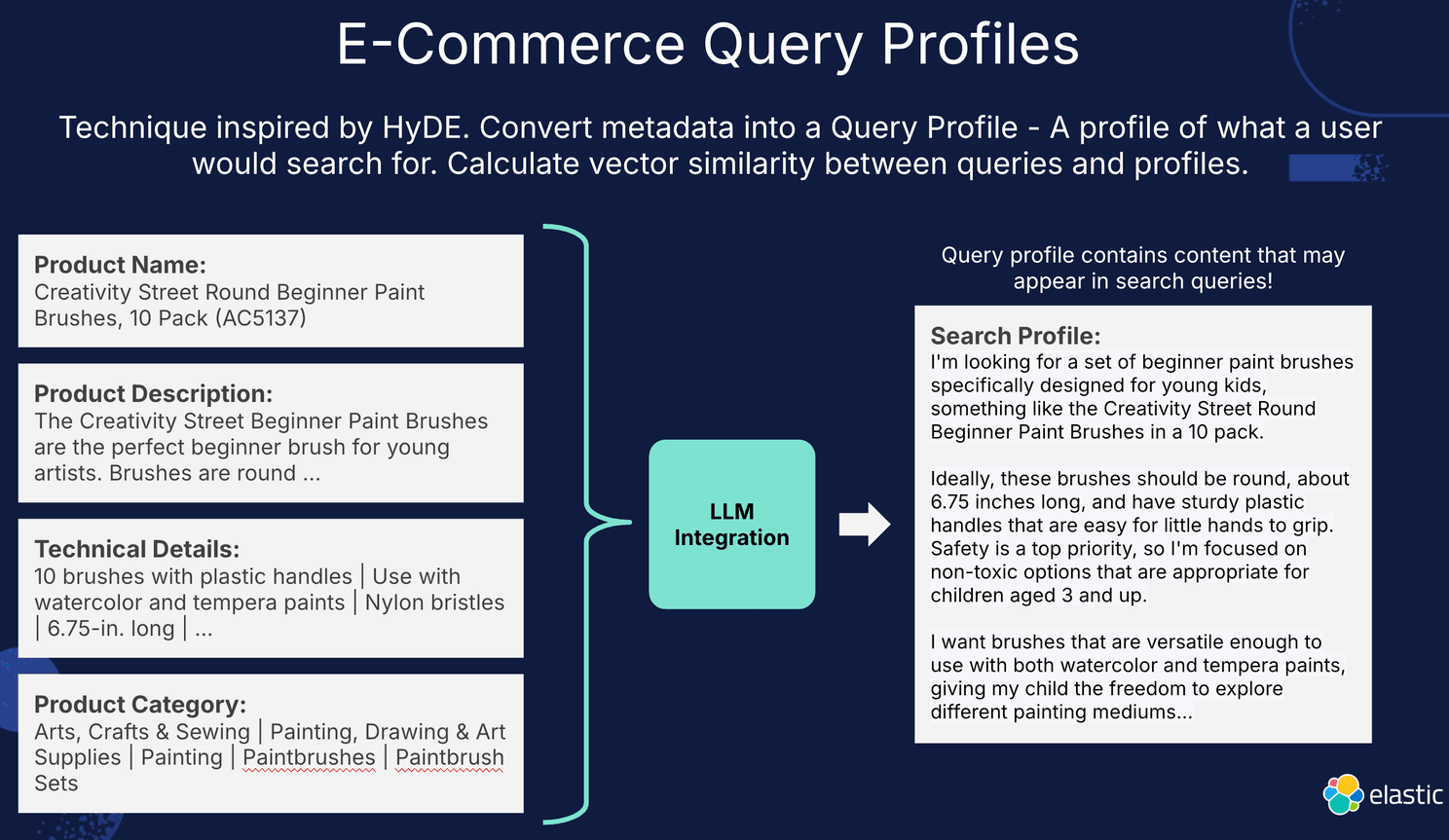
I think that there are two main advantages to this method:
- Consolidate information from multiple fields into a single document.
- Capture the likely forms of a user's request, and covering as many bases as possible when doing so.
The resulting text is information rich and might give us better results when searched over. Let's implement it and see what happens.
Implementing query profiles for e-commerce search
We will define a pipeline in Elasticsearch with an LLM processor. I'm going to make use of GPT-4o mini from my company's Azure OpenAI deployment, so let's define the inference endpoint like so:
Now, let's define an ingest pipeline containing the query profile prompt.
We'll run a reindex to create the new field with our LLM integration:
And once it's done, we'll define another index with the query profiles set to semantic_text, and run embedding with Elser. I like to split up the processing into two stages, so I can hang on to the fruits of LLM's labor separately from the embeddings. Call this insurance against an act of God.
Let's now run the same query again, this time using semantic search over the query profiles, and see what we get:
The results are quite a bit better, actually.
Okay, result number 3 is a potato head. Fine. But 1 and 2 are actual superhero bobble heads, so I'm going to take this as a win.
Conclusion
Implementing semantic search for an e-Commerce use-case brings unique challenges. The distributed nature of it means that product formatting is far from standardized. As such, embedding specific fields and trying to do semantic search isn't going to work as well as it does for searching articles or other "full" texts.
By using an LLM to create a Query Profile, we can create a piece of text that merges information from multiple fields and simultaneously captures what a user is likely to search for.
By doing this, we change the e-Commerce search problem so that it resembles a typical knowledge base search, which is a problem statement where semantic search performs quite well.
I think this provides a pathway to bringing traditional search use-cases with structured or tabular data into the Semantic/LLM-era, and that's pretty cool.
Frequently Asked Questions
How to improve e-commerce search?
E-commerce search can be improved by using query profiles in Elastic as they tackle semantic search challenges.
Related Content

February 18, 2026
Better text analysis for complex languages with Elasticsearch and neural models
Using neural models and the Elasticsearch inference API to improve search in Hebrew, German, Arabic, and other morphologically complex languages.

February 16, 2026
Elasticsearch 9.3 adds bfloat16 vector support
Exploring the new Elasticsearch element_type: bfloat16, which can halve your vector data storage.

February 10, 2026
How to defend your RAG system from context poisoning
How context engineering techniques prevent context poisoning in LLM responses.

February 12, 2026
Entity resolution with Elasticsearch & LLMs, Part 1: Preparing for intelligent entity matching
Learn what entity resolution is and how to prepare both sides of the entity resolution equation: your watch list and the articles you want to search.
February 4, 2026
Speed up vector ingestion using Base64-encoded strings
Introducing Base64-encoded strings to speed up vector ingestion in Elasticsearch.