From vector search to powerful REST APIs, Elasticsearch offers developers the most extensive search toolkit. Dive into our sample notebooks in the Elasticsearch Labs repo to try something new. You can also start your free trial or run Elasticsearch locally today.
semantic_text - You know, for semantic search!
Do you want to start using semantic search for your data, but focus on your model and results instead of on the technical details? We’ve introduced the semantic_text field type that will take care of the details and infrastructure that you need.
Semantic search is a sophisticated technique designed to enhance the relevance of search results by utilizing machine learning models. Unlike traditional keyword-based search, semantic search focuses on understanding the meaning of words and the context in which they are used. This is achieved through the application of machine learning models that provide a deeper semantic understanding of the text.
These models generate vector embeddings, which are numeric representations capturing the text meaning. These embeddings are stored alongside your document data, enabling vector search techniques that take into account the word meaning and context instead of pure lexical matches.
How to perform semantic search
To perform semantic search, you need to go through the following steps:
- Choose an inference model to create embeddings, both for indexing documents and performing queries.
- Create your index mapping to store the inference results, so they can be efficiently searched afterwards.
- Setting up indexing so inference results are calculated for new documents added to your index.
- Automatically handle long text documents, so search can be accurate and cover the entire document.
- Querying your data to retrieve results.
Configuring semantic search from the ground up can be complex. It requires setting up mappings, ingestion pipelines, and queries tailored to your chosen inference model. Each step offers opportunities for fine-tuning and optimization, but also demands careful configuration to ensure all components work together seamlessly.
While this offers a great degree of control, it makes using semantic search a detailed and deliberate process, requiring you to configure separate pieces that are all related to each other and to the inference model.
semantic_text simplifies this process by focusing on what matters: the inference model. Once you have selected the inference model, semantic_text will make it easy to start using semantic search by providing sensible defaults, so you can focus on your search and not on how to index, generate, or query your embeddings.
Let's take a look at each of these steps, and how semantic_text simplifies this setup.
Choosing an inference model
The inference model will generate embeddings for your documents and queries. Different models have different tradeoffs in terms of:
- Accuracy and relevance of the results
- Scalability and performance
- Language and multilingual support
- Cost
Elasticsearch supports both internal and external inference services:
- Internal services are deployed in the Elasticsearch cluster. You can use already included models like ELSER and E5, or import external models into the cluster using eland.
- External services are deployed by model providers. Elasticsearch supports the following:
- Cohere
- Hugging Face
- Mistral
- OpenAI
- Azure AI Studio
- Azure OpenAI
- Google AI Studio
Once you have chosen the inference mode, create an inference endpoint for it. The inference endpoint identifier will be the only configuration detail that you will need to set up semantic_text.
Creating your index mapping
Elasticsearch will need to index the embeddings generated by the model so they can be efficiently queried later.
Before semantic_text, you needed to understand about the two main field types used for storing embeddings information:
sparse_vector: It indexes sparse vector embeddings, like the ones generated by ELSER. Each embedding consists of pairs of tokens and weights. There is a small number of tokens generated per embedding.dense_vector: It indexes vectors of numbers, which contains the embedding information. A model produces vectors of a fixed size, called the vector dimension.
The field type to use is conditioned by the model you have chosen. If using dense vectors, you will need to configure the field to include the dimension count, the similarity function used to calculate vectors proximity, and storage customizations like quantization or the specific data type used for each element.
Now, if you're using semantic_text, you define a semantic_text field mapping by just specifying the inference endpoint identifier for your model:
That's it. No need for you to define other mapping options, or to understand which field type you need to use.
Setting up indexing
Once your index is ready to store the embeddings, it's time to generate them.
Before semantic_text, to generate embeddings automatically on document ingestion you needed to set up an ingestion pipeline.
Ingestion pipelines are used to automatically enrich or transform documents when ingested into an index, or when explicitly specified as part of the ingestion process.
You need to use the inference processor to generate embeddings for your fields. The processor needs to be configured using:
- The text fields from which to generate the embeddings
- The output fields where the generated embeddings will be added
- Specific inference configuration for text embeddings or sparse embeddings, depending on the model type
With semantic_text, you simply add documents to your index. semantic_text fields will automatically calculate the embeddings using the specified inference endpoint.
This means there's no need to create an inference pipeline to generate the embeddings. Using bulk, index, or update APIs will do that for you automatically:
Inference requests in semantic_text fields are also batched. If you have 10 documents in a bulk API request, and each document contains 2 semantic_text fields, then that request will perform a single inference request with 20 texts to your inference service in one go, instead of making 10 separate inference requests of 2 texts each.
Automatically handling long text passages
Part of the challenge of selecting a model is the number of tokens that the model can generate embeddings for. Models have a limited number of tokens they can process. This is referred to as the model’s context window.
If the text you need to work with is longer than the model’s context window, you may truncate the text and use just part of it to generate embeddings. This is not ideal as you'll lose information; the resulting embeddings will not capture the full context of the input text.
Even if you have a long context window, having a long text means a lot of content will be reduced to a single embedding, making it an inaccurate representation.
Also, returning a long text will be difficult for the users to understand, as they will have to scan the text to check it's what they are looking for. Using smaller snippets would be preferable instead.
Another option is to use chunking to divide long texts into smaller fragments. These smaller chunks are added to each document to provide a better representation of the complete text. You can then use a nested query to search over all the individual fragments and retrieve the documents that contain the best-scoring chunks.
Before semantic_text, chunking was not done out of the box - the inference processor did not support chunking. If you needed to use chunking, you needed to do it before ingesting your documents or use the script processor to perform the chunking in Elasticsearch.
Using semantic_text means that chunking will be done on your behalf when indexing. Long documents will be split into 250-word sections with a 100-word overlap so that each section shares 100 words with the previous section. This overlap ensures continuity and prevents vital contextual information in the input text from being lost by a hard break.
If the model and inference service support batching the chunked inputs are automatically batched together into as few requests as possible, each optimally sized for the Inference Service. The resulting chunks will be stored in a nested object structure so you can check the text contained in each chunk.
Querying your data
Now that the documents and their embeddings are indexed in Elasticsearch, it's time to do some queries!
Before semantic_text, you needed to use a different query depending on the type of embeddings the model generates (dense or sparse). A sparse vector query is needed to query sparse_vector field types, and either a knn search or a knn query can be used to search dense_vector field types.
The query process can be further customized for performance and relevance. For example, sparse vector queries can define token pruning to avoid considering irrelevant tokens. Knn queries can specify the number of candidates to consider and the top k results to be returned from each shard.
You don't need to deal with those details when using semantic_text. You use a single query type to search your documents:
Just include the field and the query text. There’s no need to decide between sparse vector and knn queries, semantic text does this for you.
Compare this with using a specific knn search with all its configuration parameters:
Under the hood: How
To understand how semantic_text works, you can create a semantic_text index and check what happens when you ingest a document. When the first document is ingested, the inference endpoint calculates the embeddings. When indexed, you will notice changes in the index mapping:
Now there is additional information about the model settings. Text embedding models will also include information like the number of dimensions or the similarity function for the model.
You can check the document already includes the embedding results:
The field does not just contain the input text, but also a structure storing the original text, the model settings, and information for each chunk the input text has been divided into.
This structure consists of an object with two elements:
- text: Contains the original input text
- inference: Inference information added by the inference endpoint, that consists of:
- inference_id of the inference endpoint
- model_settings that contain model properties
- chunks: Nested object that contains an element for each chunk that has been created from the input text. Each chunk contains:
- The text for the chunk
- The calculated embeddings for the chunk text
Customizing
semantic_text simplifies semantic search by making default decisions about indexing and querying your data:
- uses
sparse_vectorordense_vectorfield types depending on the inference model type - Automatically defines the number of dimensions and similarity according to the inference results
- Uses
int8_hnswindex type for dense vector field types to leverage scalar quantization. - Uses query defaults. No token pruning is applied for
sparse_vectorqueries, nor customkandnum_candidatesare set for knn queries.
Those are sensible defaults and allow you to quickly and easily start working with semantic search. Over time, you may want to customize your queries and data types to optimize search relevance, index and query performance, and index storage.
Query customization
There are no customization options - yet - for semantic queries. If you want to customize queries against semantic_text fields, you can perform advanced semantic_text search using explicit knn and sparse vector queries.
We're planning to add retrievers support for semantic_text, and adding configuration options to the semantic_text field so they won't be needed at query time. Stay tuned!
Data type customization
If you need deeper customization for the data indexing, you can use the sparse_vector or dense_vector field types. These field types give you full control over how embeddings are generated, indexed, and queried.
You need to create an ingest pipeline with an inference processor to generate the embeddings. This tutorial walks you through the process.
What's next with
We're just getting started with semantic_text! There are quite a few enhancements that we will keep working on, including:
- Better inference error handling
- Customize the chunking strategy
- Hiding embeddings in _source by default, to avoid cluttering the search responses
- Inner hits support, to retrieve the relevant chunks of information for a query
- Filtering and retrievers support
- Kibana support
Try it out!
semantic_textis available on Elasticsearch Serverless now! It will be available soon on Elasticsearch 8.15 version for Elastic Cloud and on Elasticsearch downloads.
If you already have an Elasticsearch serverless cluster, you can see a complete example for testing semantic search using semantic_text in this tutorial, or try it with this notebook.
We'd love to hear about your experience with semantic_text! Let us know what you think in the forums, or open an issue in the GitHub repository. Let's make semantic search easier together!
Frequently Asked Questions
What is semantic search?
Semantic search is a sophisticated technique designed to enhance the relevance of search results by utilizing machine learning models. Unlike traditional keyword-based search, semantic search focuses on understanding the meaning of words and the context in which they are used.
What is semantic_text in semantic search?
semantic_text is a field type that simplifies semantic search by making default decisions about indexing and querying your data.
Related Content
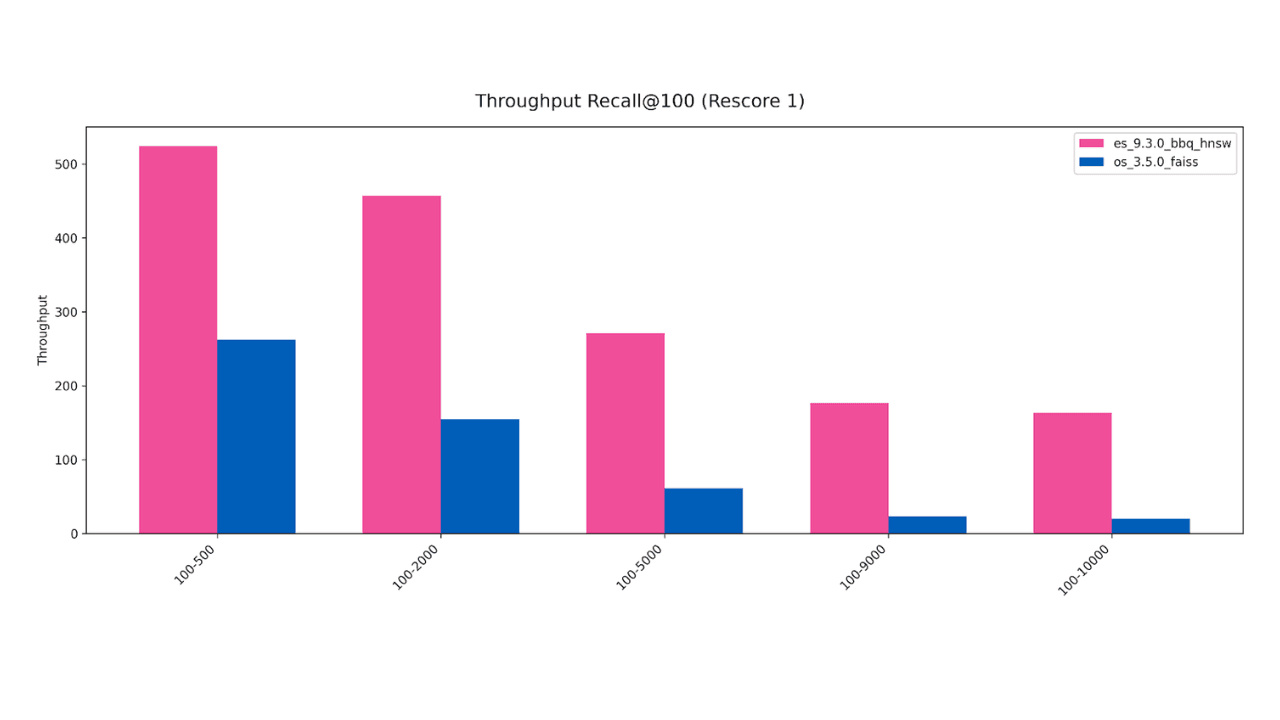
February 25, 2026
Elasticsearch vector search is up to 8x faster than OpenSearch
Exploring filtered vector search benchmarks of OpenSearch vs. Elasticsearch and why vector search performance is critical for context-engineered systems.

February 16, 2026
Elasticsearch 9.3 adds bfloat16 vector support
Exploring the new Elasticsearch element_type: bfloat16, which can halve your vector data storage.

February 10, 2026
How to defend your RAG system from context poisoning
How context engineering techniques prevent context poisoning in LLM responses.
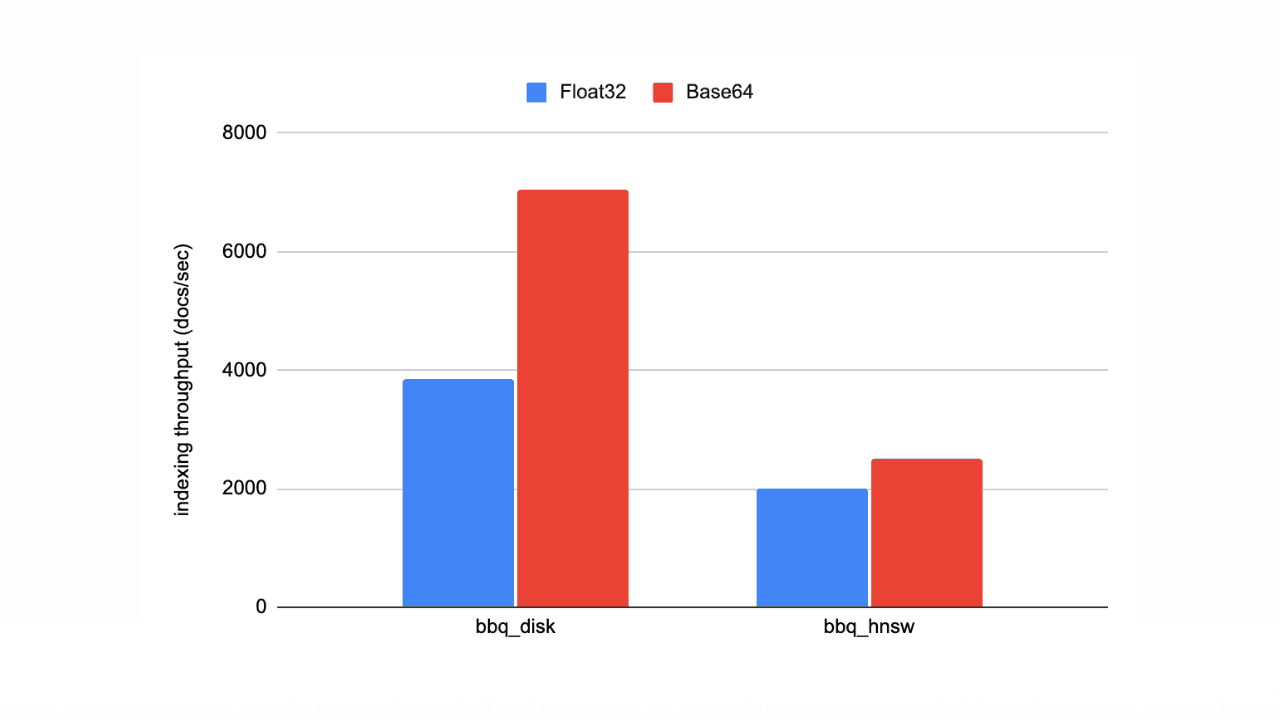
February 4, 2026
Speed up vector ingestion using Base64-encoded strings
Introducing Base64-encoded strings to speed up vector ingestion in Elasticsearch.

February 5, 2026
ES|QL dense vector search support
Using ES|QL for vector search on your dense_vector data.