What is supervised machine learning?
Supervised machine learning definition
Supervised machine learning, or supervised learning, is a type of machine learning (ML) used in artificial intelligence (AI) applications to train algorithms using labeled datasets. By feeding large labeled datasets to an algorithm, supervised machine learning 'teaches' the algorithm to accurately predict outcomes. It is the most commonly used type of machine learning.
Supervised machine learning, like all machine learning, works through pattern recognition. By analyzing a specific set of labeled data, an algorithm can detect patterns and generate predictions based on those derived patterns when queried. To get to an accurate prediction stage, the process of supervised machine learning requires data collection, and then labeling. Then, the algorithm is trained on this labeled data to classify data or predict outcomes accurately. The quality of the output is directly related to the quality of the data: better data means better predictions.
Supervised machine learning examples range from image and object recognition to customer sentiment analysis, spam detection, and predictive analytics. As a result, supervised machine learning is used in several industries such as healthcare, finance, and ecommerce to help optimize decision-making and drive innovation.
How does supervised machine learning work?
Supervised machine learning works by collecting and labeling data, then training models and iterating on the process with new data sets. It's a two-step process: defining the problem that the model is intended to solve, followed by data collection:
- Step 1: Defining the problem that the model is intended to solve. Is the model being used to make business-related predictions, automate spam detection, analyze customer sentiment, or identify images? This determines which data will be required, leading to the next step in the workflow
- Step 2: Collecting the data. Once the data is labeled, it is fed to the algorithm in training. The model is then tested, refined, and deployed to perform classification or regression tasks.
Data collection and labeling
Collecting data is the first step in supervised machine learning. Data can come from various sources such as databases, sensors, or user interactions. It is preprocessed to ensure consistency and relevance. Once collected, this large dataset is assigned labels. Each element of input data receives a corresponding label. While data classification can be time-consuming and expensive, it is necessary to teach the model patterns so it can make predictions. The quality and accuracy of these labels directly impact the model's ability to learn and make relevant predictions. Your output is only as good as your input.
Model training
During training, the algorithm analyzes the input data and learns to map it to the correct output labels. This process involves adjusting the model's parameters to minimize the difference between the predicted outputs and the actual labels. The model improves its accuracy by learning from the errors it makes during training. Once the model has been trained, it is subjected to evaluation. Validation data is used to determine a model’s accuracy. Depending on the results, it is then fine-tuned as needed.
The more data a model absorbs, the more patterns it learns, and the more accurate its predictions become — in theory. Continuous learning is a cornerstone of machine learning: model performance gets better as it keeps learning from labeled datasets.
Once deployed, supervised machine learning can accomplish two types of tasks: classification and regression.
Classification relies on an algorithm to assign a class to a given discrete data point or set. In other words, it distinguishes data categories. In classification problems, the decision boundary establishes classes.
Regression relies on an algorithm to understand the relationship between continuous dependent and independent data variables. In regression problems, the decision boundary establishes the best-fit line or probabilistic closeness.
Supervised machine learning algorithms
Different algorithms and techniques are used in supervised machine learning for classification and regression tasks, ranging from text classification to statistical predictions.
Decision tree
A decision tree algorithm is a non-parametric supervised learning algorithm, made up of a root node, branches, internal nodes, and leaf nodes. Input travels from the root node, through the branches, to the internal nodes where the algorithm processes the input and makes a decision, outputting leaf nodes. Decision trees can be used for both classification and regression tasks. They're helpful data mining and knowledge discovery tools: they let a user track why an output was produced, or why a decision was made. However, decision trees are prone to overfitting; they have difficulty handling more complexity. For this reason, smaller decision trees are more effective.
Linear regression
Linear regression algorithms predict the value of one variable — the dependent variable — based on the value of another — the independent variable. Predictions are based on the principle of a linear relationship between variables, or that there is a 'straight-line' connection between continuous variables such as salary, price, or age. Linear regression models are used to make predictions in the fields of biology, social, environmental, and behavioral sciences, and business.
Neural networks
Neural networks use nodes made up of inputs, weights, thresholds (sometimes referred to as a bias), and outputs. These nodes are layered in a structure of input, hidden, and output layers that resemble the human brain — hence, neural. Neural networks, considered deep learning algorithms, build a knowledge base from labeled training data. Therefore, they can identify complex patterns and relationships within data. They are an adaptive system and are able to 'learn' from their mistakes for continuous improvement. Neural networks can be used in image recognition and language processing applications.
Random forest
Random forest algorithms are a collection (or forest) of uncorrelated decision tree algorithms programmed to produce a single result from multiple outputs. Random forest algorithm parameters include node size, number of trees, and number of features. These hyperparameters are set before training. Their reliance on bagging and feature randomness methods ensures data variability in the decision process and ultimately produces more accurate predictions. This is the key difference between decision trees and random forests. As a result, random forest algorithms enable higher flexibility — feature bagging helps estimate missing values, which ensures accuracy when certain data points are missing.
Support vector machine (SVM)
Support vector machines (SVM) are most commonly used for data classification and occasionally for data regression. For classification applications, an SVM constructs a decision boundary that helps distinguish or classify data points, such as fruits vs. vegetables, or mammals vs. reptiles. SVM can be used for image recognition or text classification.
Naïve Bayes
Naïve Bayes is a probabilistic classification algorithm based on Bayes' theorem. It assumes that the features in a dataset are independent and that each feature, or predictor, has an even weight in the result. This assumption is referred to as 'naïve' because it can often be countered in a real-world scenario. For example, the next word in a sentence depends on the one that comes before it. In spite of this, the single probability of each variable makes Naïve Bayes algorithms computationally efficient, especially for text classification and spam filtering tasks.
K-nearest neighbors
K-nearest neighbor, also known as KNN, is a supervised learning algorithm that uses the proximity of variables to predict outputs. In other words, it works off the assumption that similar data points exist near one another. Once trained on labeled data, the algorithm calculates the distance between a query and the data it has memorized — its knowledge base — and formulates a prediction. KNN can use various distance calculation methods (Manhattan, Euclidean, Minkowski, Hamming) to establish the decision boundary on which the prediction is based. KNN is used for classification and regression tasks, including relevance ranking, similarity search, pattern recognition, and product recommendation engines.
Challenges and limitations of supervised machine learning
Though supervised machine learning enables a high level of accuracy in predictions, it is a resource-intensive machine learning technique. It's reliant on expensive data labeling processes, requiring large datasets, and as a result is vulnerable to overfitting.
- The cost of labeling data: One of the main challenges of supervised learning is the need for large, accurately labeled datasets. The accuracy of these labels is directly proportional to a model's accuracy, so quality is paramount. This is a time-consuming effort, sometimes requiring expert knowledge (depending on the data and the model's intended use), which in turn, can be very expensive. In fields like healthcare or finance where data is sensitive and complex, obtaining high-quality labeled datasets can be particularly challenging.
- Need for large datasets: A supervised learning model's reliance on large datasets can be a significant challenge for two reasons: gathering and labeling large amounts of quality data is resource-intensive, and finding the right balance between too much data and enough good data is tricky. Large datasets are necessary for effective training, but datasets that are too broad lead to overfitting.
- Overfitting: Overfitting is a common concern in supervised learning. It occurs when a model is exposed to too much training data and captures noise or irrelevant details — there is such a thing as too much data. This affects the quality of its predictions and leads to poor performance on new, unseen data. To counter or avoid overfitting, engineers rely on cross-validation, regularization, or pruning techniques.
Preprocessing data is at the heart of these challenges. It can be time-consuming and expensive, but with the right tools, it can mitigate the challenges of cost, quality, and overfitting.
Supervised vs. unsupervised machine learning
Machine learning can be supervised, unsupervised, and semi-supervised. Each data training method achieves different results and is used in different contexts. Supervised machine learning requires labeled datasets to train data, but improves its accuracy thanks to large, high-quality datasets.
In contrast, unsupervised machine learning uses unlabeled datasets to train a model for predictions. The model identifies patterns between unlabeled data points on its own, sometimes resulting in less accuracy. Unsupervised learning is often used for clustering, association, or dimensionality reduction tasks.
Semi-supervised machine learning
Semi-supervised machine learning is a combination of supervised and unsupervised learning techniques. Semi-supervised learning algorithms are trained on small amounts of labeled data and larger amounts of unlabeled data. This achieves better results than unsupervised learning models with fewer labeled examples. Semi-supervised learning is a hybrid method that can be especially useful in cases where labeling large datasets is impractical or expensive.
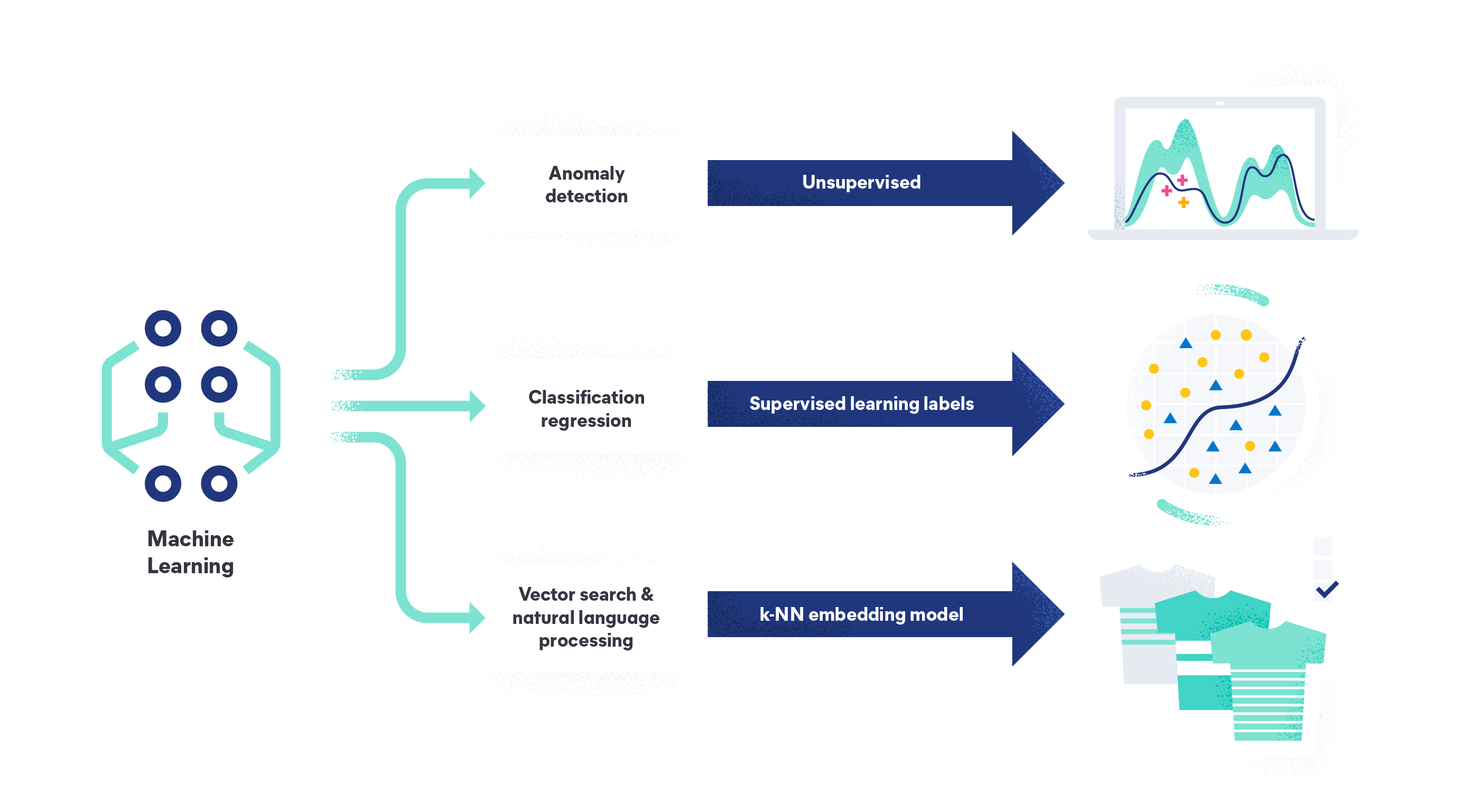
Understanding the difference between these machine learning methods is crucial for choosing the right solution for the task at hand.
Machine learning made easy with Elastic
Machine learning starts with data — that’s where Elastic comes in.
With Elastic machine learning, you can analyze your data to find anomalies, perform data frame analytics, and analyze natural language data. Elastic machine learning removes the need for a data science team, designing a system architecture from scratch, or moving data to a third-party framework for model training. As the Search AI platform, our capabilities let you ingest, understand, and build models with your data, or rely on our out-of-the-box unsupervised model for anomaly and outlier detection.
Learn more about how Elastic can help you address your data challenges with machine learning.