定義
ベクトル検索とは?
ベクトル検索は機械学習(ML)を活用して、テキストや画像などの非構造化データから意味とコンテキストを取り込み、数値表現に変換します。セマンティック検索で頻繁に使用されるベクトル検索は、近似近傍(ANN)アルゴリズムを使用して類似データを検索します。ベクトル検索は、従来のキーワード検索に比べてより高速で、より関連性の高い結果を生成できます。

ベクトル検索が重要な理由
何かを検索する際に、その名前がわからないということがよくあります。その機能は知っているし、説明ならできる場合もありますが、キーワードがないまま検索することになります。
ベクトル検索を使用すると、この制約を克服して意味内容から検索できます。つまり、類似性検索に基づいてクエリに対する回答をすばやく返すことができるのです。これは、ベクトル埋め込みが、テキストだけではなく、動画、画像、音声などの非構造化データを取り込むためです。ベクトル検索にフィルタリングとアグリゲーションを組み合わせ、ハイブリッド検索を実装して従来のスコアリングと組み合わせて関連性を最適化することにより、検索エクスペリエンスを強化できます。
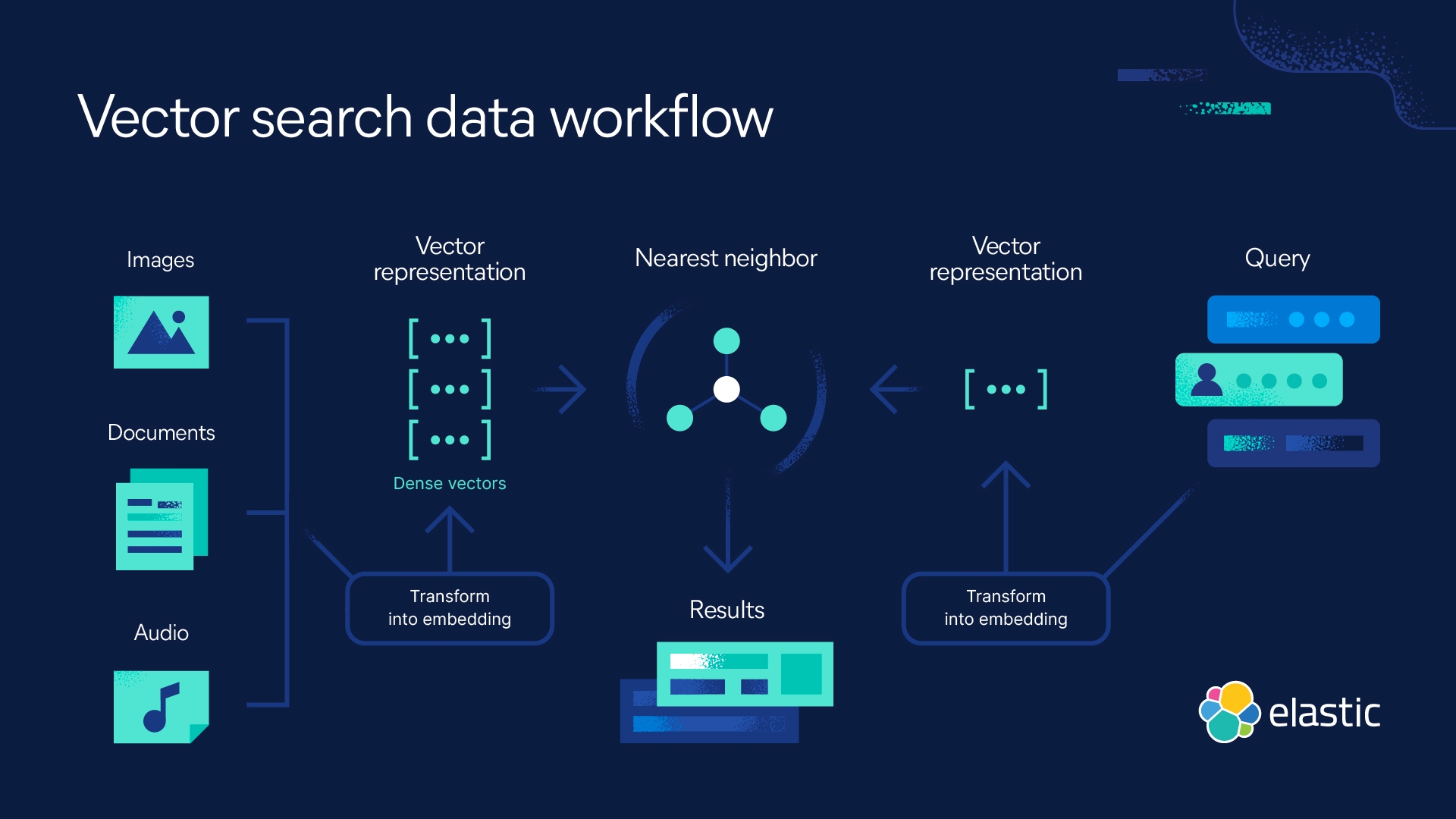
ベクトル検索のユースケース
ベクトル検索は、次世代の検索エクスペリエンスを強化するだけでなく、さまざまな新しい可能性を切り開くものです。
導入方法
Elasticで容易になるベクトル検索とNLP
ベクトル検索を実装してNLPモデルを適用するために、山を動かすような労力を払う必要はありません。Elasticsearch Relevance Engine™(ESRE)を使用すると、生成AIおよび大規模言語モデル(LLM)とともに使用できるAI検索アプリケーションを構築するためのツールキットが得られます。
ESREを使えば、革新的な検索アプリケーションの構築、埋め込みの生成、ベクトルの保存と検索、ElasticのLearned Sparse Encoderを使ったセマンティック検索の実装が可能になります。Elasticsearchをベクトル検索として使用する方法の詳細をご覧ください。または、自己ペースのベクタル検索の実践をお試しください。
