What’s the difference? Elastic and Splunk data tiers
Discover the key differences between the Elastic and Splunk data management approaches to make informed decisions for efficient data handling
_Blog_header_image-_Elastic_vs_AmazoN_OPT_1_V1.jpg)

 Share on Twitter
Share on TwitterShare on Twitter

 Share on LinkedIn
Share on LinkedInShare on LinkedIn

 Share on Facebook
Share on FacebookShare on Facebook

 Share by Email
Share by EmailShare by email

 Print this page
Print this pagePrint
In the realm of data management, terms like Hot, Warm, and Cold get tossed around frequently when discussing how data should be made available and/or retained given different performance requirements.
With unique, sometimes conflicting terminology associated with both Elastic® and Splunk’s offerings, our aim is to unravel these differences and present a clearer picture to enable strategic, cost-effective approaches to your data management needs.
What are data tiers?
At a fundamental level, data tiers are distinct storage levels that classify data based on criteria like access frequency, cost efficiency, and performance needs. They allow for optimized data organization and can help reduce costs by aligning storage expenses with the value of the information over time.
The concept of data tiers is present in most data platforms, especially in those that deal with observability and/or security tools. The volume of data collected by these tools is usually very high, with thousands or even millions of events per second being processed and made available for searching, dashboarding, and alerting. Observability and security also have a shared characteristic: the most recent data is also the most valuable, as teams administering these tools rely on the signals being collected to take immediate action in case of problems.
So it makes sense for data to be ingested and stored with the fastest possible hardware and moved “down” to cheaper, less powerful hardware as time passes. It can also move "up" when needed.
We can group the data tiers in both Elastic and Splunk in three layers in a "data cake":
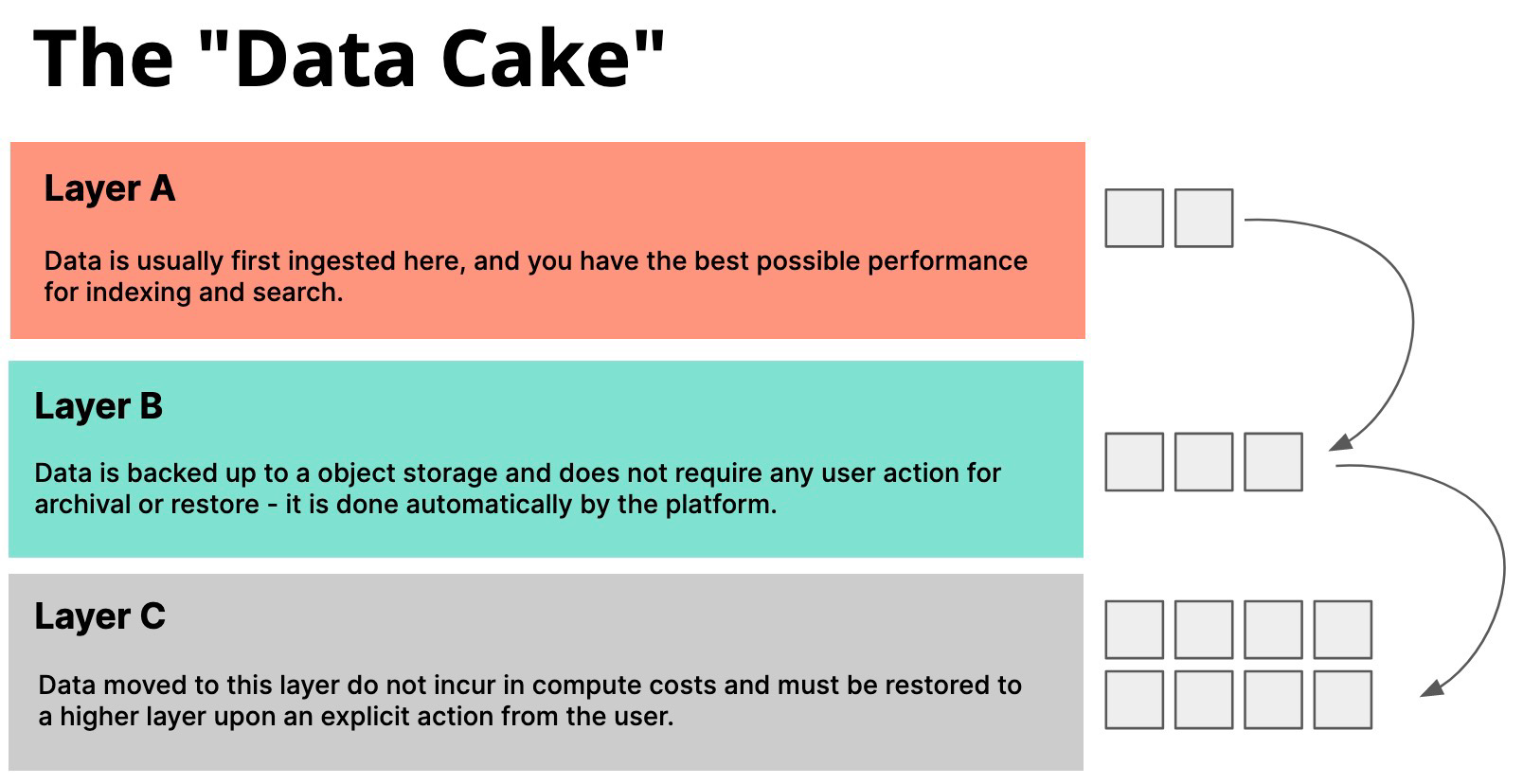
Layer A: Data is usually first written here, and we have the best possible performance for indexing and search.
Layer B: Data is moved here from other layers and it is searchable, although the performance is not as good as the above layer. Data is backed up to an object store and does not require any user action for archival or restore — it is done automatically by the platform.
Layer C: Data moved to this layer does not incur in compute costs as it is not actively indexed. In order for data to be used (searched upon), it must be restored to a higher layer upon an explicit action from the user — until that happens, the data is virtually “invisible.”
Since Layer A is the most expensive of the three, it makes sense to keep data in there only for as long as it is needed. An example might be keeping the data for one week in Layer A then moving it to B, where it will remain for six months, then to Layer C where it gets stored for, say, three years, for compliance purposes.
In our opinion, observability and security solutions must give users the ability to choose how they want to move their data up and down the layers, as much as possible, as it is ultimately their decision when it comes to how to balance performance and costs, considering several factors such as budget and business requirements.
Knowing the data tiers in both Splunk and Elastic helps in devising an appropriate data migration strategy. This includes determining which data should be migrated, how it should be transformed or restructured, and how to ensure data integrity and consistency during the migration process. Understanding the source and destination data tiers enables you to map data from one system to the other effectively.
Data tiers in Elastic and Splunk
Now that we have a single framework for comparing the data tiers, let's compare Elastic and Splunk's on-premises solutions, Elasticsearch® / Splunk Enterprise, and also their cloud solutions, Elastic Cloud / Splunk Cloud.
But first, a word about performance comparison. In this blog, we are talking strictly about data management by putting tiers side by side — we are not comparing them in terms of performance. If anything, the performance difference can be inferred by how low the layer is, but that is within the same product (e.g., Hot tier is faster than Cold in Elastic Cloud because it uses more powerful hardware and it is also more scalable, since you can replicate the data onto several nodes).
Comparison: Elasticsearch and Splunk Enterprise
While both Elastic and Splunk have Hot, Warm, Cold, and Frozen tiers, they mean completely different things on both solutions. Let's summarize.
Elastic has a five-tier structure:
Hot: This is the primary destination for freshly ingested data, offering the best possible performance and real-time availability.
Warm: Slightly less pressing data resides here, on more budget-friendly hardware while maintaining scalability and availability.
Cold: Here, just one searchable copy of the data is maintained in the cluster, with recovery from object storage being automatic in case of a change in the topology.
Frozen: This tier houses less frequently accessed data, enabling savings with compute resources, and introduces automatic data restoration for searches. It provides a way to use remote object stores to store data, such as Amazon S3, Google GCS, or Microsoft Azure Blob storage.
Snapshots: Acting as data backups, these snapshots are manually restorable copies for recovery or migration purposes.
Splunk Enterprise has a four-tier structure:
Hot+Warm: This is the primary destination for freshly ingested data, offering real-time availability and search performance. The difference between Hot and Warm in Splunk Enterprise is merely in terms of read+write and read-only — Warm data is only readable (for example, for searching) since the indexer does not write new data to them.
Cold: The cold phase allows the admins to move data that is less likely to be searched to cheaper (i.e., slower) storage devices.
SmartStore: This tier houses less frequently accessed data, enabling savings with compute resources, and introduces automatic data restoration for searches. It provides a way to use remote object stores to store data, such as Amazon S3, Google GCS, or Microsoft Azure Blob storage. This is a completely different way of architecting data tiers in Splunk as most data resides on remote storage and the indexer just maintains a local cache.
- Frozen: Acting as data backups, these snapshots are manually restorable copies for recovery or migration purposes. Here, what Splunk calls Frozen is similar to Elastic's Snapshots.
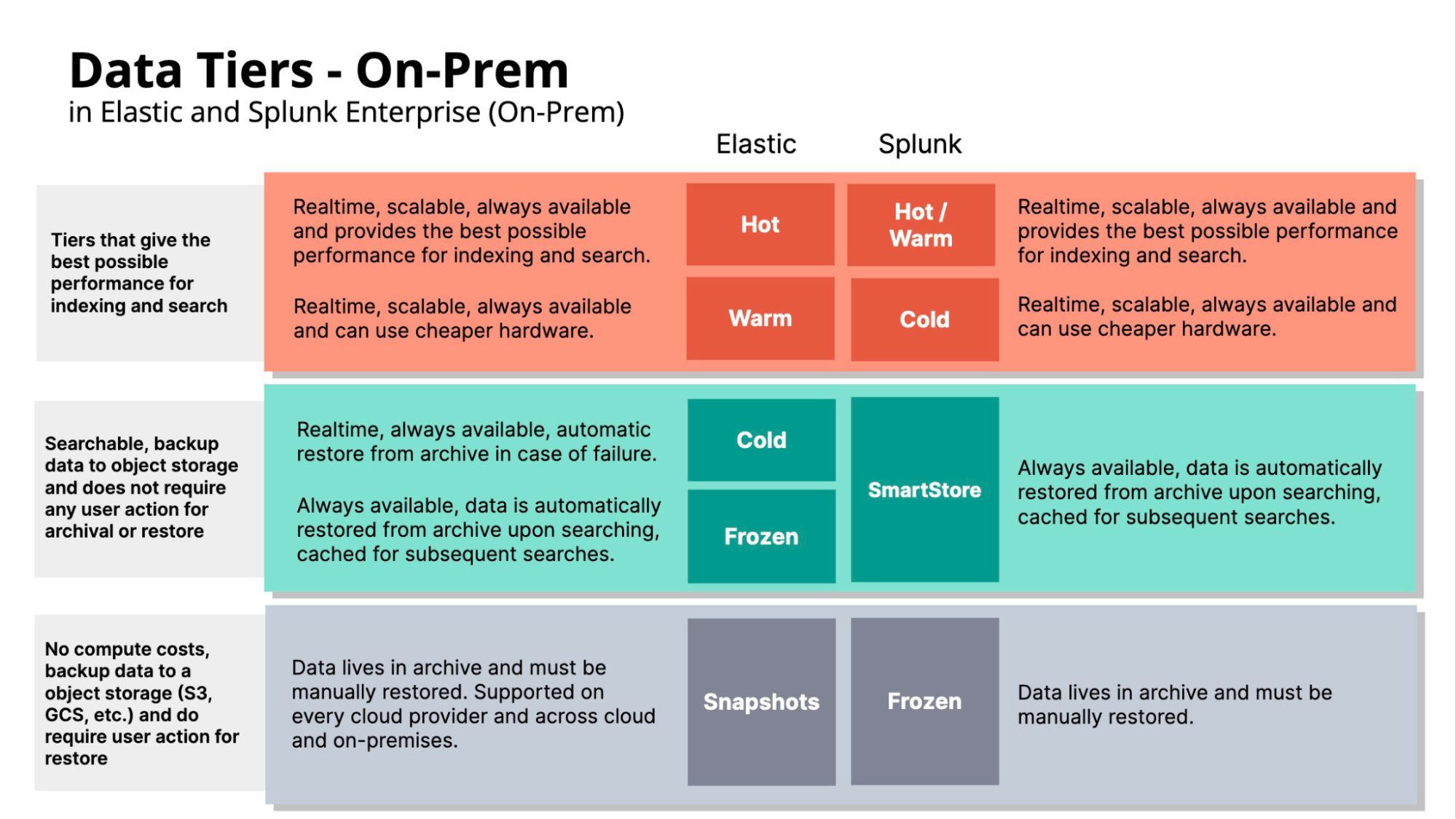
With Splunk Enterprise, the distinction between Hot and Warm tiers is less pronounced, and its Cold tier can be likened to Elastic’s Warm in terms of hardware utilization. Elastic still leads with a scalable Hot tier, facilitating a transition to Warm without relinquishing availability.
Elastic’s Cold and Frozen storage strategies ensure data is immediately queryable, thanks to object storage backups that automate the retrieval process, akin to Splunk’s SmartStore. However, Splunk’s Frozen category requires manual restoration akin to Elastic’s Snapshots.
In Elastic, both Cold and Frozen rely on the searchable snapshots feature, which allows snapshots as old as 5.0 (released way back in 2016!) to be searched without the need to be restored to an active cluster — this is very useful for governance and compliance, security investigations, and historical lookbacks regardless of what Elasticsearch version you are on.
Elastic Cloud and Splunk Cloud
In Elastic Cloud, data begins its journey in the Hot tier, known for its scalability, high availability, and peak performance for complex operations like indexing and search. In contrast, Splunk Cloud does not offer a vis-a-vis tiering option with Elastic Cloud in terms of Hot and Warm; instead, it has DDAS, which seems to prioritize cost savings, potentially at the expense of speed.
Elastic has the same five tiers in Elasticsearch and Elastic Cloud, but Splunk Cloud has a three-tier structure:
DDAS: This tier prioritizes cost savings over performance, as it leverages SmartStore. Splunk states that "Splunk Cloud Platform leverages a multi-tier storage architecture and manages the movement of data to optimize performance based on user search patterns. Generally, recently processed data (recently ingested, searched, analyzed for machine learning, and so on) will have better performance than data that has not been processed for some time."
DDAA: Data can be configured to be archived in DDAA, where Splunk will manage the storage and users must actively request a restore. Restored DDAA data is typically ready to search within 24 hours after a restoration request and remains searchable for up to 30 days. Large amounts of DDAA data restore can take beyond 24 hours to complete.
DDSS: Data in this tier is stored exclusively on object storage and needs to be manually restored (or "rehydrated) in order to be searchable. Users will manage the storage in either Amazon S3 or Google Cloud Storage in the same region as their Splunk Cloud Platform.
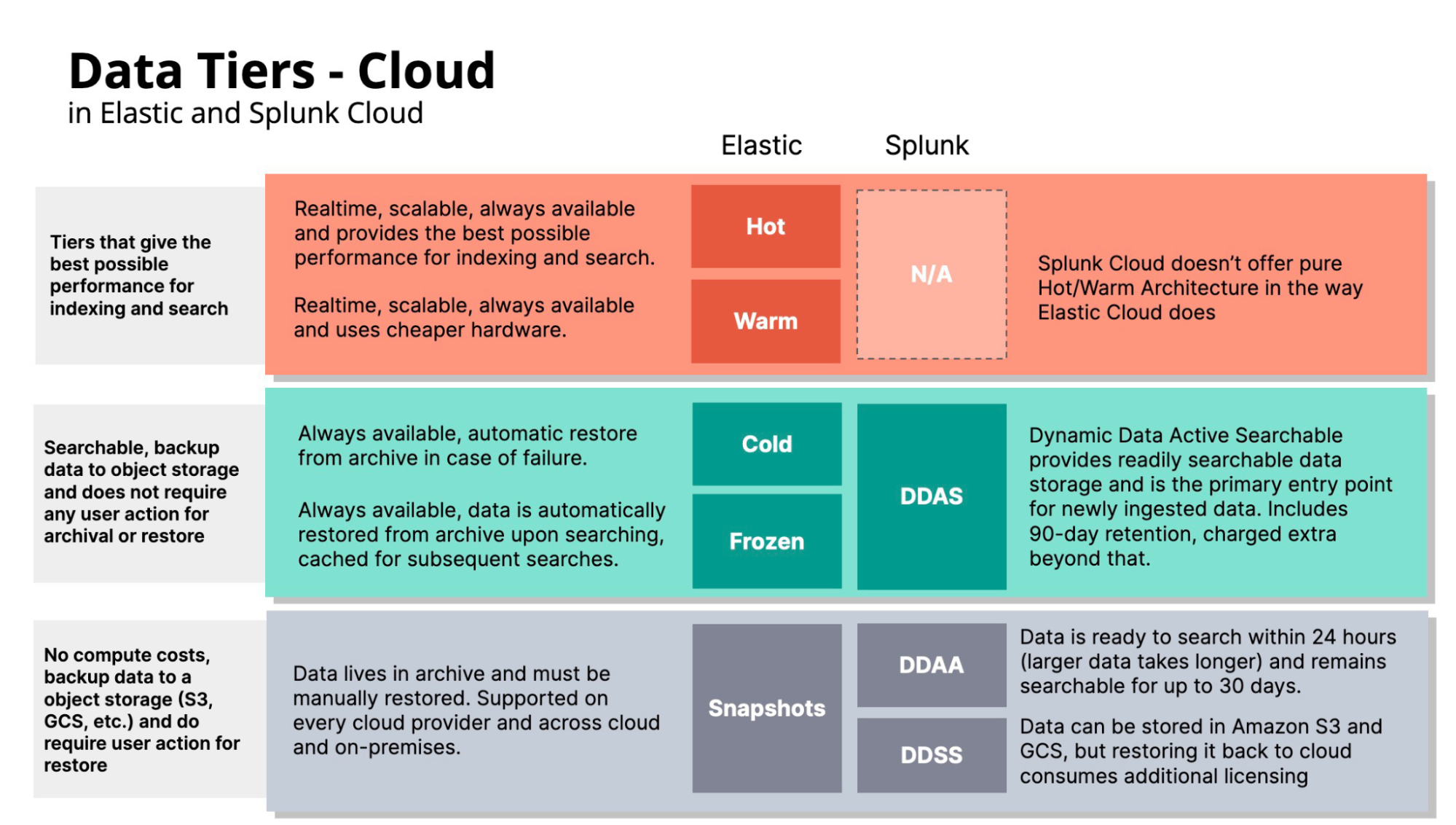
Elastic Cloud's tiers are fundamentally different from Splunk Cloud. The main difference spawns from the fact the two take very different approaches to deployment flexibility — Elastic provides a detailed list of instance types for AWS, Google Cloud, and Azure that you can choose at any point, and you can even change the instance types for data tiers at any given time without downtime. In Splunk you have two options: AWS or Google Cloud with different sets of features on each, and no visibility into the hardware.
Furthermore everything available to Elastic on-premises is also available on Elastic Cloud, since they are the exact same product, while Splunk imposes limitations on what features you might use on Cloud. Real-time search is also not enabled by default depending on your subscription level and might require a support ticket to be enabled.
In summary: Elastic and Splunk data tiers
Naming conventions can be misleading, causing understandable confusion when trying to align business needs to data storage options among providers. Having a grasp on the actual capabilities of these tiers can help you make more informed and cost-effective decisions regarding data management.
This breakdown is meant to dispel misconceptions brought about by the naming overlap in data tiers between Elastic and Splunk. With this description of data tiers, you’ll be better positioned to organize your data strategically for performance and cost benefits. It’s critical to move beyond the names and understand the underlying mechanics of each tier to ensure your data strategy is both robust and efficient.
The release and timing of any features or functionality described in this post remain at Elastic's sole discretion. Any features or functionality not currently available may not be delivered on time or at all.
Splunk and other related marks are trademarks or registered trademarks of Splunk Inc. in the United States and other countries. All other brand names, product names, or trademarks belong to their respective owners.
Share
- Share on Twitter
Share on Twitter
- Share on LinkedIn
Share on LinkedIn
- Share on Facebook
Share on Facebook
- Share by Email
Share by email
- Print this page
Print

