How to deploy NLP: Sentiment Analysis Example


 Share on Twitter
Share on TwitterShare on Twitter

 Share on LinkedIn
Share on LinkedInShare on LinkedIn

 Share on Facebook
Share on FacebookShare on Facebook

 Share by Email
Share by EmailShare by email

 Print this page
Print this pagePrint
As part of our multi-blog series on natural language processing (NLP), we will walk through an example using a sentiment analysis NLP model to evaluate if comment (text) fields contain positive or negative sentiments. Using a publicly available model, we will show you how to deploy that model to Elasticsearch and use the model in an ingest pipeline to classify customer reviews as being either a positive or negative.
Sentiment analysis is a type of binary classification where the field is predicted to be either one value or the other. There is typically a probability score for that prediction between 0 and 1, with scores closer to 1 indicating more-confident predictions. This type of NLP analysis can be usefully applied to many data sets such as product reviews or customer feedback.
The customer reviews we wish to classify are in a public data set from the 2015 Yelp Dataset Challenge. The data set, collated from the Yelp Review site, is the perfect resource for testing sentiment analysis. In this example we will evaluate a sample of the Yelp reviews data set with a common sentiment analysis NLP model and use the model to label the comments as positive or negative. We hope to discover what percentage of reviews are positive versus negative.
Deploying the sentiment analysis model to Elasticsearch
docker run -it --rm elastic/eland \
eland_import_hub_model \
--url $ELASTICSEARCH_URL \
--hub-model-id distilbert-base-uncased-finetuned-sst-2-english \
--task-type text_classification \
--start

A search toolkit for the AI era
The Elasticsearch Relevance Engine (ESRE) gives developers the tools they need to build AI-powered search apps.
This time, --task-type is set to text_classification and the --start option is passed to the Eland script so the model will be deployed automatically without having to start it in the Model Management UI.
Once deployed, try these examples in Kibana Console:
POST _ml/trained_models/distilbert-base-uncased-finetuned-sst-2-english/deployment/_infer
{
"docs": [
{
"text_field": "The movie was awesome!"
}
]
}
You should see this as the result:
{
"predicted_value" : "POSITIVE",
"prediction_probability" : 0.9998643924765398
}
You can also try this example:
POST _ml/trained_models/distilbert-base-uncased-finetuned-sst-2-english/deployment/_infer
{
"docs": [
{
"text_field": "The cat was sick on the bed"
}
]
}
Produces a strongly negative response for both the cat and person cleaning the sheets.
{
"predicted_value" : "NEGATIVE",
"prediction_probability" : 0.9992468477843378
}
Analyzing Yelp reviews
As mentioned in the introduction, we will use a subset of the Yelp reviews available on Hugging Face that have been marked up manually with sentiment. This will allow us to compare the results to the marked-up index. We’ll use Kibana's file upload feature to upload a sample of this data set for processing with the Inference processor.
In the Kibana Console we can create an ingest pipeline (as we did in the previous blog post), this time for sentiment analysis, and call it sentiment. The reviews are in a field named review. As we did before, we'll define a field_map to map review to the field the model expects. The same on_failure handler from the NER pipeline is set:
PUT _ingest/pipeline/sentiment
{
"processors": [
{
"inference": {
"model_id": "distilbert-base-uncased-finetuned-sst-2-english",
"field_map": {
"review": "text_field"
}
}
}
],
"on_failure": [
{
"set": {
"description": "Index document to 'failed-<index>'",
"field": "_index",
"value": "failed-{{{_index}}}"
}
},
{
"set": {
"description": "Set error message",
"field": "ingest.failure",
"value": "{{_ingest.on_failure_message}}"
}
}
]
}
The review documents are stored in the Elasticsearch index yelp-reviews. Use the reindex API to push the reviews data through the sentiment analysis pipeline. Given that reindex will take some time to process all the documents and infer on them, reindex in the background by invoking the API with the wait_for_completion=false flag. Check progress with the Task management API.
POST _reindex?wait_for_completion=false
{
"source": {
"index": "yelp-reviews"
},
"dest": {
"index": "yelp-reviews-with-sentiment",
"pipeline": "sentiment"
}
}
The above returns a task id. We can monitor progress of the task with:
The above returns a task id. We can monitor progress of the task with:
Alternatively, track progress by watching Inference count increase in the model stats UI.

The reindexed documents now contain the inference results. As an example one of the analyzed docs looks like this:
{
"review": "The food is good. Unfortunately the service is very hit or miss. The main issue seems to be with the kitchen, the waiters and waitresses are often very apologetic for the long waits and it's pretty obvious that some of them avoid the tables after taking the initial order to avoid hearing complaints.",
"ml": {
"inference": {
"predicted_value": "NEGATIVE",
"prediction_probability": 0.9985209630712552,
"model_id": "distilbert-base-uncased-finetuned-sst-2-english"
}
},
"timestamp": "2022-02-02T15:10:38.195345345Z"
}
The predicted value is NEGATIVE, which is reasonable given the poor service.
Visualizing how many reviews are negative
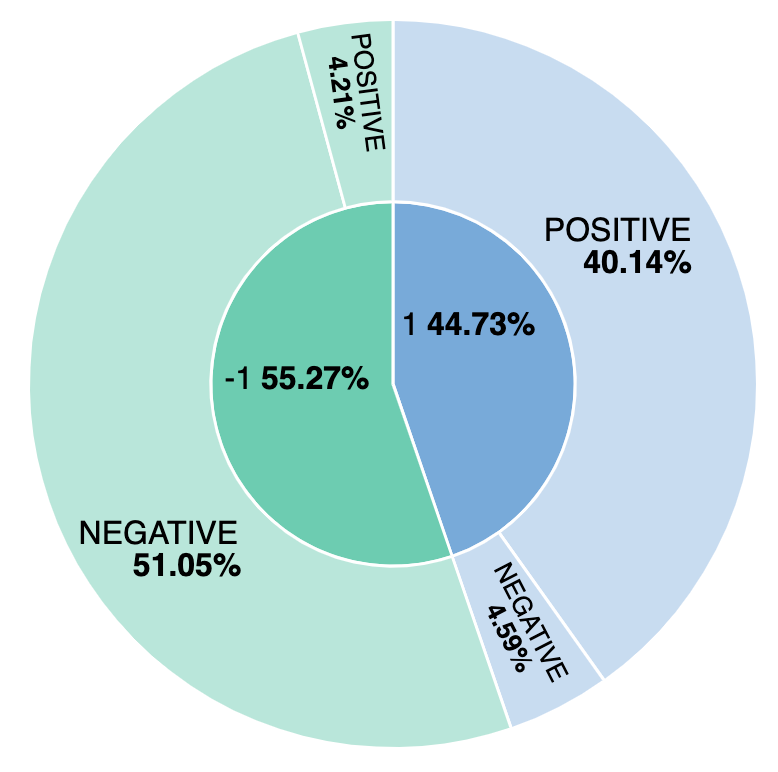
What percentage of reviews are negative? And how does our model compare to manually labeled sentiment? Let’s find out by building a simple visualization to track positive versus negative reviews from the model and manually. By creating a visualization based on the ml.inference.predicted_value field, we can report on the comparison and see that approximately 44% of reviews are considered positive and of those 4.59% are incorrectly labeled from the sentiment analysis model.
Trying it out
If you want more NLP reads:
Share
- Share on Twitter
Share on Twitter
- Share on LinkedIn
Share on LinkedIn
- Share on Facebook
Share on Facebook
- Share by Email
Share by email
- Print this page
Print

