Optimizing Strava data collection with Elastic APM and a custom script solution


 Share on Twitter
Share on TwitterShare on Twitter

 Share on LinkedIn
Share on LinkedInShare on LinkedIn

 Share on Facebook
Share on FacebookShare on Facebook

 Share by Email
Share by EmailShare by email

 Print this page
Print this pagePrint
This is the fourth blog post in our Strava series (don’t forget to catch up on the first, second, and third)! I will take you through a journey of data onboarding, manipulation, and visualization.
What is Strava, and why is it the focus? Strava is a platform where recreational and professional athletes can share their activities. All my fitness data from my Apple Watch, Garmin, and Zwift is automatically synced and saved. Getting the data out of Strava is the first step to getting an overview of my fitness.
In the last blog posts, we developed a script that imports all the data from Strava. Now it’s time for some observability and identifying issues with our script.
What is my script doing?
Remember, in the second blog, we wrote quite an extensive script. I will post it here again:
from elasticsearch import Elasticsearch, helpers
from datetime import datetime, timedelta
import requests
import json
ELASTIC_PASSWORD = "password_for_strava-User"
CLOUD_ID = "Cloud_ID retrieved from cloud.elastic.co"
client = Elasticsearch(
cloud_id=CLOUD_ID,
basic_auth=("strava", ELASTIC_PASSWORD)
)
ES_INDEX = 'strava'
stravaBaseUrl = "https://www.strava.com/api/v3/"
payload = ""
headers = {
"Authorization": "Bearer _authorization_token_acquired_from_strava"
}
def GetStravaActivities():
url = stravaBaseUrl + "athlete/activities"
querystring = {"per_page": "50", "page": "1"}
#### ^^^above the `per_page` can be changed to a maxmimum of 50
#### You can have 100 requests per 15 minutes, that would give you 1500 activities to retrieve in 15 minutes
#### Maximum of 1.000 requests per day.
#### after ever run don't forget to increase the page number.
#### Don't forget that we are now calling a 2nd API for every activity.
#### That means we can only collect 50 activites, since for every activite we call the streams API.
return json.loads((requests.request(
"GET", url, data=payload, headers=headers, params=querystring).text))
def GetStravaStreams(activity):
#Detailed Streams API call
url = stravaBaseUrl + "activities/" + str(activity['id']) + "/streams"
querystring = {"keys":"time,distance,latlng,altitude,velocity_smooth,heartrate,cadence,watts,temp,moving,grade_smooth","key_by_type":"true"}
streams = json.loads((requests.request("GET", url, data=payload, headers=headers, params=querystring)).text)
# create the doc needed for the bulk request
doc = {
"_index": ES_INDEX,
"_source": {
"strava": activity,
"data": {}
}
}
for i in range(streams['time']['original_size']):
# run the modification of the data in an extra function
yield ModifyStravaStreams(doc, streams, activity, i)
def ModifyStravaStreams(doc, streams, activity, i):
tempDateTime = datetime.strptime(activity['start_date'].replace('Z','')+activity['timezone'][4:10], '%Y-%m-%dT%H:%M:%S%z')
for stream in streams:
if stream == 'time':
tempTime = tempDateTime + timedelta(seconds=streams['time']['data'][i])
doc['_source']['@timestamp'] = tempTime.strftime('%Y-%m-%dT%H:%M:%S%z')
elif stream == 'velocity_smooth':
doc['_source']['data'][stream] = streams[stream]['data'][i]*3.6
elif stream == 'latlng':
doc['_source']['data'][stream] = {
"lat": streams[stream]['data'][i][0],
"lon": streams[stream]['data'][i][1]
}
else:
doc['_source']['data'][stream] = streams[stream]['data'][i]
return doc
def main():
# get the activities
activities = GetStravaActivities()
for activity in activities:
# I only care about cycling, you are free to modify this.
if activity['type'] == "Ride" or activity['type'] == "VirtualRide":
# I like to know what is going on and if an error occurs which activity it is.
print(activity['upload_id'], activity['name'])
helpers.bulk(client, GetStravaStreams(activity))
main()We can see that we have multiple pieces of this code. I want to know where my script is spending time. Is it slow when waiting for the response time? Is it waiting on the Strava API response, or is uploading the documents slowing it down? The manipulation of JSON within the script is slowing it down.
Instrumentation
Elastic’s application performance monitoring (APM) is super easy to get started. If you are on Cloud, activate the integration server and tada; you got APM. In Kibana, go to Observability and select APM. In the top right corner, there is an Add Data button. This shows you the secret token as well as the server URL.
First things first: in the script, import the elastic apm library. Don’t forget to install it before.
import elasticapmAfter all the imports, I like to put my instrumentation and start the APM agent.
clientapm = elasticapm.Client(service_name="StravaToElasticsearch", server_url="https://url:443",
secret_token="...", environment='production')
elasticapm.instrument()That is enough for the script to appear as a service inside the APM view. It will only send metrics, as we have yet to instrument any transactions.
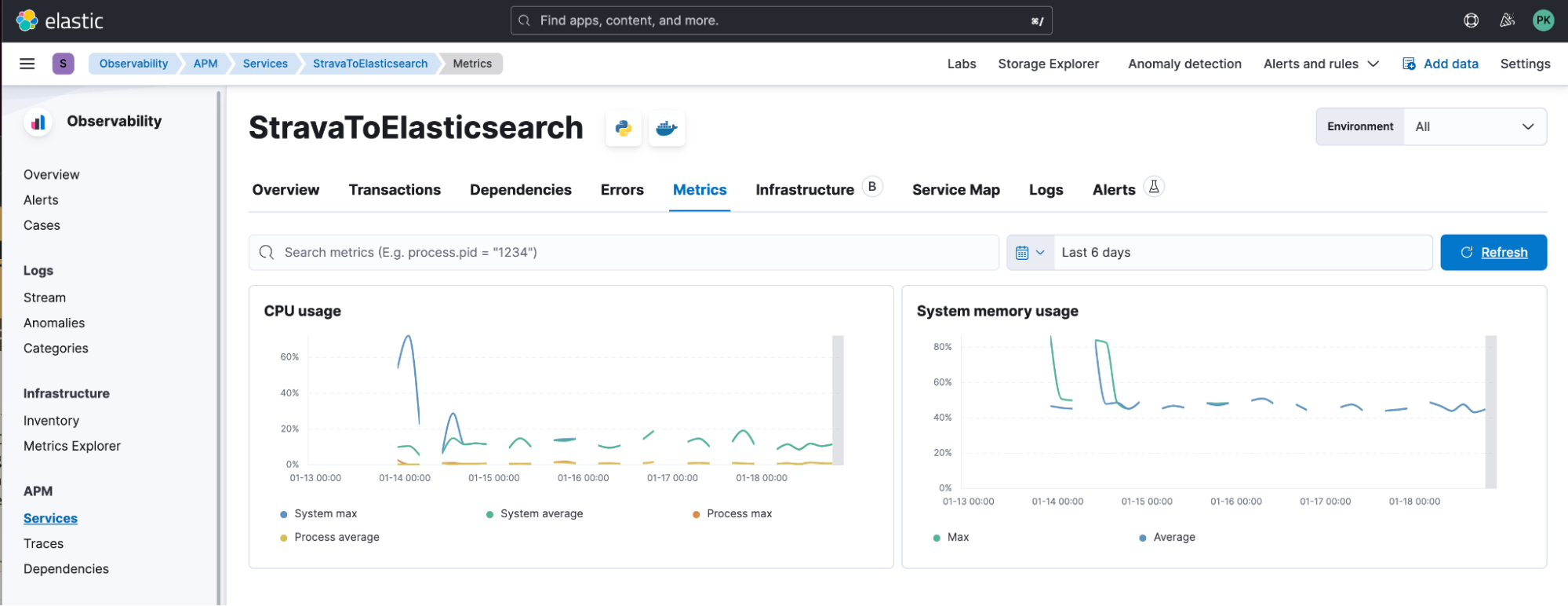
In our code, we have two things we want to instrument:
- GetStravaActivities
- GetStravaStreams
This is easy! You remember this piece of code:
def main():
# get the activities
activities = GetStravaActivities()
for activity in activities:
# I only care about cycling, you are free to modify this.
if activity['type'] == "Ride" or activity['type'] == "VirtualRide":
# I like to know what is going on and if an error occurs which activity it is.
print(activity['upload_id'], activity['name'])
helpers.bulk(client, GetStravaStreams(activity))
main()We want to add the following lines and wrap the function call within:
clientapm.begin_transaction(transaction_type="request")
clientapm.end_transaction(name="StravaActivities", result="success")In the end, it looks like this:
def main():
# get the activities
clientapm.begin_transaction(transaction_type="request")
activities = GetStravaActivities()
clientapm.end_transaction(name="StravaActivities", result="success")
for activity in activities:
# I only care about cycling, you are free to modify this.
if activity['type'] == "Ride" or activity['type'] == "VirtualRide":
# I like to know what is going on and if an error occurs which activity it is.
print(activity['upload_id'], activity['name'])
clientapm.begin_transaction(transaction_type="request")
helpers.bulk(client, GetStravaStreams(activity))
clientapm.end_transaction(name="StravaActivityData", result="success")
Yes! That looks great. Start it up. We get a transaction for StravaActivities that is this:
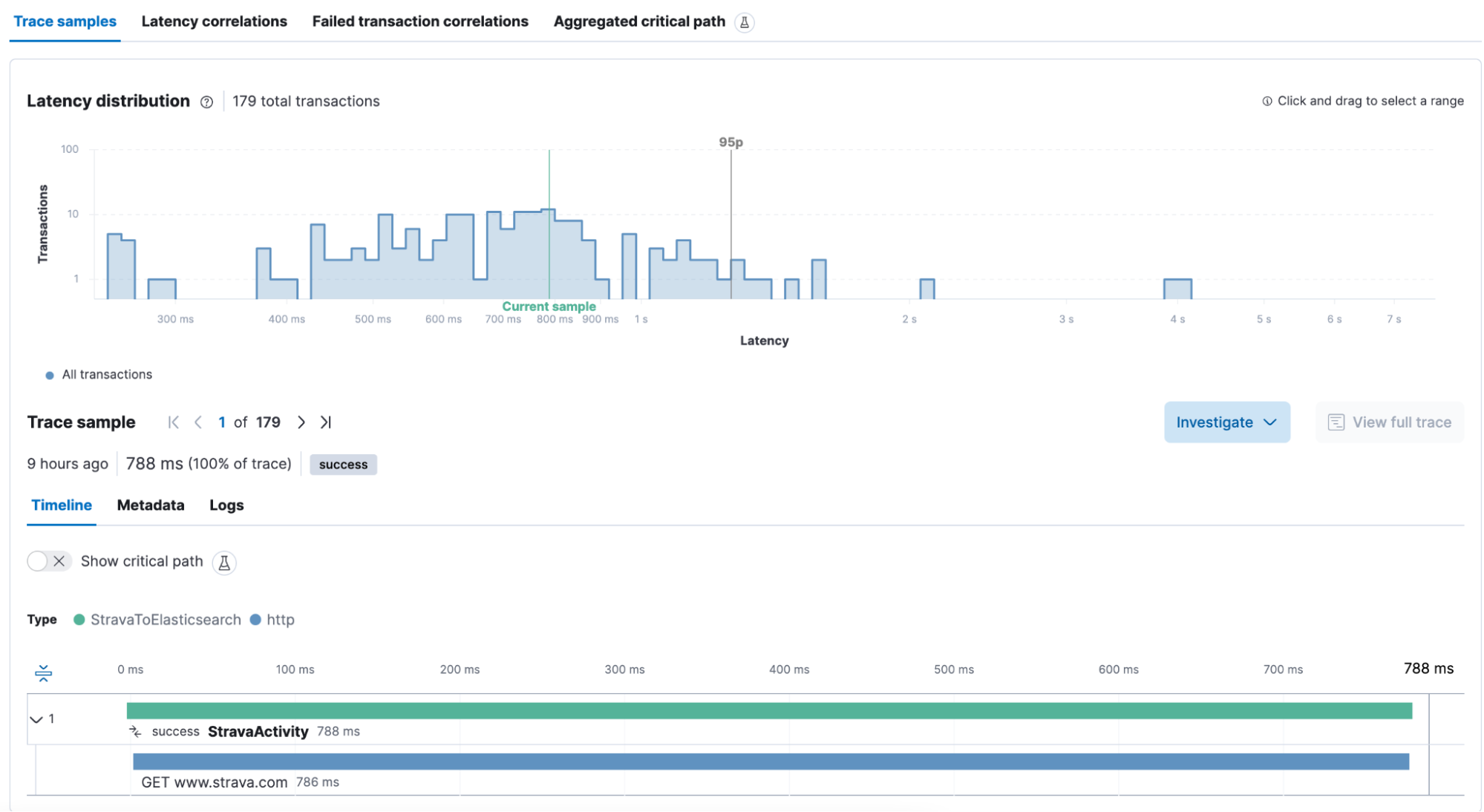
A single call to strava.com API took around ~800ms for Strava to answer what we asked. Atop we see the Latency Distribution, which is fantastic for quickly identifying if a transaction is quicker or slower.
The second call is StravaActivityData for each activity individually. The Strava call is relatively quick, and uploading the data to Elasticsearch takes most of the transaction duration.
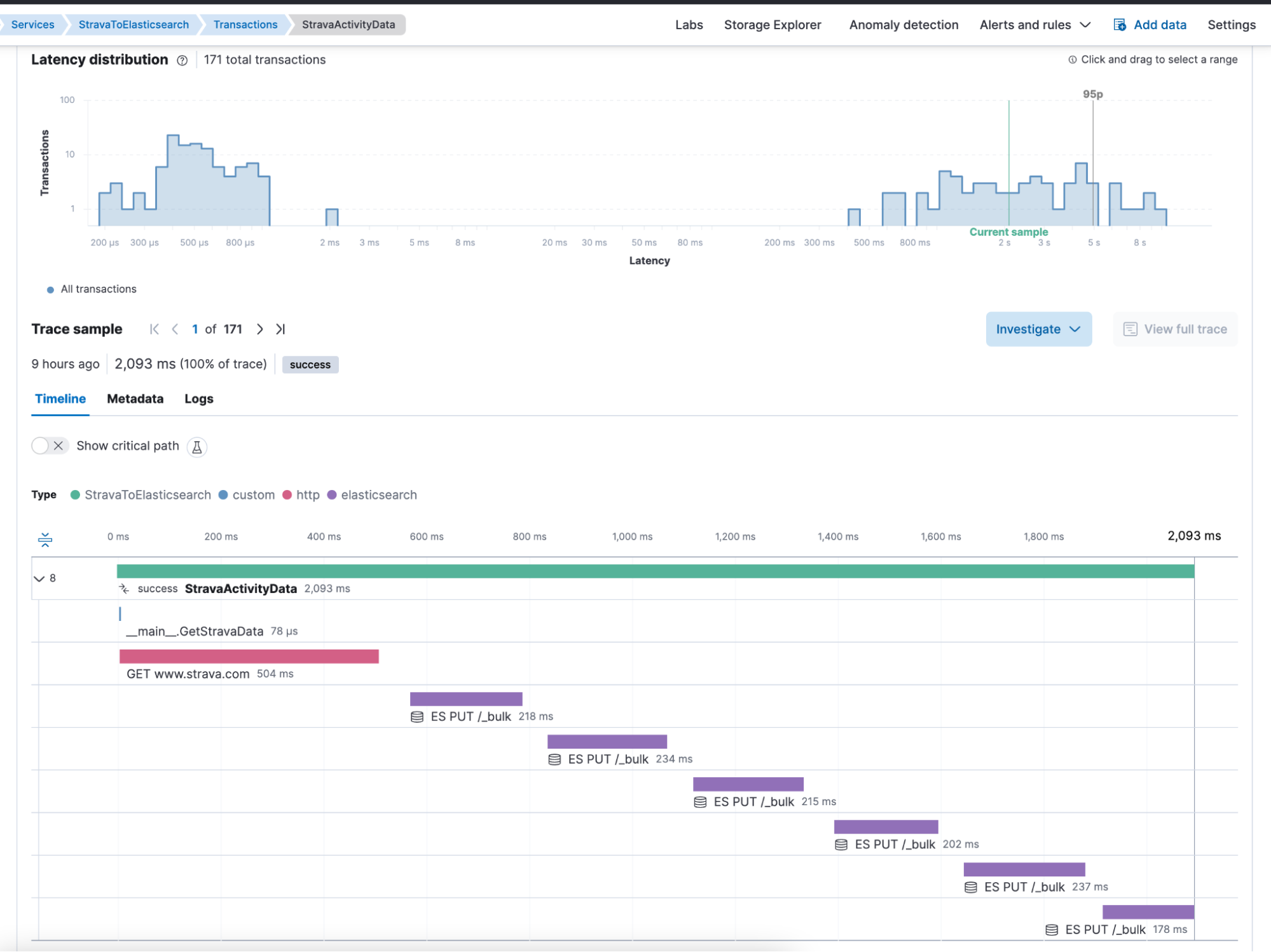
Summary
We achieved quite a bit together in this blog post! We have an instrumented script explaining what is happening behind the scenes. Have fun playing around with Elastic APM.
Ready to get started? Begin a free 14-day trial of Elastic Cloud. Or download the self-managed version of the Elastic Stack for free.
Check out the other posts in this Strava series:
- Part 1: How to import Strava data into the Elastic Stack
- Part 2: Analyze and visualize Strava activity details with the Elastic Stack
- Part 3: Get more out of Strava activity fields with runtime fields and transforms
- Part 5: How tough was your workout? Take a closer look at Strava data through Kibana Lens
- Part 6: Unlocking insights: How to analyze Strava data with Elastic AIOps
- Part 7: From data to insights: Predicting workout types in Strava with Elasticsearch and data frame analytics
Share
- Share on Twitter
Share on Twitter
- Share on LinkedIn
Share on LinkedIn
- Share on Facebook
Share on Facebook
- Share by Email
Share by email
- Print this page
Print

