Superior relevance with Elastic Learned Sparse EncodeR and hybrid scoring


 Share on Twitter
Share on TwitterShare on Twitter

 Share on LinkedIn
Share on LinkedInShare on LinkedIn

 Share on Facebook
Share on FacebookShare on Facebook

 Share by Email
Share by EmailShare by email

 Print this page
Print this pagePrint
Today we are pleased to announce the general availability of Elasticsearch 8.8. This release brings several key enhancements to vector search and lets developers leverage best-in-class AI-powered technologies in search applications without requiring the typical effort and expertise. Achieve superior search performance using Elastic’s proprietary transformer for semantic search, and implement hybrid scoring using RRF — no parameter tuning needed.
Also with Elasticsearch 8.8, use facets even if you employ dense vector retrieval under the hood, and the new Radius Query will enhance the search experiences further for your customers!
Finally, with Elasticsearch 8.8 you can combine the dramatic innovations enabled by generative AI with the power of Elasticsearch — and we are unveiling all this as the Elasticsearch Relevance Engine™.
These new features allow customers to:
- Achieve best-in-class semantic search out-of-the-box with Elastic Learned Sparse EncodeR (ELSER), Elastic’s proprietary transformer for semantic search
- Simplify hybrid scoring with Reciprocal Rank Fusion (RRF)
- Use facets on top of dense vector retrieval with radius query
- Gain greater control over assigning logs to the desired index or data stream with the reroute processor
- Receive alerts when your cluster is approaching shard capacity
Learn more about Elastic Learned Sparse EncodeR in the launch blog. Continue below to learn more details on the other capabilities highlighted above.
Simplified hybrid search with Reciprocal Rank Fusion (RRF)

Frequently, the best ranking is achieved by combining multiple ranking methods, like BM25 and an ML model that generates dense vector embeddings. In practice, combining the result sets into a single combined relevance ranked result set proves quite challenging. Sure, in theory you can normalize the scores of each of the result sets (because the original scores are on completely different ranges) and then perform a linear combination, sorting the final result set by the weighted sum of the scores from each of the ranking methods. Elasticsearch supports that and it works well, as long as you provide the right weights. In order to do that, you need to know the statistical distribution of the scores in each method in your environment and methodically optimize the weights. Realistically, this is beyond the ability of the great majority of users.
The alternative is the RRF algorithm that provides excellent zero shot blending of ranking methods, as proven in academic research. It is not just the best way to blend if you don’t possess knowledge of the exact distribution of your ranking scores in the different methods, it’s also an objectively great way to blend ranking methods — that’s quite hard to beat even if you do have the scores distribution and are able to normalize. The basic concept is that the combined order of results is defined by the position (and the existence) of each document in each of the result sets. The ranking score is thus conveniently disregarded.
Elastic 8.8 supports RRF with multiple dense vector queries and a single query that runs on the inverted index. In the near future, we expect to support blending results from BM25 and Elastic’s retrieval model (both of which are sparse vectors) yielding the best in class zero shot (no in-domain training) ranking method.
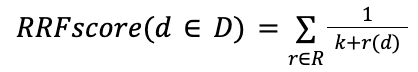
D - set of docs
R - set of rankings as permutation on 1..|D|
K - typically set to 60 by default
Facets with vector similarity
False positives in relevance rankings lead to a subpar user experience. A user who sees an irrelevant result ranked high is well aware that it is most likely pushing relevant results outside of the limited subset that they will review, and it reduces trust in the search results.
In traditional term frequency (e.g., BM25) based ranking, there is an inherent filter — most of the documents will not contain any of the words in the query and will be filtered out of the result set. This eliminates many of the false positives. In vector search in contrast, every vector in the index has a dot product to the vector of the query, and so even the most irrelevant doc is still a candidate. That problem is aggravated when facets are used because the filtering suggestions may be based on rather irrelevant results and cause the user to float these results up after using the facet value.
The relevancy threshold solves this problem, complementing Elasticsearch’s industry leading ability to aggregate over the result set and filter efficiently to support facets in vector search.
Store embeddings from OpenAI models in Elastic
Elasticsearch now supports performing kNN vector search using the HNSW algorithm with vectors with up to 2048 dimensions. There are not that many models that are useful in real life production that output vectors with more than 1024 dimensions, but recent user requests to support an OpenAI model convinced us to increase the threshold.
Reroute Ingest processor: Direct logs to the correct index or data stream
Elastic integrations make it easy to ingest common off-the-shelf log types like Apache Nginx logs, Kafka metrics, or Java traces. The agent will send each log type to the correct data stream and ingest pipeline to be parsed into usable fields. Things get more challenging when multiple log types are all coming in from one mixed source, such as container logs or a firehose. Which data stream and pipeline should they use? Do you really want to have to add that into the shipping agent configuration?
With the new reroute ingest processor, you’ll have central control over where each document goes for processing. Use known attributes of the data, like file path or container name, to identify the source and assign the desired index or data stream. The reroute processor has two modes: destination and data stream. In destination mode, you explicitly specify the target index name:
{
"reroute": {
"description": "reroute to my errors index",
"if": "ctx.message.indexOf('error') >= 0",
"destination": "myerrorsindex"
}
}In data stream mode, reroute will construct the target data stream name from the log’s type, data set, and namespace. The magic is that they will be derived from fields in the document, or you can override the data set and namespace yourself in the processor. Note that you must follow the data stream naming scheme.
For example, to reroute Nginx logs based on their file path, include this processor in your ingest pipeline:
{
"reroute": {
"description": "nginx router",
"if" : "ctx?.log?.file?.path?.contains('nginx')",
"dataset": "nginx"
}
}To reroute based on a service.name field in your documents:
{
"reroute": {
"dataset": [
"{{service.name}}",
"generic"
]
}
}If you want to onboard logs from one of these types of sources, the reroute processor could be for you:
- Lambda shipping functions, including our own functionbeat, and our new serverless log forwarder
- Docker logs coming from our docker logging driver
- Kubernetes pod logs from Filebeat, Agent, or Fluentd/Fluentbit
- Prometheus metrics: A single prometheus collector might collect metrics from many prometheus endpoints
- OpenTelemetry metrics: An OTel collector collects metrics from many metrics endpoints
- Syslog/Journald: Many services send their data via a single syslog input
- GCP DataFlow integration
- Azure MP integration
The reroute processor is in technical preview status in 8.8.
Enhancements to time_series indices
Indices in mode time_series are optimized for use with metrics data. V8.8 includes several enhancements to these indices:
- Fields with Flattened datatype can now be used as dimensions fields in time_series indices (i.e., fields that define the time series id), making it easier to convert existing data streams into time_series data streams, which typically yields around 70% reduction in index size (which in turn reduces TCO).
- A number of new compression methods have been added that are geared toward efficient compression of metrics data. These include delta encoding, XOR encoding, GCD encoding, and offset encoding. The impact of these differs greatly by the data, but in certain cases they can reduce the size that the field takes in the index by over 90%. These compression methods will be used automatically on time_series indices based on the metric type and datatype.
- The limit for the number of dimensions fields was increased from 16 to 21.
Health report API now indicates shards capacity
If your cluster gets too close to its maximum shard capacity, important operations can come to a halt. You won’t be able to index new data, restore snapshots, open a closed index, or upgrade Elasticsearch without resolving the shard capacity issue by deleting indices, adding nodes, or increasing the limit itself.
To help detect and prevent that situation, we’ve added a Shards Capacity indicator to the new Health API. This indicator will turn yellow if there are less than 10 shards available under the currently configured limit, and red if there are less than 5 shards left.
For example, if you have a cluster with 3 data nodes and the default cluster.max_shards_per_node of 1,000 shards per non-frozen data node, you have a total limit of 3,000 shards. If you currently have 2,993 shards open, the health report will indicate Shards Capacity in yellow status.
This indicator will also show up in the Elastic Cloud Deployments console. As with the rest of the Health report, we’ll indicate the possible impact and include a link to a relevant troubleshooting guide.
Wait . . . there’s more!
Elastic 8.8 includes many other enhancements! Not only additional enhancements to Elasticsearch that you can learn from What’s New in 8.8 Elasticsearch, but also customizing the Kibana experience with your custom logo and accessing machine learning where its need naturally arises in the larger workflows, starting with Discover — check out What’s New in 8.8 Kibana for more details on that. And the release notes will provide you with the complete list of enhancements.
Try it out
Existing Elastic Cloud customers can access many of these features directly from the Elastic Cloud console. Not taking advantage of Elastic on cloud? Start a free trial.
The release and timing of any features or functionality described in this post remain at Elastic's sole discretion. Any features or functionality not currently available may not be delivered on time or at all.
Share
- Share on Twitter
Share on Twitter
- Share on LinkedIn
Share on LinkedIn
- Share on Facebook
Share on Facebook
- Share by Email
Share by email
- Print this page
Print

