Elastic 7.11 veröffentlicht: Allgemeine Verfügbarkeit von durchsuchbaren Snapshots und der neuen „kalten“ Datenebene sowie die Beta-Version von „Schema-on-Read“
Wir freuen uns, die allgemeine Verfügbarkeit von Elastic 7.11 bekanntgeben zu dürfen. Diese Version ergänzt unsere auf dem Elastic Stack basierenden Elastic Enterprise Search-, Observability- und Security-Lösungen - Elasticsearch und Kibana – um etliche neue Funktionen. Diese neue Version ermöglicht unseren Kunden Optimierungen im Hinblick auf Kosten, Leistung, Einblicke und Flexibilität mit der allgemeinen Verfügbarkeit von durchsuchbaren Snapshots und der Beta-Version von „Schema-on-Read“.
Mit der Beta-Version des neuen Webcrawlers in Elastic Enterprise Search sind Inhalte aus öffentlich zugänglichen Websites mühelos durchsuchbar. Elastic Observability enthält Verbesserungen in den Bereichen Ursachenanalysen, Fehlerbehebung und Observability für Anwendungen mit speziellen Ansichten für Serviceintegrität und Hostdetails. Erkennung und Wartung in Elastic Security wurden mit neuen Erkennungsregeln, Machine Learning-Aufträgen und anpassbaren Alerting-Benachrichtigungen verbessert, und zur Vereinfachung von SecOps wurde ein einheitlicher Arbeitsbereich für Analysten implementiert.
Wir präsentieren außerdem wichtige Verbesserungen in der Elastic Cloud, dem besten verwalteten Elastic-Service und dem einzigen Service, der all unsere Lösungen enthält. Die Elastic Cloud bietet umfassende Unterstützung für durchsuchbare Snapshots, automatische Skalierung für Daten- und Machine Learning-Knoten, verbesserte Verfügbarkeit und bessere Suchleistung mit der erweiterten Cluster-übergreifenden Replikation (CCR) und Suche (CCS). Elastic 7.11 ist ab sofort in der Elastic Cloud verfügbar, dem einzigen gehosteten Elasticsearch-Angebot, das alle Funktionen der neuen Version enthält. Wenn Sie Ihre Lösungen selbst verwalten möchten, können Sie auch den Elastic Stack und unsere Produkte für die Cloud-Orchestrierung (Elastic Cloud Enterprise und Elastic Cloud auf Kubernetes) herunterladen.

Wie bereits angekündigt, ändert Elastic die Lizenzierungsoptionen für Elasticsearch und Kibana mit Version 7.11. Der bisher unter Apache 2 lizenzierte Code unterliegt in Zukunft einer doppelten Lizenzierung mit der Elastic-Lizenz und SSPL. Außerdem haben wir umfassende Änderungen an der Elastic-Lizenz vorgenommen, um sie zu vereinfachen und freizügiger zu gestalten. Unsere Distribution sowie der Quellcode für sämtliche kostenlosen und kostenpflichtigen Features sind unter der Elastic-Lizenz v2 verfügbar, und der Quellcode für einen zentralen Teil unserer kostenlosen Features ist außerdem unter SSPL v1 verfügbar. Diese Änderung hat keine Auswirkungen auf unsere Kunden und auf den größten Teil unserer Community.
Lesen Sie weiter für die Highlights der neuesten Version. Eine vollständige Beschreibung der Features finden Sie in den verschiedenen Blogposts zu den einzelnen Lösungen und Produkten.
Elastic Stack
Speichern und durchsuchen Sie mehr Daten mit durchsuchbaren Snapshots für kostengünstige Objektspeicher und die neue „kalte“ Datenebene.
Mit durchsuchbaren Snapshots können Sie Daten in Snapshots durchsuchen, die in kostengünstigen Objektspeicherlösungen wie AWS S3, Microsoft Azure Storage und Google Cloud Storage gespeichert wurden. Außerdem können Sie die Balance zwischen Speicherkosten, Suchleistung und Umfang der aus den Daten in Ihrem Elasticsearch-Cluster gewonnenen Erkenntnisse transformieren. Durchsuchbare Snapshots können Ihre Speicherkosten beträchtlich reduzieren, da sie die neue, inzwischen allgemein verfügbare und in der Elastic Cloud integrierte „kalte“ Datenebene unterstützen, mit der Sie Ihre Infrastrukturkosten mit minimalen Leistungseinbußen um bis zu 50 % senken können.
Mit „Schema-on-Read“ und Laufzeitfeldern haben Sie die Wahl zwischen der Flexibilität und Kosteneffizienz von „Schema-on-Read“ und der überwältigenden Leistung von „Schema-on-Write“ zusammen im gleichen Stack.
Mit Laufzeitfeldern können Sie das Schema für Ihre Indizes zur Abfragezeit definieren. Diese neue Funktion befindet sich in 7.11 in der Beta-Phase und ermöglicht es Ihnen, neue Daten und Workflows zu entdecken, indem Sie Schemas dynamisch erstellen. Auf diese Weise können Sie mit beispielloser Flexibilität neue Einblicke gewinnen und das Verhältnis zwischen Kosten und Leistung frei definieren.
Elasticsearch ist bekannt als rasante verteilte Suchmaschine und Analytics Engine, da die Daten in strukturierten Indizes gespeichert werden, die beim Schreiben der Daten auf den Datenträger erstellt werden (Schema-on-Write). Für diese organisierte Struktur ist es wichtig, zu verstehen und zu planen, wie die Daten in Elasticsearch abgebildet werden. Dafür lassen sich jedoch große Vorteile in den Bereichen Geschwindigkeit, Skalierbarkeit und Relevanz erzielen. Manchmal ist es jedoch auch hilfreich, Daten auf neue Arten zu erkunden und zu untersuchen, ohne das Datenschema vorher zu planen. Mit „Schema-on-Read“ und Laufzeitfeldern können Sie dynamische Datenstrukturen zum Zeitpunkt der Suche erstellen. Diese Flexibilität beschleunigt den Erkenntnisgewinn, jedoch mit gewissen Einbußen im Hinblick auf die Gesamtleistung. Mit dem agilen Elastic-Ansatz können Sie je nach Art Ihrer Suche zwischen „Schema-on-Write“ und „Schema-on-Read“ wählen.
Laufzeitfelder werden in der aktuellen Version zum ersten Mal in Elasticsearch unterstützt, und wir haben vor, diese Integration in Zukunft auf Kibana auszuweiten. „Schema-on-Read“ ist in 7.11 in der Beta-Phase. Weitere Informationen finden Sie in unserem Blogpost zu Laufzeitfeldern.
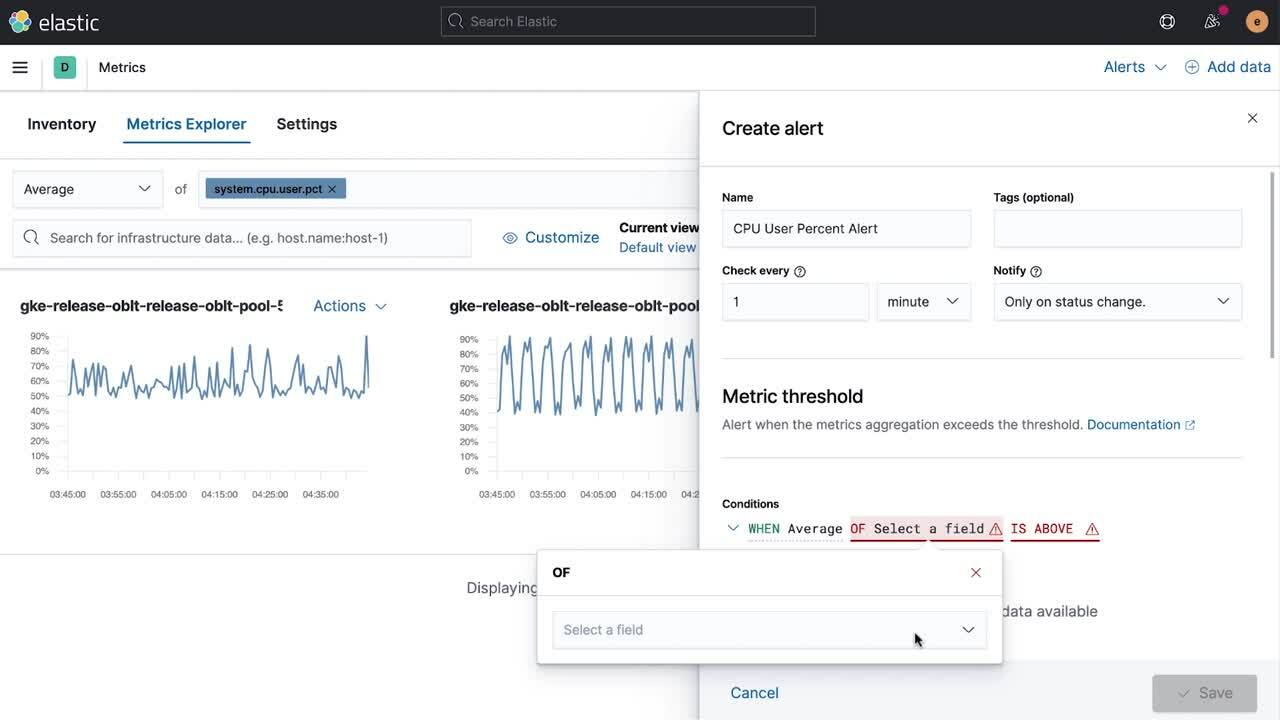
Mit dem neuerdings allgemein verfügbaren Alerting-Framework können Sie Warnungen und Benachrichtigungen im gesamten Elastic Stack und in externen Systemen erstellen, verwalten und überwachen.
Unabhängig von Ihrem Aufgabenfeld ist es entscheidend, dass Sie sofort informiert werden, wenn etwas Wichtiges in Ihrem digitalen Ökosystem geschieht. Zeitnahe Warnungen für wichtige Änderungen sind entscheidend, um auf datengestützte Einblicke reagieren zu können, egal ob es um erkannte Bedrohungen, Leistungswarnungen für Anwendungen oder um die Nachverfolgung physischer Assets geht. Vor acht Monaten haben wir die Beta-Version unseres neuen Alerting-Frameworks genau zu diesem Zweck im Elastic Stack veröffentlicht, und mit Version 7.11 ist dieses neue Alerting-Framework jetzt allgemein verfügbar.
Die Community hat dieses Framework in der Beta-Phase begeistert aufgenommen und uns darin bestärkt, ein Framework zu entwickeln, das umfassend in sämtliche Lösungen im Elastic Stack integriert ist. Außerdem lässt es sich einfach zentral verwalten und beschränkt sich nicht nur auf die Erkennung, sondern unterstützt auch Maßnahmen und die direkte Integration von Elastic in Ihre Workflows. Die Alerting-Benutzeroberfläche ist direkt in die Elastic Security- und Elastic Observability-Lösungen integriert, und wir haben das Framework um verschiedene externe Integrationen mit Plattformen wie PagerDuty, ServiceNow und Microsoft Teams erweitert. Die Warnungen können mit der rollenbasierten Zugriffssteuerung mühelos verwaltet werden.
Weitere Informationen zu diesen Funktionen und mehr finden Sie im Blogpost zu Kibana 7.11 und im Blogpost zu Elasticsearch 7.11.
Elastic Enterprise Search
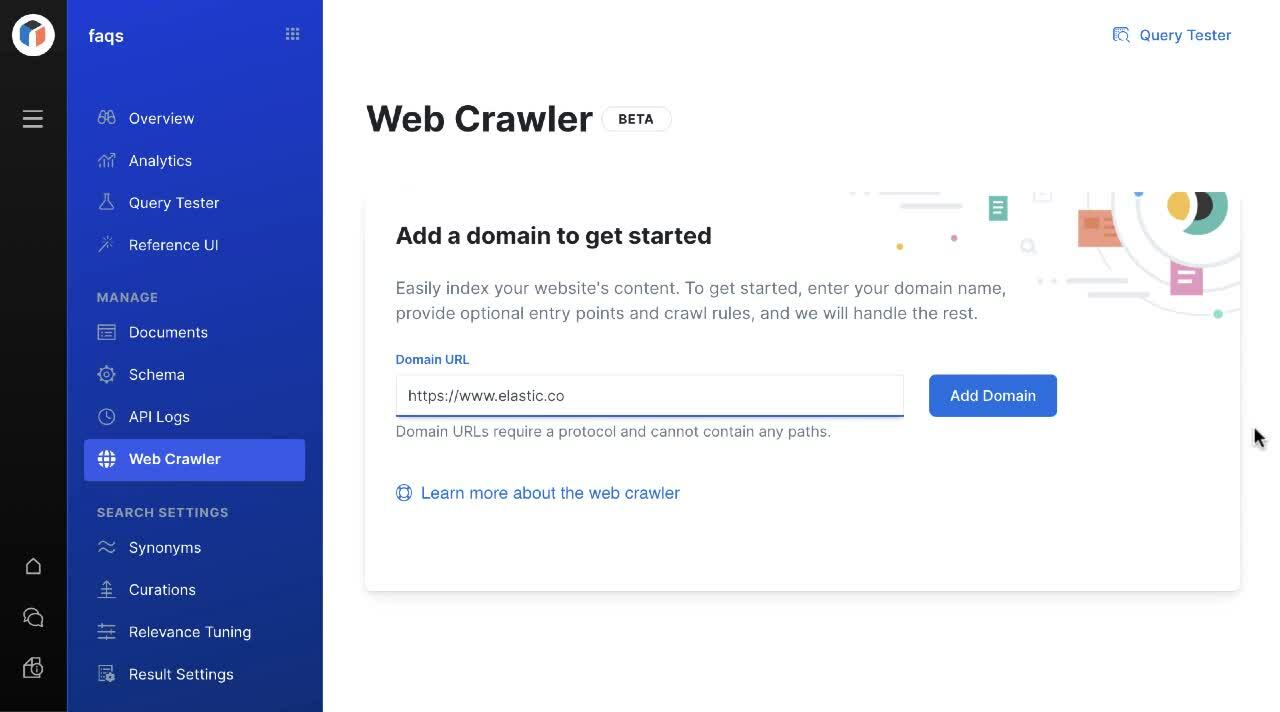
Machen Sie Inhalte aus öffentlich zugänglichen Websites mühelos durchsuchbar mit dem neuen Webcrawler für Elastic App Search.
Inhalte können auf viele verschiedene Arten durchsuchbar gemacht werden. Mit Elastic App Search können die Benutzer bereits Inhalte ingestieren, indem sie JSON hochladen oder einfügen oder API-Endpunkte verwenden. Ab Elastic Enterprise Search 7.11 können die Benutzer Inhalte mit einem leistungsstarken Webcrawler ingestieren, der Informationen aus öffentlich zugänglichen Websites abruft und in Ihren App Search Engines mühelos durchsuchbar macht. Wie auch bei den anderen Ingestionsmethoden in App Search wird das Schema beim Ingestieren abgeleitet und kann mit einem Mausklick praktisch in Echtzeit aktualisiert werden. Die Regeln für den Webcrawler können per Mausklick und ohne Code angepasst werden, um Einstiegspunkte festzulegen und Ausschlussregeln zu definieren, die dem Webcrawler mitteilen, welche Seiten, Inhalte und Begriffe gemieden werden sollen.
Suchinhalte in einem Feld, ein führendes Content Management-System mit Elastic Workplace Search.
Box war einer der ersten Pioniere für cloudbasierte Speichersysteme und hat sich inzwischen zu einem führenden Content Management-System in der Cloud mit Millionen Benutzern weltweit entwickelt. Elastic Enterprise Search unterstützt Box jetzt als Inhaltsquelle in Workplace Search. Der integrierte Connector enthält Berechtigungen auf Dokumentebene, damit jeder Benutzer nur die für ihn bestimmten Daten sieh, und sonst nichts. Die Box-Integration ergänzt das bereits vorhandene Portfolio von Inhaltsquellen in Workplace Search, inklusive Google Drive und Dropbox.
Erweitern Sie Ihre differenzierten Zugriffskontrollen mit Berechtigungen auf Dokumentebene für Atlassian Jira Cloud und Confluence Cloud für Elastic Workplace Search.
Nicht alle Inhalte sind beim Erstellen – oder Teilen – gleich. Sensible und private Inhalte müssen mit explizit definierten Personen oder Gruppen geteilt werden, und Zugriffskontrollen auf Dokumentebene sind für diese Dateien noch wichtiger, wenn sie leicht durchsuchbar sind. Elastic Workplace Search bietet jetzt Berechtigungen auf Dokumentebene für Atlassian Jira Cloud und Confluence Cloud, und die Berechtigungen aus diesen Quellanwendungen werden nach Elastic Workplace Search vererbt.
Einen Überblick über alle neuen Features in Elastic Enterprise Search erhalten Sie im Blogpost zu Elastic Enterprise Search 7.11.
Elastic Observability
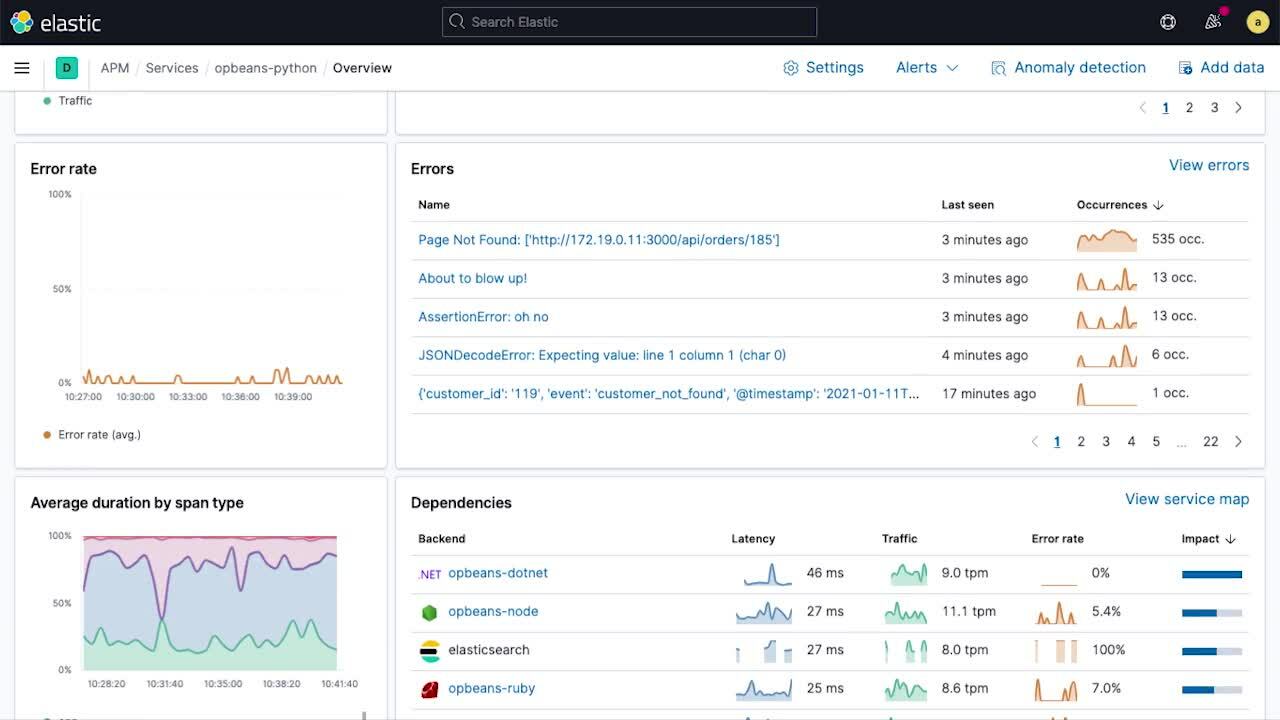
Beschleunigen Sie Ursachenanalyse und Fehlerbehebung mit der neuen Serviceintegritäts-Ansicht in Elastic APM.
Moderne native Cloudanwendungen bestehen üblicherweise aus Hunderten von Microservices, und für die Workflows zur Untersuchung von Incidents ist es entscheidend, die Leistung und Integrität einzelner Services schnell bestimmen zu können. Die neue Serviceübersichtsseite enthält eine Zusammenfassung aller Informationen zur Integrität von Services an einem Ort und erleichtert es Entwicklern und SREs, Leistungsprobleme zu beheben.
Zeitreihendiagramme für Servicelatenz, Datenverkehr und Fehlerraten bieten einen grundlegenden Überblick über die Entwicklung von Service-Kennzahlen. Überlagerte Anmerkungen wie etwa Deployment-Markierungen und Hinweise zu Anomalien liefern umfassende Kontextinformationen für wichtige Ereignisse, die möglicherweise zu Verhaltensänderungen beigetragen haben. Die Serviceübersichtsseite verwendet Sparklines, um die zeitbasierten Trends von Teilkomponenten kompakt darzustellen, die Erkennung ungewöhnlicher Änderungen zu erleichtern und Untersuchungen zu vereinfachen. Auf der Serviceübersichtsseite wird außerdem die Dienstintegrität nach den zugrunde liegenden Infrastrukturinstanzen (z. B. Container) aufgeschlüsselt, auf denen ein Service bereitgestellt wurde, um Probleme direkt zur entsprechenden Infrastruktur zuordnen zu können.
In zukünftigen Versionen werden wir noch mehr Kontextinformationen und Ansichten hinzufügen, um die Workflows für Fehlerbehebung und Ursachenanalyse noch weiter zu vereinfachen und zu beschleunigen.
Beheben Sie Infrastrukturprobleme noch schneller mit der neuen Hostdetailansicht in Elastic Metrics.
Mit der Ressourcen-Heatmap in der Elastic Metrics-App können Sie Probleme in Ihrer Infrastruktur erkennen und die nächsten Schritte für Ihre Untersuchung eingrenzen. In einer neuen Ansicht in der Metrics-Benutzeroberfläche können Sie mühelos von der höchsten Ebene zum Geschehen auf einem einzelnen Host wechseln. Klicken Sie auf eine Kachel in der Heatmap, um ein Popupfenster mit wichtigen Informationen zu öffnen, darunter Zeitleistendiagramme für wichtige Host-Metriken, vom Host generierte Logs, auf dem Host ausgeführte Prozesse und Host-Metadaten.
Erweitern Sie Ihre Kontextinformationen, indem Sie Logs und Traces automatisch mit neuen Logging-Bibliotheken im Elastic Common Schema (ECS) verknüpfen.
Für die Anwendungs-Fehlerbehebung ist es wichtig, Anwendungs-Logs und Traces korrelieren und zwischen ihnen hin- und herwechseln zu können, ohne den Kontext zu verlieren. Die Logging-Bibliotheken im Elastic Common Schema (ECS) erleichtern es Anwendungsentwicklern, den vom APM-Agent erfassten Trace-Kontext automatisch in ihre Anwendungs-Logs zu injizieren, um die für eine reibungslose Analyse erforderliche Korrelation zwischen Logs und Traces herstellen zu können.
ECS-Logging-Bibliotheken sind Plugins für Ihre bevorzugten Logging-Frameworks, wie etwa log4j, und Entwickler können Anwendungs-Logs im ECS-kompatiblen JSON-Format schreiben, ohne ihre nativen Workflows zu ändern. Die ECS-Logger schreiben den vom APM-Agent erfassten Trace-Kontext automatisch in das Log, damit die Entwickler ohne zusätzlichen Aufwand Observability für ihre Anwendungen implementieren können.
Ausführliche Informationen zu allen neuen Features finden Sie im Blogpost zu Elastic Observability 7.11.
Elastic Security
Nutzen Sie Sicherheitsdaten in großem Umfang mit durchsuchbaren Snapshots und einer „kalten“ Datenebene.
Mit Elastic 7.11 präsentieren wir die allgemeine Verfügbarkeit von durchsuchbaren Snapshots sowie eine „kalte“ Datenebene für Objektspeicher wie Amazon S3. Sicherheitsteams können jetzt direkt auf riesige Datenvolumen zugreifen, ihre Kosten um bis zu 50 % senken und verschiedenste Anwendungsfälle wie etwa Abwehr, Untersuchung und Profiling von Bedrohungen, Compliance, forensische Analysen und Adversary Emulation unterstützen. Bewahren Sie Ihre Sicherheitsdaten länger auf, damit Ihre Experten auch bei einer extrem langen Verweildauer von Bedrohungen alle erforderlichen Daten zur Hand haben. Datenquellen wie Cloud-Plattformen und -Anwendungen, IDS/IPS, DNS, übertragene Daten, Hostaktivität, Observability-Daten, MDM, IoT, OT – und viele weitere Daten, deren Integration in den alltäglichen Betrieb normalerweise zu teuer ist – können in größerem Umfang vorgehalten werden. Sicherheitsteams können sogar Daten automatisch analysieren, die andernfalls archiviert oder verworfen würden.
Entdecken Sie Angriffe gegen Apps und Hosts in der Cloud mit vorab erstellten Machine Learning-Aufträgen und Erkennungsregeln, die einen Teil der MITRE-Techniken unterstützen.
Elastic Security 7.11 schützt moderne Unternehmens-Stacks mit aktualisierten Machine Learning-Aufträgen und neuen Erkennungsregeln. Diese von Elastic entwickelten Erkennungsmethoden unterstützen einen Teil der MITRE ATT&CK®-Techniken, liefern bessere Einblicke in den Verlauf von Angriffen in Ihrem Unternehmen und verbessern die Kompatibilität mit dem ATT&CK®-Framework.
Vorab erstellte Erkennungsmethoden für Cloud-Anwendungen können Techniken und Verhaltensweisen von Angriffen auf SaaS-Technologien wie Google Workspace, Microsoft 365 und Okta automatisch erkennen und ergänzen den vorhandenen Elastic-Schutz für IaaS-Technologien. Vorab erstellte Sicherheitsanalysen für Windows- und Linux-Umgebungen können vielerlei Aktivitäten von Angreifern zentral erkennen und befassen sich hauptsächlich mit den Bereichen Persistenz, Rechteausweitung und Lateral Movement.
Die Elastic-Sicherheitsforscher haben vor Kurzem eine erweiterte Methode zur Erkennung von Domain Generation Algorithms (DGA) vorgestellt, um die Erkennung von SUNBURST und anderen Angriffen zu verbessern. Weitere Informationen finden Sie in unserem Blogpost zur DGA-Erkennung mit Machine Learning.
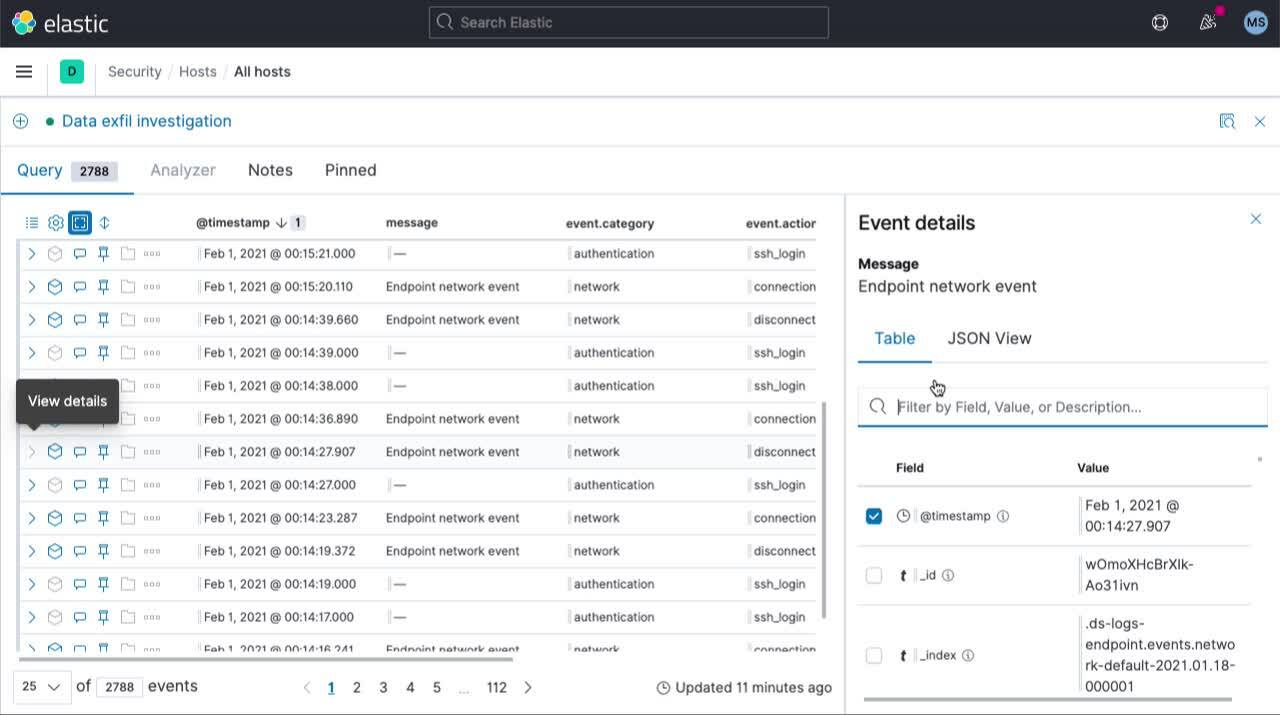
Vereinfachen Sie SOC-Workflows und verkürzen Sie Ihre Reaktionszeiten mit einer verbesserten Benachrichtigungsverwaltung, umfassenderen Regelaktionen, einem aktualisierten Zeitleisten-Arbeitsbereich und einer barrierefreien Navigation.
Mit der vereinfachten Benachrichtigungsverwaltung können Analysten Bedrohungen noch schneller beheben. Anpassbare Benachrichtigungen liefern wichtige Kontextdaten für externe Workflow-Tools wie Slack oder ServiceNow, um Analysen schneller und mit weniger Kontextwechseln durchführen zu können. Analysten können Warnungen jetzt direkt an Fälle anfügen, um Responder zu koordinieren und relevante Informationen zu zentralisieren. Die Integrationen mit Jira, ServiceNow und IBM Resilient wurden mit zusätzlichen Regelaktionen vertieft, um die SOC-Effizienz zu verbessern.
Der aktualisierte Zeitleisten-Arbeitsbereich verbessert die Effizienz bei der Bedrohungsabwehr sowie bei der Analyse und Untersuchung von Warnungen. Öffne Sie wichtige Informationen in separaten Registerkarten, zeigen Sie Ereignisse in einer Vollbildansicht an und greifen Sie auf Ereignisdetails zu, ohne die umgebenden Ereignisse aus dem Blick zu verlieren. Wechseln Sie mühelos zwischen mehreren Zeitleisten hin und her, die Sie jederzeit mit Drag & Drop-Feldern aktualisieren können.
Elastic Security 7.11 bietet eine barrierefreie Navigation dank erweiterten Tastaturfunktionen und Unterstützung für Sprachausgabeprogramme und ist somit auch für Benutzer geeignet, die diese Funktionen in ihren Tools für den Alltag benötigen. Wir hoffen, dass die neuen Funktionen diesen und anderen Power-Benutzern (Hallo, Hotkeys!) gefallen werden.
Weitere Details finden Sie im Blogpost zu Elastic Security 7.11.
Elastic Cloud
Verdoppeln Sie Ihre Speicherdichte oder sparen Sie Infrastrukturkosten mit der neuen „kalten“ Datenebene, durchsuchbaren Snapshots und Objektspeichern wie S3.
Elastic Cloud unterstützt die neuen durchsuchbaren Snapshots und die „kalte“ Datenebene mit einem benutzerfreundlichen Schieberegler in der Elastic Cloud-Konsole. Mit diesem Steuerelement können Sie mühelos eine kostengünstige Datenaufbewahrungsstrategie implementieren und mit demselben Budget mehr Daten länger aufbewahren.
Mit einer Heiß-Warm-Kalt-Architektur können Sie Ihre Daten kostengünstiger speichern und exakt steuern, wie und wo Ihre Zeitreihendaten im Verlauf der Zeit gespeichert werden. Sie können aktuelle, besonders relevante und häufig benötigte Daten in einer „heißen“ oder „warmen“ Ebene speichern. Mit dem Index-Lifecycle-Management können Sie weniger aktive schreibgeschützte Daten automatisch in die „kalte“ Ebene und somit in einen kostengünstigen und robusten Objektspeicher wie Amazon S3, Azure Blob Storage oder Google Cloud Storage verschieben.
Mit Deployment-Vorlagen können Sie schnell den Betrieb aufnehmen, und die Schieberegler für „warme“ und „kalte“ Ebenen sind in allen Vorlagen für die Verwaltung Ihrer Datenrichtlinien in vorhandenen und in neuen Deployments verfügbar. Die Elastic Cloud ist der einfachste Weg, um durchsuchbare Snapshots und die „kalte“ Datenebene zu nutzen.
Skalieren und vereinfachen Sie Ihren Cloud-Betrieb mit der automatischen Skalierung für Daten- und Machine Learning-Knoten.
Befreien Sie sich von der Last, Ihre Ressourcen ständig überwachen und verwalten zu müssen, und lassen Sie Ihren Cluster automatisch wachsen, um Ihre Kapazitätsanforderungen zu erfüllen. Die Flexibilität, Ihre Daten- und Machine Learning-Knoten automatisch zu skalieren, ist demnächst in der Elastic Cloud verfügbar. Mit der automatischen Skalierung von Datenknoten steht Ihnen immer die benötigte Kapazität zur Verfügung, auch wenn die Menge der ingestierten und indexierten Daten zunimmt. Mit der automatischen ML-Skalierung können Sie Ihre Machine Learning-Kapazität nahtlos erweitern, ohne Speicherlimits zu erreichen. Wir haben vor, unsere automatischen Skalierungsfunktionen in Zukunft zu erweitern, um weitere Metriken und Anwendungsfälle zu unterstützen. Erweitern Sie Ihre Elastic-Anwendungsfälle im Wissen, dass Sie Ihre Infrastruktur nahtlos und automatisch skalieren können.
Replizieren und durchsuchen Sie Daten in unterschiedlichen Regionen und Cloudanbietern, um die Verfügbarkeit und Suchleistung mit der erweiterten Cluster-übergreifenden Replikation (CCR) und Suche (CCS) zu verbessern.
Die erweiterte Cluster-übergreifende Replikation und Suche für unterschiedliche Regionen und Cloudanbieter ist jetzt verfügbar. Nutzen sie die Freiheit, Ihre Daten auf Cluster in unterschiedlichen Regionen und Cloudanbietern zu replizieren und dort zu durchsuchen.
Mit CCS können Sie eine beliebige Anzahl von Clustern durchsuchen, um all Ihre Daten in einer einzigen, zusammenhängenden Ansicht zu visualisieren. Auf diese Weise können Sie Datensilos abschaffen, Ihre Daten so behandeln, als befänden sie sich in einem einzigen Cluster, und neue Einblicke gewinnen. Mit CCR können Sie Kopien von Daten zwischen unterschiedlichen Clustern replizieren und speichern, Suchabfragen auch nach einem Ausfall eines Rechenzentrums ausführen, zentralisierte Daten aus mehreren Clustern an einem Ort erstellen, um sie mühelos lokal zu analysieren und zu aggregieren, und Ihre Daten näher zu den Endbenutzern bringen, um die Latenz zu reduzieren.
Für die Bereitstellung dieser Funktionen über Regionen und Cloudanbieter hinweg waren beträchtliche Innovationen in den Bereichen Sicherheit, Vertrauen und Netzwerktopologie erforderlich, aber wir haben diese Arbeit auf uns genommen, um unseren Kunden die Nutzung dieser Features in ihren Deployments zu erleichtern.
Die neuesten Ankündigungen zur Elastic Cloud finden Sie in unserem Blogpost zu den Neuigkeiten in Elastic Cloud 7.11.
Wie immer gibt es noch viel mehr zu berichten –
viel, viel mehr! Nähere Informationen zu allen Neuerungen in Version 7.11 finden Sie in den Blogposts zu den einzelnen Lösungen und Produkten:
Elastic Stack
Elasticsearch 7.11.0 veröffentlicht
Elastic-Lösungen
Elastic Enterprise Search 7.11.0 veröffentlicht
Elastic Observability 7.11.0 veröffentlicht
Elastic Security 7.11.0 veröffentlicht
Elastic Cloud
Neuigkeiten in Elastic Cloud für 7.11
Erste Schritte mit einer kostenlosen Testversion der Elastic Cloud