Was ist überwachtes Machine Learning?
Definition: überwachtes Machine Learning
Überwachtes Machine Learning, oder überwachtes Lernen, ist eine Art von Machine Learning (ML), die in Anwendungen künstlicher Intelligenz (KI) verwendet wird, um Algorithmen anhand von beschrifteten Datensätzen zu trainieren. Beim überwachten Machine Learning wird ein Algorithmus mit großen markierten Datensätzen gefüttert, damit er lernt, die Ergebnisse genau vorherzusagen. Es ist die am häufigsten verwendete Art des Machine Learning.
Überwachtes Machine Learning funktioniert wie jedes Machine Learning über Mustererkennung. Durch die Analyse eines bestimmten Satzes markierter Daten kann ein Algorithmus Muster erkennen und auf der Grundlage dieser abgeleiteten Muster Vorhersagen erstellen, wenn diese abgefragt werden. Um eine genaue Vorhersage treffen zu können, müssen beim überwachten Machine Learning zunächst Daten gesammelt und dann beschriftet werden. Anschließend wird der Algorithmus anhand dieser gekennzeichneten Daten trainiert, um Daten zu klassifizieren oder Ergebnisse genau vorherzusagen. Die Qualität der Ausgabe hängt direkt von der Qualität der Daten ab: Bessere Daten bedeuten bessere Vorhersagen.
Beispiele für überwachtes Machine Learning reichen von der Bild- und Objekterkennung über die Analyse der Kundenstimmung bis hin zur Spam-Erkennung und prädiktiven Analytik. Daher wird überwachtes Machine Learning in verschiedenen Branchen wie dem Gesundheitswesen, dem Finanzwesen und dem elektronischen Handel eingesetzt, um die Entscheidungsfindung zu optimieren und Innovationen voranzutreiben.
Wie funktioniert überwachtes Machine Learning?
Überwachtes Machine Learning funktioniert durch das Sammeln und Kennzeichnen von Daten, das anschließende Trainieren von Modellen und die Wiederholung des Prozesses mit neuen Datensätzen. Es ist ein zweistufiger Prozess: Definition des Problems, das das Modell lösen soll, gefolgt von der Datenerfassung:
- Schritt 1: Definieren des Problems, das das Modell lösen soll. Wird das Modell verwendet, um geschäftsbezogene Vorhersagen zu treffen, die Spam-Erkennung zu automatisieren, die Stimmung der Kunden zu analysieren oder Bilder zu identifizieren? Dadurch wird bestimmt, welche Daten benötigt werden, was zum nächsten Schritt im Arbeitsablauf führt
- Schritt 2: Sammeln der Daten. Sobald die Daten beschriftet sind, werden sie dem Trainingsalgorithmus zugeführt. Das Modell wird dann getestet, verfeinert und bereitgestellt, um Klassifizierungs- oder Regressionsaufgaben auszuführen.
Datenerfassung und Etikettierung
Das Sammeln von Daten ist der erste Schritt beim überwachten Machine Learning. Daten können aus verschiedenen Quellen wie Datenbanken, Sensoren oder Benutzerinteraktionen stammen. Es ist vorverarbeitet, um Einheitlichkeit und Relevanz zu gewährleisten. Nach der Erfassung werden diesem großen Datensatz Bezeichnungen zugewiesen. Jedes Element der Eingabedaten erhält eine entsprechende Bezeichnung. Die Datenklassifizierung kann zwar zeitaufwändig und teuer sein, aber es ist notwendig, die Modellmuster zu vermitteln, damit sie Vorhersagen treffen können. Die Qualität und Genauigkeit dieser Bezeichnungen wirken sich direkt auf die Fähigkeit des Modells aus, zu lernen und relevante Vorhersagen zu treffen. Ihr Ausgang ist nur so gut wie Ihr Eingang.
Trainieren des Modells
Während des Trainings analysiert der Algorithmus die Eingabedaten und lernt, sie den richtigen Ausgabebeschriftungen zuzuordnen. Bei diesem Prozess werden die Parameter des Modells angepasst, um die Differenz zwischen den vorhergesagten Ausgaben und den tatsächlichen Beschriftungen zu minimieren. Das Modell verbessert seine Genauigkeit, indem es aus den Fehlern, die es beim Training macht, lernt. Sobald das Modell trainiert wurde, wird es einer Bewertung unterzogen. Validierungsdaten werden verwendet, um die Genauigkeit eines Modells zu bestimmen. Abhängig von den Ergebnissen wird es dann nach Bedarf fein abgestimmt.
Je mehr Daten ein Modell aufnimmt, desto mehr Muster lernt es und desto genauer werden seine Vorhersagen – theoretisch. Kontinuierliches Lernen ist ein Eckpfeiler des Machine Learning: Die Leistung des Modells wird besser, da es kontinuierlich aus gekennzeichneten Datensätzen lernt.
Sobald es eingesetzt wird, kann überwachtes Machine Learning zwei Arten von Aufgaben erfüllen: Klassifizierung und Regression.
Die Klassifizierung stützt sich auf einen Algorithmus, der einem gegebenen diskreten Datenpunkt oder -satz eine Klasse zuordnet. Mit anderen Worten: Es wird zwischen Datenkategorien unterschieden. Bei Klassifizierungsproblemen legt die Entscheidungsgrenze Klassen fest.
Die Regression stützt sich auf einen Algorithmus, um die Beziehung zwischen kontinuierlichen abhängigen und unabhängigen Datenvariablen zu verstehen. Bei Regressionsproblemen legt die Entscheidungsgrenze die Best-Fit-Linie oder die wahrscheinliche Annäherung fest.
Überwachte Machine-Learning-Algorithmen
Beim überwachten Machine Learning werden unterschiedliche Algorithmen und Techniken für Klassifizierungs- und Regressionsaufgaben verwendet, von der Textklassifizierung bis hin zu statistischen Vorhersagen.
Entscheidungsbaum
Ein Entscheidungsbaum-Algorithmus ist ein nicht-parametrischer überwachter Lernalgorithmus, der aus einem Wurzelknoten, Zweigen, internen Knoten und Blattknoten besteht. Die Eingabe wandert vom Stammknoten durch die Zweige zu den internen Knoten, wo der Algorithmus die Eingabe verarbeitet und eine Entscheidung trifft und Blattknoten ausgibt. Entscheidungsbäume können sowohl für Klassifizierungs- als auch für Regressionsaufgaben verwendet werden. Sie sind hilfreiche Tools für Data Mining und Knowledge Discovery: Sie ermöglichen es dem Benutzer nachzuvollziehen, warum eine Ausgabe produziert oder eine Entscheidung getroffen wurde. Allerdings neigen Entscheidungsbäume zur Überanpassung; sie haben Schwierigkeiten, mit mehr Komplexität umzugehen. Aus diesem Grund sind kleinere Entscheidungsbäume effektiver.
Lineare Regression
Lineare Regressionsalgorithmen sagen den Wert einer Variable – der abhängigen Variable – auf der Grundlage des Wertes einer anderen – der unabhängigen Variable – voraus. Vorhersagen beruhen auf dem Prinzip einer linearen Beziehung zwischen Variablen oder der Annahme, dass es eine „geradlinige“ Verbindung zwischen kontinuierlichen Variablen wie Gehalt, Preis oder Alter gibt. Lineare Regressionsmodelle werden verwendet, um Vorhersagen in den Bereichen Biologie, Sozial-, Umwelt- und Verhaltenswissenschaften und Wirtschaft zu treffen.
Neuronale Netze
Neuronale Netze verwenden Knoten, die aus Eingaben, Gewichten, Schwellenwerten (manchmal als Bias bezeichnet) und Ausgaben bestehen. Diese Knoten sind in einer Struktur aus Eingabe-, versteckten und Ausgabeschichten geschichtet, die dem menschlichen Gehirn ähnelt – daher der Begriff neural. Neuronale Netze, die als Deep-Learning-Algorithmen betrachtet werden, bauen eine Wissensbasis aus beschrifteten Trainingsdaten auf. Daher können sie komplexe Muster und Beziehungen innerhalb der Daten erkennen. Sie sind ein adaptives System und können aus ihren Fehlern „lernen“, um sich kontinuierlich zu verbessern. Neuronale Netzwerke können in Anwendungen zur Bilderkennung und Sprachverarbeitung eingesetzt werden.
Random Forest
Random-Forest-Algorithmen sind eine Sammlung (oder ein Wald) von unkorrelierten Entscheidungsbaum-Algorithmen, die so programmiert sind, dass sie aus mehreren Ausgaben ein einziges Ergebnis erzeugen. Zu den Parametern des Random-Forest-Algorithmus gehören die Knotengröße, die Anzahl der Bäume und die Anzahl der Merkmale. Diese Hyperparameter werden vor dem Trainieren festgelegt. Ihr Vertrauen in Bagging- und Zufallsmethoden sorgt für Datenvariabilität im Entscheidungsprozess und führt letztendlich zu genaueren Vorhersagen. Dies ist der Hauptunterschied zwischen Entscheidungsbäumen und Random Forests. Infolgedessen ermöglichen Random-Forest-Algorithmen eine höhere Flexibilität. Das Feature Bagging hilft bei der Schätzung fehlender Werte, was die Genauigkeit gewährleistet, wenn bestimmte Datenpunkte fehlen.
Support Vector Machine (SVM)
Support Vector Machines (SVM) werden am häufigsten für die Datenklassifizierung und gelegentlich für die Datenregression verwendet. Für Klassifizierungsanwendungen erstellt eine SVM eine Entscheidungsgrenze, die bei der Unterscheidung oder Klassifizierung von Datenpunkten hilft, z. B. Obst vs. Gemüse oder Säugetiere vs. Reptilien. SVM kann für Bilderkennung oder Textklassifizierung verwendet werden.
Naive Bayes
Naïve Bayes ist ein probabilistischer Klassifizierungsalgorithmus, der auf dem Theorem von Bayes basiert. Er geht davon aus, dass die Merkmale in einem Datensatz unabhängig sind und dass jedes Merkmal bzw. jeder Prädiktor ein gleiches Gewicht im Ergebnis hat. Diese Annahme wird als „naiv“ bezeichnet, weil sie in einem realen Szenario oft widerlegt werden kann. Zum Beispiel hängt das nächste Wort in einem Satz von dem ab, das davor steht. Trotzdem macht die einzige Wahrscheinlichkeit jeder Variablen die Algorithmen von Naive Bayes recheneffizient, insbesondere für Textklassifizierungs- und Spam-Filteraufgaben.
K-Nearest Neighbors
K-Nearest Neighbor, auch bekannt als KNN, ist ein Algorithmus für überwachtes Lernen, der die Nähe von Variablen verwendet, um Ausgaben vorherzusagen. Mit anderen Worten geht er von der Annahme aus, dass ähnliche Datenpunkte nahe beieinander liegen. Sobald der Algorithmus mit markierten Daten trainiert wurde, berechnet er den Abstand zwischen einer Anfrage und den gespeicherten Daten – seiner Wissensbasis – und formuliert eine Vorhersage. KNN kann verschiedene Methoden zur Abstandsberechnung verwenden (Manhattan, Euklidisch, Minkowski, Hamming), um die Entscheidungsgrenze festzulegen, auf der die Vorhersage basiert. KNN wird für Klassifizierungs- und Regressionsaufgaben verwendet, einschließlich Relevanzranking, Ähnlichkeitssuche, Mustererkennung und Produktempfehlungsmaschinen.
Herausforderungen und Grenzen des überwachten Machine Learning
Obwohl überwachtes Machine Learning ein hohes Maß an Genauigkeit bei Vorhersagen ermöglicht, ist es eine ressourcenintensive maschinelle Lerntechnik. Es ist auf teure Datenbeschriftungsprozesse angewiesen, erfordert große Datensätze und ist daher anfällig für Überanpassung.
- Die Kosten für die Kennzeichnung von Daten: Eine der größten Herausforderungen beim überwachten Lernen ist der Bedarf an großen, genau beschrifteten Datensätzen. Die Genauigkeit dieser Beschriftungen ist direkt proportional zur Genauigkeit eines Modells, daher ist die Qualität von größter Bedeutung. Das ist ein zeitaufwändiger Aufwand, der manchmal Expertenwissen erfordert (abhängig von den Daten und dem Verwendungszweck des Modells), was wiederum sehr teuer sein kann. In Bereichen wie dem Gesundheitswesen oder dem Finanzwesen, in denen die Daten sensibel und komplex sind, kann es eine besondere Herausforderung sein, qualitativ hochwertige beschriftete Datensätze zu erhalten.
- Bedarf an großen Datensätzen: Die Abhängigkeit eines überwachten Lernmodells von großen Datensätzen kann aus zwei Gründen eine große Herausforderung darstellen: Das Sammeln und Kennzeichnen großer Mengen hochwertiger Daten ist ressourcenintensiv, und es ist schwierig, das richtige Gleichgewicht zwischen zu vielen und ausreichend guten Daten zu finden. Große Datensätze sind für ein effektives Training notwendig, aber zu große Datensätze führen zu einer Überanpassung.
- Überanpassung: Die Überanpassung ist ein häufiges Problem beim überwachten Lernen. Es tritt auf, wenn ein Modell zu vielen Trainingsdaten ausgesetzt ist und Geräusche oder irrelevante Details erfasst. Es gibt also so etwas wie zu viele Daten. Dies beeinträchtigt die Qualität der Vorhersagen und führt zu einer schlechten Leistung bei neuen, ungesehenen Daten. Um einer Überanpassung entgegenzuwirken oder sie zu vermeiden, verlassen sich Informatiker auf Kreuzvalidierungs-, Regularisierungs- oder Beschneidungstechniken.
Im Mittelpunkt dieser Herausforderungen steht die Vorverarbeitung von Daten. Dies kann zeitaufwändig und teuer sein, mit den richtigen Werkzeugen lassen sich die Herausforderungen hinsichtlich Kosten, Qualität und Überanpassung jedoch mildern.
Überwachtes vs. unüberwachtes Machine Learning
Machine Learning kann überwacht, unüberwacht und halbüberwacht sein. Jede Datentrainingsmethode erzielt unterschiedliche Ergebnisse und wird in unterschiedlichen Kontexten verwendet. Das überwachte Machine Learning erfordert beschriftete Datensätze, um Daten zu trainieren, verbessert aber seine Genauigkeit dank großer, hochwertiger Datensätze.
Im Gegensatz dazu werden beim unüberwachten Machine Learning unbeschriftete Datensätze verwendet, um ein Modell für Vorhersagen zu trainieren. Das Modell erkennt selbstständig Muster zwischen unbeschrifteten Datenpunkten, was manchmal zu einer geringeren Genauigkeit führt. Unüberwachtes Lernen wird häufig für Clustering-, Assoziations- oder Dimensionalitätsreduktionsaufgaben verwendet.
Halbüberwachtes Machine Learning
Halbüberwachtes Machine Learning ist eine Kombination aus überwachten und unüberwachten Lerntechniken. Halbüberwachte Lernalgorithmen werden anhand kleiner Mengen gekennzeichneter Daten und größerer Mengen ungekennzeichneter Daten trainiert. Dadurch werden bessere Ergebnisse erzielt als mit unüberwachten Lernmodellen mit weniger gekennzeichneten Beispielen. Halbüberwachtes Lernen ist eine hybride Methode, die besonders nützlich sein kann, wenn die Kennzeichnung großer Datensätze unpraktisch oder teuer ist.
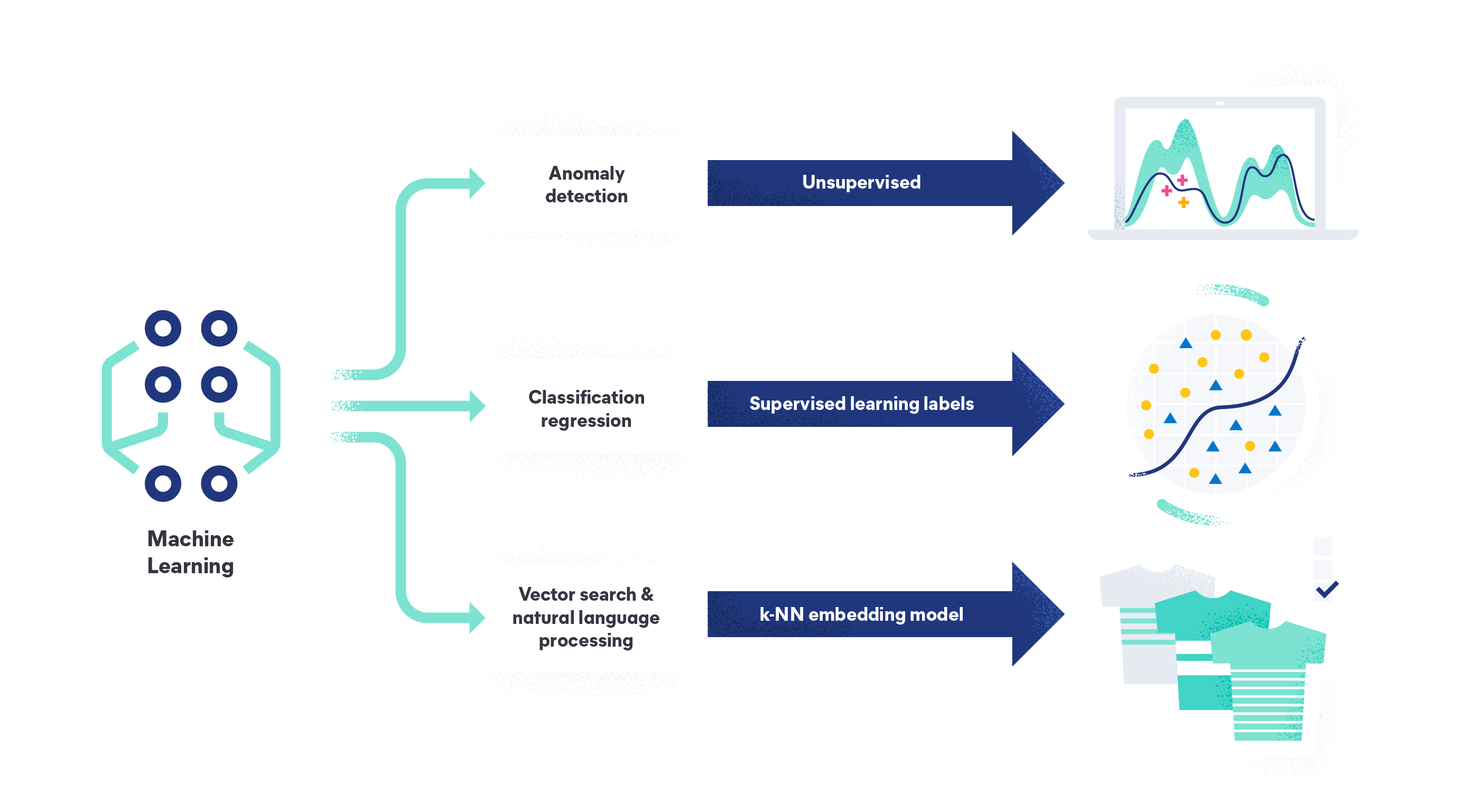
Das Verständnis des Unterschieds zwischen diesen Methoden des maschinellen Lernens ist entscheidend für die Wahl der richtigen Lösung für die anstehende Aufgabe.
Machine Learning leicht gemacht mit Elastic
Machine Learning beginnt mit Daten – und hier kommt Elastic ins Spiel.
Mit Elastic Machine Learning können Sie Ihre Daten analysieren, um Anomalien zu finden, Datenrahmenanalysen durchführen und Daten in natürlicher Sprache analysieren. Elastic Machine Learning macht ein Data-Science-Team, die Entwicklung einer Systemarchitektur von Grund auf oder das Verschieben von Daten in ein Framework eines Drittanbieters für das Modelltraining überflüssig. Als KI-Plattform für die Suche können Sie mit unseren Funktionen Ihre Daten erfassen, verstehen und Modelle erstellen oder sich auf unser sofort einsatzbereites, unüberwachtes Modell zur Erkennung von Anomalien und Ausreißern verlassen.
Erfahren Sie mehr darüber, wie Elastic Ihnen helfen kann, Ihre Datenprobleme mit Machine Learning zu bewältigen.