Corrélations APM dans Elastic Observability : comment identifier automatiquement l'origine probable d'un ralentissement ou de l'échec d'une transaction


 Share on Twitter
Share on TwitterPartager sur Twitter

 Share on LinkedIn
Share on LinkedInPartager sur LinkedIn

 Share on Facebook
Share on FacebookPartager sur Facebook

 Share by Email
Share by EmailPartage par e-mail

 Print this page
Print this pageImprimer
En tant qu'ingénieur DevOps ou SRE, vous êtes régulièrement amené à enquêter sur des problèmes complexes, et notamment sur de mystérieux problèmes de performances qui ne se produisent que par intermittence ou seulement sur certaines portions du trafic de votre application. Le plus embêtant, c'est que ces problèmes ont des répercussions négatives sur vos utilisateurs et qu'ils peuvent porter préjudice aux objectifs financiers de votre entreprise. Lorsque vous devez passer en revue des centaines voire des milliers de transactions et d'intervalles, cela revient à chercher une aiguille dans une botte de foin. Et ce n'est pas tout. Les déploiements de microservices cloud-native ou distribués viennent compliquer la tâche, ce qui rallonge d'autant plus le temps passé à déterminer l'origine d'un problème.
Est-ce que ce ne serait pas merveilleux si vous pouviez identifier rapidement un schéma commun qui pourrait expliquer un problème de toute évidence complexe, puis le démystifier et en accélérer l'analyse et la résolution ?
La magie des corrélations APM dans Elastic Observability
La fonctionnalité de corrélation d'Elastic APM met automatiquement en évidence les attributs de l'ensemble de données APM qui sont corrélés à des transactions à haute latence ou à des transactions erronées et qui ont un impact significatif sur les performances générales des services.
Un problème APM se présente et vous souhaitez l'analyser ? Rendez-vous tout d'abord dans l'onglet Transactions de la vue APM. Que vous souhaitiez étudier des transactions présentant une latence élevée ou des transactions en échec, vous devez commencer par visualiser les anomalies dans le graphique de distribution de la latence. Les transactions à latence élevée s'affichent à droite du graphique, tandis que les étiquettes des transactions à latence élevée et en échec montrent l'étendue de l'impact. En outre, l'annotation du 95e percentile sur le graphique aide à bien faire la distinction au niveau visuel avec les véritables anomalies.
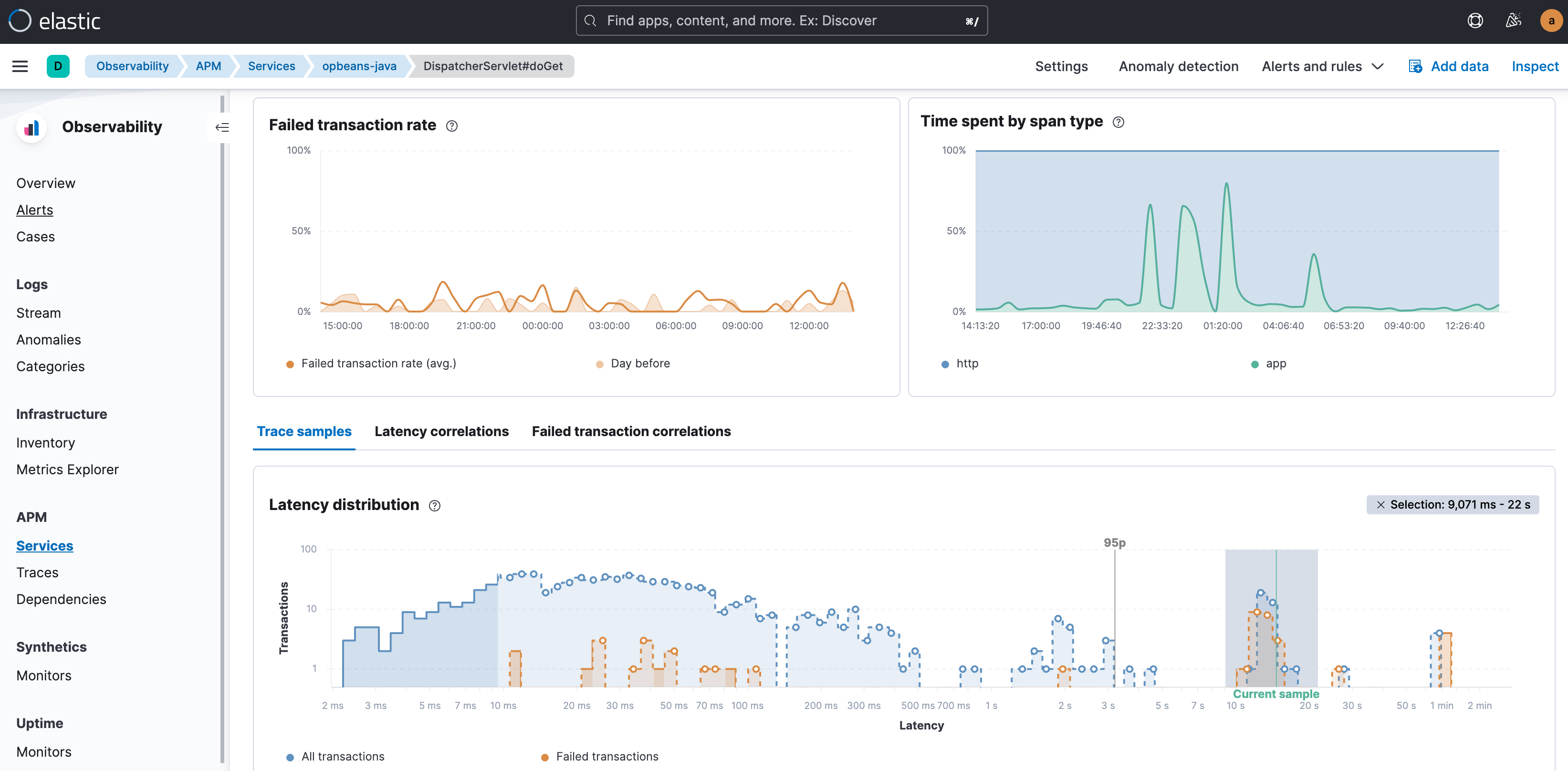
Ensuite, vous devez rechercher dans les données les attributs et les facteurs présentant la plus grande corrélation avec ces anomalies, et de là, limiter votre examen aux sous-groupes concernés dans l'ensemble de données global. En d'autres termes, recherchez des attributs qui sont exagérément représentés dans les transactions lentes ou erronées. Il peut s'agir d'étiquettes, de balises, d'attributs de trace et de métadonnées, comme des versions de service, des géolocalisations, des types d'appareil, des identifiants d'infrastructure, des étiquettes spécifiques au cloud telles que les zones de disponibilité, les systèmes d'exploitation et les types de clients pour les services front-end, ainsi que les hôtes d'autres attributs. Le but est de pouvoir expliquer les transactions anormales à partir de ces attributs. Par exemple, vous constatez que presque toutes les transactions dont la latence est élevée se produisent dans le pod Kubernetes x, ou que les transactions ayant l'étiquette shoppingCartVolumeHigh et la version de service a.b sont en échec.
Imaginez si vous deviez parcourir à la main l'ensemble de ces attributs (qui pourraient s'élever à plusieurs centaines) pour déterminer ceux pouvant expliquer les anomalies de performances.
Elastic Observability compare automatiquement les attributs associés à une latence élevée et les erreurs dans l'ensemble complet de transactions. La solution identifie ensuite les balises et les métadonnées que l'on retrouve un peu trop souvent dans les transactions aux performances médiocres. En d'autres termes, repérez les éléments qui sont plus présents dans les transactions aux performances médiocres que dans l'ensemble complet de transactions. Cela vous permettra non seulement de voir les corrélations, mais aussi de déterminer les attributs prédominants. La valeur d'une corrélation (qui va de 0 à 1,00, où 1,00 indique une corrélation parfaite) permet de voir rapidement le degré de correspondance. Cliquez sur n'importe quel attribut pour voir les transactions auquel il est associé, avec un codage couleur dans le graphique de distribution, afin de mieux visualiser le chevauchement.
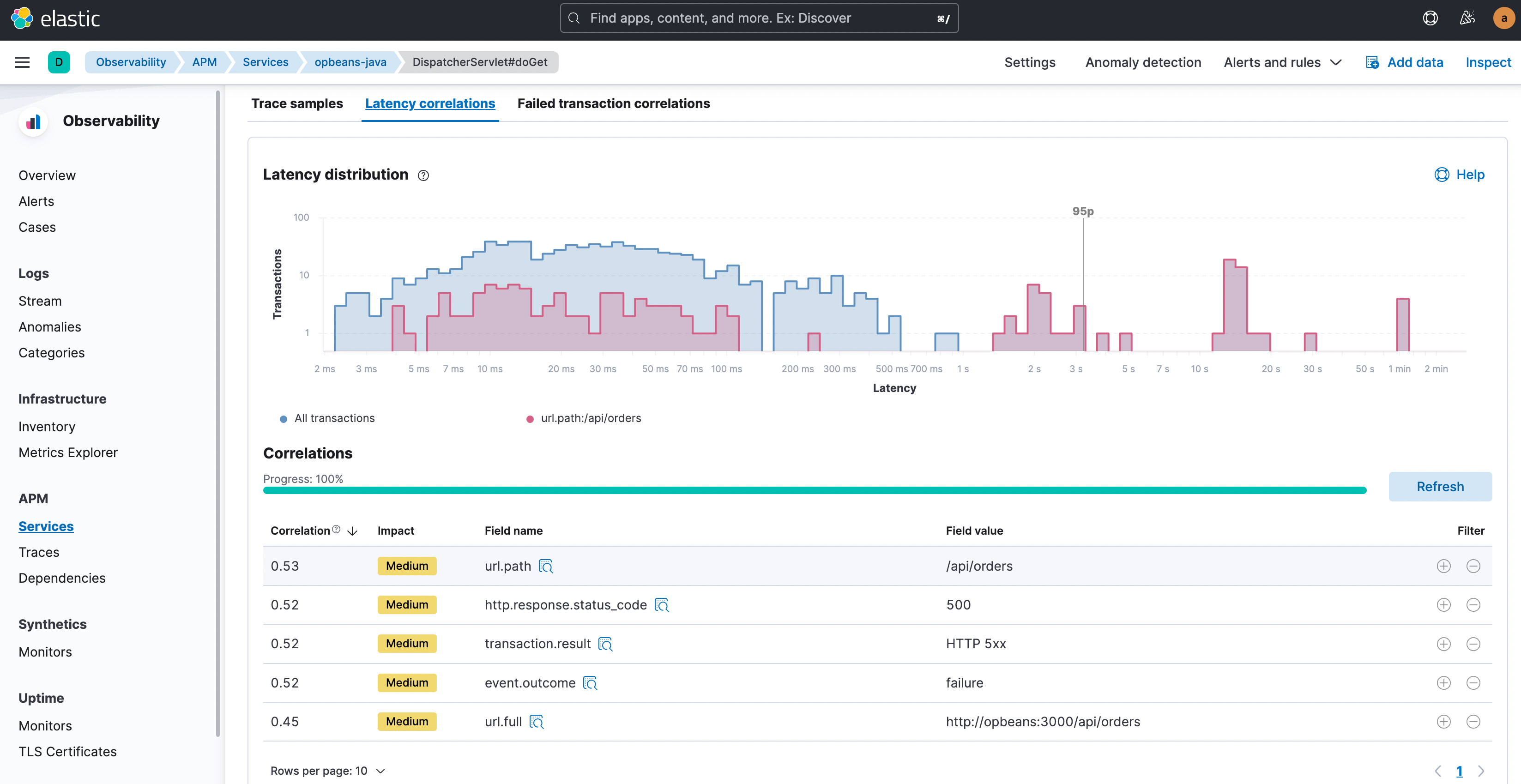
Maintenant que vous avez identifié les facteurs en corrélation, vous pouvez limiter votre examen uniquement aux transactions concernées. Cliquez sur les boutons de filtre "+" ou "-" pour sélectionner ou exclure les transactions avec cette valeur d'attribut, puis étudiez les transactions qui vous intéressent dans le détail. Pour la latence, la suite logique consiste généralement à examiner des échantillons de trace des transactions qui présentent une latence élevée et qui disposent des attributs identifiés, jusqu'à ce que vous trouviez le coupable : un appel de fonction lent dans les traces.
Une fois la cause première du problème confirmée, vous pouvez entamer le processus de résolution et de récupération au moyen de différents mécanismes, tels que les restaurations, les correctifs ou les mises à niveau, pour ne citer qu'eux.
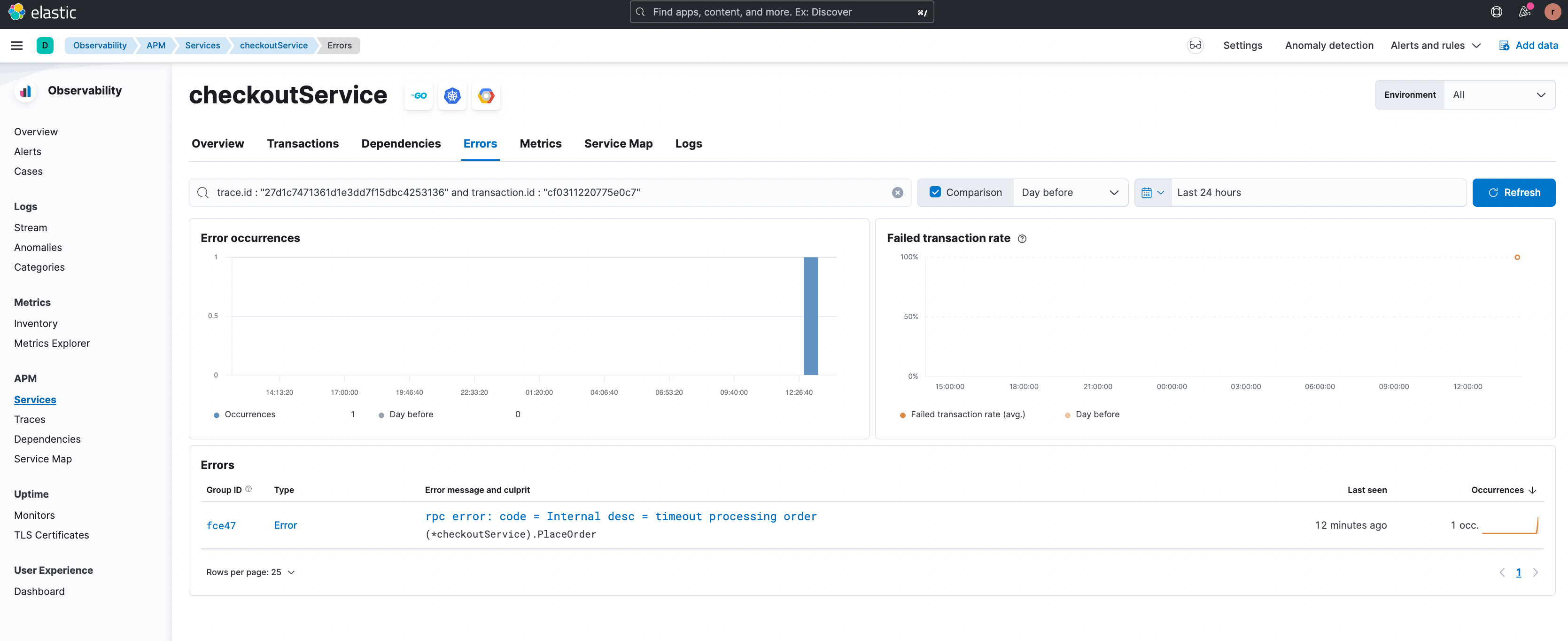
Étudions maintenant un cas où une transaction est en échec. Dans l'exemple ci-dessous, le groupe de transactions ‘/hipstershop.CheckoutService/PlaceOrder’ dans ‘checkoutService’ affiche un taux particulièrement élevé de transactions en échec.
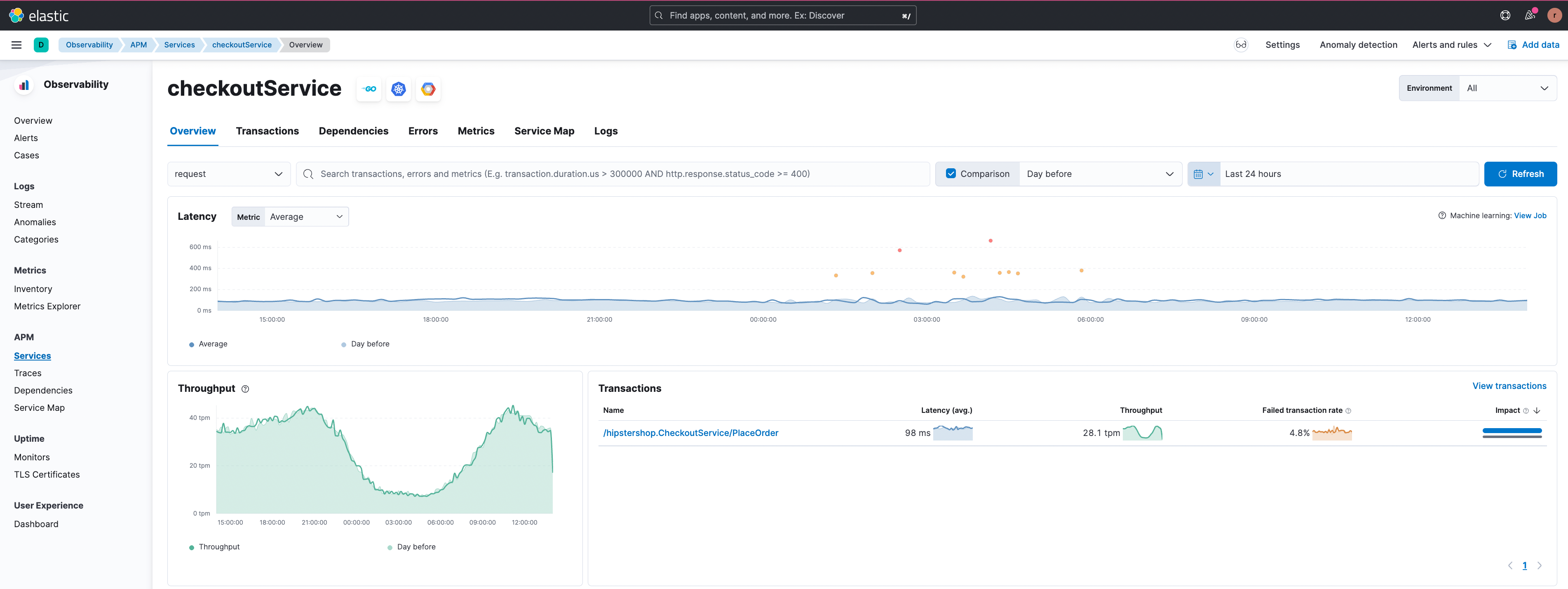
La fonctionnalité de corrélation des transactions en échec indique que les transactions en échec concernent les utilisateurs d'Afrique du Sud, comme on peut le voir dans la figure ci-dessous.
En cliquant sur le bouton de filtre "+", il est possible de se concentrer sur ce sous-ensemble spécifique de transactions et de voir un exemple de transaction comportant l'erreur rencontrée.
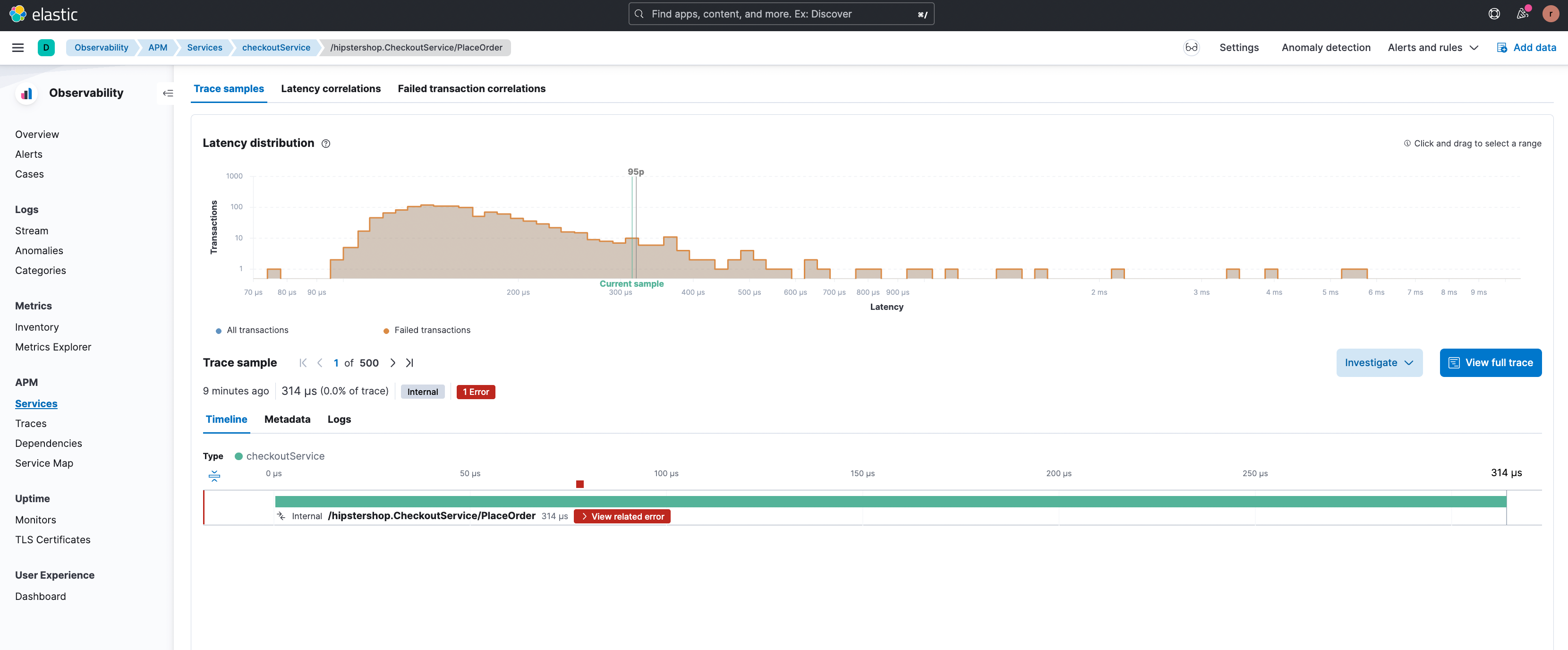
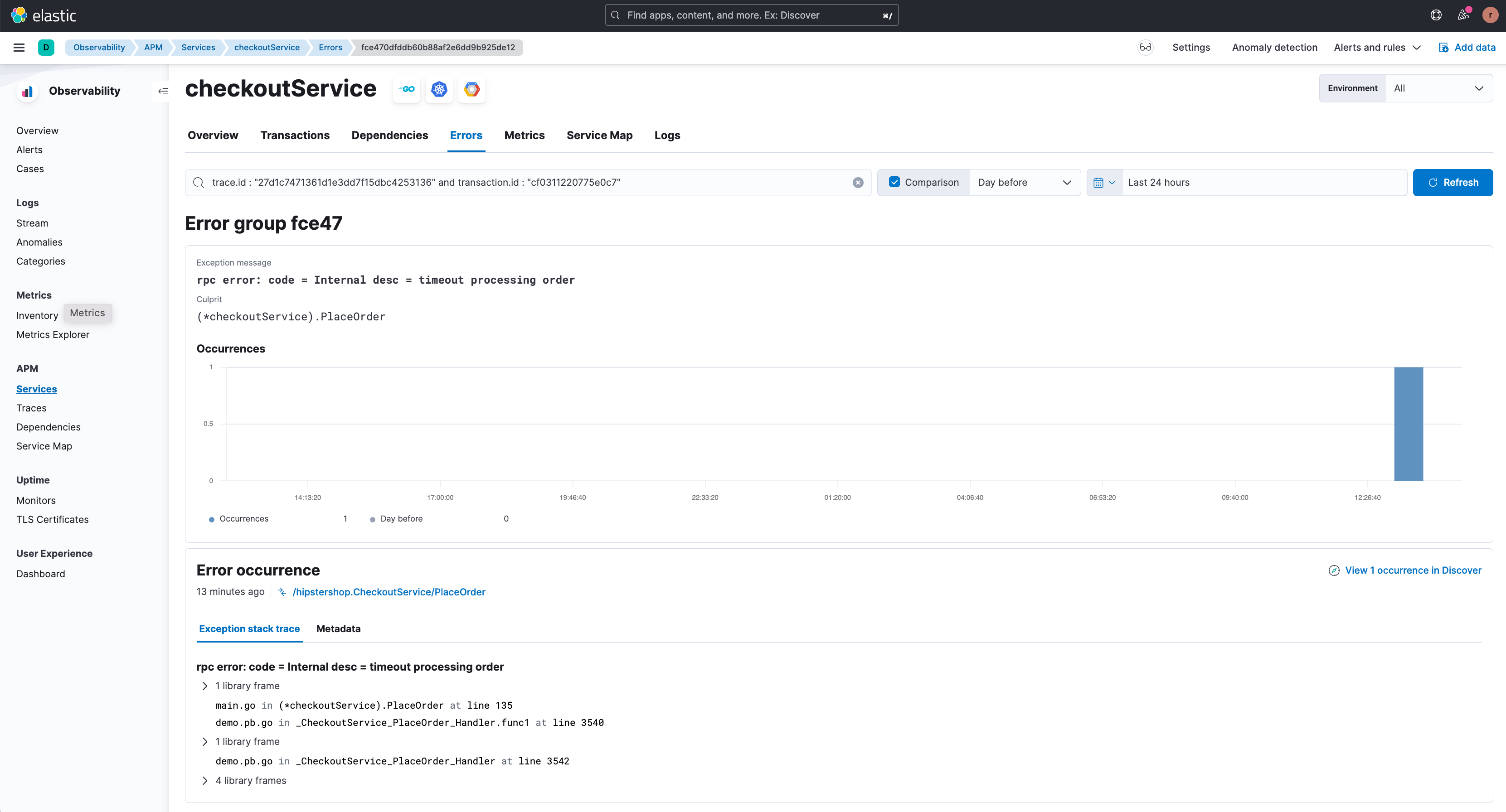
En cliquant sur "View related error" (Voir l'erreur associée), l'utilisateur est redirigé vers la page des détails concernant l'erreur appropriée (ci-dessous), dans laquelle les différents types d'erreurs associés à ce point de terminaison sont mis en évidence. La trace de pile qui concerne la survenue d'une erreur est également disponible ici. Elle fournit des informations utiles sur le débogage.
À partir des exemples ci-dessus, on voit que la fonctionnalité de corrélations APM exécute le gros du travail pour l'utilisateur en restreignant les groupes de transactions à ceux qui sont lents ou rencontrent des erreurs. Résultat : les temps moyens de détection et de résolution en sont considérablement réduits.
Entrées et données nécessaires pour les corrélations
La fonctionnalité de corrélations APM peut accélérer de façon drastique l'analyse de la cause première pour les problèmes qui ne concernent qu'un segment de la population. Plus il y a de métadonnées pour décrire les applications, les services, les transactions, l'infrastructure et les clients, plus l'analyse est riche et plus la probabilité de trouver des attributs qui expliquent les mauvaises performances d'une transaction est grande. La fonctionnalité de corrélation s'appuie sur tous les champs et étiquettes présents dans les données.
Utilisez le workflow "Add Integrations" (Ajouter des intégrations) de la page Overview (Aperçu) pour ajouter des fonctionnalités d'agent et/ou l'ingestion de données pour les applications, l'infrastructure et les dépendances déployées dans votre environnement. Remarque : vous pouvez aussi procéder à une intégration native de plusieurs technologies, notamment les environnements cloud-native comme l'environnement Kubernetes basé sur le cloud, et les technologies sans serveur telles que Lambda. Une fois que vous avez identifié les différentes sources de données télémétriques, vous pouvez enrichir les données entrantes via Logstash ou directement via l'agent APM. Elastic propose également une intégration fluide et une prise en charge native et complète des données OpenTelemetry (qui, à leur tour, prennent en charge l'instrumentation manuelle).
Les informations côté client peuvent être rassemblées à l'aide des données du monitoring des utilisateurs réels (RUM). Le traçage distribué est activé par défaut lorsque l'agent Elastic RUM est utilisé. Le traçage des requêtes entre origines multiples et la propagation de tracestate peuvent être facilement configurés en définissant l'option de configuration distributedTracingOrigins. Combiné à l'APM, le RUM ajoute des informations côté client enrichies, comme la version des navigateurs, le système d'exploitation client et le contexte utilisateur. Toutes ces données sont automatiquement incluses dans la détermination de la corrélation.
Avec l'intégration de ces données dans Elastic, les corrélations APM peuvent se mettre au travail et ainsi, fournir des insights clairs et précis, tout en réduisant le temps nécessaire à la détermination de la cause première dans de nombreux cas de figure.
Cas de figure dans lesquels les corrélations APM peuvent considérablement réduire le temps nécessaire à la détermination de la cause première
Par définition (ou presque), il n'existe pas d'ensemble de problèmes complexes pour lequel une fonctionnalité spécifique serait capable de donner toutes les réponses avec certitude. Après tout, bon nombre de problèmes d'APM sont considérés comme complexes parce qu'il y a précisément de nombreuses inconnues qu'il faut clarifier. Sinon, il nous suffirait de nous baser sur quelques problèmes connus pour savoir exactement ce qu'il faut rechercher, et il n'y aurait plus de problèmes complexes du tout !
Néanmoins, pour une majeure partie des analyses complexes, les corrélations APM peuvent jouer un rôle crucial en restreignant les domaines spécifiques à examiner de votre déploiement, ce afin de déterminer ou de valider la cause première. L'une des premières questions que vous devez vous poser est : le problème que vous rencontrez touche-t-il l'intégralité de votre déploiement ou seulement quelques sous-groupes ? Par exemple, vos transactions présentent-elles toutes une latence élevée ? Ou certaines semblent-elles s'exécuter normalement ? Si vous constatez que le problème n'est pas généralisé, utilisez la fonctionnalité de corrélations APM pour déterminer si un sous-ensemble d'attributs peut vous aider à caractériser les transactions concernées. Ces attributs vous permettent de filtrer les transactions pour obtenir un petit groupe plus facile à gérer, sur lequel vous pouvez vérifier les traces afin de faire ressortir la cause première, ou consulter les dépendances de l'infrastructure qui contribuent aux problèmes de performances des transactions.
Voici quelques cas de figure dans lesquels les corrélations APM ont été d'une grande utilité :
Problèmes de performances matérielles : plus particulièrement dans les cas d'équilibrage des charges où certaines charges dépendent d'un matériel spécifique, la dégradation des performances matérielles peut à son tour entraîner une latence élevée chez certains groupes d'utilisateurs ou certaines parties d'une application. Les corrélations APM peuvent rapidement isoler le matériel défaillant en se basant sur les étiquettes et les identifiants.
Données d'entrée utilisées :
- Étiquettes globales de l'agent APM collectées dans les traces distribuées
- Indicateurs d'infrastructure d'Elastic Agent ou de metricbeat, pour pouvoir poursuivre l'analyse après que la fonctionnalité de corrélations APM a été utilisée
Problèmes de déploiement d'une architecture multi-tenant ou multicloud d'un hyperscaler : l'utilisation d'un hyperscaler vient complexifier davantage le déploiement d'une application. Les déploiements multicloud ou de cloud hybride se sont démocratisés. Lors de la résolution de problèmes ne concernant que certaines parties d'une application, les étiquettes et les balises d'un hyperscaler (par exemple, les métadonnées cloud) permettent de détecter les instances, les fournisseurs cloud, les régions ou les zones de disponibilité en lien avec le problème. L'agent Elastic Java APM permet de détecter automatiquement le fournisseur cloud à l'aide de variables de configuration.
Données d'entrée utilisées (collectées automatiquement par l'agent APM) :
- Zone de disponibilité du cloud
- Région du cloud
Problèmes spécifiques à un emplacement géographique ou à un groupe d'utilisateurs : les corrélations APM peuvent faire ressortir les balises identifiant des emplacements géographiques ou des groupes d'utilisateurs spécifiques afin d'isoler un segment d'utilisateurs et étudier les transactions qui y sont associées. Par exemple, l'agent Elastic Java APM prend en charge les étiquettes globales utilisées par cette fonctionnalité, qui permettent de fournir plus de contexte et d'identifier un sous-ensemble de la population. Les agents Elastic APM, comme l'agent Java APM, prennent en charge la configuration des étiquettes globales, lesquelles peuvent servir à ajouter des métadonnées supplémentaires à tous les événements. Des étiquettes globales sont ajoutées aux transactions, aux indicateurs et aux erreurs. De la même façon, l'API de l'agent Java APM permet d'instrumenter manuellement les transactions qui peuvent servir à extraire des informations sur un emplacement géographique ou un groupe d'utilisateurs. Ces étiquettes aident à cibler les classes/méthodes importantes ou nouvelles dans le service pour accélérer l'analyse de la cause première, la validation des hypothèses, etc.
Données d'entrée utilisées :
- Métadonnées cloud (collectées automatiquement par l'agent APM)
- Étiquettes globales, pour ajouter éventuellement des métadonnées aux événements
- Toute donnée ajoutée par instrumentation manuelle
Problèmes liés à un déploiement en version canari ou à tout autre déploiement partiel : dans les déploiements d'applications d'entreprise, et plus particulièrement dans les applications fournies par SaaS, il n'est pas rare que différentes versions d'un logiciel s'exécutent simultanément. Les déploiements en version canari ou les stratégies de tests A/B sont des exemples de déploiements à plusieurs versions simultanées. Lorsqu'une version spécifique de l'application a un comportement anormal, les corrélations APM peuvent aider à identifier cette version, en réduisant la portée du problème et en accélérant la détermination de la cause première. La version de service peut être configurée soit par détection automatique, soit en utilisant une variable d'environnement, par exemple dans l'agent Elastic Java APM.
Données d'entrée utilisées :
- Version de service, par détection automatique ou à partir de l'agent APM
Problèmes côté client : les indicateurs côté client tels que les versions de navigateur spécifiques ou les types d'appareil aident immédiatement à réduire la portée du problème et sa cause potentielle, ce qui offre des informations précieuses sur la cause première pour pousser davantage l'analyse et résoudre le problème.
Données d'entrée utilisées :
- Données client automatiquement collectées via l'agent Elastic RUM, par exemple la version du navigateur et du système d'exploitation, les détails concernant l'appareil, le type de réseau, etc.
Problèmes avec des prestataires de services tiers : dans les scénarios qui impliquent des prestataires de services tiers, comme des fournisseurs de services d'authentification, les corrélations APM aident à identifier rapidement les problèmes qui viennent d'un prestataire spécifique. Pour cela, il est possible d'utiliser un kit SDK (Elastic ou OTel) pour ajouter des étiquettes personnalisées aux fournisseurs d'authentification afin de les identifier. Les étiquettes personnalisées peuvent être utiles également dans d'autres scénarios similaires où l'auto-instrumentation seule ne suffit pas à fournir le contexte nécessaire pour faciliter l'analyse de la cause première.
Données d'entrée utilisées :
- Étiquettes personnalisées ajoutées via le kit SDK Elastic ou OTel
- Étiquettes globales
... et bien d'autres cas d'utilisation, comme vous pouvez vous en douter. Les corrélations sont utiles lorsque des problèmes complexes touchent votre service, mais n'impactent que certains aspects de celui-ci.
Il existe néanmoins des cas dans lesquels les corrélations APM ne renvoient pas des résultats optimaux, notamment lorsqu'il s'agit d'un problème généralisé impactant l'ensemble d'un service de votre application. Dans une telle situation, de nombreux indicateurs, balises et étiquettes peuvent présenter une corrélation élevée avec les transactions aux performances médiocres, mais elles ne vous aideront pas particulièrement à analyser le problème. Pour finir, s'il vous manque des données appropriées ou si celles-ci n'ont pas suffisamment de descripteurs et d'étiquettes, il y a un grand risque pour que la corrélation ne soit pas détectée du tout. Consultez la section précédente concernant les entrées et les données utiles pour les corrélations.
Ceci étant dit, pour une grande partie de vos analyses, la fonctionnalité de corrélations APM est un outil puissant qui vous permettra de limiter votre examen aux groupes de transactions concernés. Vous pourrez ainsi identifier plus rapidement la cause première, ce qui vous permettra de réduire le temps nécessaire à l'analyse de manière drastique.
Bonne résolution !
Pour aller plus loin
La fonctionnalité de corrélations APM est en disponibilité générale à partir de la version 7.15. Cliquez ici pour consulter les notes de publication concernant cette fonctionnalité.
Pour accéder au guide d'utilisateur et à la documentation concernant la fonctionnalité de corrélations APM, cliquez ici.
Partager
- Share on Twitter
Partager sur Twitter
- Share on LinkedIn
Partager sur LinkedIn
- Share on Facebook
Partager sur Facebook
- Share by Email
Partage par e-mail
- Print this page
Imprimer

