Création d’index gelés avec l’API Elasticsearch Freeze Index
Un peu de contexte pour commencer...
Nous avons souvent recours aux architectures hot-warm lorsque nous voulons tirer pleinement parti de notre matériel. Celles-ci sont particulièrement utiles lorsque nous disposons de données temporelles, comme les logs, les indicateurs et les données APM. Pour la plupart des configurations, les données sont en lecture seule (après l’ingestion) et les index sont basés sur une durée (ou une taille). Il est donc facile de les supprimer selon la durée pendant laquelle nous souhaitons les conserver. Dans ce type d’architecture, nous classons les nœuds Elasticsearch en deux catégories : « hot » et « warm ».
Les nœuds hot conservent les données les plus récentes. Ils gèrent donc toute la charge liée à l’indexation. Comme les données récentes sont celles qui sont les plus demandées, les nœuds hot sont les nœuds les plus puissants dans notre cluster : stockage rapide, mémoire élevée et CPU performant. Mais cette puissance supplémentaire devient coûteuse. Il ne sert donc à rien de stocker les données plus anciennes qui sont moins souvent consultées que les nœuds hot.
En face, nous avons les nœuds warm, qui permettent un stockage à long terme plus économique. Les données se trouvant sur les nœuds warm ne sont pas aussi souvent consultées que celles des nœuds hot. Les données du cluster passent d’un nœud hot à un nœud warm en fonction de la durée de conservation que nous avons planifiée (à l’aide d’un filtrage d’allocation des partitions). Elles restent toutefois disponibles pour que nous puissions les consulter au besoin.
À partir de la version 6.3 de la Suite Elastic, nous avons ajouté de nouvelles fonctionnalités pour améliorer les architectures hot-warm et simplifier la manipulation des données temporelles.
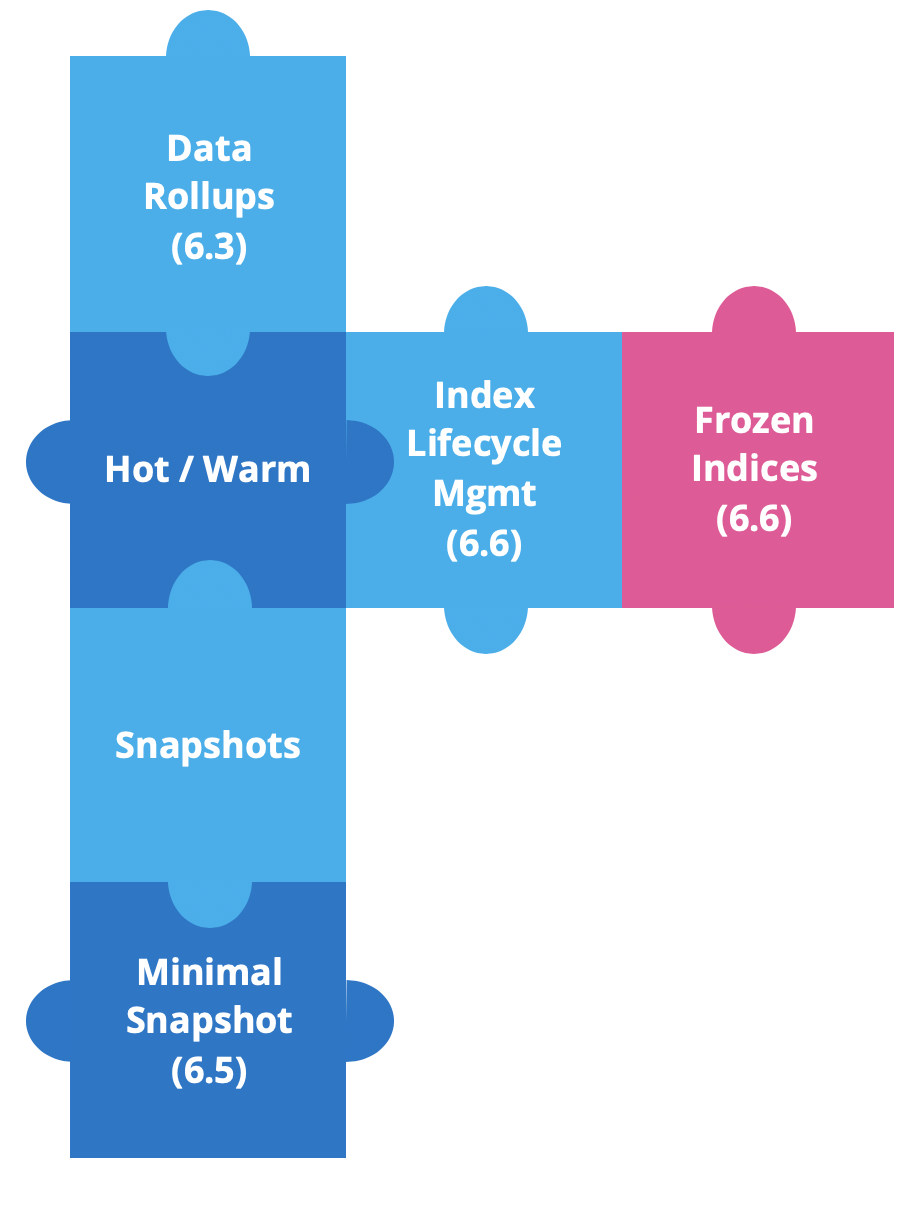
Les cumuls de données ont fait leur apparition dans la version 6.3, pour faire des économies de stockage. Plus concrètement, comment ça fonctionne ? La plupart du temps, dans les séries temporelles, nous voulons obtenir des détails précis sur les données les plus récentes. Mais ce n’est pas souvent le cas pour les données historiques. Pour ces dernières, nous étudions en général l’ensemble de données dans son intégralité. C’est là qu’interviennent les cumuls. À partir de la version 6.5, nous pouvons créer, gérer et visualiser des données cumulées dans Kibana.
Peu de temps après, nous avons ajouté les instantanés de source uniquement. Ce type d’instantané permet de réduire considérablement le volume de stockage d'instantanés. En revanche, il faut réindexer les données si nous voulons effectuer une restauration ou une recherche. Cette fonctionnalité est proposée depuis la version 6.5.
Dans la version 6.6, nous avons lancé deux fonctionnalités puissantes : la gestion du cycle de vie et le gel des index.
La gestion du cycle de vie donne les moyens d’automatiser la gestion de vos index au fil du temps. Elle simplifie la transition des index depuis un nœud hot vers un nœud warm, permet de supprimer des index lorsqu’ils sont trop anciens, ou automatise la fusion forcée d’index en un segment.
Dans le reste de cet article, nous allons nous pencher sur le gel des index.
Pourquoi geler un index ?
L’un des plus gros inconvénients des données anciennes est que les index conservent un encombrement mémoire significatif, et ce, quelle que soit leur ancienneté. Même si nous les plaçons sur des nœuds cold, ils utilisent tout de même de la mémoire.
L’une des solutions possibles serait de fermer l’index. Si nous fermons l’index, il n’utilisera pas de mémoire. Par contre, nous devrons le rouvrir si nous voulons effectuer une recherche. La réouverture d’un index implique un coût opérationnel, mais également de disposer du volume de mémoire que cet index utilisait avant d’être fermé.
Chaque nœud dispose d’une certaine quantité de mémoire disponible qui limite le volume de stockage selon un ratio. Ce ratio peut aller de 1:8 (memory:data) pour les scénarios consommant beaucoup de mémoire, à 1:100, pour les cas d'utilisation moins gourmands.
C’est là que le gel des index entre en jeu. Et si nous pouvions disposer d’index toujours ouverts (sur lesquels nous pouvons donc effectuer des recherches), mais qui n’utiliseraient pas de mémoire ? Nous pourrions augmenter la capacité de stockage des nœuds de données conservant des index gelés et modifier le ratio 1:100. En contrepartie, les recherches seraient probablement plus lentes.
Lorsque nous gelons un index, il passe en lecture seule et ses structures de données transitoires sont éliminées de la mémoire. Aussi, si nous effectuons une recherche sur des index gelés, nous devrons charger les structures de données dans la mémoire. Une recherche effectuée sur un index gelé n’est pas obligatoirement lente. Lucene dépend en majeure partie du cache du système de fichiers, qui doit avoir suffisamment de capacité pour conserver des parties importantes de votre index en mémoire. Dans un tel cas, les recherches sont comparables au niveau de la vitesse des partitions. Néanmoins, un index gelé est contraint de sorte qu’une seule partition gelée s’exécute par nœud à la fois. Cet aspect peut ralentir les recherches par rapport aux index non gelés.
Fonctionnement du gel
Les recherches sont effectuées sur les index gelés à l’aide d’un pool de threads dédié et contraint. Par défaut, seul un thread est utilisé, pour garantir que les index gelés soient chargés un par un dans la mémoire. Si des recherches simultanées sont effectuées, elles se mettront en file d’attente pour renforcer la protection et éviter que les nœuds n’aient plus assez de mémoire.
Dans une architecture hot-warm, nous pourrons désormais passer les index d’un nœud hot à un nœud warm, puis les geler avant de les archiver ou de les supprimer. Nos besoins au niveau du matériel s’en trouvent donc réduits.
Avant que cette fonctionnalité ne soit proposée, lorsque nous voulions réduire le coût de l’infrastructure, nous devions créer un instantané de nos données, puis archiver celles-ci, ce qui ajoutait un coût opérationnel significatif. Si nous avions besoin d’effectuer à nouveau une recherche dans ces données, nous devions les restaurer. Cette époque est révolue ! Désormais, nous pouvons conserver nos données historiques pour y effectuer des recherches sans surcharger la mémoire. Et si nous souhaitons intervenir à nouveau en écriture sur un index gelé, il nous suffit juste de le dégeler.

Procédure pour geler un index Elasticsearch
Le gel des index est simple à mettre en place dans votre cluster. Aussi, commençons par étudier comment utiliser l’API Freeze Index et effectuer une recherche sur des index gelés.
Nous allons tout d’abord créer des données échantillon sur un index test.
POST /sampledata/_doc
{
"name": "Jane",
"lastname": "Doe"
}
POST /sampledata/_doc
{
"name": "John",
"lastname": "Doe"
}
Nous allons ensuite vérifier que nos données ont été ingérées. Nous devrions obtenir deux résultats :
GET /sampledata/_search
Une bonne pratique consiste à effectuer une fusion forcée (force_merge) avant de geler un index. Cela permet de garantir que chaque partition dispose d’un seul segment sur le disque, tout en assurant une meilleure compression et en simplifiant les structures des données dont nous avons besoin lorsque nous procédons à une agrégation ou à une requête de recherche triée sur un index gelé. En effet, l’exécution d’une recherche sur un index gelé disposant de plusieurs segments peut avoir des répercussions significatives en termes de performances, dans une plus ou moins large mesure.
POST /sampledata/_forcemerge?max_num_segments=1
Ensuite, nous devons invoquer un gel sur notre index avec le point de terminaison de l’API Freeze Index.
POST /sampledata/_freeze
Effectuer une recherche sur des index gelés
Comme vous pouvez le constater, les recherches normales ne renvoient rien pour les index gelés. C’est normal. Pour limiter l’utilisation de la mémoire par nœud, les index gelés sont contraints. Étant donné que nous pourrions cibler un index gelé par erreur, nous ajouterons ignore_throttled=false à la requête pour éviter les ralentissements involontaires.
GET /sampledata/_search?ignore_throttled=false
{
"query": {
"match": {
"name": "jane"
}
}
}
À présent, nous pouvons vérifier le statut de notre nouvel index en exécutant la requête suivante :
GET _cat/indices/sampledata?v&h=health,status,index,pri,rep,docs.count,store.size
Vous obtiendrez un résultat similaire à celui-ci, avec un statut « open » pour l’index :
health status index pri rep docs.count store.size
green open sampledata 5 1 2 17.8kb
Comme indiqué précédemment, nous devons faire en sorte que le cluster ne soit pas à court de mémoire. De ce fait, nous sommes limités au niveau du nombre d’index gelés que nous pouvons charger sur un nœud pour y effectuer une recherche. Le nombre de threads dans le pool contraint pour la recherche est de 1 par défaut, avec une file d’attente par défaut de 100. Cela signifie donc que si nous effectuons plus d’une requête, celles-ci seront mises en file d’attente jusqu’à 100. Nous pouvons monitorer le statut du pool de threads afin de vérifier les files d’attentes et les rejets à l’aide de la requête suivante :
GET _cat/thread_pool/search_throttled?v&h=node_name,name,active,rejected,queue,completed&s=node_name
Vous devriez obtenir une réponse similaire à celle-ci :
node_name name active rejected queue completed
instance-0000000000 search_throttled 0 0 0 25
instance-0000000001 search_throttled 0 0 0 22
instance-0000000002 search_throttled 0 0 0 0
Les index gelés peuvent être plus lents, néanmoins, ils peuvent être pré-filtrés de manière très efficace. Nous vous recommandons également de définir le paramètre de requête pre_filter_shard_size sur 1.
GET /sampledata/_search?ignore_throttled=false&pre_filter_shard_size=1
{
"query": {
"match": {
"name": "jane"
}
}
}
Cela n’ajoutera pas de surcharge significative à la requête et nous permettra de bénéficier du scénario habituel. Par exemple, si vous effectuez une recherche de plage de dates sur des index temporels, certaines partitions ne seront pas renvoyées.
Écrire sur un index Elasticsearch gelé
Que se passe-t-il si nous essayons d’écrire sur un index déjà gelé ? C’est ce que nous allons voir.
POST /sampledata/_doc
{
"name": "Janie",
"lastname": "Doe"
}
Que s’est-il passé ? Les index gelés sont en lecture seule. De ce fait, il n’est pas possible d’écrire dedans. Nous pouvons le voir dans les paramètres des index :
GET /sampledata/_settings?flat_settings=true
Ce qui renvoie :
{
"sampledata" : {
"settings" : {
"index.blocks.write" : "true",
"index.frozen" : "true",
....
}
}
}
Nous devons nous servir de l’API Unfreeze Index, pour invoquer le point de terminaison de dégel sur l’index.
POST /sampledata/_unfreeze
À présent, nous allons créer un troisième document et le rechercher.
POST /sampledata/_doc
{
"name": "Janie",
"lastname": "Doe"
}
GET /sampledata/_search
{
"query": {
"match": {
"name": "janie"
}
}
}
Nous vous conseillons de dégeler un index uniquement dans des circonstances exceptionnelles. Pensez aussi à effectuer systématiquement une fusion forcée (`force_merge`) avant de geler l’index à nouveau pour garantir des performances optimales.
Utilisation d’index gelés dans Kibana
Pour commencer, nous devons charger des données échantillon, par exemple les données de vol échantillon.
Cliquez sur le bouton « Add » pour les ajouter.
Cliquons sur le bouton « View data » : nous devrions voir désormais les données chargées. Le tableau de bord sera similaire à celui-ci.
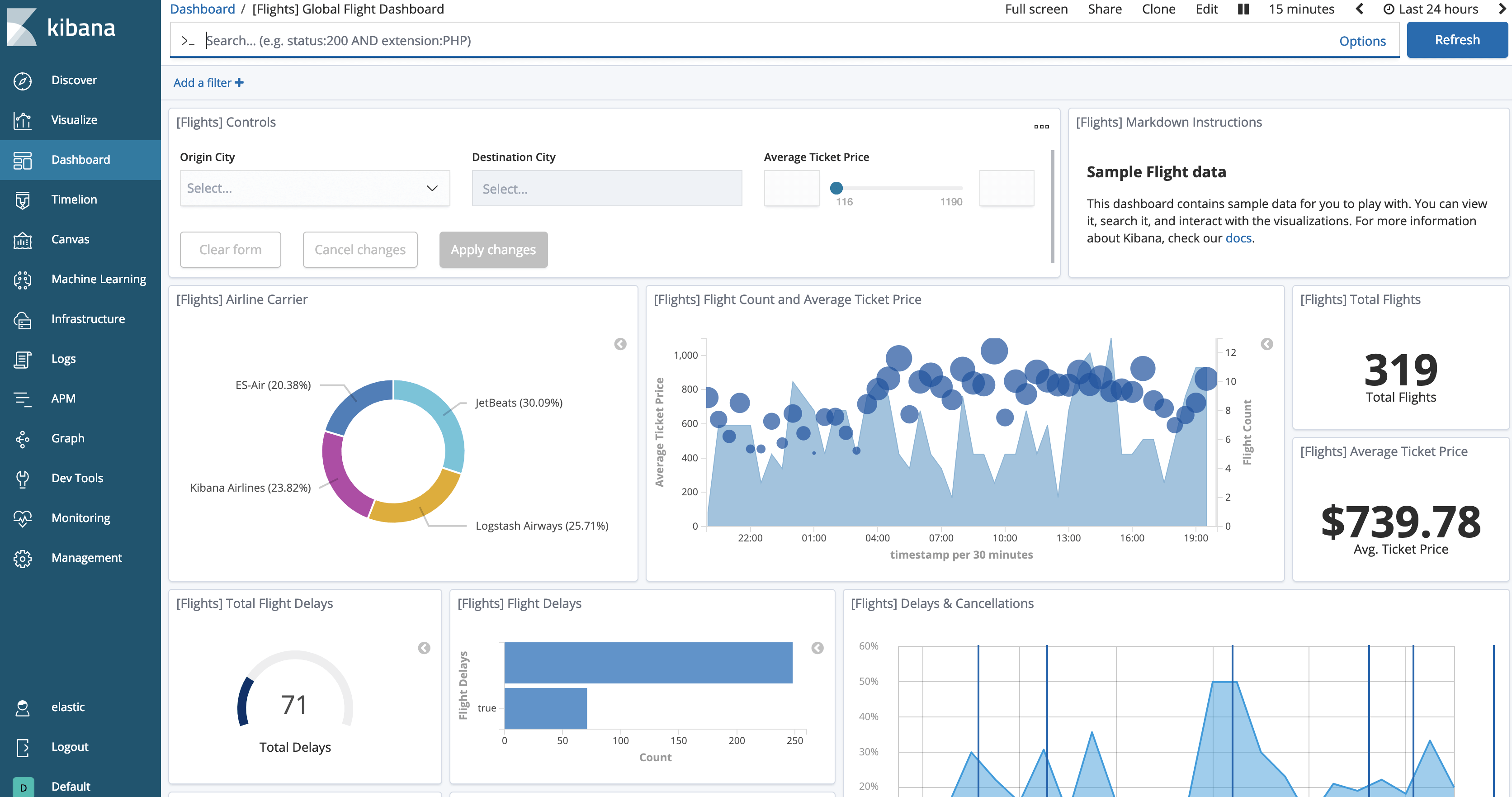
Maintenant, testons le gel de l’index :
POST /kibana_sample_data_flights/_forcemerge?max_num_segments=1
POST /kibana_sample_data_flights/_freeze
Si nous revenons sur notre tableau de bord, nous constatons que les données semblent avoir « disparu ».
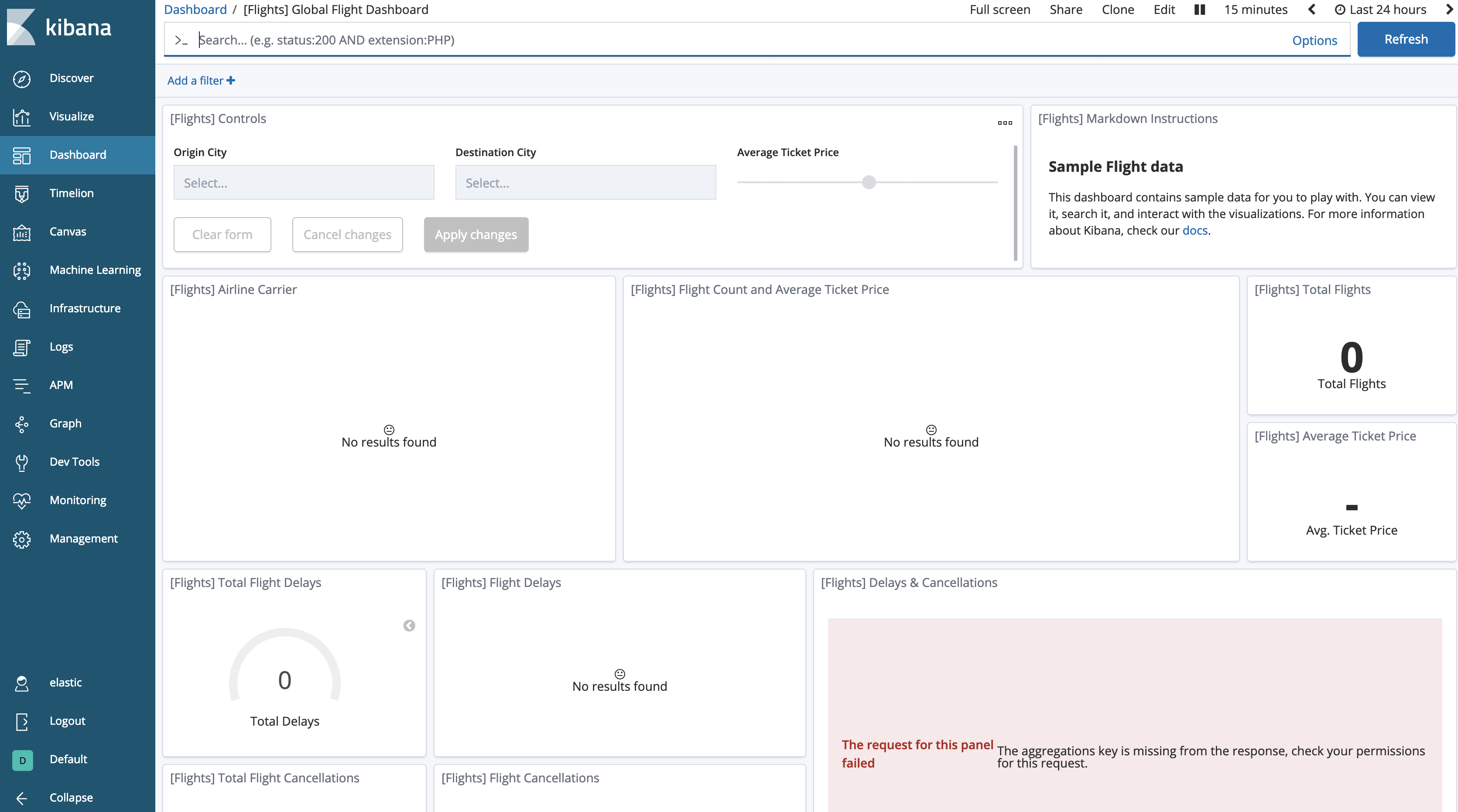
Nous devons indiquer à Kibana que les recherches sur les index gelés sont autorisées. Par défaut, ce paramètre est désactivé.
Rendez-vous dans Kibana Management, puis choisissez Advanced Settings. Dans la section « Search », vous verrez que le paramètre « Search in frozen indices » est désactivé. Activez-le et enregistrez les modifications.

À présent, le tableau de bord affiche à nouveau les données.
Pour conclure
Le gel des index est une fonctionnalité très puissante dans les architectures hot-warm. Elle offre une solution économique pour améliorer le stockage tout en laissant la possibilité d’effectuer des recherches en ligne. Je vous recommande de tester la latence de vos recherches avec votre matériel et vos données, pour avoir le dimensionnement et la latence de recherche appropriés pour vos index gelés.
Consultez la documentation d’Elasticsearch pour en savoir plus sur l’API Freeze Index. Et comme toujours, si vous avez des questions, contactez-nous sur nos forums de discussion. Que la force du gel soit avec vous !