Démocratie App : Donner un écho à la parole des Français avec Elasticsearch
Vendredi 15 mars 2019, un nouveau post apparait sur notre fil d’actualité LinkedIn : “L’Assemblée nationale organise un hackathon sur les données du Grand Débat National”. Quelques minutes plus tard, la décision est prise : nous allons y participer. Le soir-même, les premières ébauches sont griffonnées : ce sera un moteur de recherche permettant d’explorer les contributions thème par thème, en les synthétisant sans les dénaturer, déployé sur le Web et s’appellant Democratie.App.
Défi supplémentaire : le hackathon a lieu huit jours après, il faut donc trouver une solution puissante, scalable et rapide à déployer.
D’entrée de jeu, nous pensons à la Suite Elastic, déjà utilisée depuis plus de 3 ans par Antoine pour Zimple, l’entreprise d’impression 3D qu’il a co-fondée. Antoine avait commencé par utiliser la Suite Elastic en version Open Source avant de migrer vers Elasticsearch Service. Avec Gauthier, entrepreneur également, nous avons multiplié les projets appuyés sur la Suite Elastic. Sur le projet autour du Grand Débat, Elasticsearch, combiné à Python, est la pièce maîtresse. Exécuter le projet sur la version cloud d’Elastic nous a permis de déployer rapidement en production, d’obtenir une configuration optimisée, sécurisée et scalable.
La pipeline
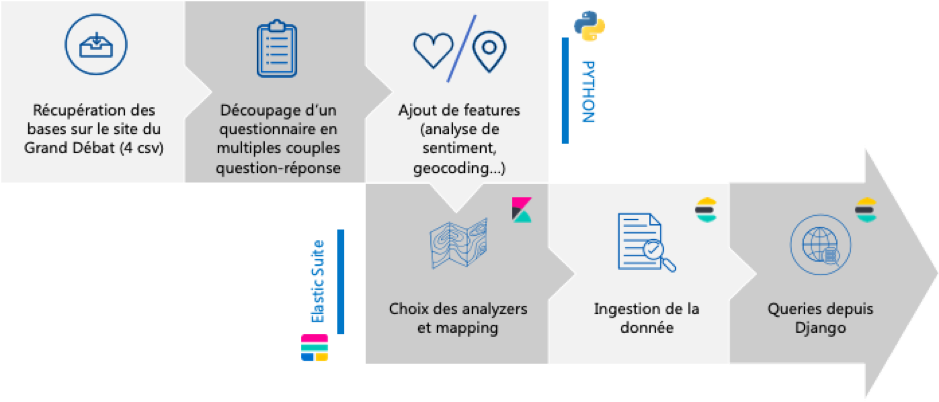
Les sources de données
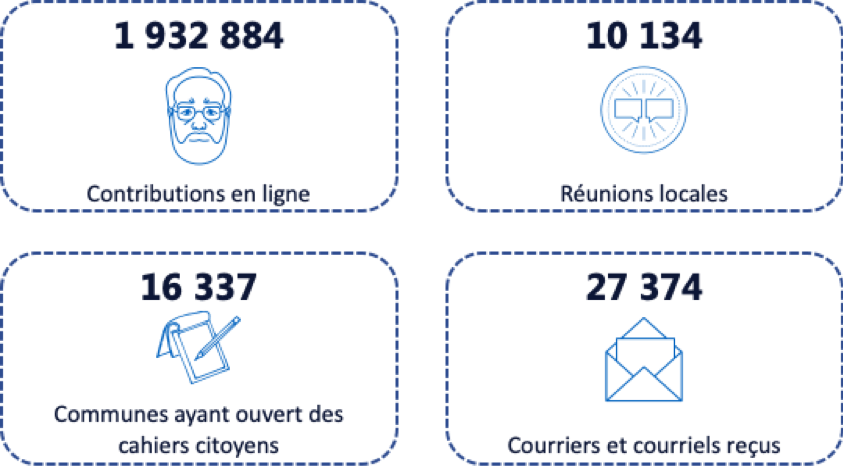
Le Grand Débat, plus grande consultation en France depuis la Révolution française, s’est étendu du 15 janvier au 23 mars 2019 et a invité l’ensemble des Français à s’exprimer sur quatre thématiques : la fiscalité et les dépenses publiques, l’organisation de l’État des services publics, la transition écologique et, enfin, la démocratie et la citoyenneté. Les citoyens pouvaient contribuer de multiples manières : principalement par des cahiers citoyens en mairie, des réunions d’initiatives locales et sur une plateforme en ligne. Le hackathon, organisé par l’Assemblée Nationale le 23 mars, a deux objectifs: nourrir le débat parlementaire des semaines suivantes et rendre les données accessibles aux citoyens. Ce hackathon se concentre sur les données de la plateforme en ligne qui sont disponibles en open data. Les données sont téléchargeables au format csv et découpées selon les quatre thématiques.
Preprocessing
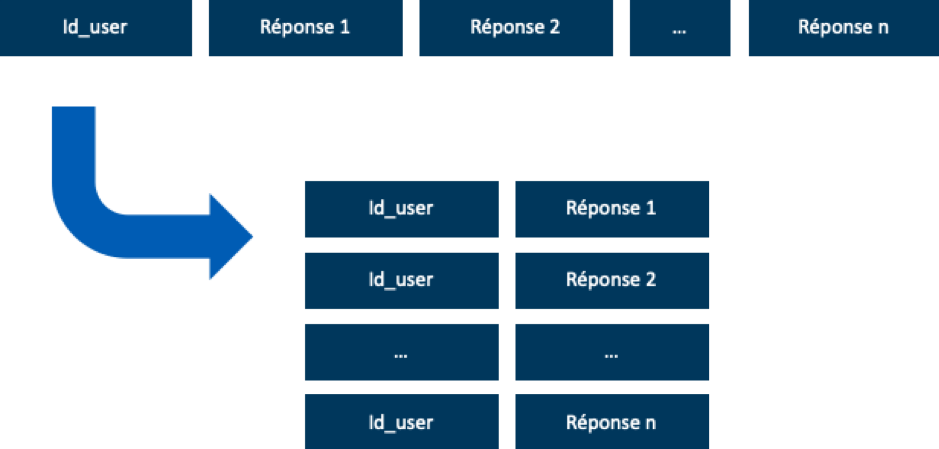
Le format initial des données associe à chaque contributeur l’ensemble des réponses aux questions posées. Le découpage par question paraît vite manquer de pertinence : les réponses sont souvent bien plus larges que la question posée. Pour étudier les avis sur l’immigration par exemple, il est trop réducteur de seulement analyser les réponses aux questions traitant directement de cette thématique; il est en effet fréquent que cette question soit évoquée au détour d’autres sujets. Nous transformons donc la base avec Python, pour que notre unité d’étude soit un couple “répondant - réponse à une question”, mettant au même plan les différentes questions.
En plus de ces changements de format, les données sont également enrichies avant leur indexation. Pour chaque répondant, seule sa nature (citoyen, élu, organisation) et son code postal sont disponibles. Il faut donc retravailler les codes postaux pour les rapprocher des numéros INSEE et ainsi géolocaliser chacune des contributions à l’aide des bases disponibles. Ce travail est particulièrement fastidieux, du fait des multiples évolutions dans les nomenclatures des communes et des incohérences dans les codes saisis par les citoyens.
Malgré des résultats très imparfaits, nous associons également à chacun des couples “répondant-réponse” un score de positivité, calculé par un modèle d’analyse de sentiment, notamment basé sur le package Python TextBlob.
Mapping et indexation
Dans la semaine qui précède le hackathon, nous testons plusieurs combinaisons d’analyzers incluant ou non des stopwords (les stopwords _french_ enrichis de quelques ajouts), un dictionnaire de synonymes que nous avons construit, du stemming … Dans la version finale, plusieurs champs textuels cohabitent avec des analyzers différents, requêtés selon les besoins. Après pré-processing, les données sont indexées sur le cluster Elasticsearch Service à l’aide du package Python elasticsearch-py.
Requêtes et affichage Web
La structure du site se dessine très vite et évolue peu durant la phase de développement. Sur la page d’accueil : une simple barre de recherche, permettant de parcourir les réponses des citoyens, accompagnée des recherches en tendance. L’interface minimaliste nous semble être la seule solution possible, pour permettre à tous les citoyens, quelque soit leur niveau d’expertise technologique ou politique de s’approprier ces données.
La requête est une combinaison d’un “match”, d’un “match_phrase”, et de fonctions de “boost” pour faire que l’ordre d’affichage des contributions reflète l’expression la plus diverse.
- La page des résultats est découpée en trois blocs. Le premier bloc contient les filtres :
- géographique (par commune, département ou circonscription)
- thématique (selon les quatre grands questionnaires)
- type de recherche, permettant de passer d’un opérateur “and” sélectionné par défaut dans la requête "match" à un opérateur “or”
- Le deuxième bloc affiche des statistiques descriptives sur les résultats, obtenues à la volée par des agrégations Elasticsearch (terms aggregation, weighted avg aggregation, cardinality aggregation, significant text, ...). Les résultats de ces requêtes sont traités en Python Django et restitués par des modules Javascript (Mapael pour les cartes, par exemple). Ce bloc permet, sujet par sujet, de synthétiser la parole citoyenne : qui s’est exprimé, où, dans quel cadre et avec quels termes.
- Le troisième et dernier bloc donne à lire l’ensemble des réponses qui satisfont la requête et permet de les télécharger. Si le bloc de statistiques descriptives et de visualisations agrégées nous semble primordial pour favoriser la synthèse, il nous paraît également évident que nous devons donner accès aux réponses brutes et permettre leur consultation. Bien que difficilement applicable à large échelle, seule la lecture des contributions permet de garder intactes la vivacité, la complexité voire l'ambiguïté des avis qui ont été exprimés par les Français. Toutefois, loin du discours démagogique qui consiste à dire que seule une lecture exhaustive ou aléatoire des contributions permettrait de comprendre l’expression citoyenne, nous estimons qu’il est très profitable d’exploiter la puissance de technologies comme Elasticsearch pour sélectionner et ordonner les contributions sans les dénaturer, requête par requête.


Usage et prolongements
Samedi 23 mars 2019, après une semaine intense et quelques milliers de requêtes de test, nous présentons notre moteur de recherche déployé (https://democratie.app) et pleinement fonctionnel au jury du hackathon qui nous a fait figurer parmi les lauréats et nous invite à le présenter devant les députés. Cette présentation est le début d’une campagne de plusieurs mois pour accompagner les près de 60 000 utilisateurs dans leur exploitation du site : des citoyens qui veulent retrouver leur contribution dans la masse, des associations ou médias qui cherchent à faire un état des lieux de l’opinion sur un sujet comme le handicap, des députés qui souhaitent être aidés dans la restitution du Grand Débat dans leur circonscription, des administrations, ministères ou cabinets qui cherchent à étudier la perception de leur action ou de leur communication…
Ce projet citoyen ouvre également de nouvelles voies pour nous, sur la manière d’utiliser la data et le Web au service du débat citoyen et de la démocratie. A l’occasion des élections municipales 2020, nous développons Municipales.App. Cet plateforme apolitique regroupe l’ensemble des propositions des candidats pour les élections municipales, permet de les comparer, d’en débattre et de voter pour ses propositions favorites. Également construite autour de la suite Elastic, elle utilise Elasticsearch pour la recherche et Kibana pour le débat en temps réel. Si le Grand Débat National a montré l’importance de débattre pour faire société et a initié un souffle nouveau, à charge pour nous d’entretenir ce souffle, de poursuivre ce débat et de l’élargir.
Découvez-en plus avec la vidéo du meetup auquel Antoine et Gauthier ont participé.

| Diplômé de l’ENSAE et de l’université Paris Sud, Antoine Franz est Data Scientist et développeur Web. Spécialisé dans le traitement et la visualisation des données textuelles massives, il est chef d’entreprise et enseigne à Sciences Po. |

| D’abord formé aux sciences sociales, Gauthier Schweitzer a ensuite étudié à l’Ecole Polytechnique et à l’ENSAE en data science. Ancien consultant, il est à présent chef d’entreprise et enseignant à Sciences Po. |