Elasticsearch utilisé au centre de l’application citoyenne #Idéo2017
Le projet
Le projet #Idéo2017, financé par la Fondation UCP, associe des chercheurs du laboratoire AGORA et du laboratoire ETIS (ENSEA / UCP / CNRS UMR 8051). L'objectif du projet était de créer un outil d'analyse des tweets politiques lors de campagnes politiques.
Partant d'acquis et de développements d'outils à partir d'un corpus de tweets déjà constitué (autour des élections municipales 2014), ce projet a permis la création d'une plateforme en ligne qui permet de traiter, avec des délais relativement courts, les messages produits en lien avec l'actualité politique (meetings, débats, émissions télévisées, etc.). Les citoyens ou journalistes peuvent ainsi effectuer leurs propres requêtes et obtenir des résultats compréhensibles grâce à cette interface qui rend accessible des analyses et critères linguistiques et informatiques habituellement complexes à appréhender.
Elasticsearch pour #Idéo2017
Le but de la plateforme #Idéo2017 est de proposer deux fonctionnalités principales à ses utilisateurs : (1) une analyse linguistique des tweets (des 11 candidats à l'élection présidentielle) qui est créée partiellement à l'aide des scripts développés dans l'outil d'analyse textuelle Iramuteq (http://www.iramuteq.org/), et (2) un moteur de recherche disposant de fonctionnalités avancées telles que la navigation par facettes pour explorer le corpus des tweets.
L'analyse linguistique
Dans le cadre de l'analyse linguistique, nous proposons deux types d'analyse : une analyse par candidat - l'utilisateur peut analyser tous les tweets d'un candidat choisi parmi les 11, et une analyse par mot (ou thème) - l'utilisateur peut analyser tous les tweets qui contiennent un mot spécifique choisi parmi une liste prédéfinie de 13 mots.
Parmi les problèmes techniques que nous avons rencontrés lors du développement de la fonctionnalité d'analyse linguistique, le plus important concerne la recherche d'un mot dans un texte (utilisée dans notre plateforme par exemple dans l'analyse par mot décrite ci-dessus). En effet, la recherche en plein texte risque de récupérer des résultats non pertinents et cela peut influencer les résultats des analyses linguistiques. Par exemple : une recherche avec le mot "loi" peut produire des résultats qu'on appelle « faux positifs » du type « emploi », « exploitation ». De plus, étant donné que nous mettons en place des analyses linguistiques, il serait nécessaire de pouvoir réaliser des recherches prenant en compte l'aspect linguistique des mots (par exemple, si nous cherchons le mot « travail », nous souhaiterions avoir comme retour les tweets contenant les mots « travail », « travailleur », etc.). Egalement, dans notre plateforme, nous souhaitons stocker les tweets dans une base de données, mais malheureusement les bases de données classiques ne proposent pas une fonctionnalité efficace de recherche d'un mot dans un texte ; ainsi, nous avions besoin d'un outil puissant qui nous permette de réaliser des recherches linguistiques en plein texte dans les tweets.
Lors de nos recherches, nous nous sommes tournés vers Elasticsearch car il répond aux problèmes présentés ci-dessus par l'utilisation d'un algorithme de pertinence basé sur le modèle TF/IDF qui est très utilisé dans la recherche d'information. Cela nous permet de ne récupérer, lors d'une recherche, que les tweets les plus pertinents correspondant aux critères de recherche.
Un moteur de recherche avancé avec Elasticsearch
Le moteur de recherche développé dans la plateforme #Idéo2017 a pour but de proposer à l'utilisateur des recherches avancées avec navigation par facettes sur la totalité des tweets. Une recherche avec facettes permet à l'utilisateur de filtrer les tweets en choisissant un ou plusieurs critères (les facettes). Dans notre plateforme, nous avons intégré trois types de facettes : la première est une facette par candidat où l'on pourra facilement filtrer les résultats pour ne voir que les tweets émanant d'un candidat particulier, la deuxième est par hashtag, et la dernière par mentions. Par exemple: si nous cherchons le mot « université », nous pouvons savoir quels sont les candidats qui parlent le plus de l'université, les hashtags liés à ce mot et les utilisateurs qui ont été mentionnés dans les tweets liés au mot « université ».
Exigences de performances
Notre projet est destiné au grand public. Aussi, la plateforme peut recevoir un nombre important de requêtes simultanées, et donc, le système choisi doit être capable de gérer ce volume de requêtes tout en garantissant d'excellents temps de réponse.
Pour répondre à ces problématiques, nous avons opté pour l'utilisation d'Elasticsearch qui propose une représentation de l'information sous la forme d'un index clusterisé ce qui nous permet non seulement de faire des recherches textuelles, mais aussi d'agréger ces données sur plusieurs facettes. De plus, pour garder notre application fonctionnelle même en cas d'un nombre important de requêtes, Elasticsearch propose la création d'un cluster avec plusieurs nœuds en répartissant la charge des requêtes entre les nœuds, et en réalisant une sauvegarde automatique et répliquée des données.
Architecture
Dans la Figure 1, nous présentons l'architecture globale de la plateforme développée, ainsi que la relation entre les éléments technologiques centraux.
Nous avons récupéré les tweets des 11 candidats suite à un protocole que nous avions déjà mis en place pour nos travaux précédents (Longhi et al. 2014, corpus Polititweets). Après la récupération des tweets, nous stockons toutes les informations liées à ces derniers dans une base de données centrale mongoDB, et ensuite nous sélectionnons les informations dont nous avons besoin pour indexer les tweets, comme par exemple le contenu du tweet, le compte de la personne qui a posté le tweet (twittos), sa date de création, ou le nombre de retweets.
Pour la mise en place de l'index, notre choix s'est porté vers Elasticsearch car pour l'indexation, il propose plusieurs types de configurations pour réaliser le mapping (qui indique comment les données sont stockées et indexées) :
- la configuration analyzer est proposée pour définir la langue du corpus et l'analyseur peut décomposer le text en tokens selon la langue choisie. Pour notre plateforme nous avons utilisé la langue française.
- la configuration normalizer permet de transformer tous les mots en minuscules ou en code ASCII, etc.
L'index construit ci-dessus sera exploité dans un premier temps dans le développement des analyses linguistiques. A cette fin, nous avons utilisé l'API Elasticsearch-PHP pour faire les analyses en temps réel. Quand l'utilisateur choisi un candidat ou un mot, le corpus se crée automatiquement (en sélectionnant uniquement les tweets du candidat choisi ou les tweets qui contiennent le mot choisi), et il sera mis à jour pour pouvoir appliquer nos analyses sur un sous-ensemble du corpus de tweets.
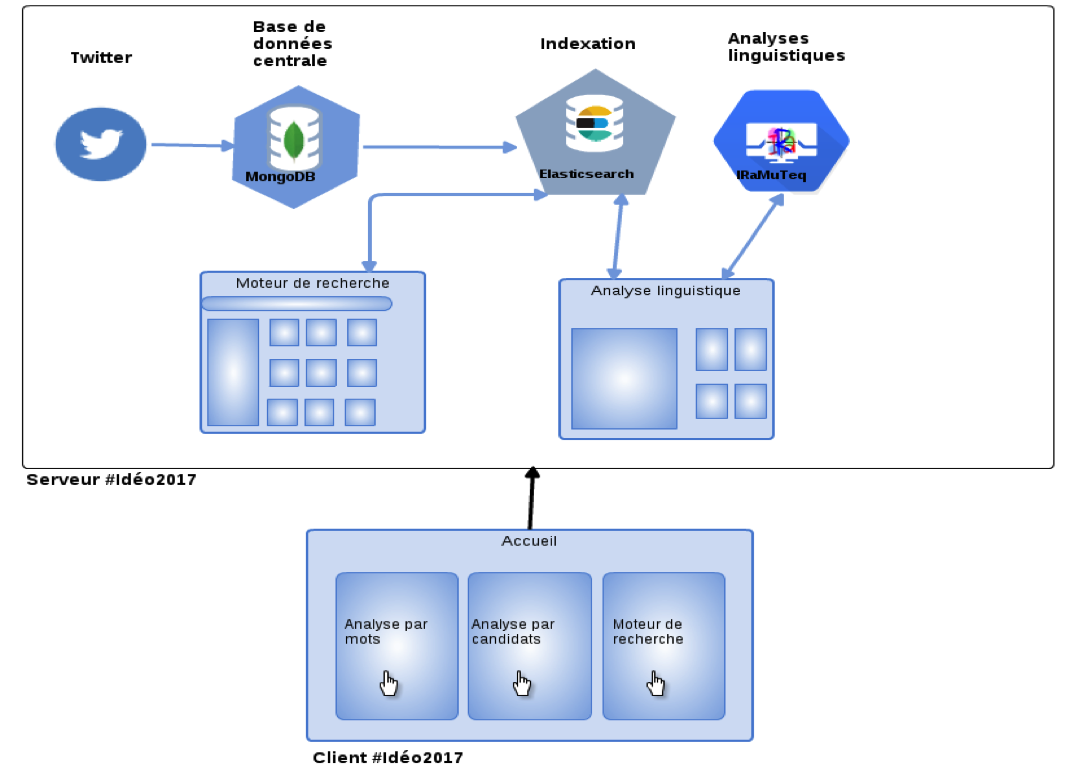
Dans un deuxième temps, l'index construit est utilisé dans la mise en place de notre moteur de recherche à facettes décrit dans la section précédente. Pour cela, nous avons utilisé ElasticUI qui est développée en AngularJS et qui nous a permis de mettre en place nos facettes et les résultats des recherches. L'utilisateur a le choix entre faire des recherches simples sur un mot, ou croiser les recherches simples avec le choix d'un candidat, d'un hashtag ou d'une mention, et les résultats seront affichés en temps réel.
Nous avons opté pour un cluster avec deux nœuds pour profiter de la gestion efficace du cluster réalisée par Elasticsearch, comme par exemple : la sauvegarde automatique et répliquée des données, l'interrogation via les API REST et la répartition de la charge entre les deux nœuds. Nous envisageons d'augmenter le nombre de nœuds dans notre cluster pour les prochaines utilisations de notre plateforme (élections législatives, etc.).
En plus de la précision, l'une des caractéristiques les plus importantes pour le choix d'Elasticsearch, c'est sa rapidité. Au niveau de la récupération d'une grande quantité de données. Elasticsearch nous a permis de surmonter le problème de lenteur qu'on peut avoir au niveau de page web lors de la récupération d'un tel volume de données.
Afin de nous différencier du moteur de recherche présent sur l'interface de Twitter, nous avons conçu notre outil de recherche comme un système hybride, associant les réponses des tweets d'une recherche en temps réel à une synthèse de plusieurs tweets par agrégation de l'information via les facettes et les calculs linguistiques de clustering ou de nuages de mots.
Ainsi pour un mot ou un thème particulier, notre objectif est de donner accès aux tweets originels pour chaque candidat mais également de connaître la répartition exacte du nombre de tweets par candidat ou par grande thématique.
Cette connaissance de la distribution de tweets nous offre une contextualisation globale pour chaque requête car notre objectif est autant de réaliser un moteur de recherche que d'offrir à nos utilisateurs une plateforme de veille concurrentielle entre les différentes stratégies de communication des candidats. Rappelons que ces deux applications (moteur et système de veille) partent de postulats opposés, en effet si le moteur de recherche ambitionne de lutter contre le bruit (toutes les réponses doivent être le plus pertinentes possibles), un système de veille comparative, type benchmark, se fixe comme ambition de réduire le silence (aucun tweet pertinent ne doit échapper à l'usager). Or lorsque l'on tente de réduire le silence, on augmente le bruit, et plus on lutte contre le bruit, plus le silence devient assourdissant. En sciences de l'information, on évalue cette complexité par le taux de précision et de rappel qui sont deux équations qui modélisent parfaitement ces valeurs diamétralement opposées que sont le bruit et le silence.
Pour relever ce défi, nous nous sommes inspirés des applications de BI (business intelligence), d'outils de reporting et de système de cartographie de l'information. Habituellement, réservés à des outils de dashboarding ou de back office, nous proposons au grand public une extension des résultats de requêtes par l'intégration visuelle et progressive d'une information synthétique par analyse linguistique directement accessible sur notre front office.
Et la sécurité dans tout ça ?
L'interface du moteur de recherche développé est basée sur le framework AngularJS, et, par conséquent, les données d'Elasticsearch seront ouvertes au public. Afin d'empêcher l'accès à nos données, nous avons mis en place un contrôle d'accès à nos données en appliquant une restriction sur les permissions d'accès à Elasticsearch avec l'attribution de la permission lecture-seule au public.
Elasticsearch et Kibana (dont l'utilisation sera décrite ci-dessous) utilisent respectivement les ports 9200 et 5601 ; ainsi, pour éviter l'accès direct du client à l'index à travers les ports, nous avons mis en place, comme indiqué dans la Figure 2, un reverse proxy qui permet de contrôler toutes les demandes d'accès directes de l'extérieur et qui n'autorise que la méthode GET. Ce proxy d'Apache devient un intermédiaire pour crypter le trafic entrant. Donc, le trafic externe sera converti en trafic interne entre Apache et Elasticsearch.
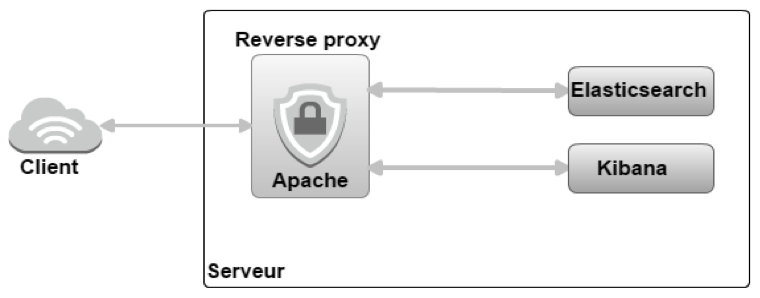
Et pour visualiser nos données…? Kibana, évidemment !
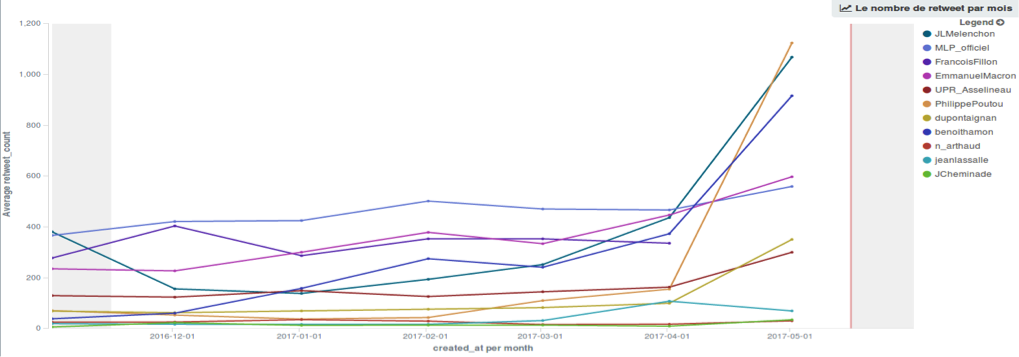
Nous utilisons Kibana dans le but de réaliser des analyses sur nos données textuelles sous forme de graphes. La figure 3 montre l'évolution de la moyenne par mois du nombre de retweets pour chaque candidat durant les six derniers mois. Nous pouvons remarquer un pic de retweets pendant le dernier mois qui précède l'élection présidentielle pour plusieurs des candidats, les premiers étant Philippe Poutou, Jean-Luc Mélenchon et Benoît Hamon.
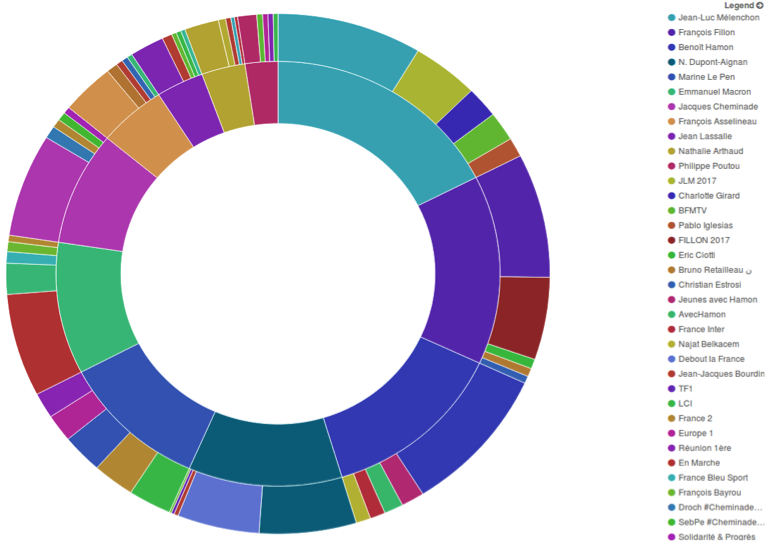
La figure 4 se compose de deux diagrammes camembert : celui de l'intérieur représente la décomposition des 11 candidats selon le nombre de tweets et celui de l'extérieur représente le pourcentage des cinq utilisateur Twitter les plus mentionnés par les candidats.
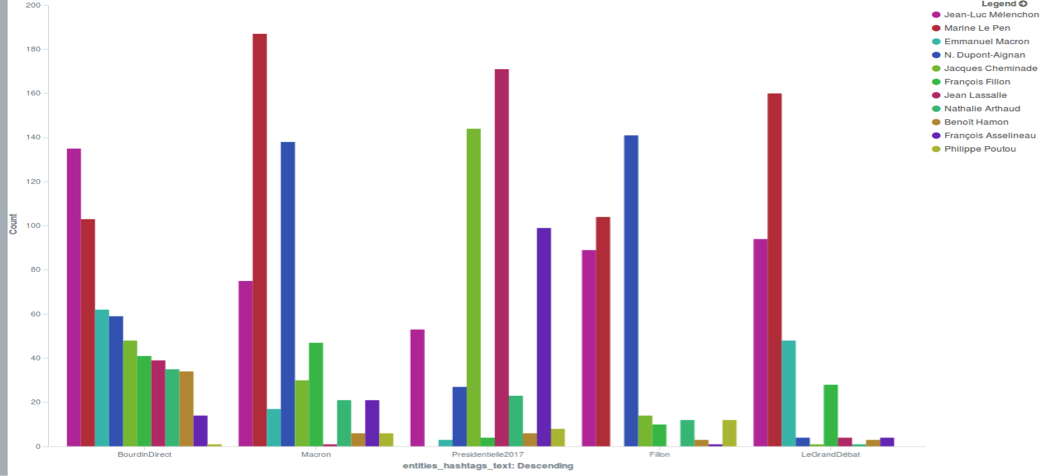
La figure 5 est un diagramme à bandes verticales ; ici nous comparons les 11 candidats par rapport aux cinq hashtags les plus utilisés : #BourdinDirect, #Macron, #Presidentielle2017, #Fillon, #LeGrandDébat.
Que peut-on découvrir lors des analyses ?
Un exemple intéressant est celui du mot « islam ». Si on cherche à comparer son usage par les différents candidats, on obtient le graphique de la figure 6 (qui indique le sur/sous emploi du mot chez chacun des candidats au regard de l'ensemble des tweets recensés) :
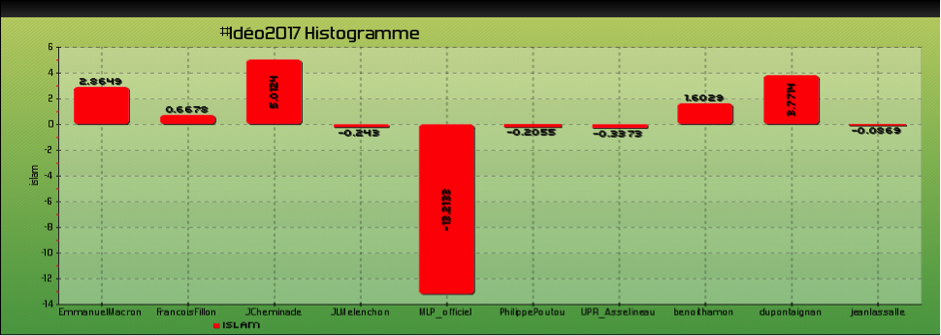
On constate ainsi le sous-emploi de « islam » par Marine Le Pen, et l'emploi relativement modeste par François Fillon. Il s'agit de la forme « islam », sans les termes qui peuvent être associés. On peut alors chercher l'emploi de ce mot et de ses dérivés, et en observer leur fréquence, comme dans la figure 7 :
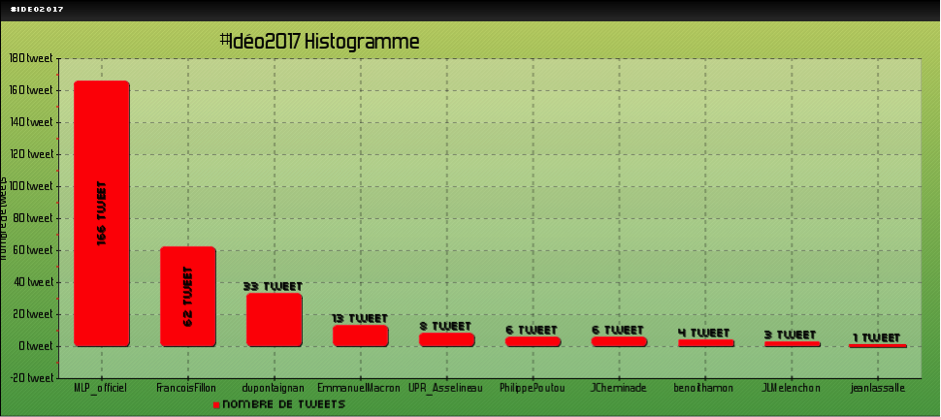
Même si le calcul n'est pas le même que dans le graphique précédent (ici il s'agit de fréquences), on perçoit néanmoins que l'usage du mot « islam » n'est pas neutre car ses dérivés semblent être un enjeu fort dans la rhétorique de certains candidats. Ceci se voit d'ailleurs dans la représentation visuelle des associations faites autour de ce terme dans la figure 8 :
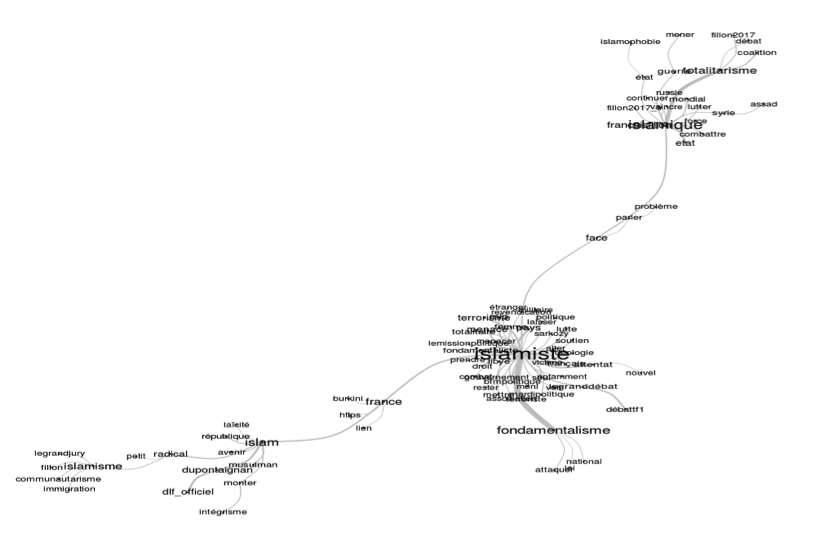
« Islam » est en effet très lié à différents réseaux ou nœuds qui ouvrent sur des enjeux discursifs très marqués : autour des associations « islamisme-immigration-communautarisme », mais aussi « islamiste-fondamentaliste-idéologie-attentat-terrorisme », ou encore « islamique-totalitarisme-Syrie » par exemple.
Ce parcours nous invite donc à nous pencher de manière plus précise sur les différents emplois du mot « islam » et de ses dérivés. Le retour au corpus est rendu possible grâce à la partie « navigation » par filtre, qui permet une représentation par facettes.
La recherche « islam » de la figure 9 ouvre sur les différents résultats de ce mot et ses dérivés par moteur de recherche :
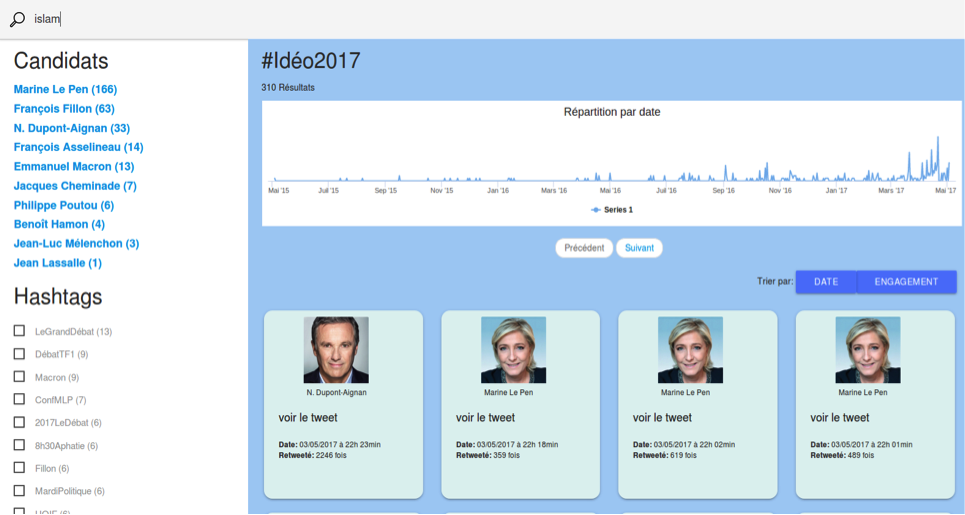
L'utilisation d'Elasticsearch garantit donc une expérience interactive et intuitive pour l'utilisateur, qui peut prolonger les résultats et hypothèses obtenus dans les analyses linguistiques.
En conclusion : le rôle pivot d'Elasticsearch pour la plateforme #Idéo2017
Recherche en plein texte, moteur de recherche, mise en place de l'index, etc., Elasticsearch a donc été un outil efficace pour mettre en place la plateforme #Idéo2017, et pour en garantir l'efficacité. Il s'intègre parfaitement aux autres technologies utilisées, et permet une bonne adéquation entre les besoins scientifiques de l'équipe du projet, et les besoins de résultats concrets des citoyens.
Nader Hassine. Développeur web backend en PHP et frontend au laboratoire ETIS (Equipes Traitement de l'Information et Systèmes, ETIS - ENSEA / UCP / CNRS UMR 8051) et stagiaire au laboratoire AGORA (université de Cergy-Pontoise), il prépare son mémoire de fin d'études dans le domaine du traitement automatique de la langue (M2 TAL université Grenoble Alpes)
Abdulhafiz ALKHOULI. Doctorant, ingénieur de recherche à l'Université de Cergy-Pontoise, laboratoire ETIS. Il travaille sur les algorithmes de top-k et les modèles de ranking dans le contexte des réseaux sociaux. Il a développé une bonne expertise dans le traitement des flux d'informations, la recherche d'information, l'indexation et le machine learning. Il est passionné par le phénomène Big Data et ses différentes technologies, le pattern MapReduce, Spark et Elasticsearch.
Boris Borzic. PhD Ingénieur de Recherche CNRS/Université de Cergy-Pontoise Laboratoire ETIS, spécialiste SIC/TIC - Web Social Information Retrieval/Data scientist/Real Time Search/SocialRank/the curation/Text Mining/intelligent reporting.
Claudia Marinica. Maître de conférences en informatique à l'Université de Cergy-Pontoise (dpt MMI de l'IUT), elle mène son activité de recherche au sein de l'équipe MIDI du laboratoire ETIS. Elle a obtenu un doctorat en informatique de l'Université de Nantes à l'Ecole Polytechnique de l'Université de Nantes en 2010. Depuis 2007, elle s'implique fortement dans la vie de l'Association "Extraction et Gestion de Connaissances" (EGC) et dans l'organisation de la conférence francophone du même nom. Ses thèmes de recherche concernent la Fouille de Données, le Web Sémantique et les Réseaux Sociaux.
Julien Longhi. Professeur des universités en sciences du langage, spécialiste d'analyse du discours, de sémantique et de linguistique de corpus. Il travaille depuis 2012 sur les tweets politiques, et collabore avec les informaticiens du laboratoire ETIS depuis 2013. Il développe une approche outillée de l'analyse du discours, intégrant des apports de la fouille de texte et de la textométrie. Il dirige le département Métiers du multimédia et de l'internet de l'IUT de Cergy-Pontoise.