Prise en main du langage de requête d'Elasticsearch, ES|QL
Accédez plus rapidement à des informations exploitables en créant des agrégations, des visualisations et des alertes directement depuis Discover avec ES|QL.

 Share on Twitter
Share on TwitterPartager sur Twitter

 Share on LinkedIn
Share on LinkedInPartager sur LinkedIn

 Share on Facebook
Share on FacebookPartager sur Facebook

 Share by Email
Share by EmailPartage par e-mail

 Print this page
Print this pageImprimer
Qu'est-ce que ES|QL, le langage de requête d'Elasticsearch ?
ES|QL est le nouveau langage de requête canalisé innovant d'Elastic®. Il est conçu pour accélérer les processus d'analyse et d'examen de vos données grâce à des capacités puissantes de calcul et d'agrégation.
Une attaque est en cours ? Un problème de production se présente ? Repérez-les avec facilité et efficacité.
Non seulement ES|QL simplifie la recherche, l'agrégation et la visualisation d'ensembles de données volumineux, mais il fournit aussi aux utilisateurs des fonctionnalités avancées comme le référencement ou le traitement en temps réel, le tout à partir d'un seul et même écran dans Discover.
Trois capacités puissantes ajoutées à la Suite Elastic par ES|QL
-
Un nouveau moteur de requête rapide, distribué et dédié qui optimise _query. Le nouveau moteur de requête ES|QL fournit des capacités de recherche avancées avec traitement simultané, qui améliorent la vitesse et l'efficacité quelles que soient la source de données et la structure. Les performances du nouveau moteur sont mesurées et publiques. Comparez les différentes performances dans ce tableau de bord public.
-
Un nouveau langage canalisé puissant. ES|QL est le nouveau langage canalisé d'Elastic qui transforme, enrichit et simplifie l'examen des données. Pour en savoir plus sur les capacités du langage ES|QL, consultez la documentation.
-
Une nouvelle expérience unifiée d'exploration et d'examen des données qui accélère la résolution en créant des agrégations et des visualisations à partir d'un seul et même écran, pour un workflow continu.
Pourquoi avons-nous investi du temps et des efforts dans ES|QL ?
Nos utilisateurs ont besoin d'outils agiles qui présentent les données, mais pas seulement. Ils doivent aussi proposer des méthodes efficaces pour extraire le sens de ces données, ainsi que la possibilité d'agir en temps réel en fonction des informations révélées et après le traitement des données ingérées.
Elastic s'est engagée à améliorer l'exploration des données pour les utilisateurs. C'est cet engagement qui nous a conduits à investir dans ES|QL. Ce langage est conçu pour être accessible pour les novices et puissant pour les utilisateurs chevronnés. Avec l'interface intuitive d'ES|QL, les utilisateurs peuvent se lancer rapidement et étudier leurs données dans les détails sans courbe d'apprentissage difficile. La saisie automatique et la documentation dans l'application contribuent à faciliter le workflow, ce qui fait que les utilisateurs peuvent élaborer des requêtes avancées en toute simplicité.
De plus, ES|QL ne se contente pas de vous montrer de simples chiffres : il leur donne du sens. Les visualisations contextuelles optimisées par le moteur de suggestions de Lens s'adaptent automatiquement à la nature de vos requêtes. Vous disposez ainsi d'une vue claire et précise sur les informations exploitables.
À cela s'ajoute une intégration directe dans les fonctionnalités Dashboards et Alerting, ce qui représente bien notre vision d'une expérience cohérente de bout en bout.
En substance, notre investissement dans ES|QL est une réponse directe à l'évolution des besoins de notre communauté. Il s'agit d'un nouveau pas vers un workflow plus interconnecté, plus pertinent et plus efficace.
Approfondissement des cas d'utilisation de sécurité et d'observabilité
Si nous nous sommes tant investis dans ES|QL, c'est aussi parce que nous sommes bien conscients des problématiques auxquelles sont confrontés nos utilisateurs, qu'il s'agisse des ingénieurs de fiabilité des sites (SRE), des DevOps ou encore des équipes travaillant à la détection des menaces.
Pour les SRE, l'observabilité est essentielle. Chaque seconde d'indisponibilité ou de bug peut avoir un effet boule de neige sur l'expérience de l'utilisateur, et de là, sur le résultat net. Pour éviter ce scénario, on peut compter sur la fonctionnalité Alerting d'ES|QL : en faisant ressortir les grandes tendances plutôt que les incidents isolés, cette fonctionnalité aide les SRE à repérer les inefficacités ou les dysfonctionnement des systèmes et à y remédier de manière proactive. Ainsi, les SRE peuvent se concentrer sur les menaces authentiques qui planent sur la stabilité des systèmes sans se laisser distraire par des interférences, ce qui rend leur réponse plus opportune et plus efficace.
Les équipes DevOps sont engagées dans une course continue contre la montre : le nombre de correctifs, de mises à jour et de nouvelles fonctionnalités qu'elles déploient est tout simplement énorme. Grâce aux nouvelles fonctionnalités puissantes d'exploration et de visualisation des données d'ES|QL, elles peuvent rapidement évaluer l'impact de chaque déploiement, monitorer l'intégrité des systèmes et recevoir des retours en temps réel. Cela permet non seulement d'améliorer la qualité des déploiements, mais aussi de rectifier rapidement le tir si besoin.
Concernant les équipes de détection des menaces, le paysage de la sécurité ne cesse d'évoluer et de se modifier. Pour les aider à faire face à ce changement perpétuel, ES|QL propose la fonctionnalité ENRICH. Cette fonctionnalité leur permet de référencer les données dans différents ensembles, et de là, d'identifier les schémas masqués ou les anomalies cachées qui pourraient indiquer une menace de sécurité. En outre, grâce aux visualisations contextuelles, les équipes ont accès à des informations exploitables, présentées visuellement, pas juste à des données brutes. Cela leur permet de réduire drastiquement le temps nécessaire pour discerner les menaces potentielles et réagir aux vulnérabilités.
Que vous soyez ingénieur SRE et que vous tentiez de comprendre pourquoi un pic est survenu dans la charge du serveur, que vous soyez un professionnel des DevOps et que vous évaluiez l'impact de la dernière version, ou que vous fassiez partie de l'équipe de détection des menaces et que vous examiniez une faille éventuelle, ES|QL est là pour vous accompagner tout au long de votre parcours.
Dans les prochaines sections de cet article, vous découvrirez comment vous lancer avec ES|QL et vous verrez quelques exemples tangibles de sa puissance lors de l'exploration des données.
Premiers pas avec ES|QL dans Kibana
Pour commencer à utiliser ES|QL, accédez à Discover et sélectionnez Try ES|QL (Essayer ES|QL) dans le sélecteur de vues des données. C'est simple et convivial.
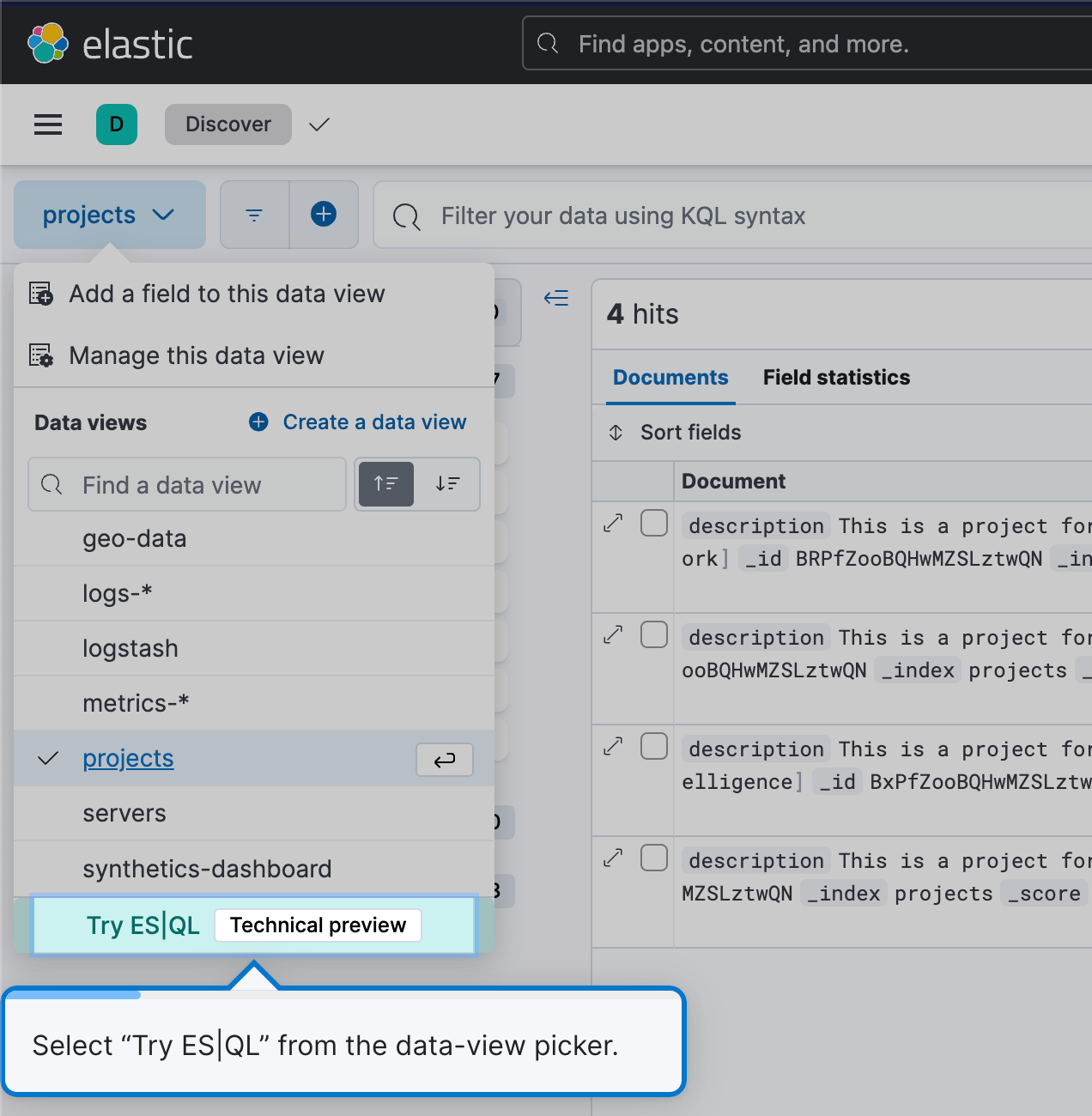
Vous accéderez ainsi au mode ES|QL dans Discover.
Une création de requêtes simple et efficace
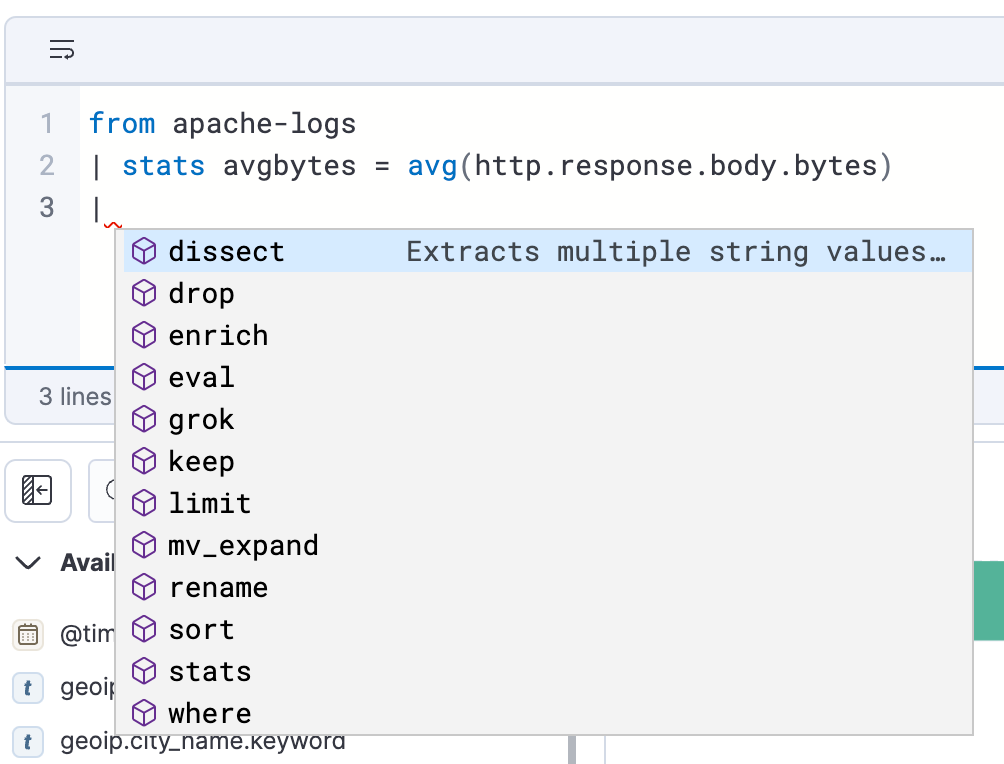
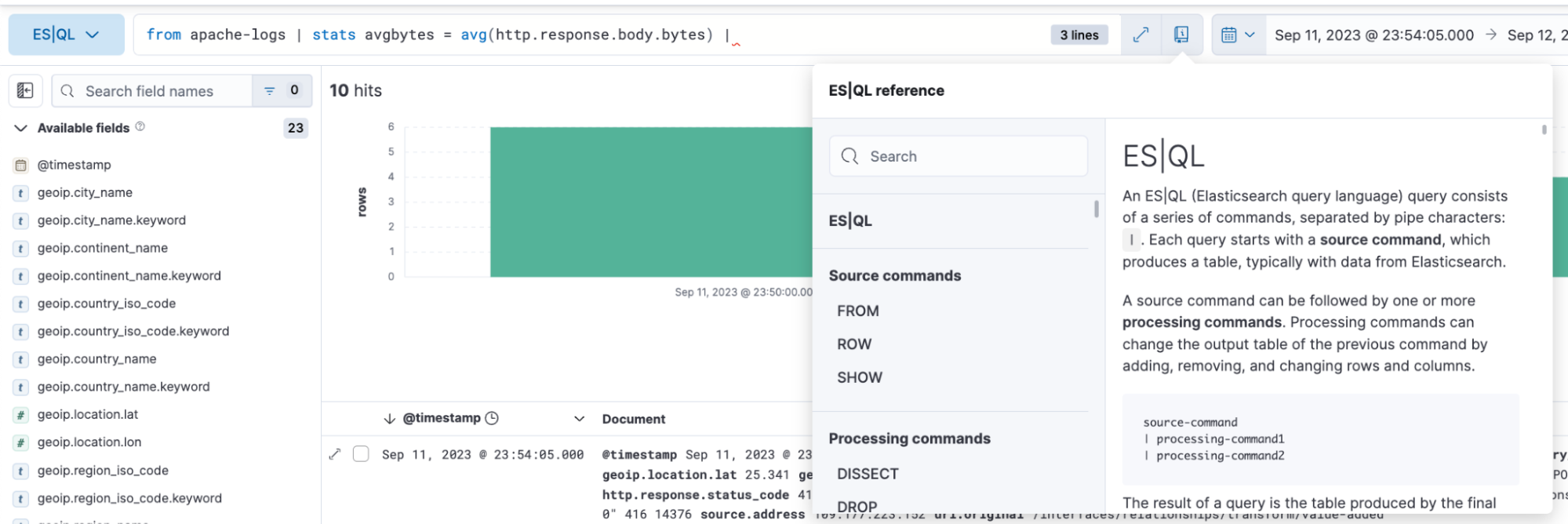
ES|QL dans Discover propose la saisie semi-automatique et la documentation dans l'application. Vous pouvez donc facilement élaborer des questions puissantes à partir de la barre de requête.
Analyse et visualisation des données avec ES|QL
Avec ES|QL, explorez vos données sous tous les angles. Ce langage vous permet d'étudier vos données dans Discover de manière ad hoc, de créer des agrégations, de transformer vos données, d'enrichir les ensembles de données, et bien plus encore. Le tout, depuis l'outil de création des requêtes. Les résultats sont présentés sous forme de tableau ou de visualisations. Tout dépend de la requête que vous exécutez.
Vous trouverez ci-dessous des exemples de requêtes ES|QL pour l'observabilité, ainsi que la représentation des résultats associés sous forme de tableau ou de visualisation.
Requête ES|QL avec indicateurs :
from metrics*
| stats max_cpu = max(kubernetes.pod.cpu.usage.node.pct), max_mem = max(kubernetes.pod.memory.usage.bytes) by kubernetes.pod.name
| sort max_cpu desc
| limit 10La requête ci-dessus illustre comment utiliser la commande source, les fonctions d'agrégation et les commandes de traitement indiquées ci-dessous :
from : commande source (cf. documentation)
from metrics*: permet de lancer une requête à partir de modèles d'indexation correspondant au modèle "metrics*". L'astérisque (*) a l'effet d'un caractère générique, ce qui signifie qu'il va sélectionner les données de tous les modèles d'indexation dont les noms commencent par "metrics".
stats…by : agrégations (cf. documentation), max (cf. documentation) et by (cf. documentation)
Ce segment agrège les données selon des statistiques spécifiques. En voici la décomposition :
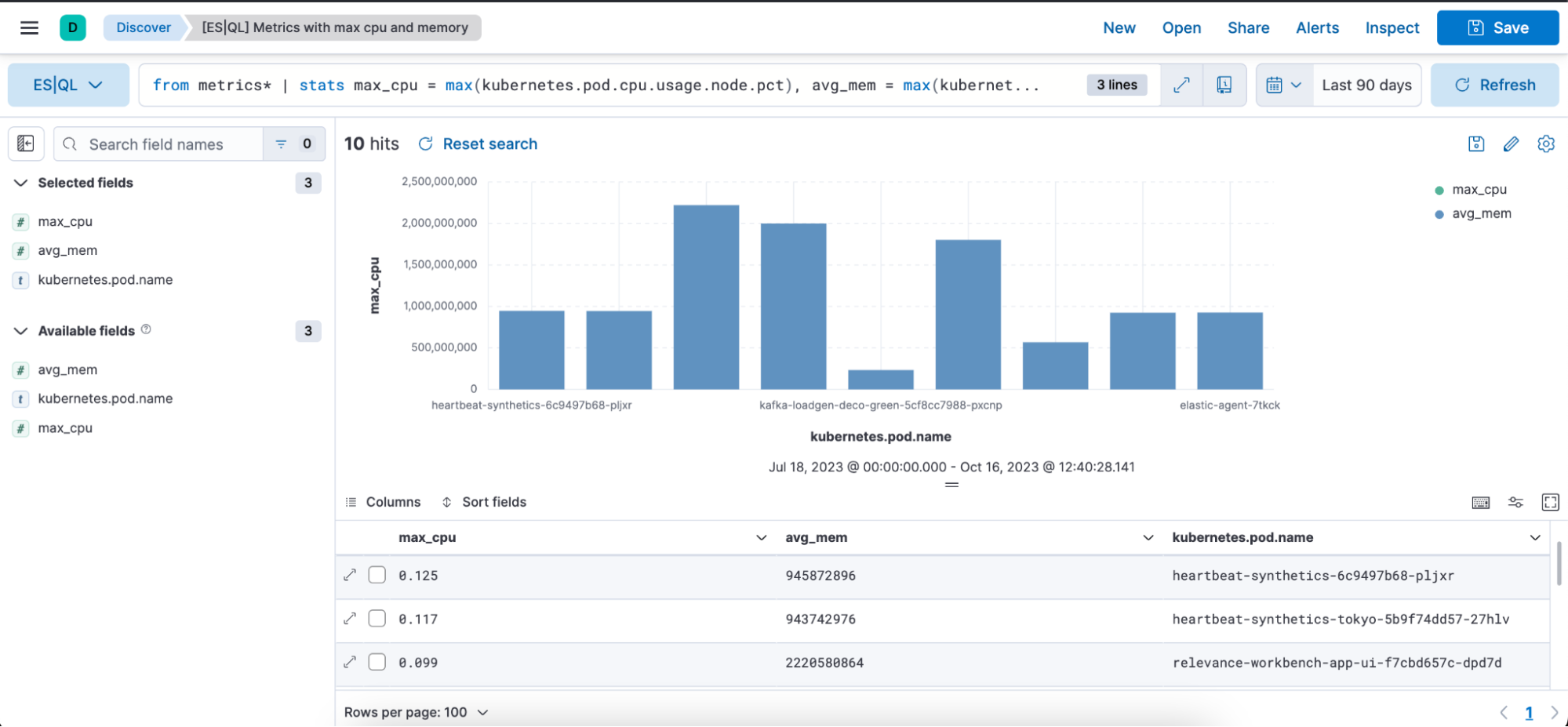
max_cpu=max(kubernetes.pd.cpu.usage.node.pct) : pour chaque "kubernetes.pod.name", il détermine le pourcentage d'utilisation maximale de la CPU et stocke cette valeur dans une nouvelle colonne appelée "max_cpu".
max_mem = max(kubernettes.pod.memory.usage.bytes) : pour chaque "kubernetes.pod.name", il détermine l'utilisation maximale de mémoire en octets et stocke cette valeur dans une nouvelle colonne appelée "avg_mem".
Commandes de traitement (cf. documentation)
- sort (cf. documentation)
- limit (cf. documentation)
sort max_cpu desc : permet de trier les lignes de données obtenues selon la colonne "max_cpu" dans l'ordre décroissant. De ce fait, la ligne ayant la valeur "max_cpu" la plus élevée apparaîtra en premier.
limit 10 : permet de limiter la sortie aux 10 premières lignes une fois le tri effectué.
En résumé, la requête :
- regroupe les données de tous les index d'indicateurs selon un modèle d'indexation ;
- agrège les données pour déterminer le pourcentage d'utilisation maximale de la CPU et l'utilisation maximale de la mémoire pour chaque pod Kubernetes ;
- trie les données agrégées par ordre décroissant selon l'utilisation maximale de la CPU ;
- renvoie uniquement les 10 premières lignes correspondant aux valeurs les plus élevées d'utilisation de la CPU ;
Visualisations contextuelles : lorsque vous écrivez des requêtes ES|QL dans Discover, vous obtenez des représentations visuelles optimisées par le moteur de suggestions de Lens. La nature de votre requête détermine le type de visualisation renvoyé : interroger, histogramme, carte thermique, etc.
Vous trouverez ci-dessous une représentation visuelle de la requête indiquée plus haut sous forme de graphique à barres et sous forme de tableau, avec les colonnes max_cpu, avg_mem et kubernetes.pod.name :
Exemple de requête ES|QL pour l'observabilité et les données temporelles :
from apache-logs |
where url.original == "/login" |
eval time_buckets = auto_bucket(@timestamp, 50, "2023-09-11T21:54:05.000Z", "2023-09-12T00:40:35.000Z") |
stats login_attempts = count(user.name) by time_buckets, user.name |
sort login_attempts descLa requête ci-dessus illustre comment utiliser la commande source, les fonctions d'agrégation, les commandes de traitement et les fonctions indiquées ci-dessous :
from : commande source (cf. documentation)
from apache-logs : permet de lancer une requête à partir d'un index appelé "apache-logs". Cet index contient des entrées de log en lien avec le trafic du serveur web Apache.
where (cf. documentation)
where url.original==”/login” : filtre les enregistrements pour lesquels le champ "url.original" a pour valeur "/fr/login". Cela signifie que nous sommes intéressés uniquement par les entrées de log appartenant aux tentatives de connexion ou aux accès à la page de connexion.
eval (cf. documentation) et auto_bucket (cf. documentation)
eval time_buckets =... : entraîne la création d'une nouvelle colonne appelée "time_buckets".
La fonction "auto_bucket" crée des buckets conviviaux et renvoie une valeur d'horodatage pour chaque ligne qui correspond à un bucket créé.
“@timestamp” est le champ qui indique l'horodatage de chaque entrée de log.
"50" est le nombre de buckets.
"2023-09-11T21:54:05.000Z" : horodatage de départ pour le bucket.
"2023-09-12T00:40:35.000Z" : horodatage de fin pour le bucket.
Cela signifie que les entrées de log comprises entre les horodatages "2023-09-11T21:54:05.000Z" et "2023-09-12T00:40:35.000Z" seront réparties en 50 intervalles espacés de manière égale. Chaque entrée sera associée à un intervalle spécifique en fonction de son horodatage.
Le but n'est pas de fournir le nombre précis de buckets, mais plutôt de sélectionner une plage avec laquelle vous vous sentez à l'aise pour travailler et qui fournit le nombre cible de buckets. Si vous demandez à avoir un plus grand nombre de buckets, alors auto_bucket peut sélectionner une plage plus petite.
stats…by : agrégations (cf. documentation), count (cf. documentation) et by (cf. documentation)
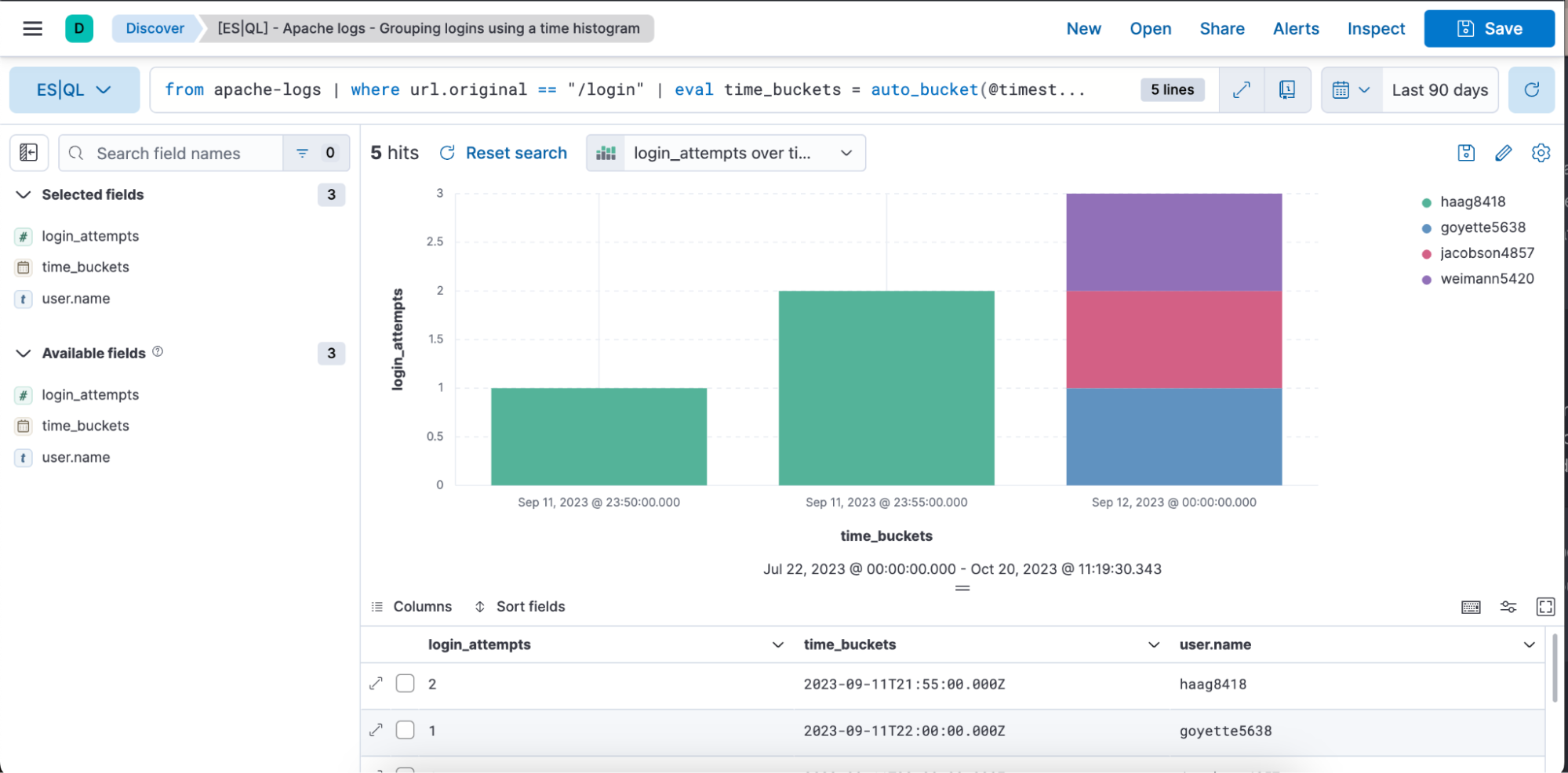
stats login_attempts = count(user.name) by time_buckets, user.name : permet d'agréger les données pour calculer le nombre de tentatives de connexion. Pour cela, cet élément compte les occurrences de "user.name" (représentant chaque utilisateur unique essayant de se connecter).
Le décompte est effectué en regroupant "time_buckets" (les intervalles de temps que nous avons créés) et "user.name". Cela signifie que pour chaque bucket temporel, nous verrons le nombre de tentatives que chaque utilisateur a effectué pour se connecter.
sort (cf. documentation)
Sort login_attempts desc : pour finir, les résultats agrégés sont triés selon la colonne "login_attempts" dans l'ordre décroissant. Le premier résultat affiché correspondra donc au nombre de tentatives de connexion le plus élevé.
En résumé, la requête :
- sélectionne les données dans l'index "apache-logs" ;
- filtre les entrées de log concernant la page de connexion ;
- regroupe ces entrées dans des intervalles de temps spécifiques ;
- compte le nombre de tentatives de connexion de chaque utilisateur dans ces intervalles ;
- renvoie des résultats triés en fonction du nombre de tentatives de connexion effectuées, le plus grand nombre apparaissant en premier.
Vous trouverez ci-dessous une représentation visuelle de la requête indiquée plus haut sous forme de graphique à barres et sous forme de tableau, avec les colonnes login_attempts, time_buckets et user.name.
Modification ligne par ligne d'une visualisation dans Discover et Dashboard
Modifiez les visualisations d'ES|QL directement dans Discover et Dashboards. Vous n'avez pas besoin d'accéder à Lens pour effectuer des modifications rapides, vous pouvez les faire directement de façon transparente.
Ci-dessous, vous trouverez une vidéo présentant un workflow de bout en bout, ainsi qu'un guide détaillé :
Écrire une requête ES|QL
Obtenir une visualisation contextuelle en fonction de la nature de la requête
Modifier la visualisation ligne par ligne
L'enregistrer dans un tableau de bord
Être capable de modifier la visualisation depuis un tableau de bord
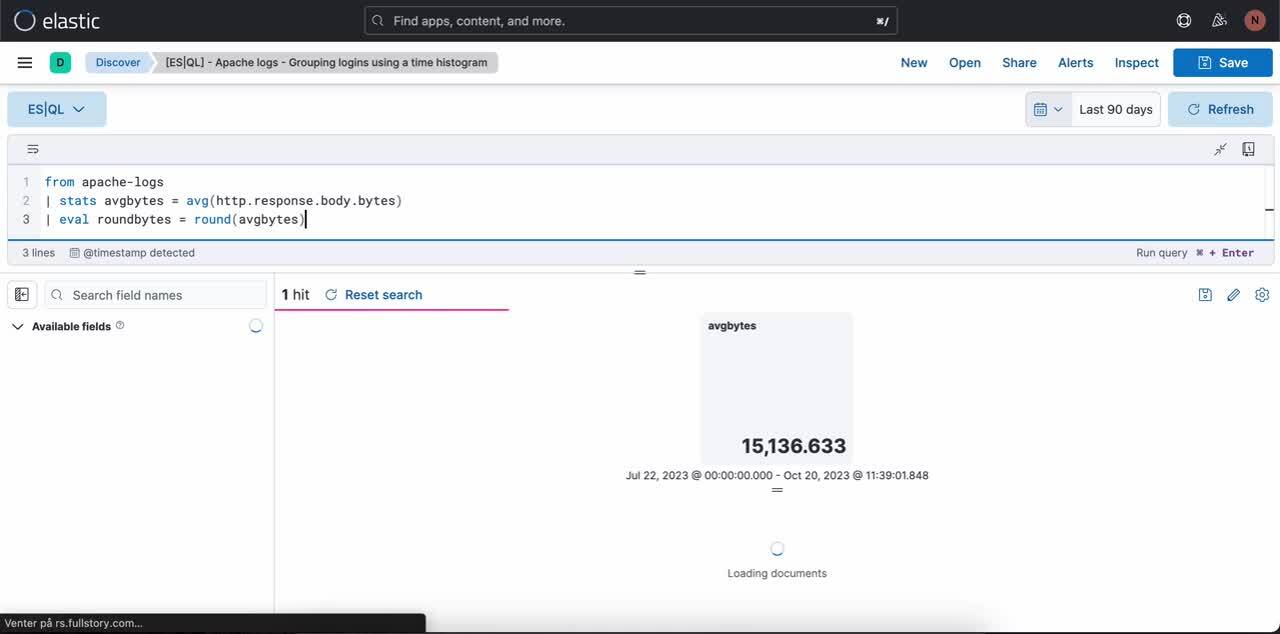
1ère étape. Écrire une requête ES|QL. Exemple de requête produisant une visualisation d'indicateurs :
from apache-logs
| stats avgbytes = avg(http.response.body.bytes)
| eval roundbytes = round(avgbytes)
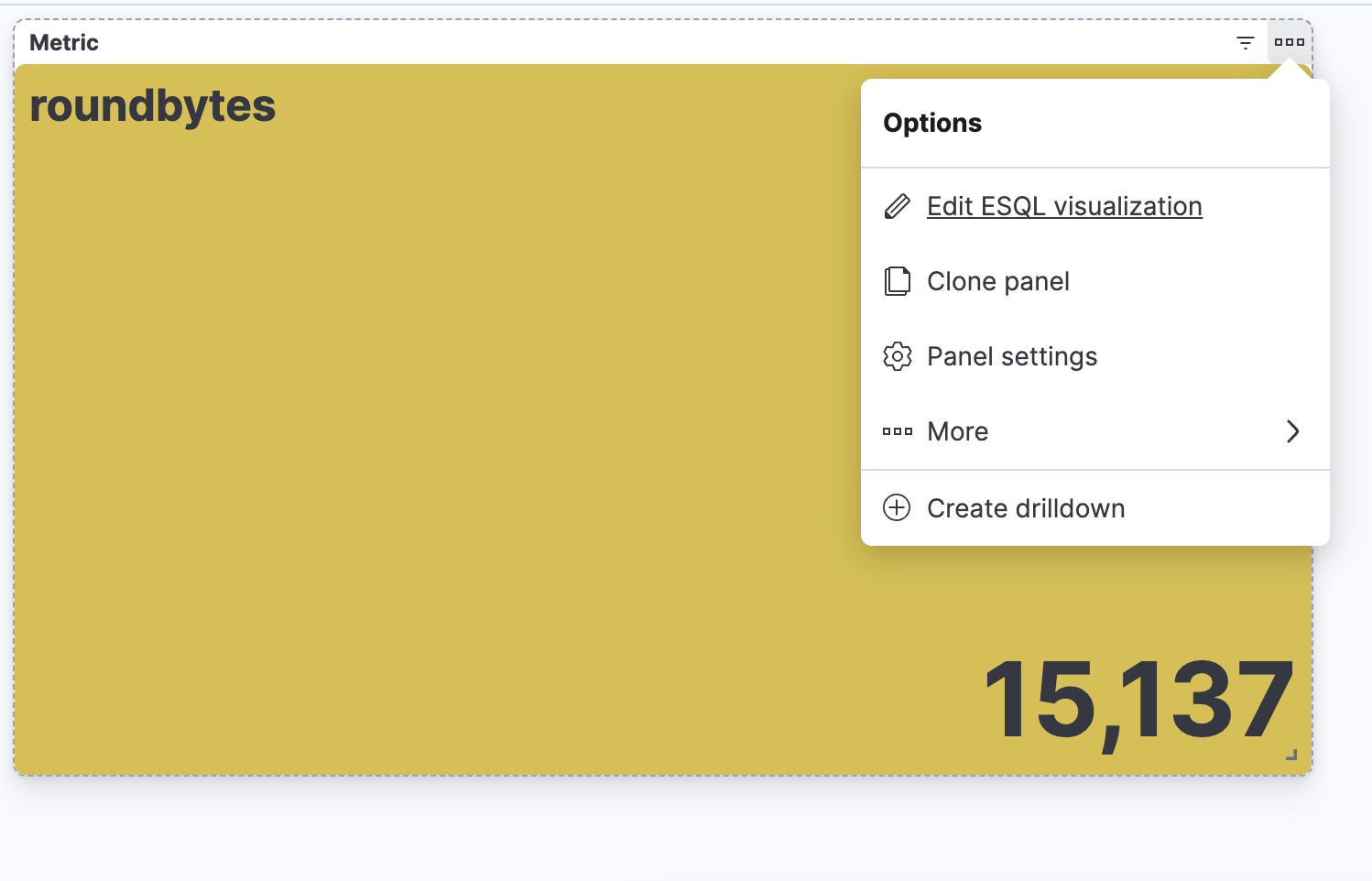
| drop avgbytes2e étape. Obtenir une visualisation contextuelle (dans le cas présent, une visualisation d'indicateurs) en fonction de la nature de la requête. Vous pouvez sélectionner l'icône en forme de crayon pour accéder au mode de modification ligne par ligne.
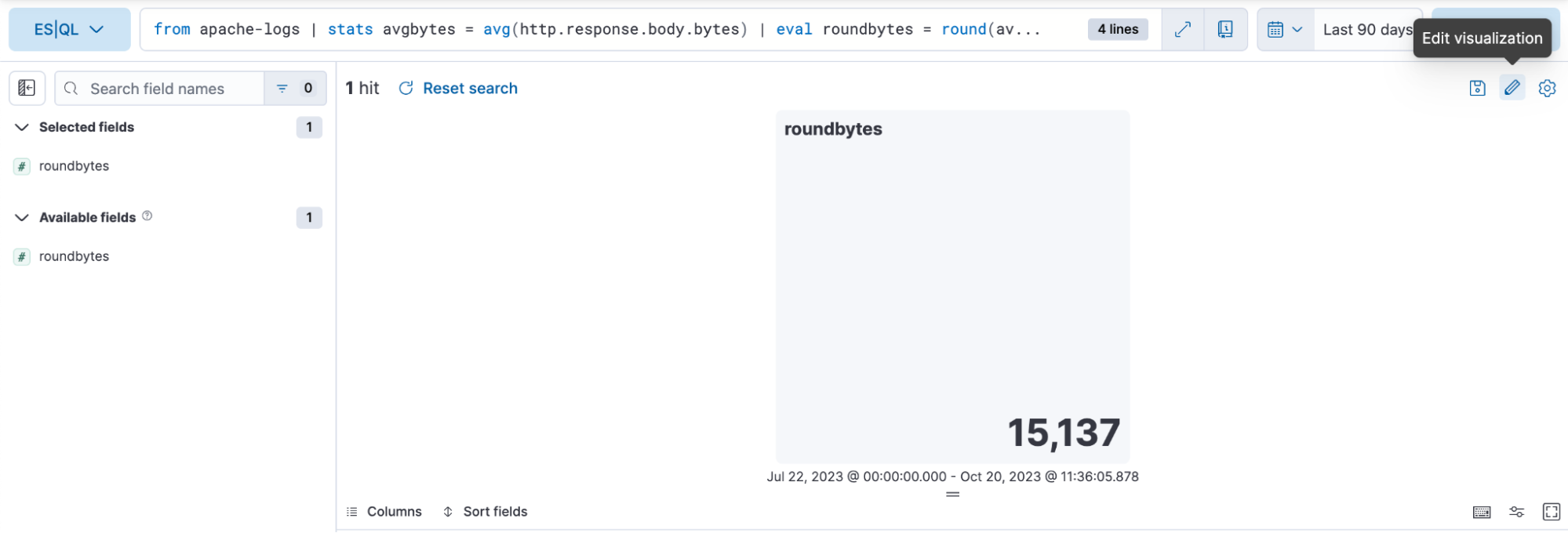
3e étape. Modifier la visualisation à l'aide du mode de modification ligne par ligne.
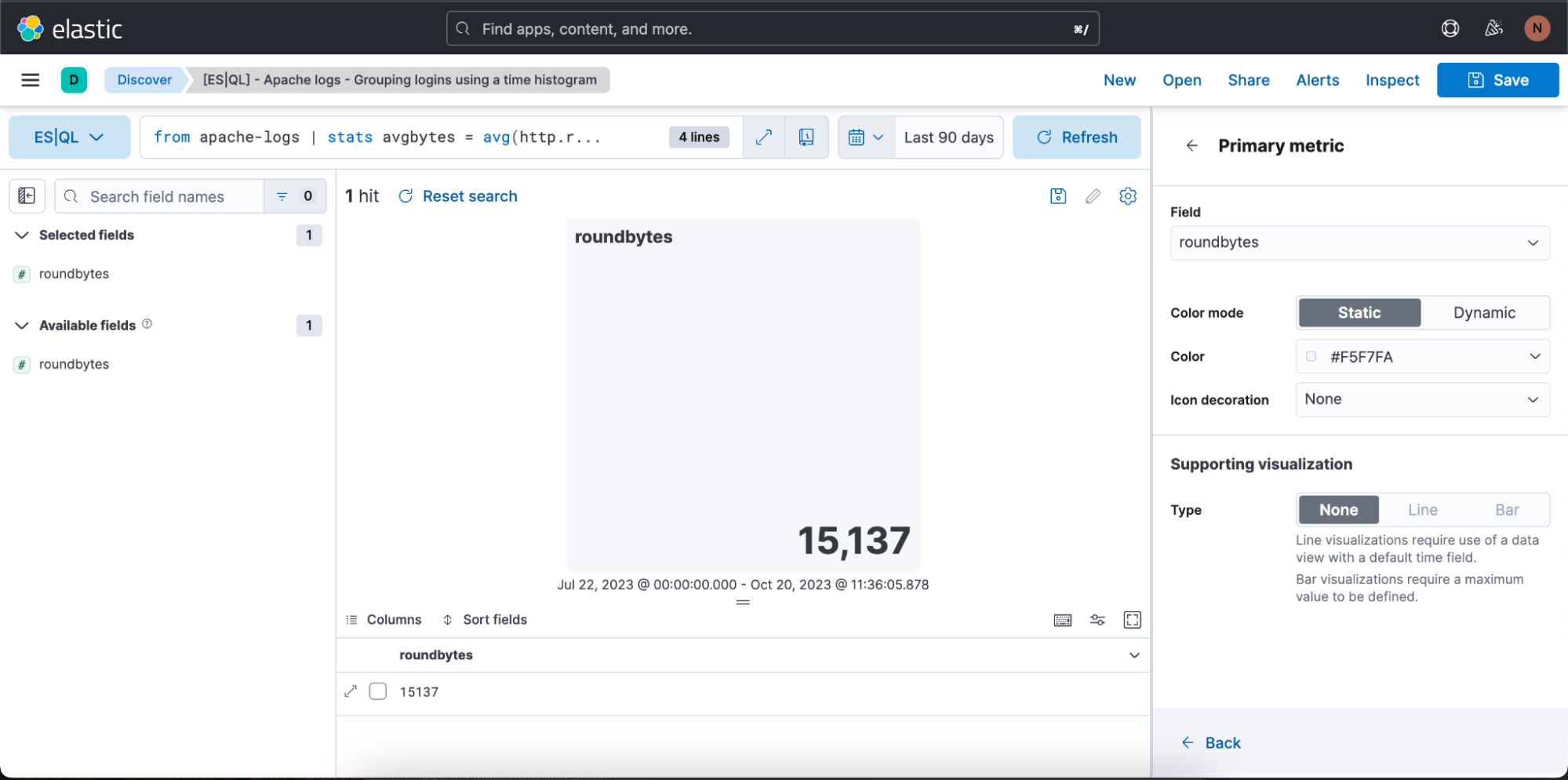
Dans le cas ci-dessus, nous souhaitons que le mode de couleur de la visualisation soit dynamique. Nous cliquons donc sur "Dynamic" (Dynamique).
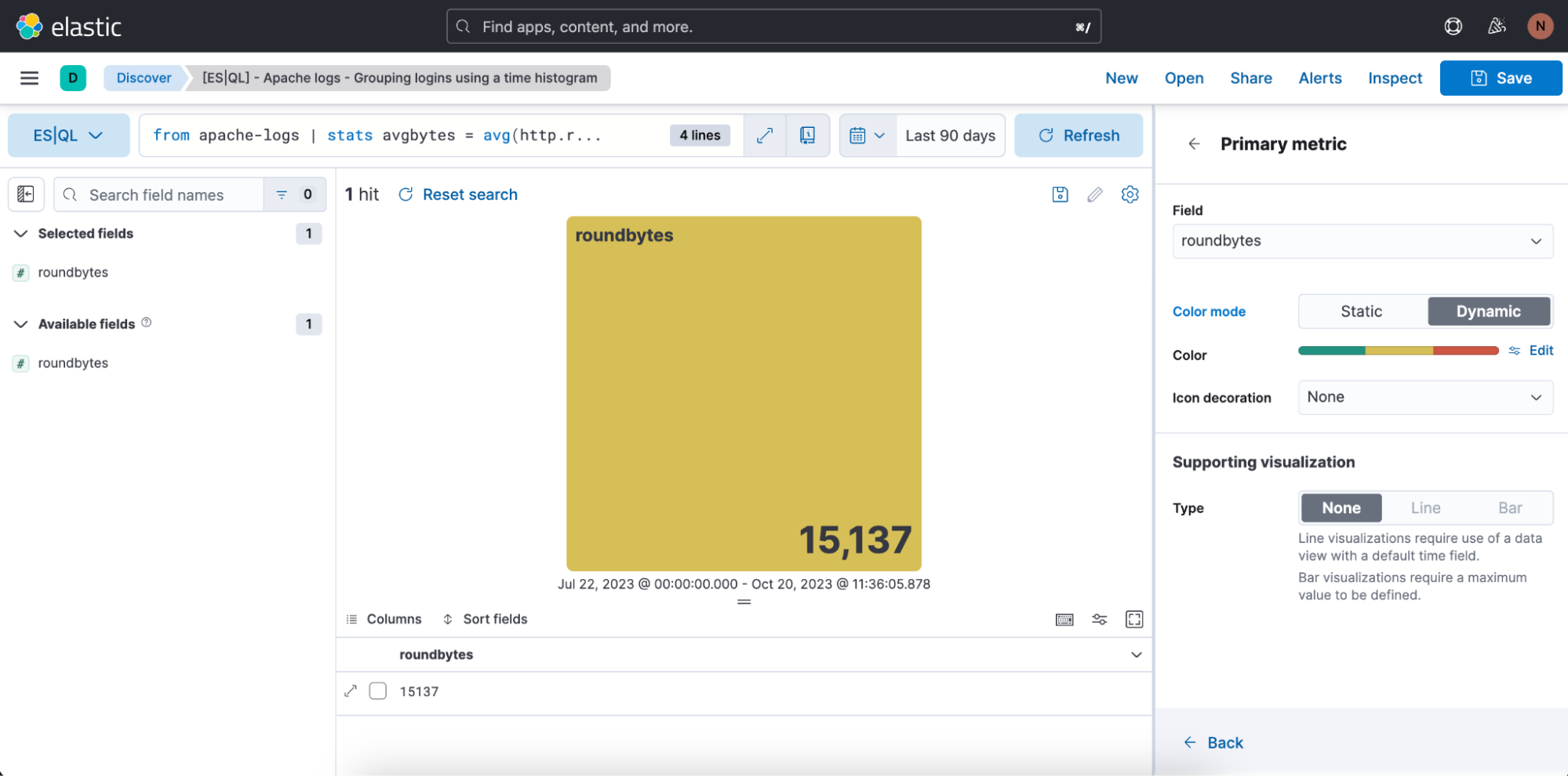
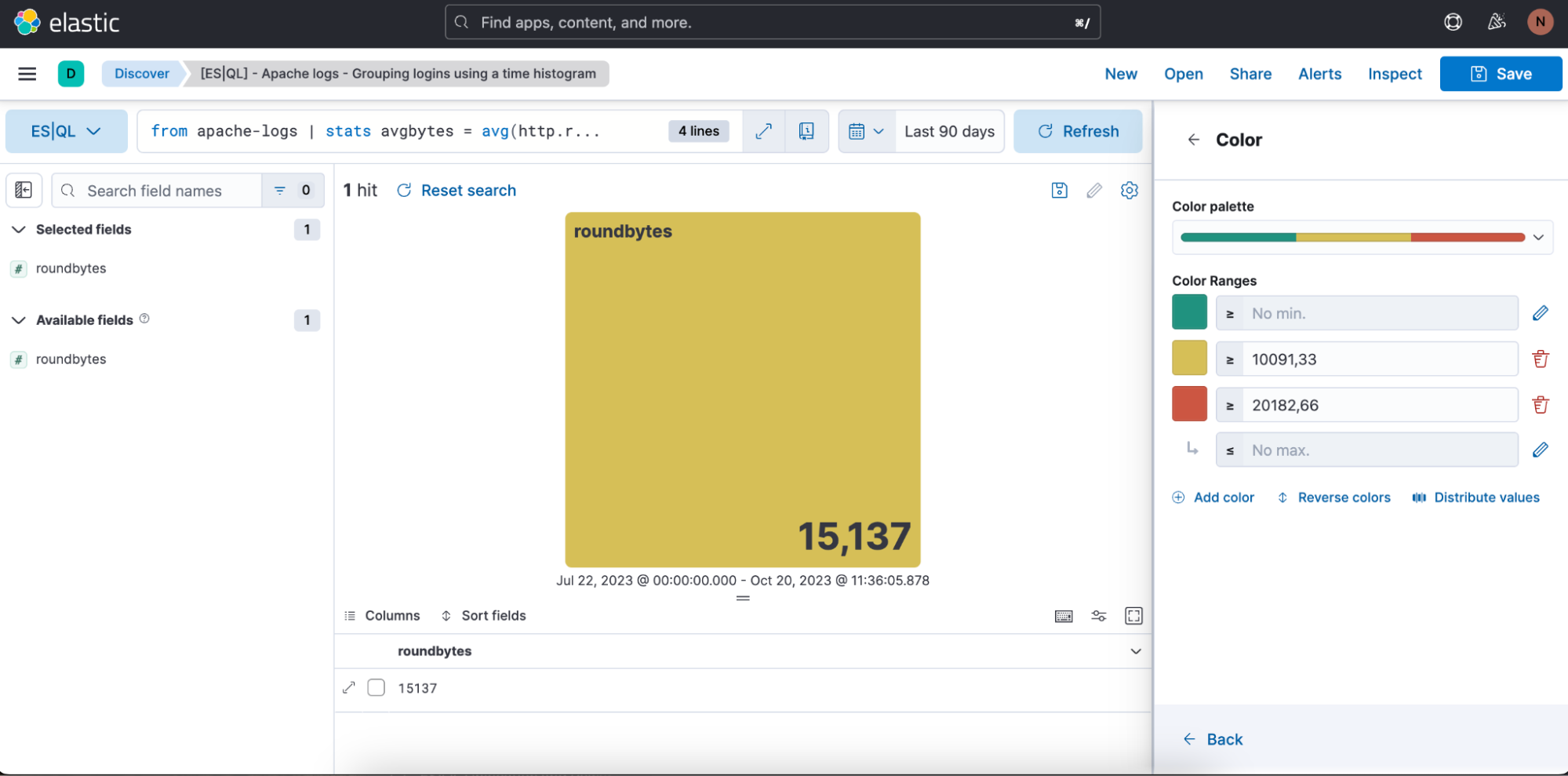
Nous avons aussi la possibilité de définir la plage de couleurs que nous souhaitons utiliser :
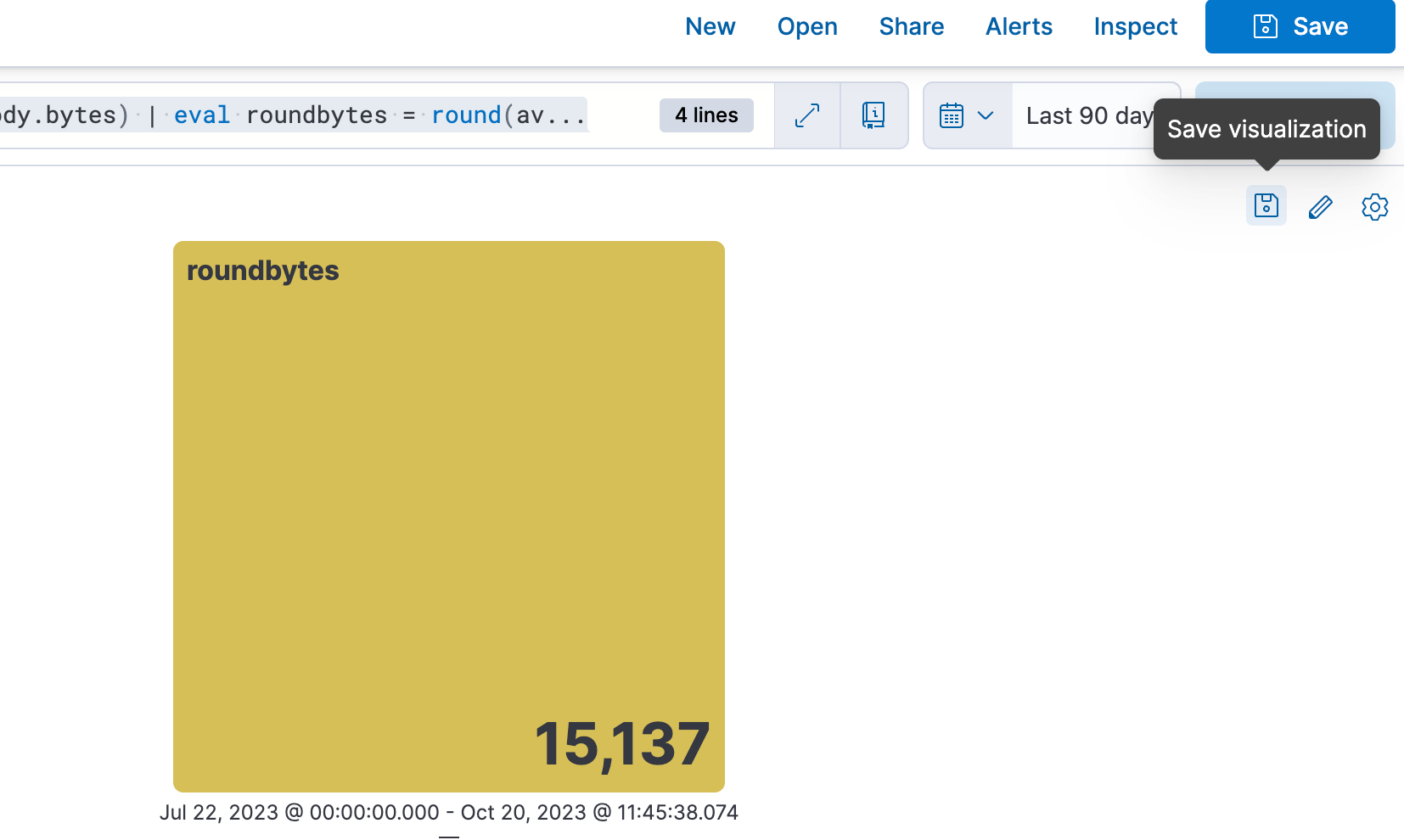
4e étape. Enregistrer la visualisation dans un tableau de bord.
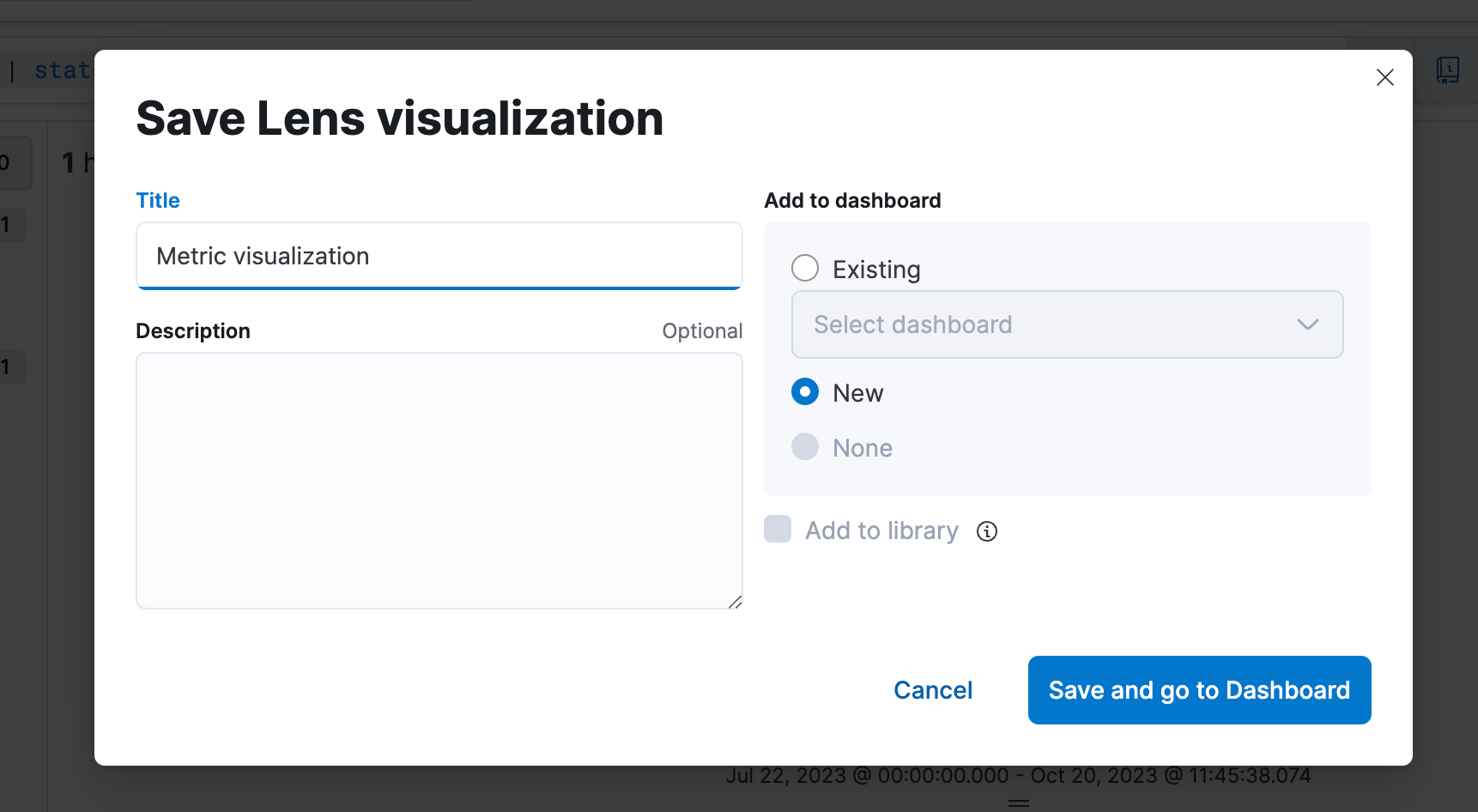
5e étape. Être capable de modifier la visualisation depuis un tableau de bord.
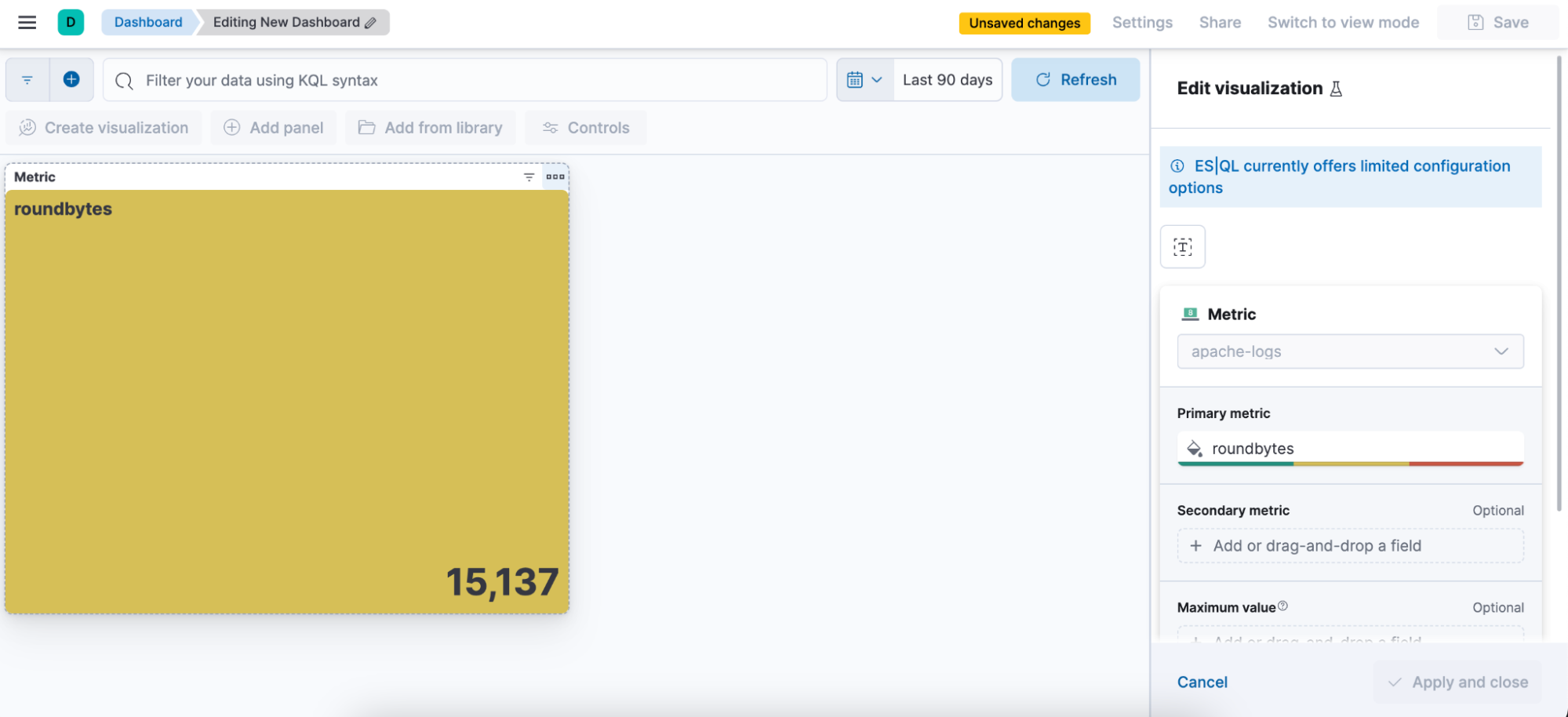
Création d'une alerte ES|QL directement depuis Discover
Vous pouvez utiliser ES|QL pour les alertes d'observabilité et de sécurité, en définissant des valeurs agrégées comme seuils. Améliorez la précision de la détection et recevez des notifications exploitables en mettant l'accent sur les grandes tendances plutôt que sur des incidents isolés, ce afin de réduire le nombre de faux positifs.
À présent, nous allons voir comment créer un type de règle d'alerte ES|QL à partir de Discover.
Le nouveau type de règle d'alerte est disponible dans le type de règle Elasticsearch existant. Ce type de règle dispose de toutes les nouvelles fonctionnalités accessibles dans ES|QL et permet de prendre en charge de nouveaux cas d'utilisation d'alerting.
Avec ce nouveau type, les utilisateurs pourront générer une alerte unique basée sur une requête ES|QL définie et en prévisualiser le résultat avant d'enregistrer la règle. Lorsque la requête renvoie un résultat vide, aucune alerte n'est générée.
Exemple de requête pour une alerte :
from metrics-pods |
stats max_cpu = max(kubernetes.pod.cpu.usage.node.pct) by kubernetes.pod.name|
sort max_cpu desc | limit 10
Comment créer une alerte à partir de Discover
1ère étape. Cliquez sur "Alerts" (Alertes), puis sur "Create search threshold rule" (Créer une règle de seuil de recherche). Vous pouvez commencer à créer votre type de règle d'alerte ES|QL soit après avoir défini votre requête ES|QL dans la barre de requête, soit avant. L'avantage de le faire après avoir défini la requête est que celle-ci est automatiquement collé dans le panneau contextuel "Create Alert" (Créer une alerte).
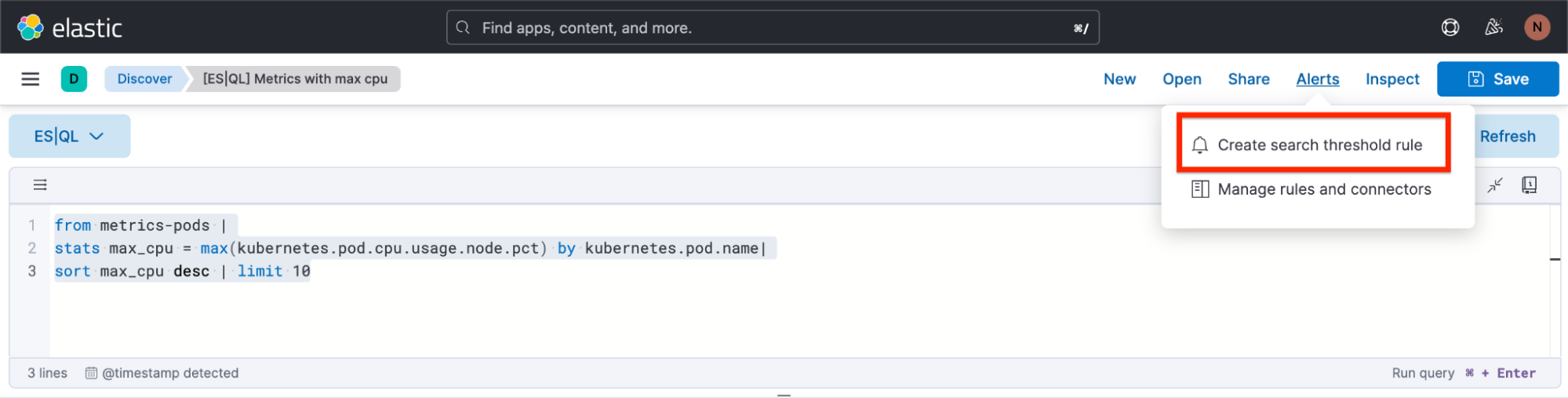
2e étape. Commencez à définir votre type de règle d'alerte ES|QL.
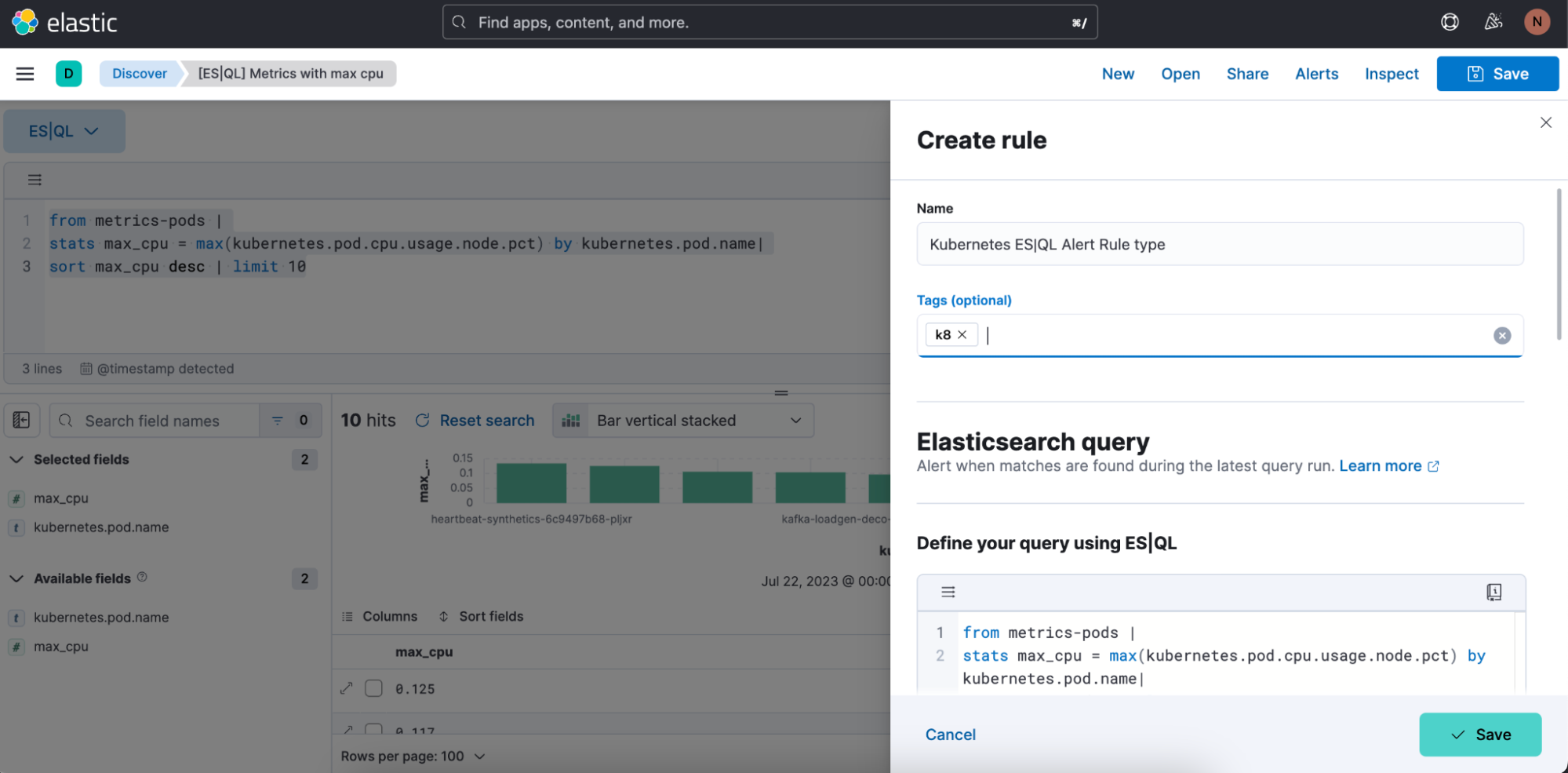
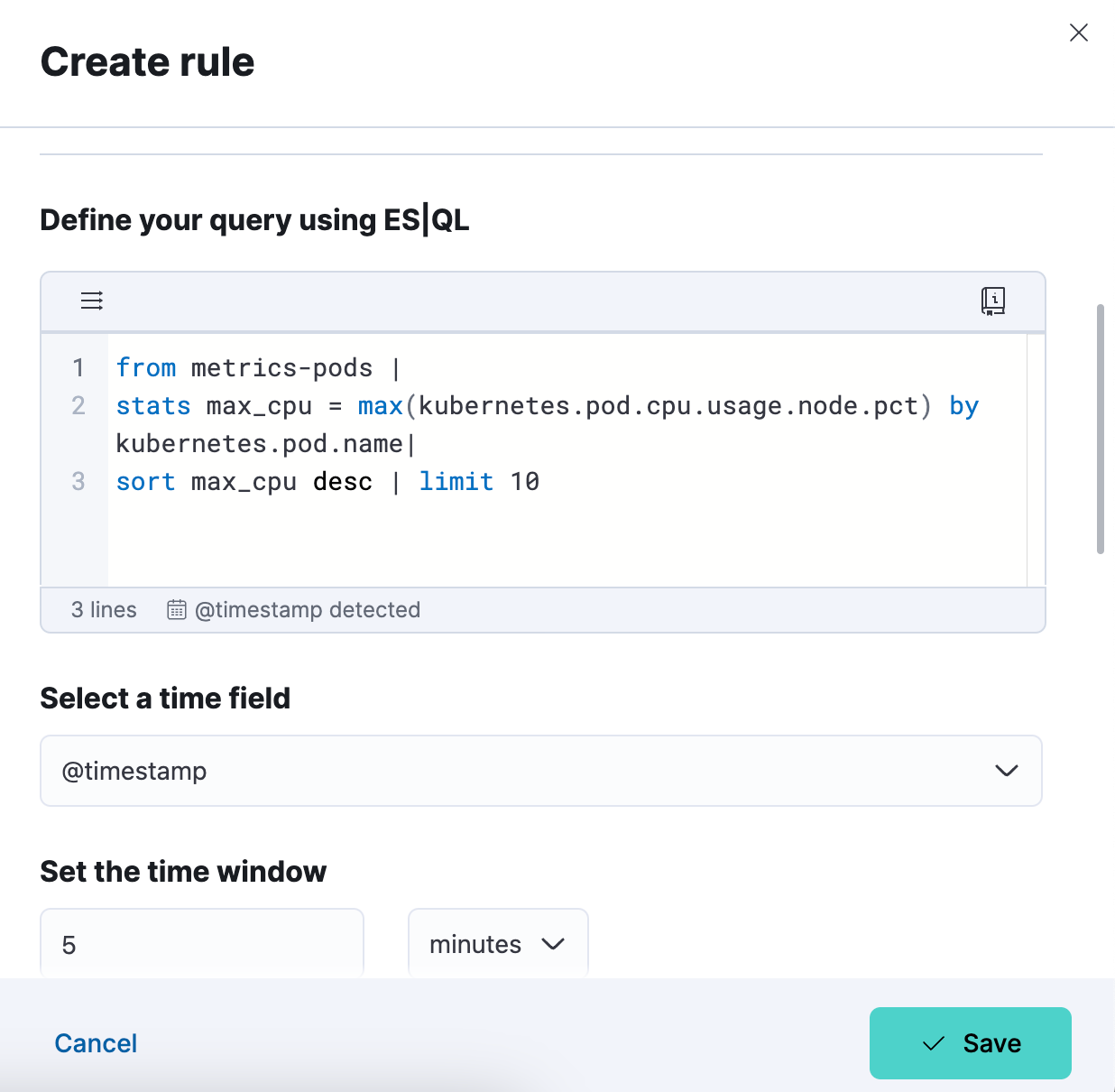
3e étape. Testez une requête pour votre type de règle d'alerte. Vous pouvez itérer avec la requête ES|QL qui y a été collée et lancer le test en cliquant sur "Test query" (Tester la requête). Vous pourrez ainsi prévisualiser les résultats dans un tableau.
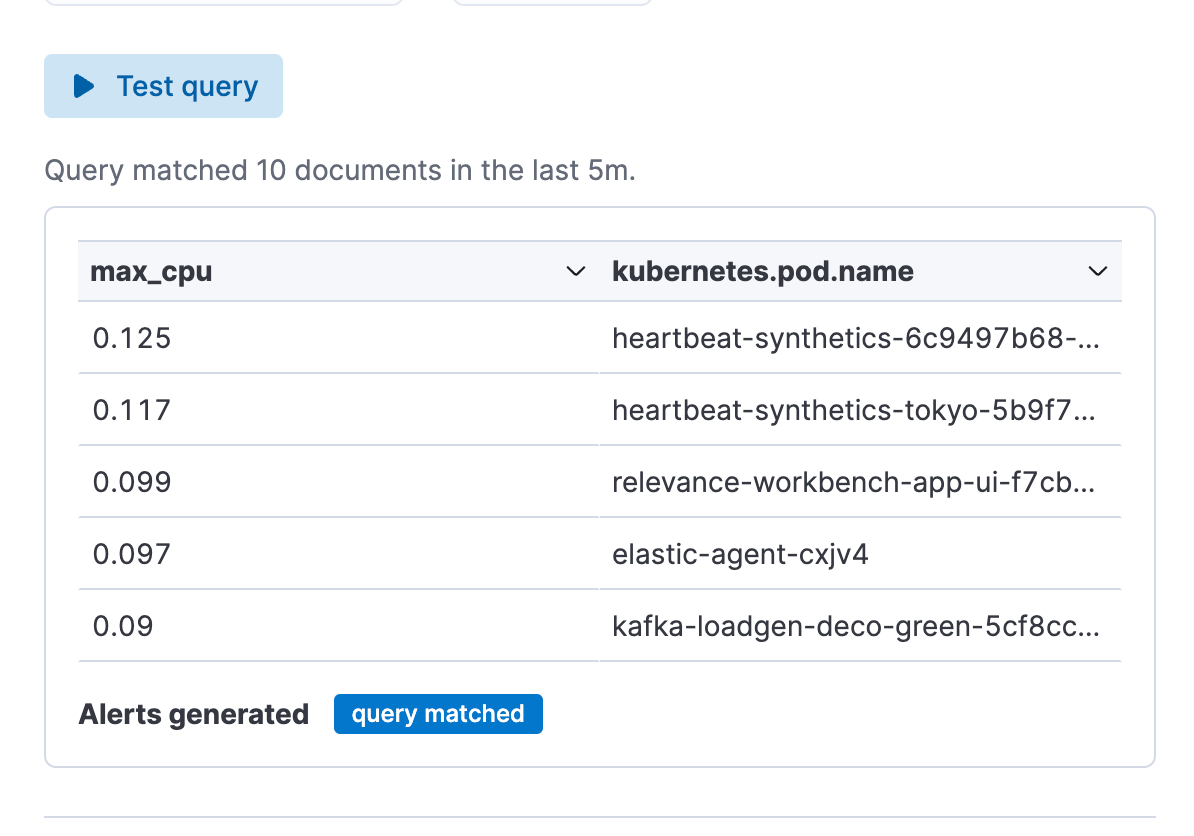
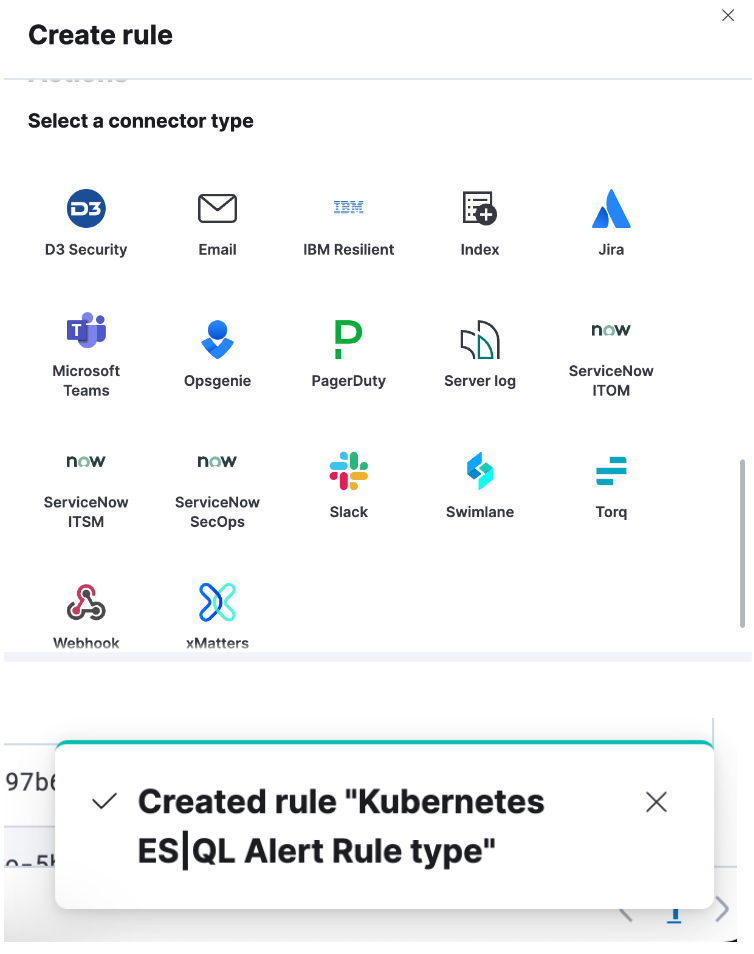
4e étape. Définissez votre connecteur et cliquez sur "Save" (Enregistrer). Vous avez désormais créé un type de règle d'alerte ES|QL !
Comment enrichir votre ensemble de données de requête avec des champs d'un autre ensemble de données
Vous pouvez utiliser la commande ENRICH (cf. documentation) pour améliorer votre ensemble de données en y ajoutant des champs d'un autre ensemble de données et en me complétant avec des suggestions contextuelle pour la politique sélectionnée (c.-à-d., en faisant référence au champ correspondant et aux colonnes enrichies).
Exemple de requête utilisant ENRICH, dans laquelle une politique d'enrichissement "servers-to-project" est utilisée via la requête pour enrichir l'ensemble de données avec "name", "server_hostname" et "cost" :
from projects* | limit 10 |
enrich servers-to-project on project_id with name, server_hostname, cost |
stats num_of_servers = count(server_hostname), total_cost = sum(cost) by project_id |
sort total_cost desc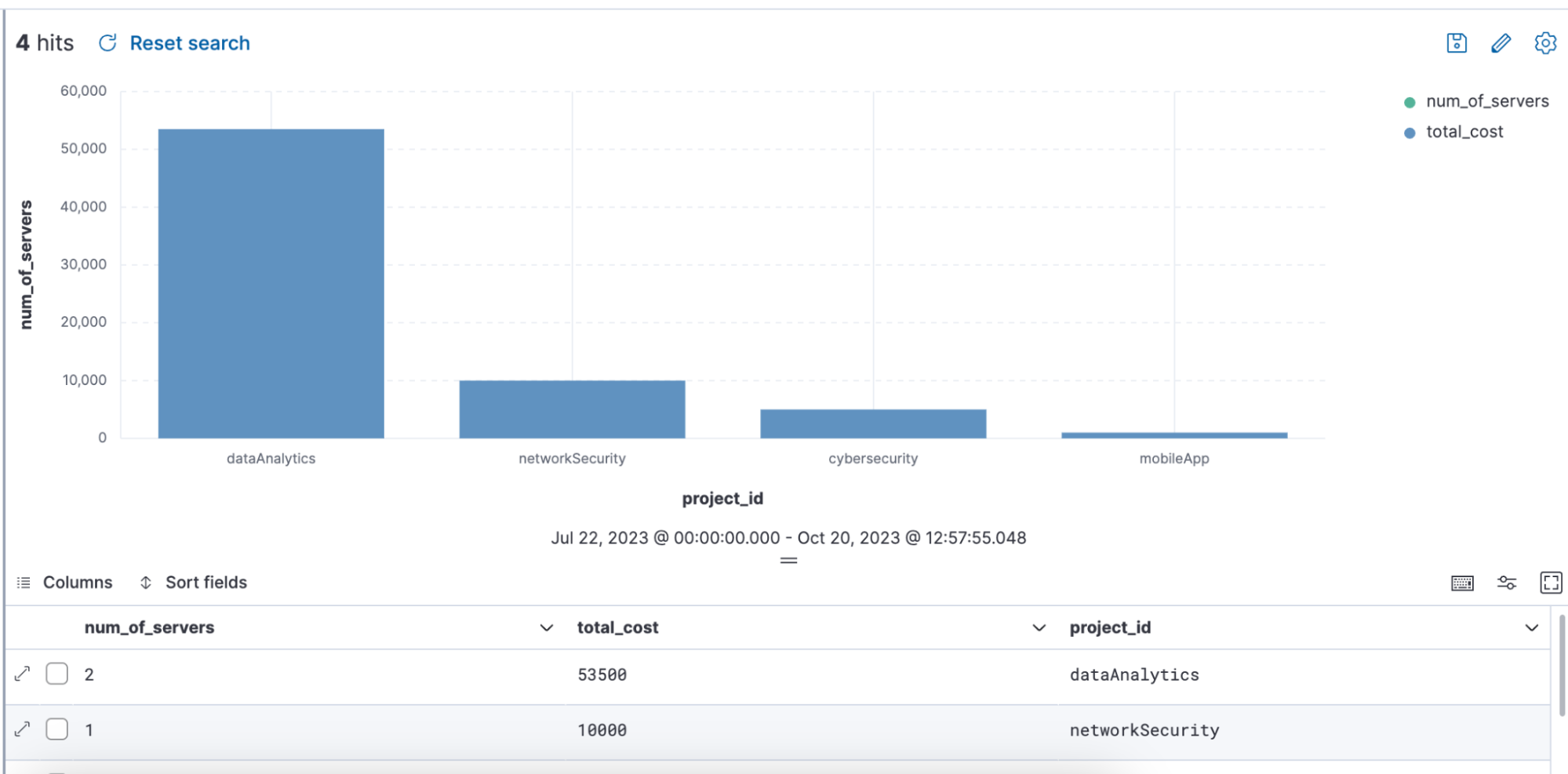
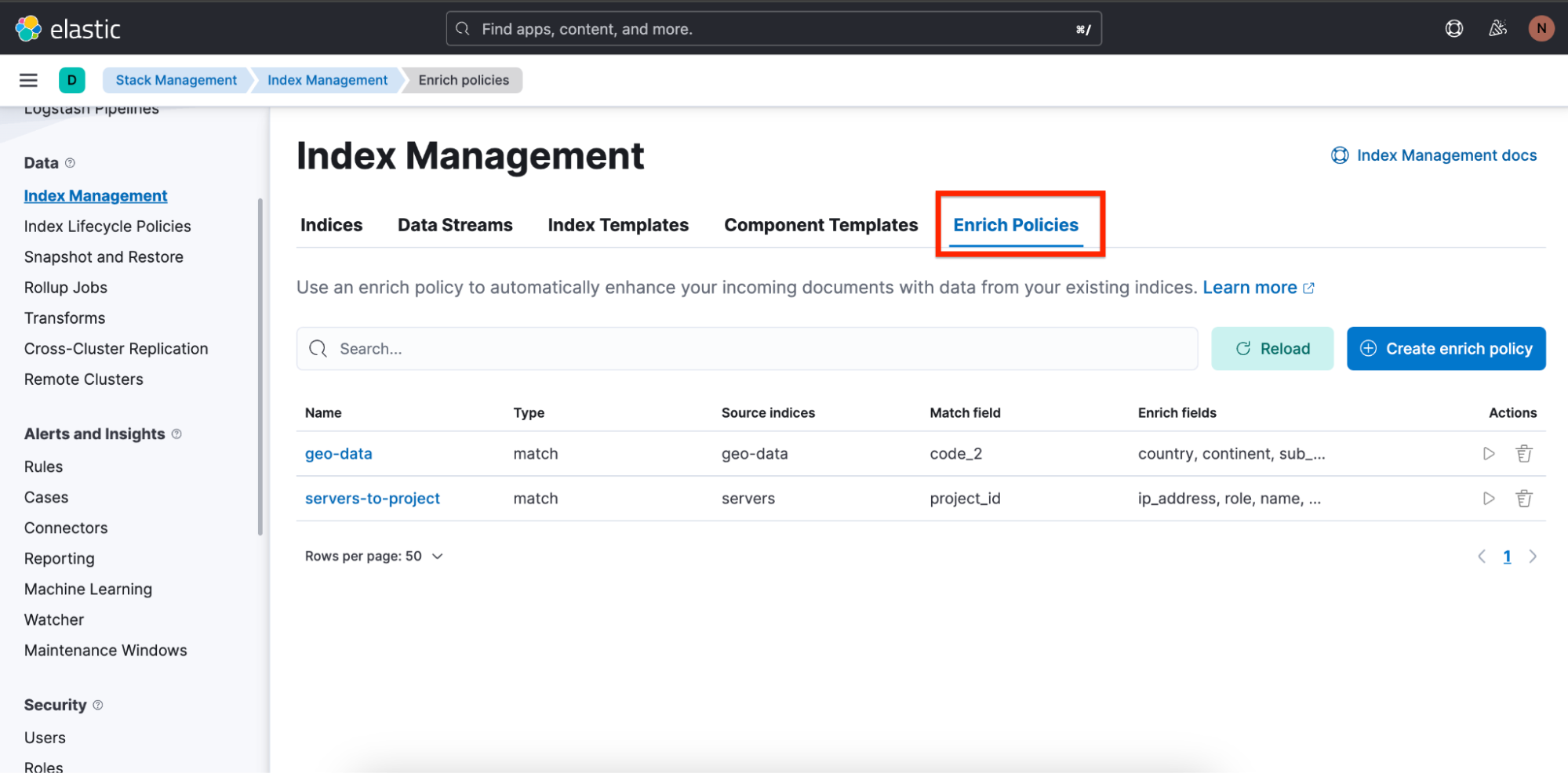
Nous avons aussi facilité la création des politiques d'enrichissement pour les utilisateurs en mettant à leur disposition un aperçu et un assistant pour les aider.
Pour obtenir un aperçu des politiques d'enrichissement, accédez à Stack Management (Gestion de la suite) ⇒ Index Management (Gestion des index). Vous y trouverez un onglet appelé Enrich Policies (Politiques d'enrichissement) :
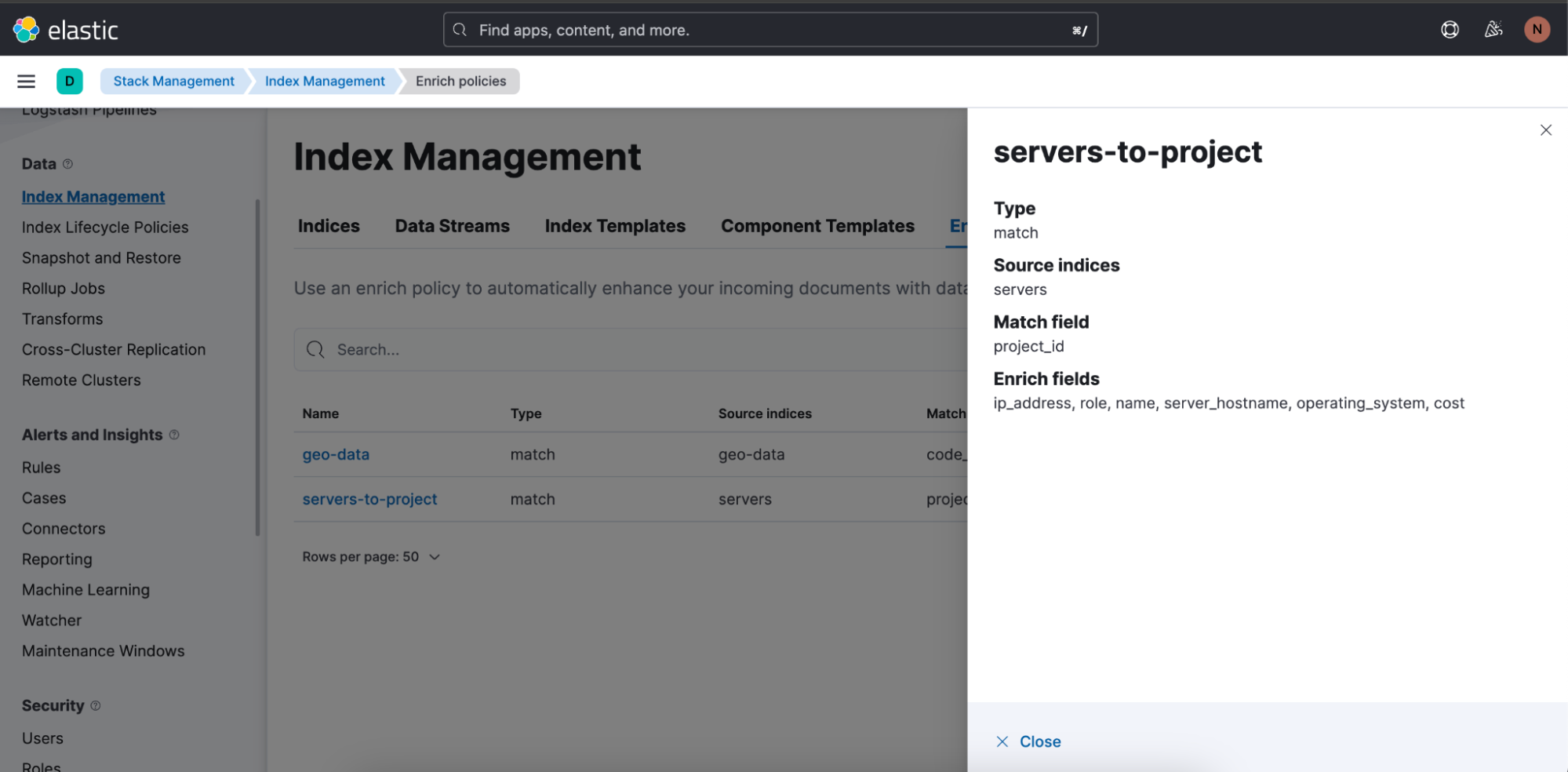
Voici la politique d'enrichissement utilisée dans la requête ci-dessus, "servers-to-project" :
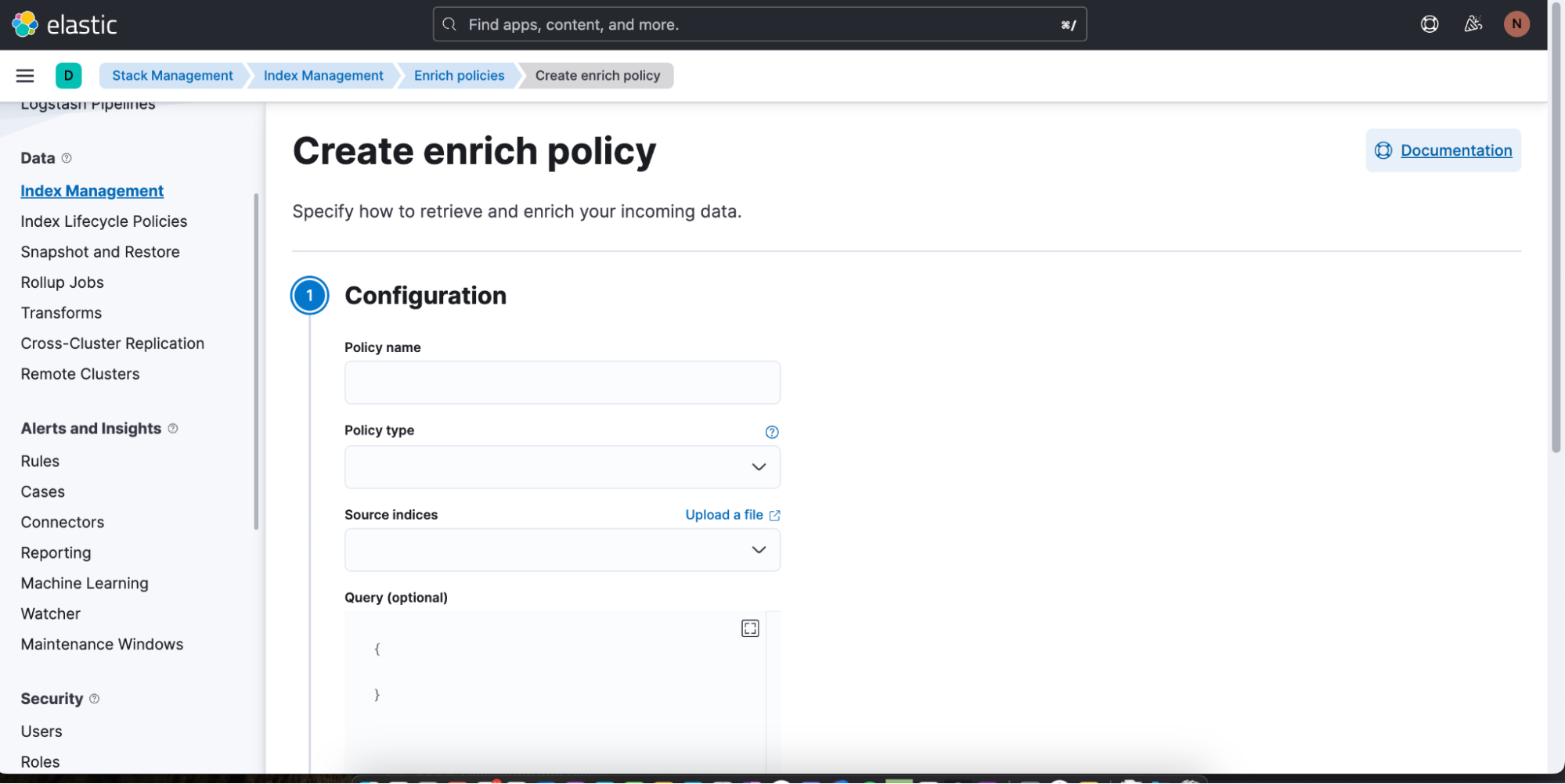
Pour créer une politique d'enrichissement, rien de plus simple : cliquez sur Create enrich policy (Créer une politique d'enrichissement). Dès que vous en avez créé une et que vous l'avez exécutée, vous pouvez alors l'appliquer à une requête ES|QL dans Discover.
Pour en savoir plus sur les politiques d'enrichissement, cliquez ici. Et pour en savoir plus sur la commande ENRICH dans ES|QL, cliquez ici.
Vers une exploration approfondie des données : l'atout ES|QL
ES|QL est la dernière innovation d'Elastic pour aller plus loin dans l'analyse et dans l'exploration des données. Cette innovation ne se contente pas de présenter les données : elle les rend compréhensibles, exploitables et attrayantes sur le plan visuel. Adossé à un moteur de requête rapide, distribué et dédié, ES|QL est conçu comme un nouveau langage canalisé proposant une expérience d'exploration des données unifiée. Il répond aux problématiques des utilisateurs, dont les ingénieurs de fiabilité des sites, les équipes DevOps, les équipes de détection des menaces, et d'autres types d'analystes.
ES|QL donne aux SRE les moyens de pallier les inefficacités des systèmes avec efficacité, aide les équipes DevOps à réaliser des déploiements de qualité et fournit aux équipes de détection des menaces des outils pour repérer rapidement les menaces de sécurité qui se profilent. Et ce n'est pas tout. Ce langage offre de nombreux avantages : une intégration directe à Dashboards, la possibilité de modifier une visualisation ligne par ligne, des fonctionnalités d'alerte ou encore des capacités comme les commandes d'enrichissement. Mis bout à bout, tous ces éléments fournissent un workflow transparent et efficace. L'interface ES|QL allie puissance et convivialité. Les utilisateurs ont la possibilité de plonger dans les détails de leurs données, ce qui rend leurs analyses plus simples et plus pertinentes. Le lancement d'ES|QL s'inscrit dans la lignée des efforts réalisés par Elastic pour améliorer les expériences des utilisateurs en matière d'exploration des données et pour prendre en charge l'évolution de leurs besoins.
ES|QL vous intéresse ? Vous pouvez l'essayer dès aujourd'hui ! Pour cela, inscrivez-vous pour bénéficier d'un essai Elastic ou testez-le directement sur notre environnement de démonstration public.
La publication et la date de publication de toute fonctionnalité ou fonction décrite dans le présent article restent à la seule discrétion d'Elastic. Toute fonctionnalité ou fonction qui n'est actuellement pas disponible peut ne pas être livrée à temps ou ne pas être livrée du tout.
Partager
- Share on Twitter
Partager sur Twitter
- Share on LinkedIn
Partager sur LinkedIn
- Share on Facebook
Partager sur Facebook
- Share by Email
Partage par e-mail
- Print this page
Imprimer