

 Share on Twitter
Share on TwitterPartager sur Twitter

 Share on LinkedIn
Share on LinkedInPartager sur LinkedIn

 Share on Facebook
Share on FacebookPartager sur Facebook

 Share by Email
Share by EmailPartage par e-mail

 Print this page
Print this pageImprimer
Dans le cadre de notre série d'articles sur le traitement du langage naturel (NLP), nous allons nous servir d'un modèle NLP utilisant la reconnaissance d'entités nommées (NER) pour localiser et extraire des catégories prédéfinies d'entités dans des champs de texte non structurés. Pour cela, nous utiliserons un modèle public que nous déploierons dans Elasticsearch. Nous verrons alors comment trouver des entités nommées dans le texte avec la nouvelle API _infer et comment tirer parti du modèle NER dans un pipeline d'ingestion pour extraire des entités au fur et à mesure que des documents sont ingérés dans Elasticsearch.
Pour extraire des entités (personnes, lieux, organisations, etc.) dans des champs full-text à l'aide du langage naturel, l'idéal est d'utiliser un modèle NER.
Dans cet exemple, nous utiliserons des paragraphes du livre Les Misérables auquel nous appliquerons un modèle NER. Ce dernier nous sera utile pour extraire les personnages et les lieux du texte, ainsi que pour visualiser les relations qui existent entre eux.
Déploiement d'un modèle NER dans Elasticsearch
Tout d'abord, nous devons sélectionner un modèle NER capable d'extraire des noms de personnages et de lieux dans des champs de texte. La bonne nouvelle, c'est qu'il y a quelques modèles NER disponibles sur Hugging Face. Après avoir consulté la documentation Elastic, nous constatons qu'il existe un modèle correspondant à ce que nous recherchons : un modèle NER qui ne tient pas compte de la casse fourni par Elastic.
Maintenant que nous avons choisi un modèle, nous pouvons utiliser Eland pour l'installer. Dans cet exemple, nous allons exécuter la commande Eland à l'aide d'une image Docker. Mais auparavant, nous devons construire cette image Docker. Pour cela, nous allons cloner le référentiel GitHub Eland et créer une image Docker d'Eland sur notre système client :
git clone git@github.com:elastic/eland.git
cd eland
docker build -t elastic/eland .
Maintenant que notre client Docker Eland est prêt, nous pouvons installer le modèle NER en exécutant la commande eland_import_hub_model dans la nouvelle image Docker comme suit :
docker run -it --rm elastic/eland \
eland_import_hub_model \
--url $ELASTICSEARCH_URL \
--hub-model-id elastic/distilbert-base-uncased-finetuned-conll03-english \
--task-type ner \
--startVous devrez remplacer ELASTICSEACH_URL par l'URL de votre cluster Elasticsearch. En ce qui concerne l'authentification, vous devrez indiquer dans l'URL un nom d'utilisateur et un mot de passe disposant des droits d'administration, au format : https://nomutilisateur:motdepasse@hôte:port.
Comme nous avons utilisé l'option --start à la fin de la commande d'importation Eland, Elasticsearch déploiera le modèle sur l'ensemble des nœuds de Machine Learning disponibles et le chargera ensuite en mémoire. Dans le cas où nous aurions plusieurs modèles à disposition parmi lesquels choisir, nous pourrions alors utiliser l'interface utilisateur de Kibana, accessible sous Machine Learning > Model Management, pour gérer le démarrage et l'arrêt des modèles.
Test du modèle NER
Pour évaluer les modèles déployés, une nouvelle venue fait son entrée en scène : l'API _infer. Pour l'entrée, nous indiquons la chaîne que nous souhaitons analyser. Dans la requête ci-dessous, text_field est le nom du champ dans lequel le modèle cherchera l'entrée, conformément à ce qui a été défini dans la configuration du modèle. Par défaut, si le modèle a été chargé via Eland, le champ d'entrée est text_field.
Testez cet exemple dans la console d'outils de développement de Kibana :
POST _ml/trained_models/elastic__distilbert-base-uncased-finetuned-conll03-english/deployment/_infer
{
"docs": [
{
"text_field": "Hi my name is Josh and I live in Berlin"
}
]
}
Le modèle trouve deux entités : la personne "Josh" et le lieu "Berlin".
{
"predicted_value" : "Hi my name is [Josh](PER&Josh) and I live in [Berlin](LOC&Berlin)",
"entities" : {
"entity" : "Josh",
"class_name" : "PER",
"class_probability" : 0.9977303419824,
"start_pos" : 14,
"end_pos" : 18
},
{
"entity" : "Berlin",
"class_name" : "LOC",
"class_probability" : 0.9992474323902818,
"start_pos" : 33,
"end_pos" : 39
}
]
}
L'élément predicted_value correspond à la chaîne d'entrée au format Annotation de texte. L'élément class_name est la classe prédite, tandis que l'élément class_probability indique le niveau de fiabilité de la prédiction. Les éléments start_pos et end_pos sont les positions de début et de fin de l'entité trouvée pour le personnage.
Ajout du modèle NER au pipeline d'ingestion d'inférence
Pour commencer de façon conviviale, l'idéal est d'utiliser l'API _infer. Notez toutefois qu'elle n'accepte qu'une seule entrée, et que les entités détectées ne sont pas stockées dans Elasticsearch. Autre méthode : vous pouvez réaliser une inférence en vrac sur les documents au fur et à mesure de leur ingestion par pipeline avec le processeur d'inférence.
Vous pouvez définir un pipeline d'ingestion dans l'interface utilisateur Stack Management ou en configurer un dans la console Kibana. Cette dernière contient de nombreux processeurs d'ingestion :
PUT _ingest/pipeline/ner
{
"description": "NER pipeline",
"processors": [
{
"inference": {
"model_id": "elastic__distilbert-base-uncased-finetuned-conll03-english",
"target_field": "ml.ner",
"field_map": {
"paragraph": "text_field"
}
}
},
{
"script": {
"lang": "painless",
"if": "return ctx['ml']['ner'].containsKey('entities')",
"source": "Map tags = new HashMap(); for (item in ctx['ml']['ner']['entities']) { if (!tags.containsKey(item.class_name)) tags[item.class_name] = new HashSet(); tags[item.class_name].add(item.entity);} ctx['tags'] = tags;"
}
}
],
"on_failure": [
{
"set": {
"description": "Index document to 'failed-<index>'",
"field": "_index",
"value": "failed-{{{ _index }}}"
}
},
{
"set": {
"description": "Set error message",
"field": "ingest.failure",
"value": "{{_ingest.on_failure_message}}"
}
}
]
}
En commençant avec le processeur inference, l'objectif de field_map est de mapper paragraph (champ permettant d'analyser les documents source) à text_field (nom du champ que le modèle est configuré pour utiliser). target_field est le nom du champ dans lequel écrire les résultats de l'inférence.
Le processeur script extrait les entités et les regroupe par type. Le résultat final se présente sous forme de listes de personnes, de lieux et d'organisations, détectés dans le texte de l'entrée. Nous ajoutons ce script painless pour pouvoir élaborer des visualisations à partir des champs créés.
La clause on_failure, quant à elle, est incluse pour repérer les erreurs. Elle définit deux actions. Premièrement, elle définit le champ méta _index sur une nouvelle valeur. C'est là que le document sera désormais stocké. Deuxièmement, le message d'erreur est écrit dans un nouveau champ : ingest.failure. L'inférence peut échouer pour de multiples raisons, qui sont toutes faciles à rectifier. Par exemple, le modèle n'a peut-être pas été déployé, le champ d'entrée est inexistant dans certains documents source, etc. Grâce à la redirection des documents en échec vers un autre index et grâce à la définition du message d'erreur, ces inférences qui n'ont pas abouti ne sont pas pour autant perdues et peuvent être étudiées ultérieurement. Une fois les erreurs rectifiées, il suffit d'effectuer une nouvelle indexation à partir de l'index qui était en échec pour récupérer les requêtes n'ayant rien donné.
Sélection des champs de texte pour l'inférence
La NER peut être appliquée à de nombreux ensembles de données. À titre d'exemple, j'ai choisi le classique de la littérature de Victor Hugo, datant de 1862 : Les Misérables. Pour charger les paragraphes du livre Les Misérables de notre fichier d'exemple json, utilisez la fonctionnalité de chargement de fichiers de Kibana. Le texte est divisé en 14 021 documents JSON, contenant chacun un seul paragraphe. Voici un paragraphe aléatoire :
{
"paragraph": "Father Gillenormand did not do it intentionally, but inattention to proper names was an aristocratic habit of his.",
"line": 12700
}
Une fois le paragraphe ingéré via le pipeline NER, le document qui en découle est stocké dans Elasticsearch et marqué avec une personne identifiée.
{
"paragraph": "Father Gillenormand did not do it intentionally, but inattention to proper names was an aristocratic habit of his.",
"@timestamp": "2020-01-01T17:38:25",
"line": 12700,
"ml": {
"ner": {
"predicted_value": "Father [Gillenormand](PER&Gillenormand) did not do it intentionally, but inattention to proper names was an aristocratic habit of his.",
"entities": [{
"entity": "Gillenormand",
"class_name": "PER",
"class_probability": 0.9806354093873283,
"start_pos": 7,
"end_pos": 19
}],
"model_id": "elastic__distilbert-base-cased-finetuned-conll03-english"
}
},
"tags": {
"PER": [
"Gillenormand"
]
}
}
Un nuage de mots-clés est une visualisation qui scale des mots selon la fréquence à laquelle ils apparaissent. C'est une infographie parfaite pour voir les entités détectées dans Les Misérables. Ouvrez Kibana et créez une nouvelle visualisation basée sur l'agrégation, puis sélectionnez un nuage de mots-clés. Sélectionnez l'index contenant les résultats de la NER et ajoutez une agrégation de termes sur le champ tags.PER.keyword.
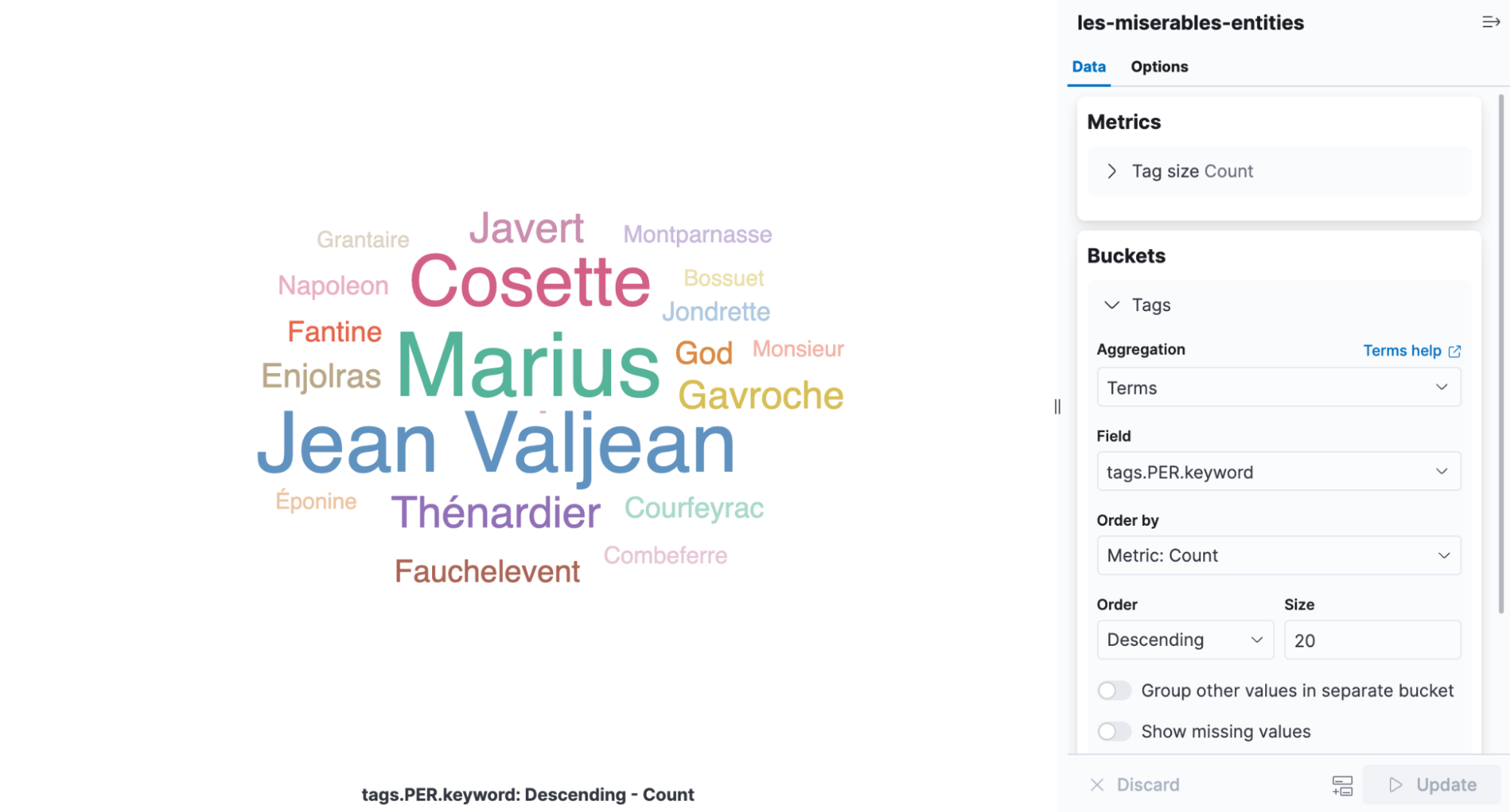
À partir de la visualisation, il est facile de voir que les personnages les plus mentionnés dans le livre sont Cosette, Marius et Jean Valjean.
Ajustement du déploiement
De retour sur l'interface utilisateur Model Management, sous les statistiques du déploiement, vous pourrez consulter la durée d'inférence moyenne. Il s'agit de la durée mesurée par le processus natif pour l'exécution de l'inférence sur une seule requête. Lors du lancement d'un déploiement, deux paramètres contrôlent la façon dont les ressources du processeur sont utilisées : inference_threads et model_threads.
Le paramètre inference_threads correspond au nombre de threads utilisés pour exécuter le modèle par requête. L'augmentation de inference_threads contribue directement à réduire la durée de l'inférence. Le nombre de requêtes évaluées simultanément est contrôlé par le paramètre model_threads. Ce paramètre ne permet pas de réduire la durée de l'inférence, mais à augmenter le débit.
En général, vous pouvez ajuster la latence en augmentant la valeur de inference_threads et accélérer le débit en augmentant la valeur de model_threads. Par défaut, les deux paramètres s'appliquent à un seul thread. Vous pouvez donc bénéficier de gains de performances considérables en les modifiant. C'est ce que nous allons voir à l'aide du modèle NER.
Pour changer l'un des paramètres du thread, le déploiement doit être arrêté, puis redémarré. Le paramètre ?force=true est transmis à l'API d'arrêt, car le déploiement est référencé par un pipeline d'ingestion qui empêcherait tout arrêt en temps normal.
POST _ml/trained_models/elastic__distilbert-base-uncased-finetuned-conll03-english/deployment/_stop?force=true
Redémarrez en utilisant quatre threads d'inférence. La durée d'inférence moyenne est réinitialisée lors du redémarrage du déploiement.
POST _ml/trained_models/elastic__distilbert-base-uncased-finetuned-conll03-english/deployment/_start?inference_threads=4Lors du traitement des paragraphes du livre Les Misérables, la durée d'inférence moyenne chute à 55,84 millisecondes par requête, contre 173,86 millisecondes lorsqu'un seul thread était utilisé.
Envie d'en savoir plus et de juger par vous-même ?
La NER est une tâche parmi d'autres que vous pouvez utiliser actuellement dans le cadre du NLP. La classification de texte, la classification zero-shot et les plongements textuels sont également disponibles. Pour consulter d'autres exemples, ainsi qu'une liste non exhaustive de modèles déployables dans la Suite Elastic, consultez la documentation sur le NLP.
Le NLP est une nouvelle fonctionnalité clé de la Suite Elastic 8.0 avec une roadmap particulièrement intéressante. Découvrez de nouvelles fonctionnalités et tenez-vous au courant des derniers développements en déployant votre cluster dans Elastic Cloud. Inscrivez-vous pour un essai gratuit de 14 jours dès aujourd'hui et testez les exemples indiqués dans cet article.
Envie d'en savoir plus sur le traitement du langage naturel ? Ces ressources peuvent vous intéresser :
Partager
- Share on Twitter
Partager sur Twitter
- Share on LinkedIn
Partager sur LinkedIn
- Share on Facebook
Partager sur Facebook
- Share by Email
Partage par e-mail
- Print this page
Imprimer
Comment déployer le traitement du langage naturel : la reconnaissance d'entités nommées (NER)