

 Share on Twitter
Share on TwitterPartager sur Twitter

 Share on LinkedIn
Share on LinkedInPartager sur LinkedIn

 Share on Facebook
Share on FacebookPartager sur Facebook

 Share by Email
Share by EmailPartage par e-mail

 Print this page
Print this pageImprimer
Dans le cadre de notre série d'articles sur le traitement du langage naturel (NLP), nous allons nous servir d'un exemple utilisant un modèle NLP d'analyse des sentiments pour déterminer si les champs (textes) de commentaires expriment des sentiments positifs ou négatifs. Pour cela, nous nous fonderons sur un modèle public que nous déploierons dans Elasticsearch. Nous verrons alors comment en tirer parti dans un pipeline d'ingestion pour classer les avis de la clientèle comme positifs ou négatifs.
L'analyse des sentiments est un type de classification binaire selon laquelle des prévisions déterminent que les champs appartiennent à l'une ou à l'autre valeur. En règle générale, les prévisions sont accompagnées d'un score de probabilité situé entre 0 et 1. Les scores plus proches de 1 indiquent des prévisions plus sûres. Ce type d'analyse NLP peut être appliquée de manière pratique à de nombreux ensembles de données, comme les avis sur les produits ou les commentaires de la clientèle.
Les avis de la clientèle que nous souhaitons classer appartiennent à un ensemble de données publiques provenant du défi Yelp Dataset 2015. Ces informations, compilées depuis le site web Yelp Review, est la ressource idéale pour tester l'analyse des sentiments. Dans cet exemple, nous évaluerons un échantillon de l'ensemble de données Yelp Review à l'aide d'un modèle NLP courant d'analyse des sentiments et nous utiliserons ce dernier pour étiqueter les commentaires comme positifs ou négatifs. Nous espérons découvrir ainsi le pourcentage des avis positifs et négatifs.
Déploiement du modèle d'analyse des sentiments dans Elasticsearch
docker run -it --rm elastic/eland \
eland_import_hub_model \
--url $ELASTICSEARCH_URL \
--hub-model-id distilbert-base-uncased-finetuned-sst-2-english \
--task-type text_classification \
--start
Cette fois-ci, --task-type est défini sur text_classification et l'option --start est transférée au script Eland, pour que le modèle soit déployé automatiquement sans avoir à être démarré dans l'interface utilisateur Model Management.
Une fois déployé, essayez les exemples ci-dessous dans la console Kibana.
POST _ml/trained_models/distilbert-base-uncased-finetuned-sst-2-english/deployment/_infer
{
"docs": [
{
"text_field": "The movie was awesome!"
}
]
}
Vous devriez obtenir le résultat suivant.
{
"predicted_value" : "POSITIVE",
"prediction_probability" : 0.9998643924765398
}
Vous pouvez également essayer l'exemple ci-dessous.
POST _ml/trained_models/distilbert-base-uncased-finetuned-sst-2-english/deployment/_infer
{
"docs": [
{
"text_field": "The cat was sick on the bed"
}
]
}
Il génère une réponse fortement négative pour le chat et la personne qui nettoie les draps.
{
"predicted_value" : "NEGATIVE",
"prediction_probability" : 0.9992468477843378
}
Analyse des avis Yelp
Comme nous l'avons expliqué en introduction, nous utiliserons un sous-ensemble d'avis Yelp qui sont disponibles sur Hugging Face et qui ont été associés manuellement à un sentiment. Ainsi, nous pourrons comparer les résultats à l'index marqué. Nous utiliserons la fonctionnalité de chargement de fichiers de Kibana pour charger un échantillon de cet ensemble de données à des fins de traitement avec le processeur d'inférence.
Dans la console Kibana, nous pouvons créer un pipeline d'ingestion (comme nous l'avons fait dans un précédent article), cette fois pour l'analyse des sentiments, et nous l'appelons sentiment. Les avis se trouvent dans un champ intitulé review. Comme nous l'avons fait auparavant, nous définissons field_map pour mapper review au champ que le modèle attend. Le même gestionnaire intitulé on_failure provenant du pipeline NER est configuré.
PUT _ingest/pipeline/sentiment
{
"processors": [
{
"inference": {
"model_id": "distilbert-base-uncased-finetuned-sst-2-english",
"field_map": {
"review": "text_field"
}
}
}
],
"on_failure": [
{
"set": {
"description": "Index document to 'failed-<index>'",
"field": "_index",
"value": "failed-{{{_index}}}"
}
},
{
"set": {
"description": "Set error message",
"field": "ingest.failure",
"value": "{{_ingest.on_failure_message}}"
}
}
]
}
Les documents contenant les avis sont stockés dans l'index d'Elasticsearch intitulé yelp-reviews. Utilisez l'API de réindexation pour faire progresser les données sur les avis dans le pipeline d'analyse des sentiments. Étant donné que cette opération prendra un peu de temps pour traiter tous les documents et en faire ressortir des inférences, procédez à la réindexation en arrière-plan en appelant l'API portant l'indicateur wait_for_completion=false. Vérifiez les avancées réalisées à l'aide de l'API de gestion des tâches.
POST _reindex?wait_for_completion=false
{
"source": {
"index": "yelp-reviews"
},
"dest": {
"index": "yelp-reviews-with-sentiment",
"pipeline": "sentiment"
}
}
Cette procédure renvoie un identifiant de tâche. Nous pouvons monitorer l'avancement de la tâche avec :
The above returns a task id. We can monitor progress of the task with:
Nous pouvons aussi vérifier la progression en consultant l'augmentation dans Inference count (Décompte d'inférences) dans l'interface utilisateur des statistiques du modèle.

Les documents réindexés contiennent désormais les résultats des inférences. Voici un exemple de ce à quoi ressemble l'un des documents analysés :
{
"review": "The food is good. Unfortunately the service is very hit or miss. The main issue seems to be with the kitchen, the waiters and waitresses are often very apologetic for the long waits and it's pretty obvious that some of them avoid the tables after taking the initial order to avoid hearing complaints.",
"ml": {
"inference": {
"predicted_value": "NEGATIVE",
"prediction_probability": 0.9985209630712552,
"model_id": "distilbert-base-uncased-finetuned-sst-2-english"
}
},
"timestamp": "2022-02-02T15:10:38.195345345Z"
}
La valeur prédite est NEGATIVE, un résultat raisonnable étant donné la mauvaise qualité du service.
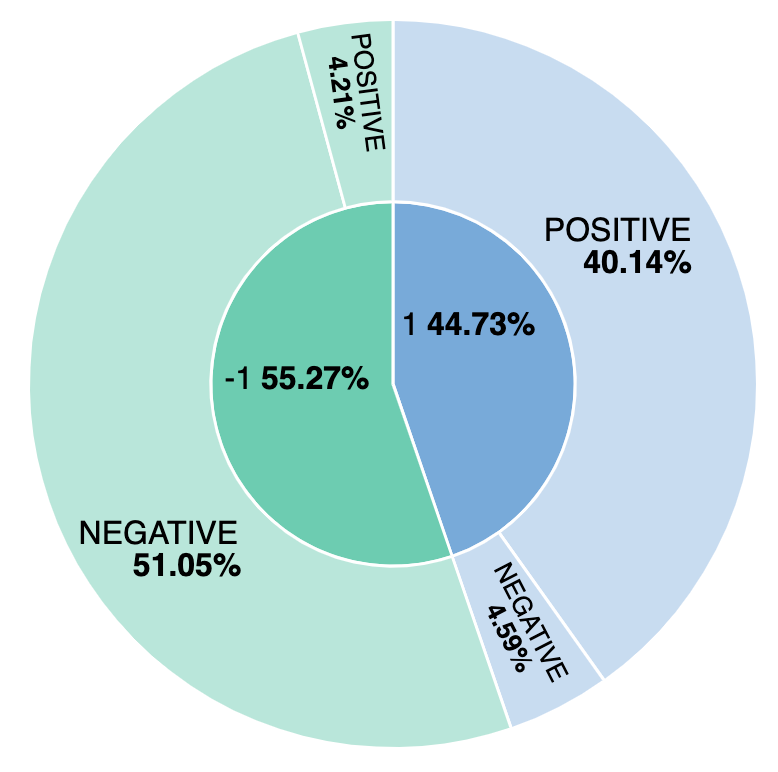
Visualisation du nombre d'avis négatifs
Quel pourcentage d'avis est négatif ? Et quelles sont les différences entre notre modèle et les sentiments étiquetés manuellement ? Découvrons comment concevoir une visualisation simple pour suivre les avis positifs et négatifs à l'aide du modèle et manuellement. En créant une visualisation fondée sur le champ ml.inference.predicted_value field, nous pouvons établir une comparaison, puis constater qu'environ 44 % des avis sont considérés comme positifs et que 4,59 % d'entre eux sont mal étiquetés par le modèle d'analyse des sentiments.
À vous de jouer
Envie d'en savoir plus sur le traitement du langage naturel ? Ces ressources peuvent vous intéresser :
Partager
- Share on Twitter
Partager sur Twitter
- Share on LinkedIn
Partager sur LinkedIn
- Share on Facebook
Partager sur Facebook
- Share by Email
Partage par e-mail
- Print this page
Imprimer


Comment déployer le traitement du langage naturel : exemple de l'analyse des sentiments