En avant pour le monitoring des indicateurs de GPU NVIDIA avec Elastic Observability
Les processeurs graphiques, ou GPU, ne sont pas réservés au jeu sur PC ! Aujourd'hui, ils servent à entraîner des réseaux de neurones artificiels, simuler la mécanique des fluides numérique, miner des Bitcoins et traiter des charges de travail dans des data centers. Et comme ils se trouvent au cœur de la plupart des systèmes informatiques hautes performances, il est crucial de monitorer leurs performances dans les data centers, en plus de celles des CPU.
En gardant ces éléments en tête, voyons comment utiliser Elastic Observability avec les outils de monitoring de GPU NVIDIA pour observer et optimiser les performances des GPU.
Dépendances
Pour avoir des indicateurs de GPU NVIDIA fonctionnels, nous devons créer des outils de monitoring de GPU NVIDIA à l'aide d'un code source (Go). Et nous aurons aussi besoin d'un GPU NVIDIA, comme vous l'aurez sans doute deviné. Les GPU de type AMD et autres utilisent des pilotes Linux et des outils de monitoring différents. Nous en parlerons donc dans un autre article.
Les GPU NVIDIA sont disponibles auprès de nombreux fournisseurs cloud, tels que Google Cloud et Amazon Web Services (AWS). Dans le cadre de cet article, nous nous servirons d'une instance fonctionnant sur Genesis Cloud.
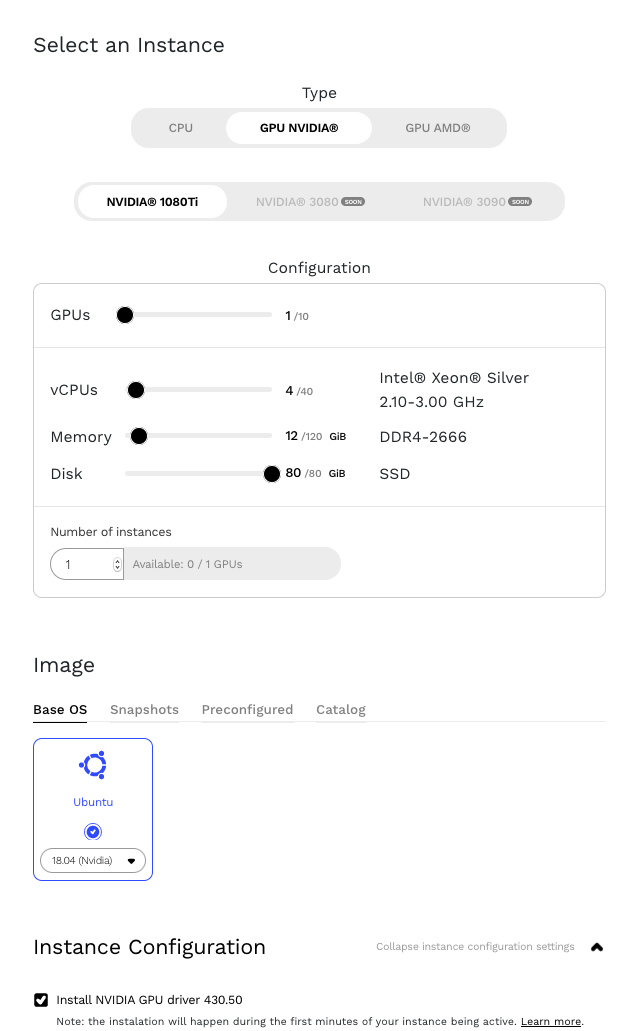
Commençons par installer NVIDIA Data Center Manager en suivant les instructions fournies dans le guide de démarrage NVIDIA’s DCGM Getting Started Guide pour Ubuntu 18.04. Remarque : tout au long de la procédure, faites attention à remplacer le paramètre <architecture> par celui qui correspond à l'architecture que nous utilisons. Vous pouvez le déterminer à l'aide de la commande uname.
uname -a
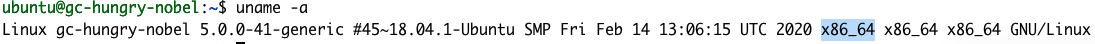
D'après la commande, notre architecture est la X86_64. Aussi, voici à quoi ressemblerait l'étape 1 du guide de démarrage :
echo "deb http://developer.download.nvidia.com/compute/cuda/repos/$distribution/x86_64 /" | sudo tee /etc/apt/sources.list.d/cuda.list
À l'étape 2, il y a une erreur. Supprimez le > de $distribution.
sudo apt-key adv --fetch-keys https://developer.download.nvidia.com/compute/cuda/repos/$distribution/x86_64/7fa2af80.pub
Une fois l'installation terminée, nous devrions être en mesure de voir les détails de notre GPU à l'aide de la commande nvidia-smi.
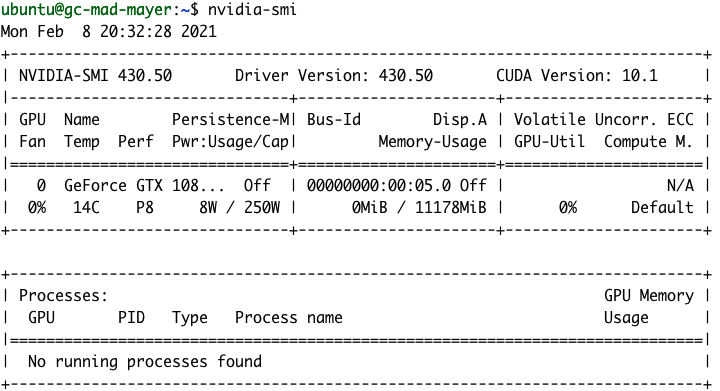
Programme gpu-monitoring-tools de NVIDIA
Pour créer le programme gpu-monitoring-tools de NVIDIA, nous devons installer Golang. C'est parti !
cd /tmp wget https://golang.org/dl/go1.15.7.linux-amd64.tar.gz sudo mv go1.15.7.linux-amd64.tar.gz /usr/local/ cd /usr/local/ sudo tar -zxf go1.15.7.linux-amd64.tar.gz sudo rm go1.15.7.linux-amd64.tar.gz
À présent, l'heure est venue de finaliser la configuration de NVIDIA avec l'installation du programme gpu-monitoring-tools à partir de GitHub.
cd /tmp git clone https://github.com/NVIDIA/gpu-monitoring-tools.git cd gpu-monitoring-tools/ sudo env "PATH=$PATH:/usr/local/go/bin" make install
Metricbeat
Nous sommes maintenant prêts à installer Metricbeat. Jetez un œil à la page elastic.co pour connaître la dernière version de Metricbeat et ajustez le numéro de version dans les commandes ci-dessous.
cd /tmp wget https://artifacts.elastic.co/downloads/beats/metricbeat/metricbeat-7.10.2-amd64.deb sudo dpkg -i metricbeat-7.10.2-amd64.deb # 7.10.2 correspond au numéro de version
Elastic Cloud
Maintenant, au tour de la Suite Elastic ! Nous devons définir un emplacement pour les données de monitoring de notre nouveau GPU. Pour cela, nous allons créer un nouveau déploiement sur Elastic Cloud. Si vous n'avez pas encore de compte Elastic Cloud, vous pouvez vous inscrire pour bénéficier d'un essai gratuit de 14 jours. Si vous préférez, vous pouvez configurer votre propre déploiement en local.
Ensuite, créez un déploiement Elastic Observability sur Elastic Cloud.
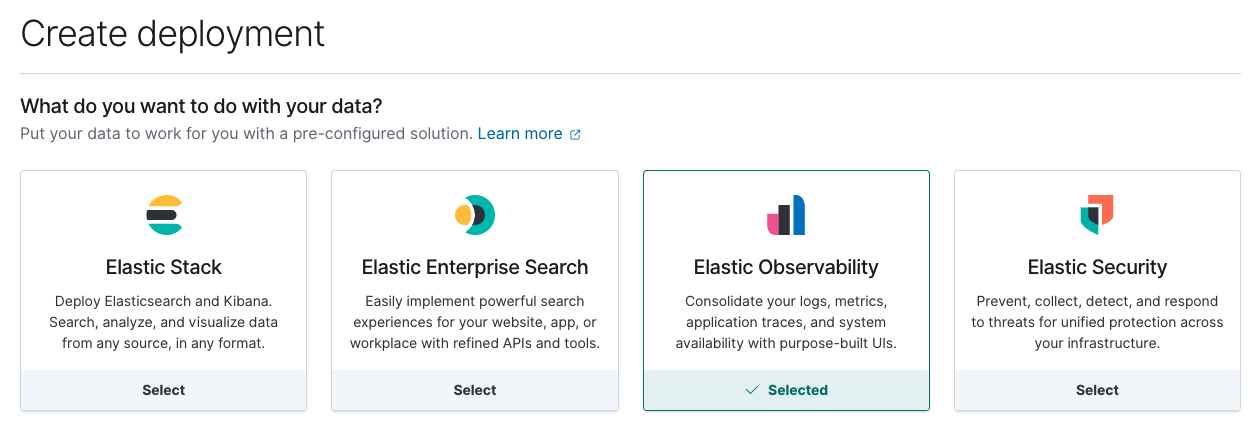
Une fois que votre déploiement est fonctionnel, notez l'ID cloud et les informations d'authentification correspondantes. Nous en aurons besoin pour notre configuration Metricbeat à venir.
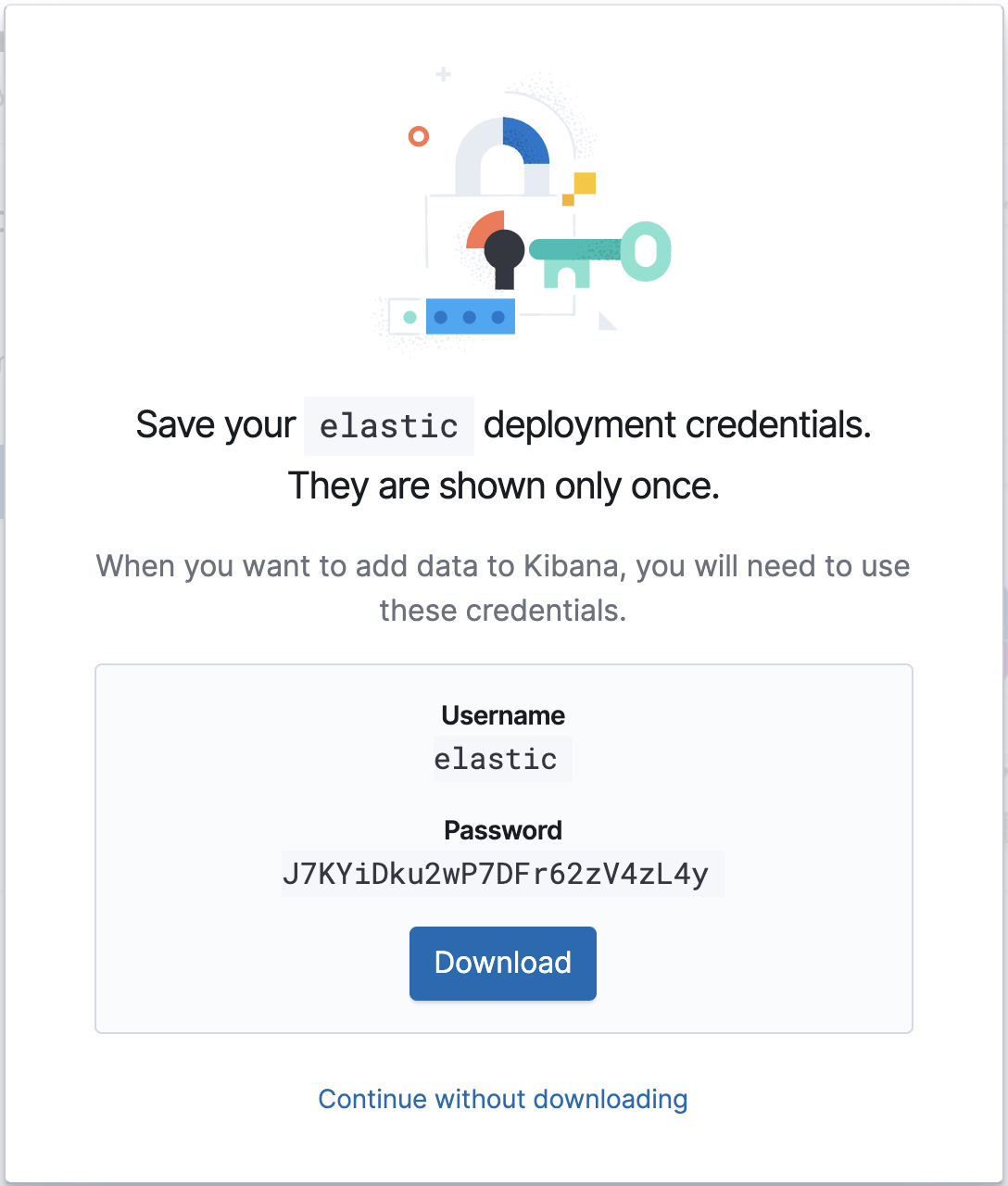
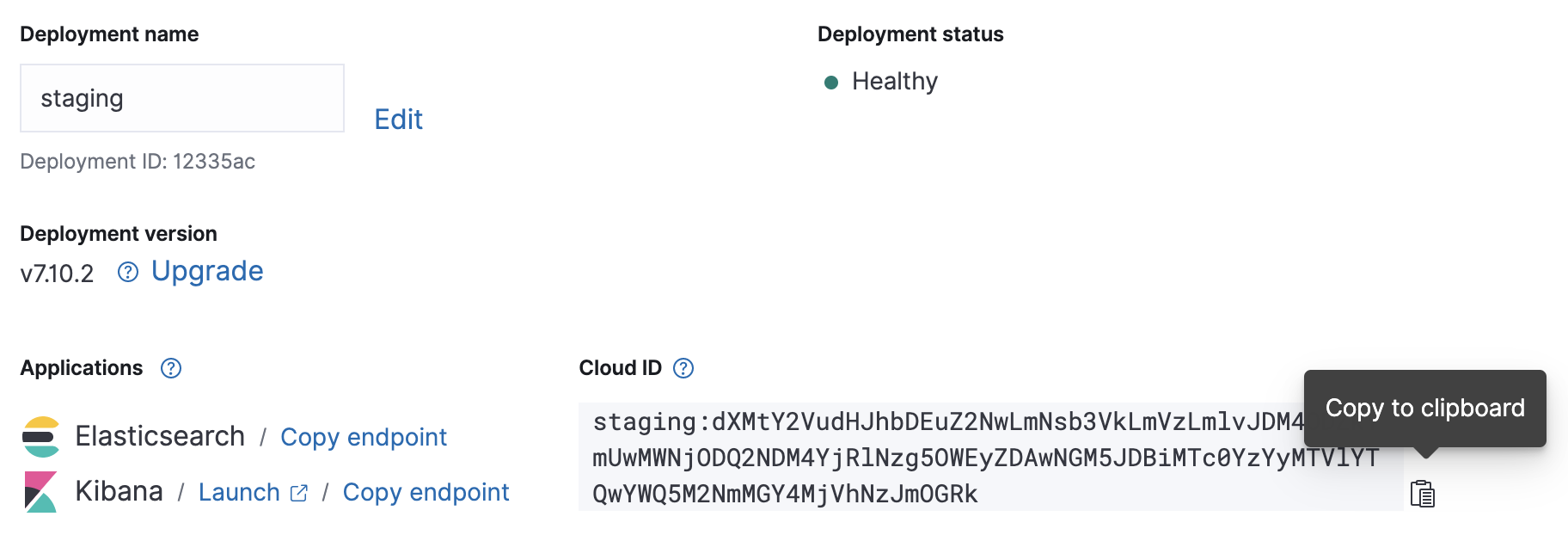
Configuration
Le fichier de configuration de Metricbeat se trouve dans /etc/metricbeat/metricbeat.yml. Ouvrez-le dans l'éditeur de votre choix et modifiez les paramètres cloud.id et cloud.auth afin qu'ils correspondent à votre déploiement.
Exemple de changements de configuration de Metricbeat avec les captures ci-dessus :
cloud.id: "staging:dXMtY2VudHJhbDEuZ2NwLmNsb3VkLmVzLmlvJDM4ODZkYmUwMWNjODQ2NDM4YjRlNzg5OWEyZDAwNGM5JDBiMTc0YzYyMTVlYTQwYWQ5M2NmMGY4MjVhNzJmOGRk" cloud.auth: "elastic:J7KYiDku2wP7DFr62zV4zL4y"
La configuration d'entrée de Metricbeat est modulaire. Le programme gpu-monitoring-tools de NVIDIA publie les indicateurs du GPU via Prometheus. Nous allons donc maintenant activer le module Metricbeat de Prometheus.
sudo metricbeat modules enable prometheus
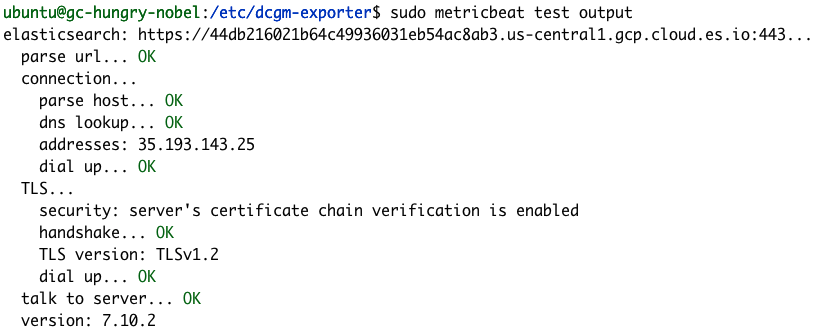
Pour vérifier que la configuration de Metricbeat fonctionne bien, exécutons les commandes "test" et "modules".
sudo metricbeat test config

sudo metricbeat test output
sudo metricbeat modules list
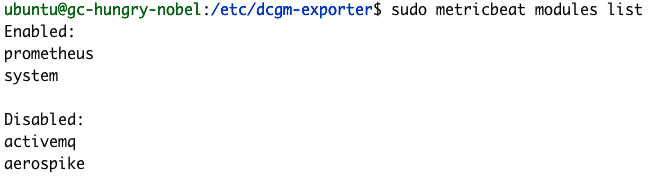
Si vos tests de configuration échouent, comme dans les exemples ci-dessus, consultez notre guide sur la résolution des problèmes de Metricbeat.
Pour terminer la configuration de Metricbeat, utilisez la commande "setup". Celle-ci chargera des tableaux de bord par défaut et définira des mappings d'index. En général, il faut quelques minutes pour que la commande "setup" s'exécute.
sudo metricbeat setup

Exportation d'indicateurs
Les indicateurs n'attendent que vous ! L'heure est venue de les exporter. Commençons avec la commande "dcgm-exporter" de NVIDIA.
dcgm-exporter --address localhost:9090 # Sortie INFO[0000] Starting dcgm-exporter INFO[0000] DCGM successfully initialized! INFO[0000] Not collecting DCP metrics: Error getting supported metrics: This request is serviced by a module of DCGM that is not currently loaded INFO[0000] Pipeline starting INFO[0000] Starting webserver
Remarque : vous pouvez ignorer l'avertissement de DCP.
La configuration des indicateurs dcgm-exporter est définie dans le fichier /etc/dcgm-exporter/default-counters.csv, dans lequel 38 indicateurs sont définis par défaut. Pour accéder à la liste complète des valeurs possibles, consultez le guide DCGM Library API Reference Guide.
Dans une autre console, lancez Metricbeat.
sudo metricbeat -e
Maintenant, vous pouvez vous rendre dans l'instance Kibana et actualiser le modèle d'indexation "metricbeat-*". Pour cela, accédez à Stack Management > Kibana> Index Patterns (Gestion de la suite > Kibana > Modèles d'indexation) et sélectionnez le modèle d'indexation metricbeat-* dans la liste. Cliquez ensuite sur Refresh field list (Actualiser la liste de champs).
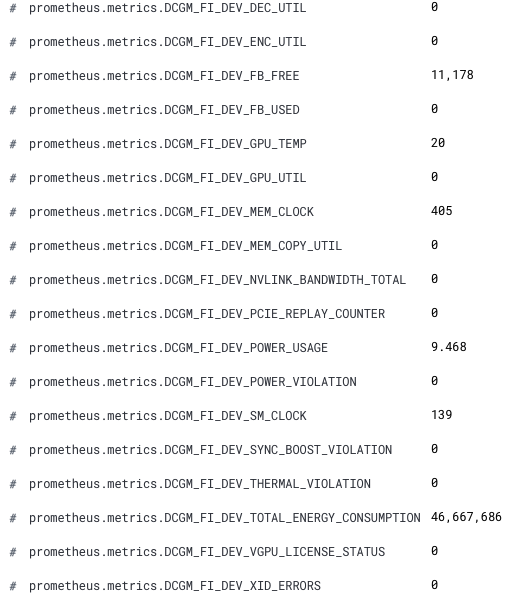
À présent, les indicateurs de notre GPU sont disponibles dans Kibana. Les nouveaux champs ont un nom qui commence par le préfixe prometheus.metrics.DCGM_. Voici un extrait présentant les nouveaux champs à partir de Discover.
Félicitations ! Nous sommes désormais prêts à analyser les indicateurs de votre GPU dans Elastic Observability.
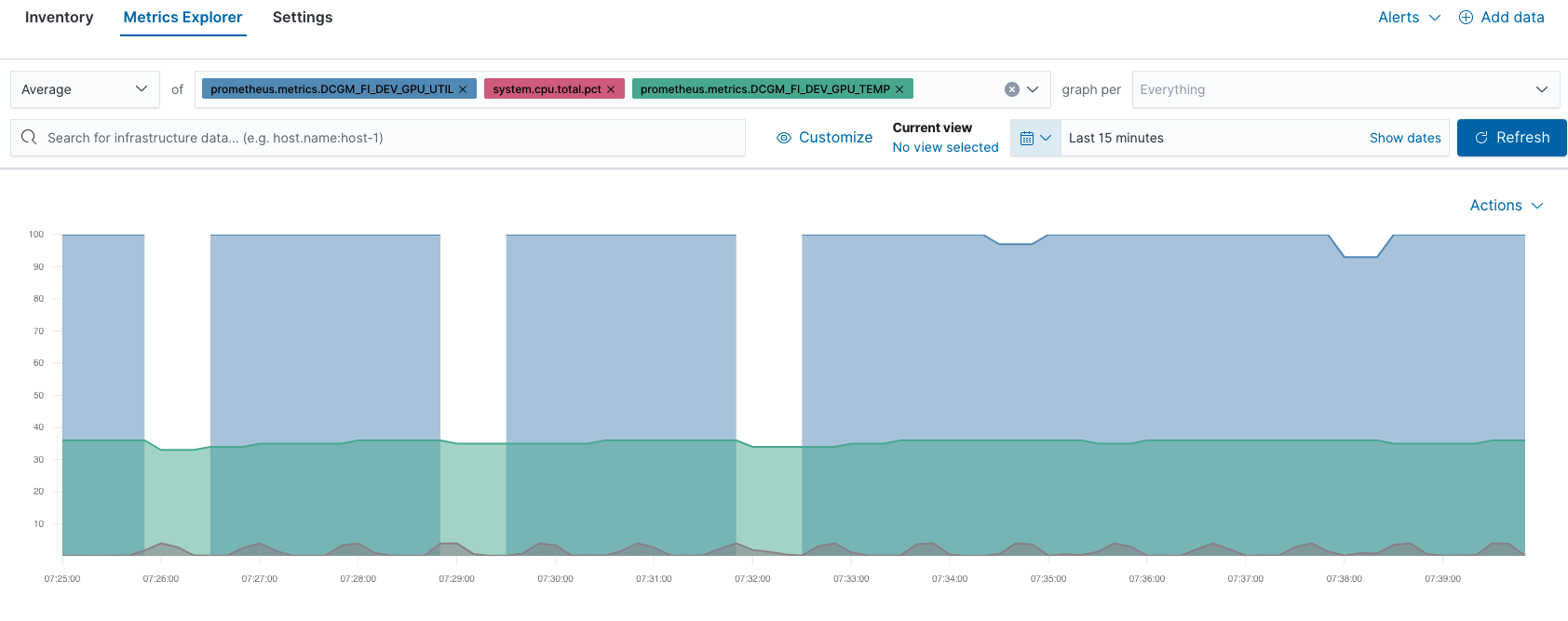
Par exemple, vous pouvez comparer les performances des GPU et des CPU dans Metrics Explorer :
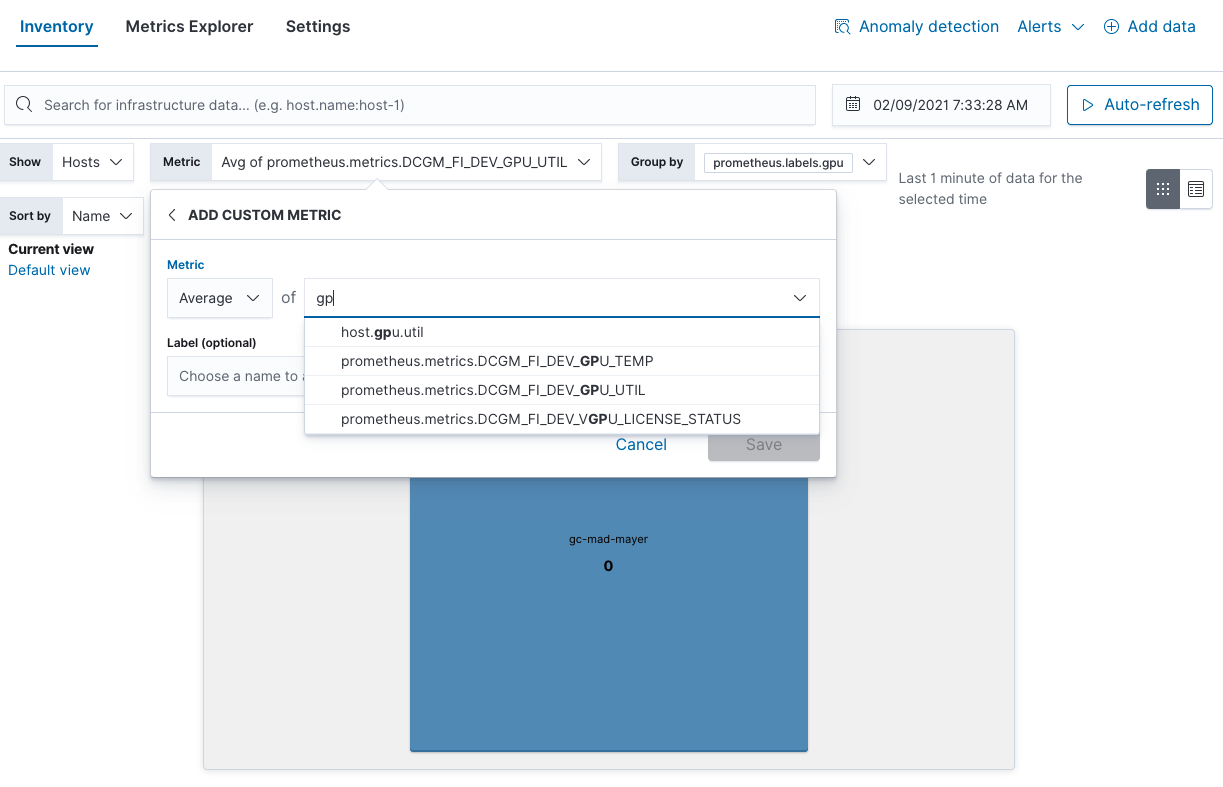
Vous pouvez également déterminer les points d'utilisation du GPU dans la vue Inventory (Inventaire) :
Considérations relatives au monitoring des GPU
Nous espérons que vous avez trouvé cet article utile. Ce sont là quelques exemples de monitoring parmi d'autres. Avec Elastic Observability, relevez tous les défis qui s'offrent à vous ! Voici d'autres aspects relatifs aux GPU que vous pouvez monitorer avec NVIDIA :
- Température du GPU : vérifiez les zones sensibles.
- Consommation de puissance du GPU : si la consommation est plus élevée que prévue, il y a probablement un souci au niveau matériel.
- Fréquence d'horloge réelle : si elle est plus faible que prévue, il peut y avoir un blocage au niveau de la puissance ou un souci matériel.
Et si vous avez besoin de simuler la charge d'un GPU, vous pouvez utiliser la commande dcgmproftester10.
dcgmproftester10 --no-dcgm-validation -t 1004 -d 30
Envie de passer au niveau supérieur ? Utilisez l'alerting Elastic pour automatiser les recommandations de NVIDIA dans le cadre du monitoring. Et pour aller encore plus loin, détectez les anomalies dans l'infrastructure de votre GPU grâce au Machine Learning. Si vous n'avez pas encore de compte Elastic Cloud et que vous souhaitez reproduire la procédure présentée dans cet article, vous pouvez vous inscrire pour bénéficier d'un essai gratuit de 14 jours.