Gestion de la mémoire Elasticsearch et résolution des problèmes
Bonne nouvelle ! Avec l'expansion de notre offre Elasticsearch Service Cloud et le renforcement de l'intégration automatisée, nous mettons aujourd'hui la Suite Elastic aux mains d'un plus large éventail d'utilisateurs : équipes opérationnelles, ingénieurs de données, équipes de sécurité, consultants, pour ne citer qu'eux ! En tant qu'ingénieur de support technique Elastic, j'ai été ravi de pouvoir interagir avec des utilisateurs aux profils divers et variés et de m'attaquer à des cas d'utilisation plus vastes.
Avec la diversification des utilisateurs, le nombre de questions concernant la gestion de l'allocation des ressources a augmenté, notamment sur le mystérieux rapport partition/segment et sur la façon d'éviter les disjoncteurs. C'est tout à fait compréhensible ! Moi-même, lorsque j'ai commencé à utilisé la Suite Elastic, je me posais les mêmes questions. C'était la première fois que je gérais des segments Java et des partitions de bases de données temporelles, et que je scalais ma propre infrastructure.
Lorsque j'ai rejoint l'équipe Elastic, j'ai particulièrement apprécié le fait de pouvoir accéder à des articles de blog et des tutoriels, en plus de la documentation, pour pouvoir être opérationnel rapidement. Mais le premier mois, cela a été difficile d'appliquer mes connaissances théoriques aux erreurs soumises par les utilisateurs via des tickets. Tout comme d'autres ingénieurs du support technique, je suis finalement parvenu à la conclusion qu'un grand nombre des erreurs signalées étaient simplement symptomatiques de problèmes d'allocation et que la même demi-douzaine de liens permettrait aux utilisateurs d'apprendre à gérer correctement leur allocation de ressources.
Dans les sections suivantes, je vais m'exprimer en tant qu'ingénieur du support technique en présentant les principaux liens que nous envoyons aux utilisateurs sur la théorie concernant la gestion de l'allocation, les principaux symptômes que nous rencontrons, et les emplacements vers lesquels nous redirigeons les utilisateurs pour qu'ils puissent mettre à jour leurs configurations et résoudre leurs problèmes d'allocation de ressources.
Théorie
En tant qu'application Java, Elasticsearch nécessite une allocation de mémoire logique (par segments) à partir de la mémoire physique du système. Cette allocation devrait ne pas dépasser la moitié de la RAM physique, soit un plafond de 32 Go. En général, lorsqu'on définit une consommation de segments supérieure à ce plafond, c'est pour pouvoir gérer des requêtes gourmandes en ressources et des volumes de stockage des données importants. Le disjoncteur parent est défini par défaut sur un seuil de 95 %, mais nous recommandons de scaler les ressources lorsqu'un seuil de 85 % est atteint de façon permanente.
Pour en savoir plus, je vous recommande vivement de consulter les articles ci-dessous, qui ont été rédigés par notre équipe :
- A heap of trouble
- Heap: Sizing and swapping
- Combien de partitions doit comporter mon cluster Elasticsearch ?
Configuration
Les paramètres par défaut d'Elasticsearch calculent automatiquement la taille de votre segment JVM en fonction du rôle du nœud et de la mémoire totale. Toutefois, vous pouvez la configurer directement selon les besoins en appliquant l'une des trois méthodes suivantes :
1. Directement dans config > fichier jvm.options dans vos fichiers Elasticsearch locaux
## JVM configuration
################################################################
## IMPORTANT: JVM heap size
################################################################
…
#Xms represents the initial size of total heap space
#Xmx represents the maximum size of total heap space
-Xms4g
-Xmx4g
2. En tant que variable d'environnement Elasticsearch dans docker-compose
version: '2.2'
services:
es01:
image: docker.elastic.co/elasticsearch/elasticsearch:7.12.0
environment:
- node.name=es01
- cluster.name=es
- bootstrap.memory_lock=true
- "ES_JAVA_OPTS=-Xms512m -Xmx512m"
- discovery.type=single-node
ulimits:
memlock:
soft: -1
hard: -1
ports:
- 9200:9200
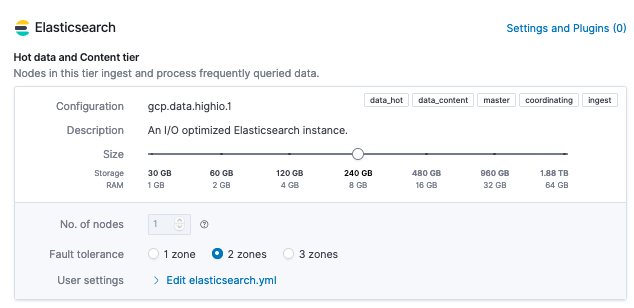
3. Via Elasticsearch Service > Deployment > Edit view (Elasticsearch Service > Déploiement > Modifier la vue). Remarque : le curseur attribue la mémoire physique, dont environ la moitié sera allouée au segment.
Résolution des problèmes
Si vous rencontrez actuellement des problèmes de performances avec votre cluster, ceux-ci s'expliquent probablement par les raisons habituelles :
- Problèmes de configuration : un trop grand nombre de partitions, pas de politique ILM
- Volume concerné : rythme élevé/charge élevée des requêtes, chevauchement de requêtes/écritures gourmandes en ressources
Toutes les requêtes de cURL ou d'API ci-dessous peuvent être émises dans Elasticsearch Service > API Console (Console API), en tant que cURL dans l'API Elasticsearch, ou dans Kibana > Dev Tools (Outils de développement).
Nombre excessif de partitions
Les index de données sont stockés dans des sous-partitions qui utilisent le segment pour la maintenance ou pendant des requêtes de recherche/d'écriture. La taille d'une partition devrait être plafonnée à 50 Go et le nombre de partitions devrait être limité selon l'équation suivante :
shards = sum(nodes.max_heap) * 20
Si l'on reprend l'exemple ci-dessus concernant Elasticsearch Service avec une mémoire physique de 8 Go sur deux zones (ce qui permettra d'allouer deux nœuds au total) :
#node.max_heap
8GB of physical memory / 2 = 4GB of heap
#sum(nodes.max_heap)
4GB of heap * 2 nodes = 8GB
#max shards
8GB * 20
160
Comparez ensuite les résultats à _cat/allocation
GET /fr/_cat/allocation?v=true&h=shards,node
shards node
41 instance-0000000001
41 instance-0000000000
Ou à _cluster/health
GET /fr/_cluster/health?filter_path=status,*_shards
{
"status": "green",
"unassigned_shards": 0,
"initializing_shards": 0,
"active_primary_shards": 41,
"relocating_shards": 0,
"active_shards": 82,
"delayed_unassigned_shards": 0
}
Dans ce déploiement, il y a donc 82 partitions sur les 160 recommandées. Si ce nombre était supérieur au nombre recommandé, il est plus que probable que vous rencontriez les symptômes que nous allons étudier dans les deux prochaines sections.
Si une partition quelconque indique une valeur supérieure à 0 en dehors de active_shards ou de active_primary_shards, il s'agit d'une erreur de configuration entraînant des problèmes de performances.
Généralement, en cas de problème, vous aurez unassigned_shards>0. S'il s'agit de partitions principales, votre cluster indiquera status:red. En revanche, s'il s'agit de répliques, il indiquera status:yellow. (C'est pourquoi il est important de définir des répliques sur les index. Ainsi, si le cluster rencontre un problème, il pourra se restaurer et éviter les pertes de données.)
Supposons que nous ayons status:yellow avec une partition non attribuée. Pour comprendre ce qui se passe, nous allons déterminer quelle partition d'index rencontre des difficultés en nous servant de _cat/shards.
GET _cat/shards?v=true&s=state
index shard prirep state docs store ip node
logs 0 p STARTED 2 10.1kb 10.42.255.40 instance-0000000001
logs 0 r UNASSIGNED
kibana_sample_data_logs 0 p STARTED 14074 10.6mb 10.42.255.40 instance-0000000001
.kibana_1 0 p STARTED 2261 3.8mb 10.42.255.40 instance-0000000001
Nous pouvons voir que le problème se trouve dans nos logs d'index hors système, qui disposent d'une réplique de partition non attribuée. Examinons ce qui bloque en exécutant _cluster/allocation/explain (petit conseil de pro : c'est exactement ce que nous faisons lorsque vous contactez le support technique).
GET _cluster/allocation/explain?pretty&filter_path=index,node_allocation_decisions.node_name,node_allocation_decisions.deciders.*
{ "index": "logs",
"node_allocation_decisions": [{
"node_name": "instance-0000000005",
"deciders": [{
"decider": "data_tier",
"decision": "NO",
"explanation": "node does not match any index setting [index.routing.allocation.include._tier] tier filters [data_hot]"
}]}]}
Ce message d'erreur désigne data_hot, qui fait partie d'une politique de gestion du cycle de vie des index (ILM). Il indique que notre politique ILM n'est pas alignée sur les paramètres d'index actuellement définis. Dans le cas présent, cette erreur s'explique par le fait qu'une politique ILM hot-warm a été définie sans qu'aucun nœud hot-warm n'ait été désigné. (Je devais m'assurer que quelque chose ne fonctionnerait pas, j'ai donc forcé les choses pour vous montrer des exemples d'erreur. Regardez à quoi j'en suis rendu 😂.)
Pour info, si vous exécutez cette commande alors que vous n'avez aucune partition non attribuée, vous obtiendrez une erreur 400 indiquant qu'il est impossible de trouver une partition non attribuée, car il n'y a aucun problème à signaler.
Si vous obtenez une cause non logique (p. ex. une erreur de réseau temporaire, comme le départ d'un nœud du cluster lors de l'allocation), vous pouvez utiliser le très pratique _cluster/reroute.
POST /fr/_cluster/reroute
Cette requête sans personnalisation lance un processus en arrière-plan asynchrone qui tente d'allouer toutes les partitions ayant un statut state:UNASSIGNED. (Ne faites pas comme moi et n'attendez pas que le processus se termine pour contacter l'équipe de développement. Je pensais que ce serait instantané et comme par hasard, au moment où j'ai fait remonter le problème, on m'a répondu qu'il n'y avait rien d'anormal parce qu'effectivement, le problème avait disparu.)
Disjoncteurs
Lorsque votre allocation de segment est saturée, les requêtes envoyées à votre cluster peuvent expirer ou échouer, ce qui peut entraîner régulièrement des exceptions de disjoncteurs. Le déclenchement d'un disjoncteur peut entraîner des événements elasticsearch.log comme suit :
Caused by: org.elasticsearch.common.breaker.CircuitBreakingException: [parent] Data too large, data for [] would be [num/numGB], which is larger than the limit of [num/numGB], usages [request=0/0b, fielddata=num/numKB, in_flight_requests=num/numGB, accounting=num/numGB]
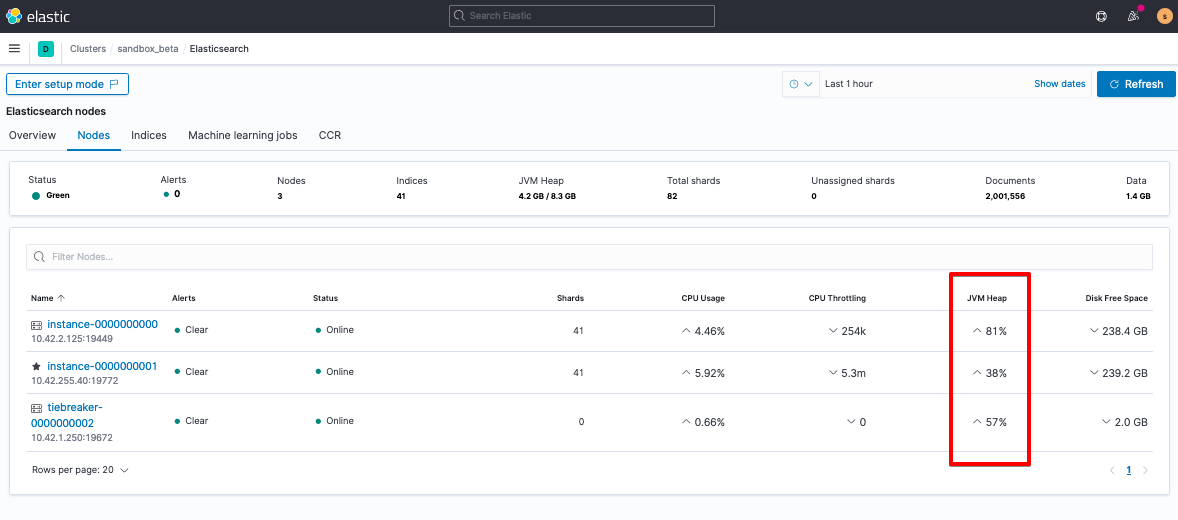
Pour comprendre ce qui se passe, examinez heap.percent, soit en passant par _cat/nodes :
GET /fr/_cat/nodes?v=true&h=name,node*,heap*
#heap = JVM (logical memory reserved for heap)
#ram = physical memory
name node.role heap.current heap.percent heap.max
tiebreaker-0000000002 mv 119.8mb 23 508mb
instance-0000000001 himrst 1.8gb 48 3.9gb
instance-0000000000 himrst 2.8gb 73 3.9gb
Soit, si vous avez précédemment activé le monitoring de la suite, en passant par Kibana > Stack Monitoring (Monitoring de la suite).
S'il est avéré que vous avez atteint le seuil de déclenchement des disjoncteurs de mémoire, envisagez d'augmenter le segment de manière temporaire afin que vous puissiez souffler et prendre le temps de faire des recherches sur l'origine du problème. Lorsque vous recherchez la cause première d'un problème, parcourez les logs de proxy de votre cluster ou le fichier elasticsearch.log pour voir les événements consécutifs qui précèdent. Recherchez notamment :
- les requêtes gourmandes en ressources, plus particulièrement :
- de nombreuses agrégations de buckets ;
- Je me suis senti si bête lorsque j'ai découvert que les recherches allouaient temporairement une certaine portion du segment avant d'exécuter la requête selon la taille des recherches ou des dimensions d'un bucket, ce qui fait qu'un paramétrage de 10 millions de lignes a vraiment donné des sueurs froides à mon équipe opérationnelle.
- les mappings non optimisés ;
- la seconde raison pour laquelle je me suis senti bête, c'est quand je pensais qu'un reporting hiérarchique donnerait de meilleurs résultats de recherche que des données lissées (ce n'est pas le cas).
- de nombreuses agrégations de buckets ;
- Le volume et le rythme des requêtes : en général les requêtes par lot ou asynchrones.
Quand l'heure de scaler arrive...
Si ce n'est pas la première fois que vous atteignez le seuil de déclenchement des disjoncteurs ou que vous suspectez qu'un problème s'est installé de façon permanente (par exemple si vous atteignez systématiquement le seuil de 85 %, ce qui signifie qu'il est temps d'envisager de scaler les ressources), nous vous recommandons de garder un œil sur la pression de mémoire JVM, qui sert d'indicateur à long terme pour votre segment. Pour consulter cet indicateur, accédez à Elasticsearch Service > Deployment (Déploiement).
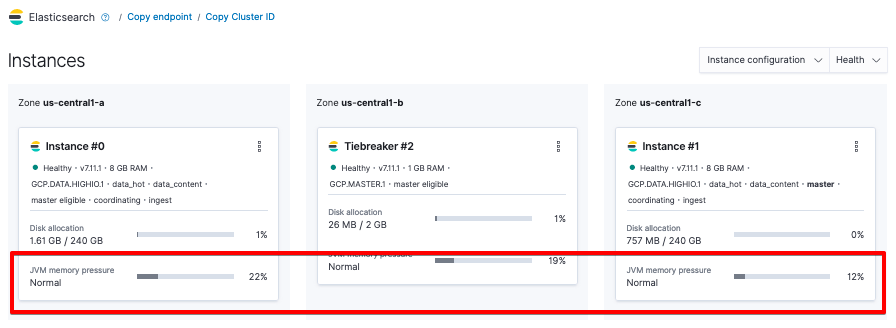
Vous pouvez aussi le calculer à partir de _nodes/stats.
GET /fr/_nodes/stats?filter_path=nodes.*.jvm.mem.pools.old
{"nodes": { "node_id": { "jvm": { "mem": { "pools": { "old": {
"max_in_bytes": 532676608,
"peak_max_in_bytes": 532676608,
"peak_used_in_bytes": 104465408,
"used_in_bytes": 104465408
}}}}}}}
où
JVM Memory Pressure = used_in_bytes / max_in_bytes
Des symptômes potentiels sont la fréquence élevée et la durée prolongée des événements du récupérateur de mémoire (gc) dans elasticsearch.log.
[timestamp_short_interval_from_last][INFO ][o.e.m.j.JvmGcMonitorService] [node_id] [gc][number] overhead, spent [21s] collecting in the last [40s]
Si ces deux symptômes sont présents, vous devriez envisager soit de scaler votre cluster, soit de réduire le nombre de demandes à traiter. Voici ce que vous pouvez faire pour résoudre le problème :
- augmenter les ressources du segment (segment/nœud, nombre de nœuds) ;
- réduire les partitions (en supprimant les données inutiles/anciennes, en utilisant l'ILM pour placer les données dans des niveaux de stockage warm/cold afin de les compacter, en désactivant les répliques des données que vous pouvez vous permettre de perdre).
Conclusion
Eh bien ! D'après ce que je vois dans le support technique Elastic, nous venons d'étudier les problèmes les plus courants pour lesquels les utilisateurs ouvrent des tickets : partitions non attribuées, mauvais équilibre partition/segment, disjoncteurs, récupération de mémoire élevée, erreurs d'allocation. Tous ces symptômes sont liés à la gestion de l'allocation des ressources. Heureusement, vous connaissez à présent la théorie et la résolution associée.
Néanmoins, si vous ne parvenez pas à résoudre un problème, n'hésitez pas à nous écrire. Nous serons très heureux de vous aider ! Vous pouvez nous contacter sur les forums de discussion Elastic, sur le canal Slack de la communauté Elastic, ou encore par le biais des équipes de consulting, de formation et de support technique.
Vive notre capacité à gérer l'allocation des ressources de la Suite Elastic !