Monitorer Kafka avec Elasticsearch, Kibana et Beats
En 2016, nous avions publié un article sur le monitoring de Kafka avec Filebeat. Depuis la version 6.5, Beats prend en charge un module Kafka. Ce module automatise une bonne partie des tâches liées au monitoring d'un cluster Kafka.
Dans cet article de blog, nous allons nous pencher sur la collecte des données de logs et d'indicateurs via les modules Kafka de Filebeat et de Metricbeat. Nous allons ingérer ces données dans un cluster hébergé sur Elasticsearch Service, et examiner les tableaux de bord Kibana fournis par les modules Beats.
Nous utiliserons ici la Suite Elastic 7.1. Vous trouverez un exemple d'environnement sur GitHub.
Pourquoi utiliser des modules ?
Quiconque a travaillé avec des filtres Grok complexes dans Logstash vous dira combien il est appréciable de pouvoir configurer la collecte de logs via un module Filebeat aussi facilement. Mais l'utilisation de modules pour configurer le monitoring présente d'autres avantages :
- Configuration simplifiée de la collecte de logs et d'indicateurs
- Documents standardisés via Elastic Common Schema
- Modèles d'index judicieux, fournissant des types optimaux de champ de données
- Taille adaptée des index. Les agents Beats utilisent l'API Rollover pour veiller à ce que la taille des partitions d'index Beats reste gérable.
Pour découvrir la liste complète des modules pris en charge par Filebeat et Metricbeat, consultez la documentation correspondante.
Présentation de l'environnement
Notre exemple de configuration est constitué d'un cluster Kafka composé de trois nœuds (kafka0, kafka1 et kafka2). Chaque nœud exécute Kafka 2.1.1, ainsi que Filebeat et Metricbeat pour assurer le monitoring du nœud. Pour envoyer les données vers notre cluster Elasticsearch Service, les agents Beats sont configurés via l'identifiant Cloud ID. Les modules Kafka intégrés à Filebeat et Metricbeat configureront quant à eux des tableaux de bord dans Kibana pour la visualisation des données. Remarque : pour essayer cette configuration dans votre propre cluster, vous pouvez déployer gratuitement une version d'essai de 14 jours d'Elasticsearch Service, et tester l'ensemble de ses fonctionnalités.
Configurer les agents Beats
Ensuite, vous allez configurer puis lancer les agents Beats.
Installer et activer les services Beats
Pour installer Filebeat et Metricbeat, nous suivrons les instructions de leurs guides de prise en main respectifs. Comme nous sommes sous Ubuntu, nous installerons les agents Beats via le référentiel APT.
wget -qO - https://artifacts.elastic.co/GPG-KEY-elasticsearch | sudo apt-key add - echo "deb https://artifacts.elastic.co/packages/7.x/apt stable main" | sudo tee -a /etc/apt/sources.list.d/elastic-7.x.list sudo apt-get update sudo apt-get install filebeat metricbeat systemctl enable filebeat.service systemctl enable metricbeat.service
Configurer l'identifiant Cloud ID du déploiement Elasticsearch Service
Copiez l'identifiant Cloud ID depuis la console Elastic Cloud, puis utilisez-le pour configurer les sorties Filebeat et Metricbeat.
CLOUD_ID=Kafka_Monitoring:ZXVyb3BlLXdlc...
CLOUD_AUTH=elastic:password
filebeat export config -E cloud.id=${CLOUD_ID} -E cloud.auth=${CLOUD_AUTH} > /etc/filebeat/filebeat.yml
metricbeat export config -E cloud.id=${CLOUD_ID} -E cloud.auth=${CLOUD_AUTH} > /etc/metricbeat/metricbeat.yml
Activer les modules Kafka et système dans Filebeat et Metricbeat
Nous devrons ensuite activer les modules Kafka et système pour les deux agents Beats.
filebeat modules enable kafka system metricbeat modules enable kafka system
Une fois les modules activés, nous pouvons lancer la commande setup pour configurer chaque agent Beats. Cette commande permet de configurer les modèles d'index et les tableaux de bord Kibana qu'utilisent les modules.
filebeat setup -e --modules kafka,system metricbeat setup -e --modules kafka,system
Lancer les agents Beats
Bien. Maintenant que tout est configuré, démarrons Filebeat et Metricbeat.
systemctl start metricbeat.service systemctl start filebeat.service
Explorer les données de monitoring
Voici que qu'affiche le tableau de bord de logging par défaut :
- Les exceptions récemment rencontrées par le cluster Kafka. Les exceptions sont groupées par classe d'exceptions et les informations détaillées de l'exception sont affichées.
- Un aperçu du débit des logs par niveau, ainsi que les informations détaillées sur le log.
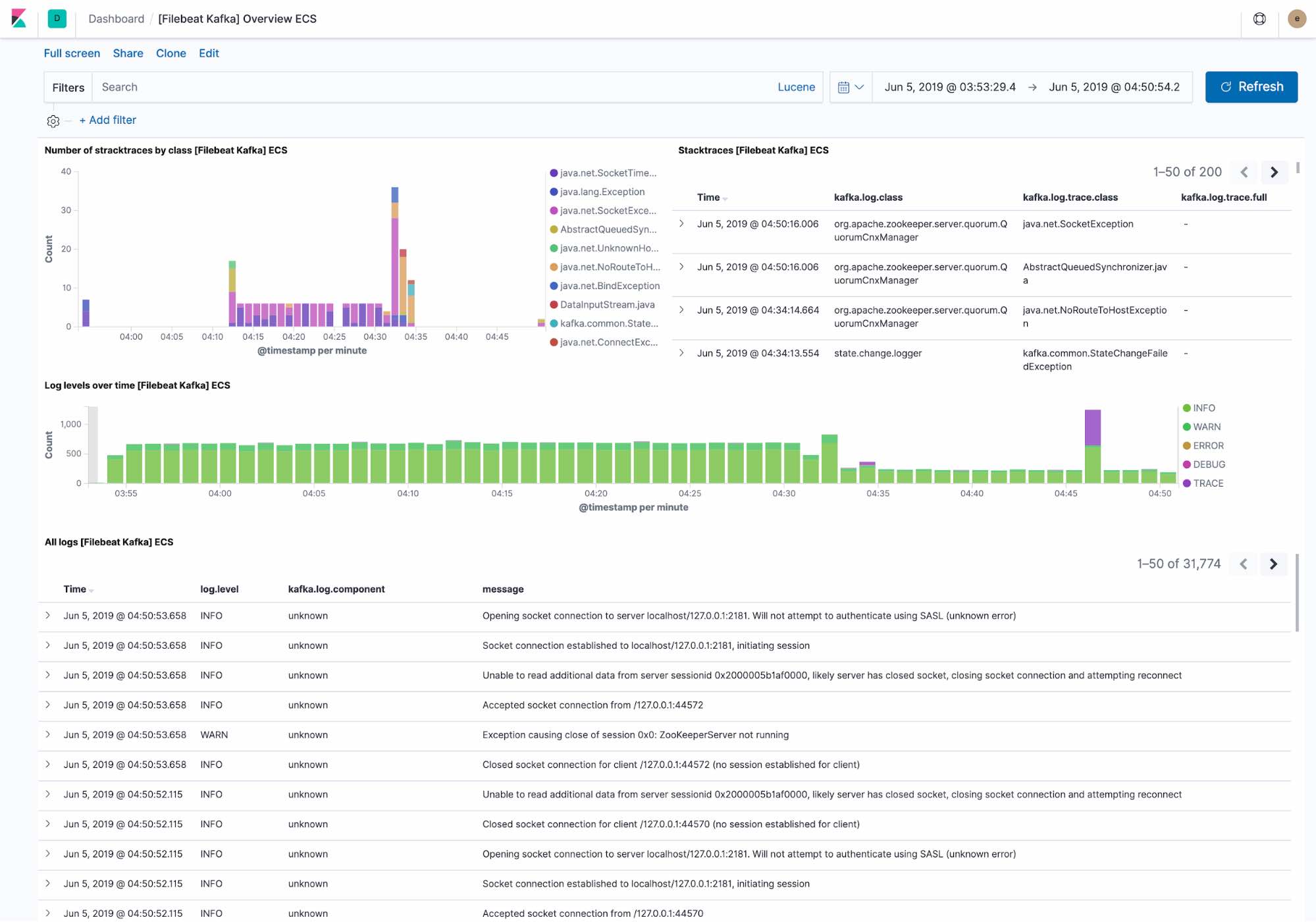
Filebeat ingère les données suivant Elastic Common Schema, ce qui nous permet d'appliquer des filtres pour descendre jusqu'au niveau de l'hôte.
Le tableau de bord fourni par Metricbeat affiche l'état actuel de n'importe quel sujet du cluster Kafka. Un menu déroulant nous permet aussi de filtrer le tableau de bord sur un seul sujet.
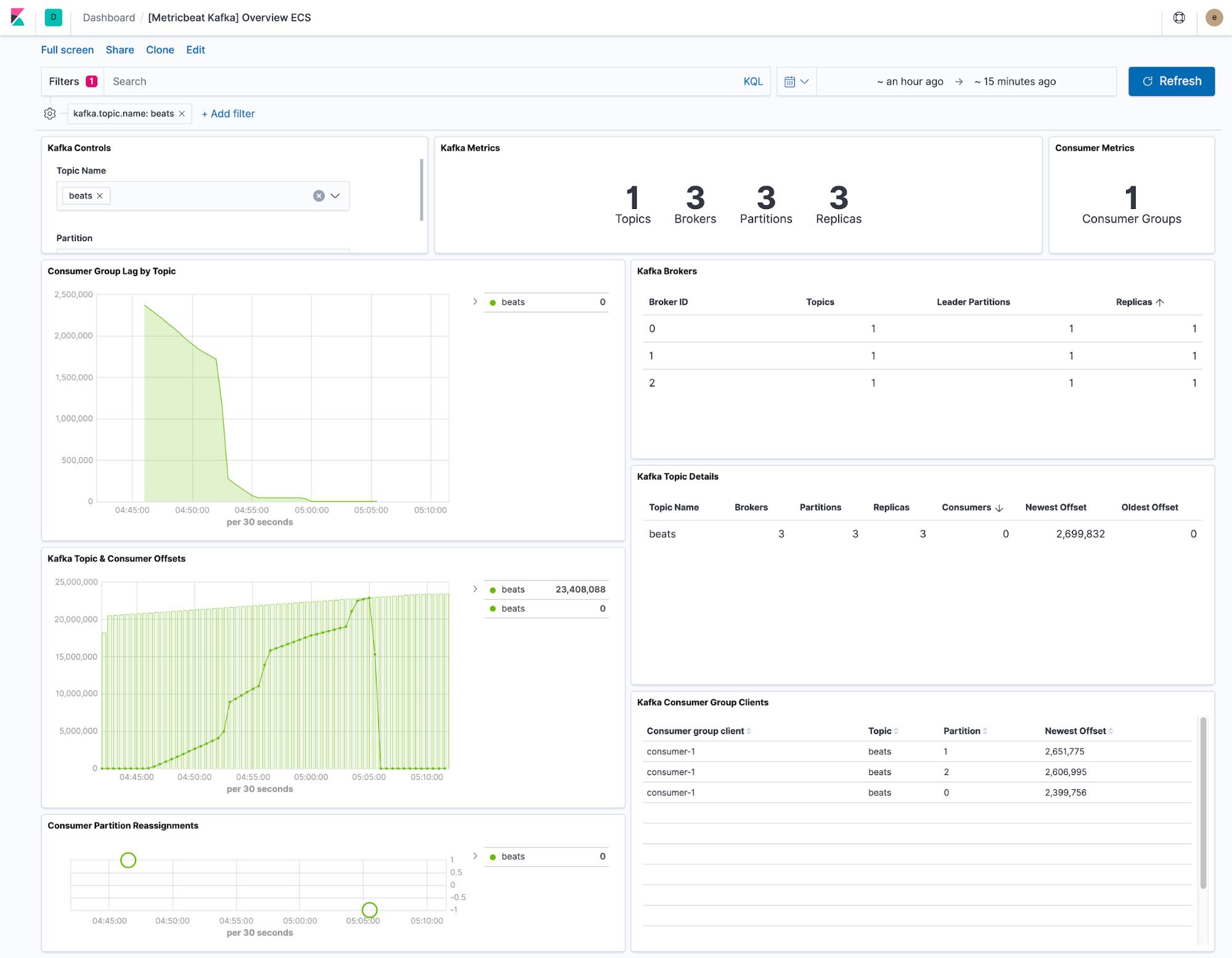
Les visualisations "consumer lag" et "offset" nous montrent si les consommateurs décrochent sur certains sujets. Les offsets par partition montrent également si une partition donnée est à la traîne.
La configuration Metricbeat par défaut collecte deux ensembles de données : kafka.partition et kafka.consumergroup. Ces ensembles de données nous informent sur l'état d'un cluster Kafka et des consommateurs qu'il contient.
L'ensemble de données kafka.partition comprend toutes les informations relatives à l'état des partitions contenues dans un cluster. Ces données peuvent servir à :
- Créer des tableaux de bord montrant le mapping des partitions vers les nœuds du cluster
- Signaler les partitions sans replicas synchronisés
- Effectuer le suivi de l'affectation des partitions au fil du temps
- Visualiser les limites d'offset des partitions au fil du temps.
Voici un document kafka.partition complet.

L'ensemble de données kafka.consumergroup indique l'état d'un seul consommateur. On peut utiliser ces données pour connaître les partitions que lit un seul consommateur et les offsets actuels de ce consommateur.
