Optimisation d'Elasticsearch : cas d'utilisation simple explorant la Suite Elastic, NiFi et Bitcoin

A travers ce tutoriel nous allons explorer quelques astuces pour optimiser les performances d'Elasticsearch.
Comme exemple de travail, et pour rendre les choses plus intéressantes, nous allons créer un graphique du taux de change Bitcoin sur Bitstamp.
À cette fin, nous allons utiliser :
- Bitstamp, qui offre une API publique qui nous permettra de rechercher le taux de change actuel
- Apache NiFi, qui est une sorte d'ETL : il permet d'extraire les données depuis une source (E: Extract), de les transformer (T: Transform) et de les charger dans un système tiers (L: Load), tout en définissant des pipelines complexes si nécessaire. Nous allons l'utiliser pour récupérer le taux de change Bitcoin sur Bitstamp
- Elasticsearch, qui est un puissant logiciel d'indexation populaire. Il peut être utilisé en tant qu'entrepôt de stockage de documents NoSQL. Nous allons donc l'utiliser pour stocker le taux de change Bitcoin sous forme de données temporelles
- Timelion, qui est un plugin Kibana conçu pour comprendre et analyser les données temporelles
Configuration d'Elasticsearch
Installation d'Elasticsearch / Kibana
Vous trouverez toutes les instructions nécessaires pour configurer la Suite Elastic directement dans la documentation Elastic :
Système / matériel
Elasticsearch est une solution gourmande en ressources ! Vous devez donc avoir la configuration système suivante pour pouvoir l'exécuter :
- Des disques (très) rapides : de préférence des disques SSD en RAID-0 pour des performances d'E/S optimales (ou vous pouvez avoir plusieurs disques montés sur votre système et laisser Elasticsearch décider où écrire les données). Cela suppose que vous disposez d'un cluster Elasticsearch avec redondance des données.
- Beaucoup de mémoire RAM : une grande quantité de mémoire RAM est nécessaire pour exécuter des requêtes complexes. Il est toutefois recommandé d'allouer la moitié de la mémoire système à Elasticsearch, et de laisser l'autre moitié pour le système de mise en cache des disques.
- Un CPU assez puissant : bien qu'Elasticsearch ne nécessite probablement pas autant de ressources de la CPU que de disques rapides ou qu'une importante quantité de mémoire RAM, l'indexation et la recherche peuvent concerner un important volume de données. Donc, plus votre CPU sera rapide, plus vous obtiendrez de meilleurs temps de réponse.
Le dimensionnement correct d'un cluster Elasticsearch est généralement une tâche difficile qui exige une certaine expérience pour pouvoir mener à bien l'opération. Identifiez vos exigences fonctionnelles :
- volume de données que vous comptez ingérer
- type de requêtes que vous allez exécuter
- temps de réponse que vous souhaitez atteindre pour les requêtes
- etc.
Puis, réalisez des tests de performance au cours des premières phases de votre projet. Vous disposerez ainsi de métriques qui vous permettront de dimensionner correctement votre plateforme de production.
Commencez par une petite plateforme et faites-la évoluer de sorte qu'elle réponde à vos exigences fonctionnelles.
L'avantage d'Elasticsearch est que vous pouvez faire évoluer votre cluster très facilement en y ajoutant d'autres nœuds, si vous avez conçu des index dans cet objectif. Nous verrons cela plus en détail un peu plus tard.
| Astuce pour les pros ! Lorsque vous adaptez votre cluster à vos besoins, préférez une évolutivité horizontale (en ajoutant plus de nœuds) à une évolutivité verticale (ajout de nœuds plus grands). Ceci facilitera non seulement le partage de la charge, mais améliorera aussi la tolérance aux pannes. |
Paramètres Elasticsearch
Certains paramètres Elasticsearch sont essentiels pour obtenir de bonnes performances :
- La taille de la mémoire heap JVM, qui doit correspondre à la moitié de la quantité totale de mémoire RAM (en laissant l'autre moitié pour la mise en cache des disques au niveau du système d'exploitation). Ce paramètre est défini dans le fichier
java.options. - Le nombre de descripteurs de fichiers ouverts doit être aussi élevé que possible (paramètre système en général : pour Linux, vous le trouverez dans le fichier de configuration
/etc/security/limits.conf). - Vous devez également vous assurer que les données Elasticsearch ne seront pas extraites de la mémoire vive et insérées dans l'espace disque afin d'éviter toute baisse sporadique et inattendue des performances.
Elastic fournit une documentation exhaustive pour un grand nombre de ces paramètres.
| Astuce pour les pros ! Vous devrez optimiser le système d'exploitation ainsi que la JVM pour obtenir les meilleures performances d'Elasticsearch. |
Maintenance des données
Elasticsearch nécessitera de plus en plus de ressources (disque, mémoire RAM, CPU) à mesure que le volume de documents augmente. Un volume de données trop important empêchera Elasticsearch d'exécuter les requêtes correctement. Il est donc primordial de se débarrasser des données obsolètes dès que possible.
La suppression de documents dans un index Elasticsearch est une opération laborieuse, en particulier si ces documents sont nombreux. En revanche, la suppression de l'ensemble d'un index est extrêmement facile.
Créez donc, dans la mesure du possible, des index temporels. Par exemple, chaque index devra contenir des données pour une journée, une semaine, un mois, une année spécifique, etc. Il vous suffira donc de supprimer la totalité des index lorsque vous voudrez vous débarrasser d'anciens documents.
Vous pouvez également fermer les index au lieu de les supprimer. Ainsi, vous conserverez les données sur le disque et libérerez des ressources CPU/RAM. Suite à cela, vous pourrez également rouvrir ces index plus tard si nécessaire.
Enfin, il y aura toujours des données stockées dans vos index que vous ne pourrez pas supprimer ou fermer, car vous les utilisez régulièrement. Souvent, les index les plus anciens cessent d'être modifiés : il en est souvent ainsi pour les données temporelles, pour lesquelles vous ajoutez des documents à l'index du jour et les anciens index sont essentiellement accessibles en lecture seule). Ces index peuvent être optimisés pour réduire leurs besoins en ressources.
Récapitulatif :
Supprimez les index lorsque les données sont obsolètes
- Fermez les index dont les données ne sont pas fréquemment utilisées
- Optimisez les index qui ne sont plus mis à jour
Il existe un outil qui vous aidera à faire tout cela en masse : curator.
Par exemple, voici comment purger les données de plus de 3 mois dans notre cas :
Définition des fichiers de configuration YAML dans curator
Tout d'abord, vous devez créer un fichier de configuration YAML nommé actions.yml afin de décrire exactement les critères sur lesquels vous souhaitez fonder la purge des données :
---
# Remember, leave a key empty if there is no value. None will be a string,
# not a Python "NoneType"
#
# Also remember that all examples have 'disable_action' set to True. If you
# want to use this action as a template, be sure to set this to False after
# copying it.
actions:
1:
action: delete_indices
description: >-
Delete indices older than 90 days (based on index name), for bitstamp-
prefixed indices. Ignore the error if the filter does not result in an
actionable list of indices (ignore_empty_list) and exit cleanly.
options:
ignore_empty_list: True
timeout_override:
continue_if_exception: False
disable_action: True
filters:
- filtertype: pattern
kind: prefix
value: logstash-
exclude:
- filtertype: age
source: name
direction: older
timestring: '%Y-%m-%d'
unit: days
unit_count: 90
exclude:
| Infos Ces informations sont directement inspirées de l'exemple fourni dans la documentation officielle. Reportez-vous à cette documentation si vous souhaitez avoir de plus amples informations sur les opérations possibles (fermeture des index ou leur réorganisation via une opération forceMerge). |
Vous devrez également créer un fichier config.yml qui indiquera à curator comment se connecter au cluster Elasticsearch. Cette procédure est expliquée plus en détail dans la documentation officielle. Je ne vais donc pas aborder ce sujet ici.
Exécution de la commande curator
Après avoir créé ces fichiers de configuration, vous pouvez exécuter curator tout simplement de la façon suivante : curator --config config.yml actions.yml
En général, vous exécutez cette commande à l'aide d'une tâche cron.
J'aimerais attirer votre attention sur l'option --dry-run : grâce à celle-ci, curator vous indique le résultat d'une exécution en situation réelle sans effectuer les opérations, ce qui peut s'avérer pratique pour le débogage.
Astuce pour les pros !
|
Configuration des index et modélisation des données
Shards et réplicas
Les index sont divisés en shards et les shards ont des réplicas. Les shards et les réplicas sont distribués entre les différents nœuds d'un cluster Elasticsearch :
- Le nombre de shards détermine la capacité du cluster à distribuer les opérations d'écriture entre les différents nœuds. S'ils ne sont pas assez nombreux, l'ajout de nœuds n'améliorera pas les performances d'écriture. Et s'ils sont trop nombreux, ils encombreront la RAM.
- Le nombre de réplicas détermine la capacité du cluster à distribuer les opérations de lecture, ainsi que la tolérance aux pannes. S'ils sont trop nombreux, ils occuperont un espace disque trop important. Et si leur nombre est faible, cela aura une incidence sur les performances de lecture et la tolérance aux pannes.
Les paramètres des index sont essentiels pour les performances d'Elasticsearch.
| Astuce pour les pros ! En ce qui concerne les shards et les réplicas, nous avons un peu affaire au principe dit de « Boucle d'Or » : il ne faut pas en avoir trop, ni trop peu, mais juste assez. Choisissez judicieusement le nombre de shards et de réplicas des index, car vous ne pourrez pas les modifier par la suite (vous devrez réindexer les données). |
Mapping des champs
L'indexation, les requêtes et les agrégations peuvent être gourmandes en ressources de la CPU et de la RAM. Mais, vous pouvez utiliser les connaissances que vous avez sur les données que vous allez stocker pour optimiser les performances d'Elasticsearch. Par exemple :
- Si vous savez que vous n'allez pas effectuer des recherches dans des champs spécifiques de vos documents, vous pouvez indiquer à Elasticsearch de ne pas les indexer.
- Si vous ne comptez pas trier ou agréger des données, n'activez pas
fielddata. - Si vous savez qu'un champ numérique sera dans une certaine plage, vous pouvez choisir le plus petit type numérique.
Compilation de l'ensemble
Les paramètres des shards / réplicas et le mapping des champs peuvent être définis dans un modèle d'index.
Voici celui que nous allons utiliser pour notre petite expérience d'indexation Bitcoin et que nous allons sauvegarder dans le fichier bitstamp-template.json :
{
"template" : "bitstamp-*",
"settings": {
"number_of_shards" : 5,
"number_of_replicas" : 0
},
"mappings" : {
"_default_" : {
"properties" : {
"timestamp" : {
"type" : "date",
"format" : "epoch_second"
}
}
},
"bitstampquotes": {
"properties" : {
"last" : {
"type" : "scaled_float",
"scaling_factor" : 100,
"index" : false,
"coerce" : true
},
"volume" : {
"type" : "float",
"index" : false,
"coerce" : true
}
}
}
}
}
Dans ce modèle assez simple, nous allons réaliser la procédure suivante :
- Nous indiquons à Elasticsearch d'appliquer le modèle à tout index dont le nom commence par « bitstamp- »
- Nous définissons le nombre de shards (qui est en fait la valeur par défaut, et pour être honnête, nous aurions pu définir la valeur sur 1 pour ce projet) et le nombre de réplicas sur zéro car nous utilisons un cluster avec un seul nœud.
- Nous indiquons que le champ
timestampest un champ de date, qui spécifie le nombre de secondes depuis le 1er janvier 1970. - Le champ
lastest une devise à 2 décimales que nous définissons avec un paramètrescaled_floatdoté d'un facteur de 100 (ce qui revient à dire que le taux last sera stocké en interne par Elasticsearch comme étant le nombre de centimes. Puis, il sera affiché après avoir été divisé par 100). - Nous ne rechercherons jamais un document indexé en fonction du
tauxlast ou duvolume. Nous indiquons donc à Elasticsearch qu'il n'est pas nécessaire de l'indexer.
Nous pouvons mettre en œuvre ce modèle d'index à l'aide de la commande suivante : curl -XPUT http://localhost:9200/_template/bitstamp_template_1?pretty -d @bitstamp-template.json
| Astuce pour les pros ! Utilisez votre connaissance des données que vous allez stocker dans Elasticsearch pour leurs permettre d'être plus efficaces et de consommer moins de ressources. |
Configuration de NiFi
NiFi agit en extrayant des données à partir de leur source, en les convertissant en un fichier « Flowfile » et puis en laissant le Flowfile être traité par les processeurs. Chaque processeur extrait ou modifie, à son tour, les données du Flowfile avant de passer au suivant. Cette opération se poursuit jusqu'à ce que le Flowfile soit passé par l'ensemble du workflow que vous avez défini.
Installation
Vous trouverez de plus amples informations sur l'extraction de la distribution NiFi, sa décompression et son démarrage dans la documentation officielle. Nous n'aborderons donc pas ces sujets ici.
Assemblage des processeurs
Nous allons utiliser 4 processeurs pour ce petit projet :
- GetHTTP va se connecter au point de terminaison de l'API Bitstamp pour obtenir le taux de change actuel et le volume.
- JoltJSONTransform sera utilisé pour ne retenir que les informations qui nous intéressent, et nous débarrasser du reste.
- EvaluateJSONPath va nous permettre de récupérer le timestamp indiqué dans le fichier Flowfile et l'enregistrer en tant qu'attribut Flowfile pour une utilisation ultérieure.
- PutElasticsearch5 va finalement indexer le fichier Flowfile dans Elasticsearch en utilisant l'attribut timestamp du fichier Flowfile pour spécifier dans quel index il doit être inséré.
Voyons maintenant plus en détail chaque processeur.
| Infos Vous devrez vous connecter à l'Interface Web de NiFi (URL par défaut spécifiée lors de l'installation en local). |
Définition d'un service de contexte SSL
Nous allons nous connecter à un site HTTPS afin de recueillir les renseignements liés au taux de change de Bitcoin, et à ce titre nous devons configurer un service de contexte SSL (StandardSSLContextService). Cela nous permettra de spécifier les certificats racines par exemple.
Vous pouvez effectuer cette opération dans NiFi comme indiqué dans l'animation suivante :
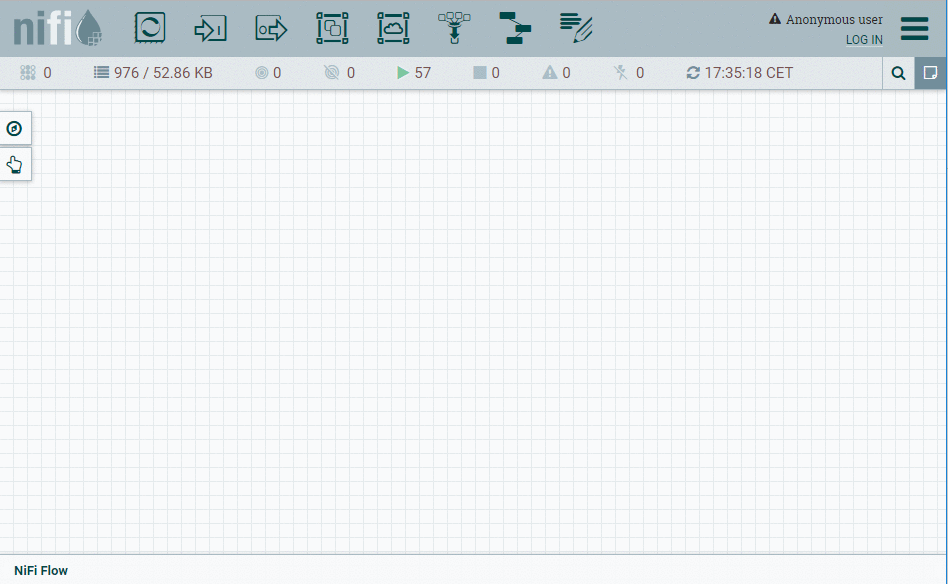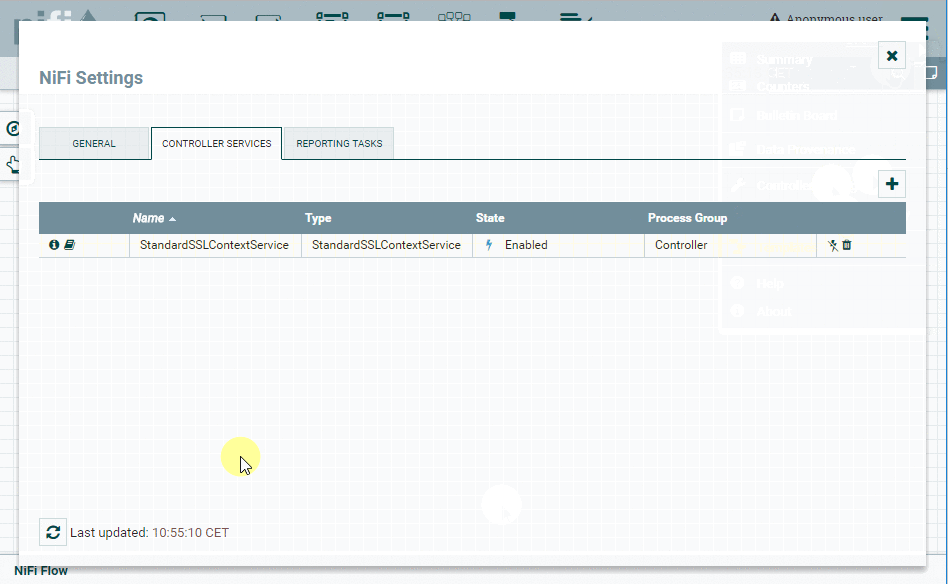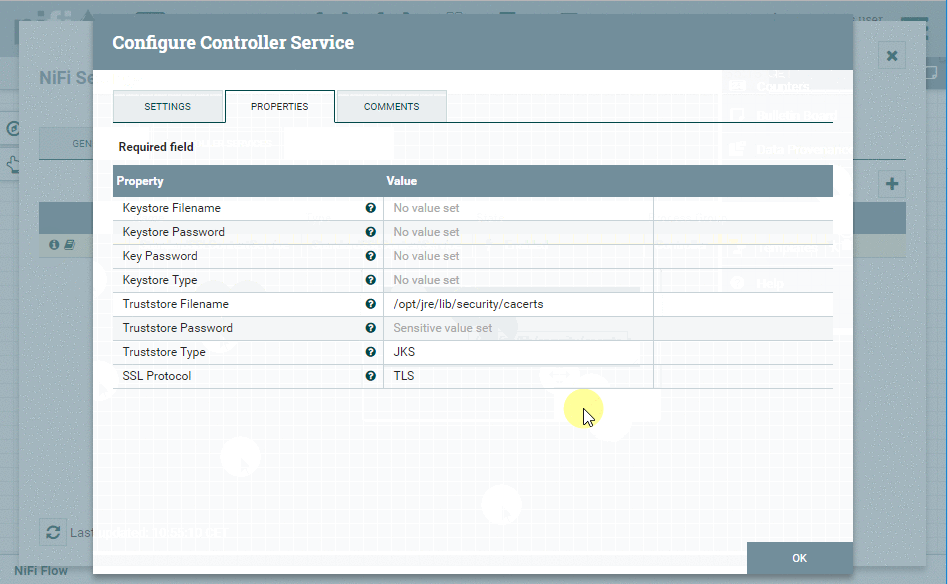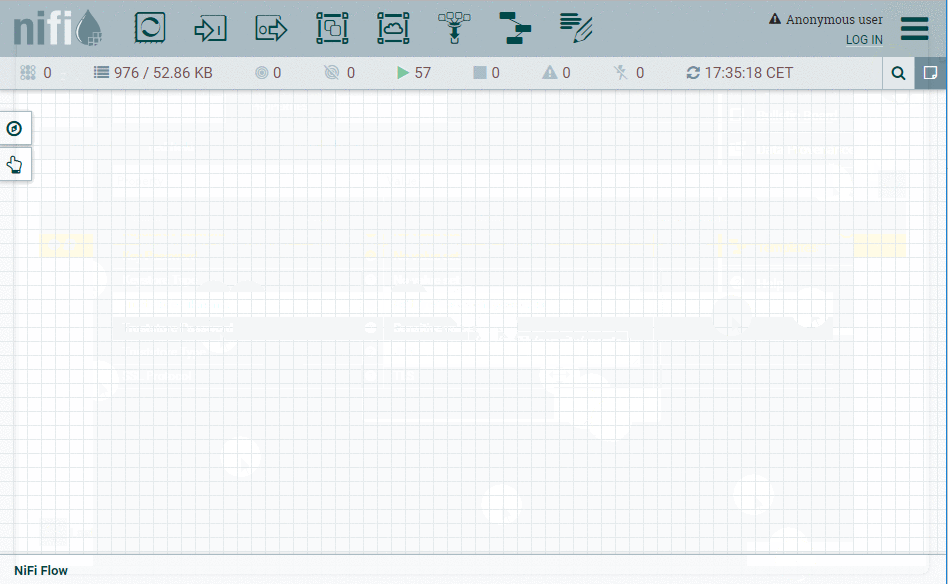
| Onglet | Propriété | Valeur |
| Settings | Name | StandardSSLContextService |
| Properties | Truststore Filename | /opt/jre/lib/security/cacerts |
| Properties | Truststore Password | changeit |
Ces paramètres sont ceux du magasin d'approbations Java Runtime Environment par défaut. Vous devrez probablement spécifier le chemin et le mot de passe correspondant à votre installation.
Positionnement des processeurs nécessaires
L'animation suivante démontre comment positionner les processeurs et les relier ensemble pour créer notre workflow :
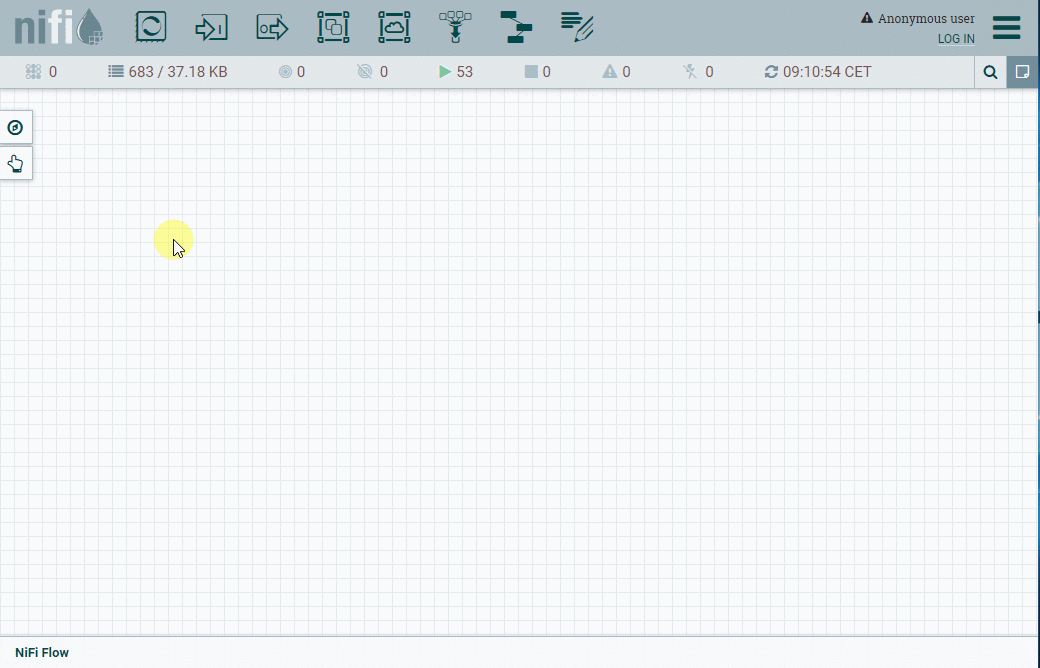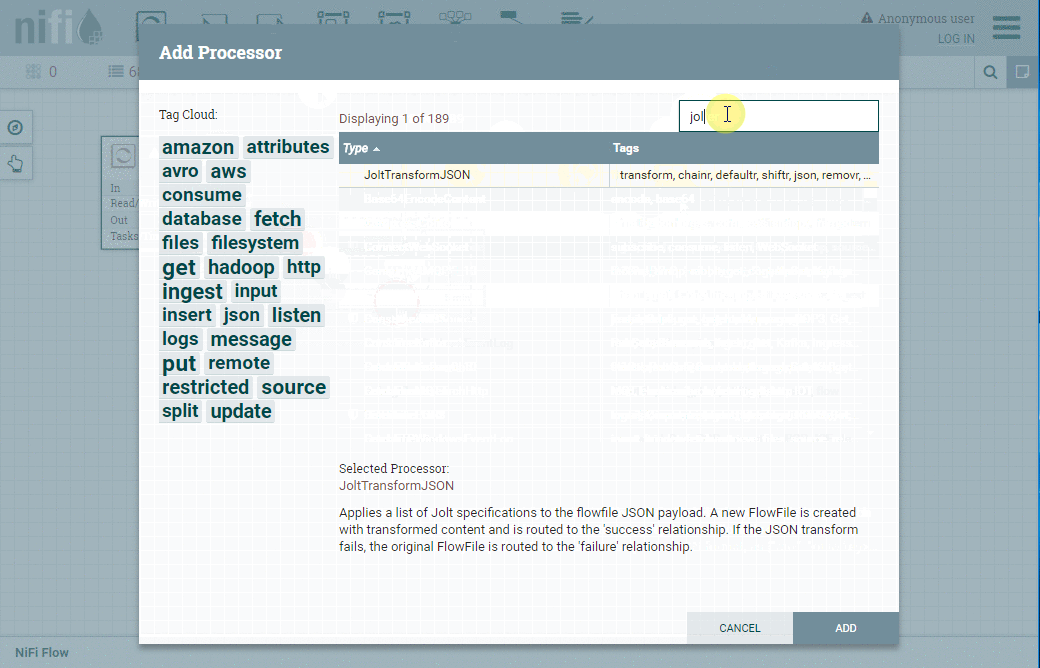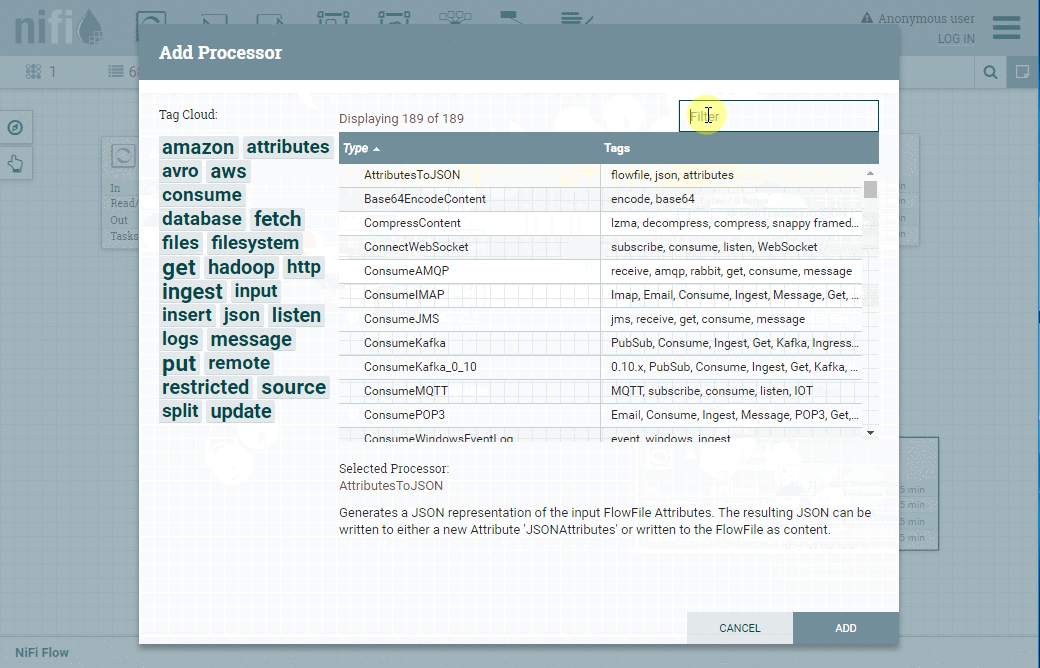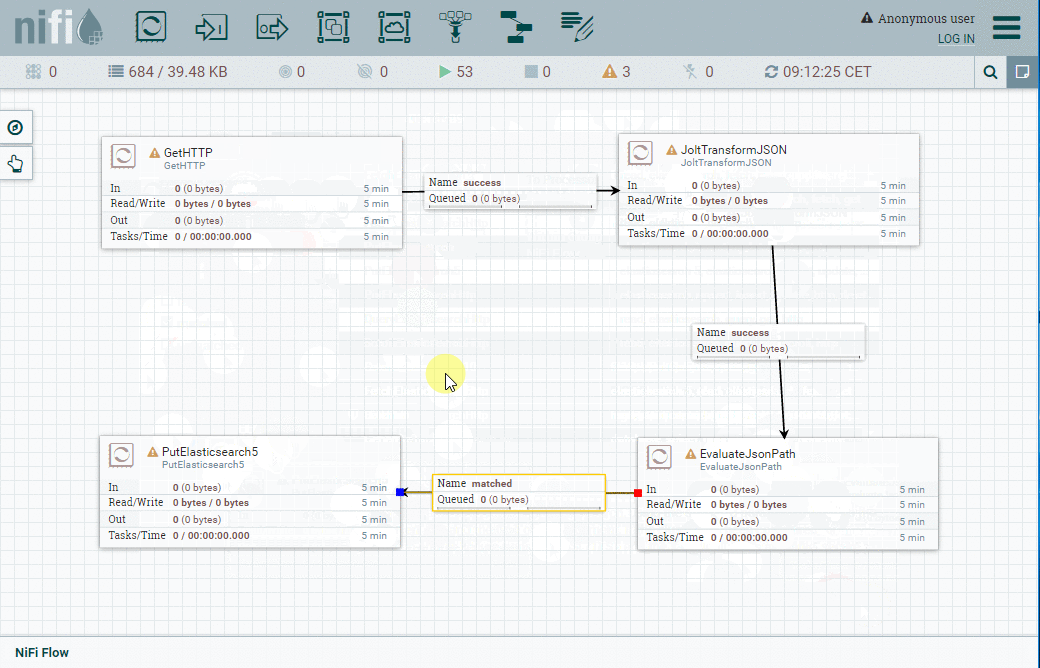
Après avoir terminé, vous devrez configurer chaque processeur.
Processeur GetHTTP
Le processeur GetHTTP est utilisé pour télécharger une seule page Web. Dans notre cas, il sera utilisé pour extraire les renseignements liés au taux de change de Bitcoin sous forme d'un fichier au format JSON fourni par l'API Bitstamp.
Voici ce que vous verrez si vous interrogez le processeur dans un navigateur Web :

Nous allons, en gros, faire en sorte que NiFi effectue la même opération via le processeur GetHTTP.
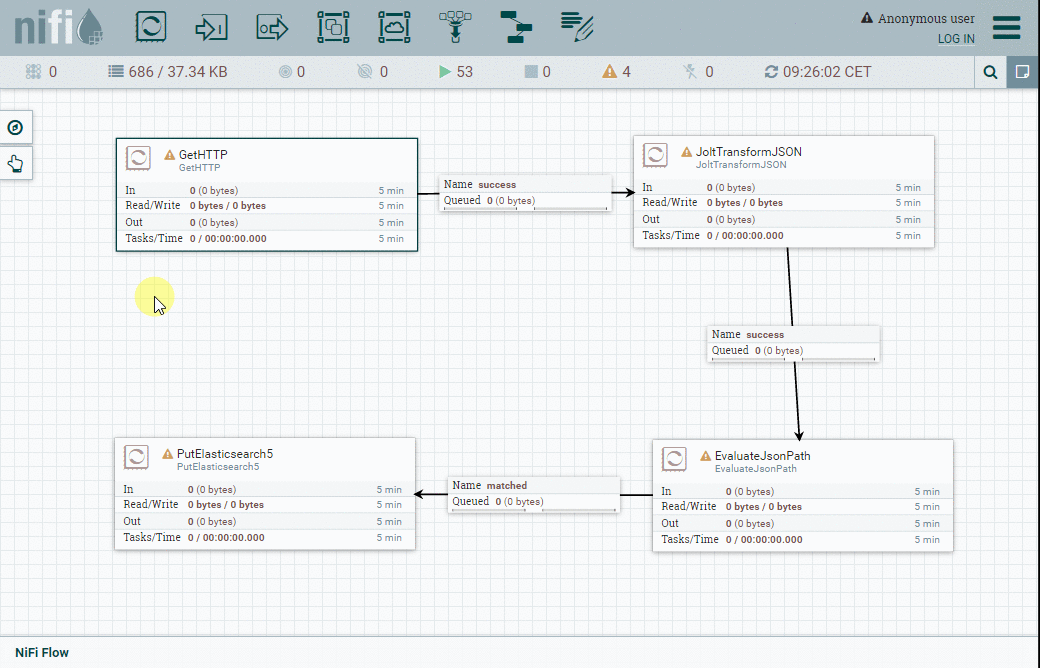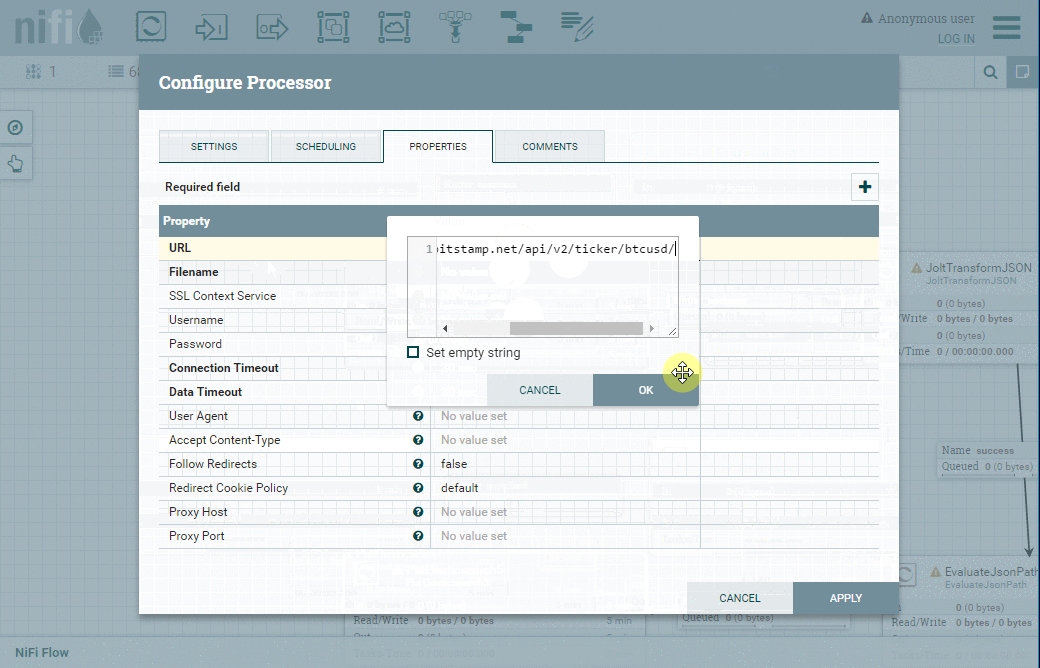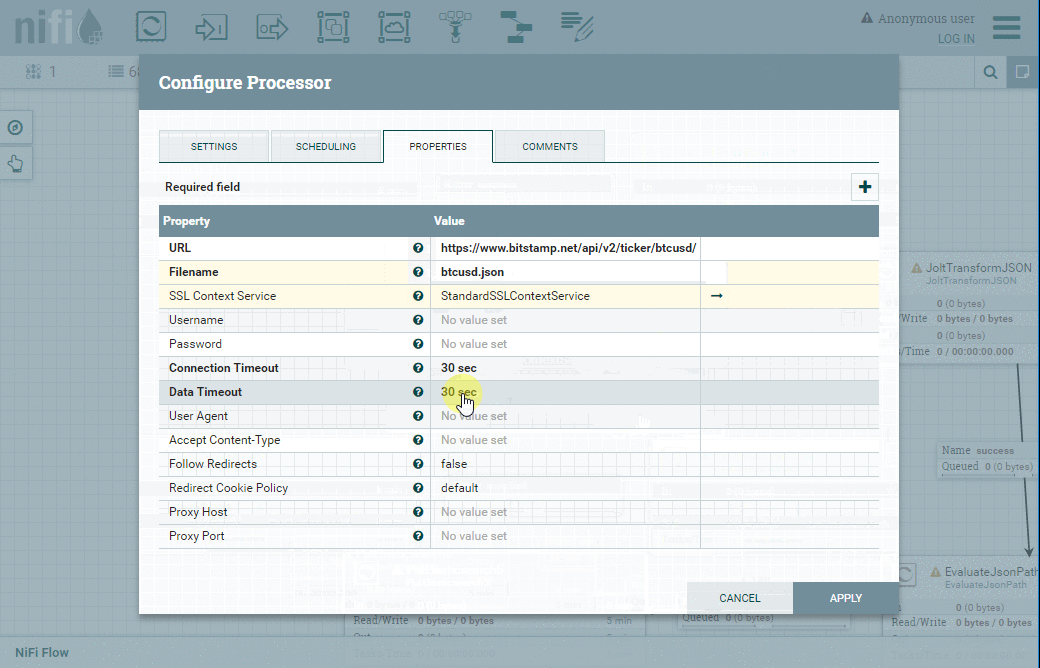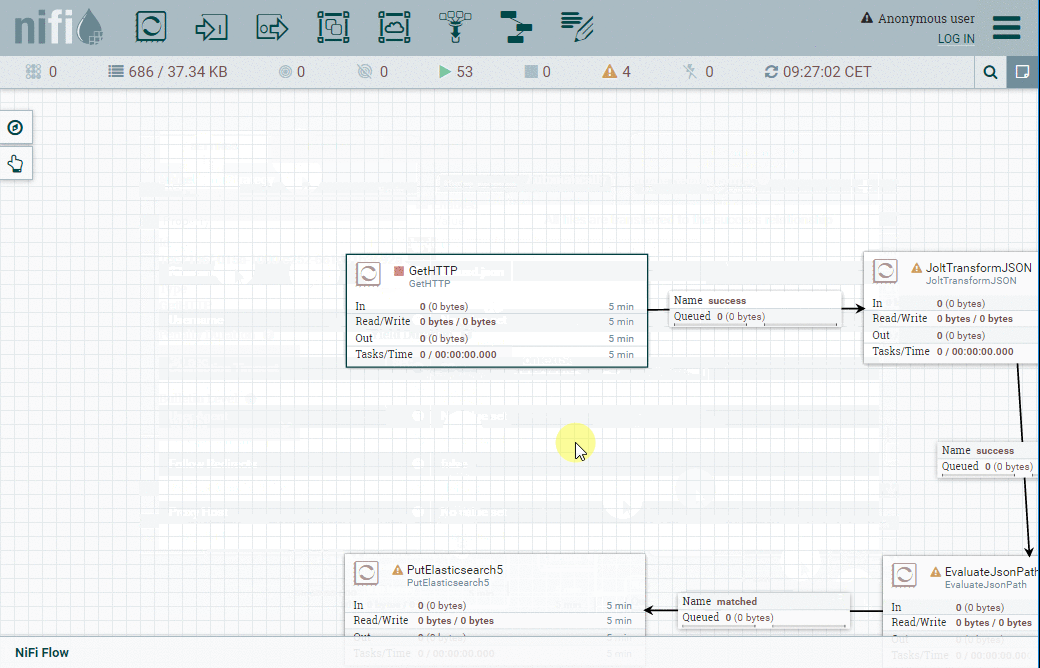
Comme vous pouvez vous en douter, nous devons configurer quelques paramètres :
| Onglet | Propriété | Valeur |
| Properties | URL | https://www.bitstamp.net/api/v2/ticker/btcusd/ |
| Properties | Filename | btcusd.json |
| Properties | Truststore Password | StandardSSLContextService |
| Properties | Run Schedule | 60 sec |
Voici la démonstration indiquant comment configurer tous ces paramètres :
Processeur JoltTransformJSON
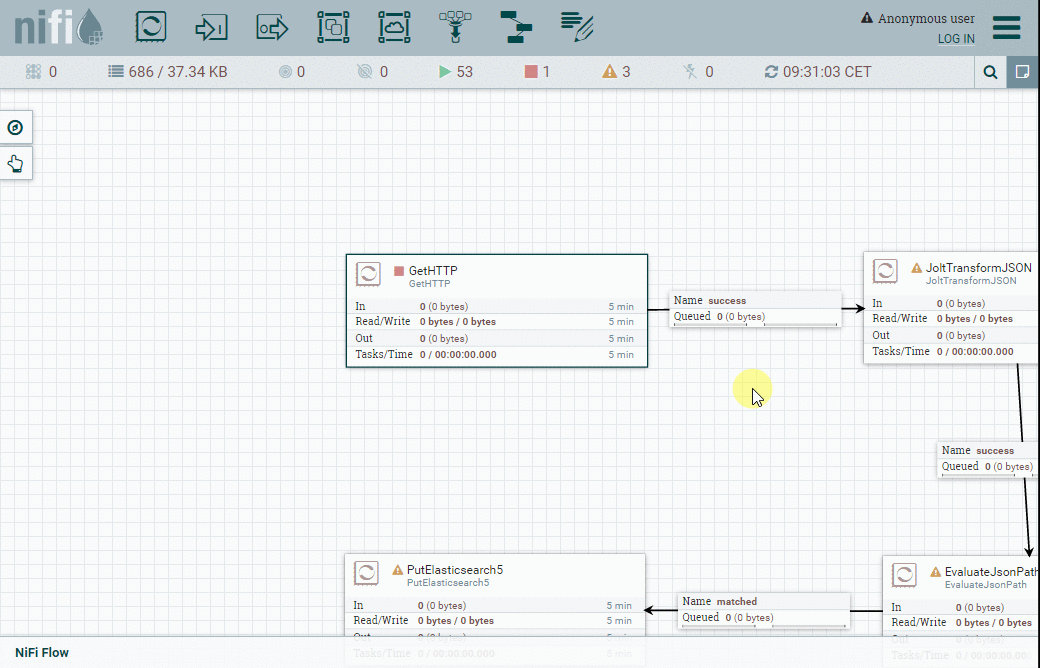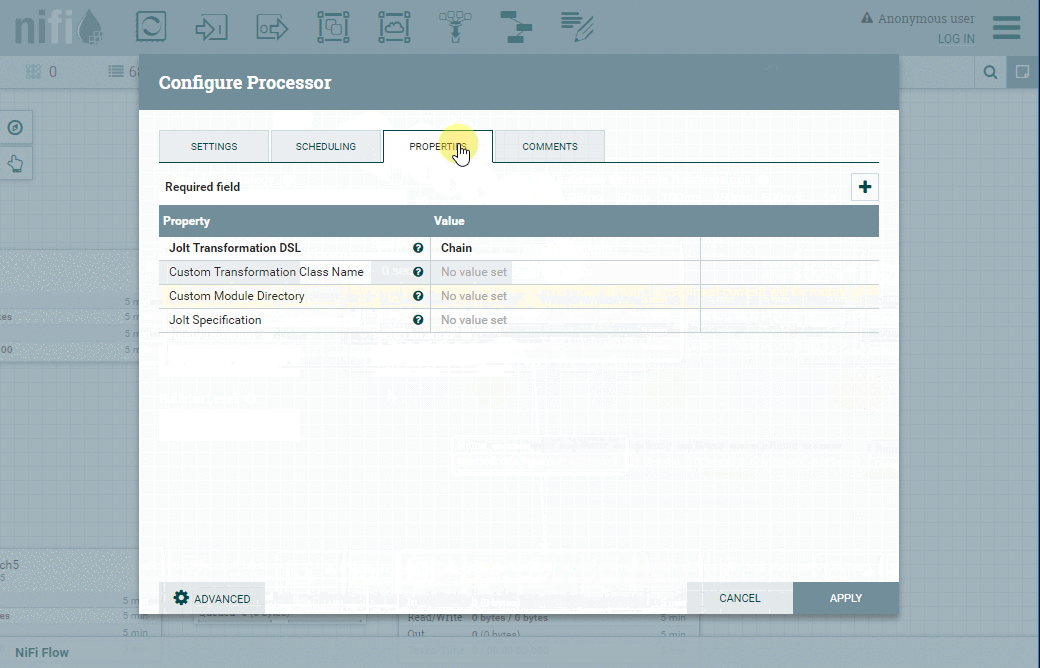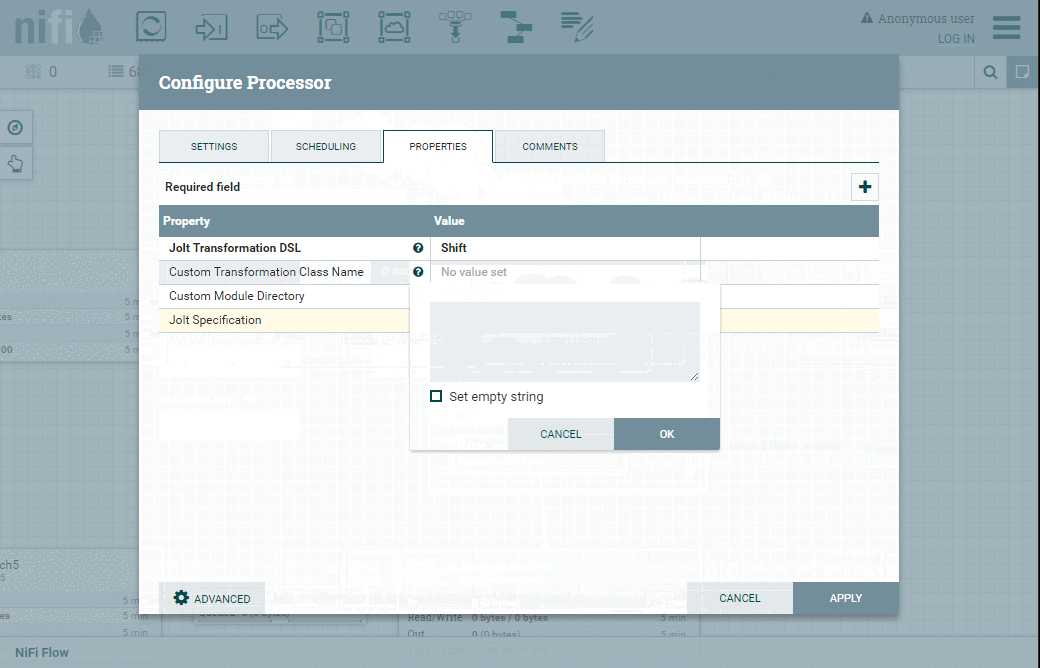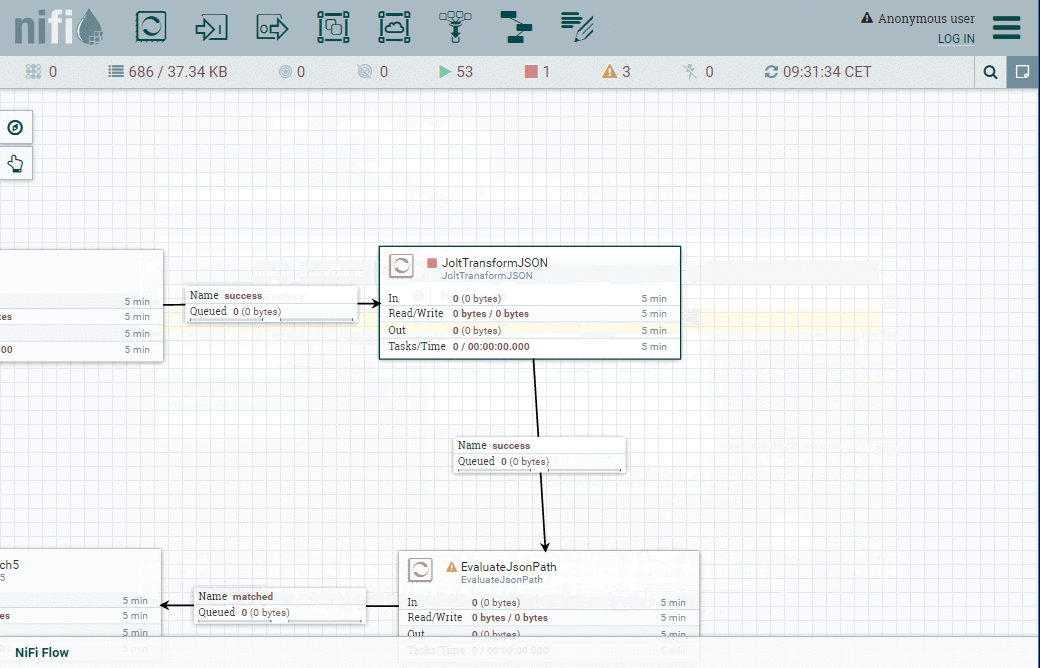
Nous allons ensuite configurer le processeur JoltTransformJSON.
Jolt est à JSON ce que XSLT est au XML. Il vous permet de spécifier dans JSON comment convertir un document d'entrée JSON en document de sortie JSON.
Nous allons utiliser ce mécanisme pour ne garder que les éléments qui nous intéressent dans le document JSON fourni par l'API Bitstamp.
Voici les paramètres à configurer :
| Onglet | Propriété | Valeur |
| Properties | Jolt Transformation DSL | Shift |
| Properties | Jolt Specification | Voir ci-dessous |
La spécification JOLT est le document JSON où nous disons essentiellement que nous allons mapper les champs timestamp, volume et last de l'entrée sur les mêmes champs de la sortie. Les autres champs seront implicitement supprimés.
Voici à quoi cela ressemble :
{
"timestamp" : "timestamp",
"last" : "last",
"volume" : "volume"
}
| Astuce pour les pros ! Les index Elasticsearch peuvent devenir volumineux très rapidement. Par conséquent, ils exigeront davantage de ressources pour stocker (espace disque) et traiter (CPU, RAM) les données. |
Processeur EvaluateJsonPath
Il y aura un index Elasticsearch pour chaque jour. Nous devons donc extraire la propriété timestamp des données JSON renvoyées par Bitstamp et le définir en tant qu'attribut Flowfile afin que nous puissions l'utiliser ultérieurement pour définir l'index dans lequel nous voulons insérer les données.
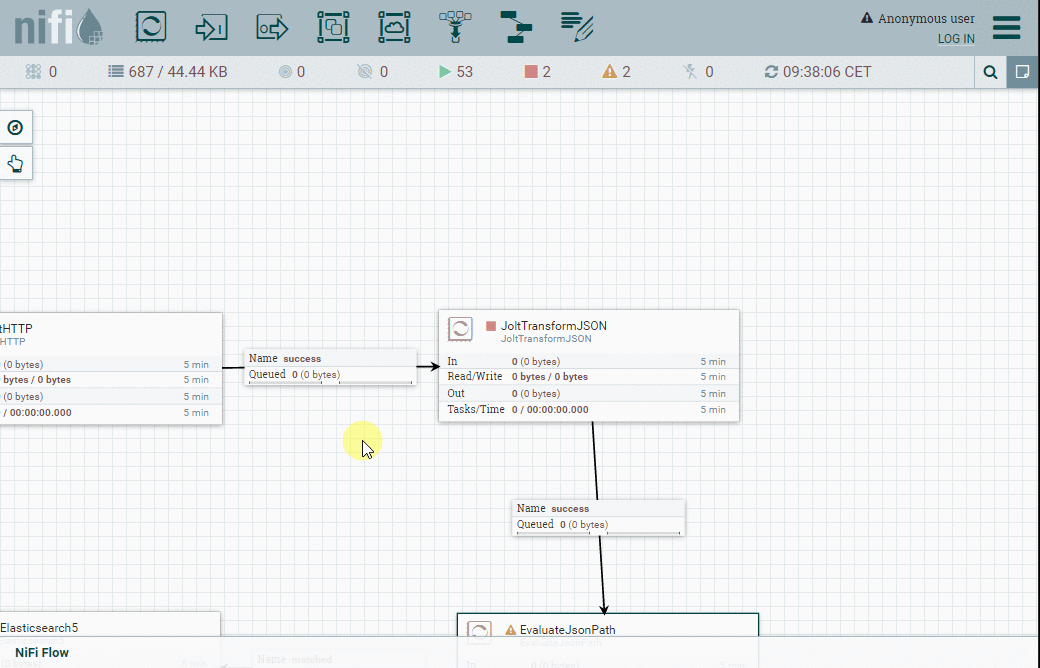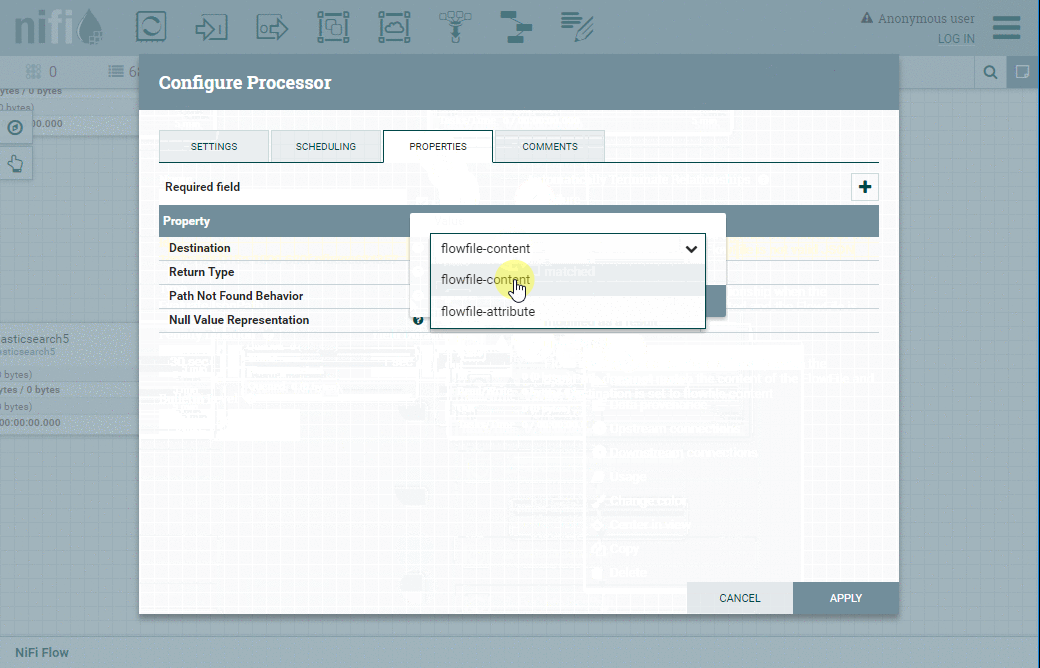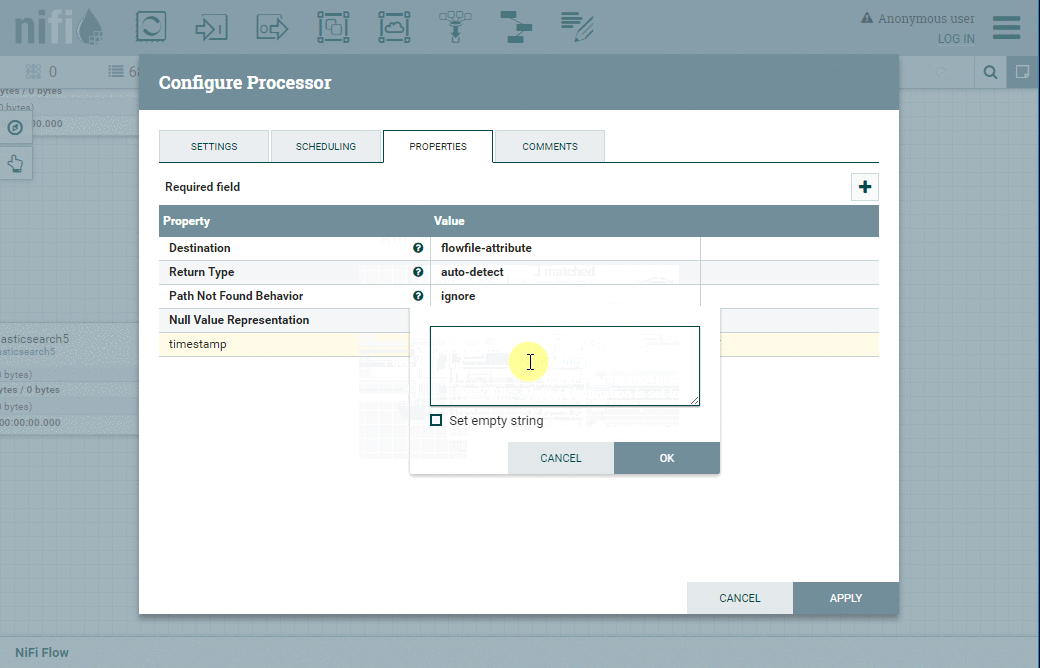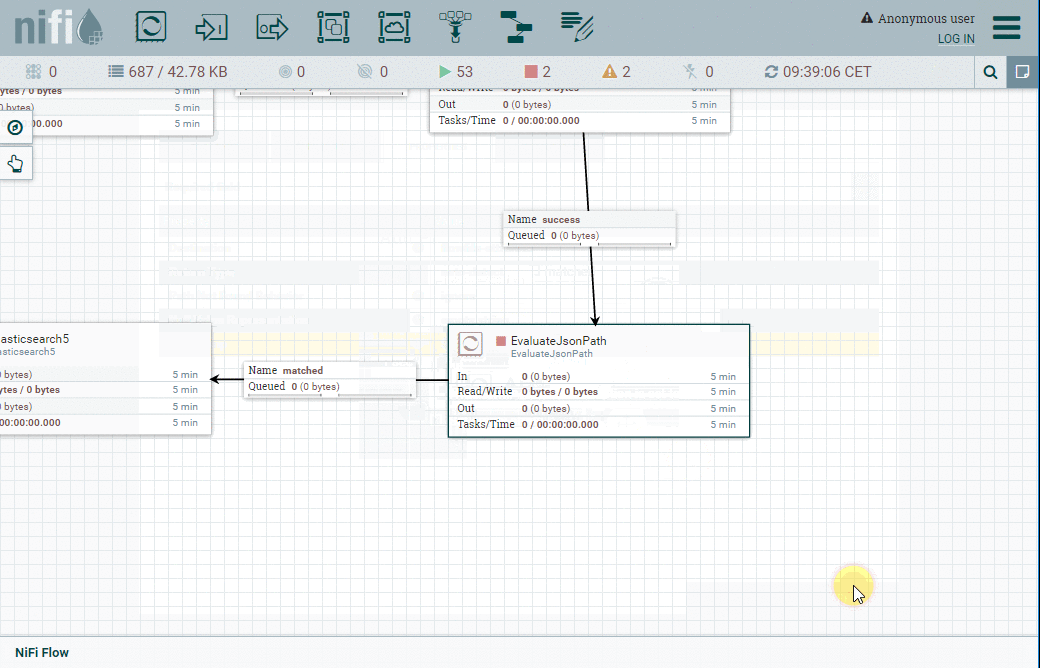
À cette fin, nous allons utiliser le processeur EvaluateJsonPath en le configurant comme indiqué dans le tableau ci-dessous :
| Onglet | Propriété | Valeur |
| Properties | Destination | Flowfile-attribute |
| Properties | timestamp | $.timestamp |
Processeur PutElasticsearch5
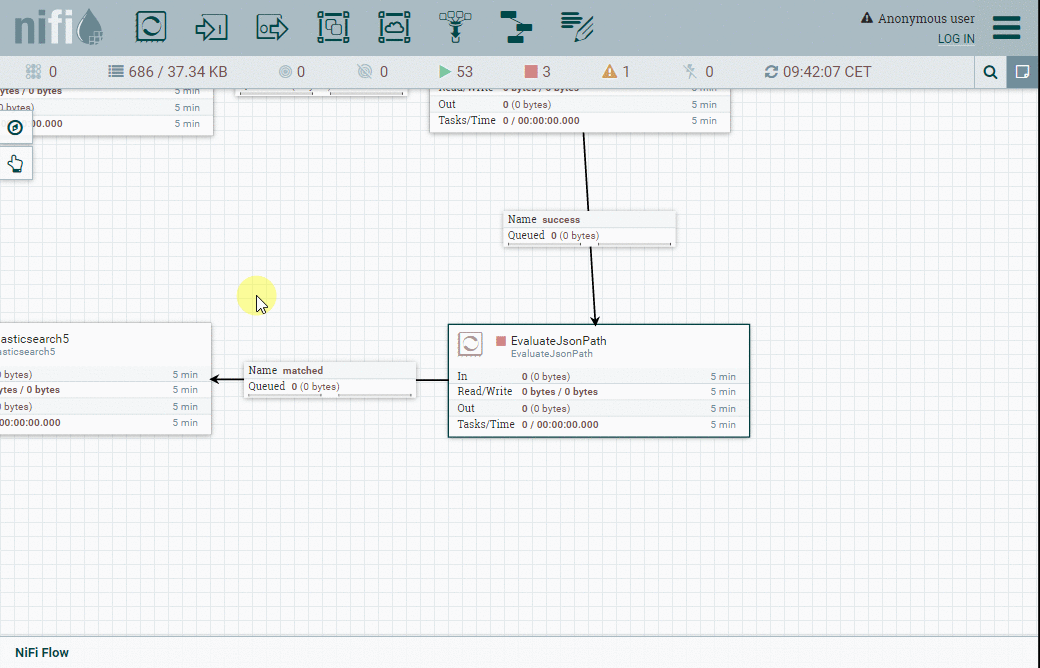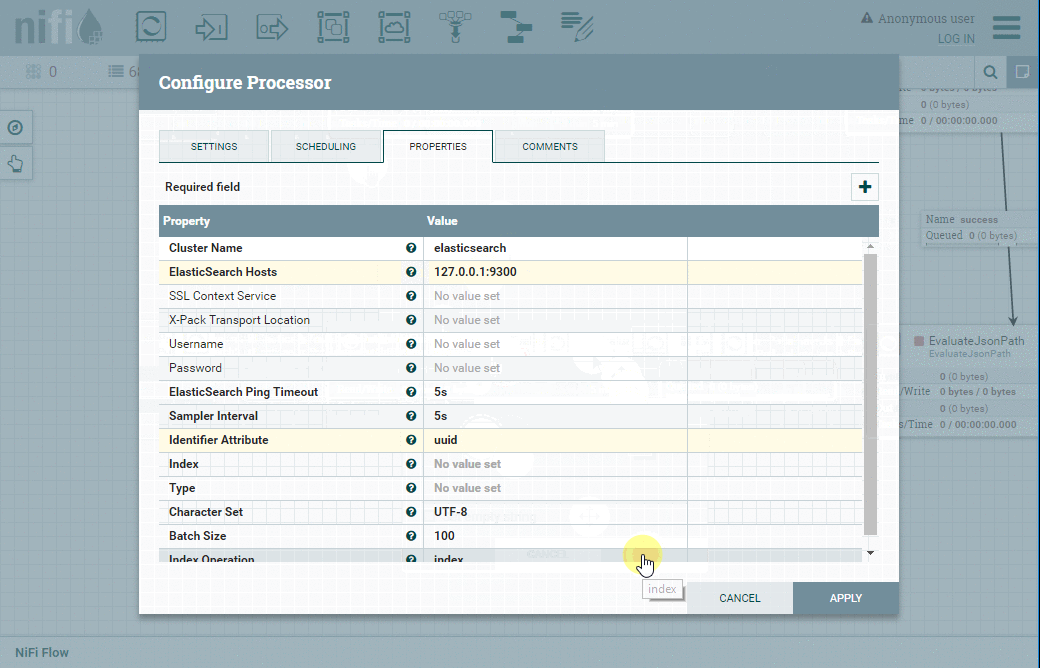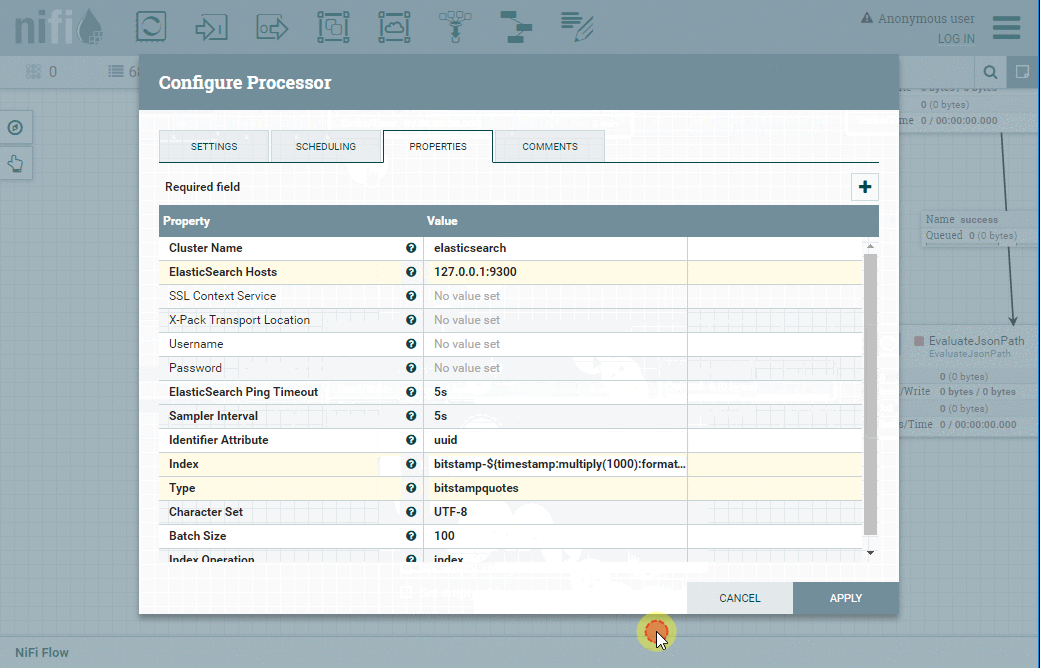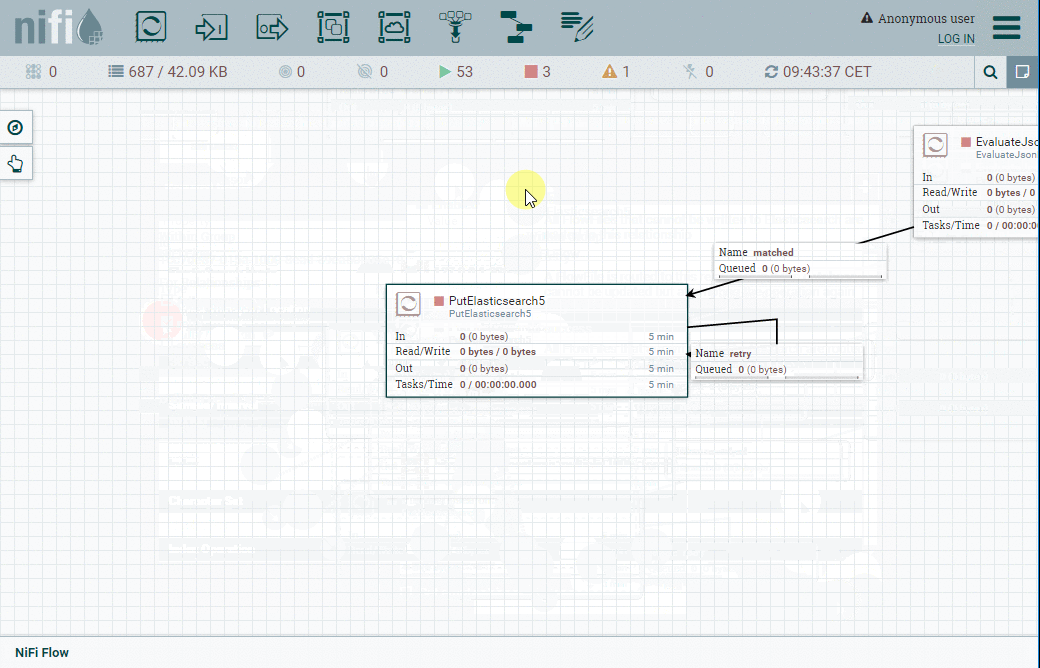
Enfin, le traitement Flowfile sera au bout du compte indexé dans Elasticsearch, opération qui sera assurée par le processeur PutElasticsearch5.
Voici les paramètres à configurer :
| Onglet | Propriété | Valeur |
| Properties | Cluster Name | Elasticsearch |
| Properties | Elasticseach Hosts | 127.0.0.1:9300 |
| Properties | Identifier Attribute | uuid |
| Properties | Index | bitstamp-${timestamp:multiply(1000):format(“yyyy-MM-dd”)} |
| Properties | Type | bitstampquotes |
| Properties | Batch Size | 100 |
À noter :
- Nous définissons l'index de sorte que son nom contienne le jour des données, et que nous puissions supprimer des index entiers lors de la purge d'anciennes données.
- Le nom
Typedoit correspondre à celui que vous avez configuré dans votre modèle d'index de sorte qu'il soit mappé aux paramètres adéquats. - Le paramètre
Batch Sizeest laissé sur sa valeur par défaut pour notre petit projet. Mais, vous devez le tester et l'ajuster de manière appropriée. Il contrôle le nombre de documents que NiFi mettra en commun avant d'envoyer une demande d'indexation en bulk à Elasticsearch.
| Astuce pour les pros ! |
Vérification du comportement des flux
Une fois que tout est en place et correctement configuré, nous pouvons définir les processeurs un par un et vérifier qu'ils se comportent comme prévu :
Timelion
Timelion est un plugin Kibana qui vous permet d'analyser des données temporelles.
Il vous permet de suivre et de comparer des sources de données différentes sur des calendriers différents (par ex. : le trafic du site Web de cette semaine par rapport à la semaine dernière), de calculer des fonctions statistiques comme les dérivées et les moyennes mobiles, et beaucoup d'autres choses encore.
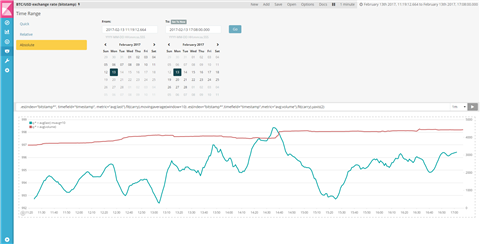
Dans notre cas, nous voulons simplement créer un graphique du taux de change Bitcoin et le volume des opérations au fil du temps :
.es(index="bitstamp*", timefield="timestamp", metric="avg:last").fit(carry).movingaverage(window=10) .es(index="bitstamp*",timefield="timestamp",metric="avg:volume").fit(carry).yaxis(2)
Regardons d'un peu plus près la première ligne :
.es(): nous utilisons la source de données Elasticsearch (.es) afin d'extraire les données des index correspondant àbitstamp*- Le champ contenant l'élément chronologique de la série temporelle est timestamp.
- Nous voulons tracer un graphique pour la moyenne du champ last (en d'autres termes, le dernier taux de change).
fit(carry): si aucune donnée n'est disponible pour un calcul nécessaire, nous utiliserons alors les données les plus récentes disponibles.movingaverage(window=10): finalement, nous tracerons un graphique de la moyenne mobile sur les 10 dernières valeurs.
Le tracé du graphique pour le volume est très similaire.
Ceci nous permet de créer le graphique suivant :
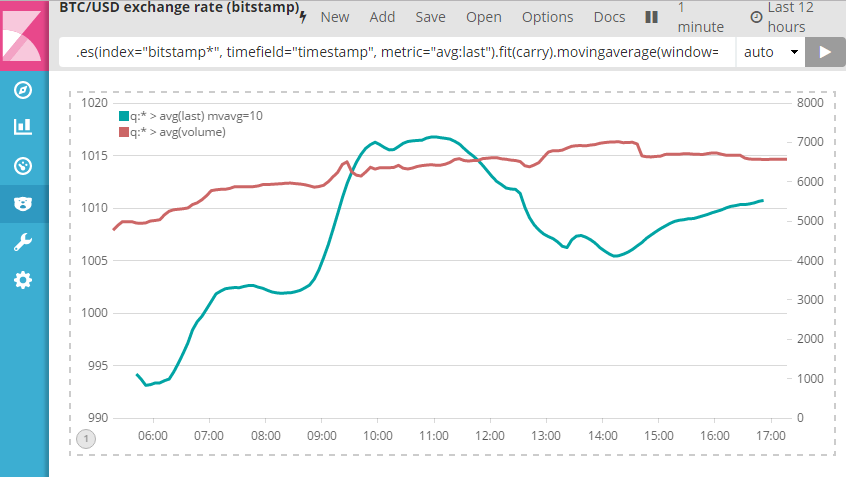
Conclusion
Elasticsearch a la réputation bien méritée d'être remarquablement rapide pour ingérer des données et répondre à des requêtes de toutes sortes.
Il permet en effet de traiter un important volume de données en pétaoctets, sur des clusters contenant des centaines ou des milliers de nœuds…
Pour y arriver au mieux, vous aurez besoin d'une connaissance approfondie de votre logique mérier et des détails techniques de la plateforme (système d'exploitation, JVM, Elasticsearch…).
Il faut s’attendre à certaines difficultés, surtout dans les configurations à grande échelle mais cela est nécessaire pour s’assurer que votre solution Elasticsearch restera rapide et que les résultats obtenus seront à la hauteur des dépenses engagées.
L’article d’origine est publié sur le blog technique de LinkByNet.
