Dimensionner les architectures hot-warm pour les logs et les métriques dans Elasticsearch Service sur Elastic Cloud
Quelle différence entre Amazon Elasticsearch Service et notre offre Elasticsearch Service officielle ? Pour le savoir, comparez les offres Elasticsearch Service d'AWS et d'Elastic sur cette page.
Excellente nouvelle ! Elasticsearch Service sur Elastic Cloud est désormais compatible avec tout un éventail de matériel et de modèles de déploiement. Le voilà parfaitement adapté au traitement efficace des logs et des métriques. Autant de flexibilité implique aussi bon nombre de décisions à prendre. Choisir l'architecture la mieux adaptée à votre cas d'utilisation et évaluer la taille du cluster dont vous aurez besoin peut être une tâche ardue. Aucune inquiétude. Nous sommes là.
Dans cet article, vous découvrirez les différentes architectures fréquemment utilisées pour les logs et les métriques et dans quels cas les utiliser. Nous vous fournirons aussi des conseils sur le dimensionnement et la gestion de votre ou de vos clusters pour une utilisation optimale.
Quelles architectures sont disponibles pour mon cluster de logs ?
Dans les clusters Elasticsearch les plus simples, tous les nœuds de données ont les mêmes spécifications et remplissent tous les rôles. À mesure qu'ils s'étendent, on y ajoute souvent des nœuds dédiés à certaines tâches (nœud maître, nœud d'ingestion et nœud de machine learning dédiés, par exemple). Cela permet de décharger les nœuds de données, qui gagnent ainsi en efficacité. Dans ce type de cluster, la charge de travail liée aux requêtes et à l'indexation est répartie entre tous les nœuds de données. Ceux-ci ayant la même spécification, on dit de ce type d'architecture de cluster qu'elle est homogène ou uniforme.
Autre architecture très appréciée (notamment par ceux qui traitent des données temporelles comme les logs et les métriques) : l'architecture hot-warm. Elle s'appuie sur l'idée que les données sont en général immuables et qu'elles peuvent être indexées dans des index temporels. Chaque index contient ainsi des données relatives à une période spécifique, ce qui rend possible la gestion de la conservation et du cycle de vie des données grâce à la suppression des anciens index. Cette architecture comporte deux types de nœuds de données présentant des profils matériels différents : les nœuds de données "hot" et les nœuds de données "warm".
Les nœuds de données hot contiennent les index les plus récents et gèrent par conséquent toute l'indexation du cluster. Les données les plus récentes étant généralement celles que l'on recherche le plus souvent, ces nœuds sont très sollicités. De plus, l'indexation dans Elasticsearch peut faire un usage très intensif du processeur et des entrées/sorties, et cette charge de travail supplémentaire liée à la recherche signifie que ces nœuds doivent rimer avec puissance et très grande rapidité de stockage. Ce qui se traduit généralement par l'utilisation de disques SSD connectés localement.
Les nœuds warm, quant à eux, sont optimisés pour le stockage à long terme des index en lecture seule du cluster. Ils riment avec rentabilité. Généralement pourvus d'une mémoire RAM et d'un processeur conséquents, ils utilisent des disques rotatifs connectés localement ou un réseau de stockage SAN en lieu et place des disques SSD. Une fois que les index des nœuds hot dépassent la période de conservation prévue sur ces nœuds et qu'ils n'y sont plus indexés, ils sont déplacés vers les nœuds warm.
Il est important de souligner que le déplacement des données des nœuds hot vers les nœuds warm n'entraîne pas nécessairement un ralentissement de la recherche. Ces nœuds ne traitant aucune indexation gourmande en ressources, ils sont souvent capables de répondre efficacement aux requêtes portant sur les anciennes données. Le tout, avec une faible latence et sans nécessiter l'utilisation d'un stockage SSD.
Les nœuds de données compris dans cette architecture sont très spécialisés et doivent pouvoir traiter une charge de travail importante. Il est donc recommandé d'utiliser des nœuds dédiés : nœud maître, nœud d'ingestion, nœud de machine learning et nœud de coordination seule.
Quelle architecture choisir ?
Ces deux architectures sont adaptées à de nombreux cas d'utilisation et il n'est pas toujours simple de décider laquelle choisir. Cependant, certaines contraintes et conditions peuvent faire pencher la balance en faveur de l'une des deux architectures.
Ainsi, le ou les types de stockage disponibles pour le cluster constituent un facteur important dont il convient de tenir compte. Une architecture hot-warm nécessite un stockage extrêmement rapide pour les nœuds hot. Elle n'est pas adaptée si le cluster ne peut finalement utiliser qu'un stockage lent. Dans ce cas, il est préférable de miser sur une architecture uniforme et de répartir l'indexation et la recherche sur le plus grand nombre de nœuds possibles.
Les clusters uniformes s'appuient souvent sur des disques rotatifs locaux ou sur un réseau de stockage SAN, bien que les disques SSD soient de plus en plus répandus. Les stockages lents sont susceptibles de ne pas pouvoir prendre en charge des taux d'indexation très élevés, notamment en cas de recherches simultanées. Le remplissage de l'espace disque peut donc prendre beaucoup de temps. Par conséquent, il n'est possible de stocker de grands volumes de données sur chaque nœud que si leur période de conservation est suffisamment longue.
Ainsi, si le cas d'utilisation prévoit une période de conservation très courte (moins de 10 jours, par exemple), les données ne resteront pas longtemps inactives sur le disque une fois indexées. Ce cas de figure nécessite un stockage performant. Une architecture hot-warm peut fonctionner, mais un cluster uniforme ne comprenant que des nœuds hot est probablement mieux adapté et plus simple à gérer.
De quel volume de stockage ai-je besoin ?
Lorsque vous dimensionnez un cluster pour le logging et/ou les indicateurs, l'un des éléments les plus importants est le volume du stockage. Le rapport entre le volume de données brutes et l'espace qu'elles occuperont sur le disque une fois indexées et répliquées dans Elasticsearch dépend beaucoup du type de données et de la façon dont elles sont indexées. Le schéma ci-dessous présente les différentes étapes que suivent les données lors de l'indexation.
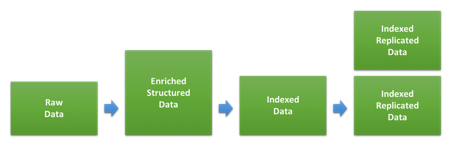
La première étape implique la transformation des données brutes en documents JSON. Ce sont ces derniers que nous indexons ensuite dans Elasticsearch. L'impact de cette transformation sur la taille des données est fonction du format d'origine et de la structure ajoutée, mais aussi de la quantité de données ajoutées via différents types d'enrichissements. On assiste à des variations considérables selon les types de données. Si vos logs sont déjà au format JSON et que vous n'ajoutez pas de données supplémentaires, la taille de vos données peut rester identique. Mais si vous avez des logs d'accès web basés sur du texte, la structure et les informations ajoutées sur le user-agent et la géolocalisation peuvent être bien plus volumineuses.
Une fois que nous indexons ces données dans Elasticsearch, les paramètres d'indexation et les mappings utilisés détermineront l'espace qu'elles occuperont sur le disque. En général, les mappings dynamiques par défaut qu'applique Elasticsearch sont plutôt conçus pour un maximum de flexibilité que pour l'optimisation du stockage sur le disque. Pour économiser de l'espace disque, vous pouvez optimiser vos mappings grâce à des modèles d'indexation personnalisés. Pour en savoir plus à ce sujet, consultez cette documentation relative à l'optimisation.
Afin d'évaluer l'espace disque que certains types de données utiliseront dans votre cluster, indexez une quantité suffisante de données. Cela vous permet d'atteindre la taille de partition (shard) que vous êtes susceptible d'utiliser en production. En phase de test, une erreur assez courante consiste à utiliser des volumes de données insuffisants, ce qui risque de générer des résultats imprécis.
Comment équilibrer ingestion et recherche ?
Lorsqu'ils dimensionnent leur cluster, la première évaluation qu'effectuent les utilisateurs vise souvent à déterminer le débit d'indexation maximal dudit cluster. Après tout, il s'agit d'une évaluation assez simple à configurer et à exécuter, et les résultats peuvent aussi servir à déterminer l'espace qu'utiliseront les données sur le disque.
Une fois que nous avons paramétré le cluster et le processus d'ingestion et que nous avons identifié le débit d'indexation maximal que nous pouvons maintenir, nous pouvons calculer le délai après lequel le disque des nœuds de données sera saturé si nous continuons à indexer à la vitesse maximale. En partant du principe que nous voulons optimiser l'utilisation de l'espace disque disponible, cela nous donne une indication sur la période de conservation minimale pour ce type de nœud.
On peut être tenté d'utiliser directement ce résultat pour déterminer la taille dont nous avons besoin. Or, nous ne disposerions alors d'aucune marge pour les recherches, toutes les ressources système étant utilisées pour l'indexation. Avouons que ce serait dommage : si les utilisateurs stockent leurs données dans Elasticsearch, c'est le plus souvent pour pouvoir les interroger à un moment ou à un autre, et il va sans dire qu'ils attendent de bonnes performances de recherche.
Quelle marge garder pour l'exécution des requêtes ? Il est difficile de donner une réponse générique à cette question. Cela dépend beaucoup du volume et de la nature des requêtes, ainsi que des niveaux de latence attendus. Le meilleur moyen de le savoir est de lancer une évaluation simulant des niveaux d'interrogation réalistes sur différents volumes de données et à différentes vitesses d'indexation, tel que décrit dans cette intervention Elastic{ON} portant sur le dimensionnement quantitatif des clusters et dans ce webinar sur l'évaluation et le dimensionnement des clusters avec Rally.
Une fois que nous avons déterminé le débit d'indexation que nous pouvons maintenir par rapport au débit maximal, tout en répondant aux requêtes des utilisateurs avec des performances acceptables, nous pouvons ajuster la période de conservation attendue, afin qu'elle corresponde à cette vitesse d'indexation moindre. Si nous ralentissons le rythme de l'indexation, nous mettrons plus de temps à remplir l'espace disque.
S'il peut nous permettre de gérer des petits pics de trafic, cet ajustement suppose en général une vitesse d'indexation constante au fil du temps. Si des pics de trafic et des fluctuations sont prévus tout au long de la journée, nous devons partir du principe que la vitesse d'indexation ajustée correspond au niveau maximal, et réduire davantage la vitesse d'indexation moyenne que chaque nœud peut gérer. En cas de fluctuations prévisibles et prolongées (par exemple pendant les heures ouvrables) une autre possibilité consiste à augmenter la taille de la zone hot pour la période concernée.
Comment utiliser tout ce stockage ?
Dans une architecture hot-warm, les nœuds warm doivent pouvoir contenir de grands volumes de données. Cela vaut aussi pour les nœuds de données d'une architecture uniforme avec période de conservation prolongée.
Le volume exact de données que vous pouvez stocker sur un nœud dépend souvent de la façon dont vous gérez l'utilisation de la mémoire. C'est souvent le principal facteur limitant que l'on rencontre sur les nœuds denses. Dans un cluster Elasticsearch, la mémoire étant sollicitée par différents processus (indexation, requêtes, mise en cache, état du cluster, données de champ et overhead de la partition, par exemple), les résultats dépendent des cas d'utilisation. De nouveau, le meilleur moyen de définir les limites applicables à votre cas d'utilisation consiste à effectuer une évaluation sur des données et des modèles de recherche réalistes. Voici toutefois quelques bonnes pratiques génériques autour des logs et des métriques, qui vous aideront à libérer tout le potentiel de vos nœuds de données.
Veillez à optimiser vos mappings
Comme évoqué plus haut, les mappings utilisés pour vos données peuvent affecter l'espace qu'elles occupent sur le disque. Ils peuvent aussi affecter la quantité de données de champ utilisées, ainsi que l'utilisation de la mémoire. Si vous avez opté pour des modules Filebeat ou des modules Logstash pour l'analyse et l'ingestion des données, ceux-ci intègrent d'office des mappings optimisés. Vous n'êtes donc pas concerné. En revanche, si vous analysez des logs personnalisés et que vous utilisez beaucoup la fonctionnalité de mapping dynamique des nouveaux champs intégrée à Elasticsearch, ce qui suit est fait pour vous.
Quand Elasticsearch assure le mapping dynamique d'une chaîne de caractères, il utilise par défaut le format champs multiples pour mapper les données en tant que texte (ce qui peut servir pour la recherche de texte libre non sensible à la casse), mais aussi en tant que mot clé (ce qui permet d'agréger les données dans Kibana). Un réglage par défaut très utile, car il permet une flexibilité optimale. Toutefois, l'inconvénient est qu'il augmente la taille des index sur le disque, ainsi que la quantité de données de champ utilisée. C'est pourquoi nous vous recommandons d'optimiser les mappings chaque fois que cela est possible, ce qui peut faire une très grande différence quand les volumes de données prennent de l'importance.
Veillez à ce que les partitions restent aussi grandes que possible
Chaque index Elasticsearch contient une ou plusieurs partitions (shards), et chacune d'entre elles présente un overhead qui utilise de l'espace mémoire. Comme l'explique cet article de blog qui traite du partitionnement, les petites partitions présentent un overhead plus important par volume de données comparées aux grandes partitions. Pour limiter au maximum l'utilisation de la mémoire sur les nœuds destinés à stocker de grands volumes de données, il est important de veiller à ce que les partitions restent aussi grandes que possible. Un bon principe de base consiste à maintenir la taille moyenne des partitions dédiées à la conservation à long terme entre 20 Go et 50 Go.
Chaque requête ou agrégation étant exécutée en monothread pour chaque partition, la latence minimale des requêtes dépend généralement de la taille de la partition. Celle-ci étant fonction des données et des requêtes, elle peut différer d'un index à l'autre, même si ces derniers relèvent du même cas d'utilisation. Pour certains volumes et types de données, il n'est cependant pas certain qu'un plus grand nombre de petites partitions affiche de meilleures performances qu'une seule grande partition.
Il est important de tester l'impact que peut avoir la taille des partitions, afin d'atteindre un équilibre optimal en tenant compte de l'utilisation des requêtes et d'un overhead minimal.
Optimisez le volume de stockage
Une compression efficace de la source JSON peut avoir un effet considérable sur l'espace disque qu'occupent les données. Par défaut, Elasticsearch compresse ces données grâce à un algorithme réglé pour atteindre un équilibre entre stockage et vitesse d'indexation, mais il propose aussi une possibilité plus radicale, le codec best_compression.
Vous pouvez le définir pour tous les nouveaux index, mais il s'accompagne d'une pénalité d'environ 5 à 10 % lors de l'indexation. Le gain d'espace disque pouvant être considérable, ce compromis peut en valoir la peine.
Si vous avez suivi les conseils de la section précédente et que vous forcez la fusion des index, vous pouvez aussi appliquer la compression améliorée juste avant de forcer la fusion.
Évitez les charges inutiles
Le dernier facteur influant sur l'utilisation de la mémoire est le traitement des requêtes. Toutes les requêtes envoyées à Elasticsearch sont coordonnées au niveau du nœud sur lequel elles arrivent. La tâche est ensuite partitionnée et répartie là où se trouvent les données. Cela concerne autant l'indexation que l'exécution de requêtes.
L'analyse et la coordination des requêtes et des réponses peuvent entraîner une utilisation considérable de la mémoire. Veillez à ce que les nœuds utilisés pour la coordination et l'indexation disposent d'une mémoire suffisante pour gérer ces tâches.
Quant aux nœuds configurés pour le stockage de données à long terme, il s'avère souvent judicieux de s'en servir comme nœuds de données dédiés et de limiter au strict minimum le nombre de tâches supplémentaires que vous leur affectez. Pour ce faire, vous pouvez diriger toutes les requêtes vers des nœuds hot ou vers des nœuds exclusivement dédiés à la coordination.
Comment appliquer tout cela à mon déploiement Elasticsearch Service ?
Elasticsearch Service est actuellement disponible sur AWS et GCP, et bien que les deux plateformes proposent les mêmes configurations d'instance et modèles de déploiement, il existe de petites différences de spécification. Dans cette section, nous aborderons les différentes configurations d'instance et verrons comment elles s'intègrent aux architectures que nous avons présentées plus haut. Nous verrons aussi comment procéder pour évaluer la taille de cluster dont nous avons besoin pour soutenir le cas d'utilisation que nous prendrons comme exemple.
Configurations d'instance disponibles
Elasticsearch Service utilise des nœuds Elasticsearch adossés à un stockage SSD rapide. C'est ce que nous appelons des nœuds highio, et ils affichent d'excellentes performances en E/S. Ils sont donc parfaitement adaptés à une utilisation comme nœuds hot dans le cadre d'une architecture hot-warm. Pour autant, ils peuvent aussi être utilisés comme nœuds de données dans une architecture uniforme. Cela est d'ailleurs souvent recommandé dans les cas où une période de conservation limitée nécessite un stockage performant.
Sur AWS et GCP, les nœuds highio affichent un ratio disque/RAM de 30:1. Autrement dit, pour 1 Go de RAM, 30 Go de stockage sont disponibles. AWS propose les tailles de nœud suivantes : 1 Go, 2 Go, 4 Go, 8 Go, 15 Go, 29 Go et 58 Go, tandis que GCP propose des tailles de 1 Go, 2 Go, 4 Go, 8 Go, 16 Go, 32 Go et 64 Go.
Autre type de nœud récemment ajouté sur Elastic Cloud : le nœud highstorage optimisé pour le stockage. Celui-ci dispose de grands volumes de stockage lent et affiche un ratio disque/RAM de 100:1. Par exemple, un nœud highstorage de 64 Go sur GCP dispose de plus de 6,2 To de stockage, et un nœud de 58 Go sur AWS propose 5,6 To. Sur chacune des deux plateformes, ces types de nœuds proposent les mêmes tailles de mémoire RAM que les nœuds highio.
Dans une architecture hot-warm, ces nœuds sont généralement utilisés comme nœuds warm. Les évaluations effectuées sur les nœuds highstorage nous apprennent que ces types de nœuds affichent de bien meilleures performances sur GCP que sur AWS, même en tenant compte des différences de tailles existantes.
2 ou 3 zones de disponibilité : que choisir ?
Dans la plupart des régions, vous pouvez choisir d'exécuter votre cluster sur deux ou trois zones de disponibilité. Et pour chaque zone du cluster, vous pouvez aussi choisir différents nombres de zone. Si vous optez pour un nombre fixe de zones de disponibilité, les tailles de cluster disponibles sont plus ou moins multipliées par deux, du moins pour les petits clusters. Si vous envisagez au contraire d'utiliser deux ou trois zones de disponibilité, vous pouvez procéder au dimensionnement par petites étapes, le passage de deux à trois zones de disponibilité en conservant la même taille de nœud n'augmentant la capacité que de 50 %.
Exemple de dimensionnement : Architecture hot-warm
Nous allons maintenant prendre l'exemple d'un cluster hot-warm qui peut ingérer quotidiennement 100 Go de logs d'accès web brut, avec une période de conservation de 30 jours. Nous allons comparer le déploiement de ce cluster avec Elastic Cloud sur AWS et sur GCP.
Remarque : Les données utilisées ici ne le sont qu'à titre d'exemple et il est fort probable que votre cas d'utilisation soit différent.
1ère étape : Évaluer le volume total des données
Dans cet exemple, nous supposons que les données sont ingérées via les modules Filebeat et que les mappings sont par conséquent optimisés. Par ailleurs, à des fins de simplification, nous nous limiterons à un seul type de données. Toujours dans cet exemple, les évaluations de l'indexation ont révélé que le ratio entre la taille des données brutes et la taille indexée sur le disque était de 1.1. On estime donc que 100 Go de données brutes donnent 110 Go de données indexées sur le disque. Un réplica a été ajouté, doublant leur taille pour atteindre 220 Go.
Sur une période de 30 jours, le volume total de données indexées et répliquées est donc de 6 600 Go, volume que le cluster dans son ensemble doit gérer.
Cet exemple suppose l'utilisation d'une partition répliquée sur l'ensemble des zones, ce qui est considéré comme une bonne pratique en matière de disponibilité et de performance.
2e étape : Dimensionner les nœuds hot
Nous avons effectué quelques évaluations du débit d'indexation maximal sur des nœuds hot utilisant cet ensemble de données, et nous avons constaté que les disques des nœuds highio sur AWS et GCP étaient pleins au bout de 3,5 jours.
Afin de garder un peu de marge pour l'exécution des requêtes et les pics de trafic, nous supposons que pour maintenir le débit d'indexation, celui-ci ne doit pas excéder 50 % du débit maximal. Si nous voulons exploiter pleinement le stockage disponible sur ces nœuds, l'indexation doit y être effectuée sur une plus longue période, et nous devons donc ajuster la période de conservation définie pour ces nœuds.
Pour une efficacité optimale, Elasticsearch nécessite aussi un espace disque supplémentaire. Pour ne pas dépasser la limite du disque, nous supposons qu'une marge de 15 % d'espace disque supplémentaire est nécessaire. Ces valeurs apparaissent dans la colonne Espace disque nécessaire du tableau ci-dessous. Tous ces éléments nous permettent de déterminer la quantité de mémoire RAM nécessaire pour chaque fournisseur.
| Plateforme | Ratio disque:RAM | Nombre de jours jusqu'au remplissage | Conservation effective (en jours) | Volume de données pris en charge (en Go) | Espace disque nécessaire (en Go) | RAM nécessaire (en Go) | Spécification relative à la zone |
| AWS | 30:1 | 3,5 | 7 | 1 440 | 1 656 | 56 | 29 Go, 2AZ |
| GCP | 30:1 | 3,5 | 7 | 1 440 | 1 656 | 56 | 32 Go, 2AZ |
3e étape : Dimensionner les nœuds warm
Les données excédant la période de conservation des nœuds hot sont déplacées vers les nœuds warm. Pour évaluer la taille nécessaire, nous calculons le volume de données que doivent contenir ces nœuds, en tenant compte de l'overhead des limites supérieures.
| Plateforme | Ratio disque:RAM | Conservation effective (en jours) | Volume de données pris en charge (en Go) | Espace disque nécessaire (en Go) | RAM nécessaire (en Go) | Spécification relative à la zone |
| AWS | 100:1 | 23 | 5 060 | 5 819 | 58 | 29 Go, 2AZ |
| GCP | 100:1 | 23 | 5 060 | 5 819 | 58 | 32 Go, 2AZ |
4e étape : Ajouter d'autres types de nœuds
Pour un cluster plus résilient et hautement disponible, outre les nœuds de données, nous avons généralement besoin de 3 nœuds maîtres dédiés. Ceux-ci ne gérant aucun trafic, leur taille peut être limitée. Pour commencer, une taille initiale de 1 à 2 Go est tout à fait adaptée. Vous pouvez ensuite scaler ces nœuds jusqu'à environ 16 Go sur 3 zones de disponibilité pour accompagner la croissance du cluster.
Et ensuite ?
Si ce n'est déjà fait, testez gratuitement la version d'essai d'Elasticsearch Service pendant 14 jours et jugez-en par vous-même. Vous verrez ainsi à quel point sa configuration et sa gestion sont simplissimes. Des questions ? Besoin d'autres conseils sur le dimensionnement d'Elasticsearch Service sur Elastic Cloud ? N'hésitez pas à nous contacter directement ou à nous faire signe sur notre forum de discussion public.